Jak oceniać generowanie aplikacji sztucznej inteligencji za pomocą usługi Azure AI Studio
Ważne
Niektóre funkcje opisane w tym artykule mogą być dostępne tylko w wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Aby dokładnie ocenić wydajność aplikacji generowania sztucznej inteligencji w przypadku zastosowania do istotnego zestawu danych, możesz zainicjować proces oceny. Podczas tej oceny aplikacja jest testowana przy użyciu danego zestawu danych, a jej wydajność będzie mierzona ilościowo przy użyciu metryk opartych na matematyce i metryk wspomaganych przez sztuczną inteligencję. Ten przebieg oceny zapewnia kompleksowy wgląd w możliwości i ograniczenia aplikacji.
Aby przeprowadzić tę ocenę, możesz użyć funkcji oceny w usłudze Azure AI Studio, kompleksowej platformy, która oferuje narzędzia i funkcje do oceny wydajności i bezpieczeństwa generowanego modelu sztucznej inteligencji. W programie AI Studio możesz rejestrować, wyświetlać i analizować szczegółowe metryki oceny.
Z tego artykułu dowiesz się, jak utworzyć przebieg oceny na podstawie zestawu danych testowych lub przepływu z wbudowanymi metrykami oceny z poziomu interfejsu użytkownika programu Azure AI Studio. Aby uzyskać większą elastyczność, można ustanowić niestandardowy przepływ oceny i stosować funkcję oceny niestandardowej. Alternatywnie, jeśli twoim celem jest wyłącznie przeprowadzenie przebiegu wsadowego bez żadnej oceny, możesz również użyć funkcji oceny niestandardowej.
Wymagania wstępne
Aby uruchomić ocenę za pomocą metryk wspomaganych przez sztuczną inteligencję, należy przygotować następujące elementy:
- Testowy zestaw danych w jednym z następujących formatów:
csvlubjsonl. - Połączenie usługi Azure OpenAI.
- Wdrożenie jednego z następujących modeli: modele GPT 3.5, modele GPT 4 lub Modele Davinci.
Tworzenie oceny za pomocą wbudowanych metryk oceny
Przebieg oceny umożliwia generowanie danych wyjściowych metryk dla każdego wiersza danych w zestawie danych testowych. Możesz wybrać co najmniej jedną metrykę oceny, aby ocenić dane wyjściowe z różnych aspektów. Możesz utworzyć przebieg oceny na podstawie stron oceny i przepływu monitów w programie AI Studio. Następnie zostanie wyświetlony kreator tworzenia oceny, który przeprowadzi Cię przez proces konfigurowania przebiegu oceny.
Na stronie oceny
Z zwijanego menu po lewej stronie wybierz pozycję Ocena>+ Nowa ocena.

Na stronie przepływu
Z zwijanego menu po lewej stronie wybierz pozycję Monituj przepływ>Oceń>wbudowaną ocenę.

Informacje podstawowe
Po wprowadzeniu kreatora tworzenia oceny możesz podać opcjonalną nazwę przebiegu oceny i wybrać scenariusz, który najlepiej pasuje do celów aplikacji. Obecnie oferujemy obsługę następujących scenariuszy:
- Pytanie i odpowiedź z kontekstem: ten scenariusz jest przeznaczony dla aplikacji, które obejmują odpowiadanie na zapytania użytkowników i dostarczanie odpowiedzi z informacjami kontekstowymi.
- Pytanie i odpowiedź bez kontekstu: ten scenariusz jest przeznaczony dla aplikacji, które obejmują odpowiadanie na zapytania użytkowników i dostarczanie odpowiedzi bez kontekstu.
Możesz użyć panelu pomocy, aby sprawdzić często zadawane pytania i samodzielnie zapoznać się z kreatorem.

Określając odpowiedni scenariusz, możemy dostosować ocenę do określonego charakteru aplikacji, zapewniając dokładne i odpowiednie metryki.
- Ocena na podstawie danych: jeśli masz już wygenerowane dane wyjściowe modelu w zestawie danych testowych, pomiń pozycję Wybierz przepływ, aby ocenić i przejść bezpośrednio do następnego kroku, aby skonfigurować dane testowe.
- Oceń z przepływu: jeśli zainicjujesz ocenę na stronie Przepływ, automatycznie wybierzemy przepływ do oceny. Jeśli zamierzasz ocenić inny przepływ, możesz wybrać inny przepływ. Należy pamiętać, że w ramach przepływu może istnieć wiele węzłów, z których każdy może mieć własny zestaw wariantów. W takich przypadkach należy określić węzeł i warianty, które chcesz ocenić podczas procesu oceny.

Konfigurowanie danych testowych
Możesz wybrać spośród wstępnie istniejących zestawów danych lub przekazać nowy zestaw danych specjalnie do oceny. Zestaw danych testowych musi mieć wygenerowane przez model dane wyjściowe, które mają być używane do oceny, jeśli w poprzednim kroku nie wybrano żadnego przepływu.
Wybierz istniejący zestaw danych: możesz wybrać zestaw danych testowych z utworzonej kolekcji zestawów danych.
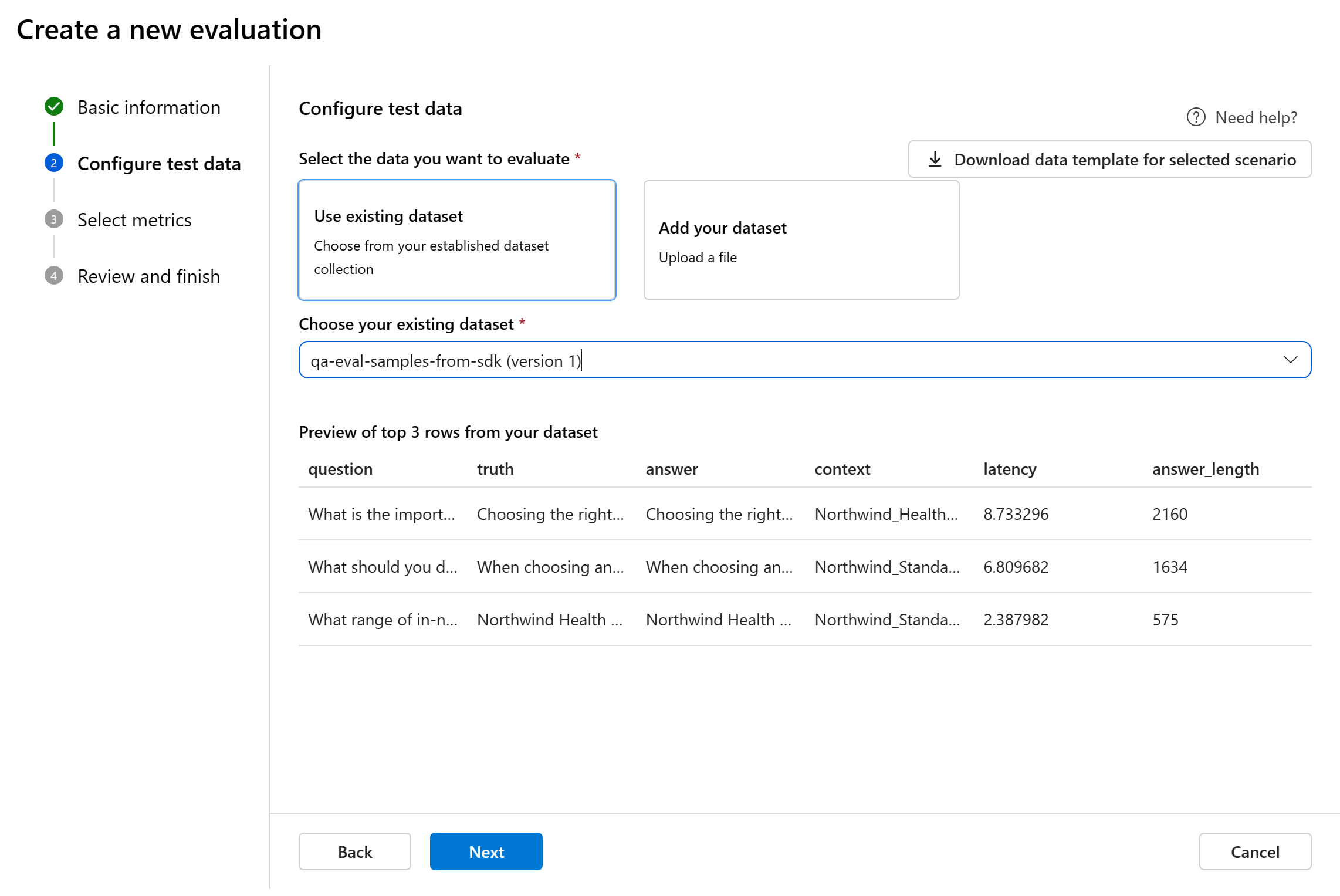
Dodaj nowy zestaw danych: możesz przekazać pliki z magazynu lokalnego. Obsługujemy
.csvtylko formaty plików i.jsonl.
Mapowanie danych dla przepływu: jeśli wybierzesz przepływ do oceny, upewnij się, że kolumny danych są skonfigurowane tak, aby były zgodne z wymaganymi danymi wejściowymi dla przepływu w celu wykonania przebiegu wsadowego, generując dane wyjściowe do oceny. Następnie zostanie przeprowadzona ocena przy użyciu danych wyjściowych z przepływu. Następnie skonfiguruj mapowanie danych dla danych wejściowych oceny w następnym kroku.




