Co to jest niestandardowy neuronowy głos?
Niestandardowy neuronowy głos (CNV) to funkcja zamiany tekstu na mowę, która umożliwia tworzenie niestandardowego, syntetycznego głosu dla aplikacji. Dzięki niestandardowemu neuronowemu głosowi można utworzyć bardzo naturalny głos dla marki lub znaków, dostarczając próbki mowy ludzkiej jako dane szkoleniowe.
Ważne
Niestandardowy dostęp do neuronowego głosu jest ograniczony na podstawie kryteriów kwalifikowalności i użycia. Zażądaj dostępu w formularzu do wprowadzania.
Dostęp do niestandardowego neuronowego głosu (CNV) Lite jest dostępny dla każdego, kto może demo i ocenić CNV przed zainwestowaniem w profesjonalne nagrania w celu utworzenia głosu o wyższej jakości.
Poza polem tekst na mowę można używać ze wstępnie utworzonymi głosami neuronowymi dla każdego obsługiwanego języka. Wstępnie utworzone głosy neuronowe działają dobrze w większości scenariuszy zamiany tekstu na mowę, jeśli unikatowy głos nie jest wymagany.
Niestandardowy neuronowy głos opiera się na technologii neuronowej zamiany tekstu na mowę i wielojęzycznego, wielo mówiącego, uniwersalnego modelu. Możesz tworzyć syntetyczne głosy, które są bogate w style mówienia lub elastyczne języki krzyżowe. Realistyczny i naturalny głos niestandardowego neuronowego głosu może reprezentować marki, personifikować maszyny i umożliwić użytkownikom interakcję z aplikacjami konwersajnie. Zobacz obsługiwane języki dla niestandardowego neuronowego głosu.
Jak to działa?
Aby utworzyć niestandardowy neuronowy głos, użyj programu Speech Studio , aby przekazać nagrany dźwięk i odpowiednie skrypty, wytrenować model i wdrożyć głos w niestandardowym punkcie końcowym.
Napiwek
Wypróbuj niestandardowy neuronowy głos (CNV) Lite , aby przeprowadzić pokaz i ocenić CNV przed zainwestowaniem w profesjonalne nagrania, aby stworzyć głos o wyższej jakości.
Utworzenie doskonałego niestandardowego neuronowego głosu wymaga starannej kontroli jakości w każdym kroku, od projektowania głosu i przygotowywania danych do wdrożenia modelu głosowego do systemu.
Przed rozpoczęciem pracy w usłudze Speech Studio zapoznaj się z kilkoma zagadnieniami:
- Zaprojektuj persona głosu reprezentującego twoją markę przy użyciu krótkiego dokumentu persona. Ten dokument definiuje elementy, takie jak cechy głosu i znak za głosem. Pomaga to w prowadzeniu procesu tworzenia niestandardowego neuronowego modelu głosu, w tym definiowania skryptów, wybierania talentów głosowych, trenowania i dostrajania głosu.
- Wybierz skrypt nagrywania, aby reprezentować scenariusze użytkownika dla głosu. Na przykład możesz użyć fraz z konwersacji bota jako skryptu nagrywania, jeśli tworzysz bota obsługi klienta. Uwzględnij różne typy zdań w skryptach, w tym instrukcje, pytania i wykrzykniki.
Poniżej przedstawiono omówienie kroków tworzenia niestandardowego neuronowego głosu w usłudze Speech Studio:
- Utwórz projekt zawierający dane, modele głosowe, testy i punkty końcowe. Każdy projekt jest specyficzny dla kraju/regionu i języka. Jeśli zamierzasz utworzyć wiele głosów, zaleca się utworzenie projektu dla każdego głosu.
- Konfigurowanie talentów głosowych. Zanim będzie można wytrenować głos neuronowy, musisz przesłać nagranie oświadczenia zgody talentu głosowego. Instrukcja talentów głosowych jest nagraniem talentów głosowych odczytujących oświadczenie, które wyraża zgodę na użycie danych mowy w celu wytrenowania niestandardowego modelu głosu.
- Przygotuj dane szkoleniowe w odpowiednim formacie. Dobrym pomysłem jest przechwycenie nagrań dźwiękowych w profesjonalnym studiu nagraniowym jakości, aby osiągnąć wysoki współczynnik sygnału do szumu. Jakość modelu głosu zależy w dużym stopniu od danych treningowych. Wymagana jest spójna głośność, szybkość mówienia, ton i spójność w ekspresywnych manierach mowy.
- Trenowanie modelu głosu. Wybierz co najmniej 300 wypowiedzi, aby utworzyć niestandardowy neuronowy głos. Seria kontroli jakości danych jest wykonywana automatycznie podczas ich przekazywania. Aby tworzyć modele głosowe wysokiej jakości, należy naprawić wszelkie błędy i przesłać je ponownie.
- Przetestuj głos. Przygotuj skrypty testowe dla modelu głosowego, które obejmują różne przypadki użycia aplikacji. Dobrym pomysłem jest użycie skryptów w zestawie danych trenowania i poza nim, dzięki czemu można szerzej przetestować jakość pod kątem innej zawartości.
- Wdrażanie i używanie modelu głosu w aplikacjach.
Możesz dostroić, dostosować i użyć niestandardowego głosu, podobnie jak wstępnie utworzony głos neuronowy. Przekonwertuj tekst na mowę w czasie rzeczywistym lub wygeneruj zawartość audio w trybie offline przy użyciu wprowadzania tekstu. Używasz interfejsu API REST, zestawu SPEECH SDK lub programu Speech Studio.
Napiwek
Zapoznaj się z przykładami kodu w repozytorium zestawu Speech SDK w usłudze GitHub , aby zobaczyć, jak używać niestandardowego neuronowego głosu w aplikacji.
Styl i cechy wytrenowanego modelu głosu zależą od stylu i jakości nagrań z talentów głosowych używanych do trenowania. Można jednak wprowadzić kilka korekt przy użyciu języka SSML (Speech Synthesis Markup Language) podczas wykonywania wywołań interfejsu API do modelu głosowego w celu wygenerowania syntetycznej mowy. SSML to język znaczników używany do komunikowania się z usługą zamiany tekstu na mowę w celu przekonwertowania tekstu na dźwięk. Korekty, które można wprowadzić, obejmują zmianę wysokości, szybkości, intonacji i korekty wymowy. Jeśli model głosowy został skompilowany przy użyciu wielu stylów, możesz również użyć języka SSML, aby przełączyć style.
Sekwencja składników
Niestandardowy głos neuronowy składa się z trzech głównych składników: analizatora tekstu, neuronowego modelu akustycznego i neuronowego vocodera. Aby wygenerować naturalną syntetyczną mowę z tekstu, tekst jest pierwszym wejściem do analizatora tekstu, który dostarcza dane wyjściowe w postaci sekwencji phoneme. Phoneme jest podstawową jednostką dźwięku, która odróżnia jedno słowo od drugiego w konkretnym języku. Sekwencja fonezy definiuje wymowę słów podanych w tekście.
Następnie sekwencja phoneme przechodzi do neuronowego modelu akustycznego w celu przewidywania cech akustycznych, które definiują sygnały mowy. Funkcje akustyczne obejmują barwy, styl mówienia, szybkość, intonacje i wzorce stresu. Na koniec neuronowy vocoder konwertuje funkcje akustyczne na fale słyszalne, dzięki czemu jest generowana syntetyczna mowa.
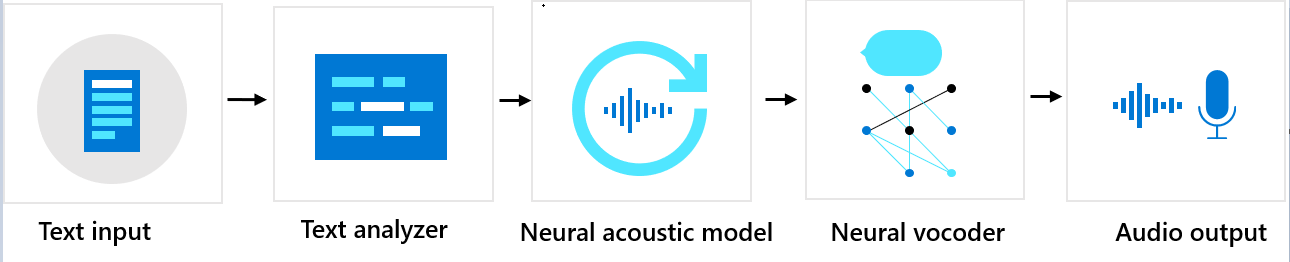
Modele neuronowego tekstu na mowę są trenowane przy użyciu głębokich sieci neuronowych opartych na próbkach ludzkich głosów. Aby uzyskać więcej informacji, zobacz ten wpis w blogu firmy Microsoft. Aby dowiedzieć się więcej na temat trenowania neuronowego vocodera, zobacz ten wpis w blogu firmy Microsoft.
Odpowiedzialne AI
System sztucznej inteligencji obejmuje nie tylko technologię, ale także osoby, które go używają, osoby, których to dotyczy, oraz środowisko, w którym jest wdrażane. Zapoznaj się z uwagami dotyczącymi przejrzystości, aby dowiedzieć się więcej na temat odpowiedzialnego używania sztucznej inteligencji i wdrażania w systemach.
- Uwaga dotycząca przezroczystości i przypadki użycia niestandardowego neuronowego głosu
- Cechy i ograniczenia dotyczące używania niestandardowego neuronowego głosu
- Ograniczony dostęp do niestandardowego neuronowego głosu
- Wytyczne dotyczące odpowiedzialnego wdrażania syntetycznej technologii głosowej
- Ujawnianie talentów głosowych
- Wytyczne dotyczące projektowania ujawniania informacji
- Wzorce projektowe ujawniania
- Kodeks postępowania dotyczącego integracji zamiany tekstu na mowę
- Dane, prywatność i zabezpieczenia niestandardowego neuronowego głosu