Niestandardowe kontenery zamiany mowy na tekst za pomocą platformy Docker
Kontener zamiany mowy niestandardowej na tekst transkrybuje mowę w czasie rzeczywistym lub wsadowe nagrania audio z wynikami pośrednimi. Możesz użyć modelu niestandardowego utworzonego w niestandardowym portalu rozpoznawania mowy. Z tego artykułu dowiesz się, jak pobrać, zainstalować i uruchomić niestandardową mowę w kontenerze tekstowym.
Aby uzyskać więcej informacji na temat wymagań wstępnych, sprawdzania poprawności działania kontenera, uruchamiania wielu kontenerów na tym samym hoście i uruchamiania odłączonych kontenerów, zobacz Instalowanie i uruchamianie kontenerów usługi Mowa za pomocą platformy Docker.
Obrazy kontenerów
Niestandardowy obraz kontenera mowy na tekst dla wszystkich obsługiwanych wersji i ustawień regionalnych można znaleźć w syndykacie usługi Microsoft Container Registry (MCR). Znajduje się on w azure-cognitive-services/speechservices/ repozytorium i ma nazwę custom-speech-to-text.

W pełni kwalifikowana nazwa obrazu kontenera to mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text. Dołącz określoną wersję lub dołącz, :latest aby uzyskać najnowszą wersję.
| Wersja | Ścieżka |
|---|---|
| Najnowsze | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest |
| 4.6.0 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:4.6.0-amd64 |
Wszystkie tagi, z wyjątkiem latest, mają następujący format i są uwzględniane wielkość liter:
<major>.<minor>.<patch>-<platform>-<prerelease>
Uwaga
voice Kontener locale i dla niestandardowej mowy na tekst jest określany przez model niestandardowy pozyskiwany przez kontener.
Tagi są również dostępne w formacie JSON dla Wygody. Treść zawiera ścieżkę kontenera i listę tagów. Tagi nie są sortowane według wersji, ale "latest" są zawsze uwzględniane na końcu listy, jak pokazano w tym fragmencie kodu:
{
"name": "azure-cognitive-services/speechservices/custom-speech-to-text",
"tags": [
"2.10.0-amd64",
"2.11.0-amd64",
"2.12.0-amd64",
"2.12.1-amd64",
<--redacted for brevity-->
"latest"
]
}
Pobieranie obrazu kontenera za pomocą ściągania platformy Docker
Potrzebujesz wymagań wstępnych , w tym wymaganego sprzętu. Zobacz również zalecaną alokację zasobów dla każdego kontenera usługi Mowa.
Użyj polecenia docker pull, aby pobrać obraz kontenera z usługi Microsoft Container Registry:
docker pull mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest
Uwaga
Kontener locale i voice dla niestandardowych kontenerów usługi Mowa jest określany przez model niestandardowy pozyskiwany przez kontener.
Pobieranie identyfikatora modelu
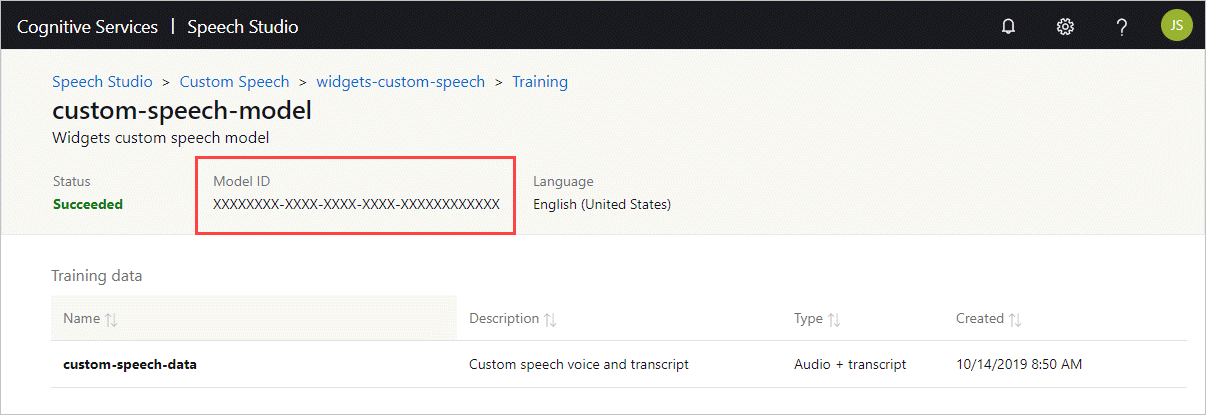
Zanim będzie można uruchomić kontener, musisz znać identyfikator modelu niestandardowego lub identyfikator modelu podstawowego. Po uruchomieniu kontenera należy określić jeden z identyfikatorów modelu do pobrania i użycia.
Model niestandardowy musi zostać wytrenowany przy użyciu programu Speech Studio. Aby uzyskać informacje o sposobie uzyskiwania identyfikatora modelu, zobacz cykl życia niestandardowego modelu mowy.
Uzyskaj identyfikator modelu, który ma być używany jako argument ModelId dla parametru docker run polecenia.
Pobieranie modelu wyświetlania
Przed uruchomieniem kontenera możesz opcjonalnie uzyskać dostępne informacje o modelach wyświetlania i wybrać pobranie tych modeli do kontenera zamiany mowy na tekst w celu uzyskania wysoce ulepszonych końcowych danych wyjściowych wyświetlania. Pobieranie modelu wyświetlania jest dostępne w kontenerze custom-speech-to-text w wersji 3.1.0 lub nowszej.
Uwaga
Mimo że używasz docker run polecenia , kontener nie jest uruchamiany dla usługi.
Możesz wykonywać zapytania lub pobierać dowolne lub wszystkie z tych typów modeli wyświetlania: Rescoring (Rescore), Interpunkcja (), Resegmentation (PunctResegment) i wfstitn (Wfstitn). W przeciwnym razie możesz użyć FullDisplay opcji (z innymi typami lub bez nich), aby wykonać zapytanie lub pobrać wszystkie typy modeli wyświetlania.
Ustaw wartość , BaseModelLocale aby wysłać zapytanie do najnowszego dostępnego modelu wyświetlania w ustawieniach regionalnych docelowych. Jeśli uwzględnisz wiele typów modeli wyświetlania, polecenie zwraca najnowsze dostępne modele wyświetlania dla każdego typu. Na przykład:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
BaseModelLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Ustaw wartość , DisplayLocale aby pobrać najnowszy dostępny model wyświetlania w ustawieniach regionalnych docelowych. Po ustawieniu DisplayLocaleparametru należy również określić FullDisplay lub rozdzielony spacjami podzestaw modeli wyświetlania. Polecenie pobiera najnowszy dostępny model wyświetlania dla każdego określonego typu. Na przykład:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
DisplayLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Ustaw jeden parametr identyfikatora modelu, aby pobrać określony model wyświetlania: Rescoring (RescoreId), Interpunkcja (), Resegmentation (PunctIdResegmentId) lub wfstitn (WfstitnId). Jest to podobne do sposobu pobierania modelu podstawowego za pomocą parametru ModelId . Na przykład aby pobrać model wyświetlania rescoringu, możesz użyć następującego polecenia z parametrem RescoreId :
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
RescoreId={RESCORE_MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Uwaga
Jeśli ustawisz więcej niż jedno zapytanie lub parametr pobierania, polecenie będzie określać priorytety w następującej kolejności: BaseModelLocale, identyfikator modelu, a następnie DisplayLocale (dotyczy tylko modeli wyświetlania).
Uruchamianie kontenera za pomocą uruchamiania platformy Docker
Użyj polecenia docker run, aby uruchomić kontener dla usługi.
W poniższej tabeli przedstawiono różne docker run parametry i odpowiadające im opisy:
| Parametr | Opis |
|---|---|
{VOLUME_MOUNT} |
Instalacja woluminu komputera hosta, która jest używana przez platformę Docker do utrwalania modelu niestandardowego. Przykładem jest c:\CustomSpeech miejsce, w c:\ którym znajduje się dysk na maszynie hosta. |
{MODEL_ID} |
Niestandardowy identyfikator mowy lub modelu podstawowego. Aby uzyskać więcej informacji, zobacz Pobieranie identyfikatora modelu. |
{ENDPOINT_URI} |
Punkt końcowy jest wymagany do pomiaru i rozliczeń. Aby uzyskać więcej informacji, zobacz argumenty rozliczeniowe. |
{API_KEY} |
Klucz interfejsu API jest wymagany. Aby uzyskać więcej informacji, zobacz argumenty rozliczeniowe. |
Po uruchomieniu kontenera niestandardowej mowy na tekst skonfiguruj port, pamięć i procesor CPU zgodnie z niestandardowymi wymaganiami i zaleceniami dotyczącymi kontenera tekstu.
Oto przykładowe docker run polecenie z wartościami zastępczymi. Musisz określić VOLUME_MOUNTwartości , MODEL_ID, ENDPOINT_URIi API_KEY :
docker run --rm -it -p 5000:5000 --memory 8g --cpus 4 \
-v {VOLUME_MOUNT}:/usr/local/models \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
ModelId={MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
To polecenie:
- Uruchamia niestandardową mowę do kontenera tekstowego z obrazu kontenera.
- Przydziela 4 rdzenie procesora CPU i 8 GB pamięci.
- Ładuje niestandardową mowę do modelu tekstowego z instalacji wejściowej woluminu, na przykład C:\CustomSpeech.
- Uwidacznia port TCP 5000 i przydziela pseudo-TTY dla kontenera.
- Pobiera model z danym elementem
ModelId(jeśli nie znaleziono go na instalacji woluminu). - Jeśli model niestandardowy został wcześniej pobrany,
ModelIdelement jest ignorowany. - Automatycznie usuwa kontener po jego zakończeniu. Obraz kontenera jest nadal dostępny na komputerze hosta.
Aby uzyskać więcej informacji na temat docker run kontenerów usługi Mowa, zobacz Instalowanie i uruchamianie kontenerów usługi Mowa za pomocą platformy Docker.
Korzystanie z kontenera
Kontenery mowy udostępniają internetowe interfejsy API punktów końcowych zapytań oparte na protokole Websocket, które są dostępne za pośrednictwem zestawu SPEECH SDK i interfejsu wiersza polecenia usługi Mowa. Domyślnie zestaw SDK usługi Mowa i interfejs wiersza polecenia usługi Mowa używają publicznej usługi rozpoznawania mowy. Aby użyć kontenera, należy zmienić metodę inicjowania.
Ważne
W przypadku korzystania z usługi Mowa z kontenerami upewnij się, że używasz uwierzytelniania hosta. Jeśli skonfigurujesz klucz i region, żądania będą kierowane do publicznej usługi rozpoznawania mowy. Wyniki z usługi Mowa mogą nie być oczekiwane. Żądania od odłączonych kontenerów zakończą się niepowodzeniem.
Zamiast używać tej konfiguracji inicjowania chmury platformy Azure:
var config = SpeechConfig.FromSubscription(...);
Użyj tej konfiguracji z hostem kontenera:
var config = SpeechConfig.FromHost(
new Uri("ws://localhost:5000"));
Zamiast używać tej konfiguracji inicjowania chmury platformy Azure:
auto speechConfig = SpeechConfig::FromSubscription(...);
Użyj tej konfiguracji z hostem kontenera:
auto speechConfig = SpeechConfig::FromHost("ws://localhost:5000");
Zamiast używać tej konfiguracji inicjowania chmury platformy Azure:
speechConfig, err := speech.NewSpeechConfigFromSubscription(...)
Użyj tej konfiguracji z hostem kontenera:
speechConfig, err := speech.NewSpeechConfigFromHost("ws://localhost:5000")
Zamiast używać tej konfiguracji inicjowania chmury platformy Azure:
SpeechConfig speechConfig = SpeechConfig.fromSubscription(...);
Użyj tej konfiguracji z hostem kontenera:
SpeechConfig speechConfig = SpeechConfig.fromHost("ws://localhost:5000");
Zamiast używać tej konfiguracji inicjowania chmury platformy Azure:
const speechConfig = sdk.SpeechConfig.fromSubscription(...);
Użyj tej konfiguracji z hostem kontenera:
const speechConfig = sdk.SpeechConfig.fromHost("ws://localhost:5000");
Zamiast używać tej konfiguracji inicjowania chmury platformy Azure:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithSubscription:...];
Użyj tej konfiguracji z hostem kontenera:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithHost:"ws://localhost:5000"];
Zamiast używać tej konfiguracji inicjowania chmury platformy Azure:
let speechConfig = SPXSpeechConfiguration(subscription: "", region: "");
Użyj tej konfiguracji z hostem kontenera:
let speechConfig = SPXSpeechConfiguration(host: "ws://localhost:5000");
Zamiast używać tej konfiguracji inicjowania chmury platformy Azure:
speech_config = speechsdk.SpeechConfig(
subscription=speech_key, region=service_region)
Użyj tej konfiguracji z punktem końcowym kontenera:
speech_config = speechsdk.SpeechConfig(
host="ws://localhost:5000")
Jeśli używasz interfejsu wiersza polecenia usługi Mowa w kontenerze, dołącz --host ws://localhost:5000/ opcję . Należy również określić --key none , aby upewnić się, że interfejs wiersza polecenia nie próbuje użyć klucza mowy do uwierzytelniania. Aby uzyskać informacje o sposobie konfigurowania interfejsu wiersza polecenia usługi Mowa, zobacz Rozpoczynanie pracy z interfejsem wiersza polecenia usługi Azure AI Speech.
Wypróbuj mowę do tekstu — szybki start przy użyciu uwierzytelniania hosta zamiast klucza i regionu.
Następne kroki
- Zobacz omówienie kontenerów usługi Mowa
- Przejrzyj konfigurowanie kontenerów pod kątem ustawień konfiguracji
- Korzystanie z większej liczby kontenerów sztucznej inteligencji platformy Azure
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla