Wskazówki dotyczące partycjonowania danych
W wielu rozwiązaniach na dużą skalę dane są podzielone na partycje , które można zarządzać i uzyskiwać do ich dostępu oddzielnie. Partycjonowanie może zwiększyć skalowalność, zmniejszyć stopień rywalizacji o zasoby i zoptymalizować wydajność. Może także zapewnić mechanizm dzielenia danych według wzorca użycia. Na przykład starsze dane można zarchiwizować w tańszym magazynie danych.
Jednak strategia partycjonowania musi być starannie wybrana, aby zmaksymalizować korzyści przy jednoczesnym zminimalizowaniu negatywnych skutków.
Uwaga / Notatka
W tym artykule termin partycjonowanie oznacza proces fizycznego dzielenia danych na oddzielne repozytoria danych. Nie jest to samo, co partycjonowanie tabel programu SQL Server.
Dlaczego warto podzielić dane na partycje?
Zwiększ skalowalność. W przypadku skalowania w górę pojedynczego systemu bazy danych ostatecznie osiągnie limit sprzętu fizycznego. W przypadku dzielenia danych między wiele partycji, z których każda jest hostowana na osobnym serwerze, można skalować system niemal w nieskończoność.
Zwiększ wydajność. Operacje dostępu do danych na każdej partycji są wykonywane na mniejszej ilości danych. Poprawnie wykonane partycjonowanie może zwiększyć wydajność systemu. Operacje, które mają wpływ na więcej niż jedną partycję, mogą być uruchamiane równolegle.
Zwiększ bezpieczeństwo. W niektórych przypadkach można oddzielić poufne i niewrażliwe dane na różne partycje i zastosować różne mechanizmy kontroli zabezpieczeń do poufnych danych.
Zapewnienie elastyczności operacyjnej. Partycjonowanie oferuje wiele możliwości dostrajania operacji, maksymalizację wydajności administracyjnej i minimalizację kosztów. Można na przykład zdefiniować różne strategie zarządzania, monitorowania, tworzenia kopii zapasowych i przywracania oraz innych zadań administracyjnych na podstawie znaczenia danych w każdej partycji.
Dopasuj magazyn danych do wzorca użycia. Partycjonowanie umożliwia wdrożenie każdej partycji w innym typie magazynu danych na podstawie kosztów i wbudowanych funkcji oferowanych przez magazyn danych. Na przykład duże dane binarne mogą być przechowywane w magazynie obiektów blob, podczas gdy bardziej ustrukturyzowane dane mogą być przechowywane w bazie danych dokumentów. Aby uzyskać więcej informacji, zobacz Wybieranie odpowiedniego magazynu danych.
Zwiększ dostępność. Oddzielenie danych między wieloma serwerami pozwala uniknąć pojedynczego punktu awarii. Jeśli jedno wystąpienie nie powiedzie się, tylko dane w tej partycji są niedostępne. Operacje na innych partycjach mogą być kontynuowane. W przypadku magazynów danych platformy zarządzanej jako usługi (PaaS) jest to mniej istotne, ponieważ te usługi są zaprojektowane z wbudowaną nadmiarowością.
Projektowanie partycji
Istnieją trzy typowe strategie partycjonowania danych:
Partycjonowanie poziome (często nazywane shardingiem). W tej strategii każda partycja jest oddzielnym magazynem danych, ale wszystkie partycje mają ten sam schemat. Każda partycja jest nazywana fragmentem i przechowuje określony podzestaw danych, na przykład wszystkie zamówienia dla określonego zestawu klientów.
Partycjonowanie pionowe. W tej strategii każda partycja zawiera podzestaw pól dla elementów w magazynie danych. Pola są podzielone zgodnie z ich wzorcem użycia. Na przykład często używane pola mogą być umieszczane w jednej partycji pionowej i rzadziej używane pola w innym.
Partycjonowanie funkcjonalne. W tej strategii dane są agregowane zgodnie ze sposobem ich użycia przez każdy ograniczony kontekst w systemie. Na przykład system handlu elektronicznego może przechowywać dane faktur w jednej partycji i danych spisu produktów w innym.
Te strategie można połączyć i zalecamy rozważenie ich wszystkich podczas projektowania schematu partycjonowania. Możesz na przykład podzielić dane na fragmenty, a następnie użyć partycjonowania pionowego, aby dalej podzielić dane w poszczególnych fragmentach.
Partycjonowanie poziome (fragmentowanie)
Rysunek 1 przedstawia partycjonowanie poziome lub dzielenie na fragmenty. W tym przykładzie dane spisu produktów są podzielone na fragmenty na podstawie klucza produktu. Każdy fragment przechowuje dane dla ciągłego zakresu kluczy (A-G i H-Z), uporządkowane alfabetycznie. Fragmentowanie rozkłada obciążenie większej liczby komputerów, co zmniejsza rywalizację i poprawia wydajność.
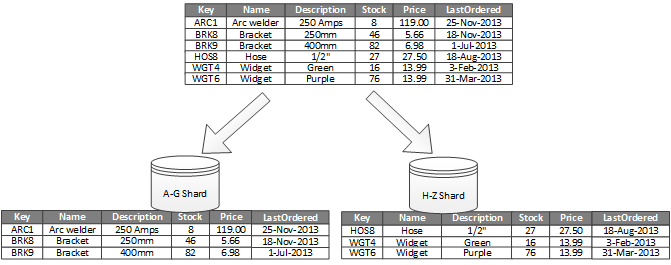
Rysunek 1. Partycjonowanie w poziomie (dzielenie na fragmenty) danych na podstawie klucza partycji.
Najważniejszym czynnikiem jest wybór klucza fragmentowania. Zmiana klucza po uruchomieniu systemu może być trudna. Klucz musi zapewnić partycjonowanie danych w celu równomiernego rozłożenia obciążenia na fragmenty.
Fragmenty nie muszą mieć tego samego rozmiaru. Ważniejsze jest zrównoważenie liczby żądań. Niektóre fragmenty mogą być bardzo duże, ale każdy element ma niewielką liczbę operacji dostępu. Inne fragmenty mogą być mniejsze, ale każdy element jest uzyskiwany znacznie częściej. Ważne jest również zapewnienie, że pojedynczy fragment nie przekracza limitów skalowania (w zakresie pojemności i zasobów przetwarzania) magazynu danych.
Unikaj tworzenia "gorących" partycji, które mogą mieć wpływ na wydajność i dostępność. Na przykład użycie pierwszej litery nazwy klienta powoduje rozkład niezrównoważony, ponieważ niektóre litery są częściej spotykane. Zamiast tego użyj skrótu identyfikatora klienta, aby równomiernie dystrybuować dane między partycjami.
Wybierz klucz fragmentowania, który minimalizuje wszelkie przyszłe wymagania dotyczące dzielenia dużych fragmentów, łączenia małych fragmentów na większe partycje lub zmiany schematu. Te operacje mogą być bardzo czasochłonne i mogą wymagać przełącznia jednego lub większej liczby fragmentów w tryb offline podczas ich wykonywania.
Jeśli fragmenty są replikowane, może być możliwe zachowanie niektórych replik w trybie online, podczas gdy inne są podzielone, scalone lub ponownie skonfigurowane. Jednak system może wymagać ograniczenia operacji, które można wykonać podczas ponownej konfiguracji. Na przykład dane w replikach mogą być oznaczone jako tylko do odczytu, aby zapobiec niespójnościom danych.
Aby uzyskać więcej informacji na temat partycjonowania poziomego, zobacz Wzorzec fragmentowania.
Partycjonowanie pionowe
Najczęstszym zastosowaniem partycjonowania pionowego jest zmniejszenie kosztów operacji we/wy i wydajności związanych z pobieraniem elementów, do których często uzyskuje się dostęp. Rysunek 2 przedstawia przykład partycjonowania pionowego. W tym przykładzie różne właściwości elementu są przechowywane w różnych partycjach. Jedna partycja przechowuje dane, do których uzyskuje się dostęp częściej, w tym nazwę produktu, opis i cenę. Inna partycja przechowuje dane spisu: liczbę akcji i datę ostatniego zamówienia.
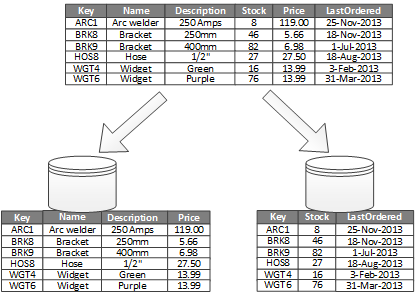
Rysunek 2. Partycjonowanie w pionie danych według wzorca użycia.
W tym przykładzie aplikacja regularnie wykonuje zapytania dotyczące nazwy produktu, opisu i ceny podczas wyświetlania szczegółów produktu klientom. Liczba zapasów i data ostatniego zamówienia są przechowywane w oddzielnej partycji, ponieważ te dwa elementy są często używane razem.
Inne zalety partycjonowania pionowego:
Stosunkowo wolno poruszające się dane (nazwa produktu, opis i cena) mogą być oddzielone od bardziej dynamicznych danych (poziom zapasów i data ostatniego zamówienia). Powolne przenoszenie danych jest dobrym kandydatem do buforowania w pamięci przez aplikację.
Poufne dane mogą być przechowywane w oddzielnej partycji z dodatkowymi mechanizmami kontroli zabezpieczeń.
Partycjonowanie pionowe może zmniejszyć ilość wymaganego dostępu współbieżnego.
Partycjonowanie pionowe działa na poziomie jednostki w magazynie danych, częściowo normalizując jednostkę w celu podzielenia jej z szerokiego elementu na zestaw elementów wąskich. Idealnie nadaje się do magazynów danych zorientowanych na kolumny, takich jak HBase i Cassandra. Jeśli dane w kolekcji kolumn nie zmienią się, możesz również rozważyć użycie magazynów kolumn w programie SQL Server.
Partycjonowanie funkcjonalne
Gdy możliwe jest zidentyfikowanie ograniczonego kontekstu dla każdego odrębnego obszaru biznesowego w aplikacji, partycjonowanie funkcjonalne to sposób na poprawę wydajności izolacji i dostępu do danych. Innym typowym zastosowaniem partycjonowania funkcjonalnego jest oddzielenie danych odczytu i zapisu od danych tylko do odczytu. Rysunek 3 przedstawia omówienie partycjonowania funkcjonalnego, w którym dane spisu są oddzielone od danych klientów.
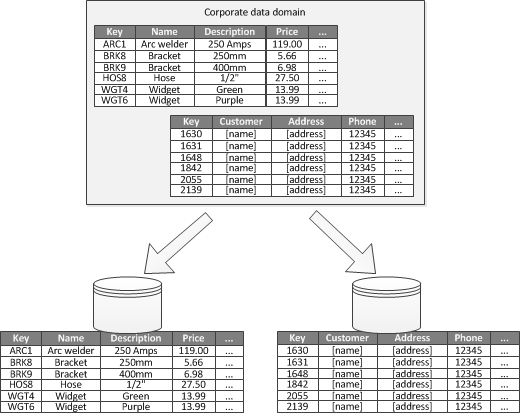
Rysunek 3. Partycjonowanie danych funkcjonalnie według powiązanego kontekstu lub poddomeny.
Ta strategia partycjonowania może pomóc zmniejszyć rywalizację o dostęp do danych w różnych częściach systemu.
Projektowanie partycji pod kątem skalowalności
Ważne jest, aby wziąć pod uwagę rozmiar i obciążenie dla każdej partycji i zrównoważyć je, aby dane były dystrybuowane w celu osiągnięcia maksymalnej skalowalności. Należy jednak również podzielić dane na partycje, aby nie przekraczały limitów skalowania pojedynczego magazynu partycji.
Wykonaj następujące kroki podczas projektowania partycji pod kątem skalowalności:
- Przeanalizuj aplikację, aby poznać wzorce dostępu do danych, takie jak rozmiar zestawu wyników zwracanego przez każde zapytanie, częstotliwość dostępu, nieodłączne opóźnienie i wymagania dotyczące przetwarzania obliczeniowego po stronie serwera. W wielu przypadkach kilka głównych jednostek będzie wymagać większości zasobów przetwarzania.
- Ta analiza służy do określania bieżących i przyszłych celów skalowalności, takich jak rozmiar danych i obciążenie. Następnie rozłóż dane między partycje, aby spełnić cel skalowalności. W przypadku partycjonowania poziomego wybranie odpowiedniego klucza fragmentu jest ważne, aby upewnić się, że dystrybucja jest równomierna. Aby uzyskać więcej informacji, zobacz wzorzec fragmentowania.
- Upewnij się, że każda partycja ma wystarczającą ilość zasobów do obsługi wymagań dotyczących skalowalności pod względem rozmiaru danych i przepływności. W zależności od magazynu danych może istnieć limit ilości miejsca do magazynowania, mocy obliczeniowej lub przepustowości sieci na partycję. Jeśli wymagania prawdopodobnie przekroczą te limity, może być konieczne uściślinie strategii partycjonowania lub podzielenie danych dalej, prawdopodobnie łącząc dwie lub więcej strategii.
- Monitoruj system, aby sprawdzić, czy dane są dystrybuowane zgodnie z oczekiwaniami i czy partycje mogą obsłużyć obciążenie. Rzeczywiste użycie nie zawsze jest zgodne z przewidywaną analizą. Jeśli tak, może być możliwe ponowne równoważenie partycji lub inne przeprojektowanie niektórych części systemu w celu uzyskania wymaganej równowagi.
Niektóre środowiska w chmurze przydzielają zasoby pod względem granic infrastruktury. Upewnij się, że limity wybranej granicy zapewniają wystarczającą ilość miejsca na przewidywany wzrost ilości danych, pod względem magazynu danych, mocy obliczeniowej i przepustowości.
Jeśli na przykład używasz usługi Azure Table Storage, istnieje limit liczby żądań, które mogą być obsługiwane przez pojedynczą partycję w określonym przedziale czasu. (Aby uzyskać więcej informacji, zobacz Cele dotyczące skalowalności i wydajności usługi Azure Storage). Zajęty fragment może wymagać więcej zasobów niż może obsłużyć pojedyncza partycja. Jeśli tak, może być konieczne ponowne podzielenie fragmentu w celu rozłożenia obciążenia. Jeśli łączny rozmiar lub przepływność tych tabel przekracza pojemność konta magazynu, może być konieczne utworzenie dodatkowych kont magazynu i rozłożenie tabel na tych kontach.
Projektowanie partycji pod kątem wydajności zapytań
Wydajność zapytań może być często zwiększana przy użyciu mniejszych zestawów danych i uruchamiania zapytań równoległych. Każda partycja powinna zawierać niewielką część całego zestawu danych. Ta redukcja woluminu może zwiększyć wydajność zapytań. Jednak partycjonowanie nie jest alternatywą dla odpowiedniego projektowania i konfigurowania bazy danych. Upewnij się na przykład, że masz wymagane indeksy.
Wykonaj następujące kroki podczas projektowania partycji pod kątem wydajności zapytań:
Sprawdź wymagania i wydajność aplikacji:
- Użyj wymagań biznesowych, aby określić krytyczne zapytania, które muszą zawsze działać szybko.
- Monitoruj system, aby zidentyfikować wszystkie zapytania, które działają wolno.
- Znajdź, które zapytania są wykonywane najczęściej. Nawet jeśli pojedyncze zapytanie ma minimalny koszt, skumulowane użycie zasobów może być znaczące.
Partycjonuj dane powodujące niską wydajność:
- Ogranicz rozmiar każdej partycji, aby czas odpowiedzi zapytania mieścił się w obszarze docelowym.
- Jeśli używasz partycjonowania poziomego, zaprojektuj klucz fragmentu, aby aplikacja mogła łatwo wybrać odpowiednią partycję. Zapobiega to konieczności skanowania zapytania przez każdą partycję.
- Rozważ lokalizację partycji. Jeśli to możliwe, spróbuj zachować dane w partycjach, które są geograficznie zbliżone do aplikacji i użytkowników, którzy do niego uzyskują dostęp.
Jeśli jednostka ma wymagania dotyczące przepływności i wydajności zapytań, użyj partycjonowania funkcjonalnego na podstawie tej jednostki. Jeśli nadal nie spełnia to wymagań, zastosuj również partycjonowanie poziome. W większości przypadków wystarczy pojedyncza strategia partycjonowania, ale w niektórych przypadkach bardziej wydajne jest łączenie obu strategii.
Rozważ równoległe uruchamianie zapytań między partycjami, aby zwiększyć wydajność.
Projektowanie partycji pod kątem dostępności
Partycjonowanie danych może zwiększyć dostępność aplikacji, zapewniając, że cały zestaw danych nie stanowi pojedynczego punktu awarii i że poszczególne podzestawy zestawu danych mogą być zarządzane niezależnie.
Rozważ następujące czynniki wpływające na dostępność:
Jak ważne jest działanie danych biznesowych. Zidentyfikuj, które dane mają krytyczne znaczenie dla działania firmy, takie jak transakcje, oraz dane są mniej krytyczne dla danych operacyjnych, takich jak pliki dziennika.
