Wskazówki dotyczące buforowania
Buforowanie jest typową techniką, której celem jest zwiększanie wydajności i skalowalności systemu. Dane są buforowane przez tymczasowe kopiowanie często używanych danych do szybkiego magazynu znajdującego się w pobliżu aplikacji. Jeśli ten szybki magazyn danych znajduje się bliżej aplikacji niż oryginalne źródło, buforowanie może znacznie poprawić czasy odpowiedzi aplikacji klienckich poprzez szybszą obsługę danych.
Buforowanie jest najbardziej skuteczne, gdy wystąpienie klienta wielokrotnie odczytuje te same dane, zwłaszcza jeśli wszystkie następujące warunki mają zastosowanie do oryginalnego magazynu danych:
- Pozostaje stosunkowo statyczny.
- Jest powolny w porównaniu do prędkości pamięci podręcznej.
- Podlega wysokiemu poziomowi rywalizacji.
- Jest daleko, gdy opóźnienie sieci może spowodować spowolnienie dostępu.
Buforowanie w aplikacjach rozproszonych
Aplikacje rozproszone zwykle implementują obie z następujących strategii podczas buforowania danych:
- Używają prywatnej pamięci podręcznej, w której dane są przechowywane lokalnie na komputerze z uruchomionym wystąpieniem aplikacji lub usługi.
- Używają udostępnionej pamięci podręcznej, pełniąc rolę wspólnego źródła, do którego można uzyskać dostęp przez wiele procesów i maszyn.
W obu przypadkach buforowanie można wykonać po stronie klienta i po stronie serwera. Buforowanie po stronie klienta jest realizowane przez proces, który zapewnia interfejs użytkownika dla systemu, jak przeglądarka internetowa lub aplikacja komputerowa. Buforowanie po stronie serwera odbywa się przez proces, który zapewnia usługi biznesowe, które działają zdalnie.
Buforowanie prywatne
Najbardziej podstawowym typem pamięci podręcznej jest magazyn w pamięci. Jest on przechowywany w przestrzeni adresowej pojedynczego procesu i uzyskiwany bezpośrednio przez kod uruchamiany w tym procesie. Dostęp do tego typu pamięci podręcznej jest szybki. Może również zapewnić skuteczne środki do przechowywania skromnych ilości danych statycznych. Rozmiar pamięci podręcznej jest zwykle ograniczany przez ilość pamięci dostępnej na maszynie, która hostuje proces.
Jeśli potrzebujesz buforować więcej informacji niż jest to fizycznie możliwe w pamięci, możesz zapisać dane w pamięci podręcznej w lokalnym systemie plików. Ten proces będzie wolniejszy niż dostęp do danych przechowywanych w pamięci, ale nadal powinien być szybszy i bardziej niezawodny niż pobieranie danych w sieci.
Jeśli masz wiele wystąpień aplikacji, które korzystają z tego modelu uruchomionego współbieżnie, każde wystąpienie aplikacji ma własną niezależną pamięć podręczną przechowującą własną kopię danych.
Pomyśl o pamięci podręcznej jako migawki oryginalnych danych w pewnym momencie w przeszłości. Jeśli te dane nie są statyczne, prawdopodobnie różne wystąpienia aplikacji przechowują różne wersje danych w swoich pamięciach podręcznych. W związku z tym to samo zapytanie wykonywane przez te wystąpienia może zwracać różne wyniki, jak pokazano na rysunku 1.
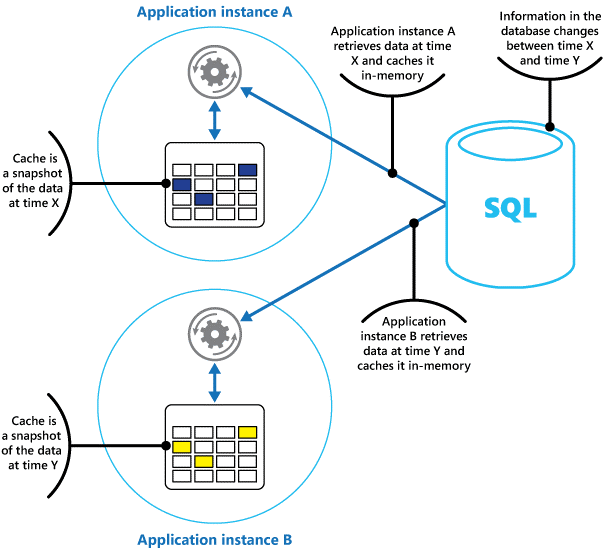
Rysunek 1. Używanie pamięci podręcznej w pamięci w różnych wystąpieniach aplikacji.
Buforowanie udostępnione
Jeśli używasz udostępnionej pamięci podręcznej, może pomóc złagodzić obawy, że dane mogą się różnić w każdej pamięci podręcznej, co może wystąpić w przypadku buforowania w pamięci. Buforowanie udostępnione gwarantuje, że różne wystąpienia aplikacji zobaczą ten sam widok buforowanych danych. Lokalizuje pamięć podręczną w oddzielnej lokalizacji, która jest zwykle hostowana jako część oddzielnej usługi, jak pokazano na rysunku 2.
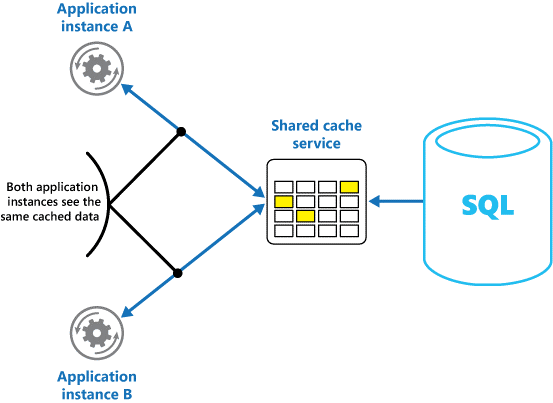
Rysunek 2. Używanie udostępnionej pamięci podręcznej.
Ważną zaletą podejścia do buforowania współużytkowanego jest skalowalność, która zapewnia. Wiele usług udostępnionej pamięci podręcznej jest implementowanych przy użyciu klastra serwerów i używa oprogramowania do przezroczystego dystrybuowania danych w klastrze. Wystąpienie aplikacji po prostu wysyła żądanie do usługi pamięci podręcznej. Podstawowa infrastruktura określa lokalizację buforowanych danych w klastrze. Pamięć podręczną można łatwo skalować, dodając więcej serwerów.
Istnieją dwie główne wady wspólnego podejścia buforowania:
- Pamięć podręczna jest wolniejsza do uzyskiwania dostępu, ponieważ nie jest już przechowywana lokalnie w każdym wystąpieniu aplikacji.
- Wymaganie implementacji oddzielnej usługi pamięci podręcznej może zwiększyć złożoność rozwiązania.
Zagadnienia dotyczące używania buforowania
W poniższych sekcjach opisano bardziej szczegółowo zagadnienia dotyczące projektowania i używania pamięci podręcznej.
Decydowanie o tym, kiedy mają być buforowane dane
Buforowanie może znacznie poprawić wydajność, skalowalność i dostępność. Im więcej danych i im większa liczba użytkowników, którzy muszą uzyskiwać dostęp do tych danych, tym większe korzyści wynikające z buforowania stają się. Buforowanie zmniejsza opóźnienie i rywalizację związaną z obsługą dużych ilości współbieżnych żądań w oryginalnym magazynie danych.
Na przykład baza danych może obsługiwać ograniczoną liczbę połączeń współbieżnych. Jednak pobieranie danych z udostępnionej pamięci podręcznej, a nie bazowej bazy danych, umożliwia aplikacji klienckiej uzyskanie dostępu do tych danych nawet wtedy, gdy liczba dostępnych połączeń jest obecnie wyczerpana. Ponadto jeśli baza danych stanie się niedostępna, aplikacje klienckie mogą nadal korzystać z danych przechowywanych w pamięci podręcznej.
Rozważ buforowanie danych, które są często odczytywane, ale modyfikowane rzadko (na przykład dane, które mają większą część operacji odczytu niż operacje zapisu). Nie zalecamy jednak używania pamięci podręcznej jako autorytatywnego magazynu informacji krytycznych. Zamiast tego upewnij się, że wszystkie zmiany, na które aplikacja nie może pozwolić sobie na utratę, są zawsze zapisywane w trwałym magazynie danych. Jeśli pamięć podręczna jest niedostępna, aplikacja nadal może działać przy użyciu magazynu danych i nie utracisz ważnych informacji.
Określanie sposobu efektywnego buforowania danych
Kluczem do efektywnego używania pamięci podręcznej jest określenie najbardziej odpowiednich danych do buforowania i buforowanie ich w odpowiednim czasie. Dane można dodawać do pamięci podręcznej na żądanie przy pierwszym pobieraniu przez aplikację. Aplikacja musi pobrać dane tylko raz z magazynu danych i że kolejny dostęp może być spełniony przy użyciu pamięci podręcznej.
Alternatywnie pamięć podręczna może być częściowo lub w pełni wypełniona danymi z wyprzedzeniem, zazwyczaj po uruchomieniu aplikacji (metoda znana jako rozmieszczanie). Jednak może nie być wskazane zaimplementowanie rozmieszczania dla dużej pamięci podręcznej, ponieważ takie podejście może narzucić nagłe, wysokie obciążenie oryginalnego magazynu danych po uruchomieniu aplikacji.
Często analiza wzorców użycia może pomóc w podjęciu decyzji, czy w pełni lub częściowo wstępnie wypełniać pamięć podręczną, i wybrać dane do buforowania. Można na przykład zainicjować pamięć podręczną ze statycznymi danymi profilu użytkownika dla klientów, którzy regularnie korzystają z aplikacji (być może codziennie), ale nie dla klientów korzystających z aplikacji tylko raz w tygodniu.
Buforowanie zwykle działa dobrze z danymi, które są niezmienne lub które zmieniają się rzadko. Przykłady obejmują informacje referencyjne, takie jak informacje o produkcie i cenach w aplikacji handlu elektronicznego lub udostępnione zasoby statyczne, które są kosztowne do konstruowania. Niektóre lub wszystkie te dane można załadować do pamięci podręcznej podczas uruchamiania aplikacji, aby zminimalizować zapotrzebowanie na zasoby i zwiększyć wydajność. Możesz również mieć proces w tle, który okresowo aktualizuje dane referencyjne w pamięci podręcznej, aby upewnić się, że jest up-to-date. Lub proces w tle może odświeżyć pamięć podręczną po zmianie danych referencyjnych.
Buforowanie jest mniej przydatne w przypadku danych dynamicznych, chociaż istnieją pewne wyjątki od tej kwestii (zobacz sekcję Buforowanie wysoce dynamicznych danych w dalszej części tego artykułu, aby uzyskać więcej informacji). Gdy oryginalne dane zmieniają się regularnie, buforowane informacje szybko stają się nieaktualne lub obciążenie związane z synchronizacją pamięci podręcznej z oryginalnym magazynem danych zmniejsza skuteczność buforowania.
Pamięć podręczna nie musi zawierać pełnych danych dla jednostki. Jeśli na przykład element danych reprezentuje obiekt wielowartościowy, taki jak klient bankowy z nazwą, adresem i saldem konta, niektóre z tych elementów mogą pozostać statyczne, takie jak nazwa i adres. Inne elementy, takie jak saldo konta, mogą być bardziej dynamiczne. W takich sytuacjach może być przydatne buforowanie statycznych części danych i pobieranie (lub obliczanie) tylko pozostałych informacji, gdy jest to wymagane.
Zalecamy przeprowadzenie testów wydajnościowych i analizy użycia w celu określenia, czy wstępnie wypełniane lub na żądanie ładowanie pamięci podręcznej, czy kombinacja obu tych operacji jest odpowiednia. Decyzja powinna być oparta na zmienności i wzorcu użycia danych. Wykorzystanie pamięci podręcznej i analiza wydajności są ważne w aplikacjach, które napotykają duże obciążenia i muszą być wysoce skalowalne. Na przykład w wysoce skalowalnych scenariuszach można zainicjować pamięć podręczną, aby zmniejszyć obciążenie magazynu danych w godzinach szczytu.
Buforowanie może również służyć do unikania powtarzania obliczeń podczas działania aplikacji. Jeśli operacja przekształca dane lub wykonuje skomplikowane obliczenia, może zapisać wyniki operacji w pamięci podręcznej. Jeśli to samo obliczenie jest wymagane później, aplikacja może po prostu pobrać wyniki z pamięci podręcznej.
Aplikacja może modyfikować dane przechowywane w pamięci podręcznej. Zalecamy jednak myślenie o pamięci podręcznej jako przejściowym magazynie danych, który może zniknąć w dowolnym momencie. Nie przechowuj cennych danych tylko w pamięci podręcznej; upewnij się, że informacje są przechowywane w oryginalnym magazynie danych. Oznacza to, że jeśli pamięć podręczna stanie się niedostępna, zminimalizujesz prawdopodobieństwo utraty danych.
Buforowanie wysoce dynamicznych danych
Podczas przechowywania szybko zmieniających się informacji w trwałym magazynie danych może to narzucić obciążenie systemu. Rozważmy na przykład urządzenie, które stale zgłasza stan lub inny pomiar. Jeśli aplikacja zdecyduje się nie buforować tych danych na podstawie tego, że buforowane informacje będą prawie zawsze nieaktualne, podczas przechowywania i pobierania tych informacji z magazynu danych może być prawdziwe. W czasie potrzebnym na zapisanie i pobranie tych danych mogło zostać zmienione.
W takiej sytuacji należy wziąć pod uwagę zalety przechowywania informacji dynamicznych bezpośrednio w pamięci podręcznej zamiast w trwałym magazynie danych. Jeśli dane są niekrytyczne i nie wymagają inspekcji, nie ma znaczenia, czy sporadyczne zmiany zostaną utracone.
Zarządzanie wygasaniem danych w pamięci podręcznej
W większości przypadków dane przechowywane w pamięci podręcznej to kopia danych przechowywanych w oryginalnym magazynie danych. Dane w oryginalnym magazynie danych mogą ulec zmianie po ich buforowanej pamięci podręcznej, co powoduje, że dane w pamięci podręcznej staną się nieaktualne. Wiele systemów buforowania umożliwia skonfigurowanie pamięci podręcznej w celu wygaśnięcia danych i skrócenie okresu, dla którego dane mogą być nieaktualne.
