Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym omówieniu poznasz korzyści i możliwości funkcji zamiany tekstu na mowę w usłudze Mowa, która jest częścią usług Azure AI.
Zamiana tekstu na mowę umożliwia aplikacjom, narzędziom lub urządzeniom konwertowanie tekstu na język ludzki, taki jak syntetyzowana mowa. Funkcja zamiany tekstu na mowę jest również znana jako synteza mowy. Używaj standardowych, ludzkich głosów dostępnych od razu, lub stwórz niestandardowy głos, który jest niepowtarzalny dla twojego produktu lub marki. Aby uzyskać pełną listę obsługiwanych głosów, języków i ustawień regionalnych, zobacz Obsługa języka i głosu dla usługi Mowa.
Podstawowe funkcje
Zamiana tekstu na mowę obejmuje następujące funkcje:
| Funkcja | Podsumowanie | Demonstracja |
|---|---|---|
| Standardowy głos (nazywany Neural na stronie z cennikiem) | Bardzo naturalne, gotowe do użycia głosy. Utwórz subskrypcję platformy Azure i zasób usługi Mowa, a następnie użyj zestawu SDK usługi Mowa lub odwiedź portal usługi Speech Studio i wybierz standardowe głosy, aby rozpocząć pracę. Sprawdź szczegóły cennika. | Sprawdź galerię głosów i określ odpowiedni głos dla Twoich potrzeb biznesowych. |
| Głos niestandardowy | Łatwa w użyciu samoobsługa do tworzenia naturalnego głosu marki z ograniczonym dostępem do odpowiedzialnego użycia. Utwórz subskrypcję platformy Azure i zasób Azure AI Foundry, a następnie złóż wniosek o używanie głosu niestandardowego. Po udzieleniu dostępu przejdź do profesjonalnej dokumentacji dostrajania głosu , aby rozpocząć pracę. Sprawdź szczegóły cennika. | Sprawdź przykłady głosu. |
Więcej informacji o funkcjach zamiany tekstu neuronowego na mowę
Zamiana tekstu na mowę używa głębokich sieci neuronowych, aby głosy komputerów niemal nie do odróżnienia od nagrań ludzi. Dzięki jasnemu artykulacji słów tekst neuronowy do mowy znacznie zmniejsza zmęczenie nasłuchiwaniem, gdy użytkownicy wchodzą w interakcje z systemami sztucznej inteligencji.
Wzorce stresu i intonacji w języku mówionym są nazywane prosodią. Tradycyjne systemy zamiany tekstu na mowę dzielą prozady na oddzielne kroki analizy językowej i przewidywania akustycznego zarządzane przez niezależne modele. To może spowodować muffled, buzzy syntezy głosu.
Poniżej przedstawiono więcej informacji o funkcjach neuronowych zamian tekstu na mowę w usłudze Mowa oraz o tym, jak przezwyciężyć limity tradycyjnych systemów zamiany tekstu na mowę:
Synteza mowy w czasie rzeczywistym: użyj zestawu SPEECH SDK lub interfejsu API REST , aby przekonwertować tekst na mowę przy użyciu standardowych głosów lub niestandardowych głosów.
Asynchroniczna synteza długiego dźwięku: użyj interfejsu API syntezy wsadowej do asynchronicznego syntetyzowania tekstu w plikach mowy dłuższych niż 10 minut (na przykład książek audio lub wykładów). W przeciwieństwie do syntezy wykonywanej za pośrednictwem zestawu SPEECH SDK lub interfejsu API REST zamiany mowy na tekst odpowiedzi nie są zwracane w czasie rzeczywistym. Oczekuje się, że żądania są wysyłane asynchronicznie, odpowiedzi są sondowane i syntetyzowany dźwięk jest pobierany, gdy usługa udostępnia je.
