Extraneous Fetching antipattern (Antywzorzec dotyczący nadmiarowego pobierania)
Wzorce antywłaszowe są typowymi wadami projektowymi, które mogą uszkodzić oprogramowanie lub aplikacje w sytuacjach stresu i nie powinny być pomijane. W nadmiarowym pobieraniu antywzorzec pobieranych jest więcej niż potrzebne dane dla operacji biznesowej, co często powoduje niepotrzebne obciążenie we/wy i zmniejszoną szybkość reakcji.
Przykłady nadmiarowego pobierania antywzorzec
Ten antywzorzec może wystąpić, jeśli aplikacja próbuje zminimalizować żądania we/wy, pobierając wszystkie dane,których może potrzebować. Często jest to wynikiem nadmiernej kompensacji antywzorca dużej liczby operacji we/wy. Na przykład aplikacja może pobrać szczegółowe informacje dla każdego produktu w bazie danych. Jednak użytkownik może potrzebować tylko ich podzestawu (niektóre mogą nie być odpowiednie dla klientów) i prawdopodobnie nie potrzebuje wyświetlić wszystkich produktów naraz. Nawet jeśli użytkownik przegląda cały wykaz, warto stronicować wyniki — na przykład wyświetlając 20 naraz.
Innym źródłem tego problemu jest niska jakość praktycznych zasad programowania lub projektowania. Na przykład następujący kod używa programu Entity Framework do pobierania wszystkich informacji dotyczących każdego produktu. Następnie filtruje on wyniki, aby zwrócić tylko podzestaw pól, odrzucając pozostałe. Pełny przykład można znaleźć tutaj.
public async Task<IHttpActionResult> GetAllFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Execute the query. This happens at the database.
var products = await context.Products.ToListAsync();
// Project fields from the query results. This happens in application memory.
var result = products.Select(p => new ProductInfo { Id = p.ProductId, Name = p.Name });
return Ok(result);
}
}
W następnym przykładzie aplikacja pobiera dane do wykonania agregacji, która zamiast tego może zostać wykonana przez bazę danych. Aplikacja oblicza łączną sprzedaż, pobierając każdy rekord dla wszystkich sprzedanych zamówień, a następnie obliczając sumę tych rekordów. Pełny przykład można znaleźć tutaj.
public async Task<IHttpActionResult> AggregateOnClientAsync()
{
using (var context = new AdventureWorksContext())
{
// Fetch all order totals from the database.
var orderAmounts = await context.SalesOrderHeaders.Select(soh => soh.TotalDue).ToListAsync();
// Sum the order totals in memory.
var total = orderAmounts.Sum();
return Ok(total);
}
}
W kolejnym przykładzie pokazano drobny problem powodowany przez sposób używania składnika LINQ to Entities przez program Entity Framework.
var query = from p in context.Products.AsEnumerable()
where p.SellStartDate < DateTime.Now.AddDays(-7) // AddDays cannot be mapped by LINQ to Entities
select ...;
List<Product> products = query.ToList();
Aplikacja próbuje odnaleźć produkty mające SellStartDate starsze niż tydzień. W większości przypadków składnik LINQ to Entities przetłumaczy klauzulę where na instrukcję SQL, która jest wykonywana przez bazę danych. Jednak w takim przypadku składnik LINQ to Entities nie może zmapować metody AddDays na język SQL. Zamiast tego jest zwracany każdy wiersz tabeli Product, a wyniki są filtrowane w pamięci.
Wywołanie AsEnumerable jest wskazówką, że występuje problem. Ta metoda konwertuje wyniki do interfejsu IEnumerable. Chociaż IEnumerable obsługuje filtrowanie, odbywa się ono po stronie klienta, a nie bazy danych. Domyślnie składnik LINQ to Entities używa IQueryable, które przekazuje odpowiedzialność za filtrowanie do źródła danych.
Jak naprawić nadmiarowe pobieranie antywzorzec
Unikaj pobierania dużych ilości danych, które mogą szybko stać się nieaktualne lub mogą zostać odrzucone, a pobieraj tylko dane niezbędne dla wykonywanej operacji.
Zamiast pobierać każdą kolumnę z tabeli, a następnie filtrować je, wybierz potrzebne kolumny z bazy danych.
public async Task<IHttpActionResult> GetRequiredFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Project fields as part of the query itself
var result = await context.Products
.Select(p => new ProductInfo {Id = p.ProductId, Name = p.Name})
.ToListAsync();
return Ok(result);
}
}
Analogicznie agregację wykonaj w bazie danych, a nie w pamięci aplikacji.
public async Task<IHttpActionResult> AggregateOnDatabaseAsync()
{
using (var context = new AdventureWorksContext())
{
// Sum the order totals as part of the database query.
var total = await context.SalesOrderHeaders.SumAsync(soh => soh.TotalDue);
return Ok(total);
}
}
W przypadku korzystania z platformy Entity Framework upewnij się, że zapytania LINQ są rozwiązywane przy użyciu interfejsu IQueryable , a nie IEnumerable. Może być konieczne dostosowanie zapytania do użycia tylko funkcji, które mogą być mapowane na źródło danych. Wcześniejszy przykład może być refaktoryzowany w celu usunięcia metody AddDays z zapytania, co pozwoli na wykonanie filtrowania przez bazę danych.
DateTime dateSince = DateTime.Now.AddDays(-7); // AddDays has been factored out.
var query = from p in context.Products
where p.SellStartDate < dateSince // This criterion can be passed to the database by LINQ to Entities
select ...;
List<Product> products = query.ToList();
Kwestie wymagające rozważenia
W niektórych przypadkach możesz poprawić wydajność, partycjonując dane w poziomie. Jeśli różne operacje uzyskują dostęp do różnych atrybutów danych, partycjonowanie poziome może zmniejszyć rywalizację. Często większość operacji jest uruchamiana dla małego podzestawu danych, dzięki czemu rozproszenie tego obciążenia może zwiększyć wydajność. Zobacz Partycjonowanie danych.
Dla operacji, które mają obsługiwać niepowiązane zapytania, należy wdrożyć stronicowanie i pobierać tylko ograniczoną liczbę jednostek naraz. Na przykład, jeśli klient przegląda katalog produktów, możesz wyświetlać po jednej stronie wyników naraz.
Jeśli to możliwe korzystaj z funkcji wbudowanych w magazyn danych. Na przykład bazy danych SQL zwykle zapewniają funkcje agregacji.
Jeśli używasz magazynu danych, który nie obsługuje określonej funkcji, takiej jak agregacja, możesz przechować obliczony wynik w innym miejscu, aktualizując wartości w miarę dodawania lub aktualizowania rekordów, dzięki czemu aplikacja nie musi przeliczać wartości za każdym razem, gdy jest to potrzebne.
Jeśli zobaczysz, że żądania pobierają dużą liczbę pól, zbadaj kod źródłowy w celu ustalenia, czy wszystkie te pola są niezbędne. Czasami te żądania są wynikiem słabo zaprojektowanego zapytania
SELECT *.Analogicznie, żądania, które pobierają dużą liczbę jednostek, mogą być znakiem, że aplikacja nie filtruje danych poprawnie. Sprawdź, czy wszystkie te jednostki są potrzebne. Jeśli to możliwe, użyj filtrowania po stronie bazy danych, używając na przykład klauzul
WHEREjęzyka SQL.Odciążanie przetwarzania do bazy danych nie zawsze jest najlepszym rozwiązaniem. Tej strategii należy używać tylko, gdy baza danych została zaprojektowana lub zoptymalizowana w tym celu. Większość systemów baz danych jest w dużym stopniu zoptymalizowana dla niektórych funkcji, ale systemy te nie są zaprojektowane do działania jako ogólnego przeznaczenia aparaty aplikacji. Aby uzyskać więcej informacji, zobacz Antywzorzec zajętej bazy danych.
