Antywzorzec dotyczący braku buforowania
Wzorce antywłaszowe są typowymi wadami projektowymi, które mogą uszkodzić oprogramowanie lub aplikacje w sytuacjach stresu i nie powinny być pomijane. Nie ma buforowania antywzorzec , gdy aplikacja w chmurze, która obsługuje wiele współbieżnych żądań, wielokrotnie pobiera te same dane. Może to zmniejszyć wydajność i skalowalność.
Brak buforowania danych może spowodować szereg niepożądanych zachowań, takich jak:
- Wielokrotne pobieranie tych samych informacji z zasobu, który generuje koszty dostępu wynikające z obciążenia we/wy lub opóźnienia.
- Wielokrotne tworzenie tych samych obiektów lub struktur danych dla wielu żądań.
- Nadmierne wywoływanie usługi zdalnej, która ma limit przydziału i ogranicza klientów po jego osiągnięciu.
Problemy te mogą z kolei wydłużać czas odpowiedzi, zmniejszać skalowalność i zwiększać rywalizację o zasoby w magazynie danych.
Przykłady braku buforowania antywzorzec
W poniższym przykładzie użyto programu Entity Framework do nawiązania połączenia z bazą danych. Każde żądanie klienta powoduje wysłanie wywołania do bazy danych, nawet jeśli wiele żądań pobiera dokładnie te same dane. Koszt powtarzanych żądań wynikający z obciążenia we/wy i opłat za dostęp do danych może szybko wzrosnąć.
public class PersonRepository : IPersonRepository
{
public async Task<Person> GetAsync(int id)
{
using (var context = new AdventureWorksContext())
{
return await context.People
.Where(p => p.Id == id)
.FirstOrDefaultAsync()
.ConfigureAwait(false);
}
}
}
Pełny przykład można znaleźć tutaj.
Oto typowe przyczyny występowania tego antywzorca:
- Implementacja, która nie korzysta z pamięci podręcznej, jest prostsza i działa prawidłowo w warunkach małych obciążeń. Buforowanie danych wymaga zwiększenia stopnia skomplikowania kodu.
- Zalety i wady używania pamięci podręcznej nie zawsze są łatwo zrozumiałe.
- Występują obawy związane z nakładem pracy wymaganej do utrzymania dokładności i aktualności buforowanych danych.
- Aplikacja została przeniesiona z systemu lokalnego, w którym opóźnienie sieci nie stanowiło problemu i który działał na drogim sprzęcie o wysokiej wydajności, co nie wymagało uwzględnienia buforowania w oryginalnym projekcie.
- Deweloperzy mogą nie wiedzieć o możliwości użycia buforowania w danym scenariuszu. Na przykład mogą oni nie korzystać z elementów ETag podczas implementowania internetowego interfejsu API.
Jak naprawić antywzorzec bez buforowania
Najbardziej popularne strategie to buforowanie na żądanie lub odkładanie do pamięci podręcznej.
- Podczas odczytu aplikacja próbuje odczytać dane z pamięci podręcznej. Jeśli ich tam nie ma, aplikacja pobiera je ze źródła danych i dodaje do pamięci podręcznej.
- Podczas zapisu aplikacja zapisuje zmiany bezpośrednio w źródle danych i usuwa starą wartość z pamięci podręcznej. Gdy dane te będą potrzebne, zostaną pobrane i dodane do pamięci podręcznej.
Ta metoda sprawdza się w przypadku często zmieniających się danych. Oto poprzedni przykład, który zaktualizowano pod kątem używania wzorca z odkładaniem do pamięci podręcznej.
public class CachedPersonRepository : IPersonRepository
{
private readonly PersonRepository _innerRepository;
public CachedPersonRepository(PersonRepository innerRepository)
{
_innerRepository = innerRepository;
}
public async Task<Person> GetAsync(int id)
{
return await CacheService.GetAsync<Person>("p:" + id, () => _innerRepository.GetAsync(id)).ConfigureAwait(false);
}
}
public class CacheService
{
private static ConnectionMultiplexer _connection;
public static async Task<T> GetAsync<T>(string key, Func<Task<T>> loadCache, double expirationTimeInMinutes)
{
IDatabase cache = Connection.GetDatabase();
T value = await GetAsync<T>(cache, key).ConfigureAwait(false);
if (value == null)
{
// Value was not found in the cache. Call the lambda to get the value from the database.
value = await loadCache().ConfigureAwait(false);
if (value != null)
{
// Add the value to the cache.
await SetAsync(cache, key, value, expirationTimeInMinutes).ConfigureAwait(false);
}
}
return value;
}
}
Zwróć uwagę, że zamiast bezpośredniego wywoływania bazy danych metoda GetAsync wywołuje klasę CacheService. Klasa CacheService najpierw próbuje pobrać element z usługi Azure Cache for Redis. Jeśli wartość nie zostanie odnaleziona w pamięci podręcznej, klasa CacheService wywołuje funkcję lambda, która została przekazana przez obiekt wywołujący. Funkcja lambda obsługuje pobieranie danych z bazy danych. W tej implementacji repozytorium oddzielono od konkretnego rozwiązania buforowania, a klasę CacheService oddzielono od bazy danych.
Zagadnienia dotyczące strategii buforowania
Jeśli pamięć podręczna jest niedostępna, na przykład z powodu przejściowego błędu, nie należy zwracać błędu do klienta. Zamiast tego należy pobrać dane z oryginalnego źródła danych. Pamiętaj jednak, że podczas odzyskiwania pamięci podręcznej może nastąpić zalew żądań w oryginalnym magazynie danych, powodujących przekroczenie limitów czasu i awarie połączeń. (W końcu jest to jedna z motywacji do korzystania z pamięci podręcznej w pierwszej kolejności). Użyj techniki, takiej jak wzorzec wyłącznika, aby uniknąć przeciążeń źródła danych.
Aplikacje buforujące dane dynamiczne powinny obsługiwać spójność ostateczną.
W przypadku internetowych interfejsów API obsługę buforowania po stronie klienta można zapewnić, dołączając nagłówek Cache-Control w komunikatach żądań i odpowiedzi oraz korzystając z elementów ETag do identyfikowania wersji obiektów. Aby uzyskać więcej informacji, zobacz Wdrażanie interfejsu API.
Nie trzeba buforować całych jednostek. Jeśli tylko niewielki fragment jednostki często się zmienia, umieść w pamięci podręcznej elementy statyczne, a elementy dynamiczne pobieraj ze źródła danych. Może to pomóc w zmniejszeniu liczby operacji we/wy wykonywanych względem źródła danych.
W niektórych przypadkach może być przydatne buforowanie danych krótkotrwałych. Przykładem może być urządzenie, które stale wysyła aktualizacje stanu. Sensowne wydaje się buforowanie pojawiających się informacji i niezapisywanie ich w magazynie trwałym.
Aby zapewnić aktualność danych, wiele rozwiązań buforowania obsługuje konfigurowanie okresów ważności, które powodują automatyczne usuwanie danych z pamięci podręcznej po upływie określonego czasu. Czas wygaśnięcia można dostosować do danego scenariusza. Wysoce statyczne dane mogą pozostawać w pamięci podręcznej dłużej niż dane nietrwałe, które szybko stają się nieaktualne.
Jeśli rozwiązanie buforowania nie udostępnia wbudowanego mechanizmu wygasania, może być konieczne wdrożenie procesu w tle, który co jakiś czas czyści pamięć podręczną, zapobiegając jej nieograniczonemu wzrostowi.
Oprócz buforowania danych z zewnętrznego źródła danych, pamięci podręcznej można użyć do zapisywania wyników złożonych obliczeń. Wcześniej jednak należy wyposażyć aplikację w instrumenty umożliwiające ustalenie, czy procesor jest faktycznie obciążony.
Przydatne może być zainicjowanie pamięci podręcznej podczas uruchamiania aplikacji. Bufor należy wypełnić danymi, które najprawdopodobniej będą używane.
Należy zawsze dołączać instrumenty umożliwiające wykrywanie trafień i chybień w pamięci podręcznej. Dzięki tym informacjom można dostosować zasady buforowania, dotyczące na przykład okresu ważności i zakresu danych przechowywanych w pamięci podręcznej.
Jeśli brak pamięci podręcznej powoduje powstanie wąskiego gardła, jej dodanie może skutkować przeciążeniem frontonu internetowego wynikającym ze znacznego zwiększenia liczby żądań. Do klientów mogą być wysyłane błędy HTTP 503 (Usługa niedostępna). Jest to wskazanie do przeskalowania frontonu w poziomie.