Standardowe głosy: Usługa Azure AI Speech używa głębokich sieci neuronowych do przezwyciężenia ograniczeń tradycyjnej syntezy mowy dotyczącej stresu i intonacji w języku mówionym. Przewidywanie prosody i synteza głosu odbywają się jednocześnie, co skutkuje bardziej płynnymi i naturalnie brzmiącymi wyjściami. Każdy standardowy model głosu jest dostępny w wersjach 24 kHz i 48 kHz o wysokiej jakości dźwięku. Możesz użyć neuronowych głosów do:
- Sprawić, aby interakcje z czatbotami i asystentami głosowymi bardziej naturalne i angażujące.
- Konwertowanie tekstów cyfrowych, takich jak książki elektroniczne, na audiobooki.
- Ulepszanie systemów nawigacji w samochodzie.
Aby uzyskać pełną listę standardowych neuronowych głosów usługi Azure AI Speech, zobacz Obsługa języka i głosu dla usługi Mowa.
Ulepszanie tekstu w danych wyjściowych mowy za pomocą języka SSML: Język znaczników syntezy mowy (SSML) to język znaczników oparty na języku XML używany do dostosowywania tekstu do danych wyjściowych mowy. Za pomocą języka SSML można dostosować ton, dodać przerwy, poprawić wymowę, zmienić częstotliwość mówienia, dostosować głośność i przypisywać wiele głosów do pojedynczego dokumentu.
Możesz użyć języka SSML, aby zdefiniować własne leksykony lub przełączyć się na różne style mówienia. Dzięki wielojęzycznym głosom możesz również dostosować języki mówiące za pomocą języka SSML. Aby poprawić dane wyjściowe głosu dla danego scenariusza, zobacz Ulepszanie syntezy za pomocą języka znaczników syntezy mowy i syntezy mowy za pomocą narzędzia do tworzenia zawartości audio.
Visemes: Visemes są kluczowymi pozycjami w obserwowanej mowie, w tym położenie ust, szczęki i języka w produkcji konkretnej fonemy. Visemes mają silną korelację z głosami i fonezami.
Używając zdarzeń viseme w zestawie SPEECH SDK, można wygenerować dane animacji twarzy. Te dane mogą służyć do animowania twarzy w komunikacji z czytaniem ust, edukacji, rozrywki i obsługi klienta. Viseme jest obecnie obsługiwany tylko w przypadku
en-USneuronowych głosów (angielski usa).
Uwaga
Oprócz neuronowych głosów usługi Azure AI Speech (innych niż HD) można również używać głosów usługi Azure AI Speech high definition (HD) i neuronowych głosów usługi Azure OpenAI (HD i innych niż HD). Głosy HD zapewniają wyższą jakość w przypadku bardziej wszechstronnych scenariuszy.
Niektóre głosy nie obsługują wszystkich tagów języka SSML (Speech Synthesis Markup Language). Obejmuje to tekst neuronowy do mowy głosów HD, głosów osobistych i osadzonych głosów.
- W przypadku głosów usługi Azure AI Speech high definition (HD) sprawdź obsługę języka SSML tutaj.
- W przypadku osobistego głosu możesz znaleźć obsługę języka SSML tutaj.
- W przypadku osadzonych głosów sprawdź obsługę języka SSML tutaj.
Rozpocznij
Aby rozpocząć pracę z zamianą tekstu na mowę , zobacz przewodnik Szybki start. Zamiana tekstu na mowę jest dostępna za pośrednictwem zestawu SPEECH SDK, interfejsu API REST i interfejsu wiersza polecenia usługi Mowa.
Napiwek
Aby przekonwertować tekst na mowę przy użyciu podejścia bez kodu, wypróbuj narzędzie do tworzenia zawartości audio w programie Speech Studio.
Przykładowy kod
Przykładowy kod zamiany tekstu na mowę jest dostępny w witrynie GitHub. Te przykłady obejmują konwersję tekstu na mowę w najpopularniejszych językach programowania:
Głos niestandardowy
Oprócz standardowych głosów można tworzyć niestandardowe głosy, które są unikatowe dla twojego produktu lub marki. Niestandardowy głos to termin parasolowy, który obejmuje profesjonalne dostrajanie głosu i indywidualny głos. Wszystko, co trzeba rozpocząć, to kilka plików audio i skojarzonych transkrypcji. Aby uzyskać więcej informacji, zobacz profesjonalną dokumentację dostrajania głosu.
Nota cenowa
Rozliczane znaki
Gdy używasz funkcji zamiany tekstu na mowę, opłaty są naliczane za każdy znak przekonwertowany na mowę, w tym interpunkcję. Mimo że sam dokument SSML nie jest rozliczany, opcjonalne elementy używane do dostosowywania sposobu konwersji tekstu na mowę, takie jak phonemy i skoki, są liczone jako rozliczane znaki. Oto lista elementów rozliczanych:
- Tekst przekazany do funkcji zamiany tekstu na mowę w treści żądania SSML
- Wszystkie znaczniki w polu tekstowym treści żądania w formacie SSML, z wyjątkiem
<speak>tagów i<voice> - Litery, znaki interpunkcyjne, spacje, karty, znaczniki i wszystkie znaki odstępu
- Każdy punkt kodu zdefiniowany w standardze Unicode
Aby uzyskać szczegółowe informacje, zobacz Cennik usługi Mowa.
Ważne
Każdy chiński znak jest liowany jako dwa znaki do rozliczeń, w tym kanji używany w języku japońskim, hanja używany w języku koreańskim lub hanzi używany w innych językach.
Trenowanie modelu i czas hostingu dla niestandardowego głosu
Indywidualne szkolenie głosu i hosting są obliczane na podstawie godzin i rozliczane na sekundę. Aby uzyskać cenę jednostkową rozliczeń, zobacz Cennik usługi Mowa.
Profesjonalny czas dostrajania głosu jest mierzony przez "godzinę obliczeniową" (jednostkę do mierzenia czasu pracy maszyny). Zazwyczaj podczas trenowania modelu głosowego dwa zadania obliczeniowe są uruchamiane równolegle. W związku z tym obliczone godziny obliczeniowe są dłuższe niż rzeczywisty czas trenowania. W przypadku profesjonalnego dostrajania głosu dostrajanie zwykle trwa od 20 do 40 godzin obliczeniowych, aby wytrenować głos w jednym stylu i około 90 godzin obliczeniowych, aby wytrenować głos wielostylowy. Profesjonalny czas dostrajania głosu jest rozliczany z limitem 96 godzin obliczeniowych. W takim przypadku, gdy model głosowy jest trenowany w ciągu 98 godzin obliczeniowych, opłaty będą naliczane tylko za 96 godzin obliczeniowych.
Dostosowane hostowanie punktu końcowego głosu jest mierzone przez rzeczywisty czas (w godzinach). Czas hostingu (godziny) dla każdego punktu końcowego jest obliczany o 00:00 UTC każdego dnia przez poprzednie 24 godziny. Jeśli na przykład punkt końcowy był aktywny przez 24 godziny pierwszego dnia, opłata jest naliczana za 24 godziny o 00:00 UTC w drugim dniu. Jeśli punkt końcowy jest nowo utworzony lub zawieszony w ciągu dnia, opłaty są naliczane za skumulowany czas działania do 00:00 UTC drugiego dnia. Jeśli punkt końcowy nie jest obecnie hostowany, nie jest rozliczany. Oprócz obliczenia dziennego o godzinie 00:00 UTC każdego dnia rozliczenia są również wyzwalane natychmiast po usunięciu lub zawieszeniu punktu końcowego. Na przykład w przypadku punktu końcowego utworzonego o godzinie 08:00 UTC 1 grudnia godzina hostingu zostanie obliczona na 16 godzin o 00:00 UTC 2 grudnia i 24 godziny o 00:00 UTC 3 grudnia. Jeśli użytkownik zawiesi hostowanie punktu końcowego o godzinie 16:30 UTC 3 grudnia, czas trwania (16,5 godziny) od 00:00 do 16:30 UTC 3 grudnia zostanie obliczony na potrzeby rozliczeń.
Osobisty głos
W przypadku korzystania z funkcji głosu osobistego opłaty są naliczane zarówno za przechowywanie profilu, jak i syntezę.
- Magazyn profilu: po utworzeniu osobistego profilu głosowego będzie on rozliczany do momentu usunięcia go z systemu. Jednostka rozliczeniowa jest na głos dziennie. Jeśli magazyn głosowy trwa krócej niż 24 godziny, opłaty są nadal naliczane jako jeden pełny dzień.
- Synteza: Rozliczane na postać. Aby uzyskać szczegółowe informacje na temat znaków podlegających rozliczaniu, zobacz powyższe rozliczane znaki.
Awatar zamiany tekstu na mowę
W przypadku korzystania z funkcji awatara zamiany tekstu na mowę opłaty są naliczane na sekundę na podstawie długości danych wyjściowych wideo. Jednak w przypadku awatara w czasie rzeczywistym opłaty są naliczane na sekundę na podstawie czasu, gdy awatar jest aktywny, niezależnie od tego, czy mówi, czy pozostaje cichy. Aby zoptymalizować koszty użycia awatara w czasie rzeczywistym, zapoznaj się z poradami "Korzystanie z lokalnego wideo dla bezczynności" podanych w przykładowym kodzie czatu awatara.
Niestandardowy tekst do trenowania awatara mowy to czas mierzony przez "godzinę obliczeniową" (czas pracy maszyny) i rozliczany na sekundę. Czas trwania szkolenia różni się w zależności od ilości używanych danych. Zwykle trenowanie niestandardowego awatara trwa średnio 20–40 godzin obliczeniowych. Czas trenowania awatara jest rozliczany z limitem 96 godzin obliczeniowych. Więc w przypadku, gdy model awatara jest trenowany w ciągu 98 godzin obliczeniowych, opłaty są naliczane tylko za 96 godzin obliczeniowych.
Hosting awatara jest rozliczany na sekundę na punkt końcowy. Możesz zawiesić punkt końcowy, aby zaoszczędzić koszty. Jeśli chcesz zawiesić punkt końcowy, możesz usunąć go bezpośrednio. Aby użyć go ponownie, ponownie wdróż punkt końcowy.
Monitorowanie metryk zamiany tekstu na mowę na platformę Azure
Monitorowanie kluczowych metryk skojarzonych z tekstem w usługach mowy ma kluczowe znaczenie dla zarządzania użyciem zasobów i kontrolowaniem kosztów. W tej sekcji opisano, jak znaleźć informacje o użyciu w witrynie Azure Portal i podać szczegółowe definicje kluczowych metryk. Aby uzyskać więcej informacji na temat metryk usługi Azure Monitor, zobacz Omówienie metryk usługi Azure Monitor.
Jak znaleźć informacje o użyciu w witrynie Azure Portal
Aby efektywnie zarządzać zasobami platformy Azure, ważne jest regularne uzyskiwanie dostępu do informacji o użyciu i ich przeglądanie. Poniżej przedstawiono sposób znajdowania informacji o użyciu:
Przejdź do witryny Azure Portal i zaloguj się przy użyciu konta platformy Azure.
Przejdź do obszaru Zasoby i wybierz zasób, który chcesz monitorować.
Wybierz pozycję Metryki w obszarze Monitorowanie z menu po lewej stronie.