Wybieranie metryk
Firma Microsoft obsługuje dwa typy metryk wyselekcjonowanych przez firmę Microsoft, aby ułatwić kompleksową ocenę aplikacji:
- Metryki wydajności i jakości: Te metryki oceniają ogólną jakość i spójność wygenerowanej zawartości.
- Metryki ryzyka i bezpieczeństwa: te metryki koncentrują się na identyfikowaniu potencjalnych zagrożeń związanych z zawartością i zapewnianiu bezpieczeństwa wygenerowanej zawartości.
Możesz zapoznać się z tabelą zawierającą pełną listę metryk, dla których oferujemy pomoc techniczną w każdym scenariuszu. Aby uzyskać bardziej szczegółowe informacje na temat każdej definicji metryki i sposobu jej obliczania, zobacz Metryki oceny i monitorowania.
| Scenariusz | Metryki wydajności i jakości | Metryki ryzyka i bezpieczeństwa |
|---|---|---|
| Pytanie i odpowiedź z kontekstem | Uziemienie, istotność, spójność, fluency, podobieństwo GPT, wynik F1 | Zawartość związana z samookaleczeniami, nienawistna i niesprawiedliwa zawartość, treści brutalne, treści seksualne |
| Pytanie i odpowiedź bez kontekstu | Spójność, płynność, podobieństwo GPT, wynik F1 | Zawartość związana z samookaleczeniami, nienawistna i niesprawiedliwa zawartość, treści brutalne, treści seksualne |
W przypadku korzystania z metryk wspomaganych przez sztuczną inteligencję na potrzeby oceny wydajności i jakości należy określić model GPT dla procesu obliczania. Wybierz połączenie Azure OpenAI i wdrożenie z modelem GPT-3.5, GPT-4 lub Davinci dla naszych obliczeń.

W przypadku metryk ryzyka i bezpieczeństwa nie trzeba dostarczać połączenia i wdrażania. Usługa zaplecza oceny bezpieczeństwa usługi Azure AI Studio aprowizuje model GPT-4, który może generować oceny ważności ryzyka zawartości i rozumowanie, aby umożliwić ocenę aplikacji pod kątem szkód w zawartości.
Możesz ustawić próg, aby obliczyć współczynnik wad dla metryk ryzyka i bezpieczeństwa. Współczynnik wad jest obliczany przez użycie procentu wystąpień z poziomami ważności (bardzo niski, niski, średni, wysoki) powyżej progu. Domyślnie ustawiamy próg jako "Średni".

Uwaga
Metryki ryzyka i bezpieczeństwa wspomagane przez sztuczną inteligencję są hostowane przez usługę zaplecza oceny bezpieczeństwa usługi Azure AI Studio i są dostępne tylko w następujących regionach: Wschodnie stany USA 2, Francja Środkowa, Południowe Zjednoczone Królestwo, Szwecja Środkowa, Szwecja Środkowa
Mapowanie danych na potrzeby oceny: musisz określić, które kolumny danych w zestawie danych odpowiadają danym wejściowym wymaganym w ocenie. Różne metryki oceny wymagają odrębnych typów danych wejściowych na potrzeby dokładnych obliczeń.

Uwaga
Jeśli oceniasz dane, wyrażenie "odpowiedź" powinno zostać zamapowane na kolumnę odpowiedzi w zestawie danych ${data$answer}. Jeśli oceniasz z przepływu, "odpowiedź" powinna pochodzić z danych wyjściowych ${run.outputs.answer}przepływu .
Aby uzyskać wskazówki dotyczące konkretnych wymagań dotyczących mapowania danych dla każdej metryki, zapoznaj się z informacjami podanymi w tabeli:
Wymagania dotyczące metryk odpowiedzi na pytania
| Metric | Pytanie | Odpowiedź | Kontekst | Prawda naziemna |
|---|---|---|---|---|
| Uziemienie | Wymagane: str | Wymagane: str | Wymagane: str | Nie dotyczy |
| Spójności | Wymagane: str | Wymagane: str | Brak | Brak |
| Płynność | Wymagane: str | Wymagane: str | Brak | Brak |
| Stopień zgodności | Wymagane: str | Wymagane: str | Wymagane: str | Nie dotyczy |
| Podobieństwo GPT | Wymagane: str | Wymagane: str | Nie dotyczy | Wymagane: str |
| Wynik F1 | Wymagane: str | Wymagane: str | Nie dotyczy | Wymagane: str |
| Zawartość związana z samookaleczeniami | Wymagane: str | Wymagane: str | Brak | Brak |
| Nienawistne i niesprawiedliwe treści | Wymagane: str | Wymagane: str | Brak | Brak |
| Brutalna zawartość | Wymagane: str | Wymagane: str | Brak | Brak |
| Zawartość seksualna | Wymagane: str | Wymagane: str | Brak | Brak |
- Pytanie: pytanie zadawane przez użytkownika w parze Odpowiedzi na pytania
- Odpowiedź: odpowiedź na pytanie wygenerowane przez model jako odpowiedź
- Kontekst: źródło, które odpowiedź jest generowana w odniesieniu do (czyli dokumentów uziemionych)
- Prawda: odpowiedź na pytanie wygenerowane przez użytkownika/człowieka jako prawdziwą odpowiedź
Przejrzyj i zakończ
Po zakończeniu wszystkich niezbędnych konfiguracji możesz przejrzeć i przejść do wybrania pozycji "Prześlij", aby przesłać przebieg oceny.

Tworzenie oceny przy użyciu niestandardowego przepływu oceny
Możesz opracować własne metody oceny:
Na stronie przepływu: z zwijanego menu po lewej stronie wybierz pozycję Monituj przepływ>Oceń>ocenę niestandardową.

Wyświetlanie ewaluatorów i zarządzanie nimi w bibliotece ewaluatorów
Biblioteka ewaluatora to scentralizowane miejsce, które umożliwia wyświetlanie szczegółów i stanu ewaluatorów. Możesz wyświetlać ewaluatorów wyselekcjonowanych przez firmę Microsoft i zarządzać nimi.
Napiwek
Możesz użyć niestandardowych ewaluatorów za pośrednictwem zestawu SDK przepływu monitów. Aby uzyskać więcej informacji, zobacz Evaluate with the prompt flow SDK (Ocena za pomocą zestawu SDK przepływu monitu).
Biblioteka ewaluatora umożliwia również zarządzanie wersjami. W razie potrzeby możesz porównać różne wersje pracy, przywrócić poprzednie wersje i łatwiej współpracować z innymi osobami.
Aby użyć biblioteki ewaluatora w programie AI Studio, przejdź do strony Ocena projektu i wybierz kartę Biblioteka ewaluatora.

Możesz wybrać nazwę ewaluatora, aby wyświetlić więcej szczegółów. Możesz zobaczyć nazwę, opis i parametry oraz sprawdzić wszystkie pliki skojarzone z ewaluatorem. Oto kilka przykładów ewaluatorów wyselekcjonowanych przez firmę Microsoft:
- W przypadku ewaluatorów wydajności i jakości wyselekcjonowanych przez firmę Microsoft możesz wyświetlić monit adnotacji na stronie szczegółów. Te monity można dostosować do własnego przypadku użycia, zmieniając parametry lub kryteria zgodnie z danymi i celami za pomocą zestawu SDK przepływu monitów. Możesz na przykład wybrać pozycję Groundedness-Evaluator i sprawdzić plik Prompty pokazujący sposób obliczania metryki.
- W przypadku ewaluatorów ryzyka i bezpieczeństwa wyselekcjonowanych przez firmę Microsoft można zobaczyć definicję metryk. Możesz na przykład wybrać narzędzie Self-Harm-Related-Content-Evaluator i dowiedzieć się, co to znaczy i jak firma Microsoft określa różne poziomy ważności dla tej metryki bezpieczeństwa
Następne kroki
Dowiedz się więcej na temat oceniania generowanych aplikacji sztucznej inteligencji:
- Ocena generowanych aplikacji sztucznej inteligencji za pośrednictwem placu zabaw
- Wyświetlanie wyników oceny
- Dowiedz się więcej o technikach ograniczania szkód.
- Transparency Note for Azure AI Studio safety evaluations (Ocena bezpieczeństwa usługi Azure AI Studio).