Jak wykryć antywzorzec braku buforowania
Następujące kroki mogą pomóc ustalić, czy brak buforowania powoduje problemy z wydajnością:
Przejrzyj projekt aplikacji. Zrób spis wszystkich magazynów danych używanych przez aplikację. Ustal, czy aplikacja używa pamięci podręcznej podczas komunikowania się z poszczególnymi magazynami. Jeśli to możliwe, ustal, jak często zmieniają się dane. Wstępnie można przyjąć, że do buforowania nadają się dane, które zmieniają się powoli, i często odczytywane statyczne dane referencyjne.
Monitoruj system produkcyjny oraz dodaj do aplikacji odpowiednie instrumenty, aby dowiedzieć się, jak często pobiera ona dane lub przeprowadza obliczenia.
Utwórz profil aplikacji w środowisku testowym, aby przechwycić metryki niskiego poziomu dotyczące obciążenia związanego z operacjami uzyskiwania dostępu do danych lub innymi często wykonywanymi obliczeniami.
Wykonaj testy obciążeniowe w środowisku testowym, aby sprawdzić, jak zachowuje się system w warunkach normalnego i dużego obciążenia. Testy obciążeniowe powinny symulować wzorzec dostępu do danych, który występuje w środowisku produkcyjnym przy realistycznym obciążeniu.
Przeanalizuj statystyki dostępu do danych przechowywanych w źródłowych magazynach danych i sprawdź, jak często powtarzają się te same żądania.
Przykładowa diagnostyka
W poniższych sekcjach zastosowano te kroki do opisanej wcześniej przykładowej aplikacji.
Instrumentacja aplikacji i monitorowanie systemu produkcyjnego
Instrumentacja i monitorowanie aplikacji pozwalają uzyskać informacje dotyczące konkretnych żądań wysyłanych przez użytkowników w środowisku produkcyjnym.
Poniższy obraz przedstawia dane monitorowania przechwycone przez oprogramowanie New Relic podczas testu obciążeniowego. W tym przypadku jedyną wykonywaną operacją HTTP GET jest Person/GetAsync. Jednak w środowisku produkcyjnym informacja o względnej częstotliwości wykonywania poszczególnych żądań może stanowić wskazanie, które zasoby powinny być buforowane.
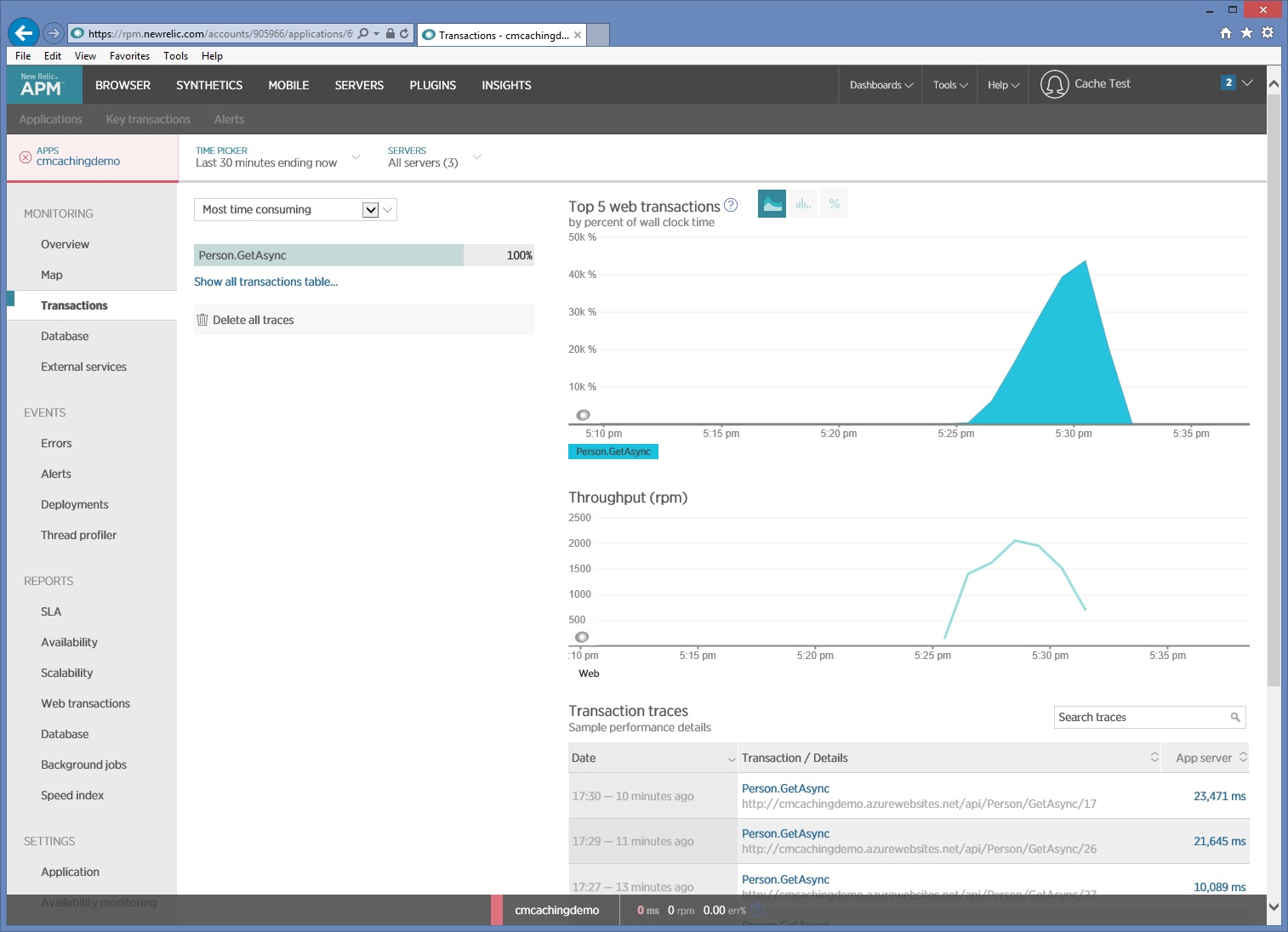
Jeśli potrzebujesz dokładniejszej analizy, za pomocą profilera możesz przechwycić dane niskiego poziomu dotyczące wydajności w środowisku testowym (nie w systemie produkcyjnym). Metryki godne uwagi obejmują liczby żądań we/wy oraz użycie pamięci i procesora. Metryki te mogą zawierać dużą liczbę żądań kierowanych do magazynu danych lub usługi albo powtarzające się obliczenia.
Test obciążeniowy aplikacji
Na poniższym wykresie przedstawiono wyniki testów obciążeniowych na przykładowej aplikacji. Zasymulowano obciążenie krokowe obejmujące do 800 użytkowników, którzy wykonują serię typowych operacji.
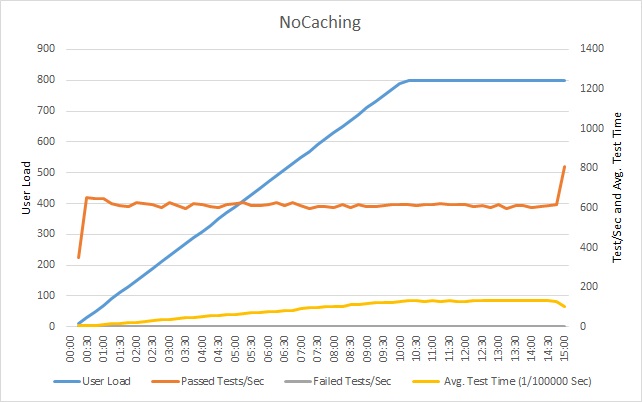
Liczba pomyślnych testów wykonywanych w każdej sekundzie osiąga pułap możliwości, a dodatkowe żądania są spowalniane. Średni czas testu stale rośnie wraz z obciążeniem. Czas odpowiedzi stabilizuje się po osiągnięciu maksymalnego obciążenia operacjami użytkowników.
Analizowanie statystyk dostępu do danych
Statystyki dostępu do danych oraz inne wskazówki udostępniane przez magazyn danych mogą stanowić źródło przydatnych informacji, na przykład dotyczących najczęściej powtarzanych zapytań. Na przykład w programie Microsoft SQL Server widok zarządzania sys.dm_exec_query_stats zawiera informacje statystyczne na temat ostatnio wykonywanych zapytań. Tekst każdego zapytania jest dostępny w widoku sys.dm_exec-query_plan. Za pomocą narzędzia SQL Server Management Studio można uruchomić następujące zapytanie SQL i ustalić, jak często są wykonywane zapytania.
SELECT UseCounts, Text, Query_Plan
FROM sys.dm_exec_cached_plans
CROSS APPLY sys.dm_exec_sql_text(plan_handle)
CROSS APPLY sys.dm_exec_query_plan(plan_handle)
Widoczna w wynikach kolumna UseCount wskazuje, jak często są uruchamiane poszczególne zapytania. Na poniższej ilustracji widać, że trzecie zapytanie było uruchamiane ponad 250 000 razy — znacznie częściej niż jakiekolwiek inne zapytanie.
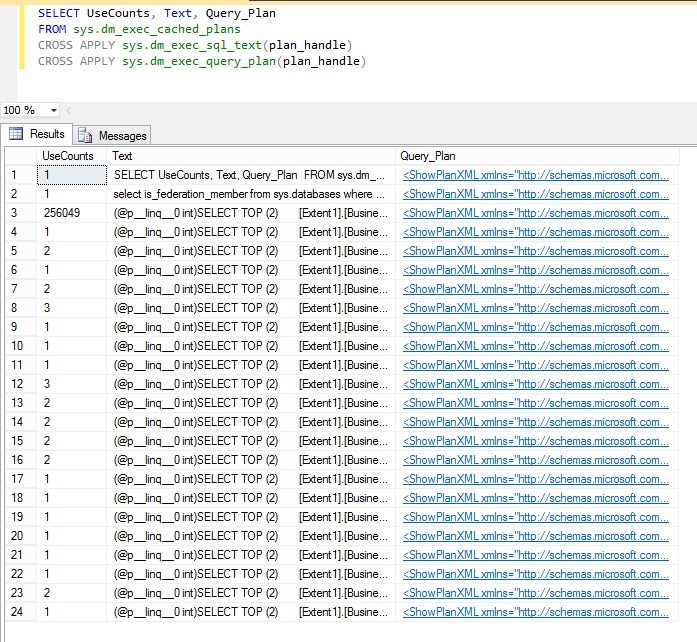
Oto zapytanie SQL powodujące występowanie tak wielu żądań bazy danych:
(@p__linq__0 int)SELECT TOP (2)
[Extent1].[BusinessEntityId] AS [BusinessEntityId],
[Extent1].[FirstName] AS [FirstName],
[Extent1].[LastName] AS [LastName]
FROM [Person].[Person] AS [Extent1]
WHERE [Extent1].[BusinessEntityId] = @p__linq__0
Jest to zapytanie generowane przez program Entity Framework w przedstawionej wcześniej metodzie GetByIdAsync.
Implementowanie rozwiązania strategii pamięci podręcznej i weryfikowanie wyniku
Po wdrożeniu pamięci podręcznej powtórz testy obciążeniowe, a następnie porównaj ich wyniki z wynikami wcześniejszych testów bez buforowania. Poniżej przedstawiono wyniki testów obciążeniowych przeprowadzonych po dodaniu pamięci podręcznej do przykładowej aplikacji.
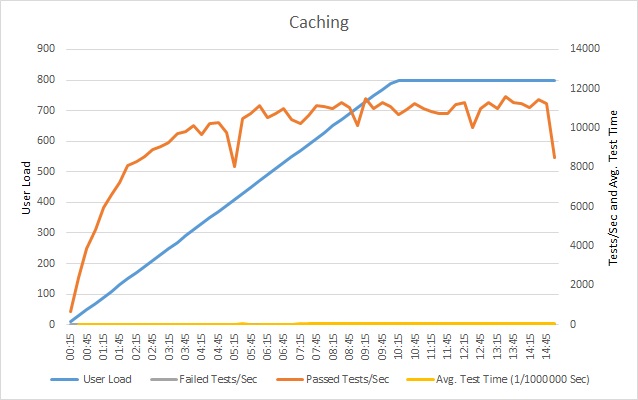
Liczba pomyślnych testów wciąż osiąga pułap, ale przy większym obciążeniu operacjami użytkowników. Liczba żądań przy tym obciążeniu jest znacznie większa niż wcześniej. Średni czas testu nadal wzrasta wraz z obciążeniem, ale maksymalny czas odpowiedzi wynosi 0,05 ms, w porównaniu z 1 ms wcześniej — 20× ulepszeniem.
Powiązane zasoby
- API implementation best practices (Najlepsze rozwiązania dotyczące implementacji interfejsów API)
- Wzorzec z odkładaniem do pamięci podręcznej
- Caching best practices (Najlepsze rozwiązania dotyczące buforowania)
- Wzorzec z wyłącznikiem
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla