Trenowanie niestandardowego modelu mowy
Z tego artykułu dowiesz się, jak wytrenować model niestandardowy w celu zwiększenia dokładności rozpoznawania z modelu podstawowego firmy Microsoft. Dokładność rozpoznawania mowy i jakość niestandardowego modelu mowy pozostaje spójna, nawet jeśli zostanie wydany nowy model podstawowy.
Uwaga
Płacisz za użycie niestandardowego modelu mowy i hostowanie punktów końcowych. Opłaty będą również naliczane za trenowanie niestandardowego modelu mowy, jeśli model podstawowy został utworzony 1 października 2023 r. i nowsze. Nie są naliczane opłaty za trenowanie, jeśli model podstawowy został utworzony przed październikiem 2023 r. Aby uzyskać więcej informacji, zobacz Cennik usługi Azure AI Speech i sekcję Opłaty za adaptację w przewodniku migracji zamiany mowy na tekst 3.2.
Trenowanie modelu jest zazwyczaj procesem iteracyjnym. Najpierw należy wybrać model podstawowy, który jest punktem wyjścia dla nowego modelu. Model można trenować przy użyciu zestawów danych, które mogą zawierać tekst i dźwięk, a następnie testować. Jeśli jakość lub dokładność rozpoznawania nie spełnia Twoich wymagań, możesz utworzyć nowy model z bardziej lub zmodyfikowanymi danymi treningowymi, a następnie ponownie przetestować.
Możesz użyć modelu niestandardowego przez ograniczony czas po jego wytrenowanym. Należy okresowo ponownie utworzyć i dostosować model niestandardowy z najnowszego modelu podstawowego, aby korzystać z ulepszonej dokładności i jakości. Aby uzyskać więcej informacji, zobacz Cykl życia modelu i punktu końcowego.
Ważne
Jeśli wytrenujesz model niestandardowy przy użyciu danych audio, wybierz region zasobów usługi Mowa z dedykowanym sprzętem do trenowania danych audio. Po wytrenowanym modelu możesz skopiować go do zasobu usługi Mowa w innym regionie zgodnie z potrzebami.
W regionach z dedykowanym sprzętem do trenowania mowy niestandardowej usługa mowa będzie używać do 100 godzin danych treningowych dźwięku i może przetwarzać około 10 godzin dziennie. Aby uzyskać więcej informacji, zobacz przypisy dolne w tabeli regionów .
Utwórz model
Po przekazaniu zestawów danych szkoleniowych postępuj zgodnie z tymi instrukcjami, aby rozpocząć trenowanie modelu:
Zaloguj się do programu Speech Studio.
Wybierz pozycję Niestandardowa mowa> Nazwa >projektu Train custom models (Trenowanie modeli niestandardowych).
Wybierz pozycję Train a new model (Trenowanie nowego modelu).
Na stronie Wybieranie modelu bazowego wybierz model podstawowy, a następnie wybierz przycisk Dalej. Jeśli nie masz pewności, wybierz najnowszy model w górnej części listy. Nazwa modelu podstawowego odpowiada dacie wydania w formacie RRRRMDD. Możliwości dostosowywania modelu podstawowego są wymienione w nawiasach po nazwie modelu w usłudze Speech Studio.
Ważne
Zanotuj datę wygaśnięcia adaptacji . Jest to ostatnia data użycia modelu podstawowego do trenowania. Aby uzyskać więcej informacji, zobacz Cykl życia modelu i punktu końcowego.
Na stronie Wybieranie danych wybierz co najmniej jeden zestaw danych, którego chcesz użyć do trenowania. Jeśli nie ma żadnych dostępnych zestawów danych, anuluj konfigurację, a następnie przejdź do menu Zestawy danych usługi Mowa, aby przekazać zestawy danych.
Wprowadź nazwę i opis modelu niestandardowego, a następnie wybierz pozycję Dalej.
Opcjonalnie zaznacz pole Dodaj test w następnym kroku . Jeśli pominiesz ten krok, możesz uruchomić te same testy później. Aby uzyskać więcej informacji, zobacz Jakość rozpoznawania testów i Model testowy ilościowo.