Jak wykryć nadmiarowe pobieranie antywzorzec
Objawy nadmiarowego pobierania to duże opóźnienie i niska przepływność. Jeśli dane są pobierane z magazynu danych, zwiększona rywalizacja jest również prawdopodobna. Użytkownicy końcowi mogą zgłaszać rozszerzone czasy odpowiedzi lub błędy spowodowane przekroczeniem limitu czasu usług. Te błędy mogą zwracać błędy HTTP 500 (wewnętrzny serwer) lub HTTP 503 (usługa niedostępna). Sprawdź dzienniki zdarzeń serwera internetowego, które najprawdopodobniej zawierają bardziej szczegółowe informacje dotyczące przyczyn i okoliczności błędów.
Objawy tego antywzorca i części uzyskanej telemetrii mogą być bardzo podobne do występujących dla Antywzorzec monolitycznej trwałości.
Możesz wykonać następujące kroki, aby ułatwić zidentyfikowanie przyczyny:
- Określ wolne obciążenia lub transakcje, wykorzystując testy obciążenia, monitorowanie procesu i inne metody przechwytywania danych instrumentacji.
- Sprawdź wszystkie wzorce zachowania ujawnione przez system. Czy istnieją określone ograniczenia dotyczące transakcji na sekundę lub liczby użytkowników?
- Skoreluj wystąpienia powolnych obciążeń ze wzorcami zachowania.
- Zidentyfikuj używane magazyny danych. Dla każdego źródła danych uruchom telemetrię niskiego poziomu, aby przyjrzeć się zachowaniu operacji.
- Zidentyfikuj wszelkie wolno działające zapytania zawierające odwołania do tych źródeł danych.
- Przeprowadź specjalną analizę zasobów dla wolno działających zapytań i upewnij się, jak dane są używane i zużywane.
Poszukaj dowolnych z tych objawów:
- Częste, duże żądania we/wy wykonywane do tego samego zasobu lub magazynu danych.
- Rywalizacja w udostępnianym zasobie lub magazynie danych.
- Operacja, która często odbiera duże ilości danych przez sieć.
- Aplikacje i usługi tracące znaczną ilość czasu na oczekiwaniu na zakończenie operacji we/wy.
Przykładowa diagnostyka
Poniższe sekcje stosują te kroki do poprzednich przykładów.
Identyfikowanie powolnych obciążeń
Ten wykres pokazuje wyniki wydajności dla testu obciążenia, który symulował maksymalnie 400 równoczesnych użytkowników z uruchomioną, pokazaną wcześniej metodą GetAllFieldsAsync. Przepływność zmniejsza się powoli w miarę wzrostu obciążenia. Średni czas odpowiedzi rośnie w miarę wzrostu obciążenia.
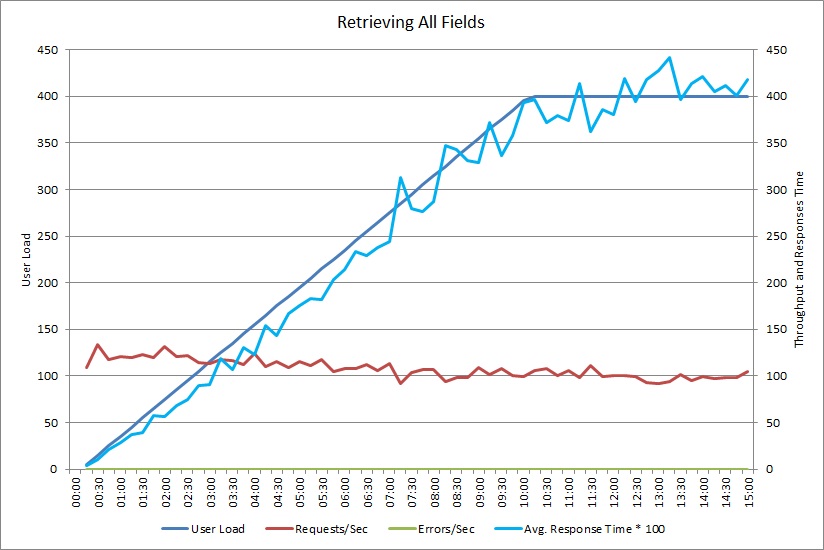
Test obciążenia dla operacji AggregateOnClientAsync również daje podobny wzorzec. Liczba żądań jest w uzasadniony sposób stabilna. Średni czas odpowiedzi zwiększa się wraz z obciążeniem, chociaż wolniej niż na poprzednim wykresie.
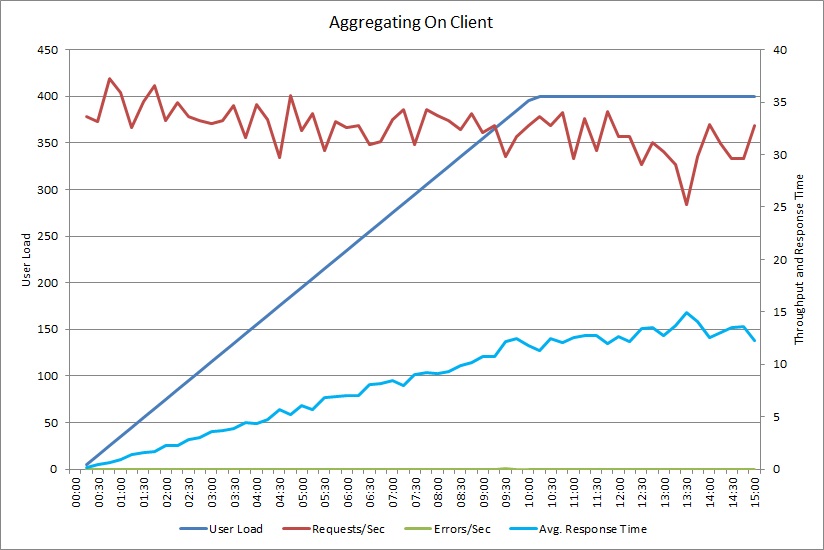
Korelowanie powolnych obciążeń ze wzorcami zachowania
Wszelka korelacja między regularnymi okresami wysokiego użycia i spowolnienia wydajności mogą wskazywać obszary zainteresowania. Dokładnie sprawdź profil wydajności funkcji, które są podejrzane o powolne działanie, aby określić, czy jest zgodny z wcześniej wykonanymi testami obciążenia.
Przeprowadź test obciążenia tych samych funkcji przy użyciu krokowych obciążeń użytkownika, aby odnaleźć punkt, w którym wydajności znacznie spada lub całkowicie zanika. Jeśli ten punkt mieści się w granicach oczekiwanego użycia w świecie rzeczywistym, sprawdź, jak te funkcje są zaimplementowane.
Wolne działanie nie musi być problemem, jeśli nie odbywa się to, gdy system jest poddawany przeciążeniu, nie jest krytyczne czasowo i nie wpływa negatywnie na wydajność innych ważnych operacji. Na przykład generowanie miesięcznych statystyk operacyjnych może być długotrwałym procesem, ale prawdopodobnie może zostać wykonane jako proces wsadowy i uruchomione jako zadanie o niskim priorytecie. Z drugiej strony klienci wysyłający zapytania do katalogu produktów stanowią operację o krytycznym znaczeniu dla firmy. Skoncentruj się na telemetrii wygenerowanej przez te krytyczne operacje, aby zobaczyć, jak wydajność zmienia się w okresach wysokiego użycia.
Identyfikowanie źródeł danych w powolnych obciążeniach
Jeśli podejrzewasz, że usługa źle działa ze względu na sposób, w jaki pobiera dane, zbadaj, jak aplikacja wchodzi w interakcje z używanymi repozytoriami. Monitoruj system na żywo, aby zobaczyć, które źródła są dostępne w okresach pogorszenia wydajności.
Dla każdego źródła danych przygotuj instrumentację systemu, aby przechwycić następujące informacje:
- Częstotliwość, z którą następuje dostęp do każdego magazynu danych.
- Ilość danych wprowadzanych i wyprowadzanych z magazynu danych.
- Synchronizację tych operacji, szczególnie opóźnienia żądań.
- Rodzaj i częstotliwość błędów występujących podczas uzyskiwania dostępu do poszczególnych magazynów danych dla typowego obciążenia.
Porównaj te informacje z ilością danych zwracanych przez aplikację klientowi. Śledź stosunek ilości danych zwróconych przez magazyn danych do ilości danych zwracanych klientowi. W przypadku dużych różnic, sprawdź, aby określić, czy aplikacja pobiera dane, których nie potrzebuje.
Może być możliwe przechwycenie tych danych dzięki obserwacji systemu na żywo i śledzeniu cyklu życia każdego żądania użytkownika, lub możesz modelować szereg syntetycznych obciążeń i uruchomić je w systemie testowym.
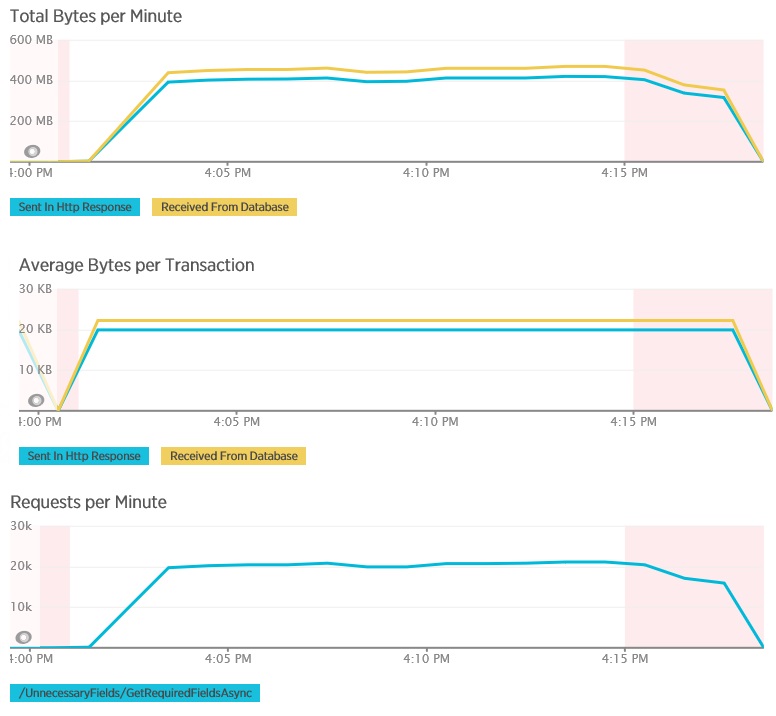
Poniższe wykresy pokazują telemetrię przechwyconą za pomocą usługi New Relic APM podczas testu obciążeniowego metody GetAllFieldsAsync. Należy zanotować różnicę między ilościami danych odebranych z bazy danych a odpowiednimi odpowiedziami protokołu HTTP.
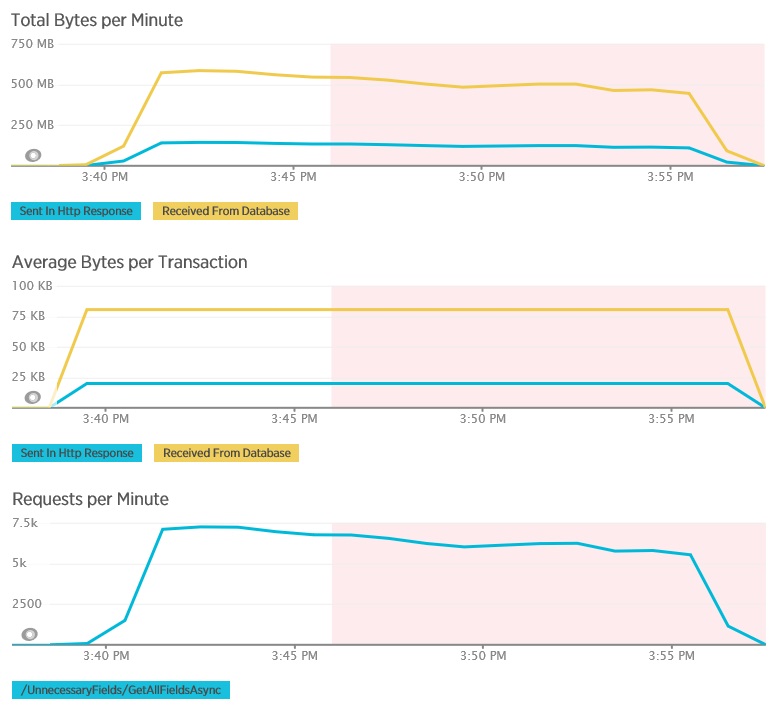
Dla każdego żądania baza danych zwróciła 80 503 bajty, ale odpowiedź do klienta zawierała tylko 19 855 bajtów, czyli około 25% rozmiaru odpowiedzi bazy danych. Rozmiar danych zwracanych klientowi może zależeć od formatu. Dla tego testu obciążenia klient zażądał danych JSON. Oddzielne testowanie z użyciem języka XML (nie pokazane) wykazało rozmiar odpowiedzi równy 35 655 bajtów lub 44% rozmiaru odpowiedzi bazy danych.
Test obciążenia dla metody AggregateOnClientAsync zawiera więcej ekstremalnych wyników. W tym przypadku każdy test wykonał zapytanie, które pobrało ponad 280 KB danych z bazy danych, ale odpowiedź w formacie JSON to zaledwie 14 B. Taka duża rozbieżność wynika z tego, że metoda oblicza zagregowany wynik na podstawie dużej ilości danych.
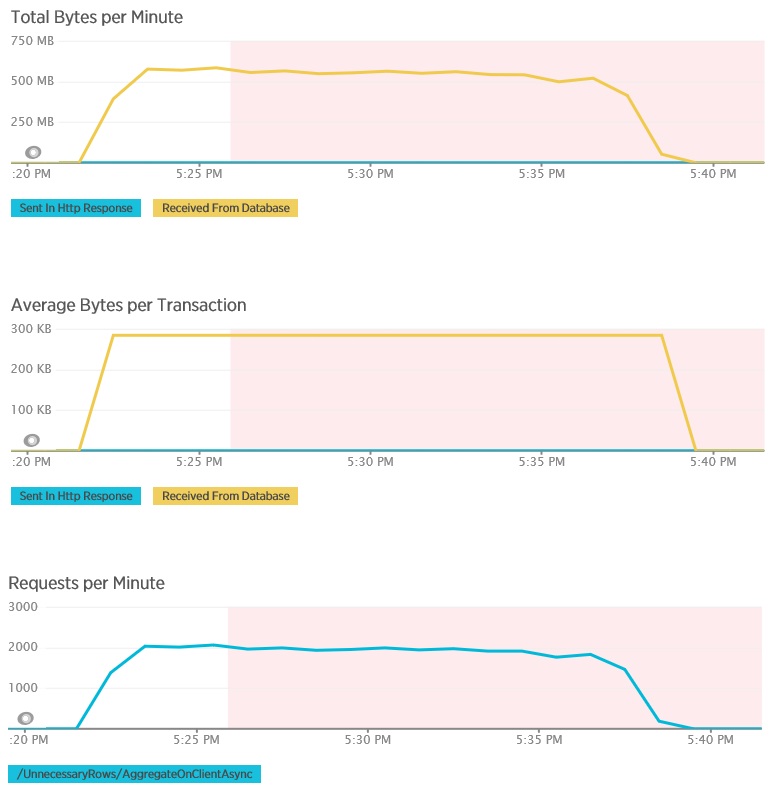
Identyfikacja i analiza powolnych zapytań
Poszukaj zapytań bazy danych, które zużywają najwięcej zasobów i których wykonanie zajmuje najwięcej czasu. Możesz dodać instrumentację, aby odnaleźć czasy rozpoczęcia i zakończenia wielu operacji bazy danych. Wiele magazynów danych udostępnia również szczegółowe informacje dotyczące sposobu wykonywania i optymalizowania zapytań. Na przykład w okienku wyników zapytania w portalu zarządzania bazy danych Azure SQL Database możesz wybrać zapytanie i wyświetlić informacje o wydajności w środowisku uruchomieniowym. Oto zapytanie wygenerowane przez operację GetAllFieldsAsync:
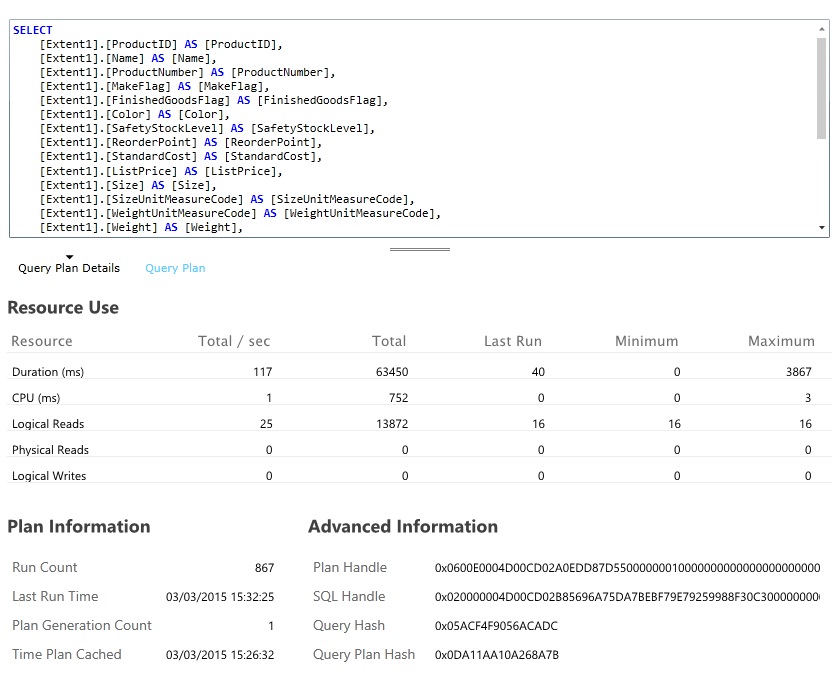
Implementowanie rozwiązania i weryfikowanie wyniku
Po zmianie metody GetRequiredFieldsAsync, aby użyć instrukcji SELECT po stronie bazy danych, testy obciążenia wykazały następujące wyniki.
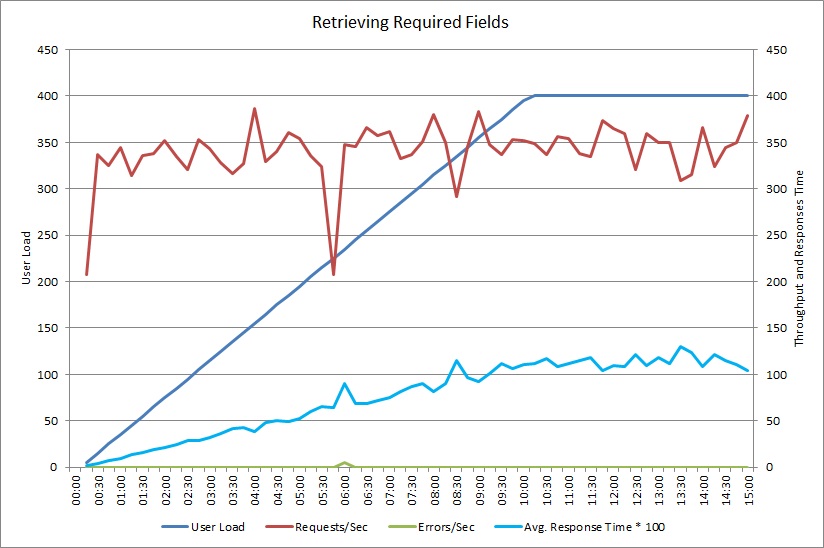
Ten test obciążenia używał tego samego wdrożenia i tego samego symulowanego obciążenia odpowiadającego 400 równoczesnym użytkownikom jak przedtem. Na wykresie widać znacznie mniejsze opóźnienie. Czas odpowiedzi wzrasta z obciążeniem do około 1,3 sekundy w porównaniu do 4 sekund w poprzednim przypadku. Przepływność jest również większa dla 350 żądań na sekundę w porównaniu do 100 wcześniej. Ilość pobieranych z bazy danych teraz ściśle odpowiada rozmiarowi komunikatów odpowiedzi HTTP.
Testy obciążenia przy użyciu metody AggregateOnDatabaseAsync generują następujące wyniki:
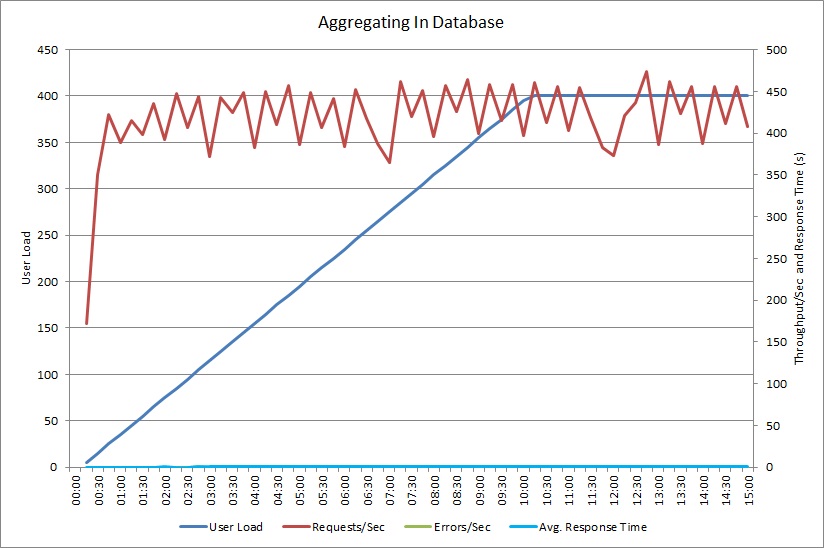
Średni czas odpowiedzi jest teraz minimalny. Jest to poprawa wydajności o rząd wielkości spowodowana przede wszystkim dużym skróceniem operacji we/wy z bazy danych.
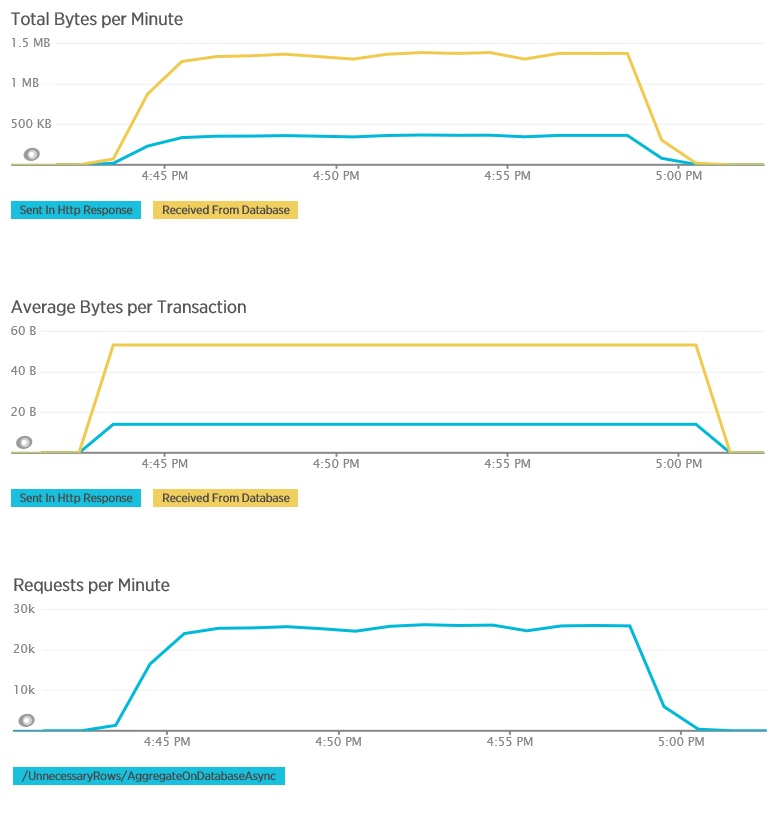
Oto odpowiednie dane telemetryczne dotyczące metody AggregateOnDatabaseAsync. Ilość danych pobranych z bazy danych została znacznie zredukowana — z ponad 280 KB na transakcję do 53 B. W wyniku tego maksymalna utrzymywana liczba żądań na minutę wzrosła z około 2000 do ponad 25 000.
Powiązane zasoby
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla