Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ta zawartość dotyczy:![]() v4.0 (GA) | Wcześniejsze wersje:
v4.0 (GA) | Wcześniejsze wersje:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (wycofywana)
v3.0 (wycofywana)![]() v2.1 (wycofywana)
v2.1 (wycofywana)
Model układu Azure Document Intelligence in Foundry Tools to zaawansowany interfejs API analizy dokumentów oparty na uczeniu maszynowym. Model jest dostępny w chmurze analizy dokumentów. Można go użyć do przetwarzania dokumentów w różnych formatach i zwracania ustrukturyzowanych reprezentacji danych z dokumentów. Model łączy ulepszoną wersję zaawansowanych funkcji optycznego rozpoznawania znaków (OCR) z modelami uczenia głębokiego w celu wyodrębniania tekstu, tabel, znaczników zaznaczenia i struktury dokumentów.
Analiza układu struktury dokumentu
Analiza układu struktury dokumentów to proces analizowania dokumentu w celu wyodrębnienia interesujących regionów i ich powiązań. Celem jest wyodrębnienie tekstu i elementów strukturalnych ze strony w celu utworzenia lepszych semantycznych modeli rozumienia. Istnieją dwa typy ról w układzie dokumentu:
- Role geometryczne: Tekst, tabele, rysunki i znaczniki zaznaczenia to przykłady ról geometrycznych.
- Role logiczne: Tytuły, nagłówki i stopki to przykłady ról logicznych tekstów.
Poniższa ilustracja przedstawia typowe składniki na obrazie przykładowej strony.

Opcje programowania
Analiza dokumentów w wersji 4.0: 2024-11-30 (GA) obsługuje następujące narzędzia, aplikacje i biblioteki.
| Funkcja | Zasoby | Identyfikator modelu |
|---|---|---|
| Model układu | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-layout |
Obsługiwane języki
Aby uzyskać pełną listę obsługiwanych języków, zobacz Obsługa języków: Modele analizy dokumentów.
Obsługiwane typy plików
Model układu analizy dokumentów w wersji 4.0: 2024-11-30 (GA) obsługuje następujące formaty plików:
| Model | Obraz: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Microsoft Office: Word (DOCX), Excel (XLS), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Układ | ✔ | ✔ | ✔ |
Wymagania dotyczące danych wejściowych
- Zdjęcia i skanowania: Aby uzyskać najlepsze wyniki, podaj jedno jasne zdjęcie lub wysokiej jakości skanowanie na dokument.
- Pliki PDF i pliki TIFF: w przypadku plików PDF i plików TIFF można przetworzyć maksymalnie 2000 stron. (W przypadku subskrypcji w warstwie Bezpłatna przetwarzane są tylko dwie pierwsze strony).
- Blokady haseł: jeśli pliki PDF są zablokowane hasłem, należy usunąć blokadę przed przesłaniem.
- Rozmiar pliku: rozmiar pliku do analizowania dokumentów wynosi 500 MB dla warstwy płatnej (S0) i 4 MB dla warstwy bezpłatnej (F0).
- Wymiary obrazu: Wymiary obrazu muszą mieć od 50 pikseli x 50 pikseli do 10 000 pikseli x 10 000 pikseli.
- Wysokość tekstu: minimalna wysokość tekstu do wyodrębnienia wynosi 12 pikseli dla obrazu o rozmiarze 1024 x 768 pikseli. Ten wymiar odpowiada około 8-punktowemu tekstowi na 150 kropek na cal.
- Trenowanie modelu niestandardowego: maksymalna liczba stron dla danych szkoleniowych to 500 dla niestandardowego modelu szablonu i 50 000 dla niestandardowego modelu neuronowego.
- Trenowanie niestandardowego modelu wyodrębniania: całkowity rozmiar danych szkoleniowych wynosi 50 MB dla modelu wzorcowego i 1 GB dla modelu neuronowego.
- Trenowanie niestandardowego modelu klasyfikacyjnego: całkowity rozmiar danych treningowych wynosi 1 GB z maksymalnie 10 000 stron. W przypadku wersji 2024-11-30 (GA) całkowity rozmiar danych treningowych wynosi 2 GB z maksymalnie 10 000 stron.
- Typy plików pakietu Office (DOCX, XLSX, PPTX): Maksymalny limit długości ciągu wynosi 8 milionów znaków.
Aby uzyskać więcej informacji na temat użycia modelu, limitów przydziału i limitów usług, zobacz Limity usług.
Wprowadzenie do modelu układu
Zobacz, jak dane, w tym tekst, tabele, nagłówki tabeli, znaczniki wyboru i informacje o strukturze, są wyodrębniane z dokumentów przy użyciu analizy dokumentów. Potrzebne są następujące zasoby:
Subskrypcja Azure. Możesz utworzyć go bezpłatnie.
Instancja Document Intelligence w portalu Azure. Aby wypróbować usługę, możesz użyć bezpłatnej warstwy cenowej (F0). Po wdrożeniu zasobu wybierz pozycję Przejdź do zasobu , aby uzyskać klucz i punkt końcowy.
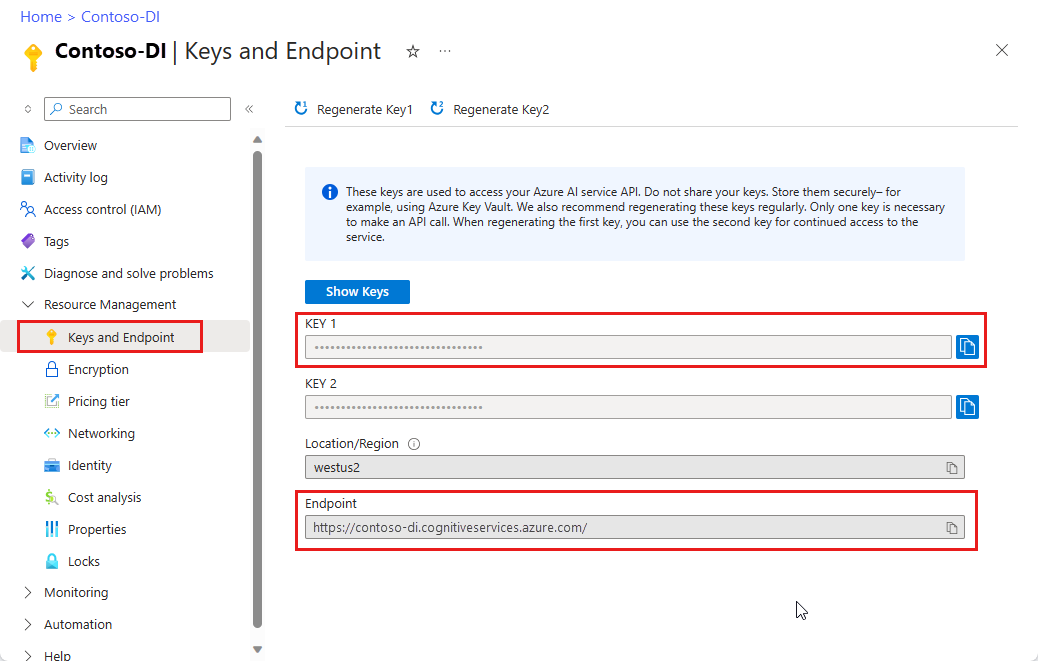
Po pobraniu klucza i punktu końcowego użyj następujących opcji programowania, aby skompilować i wdrożyć aplikacje analizy dokumentów.
Wyodrębnianie danych
Model układu wyodrębnia elementy strukturalne z dokumentów. W pozostałej części tego artykułu opisano następujące elementy strukturalne wraz ze wskazówkami dotyczącymi wyodrębniania ich z danych wejściowych dokumentu:
- Stron
- Ustępów
- Tekst, wiersze i wyrazy
- Znaczniki zaznaczenia
- Tabel
- Odpowiedź wyjściowa w formacie markdown
- Rysunki
- Sekcje
Uruchom przykładową analizę dokumentu układu w programie Document Intelligence Studio. Następnie przejdź do karty wyników i uzyskaj dostęp do pełnych danych wyjściowych JSON.
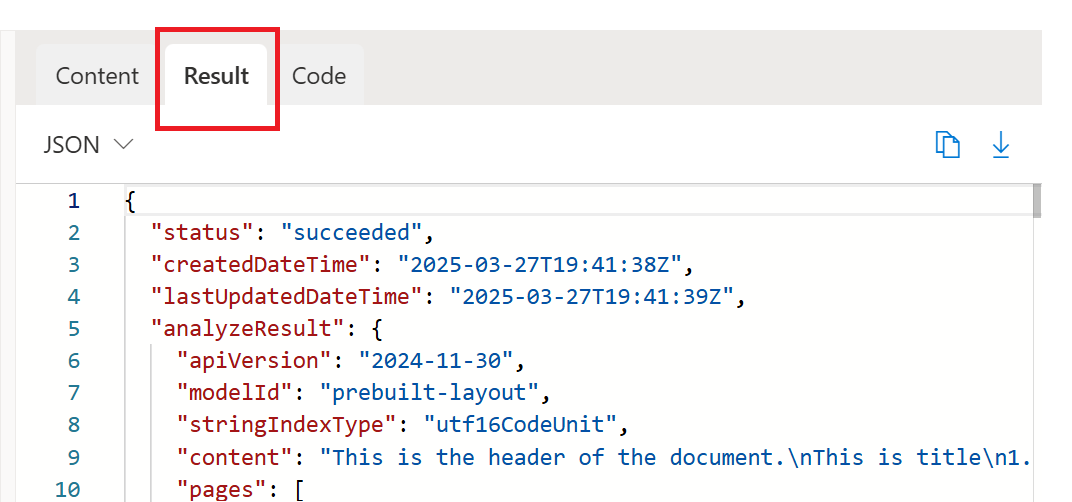
Stron
Kolekcja pages jest listą stron w dokumencie. Każda strona jest reprezentowana sekwencyjnie w dokumencie i zawiera kąt orientacji, który wskazuje, czy strona jest obracana, oraz szerokość i wysokość (wymiary w pikselach). Jednostki strony w danych wyjściowych modelu są obliczane, jak pokazano w poniższej tabeli.
| Format pliku | Obliczona jednostka strony | Łączna liczba stron |
|---|---|---|
| Obrazy (JPEG/JPG, PNG, BMP, HEIF) | Każdy obraz = 1 jednostka strony. | Łączna liczba obrazów |
| Każda strona w pliku PDF = 1 jednostka strony. | Łączna liczba stron w pliku PDF | |
| TIFF | Każdy obraz w formacie TIFF to jedna strona. | Łączna liczba obrazów w TIFF |
| Word (DOCX) | Maksymalnie 3000 znaków = 1 jednostka strony. Osadzone lub połączone obrazy nie są obsługiwane. | Łączna liczba stron po maksymalnie 3000 znaków każda |
| Excel (XLSX) | Każdy arkusz = 1 jednostka strony. Osadzone lub połączone obrazy nie są obsługiwane. | Łączna liczba arkuszy |
| PowerPoint (PPTX) | Każdy slajd = 1 jednostka strony. Osadzone lub połączone obrazy nie są obsługiwane. | Łączna liczba slajdów |
| HTML | Maksymalnie 3000 znaków = 1 jednostka strony. Osadzone lub połączone obrazy nie są obsługiwane. | Łączna liczba stron, każda z maksymalnie 3000 znakami |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Zobacz przykłady na GitHubie.
Wyodrębnianie wybranych stron
W przypadku dużych dokumentów wielostronicowych użyj parametru pages zapytania, aby wskazać określone numery stron lub zakresy stron na potrzeby wyodrębniania tekstu.
Ustępy
Model układu wyodrębnia wszystkie zidentyfikowane bloki tekstu w paragraphs kolekcji jako obiekt najwyższego poziomu pod analyzeResults. Każdy wpis w tej kolekcji reprezentuje blok tekstu i zawiera wyodrębniony tekst jako content oraz współrzędne graniczne polygon. Informacje spans wskazują fragment tekstu we właściwości najwyższego poziomu content zawierającej pełny tekst z dokumentu.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Role akapitu
Nowe wykrywanie obiektów strony na podstawie uczenia maszynowego wyodrębnia role logiczne, takie jak tytuły, nagłówki sekcji, nagłówki stron, stopki stron i inne. Model układu analizy dokumentów przypisuje niektóre bloki tekstowe w paragraphs kolekcji z ich wyspecjalizowaną rolą lub typem przewidywanym przez model.
Najlepiej używać ról akapitów z dokumentami bez struktury, aby ułatwić zrozumienie układu wyodrębnionej zawartości na potrzeby bardziej rozbudowanej analizy semantycznej. Obsługiwane są następujące role akapitu.
| Przewidywana rola | Opis | Obsługiwane typy plików |
|---|---|---|
title |
Główne nagłówki na stronie | PDF, Image, DOCX, PPTX, XLSX, HTML |
sectionHeading |
Co najmniej jedna podpozycja na stronie | PDF, Image, DOCX, XLSX, HTML |
footnote |
Tekst w dolnej części strony | PDF, obraz |
pageHeader |
Tekst w górnej krawędzi strony | PDF, Image, DOCX |
pageFooter |
Tekst w dolnej krawędzi strony | PDF, Image, DOCX, PPTX, HTML |
pageNumber |
Numer strony | PDF, obraz |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Tekst, wiersze i wyrazy
Model układu dokumentu w usłudze Document Intelligence wyodrębnia tekst drukowany i w stylu odręcznym jako lines i words. Kolekcja styles zawiera dowolny styl odręczny wierszy, jeśli zostanie wykryty, wraz z zakresami wskazującymi skojarzony tekst. Ta funkcja ma zastosowanie do obsługiwanych języków odręcznych.
W przypadku Microsoft Word, Excel, PowerPoint i HTML model układu Analizy dokumentów w wersji 4.0 2024-11-30 (GA) wyodrębnia cały osadzony tekst w następujący sposób. Teksty są wyodrębniane jako wyrazy i akapity. Obrazy osadzone nie są obsługiwane.
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
Zobacz przykłady na GitHubie.
Styl odręczny dla wierszy tekstu
Odpowiedź zawiera, czy każdy wiersz tekstu jest w stylu odręcznym, czy nie, wraz z oceną ufności. Aby uzyskać więcej informacji, zobacz Obsługa języka odręcznego. Poniższy przykład przedstawia przykładowy fragment kodu JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Jeśli włączysz funkcję dodawania czcionki/stylu, uzyskasz również wynik czcionki/stylu jako część styles obiektu.
Znaczniki zaznaczenia
Model układu wyodrębnia również znaczniki wyboru z dokumentów. Wyodrębnione znaczniki wyboru są wyświetlane w kolekcji pages dla każdej strony. Obejmują one ograniczenie polygon, confidencei zaznaczenie state (selected/unselected). Reprezentacja tekstu (czyli :selected::unselected) jest również dołączana jako indeks początkowy (offset) i length odwołuje się do właściwości najwyższego poziomu content zawierającej pełny tekst z dokumentu.
# Analyze selection marks.
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
Zobacz przykłady na GitHubie.
Tabele
Wyodrębnianie tabel jest kluczowym wymaganiem do przetwarzania dokumentów zawierających duże ilości danych zwykle sformatowanych jako tabele. Model układu wyodrębnia tabele w sekcji pageResults wyniku JSON. Wyodrębnione informacje o tabeli zawierają liczbę kolumn i wierszy, zakres wierszy i zakres kolumn.
Każda komórka z powiązanym wielokątem jest zwracana wraz z informacjami o tym, czy obszar jest rozpoznawany jako columnHeader , czy nie. Model obsługuje wyodrębnianie tabel, które są obracane. Każda komórka tabeli zawiera indeks wierszy i kolumn oraz współrzędne wielokątów ograniczających. W przypadku tekstu komórki model zwraca span informacje, które zawierają indeks początkowy (offset). Model zwraca również length w zawartości najwyższego poziomu, która zawiera pełny tekst z dokumentu.
Poniżej przedstawiono kilka czynników, które należy wziąć pod uwagę podczas korzystania z możliwości ekstrakcji danych w inteligentnej analizie dokumentów:
- Czy dane, które chcesz wyodrębnić, są przedstawione w formie tabeli i czy struktura tabeli ma sens?
- Czy dane mogą mieścić się w siatce dwuwymiarowej, jeśli dane nie są w formacie tabeli?
- Czy tabele obejmują wiele stron? Jeśli tak, aby uniknąć konieczności etykietowania wszystkich stron, przed wysłaniem go do analizy dokumentów należy podzielić plik PDF na strony. Po analizie przetwórz strony, aby stworzyć pojedynczą tabelę.
- Jeśli tworzysz modele niestandardowe , zobacz Pola tabelaryczne . Tabele dynamiczne mają zmienną liczbę wierszy dla każdej kolumny. Stałe tabele mają stałą liczbę wierszy dla każdej kolumny.