Rozważ przechowywanie krytycznych danych w partycjach o wysokiej dostępności przy użyciu odpowiedniego planu tworzenia kopii zapasowych.
Ustanów oddzielne procedury zarządzania i monitorowania dla różnych zestawów danych.
Umieść dane o tym samym poziomie krytycznym w tej samej partycji, aby można było utworzyć kopię zapasową razem z odpowiednią częstotliwością. Na przykład partycje przechowujące dane transakcji mogą wymagać częstszego tworzenia kopii zapasowych niż partycje przechowujące informacje rejestrowania lub śledzenia.
Jak można zarządzać poszczególnymi partycjami. Projektowanie partycji w celu obsługi niezależnego zarządzania i konserwacji zapewnia kilka zalet. Przykład:
Jeśli partycja ulegnie awarii, można ją odzyskać niezależnie, bez konieczności używania programów, które uzyskują dostęp do danych w innych partycjach.
Partycjonowanie danych według obszaru geograficznego umożliwia wykonywanie zaplanowanych zadań konserwacji poza godzinami szczytu dla każdej lokalizacji. Upewnij się, że partycje nie są zbyt duże, aby zapobiec zakończeniu planowanej konserwacji w tym okresie.
Czy replikować krytyczne dane między partycjami. Ta strategia może zwiększyć dostępność i wydajność, ale może również wprowadzać problemy ze spójnością. Synchronizacja zmian z każdą repliką zajmuje trochę czasu. W tym okresie różne partycje będą zawierać różne wartości danych.
Zagadnienia dotyczące projektowania aplikacji
Partycjonowanie zwiększa złożoność projektowania i opracowywania systemu. Rozważ partycjonowanie jako podstawową część projektowania systemu, nawet jeśli system początkowo zawiera tylko jedną partycję. Jeśli adresujesz partycjonowanie jako pokutę, będzie to trudniejsze, ponieważ masz już system na żywo do utrzymania:
- Logika dostępu do danych musi zostać zmodyfikowana.
- Aby dystrybuować je między partycjami, może być konieczne przeprowadzenie migracji dużych ilości istniejących danych.
- Użytkownicy oczekują, że będą mogli nadal korzystać z systemu podczas migracji.
W niektórych przypadkach partycjonowanie nie jest uznawane za ważne, ponieważ początkowy zestaw danych jest mały i może być łatwo obsługiwany przez pojedynczy serwer. Może to być prawdziwe w przypadku niektórych obciążeń, ale w miarę wzrostu liczby użytkowników wiele systemów komercyjnych musi się zwiększać.
Ponadto nie tylko duże magazyny danych korzystają z partycjonowania. Na przykład do małego magazynu danych mogą uzyskiwać dostęp setki równoczesnych klientów. Partycjonowanie danych w tej sytuacji może pomóc zmniejszyć rywalizację i zwiększyć przepływność.
Podczas projektowania schematu partycjonowania danych należy wziąć pod uwagę następujące kwestie:
Zminimalizuj operacje dostępu do danych między partycjami. Jeśli to możliwe, zachowaj dane dla najbardziej typowych operacji bazy danych w każdej partycji, aby zminimalizować operacje dostępu do danych między partycjami. Wykonywanie zapytań między partycjami może być bardziej czasochłonne niż wykonywanie zapytań w ramach jednej partycji, ale optymalizacja partycji dla jednego zestawu zapytań może niekorzystnie wpłynąć na inne zestawy zapytań. Jeśli musisz wykonywać zapytania między partycjami, zminimalizuj czas zapytania, uruchamiając zapytania równoległe i agregując wyniki w aplikacji. (Takie podejście może nie być możliwe w niektórych przypadkach, na przykład gdy wynik jednego zapytania jest używany w następnym zapytaniu).
Rozważ replikowanie statycznych danych referencyjnych. Jeśli zapytania używają stosunkowo statycznych danych referencyjnych, takich jak tabele kodu pocztowego lub listy produktów, rozważ replikowanie tych danych we wszystkich partycjach w celu zmniejszenia oddzielnych operacji wyszukiwania w różnych partycjach. Takie podejście może również zmniejszyć prawdopodobieństwo, że dane referencyjne staną się "gorącym" zestawem danych, przy dużym natężeniu ruchu z całego systemu. Istnieje jednak dodatkowy koszt związany z synchronizowaniem wszelkich zmian w danych referencyjnych.
Zminimalizuj sprzężenia między partycjami. Jeśli to możliwe, zminimalizuj wymagania dotyczące integralności referencyjnej w partycjach pionowych i funkcjonalnych. W tych schematach aplikacja jest odpowiedzialna za utrzymanie integralności referencyjnej między partycjami. Zapytania, które łączą dane w wielu partycjach, są nieefektywne, ponieważ aplikacja zazwyczaj musi wykonywać kolejne zapytania na podstawie klucza, a następnie klucza obcego. Zamiast tego należy rozważyć replikowanie lub anulowanie normalizacji odpowiednich danych. Jeśli konieczne jest łączenie między partycjami, uruchom zapytania równoległe na partycjach i połącz dane w aplikacji.
Przyjmij spójność ostateczną. Oceń, czy silna spójność jest w rzeczywistości wymaganiem. Typowym podejściem w systemach rozproszonych jest zaimplementowanie spójności ostatecznej. Dane w każdej partycji są aktualizowane oddzielnie, a logika aplikacji gwarantuje, że wszystkie aktualizacje zostaną ukończone pomyślnie. Obsługuje również niespójności, które mogą wynikać z wykonywania zapytań dotyczących danych, podczas gdy ostatecznie spójna operacja jest uruchomiona.
Zastanów się, jak zapytania lokalizują poprawną partycję. Jeśli zapytanie musi skanować wszystkie partycje w celu zlokalizowania wymaganych danych, istnieje znaczący wpływ na wydajność, nawet jeśli uruchomiono wiele zapytań równoległych. W przypadku partycjonowania pionowego i funkcjonalnego zapytania mogą naturalnie określać partycję. Z drugiej strony partycjonowanie w poziomie może utrudnić lokalizowanie elementu, ponieważ każdy fragment ma ten sam schemat. Typowe rozwiązanie do obsługi mapy używanej do wyszukiwania lokalizacji fragmentu dla określonych elementów. Tę mapę można zaimplementować w logice fragmentowania aplikacji lub utrzymywać przez magazyn danych, jeśli obsługuje przezroczyste fragmentowanie.
Rozważ okresowe ponowne równoważenie fragmentów. Dzięki partycjonowaniu poziomym ponowne równoważenie fragmentów może pomóc równomiernie dystrybuować dane według rozmiaru i obciążenia, aby zminimalizować hotspoty, zmaksymalizować wydajność zapytań i obejść ograniczenia magazynu fizycznego. Jest to jednak złożone zadanie, które często wymaga użycia niestandardowego narzędzia lub procesu.
Replikowanie partycji. W przypadku replikowania każdej partycji zapewnia dodatkową ochronę przed awarią. Jeśli pojedyncza replika zakończy się niepowodzeniem, zapytania mogą być kierowane do działającej kopii.
Jeśli osiągniesz fizyczne limity strategii partycjonowania, może być konieczne rozszerzenie skalowalności na inny poziom. Jeśli na przykład partycjonowanie znajduje się na poziomie bazy danych, może być konieczne zlokalizowanie lub replikowanie partycji w wielu bazach danych. Jeśli partycjonowanie jest już na poziomie bazy danych, a ograniczenia fizyczne są problemem, może to oznaczać, że trzeba zlokalizować lub replikować partycje na wielu kontach hostingu.
Unikaj transakcji, które uzyskują dostęp do danych w wielu partycjach. Niektóre magazyny danych implementują spójność transakcyjną i integralność operacji modyfikujących dane, ale tylko wtedy, gdy dane znajdują się w jednej partycji. Jeśli potrzebujesz obsługi transakcyjnej w wielu partycjach, prawdopodobnie musisz zaimplementować tę funkcję w ramach logiki aplikacji, ponieważ większość systemów partycjonowania nie zapewnia natywnej obsługi.
Wszystkie magazyny danych wymagają działania zarządzania operacyjnego i monitorowania. Zadania mogą obejmować ładowanie danych, tworzenie kopii zapasowych i przywracanie danych, reorganizację danych oraz zapewnienie prawidłowego i wydajnego działania systemu.
Rozważ następujące czynniki wpływające na zarządzanie operacyjne:
Jak zaimplementować odpowiednie zadania zarządzania i operacyjne podczas partycjonowania danych. Te zadania mogą obejmować tworzenie kopii zapasowych i przywracanie, archiwizowanie danych, monitorowanie systemu i inne zadania administracyjne. Na przykład utrzymanie spójności logicznej podczas operacji tworzenia kopii zapasowych i przywracania może stanowić wyzwanie.
Jak załadować dane do wielu partycji i dodać nowe dane pochodzące z innych źródeł. Niektóre narzędzia i narzędzia mogą nie obsługiwać operacji podzielonych na fragmenty danych, takich jak ładowanie danych do właściwej partycji.
Jak regularnie archiwizować i usuwać dane. Aby zapobiec nadmiernemu wzrostowi partycji, należy regularnie archiwizować i usuwać dane (na przykład miesięczne). Może być konieczne przekształcenie danych w celu dopasowania ich do innego schematu archiwum.
Jak zlokalizować problemy z integralnością danych. Rozważ uruchomienie okresowego procesu lokalizowania wszelkich problemów z integralnością danych, takich jak dane w jednej partycji, która odwołuje się do brakujących informacji w innej. Proces może próbować automatycznie rozwiązać te problemy lub wygenerować raport na potrzeby ręcznego przeglądu.
Ponowne równoważenie partycji
W miarę dojrzewania systemu może być konieczne dostosowanie schematu partycjonowania. Na przykład poszczególne partycje mogą zacząć uzyskać nieproporcjonalną ilość ruchu i stać się gorące, co prowadzi do nadmiernej rywalizacji. Możesz też lekceważyć ilość danych w niektórych partycjach, co może spowodować, że niektóre partycje zbliżają się do limitów pojemności.
Niektóre magazyny danych, takie jak Azure Cosmos DB, mogą automatycznie ponownie równoważyć partycje. W innych przypadkach ponowne równoważenie to zadanie administracyjne składające się z dwóch etapów:
Określ nową strategię partycjonowania.
- Które partycje muszą być podzielone (lub ewentualnie połączone)?
- Co to jest nowy klucz partycji?
Migrowanie danych ze starego schematu partycjonowania do nowego zestawu partycji.
W zależności od magazynu danych można migrować dane między partycjami, gdy są one używane. Jest to nazywane migracją online. Jeśli nie jest to możliwe, może być konieczne uczynienie partycji niedostępnymi podczas przenoszenia danych (migracja w trybie offline).
Migracja w trybie offline
Migracja w trybie offline jest zwykle prostsza, ponieważ zmniejsza prawdopodobieństwo wystąpienia rywalizacji. Migracja w trybie offline działa w następujący sposób:
- Oznacz partycję w trybie offline.
- Dzielenie, scalanie i przenoszenie danych do nowych partycji.
- Zweryfikuj dane.
- Przełącz nowe partycje w tryb online.
- Usuń starą partycję.
Opcjonalnie możesz oznaczyć partycję jako tylko do odczytu w kroku 1, aby aplikacje mogły nadal odczytywać dane podczas przenoszenia.
Migracja online
Migracja online jest bardziej skomplikowana do wykonania, ale mniej destrukcyjna. Proces jest podobny do migracji w trybie offline, z wyjątkiem oryginalnej partycji nie jest oznaczany w trybie offline. W zależności od stopnia szczegółowości procesu migracji (na przykład elementu według elementu a fragmentu według fragmentu) kod dostępu do danych w aplikacjach klienckich może być musiał obsługiwać odczytywanie i zapisywanie danych przechowywanych w dwóch lokalizacjach, oryginalnej partycji i nowej partycji.
Dalsze kroki
- Dowiedz się więcej o strategiach partycjonowania dla określonych usług platformy Azure. Aby uzyskać więcej informacji, zobacz Strategie partycjonowania danych.
- Cele dotyczące skalowalności i wydajności usługi Azure Storage
Powiązane zasoby
Następujące wzorce projektowe mogą być istotne dla danego scenariusza:
Wzorzec fragmentowania opisuje niektóre typowe strategie fragmentowania danych.
Wzorzec tabeli indeksów pokazuje, jak utworzyć indeksy pomocnicze na danych. Aplikacja może szybko pobierać dane za pomocą tego podejścia, korzystając z zapytań, które nie odwołują się do klucza podstawowego kolekcji.
Wzorzec zmaterializowanego widoku opisuje sposób generowania wstępnie wypełnionych widoków, które podsumowują dane w celu obsługi szybkich operacji zapytań. Takie podejście może być przydatne w podzielonym na partycje magazynie danych, jeśli partycje zawierające podsumowane dane są dystrybuowane w wielu lokacjach.