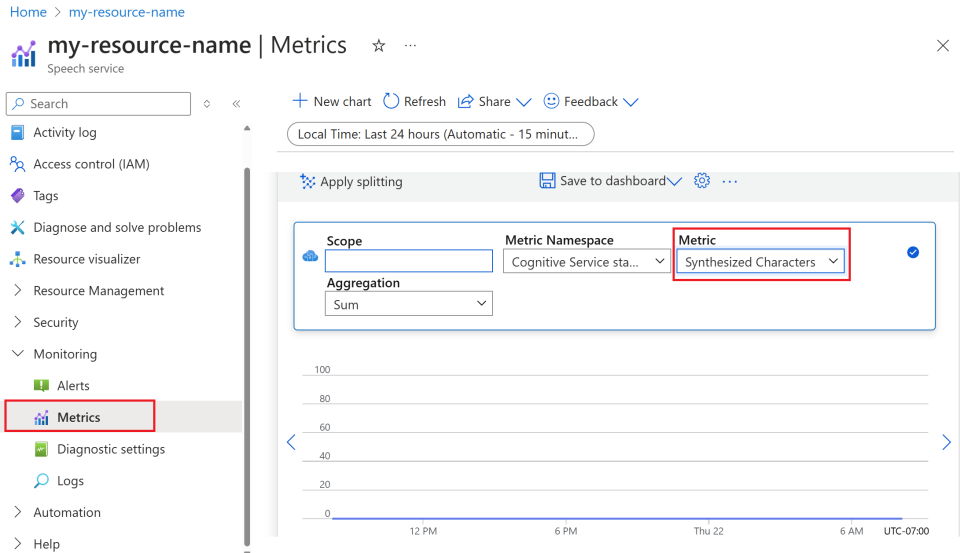
Dostosowywanie widoków metryk.
Dane można filtrować według typu zasobu, typu metryki, zakresu czasu i innych parametrów, aby tworzyć widoki niestandardowe zgodne z potrzebami monitorowania. Ponadto możesz zapisać widok metryki na pulpitach nawigacyjnych, wybierając pozycję Zapisz na pulpicie nawigacyjnym , aby ułatwić dostęp do często używanych metryk.
Konfigurowanie alertów.
Aby efektywniej zarządzać użyciem, skonfiguruj alerty, przechodząc do karty Alerty w obszarze Monitorowanie z menu po lewej stronie. Alerty mogą powiadamiać o osiągnięciu określonych progów użycia, co pomaga zapobiec nieoczekiwanym kosztom.
Definicja metryk
Oto tabela podsumowująca kluczowe metryki tekstu na mowę platformy Azure.
| Nazwa metryki | Opis |
|---|---|
| Znaki syntetyzowane | Śledzi liczbę znaków przekonwertowanych na mowę, w tym standardowego i niestandardowego głosu. Aby uzyskać szczegółowe informacje o rozliczanych znakach, zobacz Billable characters (Znaki rozliczane). |
| Syntetyzowane sekundy wideo | Mierzy całkowity czas trwania syntezy wideo, w tym syntezę awatara wsadowego, syntezę awatara w czasie rzeczywistym i niestandardową syntezę awatara. |
| Model awatara hostuje sekundy | Śledzi łączny czas w sekundach hostowanych przez niestandardowy model awatara. |
| Godziny hostingu modelu głosowego | Śledzi łączny czas w godzinach, przez który niestandardowy model głosu jest hostowany. |
| Minuty trenowania modelu głosowego | Mierzy całkowity czas trenowania niestandardowego modelu głosu w minutach. |
Dokumenty referencyjne
Odpowiedzialne AI
System sztucznej inteligencji obejmuje nie tylko technologię, ale także osoby, które go używają, osoby, których to dotyczy, oraz środowisko, w którym jest wdrażane. Zapoznaj się z uwagami dotyczącymi przejrzystości, aby dowiedzieć się więcej na temat odpowiedzialnego używania sztucznej inteligencji i wdrażania w systemach.
- Notatka dotycząca przejrzystości i przypadki użycia niestandardowego głosu
- Cechy i ograniczenia dotyczące używania głosu niestandardowego
- Ograniczony dostęp do spersonalizowanego głosu
- Wytyczne dotyczące odpowiedzialnego wdrażania syntetycznej technologii głosowej
- Ujawnianie talentów głosowych
- Wytyczne dotyczące projektowania ujawniania informacji
- Wzorce projektowe ujawniania
- Kodeks postępowania dotyczącego integracji zamiany tekstu na mowę
- Dane, prywatność i zabezpieczenia dla niestandardowego głosu