Uwaga
Analiza tabeli nie jest obsługiwana, jeśli plik wejściowy to XLSX. W przypadku wersji 2024-11-30 (GA) regiony ograniczenia dla rysunków i tabel obejmują tylko podstawową zawartość i wykluczają skojarzony podpis i przypisy dolne.
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
# Analyze cells.
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
Zobacz przykłady na GitHubie.
Konwertuj odpowiedź do formatu Markdown
API układu może wygenerować wyodrębniony tekst w formacie Markdown. Użyj elementu , outputContentFormat=markdown aby określić format danych wyjściowych w języku Markdown. Zawartość języka Markdown jest danymi wyjściowymi jako część sekcji content.
Uwaga
W przypadku wersji 4.0 2024-11-30 (GA) reprezentacja tabel jest zmieniana na tabele HTML, aby umożliwić renderowanie elementów, takich jak scalone komórki i nagłówki wielowzrokowe. Inną powiązaną zmianą jest użycie znaków ☒ pola wyboru Unicode i ☐ dla znaków zaznaczenia zamiast :selected: i :unselected:. Ta aktualizacja oznacza, że zawartość pól znacznika wyboru zawiera :selected: , mimo że ich zakresy odnoszą się do znaków Unicode w zakresie najwyższego poziomu. Aby uzyskać pełną definicję elementów języka Markdown, zobacz Format danych wyjściowych języka Markdown.
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)
Zobacz przykłady na GitHubie.
Liczby
Ilustracje (wykresy i obrazy) w dokumentach odgrywają kluczową rolę w uzupełnianiu i ulepszaniu zawartości tekstowej. Zapewniają one wizualne reprezentacje, które ułatwiają zrozumienie złożonych informacji.
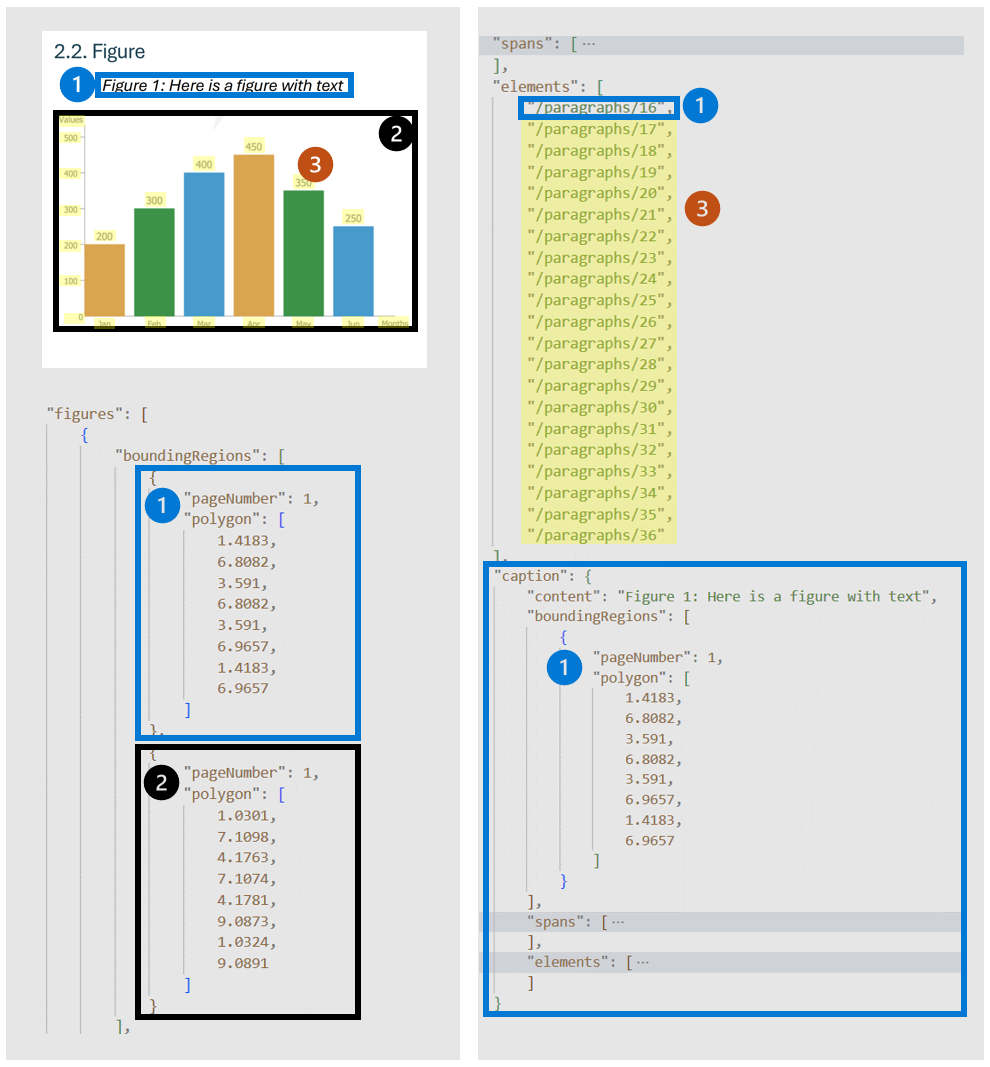
figures Obiekt wykryty przez model układu ma kluczowe właściwości, takie jak:
-
boundingRegions: lokalizacje przestrzenne rysunku na stronach dokumentu, w tym numer strony i współrzędne wielokąta, które przedstawiają granicę rysunku. -
spans: Tekst jest związany z rysunkiem i opisuje ich przesunięcia i długości w tekście dokumentu. To połączenie pomaga skojarzyć rysunek z odpowiednim kontekstem tekstowym. -
elements: identyfikatory elementów tekstowych lub akapitów w dokumencie, które są powiązane z rysunkami lub opisują je. -
caption: opis, jeśli istnieje.
Gdy output=figures jest określony podczas początkowej operacji analizowania, usługa generuje przycięte obrazy dla wszystkich wykrytych liczb, do których można uzyskać dostęp za pośrednictwem ./analyeResults/{resultId}/figures/{figureId} Wartość FigureId jest identyfikatorem uwzględnionym w każdym obiekcie rysunku, zgodnie z nieudokumentowaną konwencją {pageNumber}.{figureIndex} , w której figureIndex resetuje się do jednej na stronę.
W przypadku wersji 4.0 2024-11-30 (GA) regiony ograniczenia dla rysunków i tabel obejmują tylko podstawową zawartość i wykluczają skojarzony podpis i przypisy dolne.
# Analyze figures.
if result.figures:
for figures_idx,figures in enumerate(result.figures):
print(f"Figure # {figures_idx} has the following spans:{figures.spans}")
for region in figures.bounding_regions:
print(f"Figure # {figures_idx} location on page:{region.page_number} is within bounding polygon '{region.polygon}'")
Zobacz przykłady na GitHubie.
Sekcje
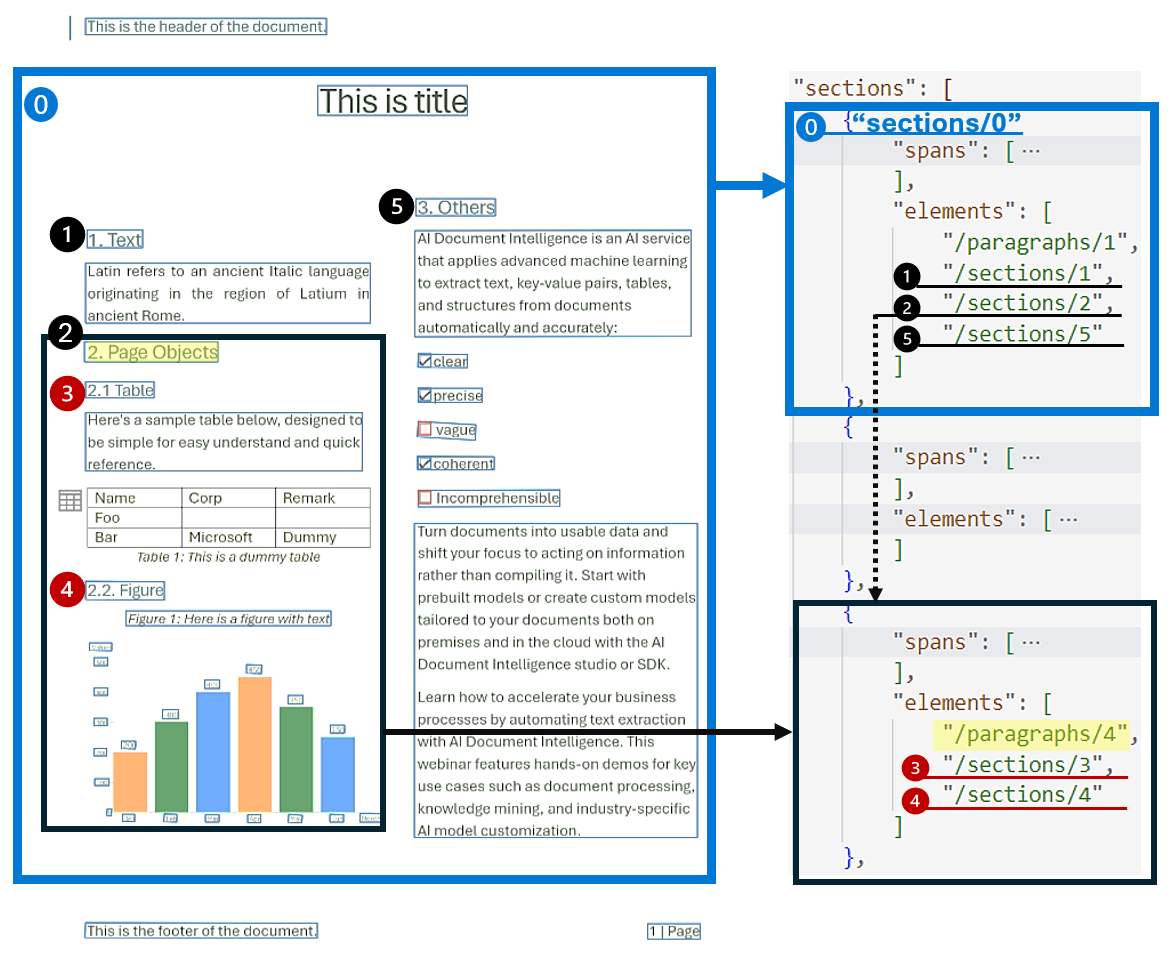
Hierarchiczna analiza struktury dokumentów jest kluczowa w organizowaniu, zrozumieniu i przetwarzaniu obszernych dokumentów. Takie podejście ma kluczowe znaczenie dla semantycznie segmentacji długich dokumentów w celu zwiększenia zrozumienia, ułatwienia nawigacji i poprawy pobierania informacji. Pojawienie się generacji wspomaganej pobieraniem (RAG) w generującej dokumenty sztucznej inteligencji podkreśla znaczenie analizy struktury dokumentów w hierarchicznej formie.
Model układu obsługuje sekcje i podsekcje w danych wyjściowych, które identyfikują relację sekcji i obiektów w każdej sekcji. Struktura hierarchiczna jest utrzymywana w elements dla każdej sekcji. Możesz użyć odpowiedzi wyjściowej do formatu Markdown , aby łatwo uzyskać sekcje i podsekcje w języku Markdown.
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)
Zobacz przykłady na GitHubie.
Ta zawartość dotyczy:![]() v3.0 (wycofywana) | Najnowsze wersje:
v3.0 (wycofywana) | Najnowsze wersje:![]() v4.0 (GA)
v4.0 (GA)![]() v3.1 | Poprzednia wersja:
v3.1 | Poprzednia wersja:![]() v2.1 (wycofywana)
v2.1 (wycofywana)
Ta zawartość dotyczy:![]() v2.1 | Najnowsza wersja:
v2.1 | Najnowsza wersja:![]() v4.0 (GA)
v4.0 (GA)
Model układu analizy dokumentów to zaawansowany interfejs API analizy dokumentów. Model jest oparty na uczeniu maszynowym i jest dostępny w chmurze analizy dokumentów. Można go użyć do przetwarzania dokumentów w różnych formatach i zwracania ustrukturyzowanych reprezentacji danych z dokumentów. Łączy ona ulepszoną wersję zaawansowanych funkcji OCR z modelami uczenia głębokiego. Służy do wyodrębniania tekstu, tabel, znaczników zaznaczenia i struktury dokumentów.
Analiza układu dokumentu
Analiza układu struktury dokumentów to proces analizowania dokumentu w celu wyodrębnienia interesujących regionów i ich powiązań. Celem jest wyodrębnienie tekstu i elementów strukturalnych ze strony w celu utworzenia lepszych semantycznych modeli rozumienia. Istnieją dwa typy ról w układzie dokumentu:
- Role geometryczne: Tekst, tabele, rysunki i znaczniki zaznaczenia to przykłady ról geometrycznych.
- Role logiczne: Tytuły, nagłówki i stopki to przykłady ról logicznych tekstów.
Poniższa ilustracja przedstawia typowe składniki na obrazie przykładowej strony.
Obsługiwane języki i ustawienia regionalne
Aby uzyskać pełną listę obsługiwanych języków, zobacz Obsługa języków: Modele analizy dokumentów.
Narzędzie Document Intelligence w wersji 2.1 obsługuje następujące narzędzia, aplikacje i biblioteki.
| Funkcja | Zasoby |
|---|---|
| Model układu | • Narzędzie do etykietowania analizy dokumentów • REST API • Biblioteka SDK klienta • Kontener Docker analizy dokumentów |
Wskazówki dotyczące danych wejściowych
Obsługiwane formaty plików:
| Model | Obraz: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Office: Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Odczytu | ✔ | ✔ | ✔ |
| Układ | ✔ | ✔ | |
| Dokument ogólny | ✔ | ✔ | |
| Wstępnie zbudowany | ✔ | ✔ | |
| Wyodrębnianie niestandardowe | ✔ | ✔ | |
| Klasyfikacja niestandardowa | ✔ | ✔ | ✔ |
- Zdjęcia i skanowania: Aby uzyskać najlepsze wyniki, podaj jedno jasne zdjęcie lub wysokiej jakości skanowanie na dokument.
- Pliki PDF i TIFF: można przetwarzać maksymalnie 2,000 stron przy użyciu bezpłatnej subskrypcji. Przetwarzane są tylko pierwsze dwie strony.
- Rozmiar pliku: rozmiar pliku do analizowania dokumentów wynosi 500 MB dla warstwy płatnej (S0) i 4 MB dla warstwy bezpłatnej (F0).
- Wymiary obrazu: Wymiary obrazu muszą mieć od 50 pikseli x 50 pikseli do 10 000 pikseli x 10 000 pikseli.
- Blokady haseł: jeśli pliki PDF są zablokowane hasłem, należy usunąć blokadę przed przesłaniem.
- Wysokość tekstu: minimalna wysokość tekstu do wyodrębnienia wynosi 12 pikseli dla obrazu o rozmiarze 1024 x 768 pikseli. Ten wymiar odpowiada około 8-punktowemu tekstowi na 150 kropek na cal.
- Trenowanie modelu niestandardowego: maksymalna liczba stron dla danych szkoleniowych to 500 dla niestandardowego modelu szablonu i 50 000 dla niestandardowego modelu neuronowego.
- Trenowanie niestandardowego modelu wyodrębniania: całkowity rozmiar danych szkoleniowych wynosi 50 MB dla modelu wzorcowego i 1 GB dla modelu neuronowego.
- Trenowanie niestandardowego modelu klasyfikacyjnego: całkowity rozmiar danych treningowych wynosi 1 GB z maksymalnie 10 000 stron. W przypadku wersji 2024-11-30 (GA) całkowity rozmiar danych treningowych wynosi 2 GB z maksymalnie 10 000 stron.
- Typy plików pakietu Office (DOCX, XLSX, PPTX): Maksymalny limit długości ciągu wynosi 8 milionów znaków.
Przewodnik po danych wejściowych
- Obsługiwane formaty plików: JPEG, PNG, PDF i TIFF.
- Obsługiwana liczba stron: w przypadku plików PDF i TIFF przetwarzane są maksymalnie 2000 stron. W przypadku subskrybentów warstwy Bezpłatna przetwarzane są tylko dwie pierwsze strony.
- Obsługiwany rozmiar pliku: rozmiar pliku musi być mniejszy niż 50 MB, a wymiary muszą mieć co najmniej 50 x 50 pikseli i maksymalnie 10 000 x 10 000 pikseli.
Wprowadzenie
Za pomocą analizy dokumentów można wyodrębniać dane, takie jak tekst, tabele, nagłówki tabeli, znaczniki zaznaczenia i informacje o strukturze z dokumentów. Potrzebne są następujące zasoby:
- Subskrypcja Azure. Możesz utworzyć go bezpłatnie.
- Instancja Document Intelligence w portalu Azure. Aby wypróbować usługę, możesz użyć bezpłatnej warstwy cenowej (F0). Po wdrożeniu zasobu wybierz pozycję Przejdź do zasobu , aby uzyskać klucz i punkt końcowy.
Po pobraniu klucza i punktu końcowego możesz użyć następujących opcji programowania do kompilowania i wdrażania aplikacji analizy dokumentów.
Uwaga
Program Document Intelligence Studio jest dostępny z interfejsami API w wersji 3.0 i nowszymi wersjami.
interfejs API REST
Narzędzie do etykietowania przykładów z analizą dokumentów
Przejdź do narzędzia do etykietowania próbek Inteligencji Dokumentów.
Na stronie głównej przykładowego narzędzia wybierz pozycję Użyj układu, aby pobrać tekst, tabele i znaczniki wyboru.
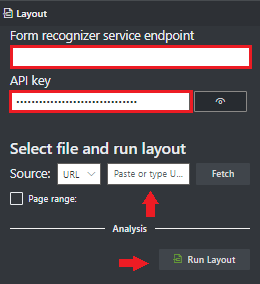
W polu Punkt końcowy usługi Analizy dokumentów wklej punkt końcowy uzyskany w ramach subskrypcji analizy dokumentów.
W polu klucz wklej klucz uzyskany z zasobu analizy dokumentów.
W polu Źródło wybierz pozycję Adres URL z menu rozwijanego. Możesz użyć przykładowego dokumentu:
Wybierz Pobierz.
Wybierz Uruchom układ. Narzędzie do etykietowania próbek w technologii Document Intelligence wywołuje API do analizy układu w celu analizy dokumentu.
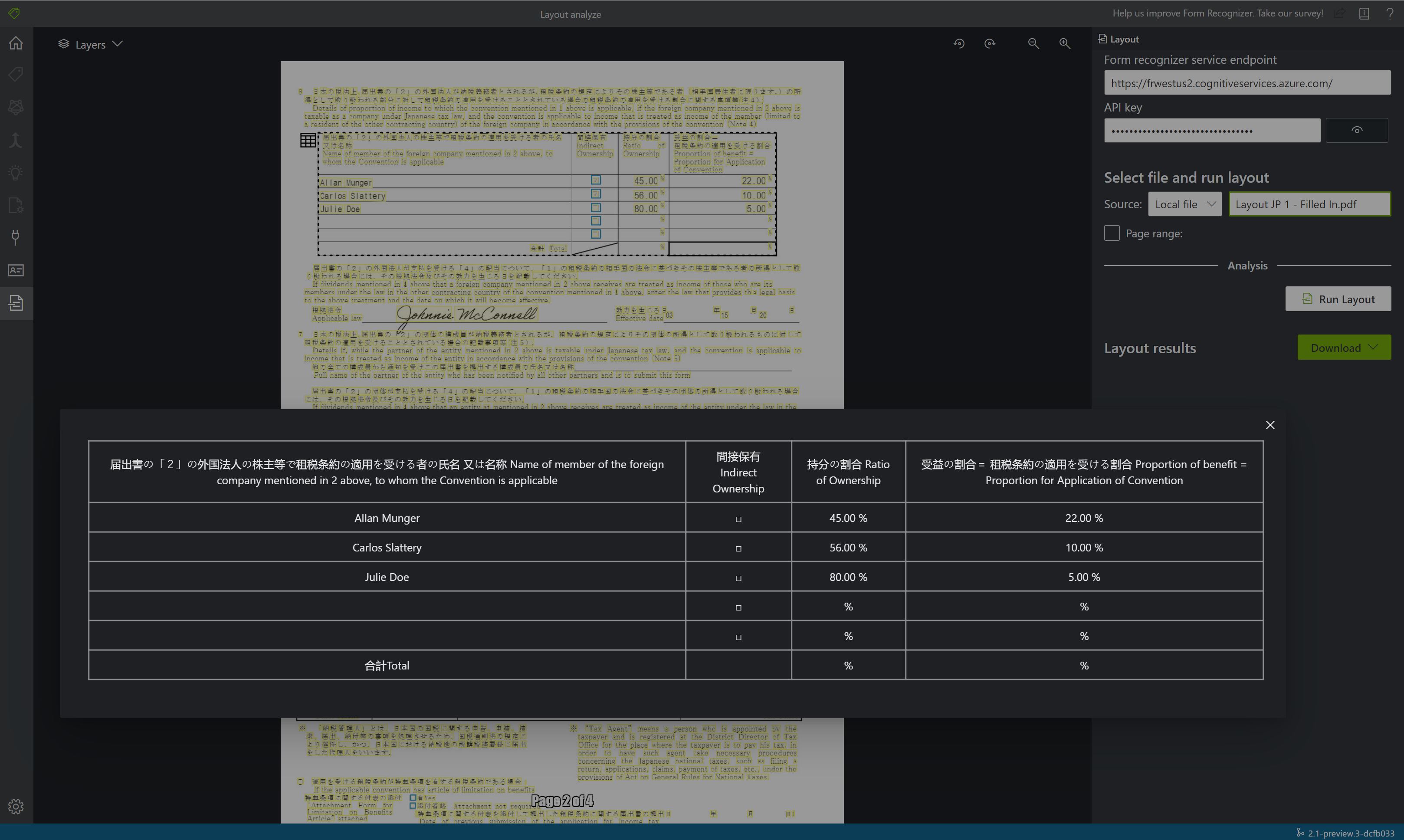
Wyświetl wyniki. Zobacz wyróżniony wyodrębniony tekst, wykryte znaczniki zaznaczenia i wykryte tabele.
{kind=link}
Narzędzie Document Intelligence w wersji 2.1 obsługuje następujące narzędzia, aplikacje i biblioteki.
| Funkcja | Zasoby |
|---|---|
| Layout API | • Narzędzie do etykietowania analizy dokumentów • REST API • Biblioteka SDK klienta • Kontener Docker analizy dokumentów |
Wyodrębnianie danych
Model układu wyodrębnia elementy strukturalne z dokumentów. Elementy strukturalne zostały opisane tutaj, a poniższe wskazówki pokazują, jak wyodrębnić je z danych wejściowych dokumentu.
Wyodrębnianie danych
Model układu wyodrębnia elementy strukturalne z dokumentów. Elementy strukturalne zostały opisane tutaj, a poniższe wskazówki pokazują, jak wyodrębnić je z danych wejściowych dokumentu.
Strona
Kolekcja pages jest listą stron w dokumencie. Każda strona jest reprezentowana sekwencyjnie w dokumencie i zawiera kąt orientacji, który wskazuje, czy strona jest obracana, oraz szerokość i wysokość (wymiary w pikselach). Jednostki strony w danych wyjściowych modelu są obliczane, jak pokazano w poniższej tabeli.
| Format pliku | Obliczona jednostka strony | Łączna liczba stron |
|---|---|---|
| Obrazy (JPEG/JPG, PNG, BMP, HEIF) | Każdy obraz = 1 jednostka strony. | Łączna liczba obrazów |
| Każda strona w pliku PDF = 1 jednostka strony. | Łączna liczba stron w pliku PDF | |
| TIFF | Każdy obraz w formacie TIFF to jedna strona. | Łączna liczba obrazów w TIFF |
| Word (DOCX) | Maksymalnie 3000 znaków = 1 jednostka strony. Osadzone lub połączone obrazy nie są obsługiwane. | Łączna liczba stron, każda z maksymalnie 3000 znakami |
| Excel (XLSX) | Każdy arkusz = 1 jednostka strony. Osadzone lub połączone obrazy nie są obsługiwane. | Łączna liczba arkuszy |
| PowerPoint (PPTX) | Każdy slajd = 1 jednostka strony. Osadzone lub połączone obrazy nie są obsługiwane. | Łączna liczba slajdów |
| HTML | Maksymalnie 3000 znaków = 1 jednostka strony. Osadzone lub połączone obrazy nie są obsługiwane. | Łączna liczba stron, każda z maksymalnie 3000 znakami |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Zobacz przykłady na GitHubie.
Wyodrębnianie wybranych stron z dokumentów
W przypadku dużych dokumentów wielostronicowych użyj parametru pages zapytania, aby wskazać określone numery stron lub zakresy stron na potrzeby wyodrębniania tekstu.
Ustęp
Model układu wyodrębnia wszystkie zidentyfikowane bloki tekstu w paragraphs kolekcji jako obiekt najwyższego poziomu pod analyzeResults. Każdy wpis w tej kolekcji reprezentuje blok tekstu i zawiera wyodrębniony tekst jako content oraz ograniczające współrzędne polygon. Informacje span wskazują fragment tekstu we właściwości najwyższego poziomu content zawierającej pełny tekst z dokumentu.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Rola akapitu
Nowe wykrywanie obiektów strony na podstawie uczenia maszynowego wyodrębnia role logiczne, takie jak tytuły, nagłówki sekcji, nagłówki stron, stopki stron i inne. Model układu analizy dokumentów przypisuje niektóre bloki tekstowe w paragraphs kolekcji z ich wyspecjalizowaną rolą lub typem przewidywanym przez model. Najlepiej używać ról akapitów z dokumentami bez struktury, aby ułatwić zrozumienie układu wyodrębnionej zawartości na potrzeby bardziej rozbudowanej analizy semantycznej. Obsługiwane są następujące role akapitu.
| Przewidywana rola | Opis | Obsługiwane typy plików |
|---|---|---|
title |
Główne nagłówki na stronie | PDF, Image, DOCX, PPTX, XLSX, HTML |
sectionHeading |
Co najmniej jedna podpozycja na stronie | PDF, Image, DOCX, XLSX, HTML |
footnote |
Tekst w dolnej części strony | PDF, obraz |
pageHeader |
Tekst w górnej krawędzi strony | PDF, Image, DOCX |
pageFooter |
Tekst w dolnej krawędzi strony | PDF, Image, DOCX, PPTX, HTML |
pageNumber |
Numer strony | PDF, obraz |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Tekst, wiersz i wyraz
Model układu dokumentu w usłudze Document Intelligence wyodrębnia tekst drukowany i odręczny jako wiersze i wyrazy. Kolekcja styles zawiera dowolny styl odręczny wierszy, jeśli zostaną wykryte wraz z zakresami wskazującymi skojarzony tekst. Ta funkcja ma zastosowanie do obsługiwanych języków odręcznych.
W przypadku Word, Excel, PowerPoint i HTML model układu Analizy dokumentów w wersji 4.0 2024-11-30 (GA) wyodrębnia cały osadzony tekst w następujący sposób. Teksty są wyodrębniane jako wyrazy i akapity. Obrazy osadzone nie są obsługiwane.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
przykłady Zobacz na GitHubie.
Styl odręczny
Odpowiedź zawiera klasyfikację, czy każdy wiersz tekstu ma styl pisma ręcznego, czy nie, wraz z współczynnikiem ufności. Aby uzyskać więcej informacji, zobacz Obsługa języka odręcznego. Poniższy przykład przedstawia przykładowy fragment kodu JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Jeśli włączysz funkcję dodawania czcionki/stylu, uzyskasz również wynik czcionki/stylu jako część styles obiektu.
Znacznik wyboru
Model układu wyodrębnia również znaczniki wyboru z dokumentów. Wyodrębnione znaczniki wyboru są wyświetlane w kolekcji pages dla każdej strony. Obejmują one ograniczenie polygon, confidencei zaznaczenie state (selected/unselected). Reprezentacja tekstu (czyli :selected::unselected) jest również dołączana jako indeks początkowy (offset) i length odwołuje się do właściwości najwyższego poziomu content zawierającej pełny tekst z dokumentu.
{
"selectionMarks": [
{
"state": "unselected",
"polygon": [],
"confidence": 0.995,
"span": {
"offset": 1421,
"length": 12
}
}
]
}
# Analyze selection marks.
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
Zobacz przykłady na GitHubie.
Tabeli
Wyodrębnianie tabel jest kluczowym wymaganiem do przetwarzania dokumentów zawierających duże ilości danych zwykle sformatowanych jako tabele. Model układu wyodrębnia tabele w sekcji pageResults wyniku JSON. Wyodrębnione informacje o tabeli zawierają liczbę kolumn i wierszy, zakres wierszy i zakres kolumn. Każda komórka z powiązanym wielokątem jest zwracana wraz z informacjami o tym, czy obszar jest rozpoznawany jako columnHeader , czy nie.
Model obsługuje wyodrębnianie tabel, które są obracane. Każda komórka tabeli zawiera indeks wierszy i kolumn oraz współrzędne wielokątów ograniczających. W przypadku tekstu komórki model zwraca span informacje, które zawierają indeks początkowy (offset). Model zwraca również length w zawartości najwyższego poziomu, która zawiera pełny tekst z dokumentu.
Poniżej przedstawiono kilka czynników, które należy wziąć pod uwagę podczas korzystania z możliwości ekstrakcji danych w inteligentnej analizie dokumentów:
- Czy dane, które chcesz wyodrębnić, są przedstawione w formie tabeli i czy struktura tabeli ma sens?
- Czy dane mogą mieścić się w siatce dwuwymiarowej, jeśli dane nie są w formacie tabeli?
- Czy tabele obejmują wiele stron? Jeśli tak, aby uniknąć konieczności etykietowania wszystkich stron, przed wysłaniem go do analizy dokumentów należy podzielić plik PDF na strony. Po analizie przetwórz strony, aby stworzyć pojedynczą tabelę.
- Jeśli tworzysz modele niestandardowe , zobacz Pola tabelaryczne . Tabele dynamiczne mają zmienną liczbę wierszy dla każdej kolumny. Stałe tabele mają stałą liczbę wierszy dla każdej kolumny.
Uwaga
Analiza tabeli nie jest obsługiwana, jeśli plik wejściowy to XLSX. Document Intelligence w wersji 4.0 z 30.11.2024 (GA) obsługuje regiony ograniczeń dla rysunków i tabel, które obejmują tylko treść główną i wykluczają skojarzone podpisy i przypisy dolne.
{
"tables": [
{
"rowCount": 9,
"columnCount": 4,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"columnSpan": 4,
"content": "(In millions, except earnings per share)",
"boundingRegions": [],
"spans": []
},
]
}
]
}
# Analyze tables.
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
Zobacz przykłady na GitHubie.
Adnotacje
Model układu graficznego wyodrębnia adnotacje w dokumentach, takie jak znaki i krzyże. Odpowiedź zawiera rodzaj adnotacji, wynik pewności oraz wielokąt ograniczający.
{
"pages": [
{
"annotations": [
{
"kind": "cross",
"polygon": [...],
"confidence": 1
}
]
}
]
}
Dane wyjściowe kolejności odczytu naturalnego (wyłącznie w alfabecie łacińskim)
Możesz określić kolejność, w jakiej wiersze tekstowe są danymi wyjściowymi z parametrem readingOrder zapytania. Użyj natural dla bardziej przyjaznej dla człowieka kolejności czytania, jak pokazano w poniższym przykładzie. Ta funkcja jest obsługiwana tylko w językach łacińskich.

Wybieranie numeru strony lub zakresu na potrzeby wyodrębniania tekstu
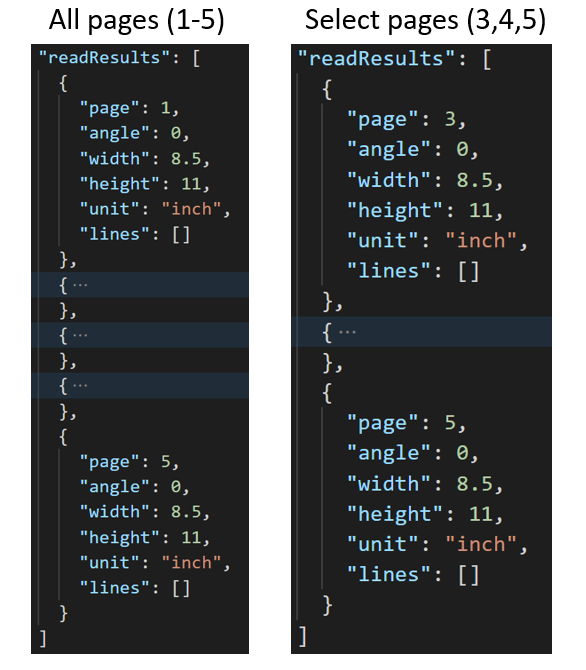
W przypadku dużych dokumentów wielostronicowych użyj parametru pages zapytania, aby wskazać określone numery stron lub zakresy stron na potrzeby wyodrębniania tekstu. Poniższy przykład przedstawia dokument z 10 stronami z tekstem wyodrębnionym w obu przypadkach, wszystkimi stronami (1–10) i wybranymi stronami (3–6).
Operacja Pobierz wynik układu analizy
Drugim krokiem jest wywołanie Get Analyze Layout Result operacji. Ta operacja przyjmuje jako dane wejściowe identyfikator wyniku, który został utworzony przez operację Analyze Layout . Zwraca odpowiedź JSON zawierającą pole stanu z następującymi możliwymi wartościami.
| Pole | Typ | Możliwe wartości |
|---|---|---|
| Stan | ciąg |
notStarted: Operacja analizy nie została uruchomiona.running: Operacja analizy jest w toku.failed: Operacja analizy nie powiodła się.succeeded: Operacja analizy zakończyła się pomyślnie. |
Wywołaj tę operację iteracyjnie, dopóki nie zwróci succeeded wartości. Aby uniknąć przekroczenia liczby żądań na sekundę, należy użyć interwału od trzech do pięciu sekund.
Gdy pole stanu ma succeeded wartość, odpowiedź JSON zawiera wyodrębniony układ, tekst, tabele i znaczniki zaznaczenia. Wyodrębnione dane obejmują wyodrębnione wiersze tekstu i wyrazy, ramki ograniczające, wygląd tekstu z oznaczeniem pisma odręcznego, tabeli oraz znaczniki zaznaczenia z oznaczeniem jako wybrane/niewybrane.
Klasyfikacja odręczna dla wierszy tekstu (tylko łaciński)
Odpowiedź zawiera klasyfikację, czy każdy wiersz tekstu ma styl odręczny, czy nie, wraz z oceną ufności. Ta funkcja jest obsługiwana tylko w językach łacińskich. Poniższy przykład przedstawia klasyfikację odręczną tekstu na obrazie.
Zrzut ekranu przedstawiający proces klasyfikacji pisma ręcznego przez model układu.
Przykładowe dane wyjściowe JSON
Odpowiedź na Get Analyze Layout Result operację jest ustrukturyzowaną reprezentacją dokumentu ze wszystkimi wyodrębnionymi informacjami.
Zobacz plik dokumentu przykładowy i jego ustrukturyzowane dane wyjściowe przykładowe dane wyjściowe układu.
Dane wyjściowe JSON mają dwie części:
- Węzeł
readResultszawiera cały rozpoznany tekst i znacznik zaznaczenia. Hierarchia prezentacji tekstowej to strona, a następnie wiersz, a następnie poszczególne wyrazy. - Węzeł
pageResultszawiera tabele i komórki wyodrębnione z ich ramkami ograniczającymi, stopniem pewności oraz odniesieniem do wierszy i wyrazów w polureadResults.
Przykładowe dane wyjściowe
Tekst
Interfejs API rozkładu tekstu wyodrębnia tekst z dokumentów i obrazów, niezależnie od wielu kątów i kolorów tekstu. Akceptuje zdjęcia dokumentów, faksów, tekstów drukowanych i/lub odręcznych (tylko w języku angielskim) oraz dokumentów mieszanych. Tekst jest wyodrębniany z informacjami podanymi w wierszach, wyrazach, ramkach ograniczających, wskaźnikach ufności i stylu (odręcznego lub innego). Wszystkie informacje tekstowe znajdują się w readResults sekcji danych wyjściowych JSON.
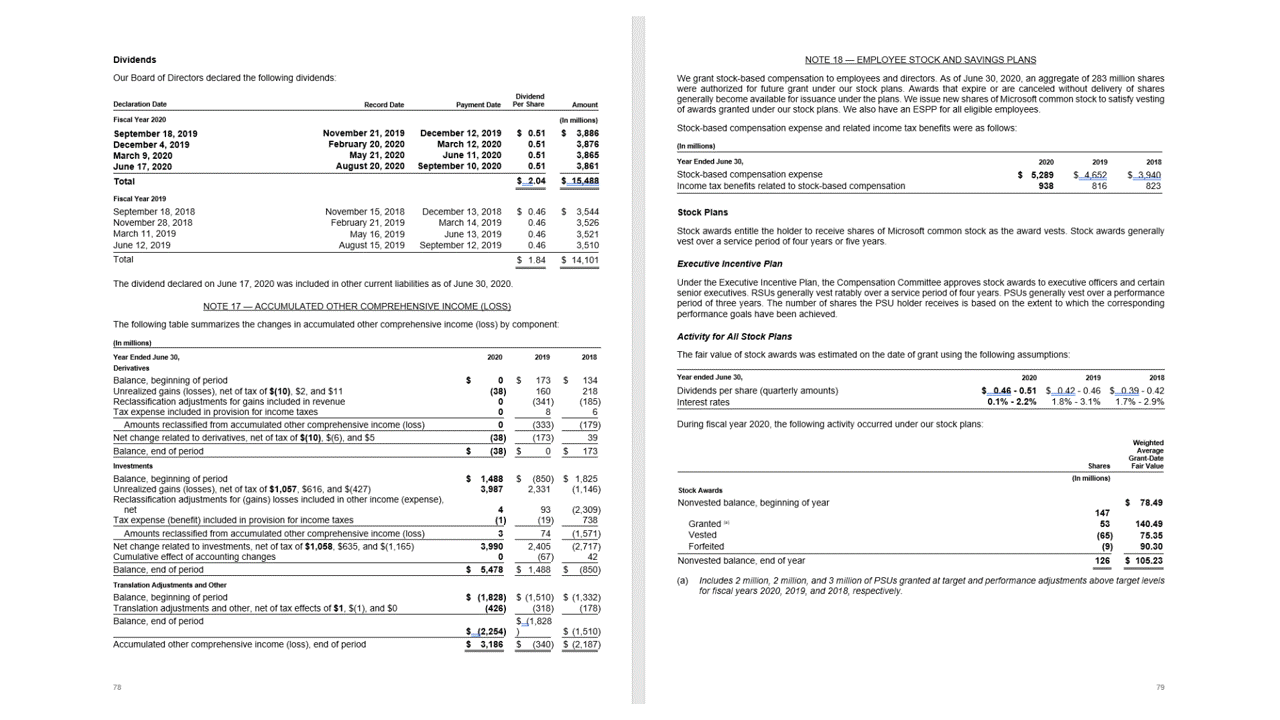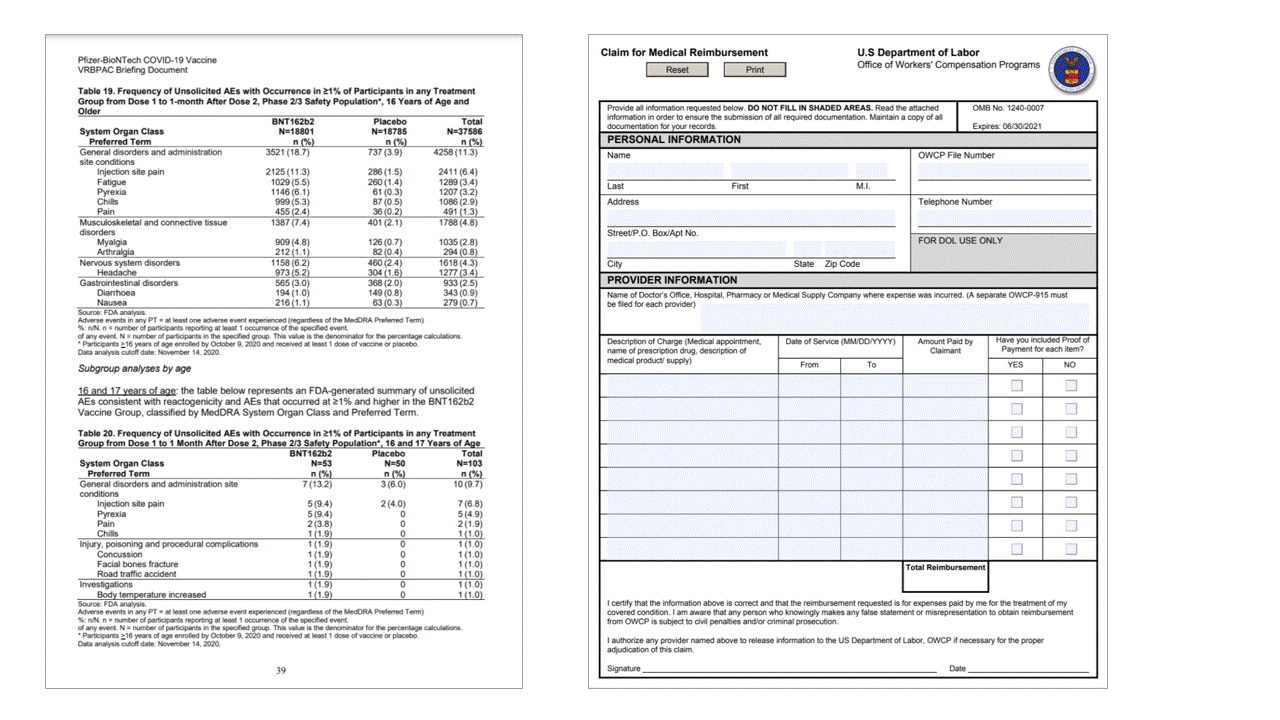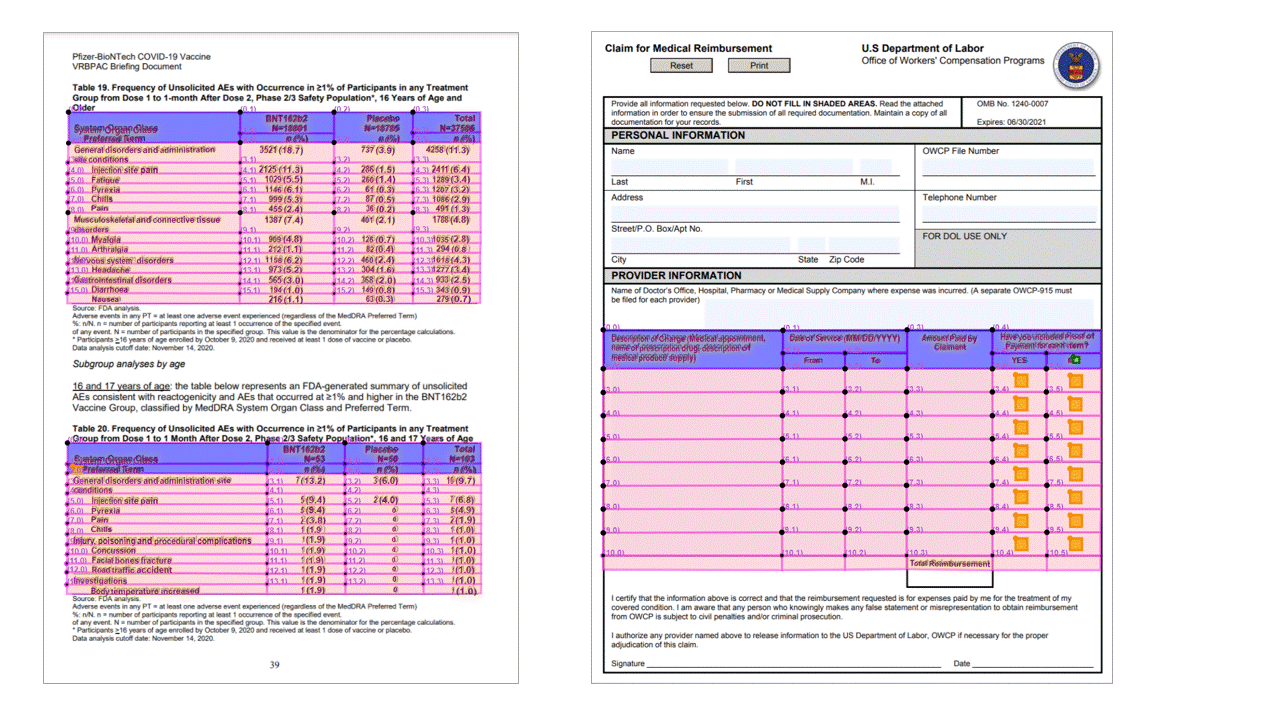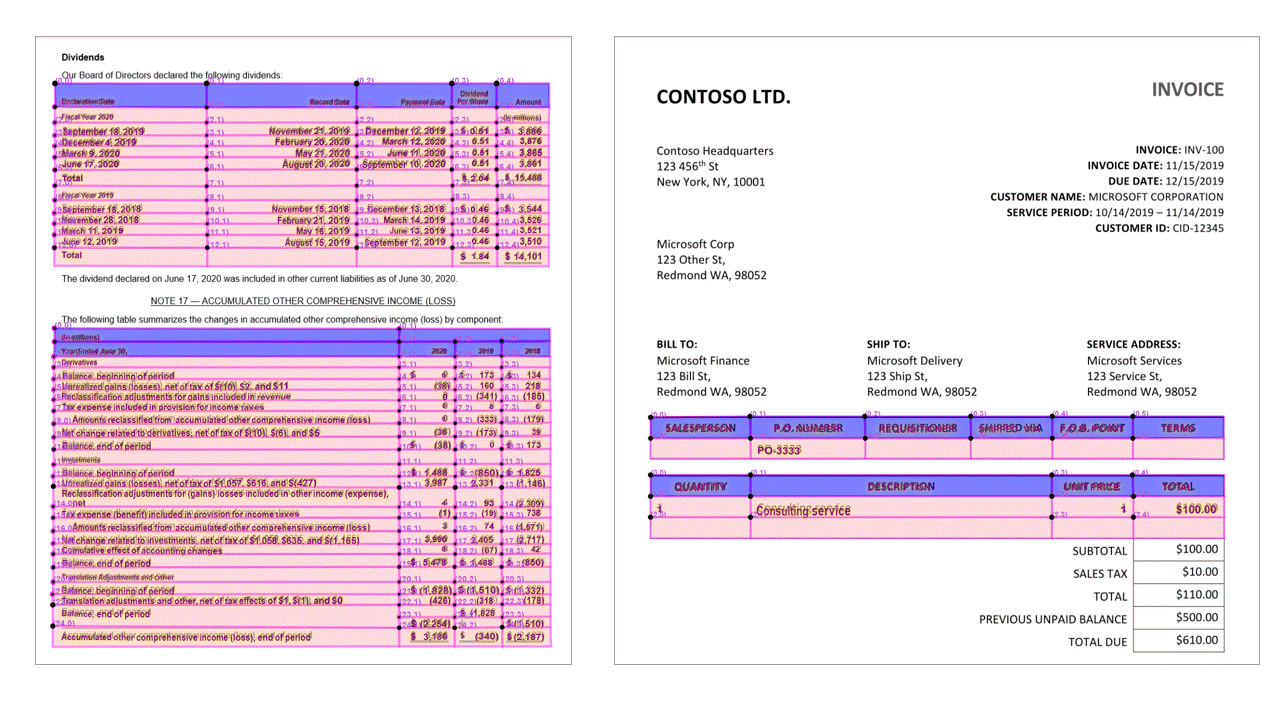
Tabele z nagłówkami
Interfejs API layoutu wyodrębnia tabele w pageResults sekcji danych wyjściowych JSON. Możesz skanować, fotografować lub cyfrować dokumenty. Tabele mogą być złożone ze scalanymi komórkami lub kolumnami, z obramowaniem lub bez obramowania oraz z nieparzystnymi kątami.
Wyodrębnione informacje o tabeli zawierają liczbę kolumn i wierszy, zakres wierszy i zakres kolumn. Każda komórka z polem ograniczenia jest danymi wyjściowymi wraz z tym, czy obszar jest rozpoznawany jako część nagłówka, czy nie. Komórki nagłówkowe przewidywane przez model mogą obejmować wiele wierszy i nie muszą być pierwszymi wierszami w tabeli. Współpracują również z obróconymi tabelami. Każda komórka tabeli zawiera również pełny tekst z odwołaniami do poszczególnych wyrazów w readResults sekcji.
Znaczniki zaznaczenia (dokumenty)
Interfejs API układu wyodrębnia również znaczniki wyboru z dokumentów. Wyodrębnione znaczniki zaznaczenia obejmują pole ograniczenia, stopień pewności i stan (wybrane/niezaznaczone). Informacje o znaczniku readResults wyboru są wyodrębniane w sekcji danych wyjściowych JSON.
Przewodnik migracji
- Aby dowiedzieć się, jak używać wersji 3.1 w aplikacjach i przepływach pracy, wykonaj kroki opisane w przewodniku migracji analizy dokumentów w wersji 3.1.
Powiązana zawartość
- Dowiedz się, jak przetwarzać własne formularze i dokumenty za pomocą programu Document Intelligence Studio.
- Zakończ szybki start Inteligencji Dokumentów i utwórz aplikację do przetwarzania dokumentów w dowolnym wybranym języku programowania.
- Dowiedz się, jak przetwarzać własne formularze i dokumenty za pomocą narzędzia Document Intelligence Sample Labeling.
- Zakończ szybki przewodnik dotyczący inteligencji dokumentów i utwórz aplikację do przetwarzania dokumentów w wybranym przez ciebie języku programowania.