Wybierz pozycję Zapisz i zamknij , aby rozpocząć kompilację dla modelu niestandardowego.
Wróć do strony Trenowanie modeli niestandardowych.
Ważne
Zanotuj datę wygaśnięcia . Jest to ostatnia data, w której można użyć modelu niestandardowego do rozpoznawania mowy. Aby uzyskać więcej informacji, zobacz Cykl życia modelu i punktu końcowego.
Aby utworzyć model z zestawami danych na potrzeby trenowania, użyj spx csr model create polecenia . Skonstruuj parametry żądania zgodnie z następującymi instrukcjami:
-
projectUstaw parametr na identyfikator istniejącego projektu. Ten parametr jest zalecany, aby można było również wyświetlać model i zarządzać nim w usłudze Speech Studio. Możesz uruchomić polecenie ,spx csr project listaby uzyskać dostępne projekty. - Ustaw wymagany
datasetparametr na identyfikator zestawu danych, który ma być używany do trenowania. Aby określić wiele zestawów danych, ustawdatasetsparametr (mnogi) i rozdziel identyfikatory średnikami. - Ustaw wymagany
languageparametr. Ustawienia regionalne zestawu danych muszą być zgodne z ustawieniami regionalnymi projektu. Nie można później zmienić ustawień regionalnych. Parametr interfejsulocalewiersza polecenialanguageusługi Mowa odpowiada właściwości w żądaniu i odpowiedzi w formacie JSON. - Ustaw wymagany
nameparametr. Ten parametr to nazwa wyświetlana w programie Speech Studio. Parametr interfejsudisplayNamewiersza polecenianameusługi Mowa odpowiada właściwości w żądaniu i odpowiedzi w formacie JSON. - Opcjonalnie można ustawić
basewłaściwość . Na przykład:--base 5988d691-0893-472c-851e-8e36a0fe7aaf. Jeśli nie określiszbasewartości , zostanie użyty domyślny model podstawowy ustawień regionalnych. Parametr interfejsubaseModelwiersza poleceniabaseusługi Mowa odpowiada właściwości w żądaniu i odpowiedzi w formacie JSON.
Oto przykładowe polecenie interfejsu wiersza polecenia usługi Mowa, które tworzy model z zestawami danych na potrzeby trenowania:
spx csr model create --api-version v3.2 --project YourProjectId --name "My Model" --description "My Model Description" --dataset YourDatasetId --language "en-US"
Uwaga
W tym przykładzie base parametr nie jest ustawiony, więc jest używany domyślny model podstawowy ustawień regionalnych. Identyfikator URI modelu podstawowego jest zwracany w odpowiedzi.
Treść odpowiedzi powinna zostać wyświetlona w następującym formacie:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd:copy",
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"deprecationDates": {
"transcriptionDateTime": "2026-07-15T00:00:00Z"
},
"customModelWeightPercent": 30,
"features": {
"supportsTranscriptions": true,
"supportsEndpoints": true,
"supportsTranscriptionsOnSpeechContainers": false,
"supportedOutputFormats": [
"Display",
"Lexical"
]
}
},
"lastActionDateTime": "2024-07-14T21:38:40Z",
"status": "Running",
"createdDateTime": "2024-07-14T21:38:40Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}
Ważne
Zanotuj adaptationDateTime datę we właściwości . Jest to ostatnia data użycia modelu podstawowego do trenowania. Aby uzyskać więcej informacji, zobacz Cykl życia modelu i punktu końcowego.
Zanotuj transcriptionDateTime datę we właściwości . Jest to ostatnia data, w której można użyć modelu niestandardowego do rozpoznawania mowy. Aby uzyskać więcej informacji, zobacz Cykl życia modelu i punktu końcowego.
Właściwość najwyższego poziomu self w treści odpowiedzi to identyfikator URI modelu. Użyj tego identyfikatora URI, aby uzyskać szczegółowe informacje na temat dat zakończenia i projektu modelu. Ten identyfikator URI służy również do aktualizowania lub usuwania modelu.
Aby uzyskać pomoc dotyczącą interfejsu wiersza polecenia usługi Mowa w modelach, uruchom następujące polecenie:
spx help csr model
Aby utworzyć model z zestawami danych na potrzeby trenowania, użyj Models_Create operacji zamiany mowy na tekst interfejsu API REST. Skonstruuj treść żądania zgodnie z następującymi instrukcjami:
-
projectUstaw właściwość na identyfikator URI istniejącego projektu. Ta właściwość jest zalecana, aby można było również wyświetlać model i zarządzać nim w usłudze Speech Studio. Możesz wysłać żądanie Projects_List , aby uzyskać dostępne projekty. - Ustaw wymaganą
datasetswłaściwość na identyfikator URI zestawów danych, które mają być używane do trenowania. - Ustaw wymaganą
localewłaściwość. Ustawienia regionalne modelu muszą być zgodne z ustawieniami regionalnymi projektu i modelu podstawowego. Nie można później zmienić ustawień regionalnych. - Ustaw wymaganą
displayNamewłaściwość. Ta właściwość to nazwa wyświetlana w programie Speech Studio. - Opcjonalnie można ustawić
baseModelwłaściwość . Na przykład:"baseModel": {"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"}. Jeśli nie określiszbaseModelwartości , zostanie użyty domyślny model podstawowy ustawień regionalnych.
Utwórz żądanie HTTP POST przy użyciu identyfikatora URI, jak pokazano w poniższym przykładzie. Zastąp YourSubscriptionKey ciąg kluczem zasobu usługi Mowa, zastąp YourServiceRegion element regionem zasobu usługi Mowa i ustaw właściwości treści żądania zgodnie z wcześniejszym opisem.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Model",
"description": "My Model Description",
"baseModel": null,
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models"
Uwaga
W tym przykładzie baseModel parametr nie jest ustawiony, więc jest używany domyślny model podstawowy ustawień regionalnych. Identyfikator URI modelu podstawowego jest zwracany w odpowiedzi.
Treść odpowiedzi powinna zostać wyświetlona w następującym formacie:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd:copy",
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"deprecationDates": {
"transcriptionDateTime": "2026-07-15T00:00:00Z"
},
"customModelWeightPercent": 30,
"features": {
"supportsTranscriptions": true,
"supportsEndpoints": true,
"supportsTranscriptionsOnSpeechContainers": false,
"supportedOutputFormats": [
"Display",
"Lexical"
]
}
},
"lastActionDateTime": "2024-07-14T21:38:40Z",
"status": "Running",
"createdDateTime": "2024-07-14T21:38:40Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}
Ważne
Zanotuj adaptationDateTime datę we właściwości . Jest to ostatnia data użycia modelu podstawowego do trenowania. Aby uzyskać więcej informacji, zobacz Cykl życia modelu i punktu końcowego.
Zanotuj transcriptionDateTime datę we właściwości . Jest to ostatnia data, w której można użyć modelu niestandardowego do rozpoznawania mowy. Aby uzyskać więcej informacji, zobacz Cykl życia modelu i punktu końcowego.
Właściwość najwyższego poziomu self w treści odpowiedzi to identyfikator URI modelu. Użyj tego identyfikatora URI, aby uzyskać szczegółowe informacje na temat dat zakończenia i projektu modelu. Ten identyfikator URI służy również do aktualizowania lub usuwania modelu.
Kopiowanie modelu
Model można skopiować do innego projektu, który używa tych samych ustawień regionalnych. Na przykład po wytrenowanym modelu przy użyciu danych dźwiękowych w regionie z dedykowanym sprzętem do trenowania możesz skopiować go do zasobu usługi Mowa w innym regionie zgodnie z potrzebami.
Postępuj zgodnie z tymi instrukcjami, aby skopiować model do projektu w innym regionie:
- Zaloguj się do programu Speech Studio.
- Wybierz pozycję Niestandardowa mowa> Nazwa >projektu Train custom models (Trenowanie modeli niestandardowych).
- Wybierz pozycję Kopiuj do.
-
Na stronie Kopiowanie modelu mowy wybierz region docelowy, w którym chcesz skopiować model.

- Wybierz zasób usługi Mowa w regionie docelowym lub utwórz nowy zasób usługi Mowa.
- Wybierz projekt, w którym chcesz skopiować model, lub utwórz nowy projekt.
