Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Z tego artykułu dowiesz się, jak ilościowo mierzyć i poprawiać dokładność podstawowej mowy na model tekstowy lub własne modele niestandardowe. Do testowania dokładności wymagany jest dźwięk i dane transkrypcji oznaczone przez człowieka. Należy podać od 30 minut do 5 godzin reprezentatywnego dźwięku.
Ważne
Podczas testowania system wykona transkrypcję. Należy pamiętać o tym, ponieważ ceny różnią się w zależności od oferty usług i poziomu subskrypcji. Aby uzyskać najnowsze informacje, zawsze zapoznaj się z oficjalnymi cennikami usług Azure AI.
Tworzenie testu
Dokładność modelu niestandardowego można przetestować, tworząc test. Test wymaga kolekcji plików audio i odpowiednich transkrypcji. Dokładność modelu niestandardowego można porównać z mową z modelem bazowym tekstu lub innym modelem niestandardowym. Po otrzymaniu wyników testu oceń współczynnik błędów słów (WER) w porównaniu z wynikami rozpoznawania mowy.
Po przekazaniu plików danych szkoleniowych i testowych można utworzyć test.
Aby przetestować dostosowany niestandardowy model mowy, wykonaj następujące kroki:
Zaloguj się do portalu usługi Azure AI Foundry.
Wybierz Dostrajanie z lewego panelu, a następnie wybierz dostrajanie usługi AI.
Wybierz zadanie dostosowywania mowy niestandardowej (według nazwy modelu), które zostało uruchomione zgodnie z opisem w artykule dotyczącym dostosowywania mowy niestandardowej.
Wybierz pozycję Modele >+ Utwórz test.
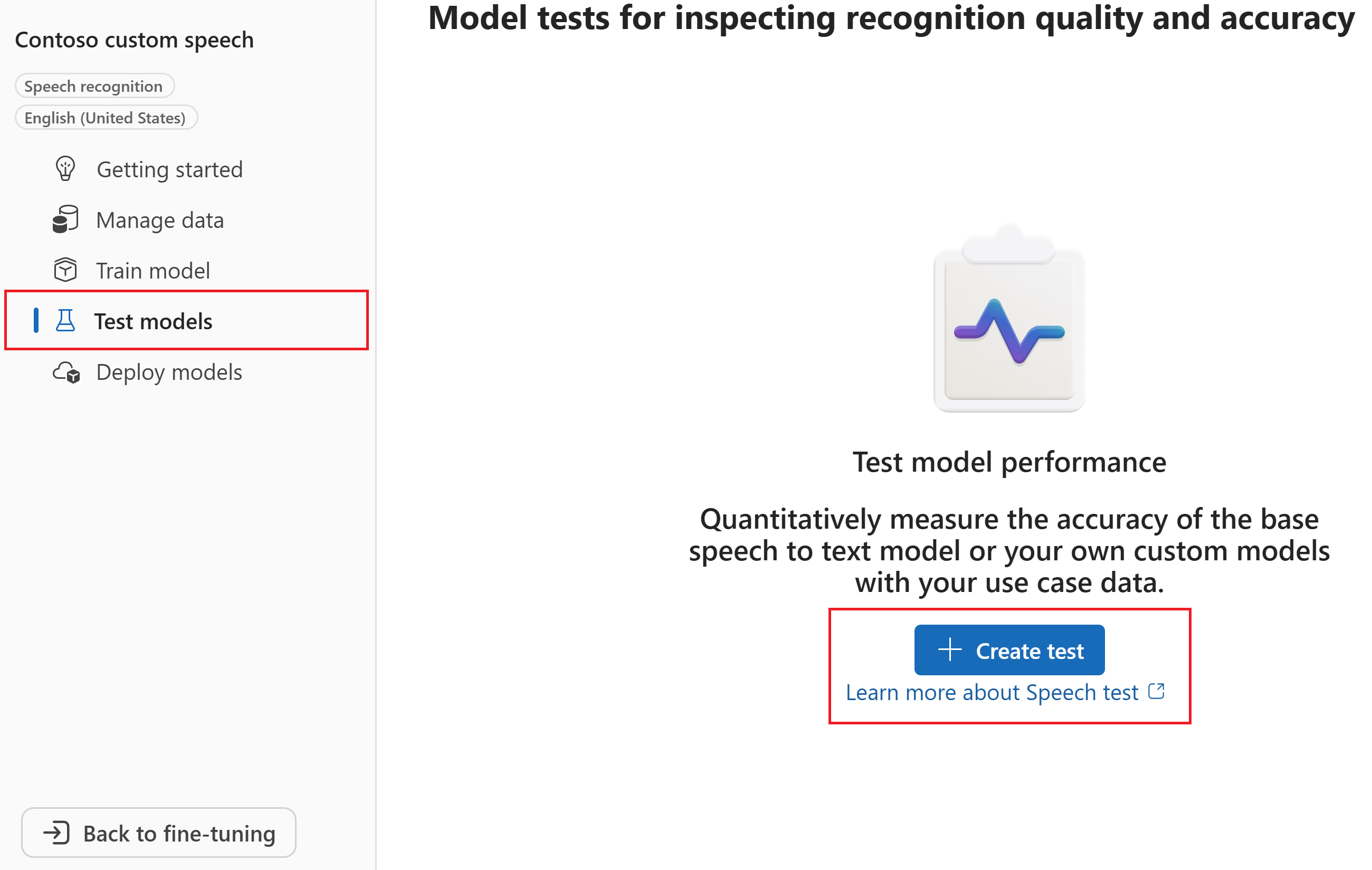
W kreatorze Tworzenie nowego testu wybierz typ testu . Aby uzyskać test dokładności (ilościowy), wybierz pozycję Oceń dokładność (Audio + dane transkrypcji). Następnie wybierz Dalej.
