Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano, jak korzystać z kontroli kondycji w portalu Azure do monitorowania wystąpień usługi App Service. Monitorowanie kondycji zwiększa dostępność aplikacji, przekierowując żądania z dala od niezdrowych instancji i zastępując instancje, jeśli pozostają niezdrowe. Robi to, wysyłając polecenie ping do aplikacji internetowej co minutę za pomocą wybranej ścieżki.
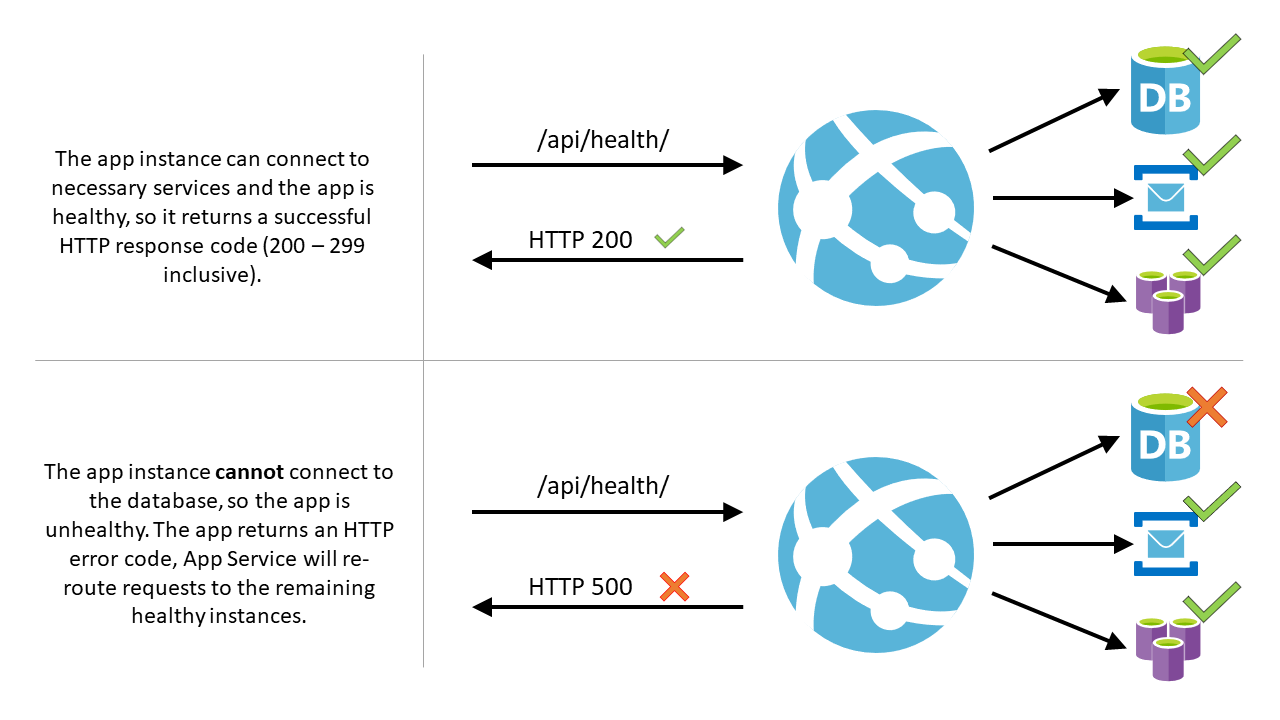
Należy pamiętać, że /api/health jest tylko przykładem. Nie ma domyślnej ścieżki sprawdzania kondycji. Upewnij się, że wybrana ścieżka jest prawidłową ścieżką, która istnieje w aplikacji.
Jak działa sprawdzanie kondycji
- Podczas podania ścieżki w aplikacji, kontrola kondycji wysyła polecenie ping do ścieżki we wszystkich wystąpieniach twojej aplikacji w usłudze App Service w odstępach co minutę.
- Jeśli aplikacja internetowa uruchomiona w danym wystąpieniu nie odpowiada za pomocą kodu stanu z zakresu od 200 do 299 (włącznie) po 10 żądaniach, usługa App Service określa, że wystąpienie jest w złej kondycji i usuwa je z modułu równoważenia obciążenia dla aplikacji internetowej. Wymagana liczba żądań zakończonych niepowodzeniem dla wystąpienia, aby zostało uznane za niesprawne, może być skonfigurowana na co najmniej dwa żądania.
- Po usunięciu wystąpienia, test kondycji nadal wykonuje pingowanie. Jeśli instancja zacznie odpowiadać kodem statusu oznaczającym prawidłowe działanie (200–299), instancja zostanie zwrócona do równoważnika obciążenia.
- Jeśli aplikacja webowa uruchomiona na instancji pozostaje niedziałająca prawidłowo przez jedną godzinę, instancja zostanie zastąpiona nową.
- Podczas skalowania w górę usługa App Service wysyła polecenie ping do ścieżki sprawdzania kondycji, aby upewnić się, że nowe wystąpienia są gotowe.
Uwaga / Notatka
- Kontrola kondycji nie podąża za przekierowaniami 302.
- Maksymalnie jedno wystąpienie będzie zastępowane na godzinę, z nie więcej niż trzema wystąpieniami dziennie na Plan App Service.
- Jeśli sprawdzanie kondycji wysyła stan
Waiting for health check response, może to oznaczać niepowodzenie z powodu kodu stanu HTTP 307, co może się zdarzyć, jeśli masz włączone przekierowanie do HTTPS, aleHTTPS Onlyjest wyłączone.
Włącz kontrolę kondycji

- Aby włączyć kontrolę kondycji, przejdź do witryny Azure Portal i wybierz aplikację usługi App Service.
- W obszarze Monitorowanie wybierz pozycję Sprawdzanie kondycji.
- Wybierz pozycję Włącz i podaj prawidłową ścieżkę adresu URL dla aplikacji, na przykład
/healthlub/api/health. - Wybierz Zapisz.
Uwaga / Notatka
- Plan usługi App Service powinien być skalowany do co najmniej dwóch wystąpień, aby w pełni wykorzystać kontrolę kondycji.
- Ścieżka sprawdzania kondycji powinna sprawdzać krytyczne składniki aplikacji. Jeśli na przykład aplikacja zależy od bazy danych i systemu obsługi komunikatów, punkt końcowy sprawdzania kondycji powinien połączyć się z tymi składnikami. Jeśli aplikacja nie może nawiązać połączenia ze składnikiem krytycznym, ścieżka powinna zwrócić kod odpowiedzi na poziomie 500, aby wskazać, że aplikacja jest w złej kondycji. Ponadto, jeśli ścieżka nie zwróci odpowiedzi w ciągu jednej minuty, ping sprawdzania stanu zdrowia uznaje się za niesprawny.
- Podczas wybierania ścieżki kontroli kondycji, upewnij się, że wybierasz ścieżkę zwracającą kod stanu 200 tylko wtedy, gdy aplikacja jest w pełni gotowa do działania.
- Aby korzystać z kontroli kondycji w aplikacji funkcyjnej, należy użyć planu hostingu w warstwie Premium lub dedykowanej.
- Szczegóły dotyczące kontroli zdrowia aplikacji funkcji można znaleźć tutaj: Monitorowanie aplikacji funkcji przy użyciu kontroli zdrowia.
Ostrzeżenie
Zmiany konfiguracji kontroli kondycji ponownie uruchamiają aplikację. Aby zminimalizować wpływ na aplikacje produkcyjne, zalecamy skonfigurowanie miejsc przejściowych i zamianę na środowisko produkcyjne.
Konfiguracja
Oprócz konfigurowania opcji kontroli kondycji można również skonfigurować następujące ustawienia aplikacji:
| Nazwa ustawienia aplikacji | Dozwolone wartości | Opis |
|---|---|---|
WEBSITE_HEALTHCHECK_MAXPINGFAILURES |
2 - 10 | Wymagana liczba żądań zakończonych niepowodzeniem dla wystąpienia, które mają zostać uznane za w złej kondycji i usunięte z modułu równoważenia obciążenia. Na przykład, gdy ustawisz to na 2, wystąpienia zostaną usunięte po 2 nieudanych pingach. (Wartość domyślna to 10.) |
WEBSITE_HEALTHCHECK_MAXUNHEALTHYWORKERPERCENT |
1 - 100 | Domyślnie, aby uniknąć przeciążenia pozostałych zdrowych wystąpień, nie więcej niż połowa wystąpień zostanie wykluczona z modułu równoważenia obciążenia jednocześnie. Jeśli na przykład plan usługi App Service jest skalowany do czterech wystąpień, a trzy są w złej kondycji, dwa są wykluczone. Pozostałe dwie instancje (jedna w dobrej kondycji i jedna w złej kondycji) nadal przyjmują żądania. W scenariuszu, w którym wszystkie wystąpienia są w złej kondycji, żaden z nich nie jest wykluczony. Aby zastąpić to zachowanie, ustaw to ustawienie aplikacji na wartość między 1 i 100. Wyższa wartość oznacza, że usunięto więcej niezdrowych przypadków. (Wartość domyślna to 50.). |
Uwierzytelnianie i zabezpieczenia
Kontrola kondycji integruje się z funkcjami uwierzytelniania i autoryzacji usługi App Service. Nie są wymagane żadne inne ustawienia, jeśli te funkcje zabezpieczeń są włączone.
Jeśli używasz własnego systemu uwierzytelniania, ścieżka kontrolna zdrowia powinna umożliwiać dostęp anonimowy. Aby zapewnić bezpieczeństwo punktu końcowego kontroli kondycji, należy najpierw użyć funkcji, takich jak ograniczenia adresów IP, certyfikaty klienta lub sieć wirtualna, aby ograniczyć dostęp do aplikacji. Po wprowadzeniu tych funkcji można uwierzytelnić żądanie sprawdzania kondycji, sprawdzając nagłówek x-ms-auth-internal-token i sprawdzając, czy jest on zgodny ze skrótem SHA256 zmiennej środowiskowej WEBSITE_AUTH_ENCRYPTION_KEY. Jeśli są one zgodne, żądanie sprawdzania kondycji jest prawidłowe i pochodzi z usługi App Service.
Uwaga / Notatka
W przypadku uwierzytelniania usługi Azure Functions funkcja, która służy jako punkt końcowy kontroli kondycji, musi zezwalać na dostęp anonimowy.
using System;
using System.Security.Cryptography;
using System.Text;
/// <summary>
/// Method <c>HeaderMatchesEnvVar</c> returns true if <c>headerValue</c> matches WEBSITE_AUTH_ENCRYPTION_KEY.
/// </summary>
public bool HeaderMatchesEnvVar(string headerValue)
{
var sha = SHA256.Create();
string envVar = Environment.GetEnvironmentVariable("WEBSITE_AUTH_ENCRYPTION_KEY");
string hash = Convert.ToBase64String(sha.ComputeHash(Encoding.UTF8.GetBytes(envVar)));
return string.Equals(hash, headerValue, StringComparison.Ordinal);
}
Uwaga / Notatka
Nagłówek x-ms-auth-internal-token jest dostępny tylko w usłudze App Service dla systemu Windows.
Przypadki
Po włączeniu sprawdzania kondycji można ponownie uruchomić i monitorować stan wystąpień aplikacji na karcie wystąpień. Karta wystąpień zawiera nazwę wystąpienia i jego stan. Możesz również ręcznie wykonać zaawansowane ponowne uruchomienie aplikacji z tej karty za pomocą przycisku "Uruchom ponownie".
Jeśli stan wystąpienia aplikacji jest "niesprawny", możesz uruchomić ponownie proces roboczy odpowiedniej aplikacji ręcznie, używając przycisku restartu w tabeli. Nie będzie to mieć wpływu na żadną z innych aplikacji hostowanych w tym samym planie usługi App Service. Jeśli istnieją inne aplikacje korzystające z tego samego planu usługi App Service co wystąpienie, są one wyświetlane w oknie otwieranym z przyciskiem ponownego uruchamiania.
Jeśli uruchomisz ponownie wystąpienie, a proces ponownego uruchamiania zakończy się niepowodzeniem, otrzymasz możliwość zastąpienia pracownika. (Można wymienić tylko jedno wystąpienie na godzinę). Będzie to miało wpływ na wszystkie aplikacje korzystające z tego samego planu usługi App Service.
W przypadku aplikacji systemu Windows można również wyświetlać procesy za pośrednictwem Eksploratora procesów. Zapewnia to dalszy wgląd na temat procesów wystąpienia, w tym liczby wątków, pamięci prywatnej i łącznego czasu CPU.
Zbieranie informacji diagnostycznych
W przypadku aplikacji systemu Windows możesz zbierać informacje diagnostyczne na karcie Kontrola kondycji. Włączenie zbierania danych diagnostycznych dodaje regułę automatycznej naprawy, która tworzy zrzuty pamięci dla niesprawnych wystąpień i zapisuje je na wyznaczonym koncie magazynowym. Włączenie tej opcji powoduje zmianę konfiguracji automatycznego naprawiania. Jeśli istnieją reguły automatycznego uzdrawiania, zalecamy skonfigurować to przy użyciu diagnostyki usługi App Service.
Po włączeniu zbierania danych diagnostycznych możesz utworzyć konto składowania lub wybrać istniejące na potrzeby plików. Możesz wybrać tylko konta magazynu w tym samym regionie co aplikacja. Pamiętaj, że zapisywanie ponownie uruchamia aplikację. Po zapisaniu, jeśli wystąpienia witryny będą niedziałające prawidłowo po ciągłym pingowaniu, możesz przejść do zasobu konta magazynowego i wyświetlić zrzuty pamięci.
Nadzorowanie
Po podaniu ścieżki sprawdzania kondycji aplikacji możesz monitorować kondycję witryny przy użyciu usługi Azure Monitor. W bloku Sprawdzanie kondycji w portalu wybierz pozycję Metryki na górnym pasku narzędzi. Spowoduje to otwarcie nowego panelu, w którym można wyświetlić historię statusu sprawdzania kondycji witryny oraz utworzyć nową regułę alertu. Metryka monitorowania kondycji systemu agreguje udane odpowiedzi ping i wyświetla błędy tylko, gdy instancja została uznana za uszkodzoną na podstawie skonfigurowanej wartości progowej dla równoważenia obciążenia w monitorowaniu kondycji. Domyślnie ta wartość jest ustawiona na 10 minut, więc wykonanie 10 kolejnych poleceń ping (1 na minutę) dla danego wystąpienia zostanie uznane za niezdrowe, i dopiero wtedy będzie to odzwierciedlone w metryce. Aby uzyskać więcej informacji na temat monitorowania witryn, zobacz Limity przydziału i alerty usługi Azure App Service.
Ograniczenia
- Sprawdzanie kondycji można włączyć dla bezpłatnych i udostępnionych planów usługi App Service, dzięki czemu można mieć metryki dotyczące kondycji witryny i konfigurować alerty. Ponieważ witryny Free i Shared nie obsługują skalowania w poziomie, niesprawne instancje nie zostaną automatycznie zamienione. Należy przenieść się na poziom Podstawowy lub wyższy, aby można było skalować poziomo do dwóch lub więcej wystąpień i uzyskać pełne korzyści z funkcji 'Health check'. Jest to zalecane w przypadku aplikacji przeznaczonych dla środowiska produkcyjnego, ponieważ zwiększa dostępność i wydajność aplikacji.
- Plan usługi App Service może mieć maksymalnie jedno niesprawne wystąpienie zastąpione na godzinę i co najwyżej trzy wystąpienia dziennie.
- Istnieje niekonfigurowalny limit całkowitej liczby wystąpień zastąpionych przez kontrolę kondycji na jednostkę skalowania. Jeśli ten limit zostanie osiągnięty, nie zostaną zastąpione żadne niezdrowe instancje. Ta wartość jest resetowana co 12 godzin.
Najczęściej zadawane pytania
Co się stanie, jeśli moja aplikacja jest uruchomiona w jednym wystąpieniu?
Jeśli aplikacja jest skalowana tylko do jednego wystąpienia i przestaje działać prawidłowo, nie zostanie usunięta z load balancera, ponieważ doprowadziłoby to do całkowitego przestoju aplikacji. Jednak po upływie jednej godziny ciągłych niezdrowych pingów instancja zostanie zastąpiona. Skalowanie w poziomie do co najmniej dwóch wystąpień w celu uzyskania korzyści z przekierowania kontroli kondycji. Jeśli aplikacja jest uruchomiona w jednym wystąpieniu, nadal możesz użyć funkcji monitorowania kontroli kondycji, aby śledzić kondycję aplikacji.
Dlaczego żądania sprawdzania kondycji nie są wyświetlane w dziennikach serwera internetowego?
Żądania kontroli kondycji są wysyłane wewnętrznie do witryny, więc żądanie nie będzie wyświetlane w dziennikach serwera internetowego. Możesz dodać logi w swoim kodzie kontroli zdrowia, aby zapisywać, kiedy do ścieżki kontroli zdrowia wysyłane jest polecenie ping.
Czy żądania kontroli kondycji są wysyłane za pośrednictwem protokołu HTTP lub HTTPS?
W usłudze App Service dla systemów Windows i Linux żądania sprawdzania kondycji są wysyłane za pośrednictwem protokołu HTTPS, gdy w witrynie jest włączony tylko protokół HTTPS . W przeciwnym razie są one wysyłane za pośrednictwem protokołu HTTP.
Czy kontrola kondycji podąża za przekierowaniami skonfigurowanymi w kodzie aplikacji między domeną domyślną a domeną niestandardową?
Nie, funkcja sprawdzania kondycji wysyła polecenie ping do ścieżki domyślnej domeny aplikacji internetowej. Jeśli istnieje przekierowanie z domeny domyślnej do domeny niestandardowej, kod stanu zwracany przez sprawdzanie kondycji nie będzie 200. Będzie to przekierowanie (301), które oznacza złą kondycję procesu roboczego.
Co zrobić, jeśli mam wiele aplikacji w tym samym planie usługi App Service?
Niezdrowe instancje będą zawsze usuwane z rotacji równoważenia obciążenia niezależnie od innych aplikacji w planie usługi App Service (do wartości procentowej określonej w elemencie WEBSITE_HEALTHCHECK_MAXUNHEALTHYWORKERPERCENT). Jeśli aplikacja w wystąpieniu pozostaje w złej kondycji przez więcej niż godzinę, wystąpienie zostanie zastąpione tylko wtedy, gdy wszystkie inne aplikacje, dla których włączono kontrolę kondycji, również będą w złej kondycji. Aplikacje, które nie mają włączonej kontroli kondycji, nie będą uwzględniane.
Przykład
Załóżmy, że masz dwie aplikacje (lub jedną aplikację ze slotem) z włączonym monitoringiem zdrowia. Nazywają się App A i App B. Znajdują się w tym samym planie usługi App Service, a plan jest skalowany w poziomie do czterech wystąpień. Jeśli aplikacja A stanie się w złej kondycji w dwóch wystąpieniach, moduł równoważenia obciążenia przestanie wysyłać żądania do aplikacji A w tych dwóch wystąpieniach. Żądania są nadal kierowane do aplikacji B w tych wystąpieniach, przy założeniu, że aplikacja B jest w dobrej kondycji. Jeśli aplikacja A pozostaje niesprawna przez ponad godzinę w tych dwóch przypadkach, przypadki są zastępowane tylko wtedy, gdy aplikacja B jest również niesprawna w tych przypadkach. Jeśli aplikacja B jest w dobrej kondycji, wystąpienia nie są zastępowane.
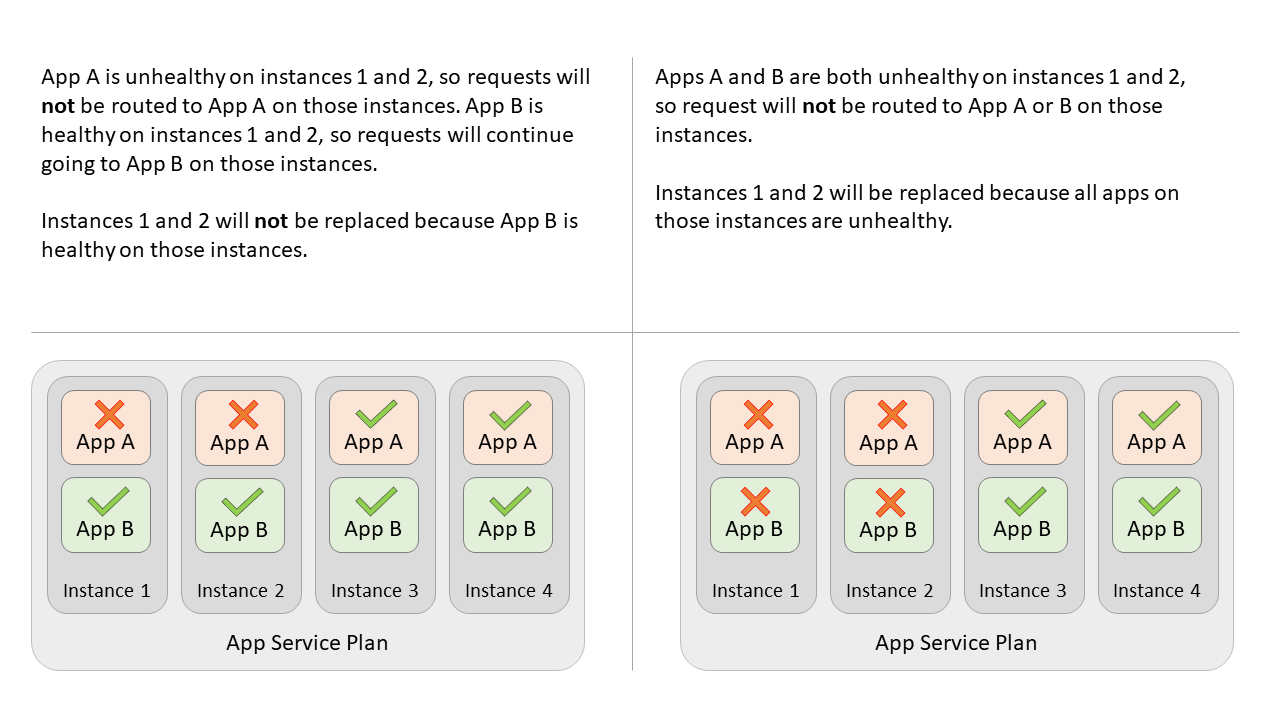
Uwaga / Notatka
Jeśli na innym miejscu lub slocie w planie (App C) nie włączono sprawdzania kondycji, nie będzie brany pod uwagę przy zamianie instancji.
Co zrobić, jeśli wszystkie moje wystąpienia są niezdrowe?
Jeśli wszystkie wystąpienia aplikacji są niedziałające prawidłowo, usługa App Service nie usunie wystąpień z systemu równoważenia obciążenia. W tym scenariuszu usunięcie wszystkich niezdrowych wystąpień aplikacji z rotacji równoważnika obciążenia spowodowałoby awarię aplikacji. Jednak zastąpienie wystąpienia nadal nastąpi.
Co się dzieje podczas zamiany miejsca?
Konfiguracja kontroli kondycji nie jest specyficzna dla miejsca, więc po zamianie konfiguracja kontroli kondycji zamienionego miejsca zostanie zastosowana do miejsca docelowego i na odwrót. Jeśli na przykład włączono kontrolę kondycji dla miejsca przejściowego, skonfigurowany punkt końcowy zostanie zastosowany do miejsca produkcyjnego po zamianie. Zalecamy używanie spójnej konfiguracji dla miejsc produkcyjnych i nieprodukcyjnych, jeśli jest to możliwe, aby zapobiec nieoczekiwanemu zachowaniu po zamianie.
Czy kontrola zdrowia działa w App Service Environment?
Tak, sprawdzanie kondycji jest dostępne dla środowiska App Service Environment w wersji 3.
Dalsze kroki
- Utwórz alert dziennika aktywności, aby monitorować wszystkie operacje mechanizmu autoskalowania w ramach subskrypcji
- Utwórz alert dziennika aktywności, aby monitorować wszystkie nieudane operacje automatycznego skalowania w górę/w dół w ramach subskrypcji
- Referencja zmiennych środowiskowych i ustawień aplikacji