- Wybierz Kopiuj.

Po pomyślnym skopiowaniu modelu otrzymasz powiadomienie i będzie można go wyświetlić w projekcie docelowym.
Kopiowanie modelu bezpośrednio do projektu w innym regionie nie jest obsługiwane za pomocą interfejsu wiersza polecenia usługi Mowa. Model można skopiować do projektu w innym regionie przy użyciu programu Speech Studio lub interfejsu API REST zamiany mowy na tekst.
Aby skopiować model do innego zasobu usługi Mowa, użyj operacji Models_Copy interfejsu API REST zamiany mowy na tekst. Skonstruuj treść żądania zgodnie z następującymi instrukcjami:
- Ustaw wymaganą
targetSubscriptionKeywłaściwość na klucz docelowego zasobu usługi Mowa.
Utwórz żądanie HTTP POST przy użyciu identyfikatora URI, jak pokazano w poniższym przykładzie. Użyj regionu i identyfikatora URI modelu, z którego chcesz skopiować. Zastąp YourModelId ciąg identyfikatorem modelu, zastąp ciąg kluczem zasobu usługi Mowa, zastąp YourSubscriptionKeyYourServiceRegion element regionem zasobu usługi Mowa i ustaw właściwości treści żądania zgodnie z wcześniejszym opisem.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"targetSubscriptionKey": "ModelDestinationSpeechResourceKey"
} ' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models/YourModelId:copy"
Uwaga
targetSubscriptionKey Tylko właściwość w treści żądania zawiera informacje o docelowym zasobie usługi Mowa.
Treść odpowiedzi powinna zostać wyświetlona w następującym formacie:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/eb5450a7-3ca2-461a-b2d7-ddbb3ad96540"
},
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae:copy"
},
"properties": {
"deprecationDates": {
"adaptationDateTime": "2023-01-15T00:00:00Z",
"transcriptionDateTime": "2024-07-15T00:00:00Z"
}
},
"lastActionDateTime": "2022-05-22T23:15:27Z",
"status": "NotStarted",
"createdDateTime": "2022-05-22T23:15:27Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description",
"customProperties": {
"PortalAPIVersion": "3",
"Purpose": "",
"VadKind": "None",
"ModelClass": "None",
"UsesHalide": "False",
"IsDynamicGrammarSupported": "False"
}
}
Łączenie modelu
Modele mogły zostać skopiowane z jednego projektu przy użyciu interfejsu wiersza polecenia usługi Mowa lub interfejsu API REST bez połączenia z innym projektem. Łączenie modelu polega na aktualizowaniu modelu przy użyciu odwołania do projektu.
Jeśli zostanie wyświetlony monit w programie Speech Studio, możesz nawiązać z nimi połączenie, wybierając przycisk Połącz .
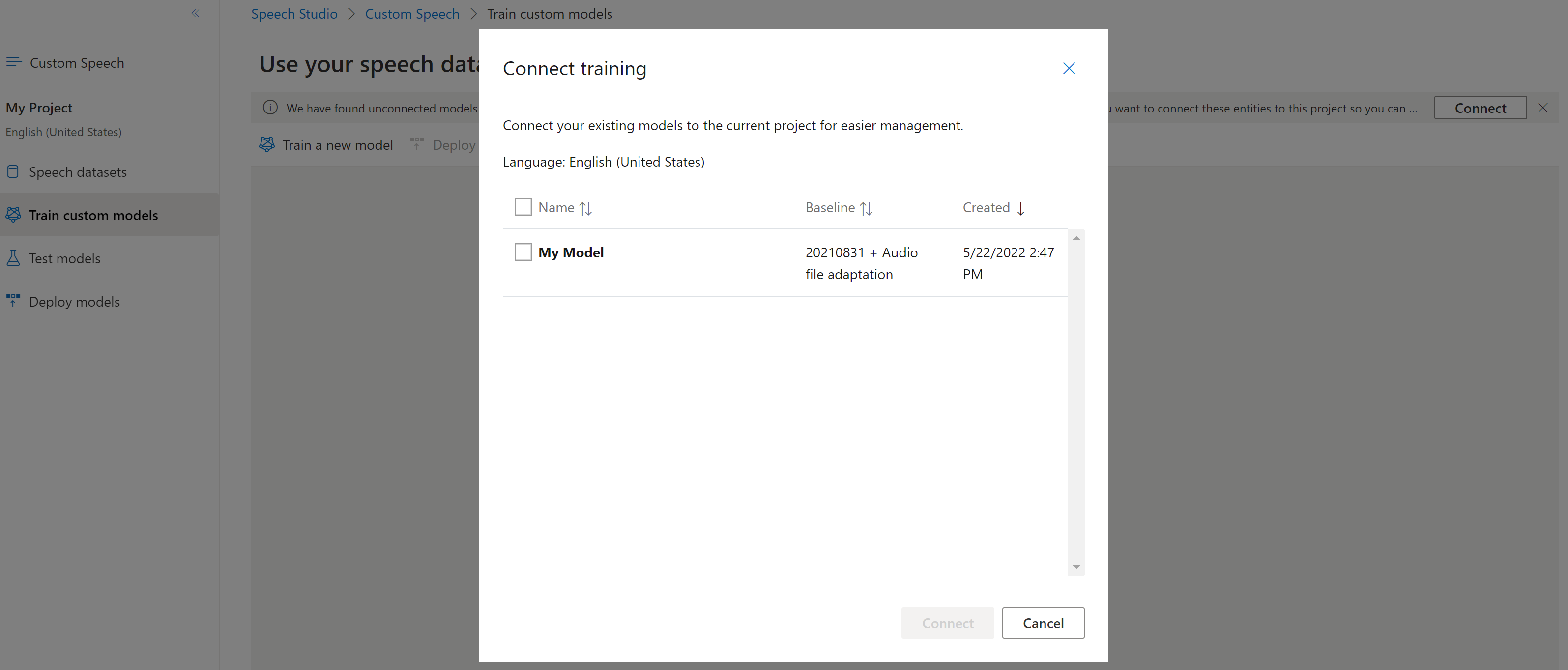
Aby połączyć model z projektem, użyj spx csr model update polecenia . Skonstruuj parametry żądania zgodnie z następującymi instrukcjami:
-
projectUstaw parametr na identyfikator URI istniejącego projektu. Ten parametr jest zalecany, aby można było również wyświetlać model i zarządzać nim w usłudze Speech Studio. Możesz uruchomić polecenie ,spx csr project listaby uzyskać dostępne projekty. - Ustaw wymagany
modelIdparametr na identyfikator modelu, który chcesz połączyć z projektem.
Oto przykładowe polecenie interfejsu wiersza polecenia usługi Mowa, które łączy model z projektem:
spx csr model update --api-version v3.2 --model YourModelId --project YourProjectId
Treść odpowiedzi powinna zostać wyświetlona w następującym formacie:
{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}
Aby uzyskać pomoc dotyczącą interfejsu wiersza polecenia usługi Mowa w modelach, uruchom następujące polecenie:
spx help csr model
Aby połączyć nowy model z projektem zasobu usługi Mowa, w którym został skopiowany model, użyj Models_Update operacji zamiany mowy na tekst interfejsu API REST. Skonstruuj treść żądania zgodnie z następującymi instrukcjami:
- Ustaw wymaganą
projectwłaściwość na identyfikator URI istniejącego projektu. Ta właściwość jest zalecana, aby można było również wyświetlać model i zarządzać nim w usłudze Speech Studio. Możesz wysłać żądanie Projects_List , aby uzyskać dostępne projekty.
Utwórz żądanie HTTP PATCH przy użyciu identyfikatora URI, jak pokazano w poniższym przykładzie. Użyj identyfikatora URI nowego modelu. Nowy identyfikator modelu można pobrać z self właściwości treści odpowiedzi Models_Copy . Zastąp YourSubscriptionKey ciąg kluczem zasobu usługi Mowa, zastąp YourServiceRegion element regionem zasobu usługi Mowa i ustaw właściwości treści żądania zgodnie z wcześniejszym opisem.
curl -v -X PATCH -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models"
Treść odpowiedzi powinna zostać wyświetlona w następującym formacie:
{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}