Wybierz dane, których chcesz użyć do testowania. Następnie wybierz Dalej.
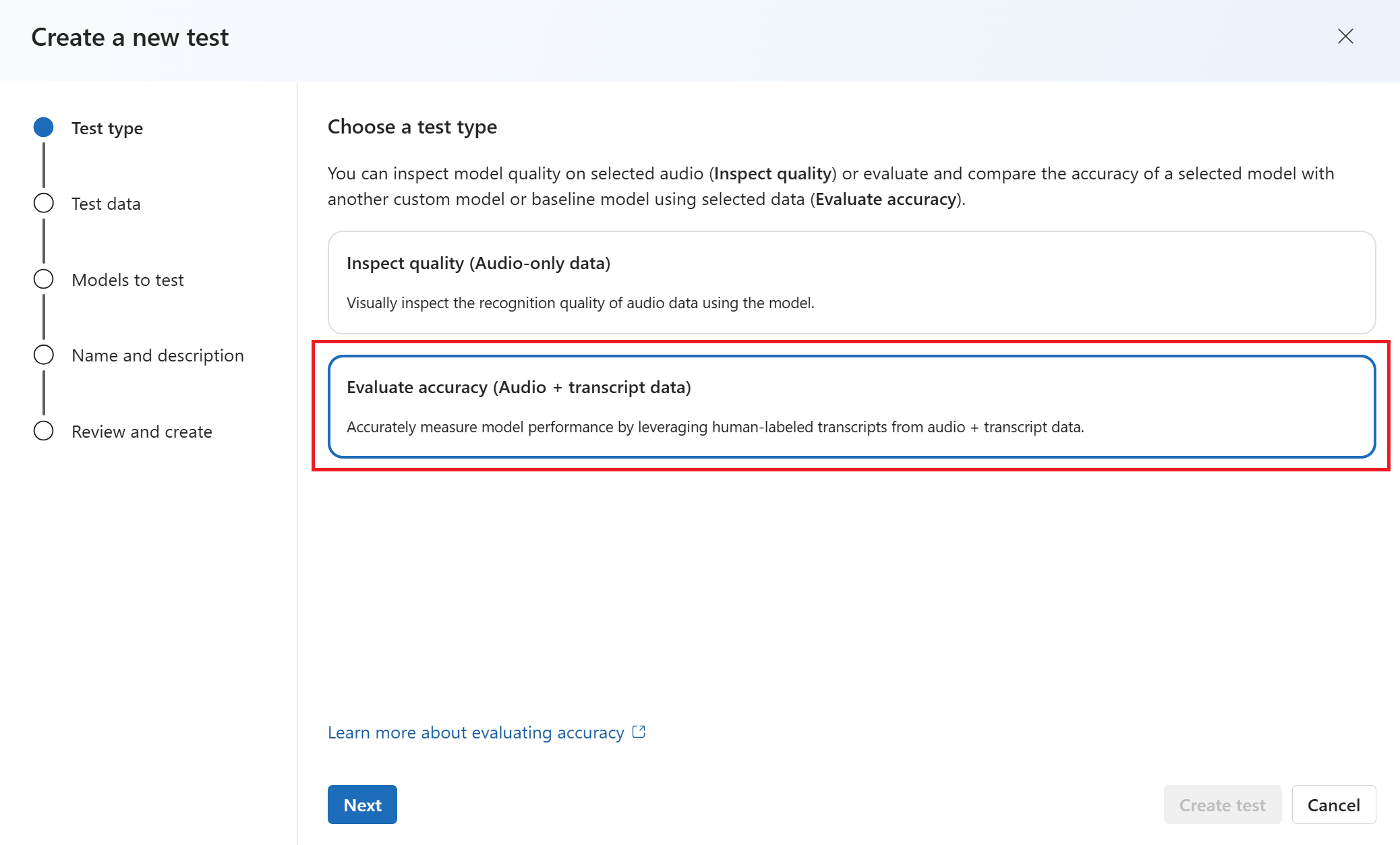
Wybierz maksymalnie dwa modele, aby ocenić i porównać dokładność. W tym przykładzie wybieramy model, który wytrenowaliśmy i model podstawowy. Następnie wybierz Dalej.
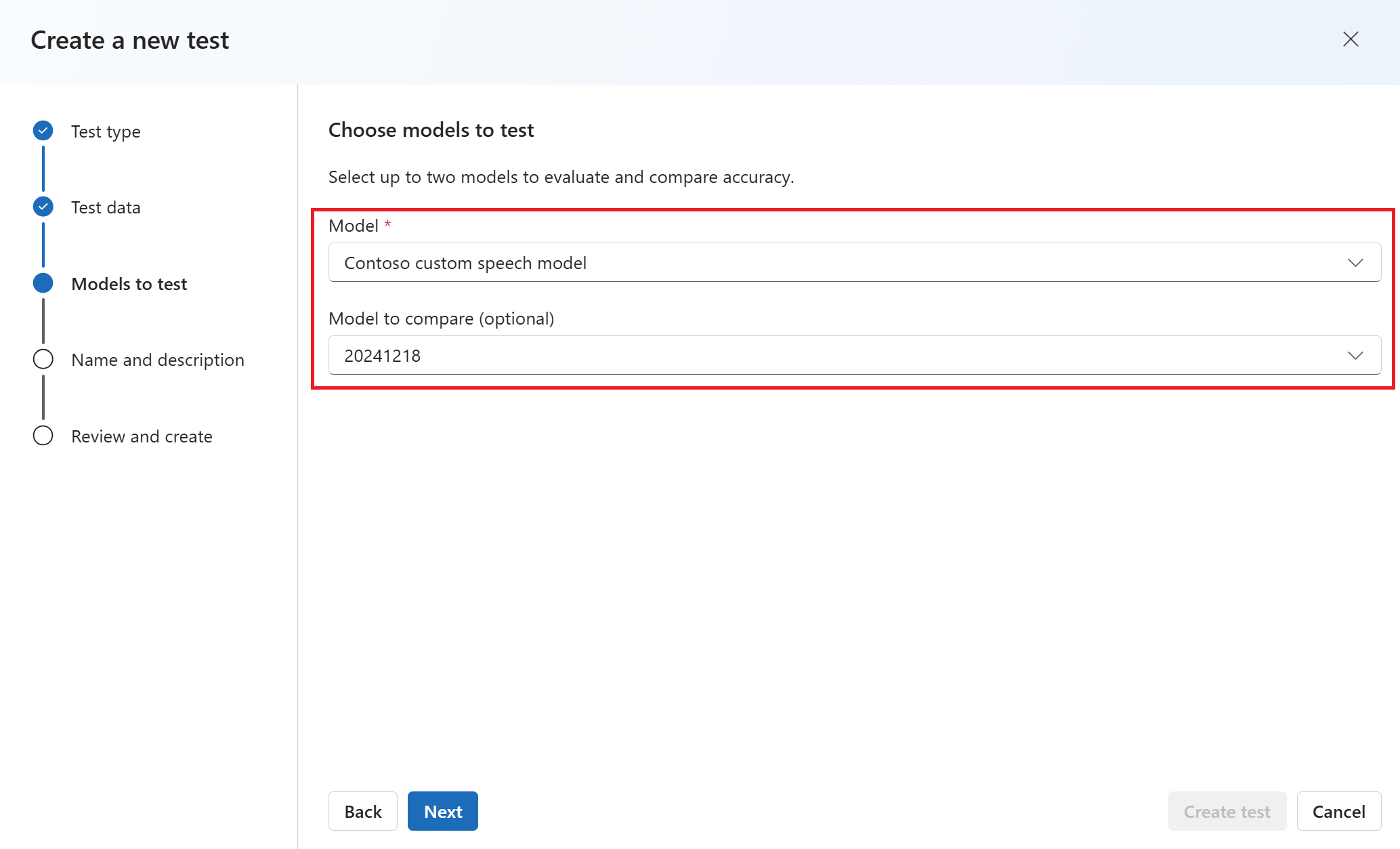
Wprowadź nazwę i opis testu. Następnie wybierz Dalej.
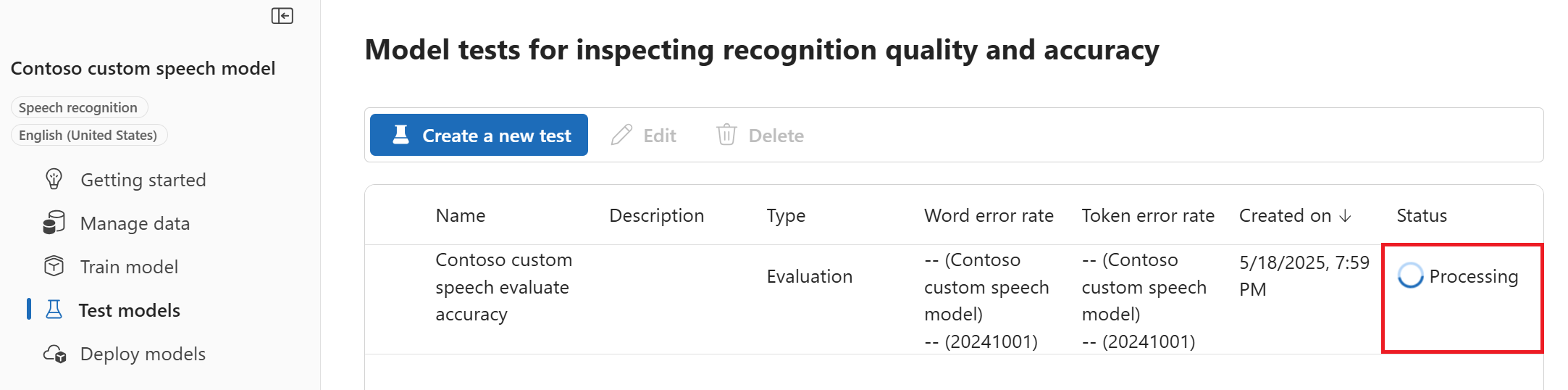
Przejrzyj ustawienia i wybierz pozycję Utwórz test. Wrócisz do strony Modele testowe. Stan danych to Przetwarzanie.




Wykonaj następujące kroki, aby utworzyć test dokładności:
Zaloguj się do programu Speech Studio.
Wybierz pozycję Nazwa >> testowe.
Wybierz pozycję Utwórz nowy test.
Wybierz pozycję Oceń dokładność>Dalej.
Wybierz jeden zestaw danych transkrypcji z etykietą ludzką i audio, a następnie wybierz przycisk Dalej. Jeśli nie ma żadnych dostępnych zestawów danych, anuluj konfigurację, a następnie przejdź do menu Zestawy danych usługi Mowa, aby przekazać zestawy danych.
Uwaga
Ważne jest, aby wybrać zestaw danych akustycznych, który różni się od zestawu danych używanego z modelem. Takie podejście może zapewnić bardziej realistyczne poczucie wydajności modelu.
Wybierz maksymalnie dwa modele do oceny, a następnie wybierz pozycję Dalej.
Wprowadź nazwę testu i opis, a następnie wybierz przycisk Dalej.
Przejrzyj szczegóły testu, a następnie wybierz pozycję Zapisz i zamknij.
Aby utworzyć test, użyj spx csr evaluation create polecenia . Skonstruuj parametry żądania zgodnie z następującymi instrukcjami:
- Ustaw właściwość
projectna identyfikator istniejącego projektu. Ta właściwość jest zalecana, aby można było również wyświetlić test w portalu usługi Azure AI Foundry. Możesz uruchomić polecenie ,spx csr project listaby uzyskać dostępne projekty. - Ustaw wymaganą
model1właściwość na identyfikator modelu, który chcesz przetestować. - Ustaw wymaganą
model2właściwość na identyfikator innego modelu, który chcesz przetestować. Jeśli nie chcesz porównywać dwóch modeli, użyj tego samego modelu dla obumodel1model2i . - Ustaw wymaganą
datasetwłaściwość na identyfikator zestawu danych, którego chcesz użyć na potrzeby testu. - Ustaw właściwość
language, w przeciwnym razie CLI usługi Mowa ustawia domyślnie wartość "en-US". Ten parametr powinien być ustawieniami regionalnymi zawartości zestawu danych. Nie można później zmienić ustawień regionalnych. Właściwośćlanguageinterfejsu wiersza polecenia usługi Mowa odpowiada właściwościlocalew żądaniu i odpowiedzi w formacie JSON. - Ustaw wymaganą
namewłaściwość. Ten parametr to nazwa wyświetlana w portalu usługi Azure AI Foundry. Właściwośćnameinterfejsu wiersza polecenia usługi Mowa odpowiada właściwościdisplayNamew żądaniu i odpowiedzi w formacie JSON.
Oto przykładowe polecenie interfejsu wiersza polecenia usługi Mowa, które tworzy test:
spx csr evaluation create --api-version v3.2 --project 0198f569-cc11-4099-a0e8-9d55bc3d0c52 --dataset 23b6554d-21f9-4df1-89cb-f84510ac8d23 --model1 ff43e922-e3e6-4bf0-8473-55c08fd68048 --model2 13fb305e-09ad-4bce-b3a1-938c9124dda3 --name "My Evaluation" --description "My Evaluation Description"
Treść odpowiedzi powinna zostać wyświetlona w następującym formacie:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:31:14Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
Właściwość najwyższego poziomu self w treści odpowiedzi to identyfikator URI oceny. Użyj tego identyfikatora URI, aby uzyskać szczegółowe informacje o projekcie i wynikach testów. Ten identyfikator URI służy również do aktualizowania lub usuwania oceny.
Aby uzyskać pomoc dotyczącą interfejsu wiersza polecenia usługi Mowa w ocenach, uruchom następujące polecenie:
spx help csr evaluation
Aby utworzyć test, użyj operacji Evaluations_Create interfejsu API REST zamiany mowy na tekst. Skonstruuj treść żądania zgodnie z następującymi instrukcjami:
-
projectUstaw właściwość na identyfikator URI istniejącego projektu. Ta właściwość jest zalecana, aby można było również wyświetlić test w portalu usługi Azure AI Foundry. Możesz wysłać żądanie Projects_List , aby uzyskać dostępne projekty. - Ustaw właściwość na
testingKindwartość w elem.EvaluationcustomPropertiesJeśli nie określiszEvaluationparametru , test jest traktowany jako test inspekcji jakości. Niezależnie od tego, czy właściwość jest ustawiona natestingKind,Evaluation, czy nie jest ustawiona naInspection, możesz uzyskać dostęp do wyników dokładności za pośrednictwem API, ale nie w portalu Azure AI Foundry. - Ustaw wymaganą
model1właściwość na identyfikator URI modelu, który chcesz przetestować. - Ustaw wymaganą
model2właściwość na identyfikator URI innego modelu, który chcesz przetestować. Jeśli nie chcesz porównywać dwóch modeli, użyj tego samego modelu dla obumodel1model2i . - Ustaw wymaganą
datasetwłaściwość na identyfikator URI zestawu danych, którego chcesz użyć na potrzeby testu. - Ustaw wymaganą
localewłaściwość. Ta właściwość powinna być ustawieniami regionalnymi zawartości zestawu danych. Nie można później zmienić ustawień regionalnych. - Ustaw wymaganą
displayNamewłaściwość. Ta właściwość to nazwa wyświetlana w portalu usługi Azure AI Foundry.
Utwórz żądanie HTTP POST przy użyciu identyfikatora URI, jak pokazano w poniższym przykładzie. Zastąp YourSpeechResoureKey ciąg kluczem zasobu usługi Mowa, zastąp YourServiceRegion element regionem zasobu usługi Mowa i ustaw właściwości treści żądania zgodnie z wcześniejszym opisem.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
},
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
Treść odpowiedzi powinna zostać wyświetlona w następującym formacie:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:31:14Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
Właściwość najwyższego poziomu self w treści odpowiedzi to identyfikator URI oceny. Użyj tego identyfikatora URI, aby uzyskać szczegółowe informacje o projekcie oceny i wynikach testu. Ten identyfikator URI służy również do aktualizowania lub usuwania oceny.
Uzyskiwanie wyników testu
Należy uzyskać wyniki testu i ocenić współczynnik błędów słów (WER) w porównaniu z wynikami rozpoznawania mowy.
Gdy stan testu to Powodzenie, możesz wyświetlić wyniki. Wybierz test, aby wyświetlić wyniki.
Wykonaj następujące kroki, aby uzyskać wyniki testu:
- Zaloguj się do programu Speech Studio.
- Wybierz pozycję Nazwa >> testowe.
- Wybierz link według nazwy testu.
- Po zakończeniu testu, zgodnie ze stanem ustawionym na Powodzenie, powinny zostać wyświetlone wyniki zawierające numer WER dla każdego przetestowanego modelu.
Na tej stronie wymieniono wszystkie wypowiedzi w zestawie danych i wyniki rozpoznawania wraz z transkrypcją z przesłanego zestawu danych. Można przełączać różne typy błędów, w tym wstawiania, usuwania i zastępowania. Słuchając dźwięku i porównując wyniki rozpoznawania w każdej kolumnie, możesz zdecydować, który model spełnia Twoje potrzeby, i określić, gdzie wymagane jest więcej szkoleń i ulepszeń.
Aby uzyskać wyniki testu, użyj spx csr evaluation status polecenia . Skonstruuj parametry żądania zgodnie z następującymi instrukcjami:
- Ustaw wymaganą właściwość
evaluationna identyfikator oceny, aby uzyskać wyniki testu.
Oto przykładowe polecenie interfejsu wiersza polecenia usługi Mowa, które pobiera wyniki testu:
spx csr evaluation status --api-version v3.2 --evaluation 8bfe6b05-f093-4ab4-be7d-180374b751ca
Słowa współczynniki błędów i więcej szczegółów są zwracane w treści odpowiedzi.
Treść odpowiedzi powinna zostać wyświetlona w następującym formacie:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:31:22Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
Aby uzyskać pomoc dotyczącą interfejsu wiersza polecenia usługi Mowa w ocenach, uruchom następujące polecenie:
spx help csr evaluation
Aby uzyskać wyniki testu, zacznij od użycia Evaluations_Get operacji interfejsu API REST zamiany mowy na tekst.
Utwórz żądanie HTTP GET przy użyciu identyfikatora URI, jak pokazano w poniższym przykładzie. Zastąp ciąg identyfikatorem oceny, zastąp YourEvaluationId ciąg kluczem zasobu usługi Mowa i zastąp YourSpeechResoureKeyYourServiceRegion element regionem zasobu usługi Mowa.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey"
Słowa współczynniki błędów i więcej szczegółów są zwracane w treści odpowiedzi.
Treść odpowiedzi powinna zostać wyświetlona w następującym formacie:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:31:22Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
Ocena współczynnika błędów wyrazów (WER)
Standardem branżowym do pomiaru dokładności modelu jest współczynnik błędów słów (WER). WER zlicza niepoprawne wyrazy zidentyfikowane podczas rozpoznawania i dzieli sumę przez łączną liczbę wyrazów podanych w transkrypcji oznaczonej przez człowieka (N).
Niepoprawnie zidentyfikowane wyrazy należą do trzech kategorii:
- Wstawianie (I): wyrazy, które są niepoprawnie dodawane w transkrypcji hipotezy
- Usuwanie (D): wyrazy, które są niewykryte w transkrypcji hipotezy
- Podstawianie (S): słowa, które zostały zastąpione między odniesieniem a hipotezą
W portalu Azure AI Foundry i Speech Studio iloraz jest mnożony przez 100 i wyświetlany jako wartość procentowa. Wyniki interfejsu wiersza polecenia usługi Mowa i interfejsu API REST nie są mnożone przez 100.
$$ WER = {{I+D+S} N}\over\times 100 $$
Oto przykład pokazujący niepoprawnie zidentyfikowane wyrazy w porównaniu z transkrypcją oznaczona przez człowieka:

Wynik rozpoznawania mowy został błędny w następujący sposób:
- Wstawianie (I): dodano słowo "a"
- Usuwanie (D): Usunięto słowo "are"
- Podstawianie (S): podstawiło słowo "Jones" dla "Johna"
Szybkość błędów słów z poprzedniego przykładu wynosi 60%.
Jeśli chcesz replikować pomiary WER lokalnie, możesz użyć narzędzia sclite z zestawu narzędzi NIST Scoring Toolkit (SCTK).
Usuwanie błędów i ulepszanie usługi WER
Możesz użyć obliczenia WER z wyników rozpoznawania maszyny, aby ocenić jakość modelu, którego używasz z aplikacją, narzędziem lub produktem. WER 5-10% jest uważany za dobrą jakość i jest gotowy do użycia. WER 20% jest akceptowalny, ale warto rozważyć więcej szkoleń. WER o 30% lub więcej sygnałów niskiej jakości i wymaga dostosowania i szkolenia.
Sposób dystrybucji błędów jest ważny. W przypadku napotkania wielu błędów usuwania zwykle jest to spowodowane słabą siłą sygnału audio. Aby rozwiązać ten problem, należy zebrać dane audio bliżej źródła. Błędy wstawiania oznaczają, że dźwięk został zarejestrowany w hałaśliwym środowisku, a crosstalk może być obecny, powodując problemy z rozpoznawaniem. Błędy podstawiania są często spotykane, gdy podano niewystarczającą próbkę terminów specyficznych dla domeny jako transkrypcje oznaczone przez człowieka lub powiązany tekst.
Analizując poszczególne pliki, można określić, jaki typ błędów istnieje, oraz jakie błędy są unikatowe dla określonego pliku. Zrozumienie problemów na poziomie pliku pomaga w określaniu celu ulepszeń.
Ocena współczynnika błędów tokenu (TER)
Oprócz współczynnika błędów słów można również użyć rozszerzonego pomiaru współczynnika błędów tokenu (TER) do oceny jakości w końcowym formacie wyświetlania. Oprócz formatu leksykacyjnego (That will cost $900. zamiast that will cost nine hundred dollars), ter uwzględnia aspekty formatu wyświetlania, takie jak interpunkcja, wielkie litery i ITN. Dowiedz się więcej o wyświetlaniu formatowania danych wyjściowych za pomocą mowy na tekst.
Ter zlicza niepoprawne tokeny zidentyfikowane podczas rozpoznawania i dzieli sumę przez łączną liczbę tokenów podanych w transkrypcji oznaczonej przez człowieka (N).
$$ TER = {{I+D+S} N}\over\times 100 $$
Formuła obliczeń TER jest również podobna do WER. Jedyną różnicą jest to, że ter jest obliczany na podstawie poziomu tokenu zamiast poziomu słowa.
- Wstawianie (I): Tokeny, które są niepoprawnie dodawane w transkrypcji hipotezy
- Usuwanie (D): tokeny, które nie są wykrywane w transkrypcji hipotezy
- Podstawianie (S): tokeny, które zostały zastąpione między odwołaniem a hipotezą
W rzeczywistym przypadku można analizować wyniki zarówno WER, jak i TER, aby uzyskać żądane ulepszenia.
Uwaga
Aby zmierzyć ter, należy upewnić się, że dane testowania dźwięku i transkrypcji zawierają transkrypcje z formatowaniem wyświetlania, takim jak interpunkcja, wielkie litery i ITN.
Przykładowe wyniki scenariusza
Scenariusze rozpoznawania mowy różnią się w zależności od jakości i języka dźwięku (słownictwo i styl mówienia). W poniższej tabeli przedstawiono cztery typowe scenariusze:
| Scenariusz | Jakość dźwięku | Słownictwo | Styl mówienia |
|---|---|---|---|
| Biuro obsługi | Niski, 8 kHz, może być dwie osoby na jednym kanale audio, można skompresować | Wąskie, unikatowe dla domeny i produktów | Konwersacyjna, luźno ustrukturyzowana |
| Asystent głosowy, taki jak Cortana, lub okno przejeżdżania | Wysoka, 16 kHz | Entity-heavy (tytuły piosenek, produkty, lokalizacje) | Wyraźnie określone wyrazy i frazy |
| Dyktowanie (wiadomość błyskawiczna, notatki, wyszukiwanie) | Wysoka, 16 kHz | Zróżnicowane | Sporządzanie notatek |
| Napisy wideo | Zróżnicowane, w tym zróżnicowane użycie mikrofonu, dodano muzykę | Zróżnicowane, od spotkań, cytowane przemówienie, teksty muzyczne | Odczyt, przygotowany lub luźno ustrukturyzowany |
Różne scenariusze generują różne wyniki jakości. W poniższej tabeli przedstawiono sposób oceniania zawartości z tych czterech scenariuszy w usłudze WER. W tabeli przedstawiono typy błędów, które są najbardziej typowe w każdym scenariuszu. Współczynnik błędów wstawiania, zastępowania i usuwania pomaga określić, jakiego rodzaju dane mają zostać dodane, aby ulepszyć model.
| Scenariusz | Jakość rozpoznawania mowy | Błędy wstawiania | Błędy usuwania | Błędy podstawiania |
|---|---|---|---|---|
| Biuro obsługi | Śred. (< 30% WER) |
Niski, z wyjątkiem sytuacji, gdy inni ludzie mówią w tle | Może być wysoki. Centra połączeń mogą być hałaśliwe, a nakładające się głośniki mogą mylić model | Średnia. Nazwy produktów i osób mogą powodować te błędy |
| Asystent głosowy | Wys. (może wynosić < 10% WER) |
Niski | Niski | Średni, ze względu na tytuły piosenek, nazwy produktów lub lokalizacje |
| Dyktowanie | Wys. (może wynosić < 10% WER) |
Niski | Niski | Wys. |
| Napisy wideo | Zależy od typu wideo (może wynosić < 50% WER) | Niski | Może być wysoka ze względu na muzykę, szumy, jakość mikrofonu | Żargon może spowodować te błędy |