Gdy dane buforowane wygasają, zostaną usunięte z pamięci podręcznej, a aplikacja musi pobrać dane z oryginalnego magazynu danych (może umieścić nowo pobrane informacje z powrotem w pamięci podręcznej). Podczas konfigurowania pamięci podręcznej można ustawić domyślne zasady wygasania. W wielu usługach pamięci podręcznej można również określić okres wygaśnięcia poszczególnych obiektów podczas programowego przechowywania ich w pamięci podręcznej. Niektóre pamięci podręczne umożliwiają określenie okresu wygaśnięcia jako wartości bezwzględnej lub jako wartości przesuwanej, która powoduje usunięcie elementu z pamięci podręcznej, jeśli nie jest on dostępny w określonym czasie. To ustawienie zastępuje wszystkie zasady wygasania całej pamięci podręcznej, ale tylko dla określonych obiektów.
Uwaga / Notatka
Należy wziąć pod uwagę okres wygaśnięcia pamięci podręcznej i obiekty, które zawiera dokładnie. Jeśli staniesz się zbyt krótki, obiekty wygasną zbyt szybko i zmniejszysz korzyści wynikające z używania pamięci podręcznej. Jeśli okres będzie zbyt długi, ryzyko, że dane staną się nieaktualne.
Istnieje również możliwość, że pamięć podręczna może zostać wypełniona, jeśli dane mogą pozostać rezydentami przez długi czas. W takim przypadku wszelkie żądania dodania nowych elementów do pamięci podręcznej mogą spowodować wymuszone usunięcie niektórych elementów w procesie znanym jako eksmisja. Usługi pamięci podręcznej zwykle eksmitują dane na podstawie najmniej ostatnio używanych (LRU), ale zazwyczaj można zastąpić te zasady i uniemożliwić eksmitowanie elementów. Jeśli jednak zastosujesz to podejście, ryzyko przekroczenia pamięci dostępnej w pamięci podręcznej. Aplikacja, która próbuje dodać element do pamięci podręcznej, zakończy się niepowodzeniem z wyjątkiem.
Niektóre implementacje buforowania mogą zapewniać dodatkowe zasady eksmisji. Istnieje kilka typów zasad eksmisji. Są to:
- Ostatnio używane zasady (w oczekiwaniu, że dane nie będą ponownie wymagane).
- Zasady pierwszego na pierwszym wyjeździe (najstarsze dane są najpierw eksmitowane).
- Jawne zasady usuwania oparte na wyzwolonym zdarzeniu (na przykład modyfikowane dane).
Unieważnianie danych w pamięci podręcznej po stronie klienta
Dane przechowywane w pamięci podręcznej po stronie klienta są zwykle uważane za poza pomyślnością usługi, która dostarcza dane klientowi. Usługa nie może bezpośrednio wymusić na kliencie dodawania ani usuwania informacji z pamięci podręcznej po stronie klienta.
Oznacza to, że istnieje możliwość, aby klient, który używa źle skonfigurowanej pamięci podręcznej do kontynuowania korzystania z nieaktualnych informacji. Jeśli na przykład zasady wygasania pamięci podręcznej nie są prawidłowo implementowane, klient może używać nieaktualnych informacji buforowanych lokalnie, gdy informacje w oryginalnym źródle danych uległy zmianie.
Jeśli tworzysz aplikację internetową, która obsługuje dane za pośrednictwem połączenia HTTP, możesz niejawnie wymusić na kliencie internetowym (takim jak przeglądarka lub internetowy serwer proxy), aby pobrać najnowsze informacje. Można to zrobić, jeśli zasób zostanie zaktualizowany przez zmianę identyfikatora URI tego zasobu. Klienci sieci Web zazwyczaj używają identyfikatora URI zasobu jako klucza w pamięci podręcznej po stronie klienta, więc jeśli identyfikator URI ulegnie zmianie, klient internetowy ignoruje wszystkie wcześniej buforowane wersje zasobu i pobiera nową wersję.
Zarządzanie współbieżnością w pamięci podręcznej
Pamięci podręczne są często przeznaczone do współużytkowania przez wiele wystąpień aplikacji. Każde wystąpienie aplikacji może odczytywać i modyfikować dane w pamięci podręcznej. W związku z tym te same problemy ze współbieżnością, które występują z dowolnym udostępnionym magazynem danych, mają również zastosowanie do pamięci podręcznej. W sytuacji, gdy aplikacja musi zmodyfikować dane przechowywane w pamięci podręcznej, może być konieczne upewnienie się, że aktualizacje wprowadzone przez jedno wystąpienie aplikacji nie zastępują zmian wprowadzonych przez inne wystąpienie.
W zależności od charakteru danych i prawdopodobieństwa kolizji można przyjąć jedno z dwóch podejść do współbieżności:
- Optymistyczne. Bezpośrednio przed zaktualizowaniem danych aplikacja sprawdza, czy dane w pamięci podręcznej uległy zmianie od czasu ich pobrania. Jeśli dane są nadal takie same, można wprowadzić zmianę. W przeciwnym razie aplikacja musi zdecydować, czy ją zaktualizować. (Logika biznesowa, która napędza tę decyzję, będzie specyficzna dla aplikacji). Takie podejście jest odpowiednie w sytuacjach, w których aktualizacje są rzadko dostępne lub w przypadku wystąpienia kolizji jest mało prawdopodobne.
- Pesymistyczny. Po pobraniu danych aplikacja blokuje je w pamięci podręcznej, aby zapobiec zmianie innego wystąpienia. Ten proces gwarantuje, że nie mogą wystąpić kolizje, ale mogą również blokować inne wystąpienia, które muszą przetwarzać te same dane. Pesymistyczna współbieżność może mieć wpływ na skalowalność rozwiązania i jest zalecana tylko w przypadku krótkotrwałych operacji. Takie podejście może być odpowiednie w sytuacjach, w których kolizje są bardziej prawdopodobne, zwłaszcza jeśli aplikacja aktualizuje wiele elementów w pamięci podręcznej i musi zapewnić spójne stosowanie tych zmian.
Implementowanie wysokiej dostępności i skalowalności oraz zwiększanie wydajności
Unikaj używania pamięci podręcznej jako podstawowego repozytorium danych; jest to rola oryginalnego magazynu danych, z którego jest wypełniana pamięć podręczna. Oryginalny magazyn danych jest odpowiedzialny za zapewnienie trwałości danych.
Należy zachować ostrożność, aby nie wprowadzać krytycznych zależności od dostępności usługi udostępnionej pamięci podręcznej do Twoich rozwiązań. Aplikacja powinna mieć możliwość kontynuowania działania, jeśli usługa udostępniająca udostępnioną pamięć podręczną jest niedostępna. Aplikacja nie powinna odpowiadać ani nie działać podczas oczekiwania na wznowienie usługi pamięci podręcznej.
W związku z tym aplikacja musi być przygotowana do wykrywania dostępności usługi pamięci podręcznej i powrotu do oryginalnego magazynu danych, jeśli pamięć podręczna jest niedostępna. WzorzecCircuit-Breaker jest przydatny do obsługi tego scenariusza. Usługa udostępniająca pamięć podręczną można odzyskać i po udostępnieniu jej można ponownie wypełniać pamięć podręczną, ponieważ dane są odczytywane z oryginalnego magazynu danych, zgodnie ze strategią taką jak wzorzec z odkładania do pamięci podręcznej.
Jednak skalowalność systemu może mieć wpływ, jeśli aplikacja wróci do oryginalnego magazynu danych, gdy pamięć podręczna jest tymczasowo niedostępna. Gdy magazyn danych jest odzyskiwany, oryginalny magazyn danych może być zamazany żądaniami dotyczącymi danych, co powoduje przekroczenie limitu czasu i nieudane połączenia.
Rozważ zaimplementowanie lokalnej, prywatnej pamięci podręcznej w każdym wystąpieniu aplikacji wraz z udostępnioną pamięcią podręczną dostępną dla wszystkich wystąpień aplikacji. Gdy aplikacja pobiera element, może najpierw sprawdzić w lokalnej pamięci podręcznej, a następnie w udostępnionej pamięci podręcznej, a na koniec w oryginalnym magazynie danych. Lokalna pamięć podręczna może zostać wypełniona przy użyciu danych w udostępnionej pamięci podręcznej lub w bazie danych, jeśli udostępniona pamięć podręczna jest niedostępna.
Takie podejście wymaga starannej konfiguracji, aby zapobiec zbyt nieaktualności lokalnej pamięci podręcznej w odniesieniu do udostępnionej pamięci podręcznej. Jednak lokalna pamięć podręczna działa jako bufor, jeśli udostępniona pamięć podręczna jest niedostępna. Rysunek 3 przedstawia tę strukturę.
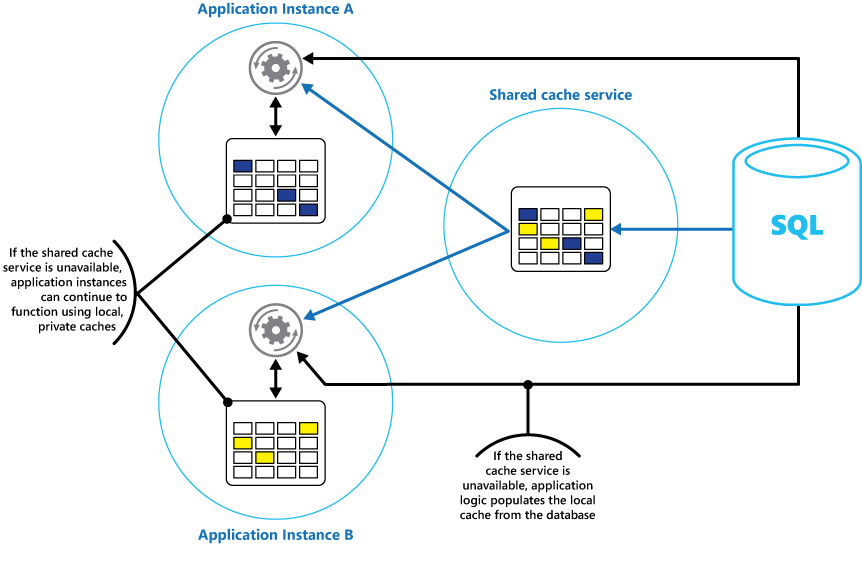
Rysunek 3. Używanie lokalnej prywatnej pamięci podręcznej z udostępnioną pamięcią podręczną.
Aby obsługiwać duże pamięci podręczne przechowujące stosunkowo długotrwałe dane, niektóre usługi pamięci podręcznej zapewniają opcję wysokiej dostępności, która implementuje automatyczne przełączanie w tryb failover, jeśli pamięć podręczna stanie się niedostępna. Takie podejście zwykle polega na replikowaniu buforowanych danych przechowywanych na serwerze podstawowej pamięci podręcznej na pomocniczym serwerze pamięci podręcznej i przełączaniu się na serwer pomocniczy, jeśli serwer podstawowy ulegnie awarii lub zostanie utracona łączność.
Aby zmniejszyć opóźnienie skojarzone z zapisywaniem w wielu miejscach docelowych, replikacja do serwera pomocniczego może wystąpić asynchronicznie, gdy dane są zapisywane w pamięci podręcznej na serwerze podstawowym. Takie podejście prowadzi do możliwości utraty niektórych buforowanych informacji, jeśli wystąpi awaria, ale odsetek tych danych powinien być niewielki w porównaniu z ogólnym rozmiarem pamięci podręcznej.
Jeśli udostępniona pamięć podręczna jest duża, korzystne może być podzielenie buforowanych danych między węzłami w celu zmniejszenia szans rywalizacji i zwiększenia skalowalności. Wiele udostępnionych pamięci podręcznych obsługuje możliwość dynamicznego dodawania (i usuwania) węzłów oraz ponownego równoważenia danych między partycjami. Takie podejście może obejmować klastrowanie, w którym kolekcja węzłów jest prezentowana aplikacjom klienckim jako bezproblemowa, pojedyncza pamięć podręczna. Jednak wewnętrznie dane są rozproszone między węzłami zgodnie ze wstępnie zdefiniowaną strategią dystrybucji, która równoważy obciążenie. Aby uzyskać więcej informacji na temat możliwych strategii partycjonowania, zobacz Wskazówki dotyczące partycjonowania danych.
Klastrowanie może również zwiększyć dostępność pamięci podręcznej. Jeśli węzeł ulegnie awarii, pozostała część pamięci podręcznej będzie nadal dostępna. Klastrowanie jest często używane w połączeniu z replikacją i trybem failover. Każdy węzeł można replikować, a replika może zostać szybko przełączona do trybu online, jeśli węzeł ulegnie awarii.
Wiele operacji odczytu i zapisu może obejmować pojedyncze wartości danych lub obiekty. Jednak czasami może być konieczne szybkie przechowywanie lub pobieranie dużych ilości danych. Na przykład rozmieszczanie pamięci podręcznej może obejmować zapisywanie setek lub tysięcy elementów w pamięci podręcznej. Aplikacja może również wymagać pobrania dużej liczby powiązanych elementów z pamięci podręcznej w ramach tego samego żądania.
Wiele pamięci podręcznych na dużą skalę zapewnia operacje wsadowe dla tych celów. Dzięki temu aplikacja kliencka może spakować dużą liczbę elementów do pojedynczego żądania i zmniejszyć obciążenie związane z wykonywaniem dużej liczby małych żądań.
Buforowanie i spójność ostateczna
Aby wzorzec odkładania do pamięci podręcznej działał, wystąpienie aplikacji, która wypełnia pamięć podręczną, musi mieć dostęp do najnowszej i spójnej wersji danych. W systemie, który implementuje spójność ostateczną (na przykład zreplikowany magazyn danych), może to nie być tak.
Jedno wystąpienie aplikacji może zmodyfikować element danych i unieważnić buforowana wersję tego elementu. Inne wystąpienie aplikacji może próbować odczytać ten element z pamięci podręcznej, co powoduje chybienie pamięci podręcznej, więc odczytuje dane z magazynu danych i dodaje go do pamięci podręcznej. Jeśli jednak magazyn danych nie został w pełni zsynchronizowany z innymi replikami, wystąpienie aplikacji może odczytywać i wypełniać pamięć podręczną starą wartością.
Aby uzyskać więcej informacji na temat obsługi spójności danych, zobacz Podstawy spójności danych.
Ochrona buforowanych danych
Niezależnie od używanej usługi pamięci podręcznej należy rozważyć sposób ochrony danych przechowywanych w pamięci podręcznej przed nieautoryzowanym dostępem. Istnieją dwa główne problemy:
- Prywatność danych w pamięci podręcznej.
- Prywatność danych przepływa między pamięcią podręczną a aplikacją korzystającą z pamięci podręcznej.
Aby chronić dane w pamięci podręcznej, usługa pamięci podręcznej może zaimplementować mechanizm uwierzytelniania, który wymaga określenia przez aplikacje następujących elementów:
- Które tożsamości mogą uzyskiwać dostęp do danych w pamięci podręcznej.
- Które operacje (odczyt i zapis) mogą wykonywać te tożsamości.
Aby zmniejszyć nakład pracy związany z odczytywaniem i zapisywaniem danych, po udzieleniu tożsamości dostępu do zapisu lub odczytu do pamięci podręcznej ta tożsamość może używać dowolnych danych w pamięci podręcznej.
Jeśli musisz ograniczyć dostęp do podzbiorów buforowanych danych, możesz wykonać jedną z następujących czynności:
- Podziel pamięć podręczną na partycje (przy użyciu różnych serwerów pamięci podręcznej) i przyznaj dostęp tylko tożsamościom dla partycji, które powinny być używane.
- Szyfruj dane w każdym podzestawie przy użyciu różnych kluczy i udostępniaj klucze szyfrowania tylko tożsamościom, które powinny mieć dostęp do każdego podzestawu. Aplikacja kliencka może nadal mieć możliwość pobrania wszystkich danych w pamięci podręcznej, ale będzie mogła odszyfrować tylko dane, dla których ma klucze.
Należy również chronić dane, gdy przepływają do i z pamięci podręcznej. W tym celu zależysz od funkcji zabezpieczeń udostępnianych przez infrastrukturę sieci używaną przez aplikacje klienckie do łączenia się z pamięcią podręczną. Jeśli pamięć podręczna jest implementowana przy użyciu serwera lokalnego w tej samej organizacji, która hostuje aplikacje klienckie, izolacja samej sieci może nie wymagać wykonania dodatkowych kroków. Jeśli pamięć podręczna znajduje się zdalnie i wymaga połączenia TCP lub HTTP za pośrednictwem sieci publicznej (takiej jak Internet), rozważ zaimplementowanie protokołu SSL.
Zagadnienia dotyczące implementowania buforowania na platformie Azure
Azure Cache for Redis to implementacja pamięci podręcznej Redis typu open source, która działa jako usługa w centrum danych platformy Azure. Udostępnia ona usługę buforowania, do których można uzyskać dostęp z dowolnej aplikacji platformy Azure, niezależnie od tego, czy aplikacja jest implementowana jako usługa w chmurze, witryna internetowa, czy wewnątrz maszyny wirtualnej platformy Azure. Pamięci podręczne mogą być współużytkowane przez aplikacje klienckie, które mają odpowiedni klucz dostępu.
Usługa Azure Cache for Redis to rozwiązanie do buforowania o wysokiej wydajności, które zapewnia dostępność, skalowalność i zabezpieczenia. Zazwyczaj działa jako usługa rozłożona na co najmniej jedną dedykowaną maszynę. Próbuje przechowywać jak najwięcej informacji w pamięci, aby zapewnić szybki dostęp. Ta architektura ma na celu zapewnienie małych opóźnień i wysokiej przepływności przez zmniejszenie konieczności wykonywania powolnych operacji we/wy.
Usługa Azure Cache for Redis jest zgodna z wieloma różnymi interfejsami API używanymi przez aplikacje klienckie. Jeśli masz istniejące aplikacje, które już korzystają z usługi Azure Cache for Redis działającej lokalnie, usługa Azure Cache for Redis udostępnia szybką ścieżkę migracji do buforowania w chmurze.
Funkcje usługi Redis
Usługa Redis to więcej niż prosty serwer pamięci podręcznej. Zapewnia rozproszoną bazę danych w pamięci z rozbudowanym zestawem poleceń obsługującym wiele typowych scenariuszy. Zostały one opisane w dalszej części tego dokumentu w sekcji Korzystanie z buforowania usługi Redis. Ta sekcja zawiera podsumowanie niektórych kluczowych funkcji oferowanych przez usługę Redis.
Redis jako baza danych w pamięci
Usługa Redis obsługuje operacje odczytu i zapisu. W usłudze Redis zapisy mogą być chronione przed awarią systemu przez okresowe przechowywanie w lokalnym pliku migawki lub w pliku dziennika tylko do dołączania. Taka sytuacja nie jest taka w przypadku wielu pamięci podręcznych, które należy traktować jako przejściowe magazyny danych.
Wszystkie operacje zapisu są asynchroniczne i nie blokują klientom odczytywania i zapisywania danych. Gdy usługa Redis zacznie działać, odczytuje dane z migawki lub pliku dziennika i używa ich do konstruowania pamięci podręcznej w pamięci. Aby uzyskać więcej informacji, zobacz Trwałość usługi Redis w witrynie internetowej usługi Redis.
Uwaga / Notatka
Usługa Redis nie gwarantuje, że wszystkie zapisy zostaną zapisane, jeśli wystąpi katastrofalna awaria, ale w najgorszym przypadku może utracić tylko kilka sekund wartości danych. Należy pamiętać, że pamięć podręczna nie jest przeznaczona do działania jako autorytatywne źródło danych i odpowiada za aplikacje korzystające z pamięci podręcznej w celu zapewnienia pomyślnego zapisania krytycznych danych w odpowiednim magazynie danych. Aby uzyskać więcej informacji, zobacz Wzorzec odkładania do pamięci podręcznej.
Typy danych usługi Redis
Redis to magazyn klucz-wartość, w którym wartości mogą zawierać proste typy lub złożone struktury danych, takie jak skróty, listy i zestawy. Obsługuje zestaw operacji niepodzielnych na tych typach danych. Klucze mogą być trwałe lub oznaczone ograniczonym czasem wygaśnięcia, w którym klucz i odpowiadająca mu wartość są automatycznie usuwane z pamięci podręcznej. Aby uzyskać więcej informacji na temat kluczy i wartości usługi Redis, odwiedź stronę Wprowadzenie do typów danych i abstrakcji usługi Redis w witrynie internetowej usługi Redis.
Replikacja i klastrowanie usługi Redis
Usługa Redis obsługuje replikację podstawową/podrzędną w celu zapewnienia dostępności i utrzymania przepływności. Operacje zapisu w węźle podstawowym usługi Redis są replikowane do co najmniej jednego węzła podrzędnego. Operacje odczytu mogą być obsługiwane przez element podstawowy lub dowolny z podwładnych.
Jeśli masz partycję sieciową, podwładni mogą nadal obsługiwać dane, a następnie w sposób przezroczysty ponownie synchronizować dane z podstawowymi elementami po ponownym utworzeniu połączenia. Aby uzyskać więcej informacji, odwiedź stronę Replikacja w witrynie internetowej usługi Redis.
Usługa Redis udostępnia również klastrowanie, które umożliwia przezroczyste partycjonowanie danych na fragmenty między serwerami i rozłożenie obciążenia. Ta funkcja zwiększa skalowalność, ponieważ nowe serwery Redis można dodawać, a dane są ponownie partycjonowane w miarę wzrostu rozmiaru pamięci podręcznej.
Ponadto każdy serwer w klastrze można replikować przy użyciu replikacji podstawowej/podrzędnej. Zapewnia to dostępność w każdym węźle w klastrze. Aby uzyskać więcej informacji na temat klastrowania i fragmentowania, odwiedź stronę samouczka klastra Redis w witrynie internetowej usługi Redis.
Użycie pamięci redis
Pamięć podręczna Redis Cache ma skończony rozmiar, który zależy od zasobów dostępnych na komputerze hosta. Podczas konfigurowania serwera Redis można określić maksymalną ilość pamięci, której może używać. Możesz również skonfigurować klucz w pamięci podręcznej Redis, aby mieć czas wygaśnięcia, po którym zostanie automatycznie usunięty z pamięci podręcznej. Ta funkcja może pomóc zapobiec wypełnianiu pamięci podręcznej w pamięci starymi lub nieaktualnymi danymi.
W miarę wypełniania pamięci usługa Redis może automatycznie eksmitować klucze i ich wartości, postępując zgodnie z wieloma zasadami. Wartość domyślna to LRU (co najmniej ostatnio używane), ale można również wybrać inne zasady, takie jak eksmitowanie kluczy losowo lub całkowite wyłączenie eksmisji (w tym przypadku próby dodania elementów do pamięci podręcznej kończą się niepowodzeniem, jeśli jest pełna). Strona Using Redis as an LRU cache (Używanie usługi Redis jako pamięci podręcznej LRU) zawiera więcej informacji.
Transakcje i partie usługi Redis
Usługa Redis umożliwia aplikacji klienckiej przesyłanie serii operacji odczytujących i zapisujących dane w pamięci podręcznej jako transakcji niepodzielnej. Wszystkie polecenia w transakcji są gwarantowane sekwencyjnie, a żadne polecenia wydane przez innych współbieżnych klientów nie będą połączone między nimi.
Jednak nie są to prawdziwe transakcje, ponieważ relacyjna baza danych je wykona. Przetwarzanie transakcji składa się z dwóch etapów — pierwszy polega na tym, że polecenia są kolejkowane, a drugi to czas uruchamiania poleceń. Podczas etapu kolejkowania poleceń polecenia, które składają się na transakcję, są przesyłane przez klienta. Jeśli w tym momencie wystąpi jakiś błąd (np. błąd składniowy lub nieprawidłowa liczba parametrów), usługa Redis odmawia przetworzenia całej transakcji i odrzuci ją.
W fazie uruchamiania usługa Redis wykonuje każde polecenie w kolejce w sekwencji. Jeśli polecenie zakończy się niepowodzeniem w tej fazie, usługa Redis będzie kontynuować wykonywanie następnego polecenia w kolejce i nie wycofa efektów żadnych poleceń, które zostały już uruchomione. Ta uproszczona forma transakcji pomaga zachować wydajność i uniknąć problemów z wydajnością, które są spowodowane rywalizacją.
Usługa Redis implementuje formę optymistycznego blokowania, aby pomóc w utrzymaniu spójności. Aby uzyskać szczegółowe informacje na temat transakcji i blokowania za pomocą usługi Redis, odwiedź stronę Transakcje w witrynie internetowej usługi Redis.
Usługa Redis obsługuje również nietransakcyjne przetwarzanie wsadowe żądań. Protokół Redis używany przez klientów do wysyłania poleceń do serwera Redis umożliwia klientowi wysyłanie serii operacji w ramach tego samego żądania. Może to pomóc zmniejszyć fragmentację pakietów w sieci. Po przetworzeniu partii każde polecenie jest wykonywane. Jeśli którekolwiek z tych poleceń jest źle sformułowane, zostaną odrzucone (co nie nastąpi z transakcją), ale pozostałe polecenia zostaną wykonane. Nie ma również gwarancji co do kolejności przetwarzania poleceń w partii.
Zabezpieczenia usługi Redis
Usługa Redis koncentruje się wyłącznie na zapewnianiu szybkiego dostępu do danych i jest przeznaczona do uruchamiania w zaufanym środowisku, do którego można uzyskiwać dostęp tylko przez zaufanych klientów. Usługa Redis obsługuje ograniczony model zabezpieczeń oparty na uwierzytelnianiu haseł. (Istnieje możliwość całkowitego usunięcia uwierzytelniania, chociaż nie zalecamy tego).
Wszyscy uwierzytelnieni klienci mają takie samo hasło globalne i mają dostęp do tych samych zasobów. Jeśli potrzebujesz bardziej kompleksowych zabezpieczeń logowania, musisz zaimplementować własną warstwę zabezpieczeń przed serwerem Redis, a wszystkie żądania klientów powinny przechodzić przez tę dodatkową warstwę. Usługa Redis nie powinna być bezpośrednio widoczna dla niezaufanych lub nieuwierzytelnionych klientów.
Dostęp do poleceń można ograniczyć, wyłączając je lub zmieniając ich nazwy (i podając tylko uprzywilejowanych klientów o nowych nazwach).
Usługa Redis nie obsługuje bezpośrednio żadnej formy szyfrowania danych, więc wszystkie kodowanie musi być wykonywane przez aplikacje klienckie. Ponadto usługa Redis nie zapewnia żadnej formy zabezpieczeń transportu. Jeśli musisz chronić dane podczas przepływu w sieci, zalecamy zaimplementowanie serwera proxy SSL.
Aby uzyskać więcej informacji, odwiedź stronę zabezpieczeń usługi Redis w witrynie internetowej usługi Redis.
Uwaga / Notatka
Usługa Azure Cache for Redis udostępnia własną warstwę zabezpieczeń, za pośrednictwem której klienci nawiązują połączenie. Podstawowe serwery Redis nie są widoczne w sieci publicznej.
Azure Redis Cache
Usługa Azure Cache for Redis zapewnia dostęp do serwerów Redis hostowanych w centrum danych platformy Azure. Działa jako fasada, która zapewnia kontrolę dostępu i zabezpieczenia. Pamięć podręczną można aprowizować przy użyciu witryny Azure Portal.
Portal udostępnia szereg wstępnie zdefiniowanych konfiguracji. Obejmują one 53 GB pamięci podręcznej działającej jako dedykowaną usługę, która obsługuje komunikację SSL (w celu zachowania prywatności) i replikację główną/podrzędną z umową dotyczącą poziomu usług (SLA) z 99,9% dostępności, do 250 MB pamięci podręcznej bez replikacji (bez gwarancji dostępności) uruchomionych na udostępnionym sprzęcie.
Za pomocą witryny Azure Portal można również skonfigurować zasady eksmisji pamięci podręcznej i kontrolować dostęp do pamięci podręcznej, dodając użytkowników do udostępnionych ról. Te role, które definiują operacje, które mogą wykonywać członkowie, obejmują właściciela, współautora i czytelnika. Na przykład członkowie roli Właściciel mają pełną kontrolę nad pamięcią podręczną (w tym zabezpieczeniami) i jej zawartością, członkowie roli Współautor mogą odczytywać i zapisywać informacje w pamięci podręcznej, a członkowie roli Czytelnik mogą pobierać tylko dane z pamięci podręcznej.
Większość zadań administracyjnych jest wykonywanych za pośrednictwem witryny Azure Portal. Z tego powodu wiele poleceń administracyjnych dostępnych w standardowej wersji usługi Redis nie jest dostępnych, w tym możliwość programowego modyfikowania konfiguracji, zamykania serwera Redis, konfigurowania dodatkowych podwładnych lub wymuszania zapisywania danych na dysku.
Witryna Azure Portal zawiera wygodny graficzny ekran, który umożliwia monitorowanie wydajności pamięci podręcznej. Można na przykład wyświetlić liczbę wykonanych połączeń, liczbę wykonywanych żądań, liczbę operacji odczytu i zapisu oraz liczbę trafień pamięci podręcznej w porównaniu z błędami pamięci podręcznej. Korzystając z tych informacji, możesz określić skuteczność pamięci podręcznej i w razie potrzeby przełączyć się na inną konfigurację lub zmienić zasady eksmisji.
Ponadto możesz utworzyć alerty, które wysyłają wiadomości e-mail do administratora, jeśli co najmniej jedna metryka krytyczna wykracza poza oczekiwany zakres. Na przykład możesz chcieć powiadomić administratora, jeśli liczba nieodebranych pamięci podręcznych przekroczy określoną wartość w ciągu ostatniej godziny, ponieważ oznacza to, że pamięć podręczna może być zbyt mała lub dane mogą być zbyt szybko eksmitowane.
Można również monitorować użycie procesora CPU, pamięci i sieci dla pamięci podręcznej.
Aby uzyskać więcej informacji i przykładów pokazujących, jak utworzyć i skonfigurować usługę Azure Cache for Redis, odwiedź stronę Lap around Azure Cache for Redis (Okrążenie usługi Azure Cache for Redis) w blogu platformy Azure.
Stan sesji buforowania i dane wyjściowe HTML
Jeśli tworzysz ASP.NET aplikacje internetowe uruchamiane przy użyciu ról internetowych platformy Azure, możesz zapisać informacje o stanie sesji i dane wyjściowe HTML w usłudze Azure Cache for Redis. Dostawca stanu sesji dla usługi Azure Cache for Redis umożliwia udostępnianie informacji o sesji między różnymi wystąpieniami aplikacji internetowej ASP.NET i jest bardzo przydatny w sytuacjach farmy internetowej, w których koligacja klient-serwer nie jest dostępna, a buforowanie danych sesji w pamięci nie byłoby odpowiednie.
Korzystanie z dostawcy stanu sesji z usługą Azure Cache for Redis zapewnia kilka korzyści, w tym:
- Udostępnianie stanu sesji przy użyciu dużej liczby wystąpień aplikacji internetowych ASP.NET.
- Zapewnienie ulepszonej skalowalności.
- Obsługa kontrolowanego, współbieżnego dostępu do tych samych danych stanu sesji dla wielu czytelników i jednego modułu zapisywania.
- Użycie kompresji w celu zaoszczędzenia pamięci i zwiększenia wydajności sieci.
Aby uzyskać więcej informacji, zobacz dostawca stanu sesji ASP.NET dla usługi Azure Cache for Redis.
Uwaga / Notatka
Nie używaj dostawcy stanu sesji dla usługi Azure Cache for Redis z aplikacjami ASP.NET uruchomionymi poza środowiskiem platformy Azure. Opóźnienie uzyskiwania dostępu do pamięci podręcznej spoza platformy Azure może wyeliminować korzyści z wydajności buforowania danych.
Podobnie dostawca wyjściowej pamięci podręcznej dla usługi Azure Cache for Redis umożliwia zapisywanie odpowiedzi HTTP generowanych przez aplikację internetową ASP.NET. Użycie dostawcy wyjściowej pamięci podręcznej z usługą Azure Cache for Redis może poprawić czas odpowiedzi aplikacji renderujących złożone dane wyjściowe HTML. Wystąpienia aplikacji generujące podobne odpowiedzi mogą używać udostępnionych fragmentów danych wyjściowych w pamięci podręcznej, a nie generowania tych danych wyjściowych HTML na nowo. Aby uzyskać więcej informacji, zobacz dostawca ASP.NET wyjściowej pamięci podręcznej dla usługi Azure Cache for Redis.
Tworzenie niestandardowej pamięci podręcznej Redis
Usługa Azure Cache for Redis działa jako fasada bazowych serwerów Redis. Jeśli potrzebujesz zaawansowanej konfiguracji, która nie jest objęta pamięcią podręczną Azure Redis Cache (np. pamięci podręcznej większej niż 53 GB), możesz skompilować i hostować własne serwery Redis przy użyciu usługi Azure Virtual Machines.
Jest to potencjalnie złożony proces, ponieważ może być konieczne utworzenie kilku maszyn wirtualnych do działania jako węzły podstawowe i podrzędne, jeśli chcesz zaimplementować replikację. Ponadto jeśli chcesz utworzyć klaster, potrzebujesz wielu prawyborów i serwerów podrzędnych. Minimalna topologia replikacji klastrowanej zapewniająca wysoki stopień dostępności i skalowalności obejmuje co najmniej sześć maszyn wirtualnych zorganizowanych jako trzy pary serwerów podstawowych/podrzędnych (klaster musi zawierać co najmniej trzy węzły podstawowe).
Każda para podstawowa/podrzędna powinna znajdować się blisko siebie, aby zminimalizować opóźnienie. Jednak każdy zestaw par może być uruchomiony w różnych centrach danych platformy Azure znajdujących się w różnych regionach, jeśli chcesz zlokalizować buforowane dane w pobliżu aplikacji, które najprawdopodobniej będą z nich korzystać. Aby zapoznać się z przykładem kompilowania i konfigurowania węzła Redis uruchomionego jako maszyna wirtualna platformy Azure, zobacz Running Redis on a CentOS Linux VM in Azure (Uruchamianie usługi Redis na maszynie wirtualnej z systemem CentOS Linux na platformie Azure).
Uwaga / Notatka
Jeśli w ten sposób zaimplementujesz własną pamięć podręczną Redis Cache, odpowiadasz za monitorowanie i zabezpieczanie usługi oraz zarządzanie nią.
Partycjonowanie pamięci podręcznej Redis Cache
Partycjonowanie pamięci podręcznej obejmuje podzielenie pamięci podręcznej między wiele komputerów. Ta struktura zapewnia kilka zalet korzystania z pojedynczego serwera pamięci podręcznej, w tym:
- Tworzenie pamięci podręcznej, która jest znacznie większa niż można przechowywać na jednym serwerze.
- Dystrybucja danych między serwerami, poprawa dostępności. Jeśli jeden serwer ulegnie awarii lub stanie się niedostępny, dane przechowywane są niedostępne, ale dane na pozostałych serwerach będą nadal dostępne. W przypadku pamięci podręcznej nie ma to kluczowego znaczenia, ponieważ buforowane dane są tylko przejściową kopią danych przechowywanych w bazie danych. Buforowane dane na serwerze, który staje się niedostępny, można zamiast tego buforować na innym serwerze.
- Rozłożenie obciążenia między serwerami, co zwiększa wydajność i skalowalność.
- Geolokowanie danych blisko użytkowników, którzy do niego uzyskują dostęp, co zmniejsza opóźnienie.
W przypadku pamięci podręcznej najbardziej typową formą partycjonowania jest dzielenie na fragmenty. W tej strategii każda partycja (lub fragment) jest pamięcią podręczną Redis cache samodzielnie. Dane są kierowane do określonej partycji przy użyciu logiki fragmentowania, która może użyć różnych metod dystrybucji danych. Wzorzec fragmentowania zawiera więcej informacji na temat implementowania fragmentowania.
Aby zaimplementować partycjonowanie w pamięci podręcznej Redis Cache, można wykonać jedną z następujących metod:
- Routing zapytań po stronie serwera. W tej technice aplikacja kliencka wysyła żądanie do dowolnego z serwerów Redis, które składają się na pamięć podręczną (prawdopodobnie najbliższy serwer). Każdy serwer Redis przechowuje metadane opisujące przechowywaną partycję, a także informacje o tym, które partycje znajdują się na innych serwerach. Serwer Redis sprawdza żądanie klienta. Jeśli można go rozpoznać lokalnie, wykona żądaną operację. W przeciwnym razie przekaże żądanie do odpowiedniego serwera. Ten model jest implementowany przez klaster usługi Redis i opisano go bardziej szczegółowo na stronie samouczka klastra Redis w witrynie internetowej usługi Redis. Klastrowanie usługi Redis jest niewidoczne dla aplikacji klienckich, a dodatkowe serwery Redis można dodawać do klastra (i partycjonowane dane) bez konieczności ponownego konfigurowania klientów.
- Partycjonowanie po stronie klienta. W tym modelu aplikacja kliencka zawiera logikę (prawdopodobnie w postaci biblioteki), która kieruje żądania do odpowiedniego serwera Redis. Tego podejścia można użyć z usługą Azure Cache for Redis. Utwórz wiele usługi Azure Cache for Redis (po jednej dla każdej partycji danych) i zaimplementuj logikę po stronie klienta, która kieruje żądania do poprawnej pamięci podręcznej. Jeśli schemat partycjonowania ulegnie zmianie (jeśli na przykład zostanie utworzona dodatkowa usługa Azure Cache for Redis), aplikacje klienckie mogą wymagać ponownej konfiguracji.
- Partycjonowanie wspomagane przez serwer proxy. W tym schemacie aplikacje klienckie wysyłają żądania do usługi pośredniczącego serwera proxy, która rozumie sposób partycjonowania danych, a następnie kieruje żądanie do odpowiedniego serwera Redis. Tego podejścia można również użyć z usługą Azure Cache for Redis; usługę proxy można zaimplementować jako usługę w chmurze platformy Azure. Takie podejście wymaga dodatkowego poziomu złożoności w celu zaimplementowania usługi, a żądania mogą trwać dłużej niż przy użyciu partycjonowania po stronie klienta.
Strona Partycjonowanie: sposób dzielenia danych między wiele wystąpień usługi Redis w witrynie internetowej usługi Redis zawiera więcej informacji na temat implementowania partycjonowania za pomocą usługi Redis.
Implementowanie aplikacji klienckich pamięci podręcznej Redis Cache
Usługa Redis obsługuje aplikacje klienckie napisane w wielu językach programowania. Jeśli tworzysz nowe aplikacje przy użyciu programu .NET Framework, zalecamy użycie biblioteki klienta StackExchange.Redis. Ta biblioteka zawiera model obiektów programu .NET Framework, który abstrahuje szczegóły dotyczące nawiązywania połączenia z serwerem Redis, wysyłania poleceń i odbierania odpowiedzi. Jest ona dostępna w programie Visual Studio jako pakiet NuGet. Tej samej biblioteki można używać do nawiązywania połączenia z usługą Azure Cache for Redis lub niestandardową pamięcią podręczną Redis hostowaną na maszynie wirtualnej.
Aby nawiązać połączenie z serwerem Redis, użyj metody statycznej ConnectConnectionMultiplexer klasy . Połączenie tworzone przez tę metodę jest przeznaczone do użycia przez cały okres istnienia aplikacji klienckiej, a to samo połączenie może być używane przez wiele współbieżnych wątków. Nie należy ponownie łączyć się i rozłączać za każdym razem, gdy wykonujesz operację redis, ponieważ może to obniżyć wydajność.
Możesz określić parametry połączenia, takie jak adres hosta Redis i hasło. Jeśli używasz usługi Azure Cache for Redis, hasło jest kluczem podstawowym lub pomocniczym generowanym dla usługi Azure Cache for Redis przy użyciu witryny Azure Portal.
Po nawiązaniu połączenia z serwerem Redis można uzyskać dojście do bazy danych Redis, która działa jako pamięć podręczna. Połączenie usługi Redis udostępnia metodę GetDatabase w tym celu. Następnie możesz pobrać elementy z pamięci podręcznej i przechowywać dane w pamięci podręcznej przy użyciu StringGet metod i StringSet . Metody te oczekują klucza jako parametru i zwracają element w pamięci podręcznej, która ma zgodną wartość (StringGet) lub dodaj element do pamięci podręcznej przy użyciu tego klucza (StringSet).
W zależności od lokalizacji serwera Redis wiele operacji może spowodować pewne opóźnienie podczas przesyłania żądania do serwera, a odpowiedź jest zwracana do klienta. Biblioteka StackExchange udostępnia asynchroniczne wersje wielu metod, które uwidacznia, aby ułatwić aplikacjom klienckim reagowanie. Te metody obsługują wzorzec asynchroniczny oparty na zadaniach w programie .NET Framework.
Poniższy fragment kodu przedstawia metodę o nazwie RetrieveItem. Ilustruje implementację wzorca z odkładania do pamięci podręcznej na podstawie usługi Redis i biblioteki StackExchange. Metoda przyjmuje wartość klucza ciągu i próbuje pobrać odpowiedni element z pamięci podręcznej Redis, wywołując StringGetAsync metodę (asynchroniczną wersję StringGetelementu ).
Jeśli element nie zostanie znaleziony, zostanie pobrany z bazowego źródła danych przy użyciu GetItemFromDataSourceAsync metody (która jest metodą lokalną, a nie częścią biblioteki StackExchange). Następnie jest dodawany do pamięci podręcznej przy użyciu StringSetAsync metody , aby można było go pobrać szybciej następnym razem.
// Connect to the Azure Redis cache
ConfigurationOptions config = new ConfigurationOptions();
config.EndPoints.Add("<your DNS name>.redis.cache.windows.net");
config.Password = "<Redis cache key from management portal>";
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase cache = redisHostConnection.GetDatabase();
...
private async Task<string> RetrieveItem(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await cache.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue == null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await cache.StringSetAsync(itemKey, itemValue);
}
// Return the item
return itemValue;
}
Metody StringGet i StringSet nie są ograniczone do pobierania ani przechowywania wartości ciągów. Mogą przyjmować dowolny element, który jest serializowany jako tablica bajtów. Jeśli musisz zapisać obiekt platformy .NET, możesz serializować go jako strumień bajtów i użyć StringSet metody , aby zapisać go w pamięci podręcznej.
Podobnie można odczytać obiekt z pamięci podręcznej przy użyciu StringGet metody i deserializować go jako obiekt platformy .NET. Poniższy kod przedstawia zestaw metod rozszerzenia dla interfejsu IDatabase ( GetDatabase metoda połączenia redis zwraca IDatabase obiekt) i przykładowy kod, który używa tych metod do odczytywania i zapisywania BlogPost obiektu w pamięci podręcznej:
public static class RedisCacheExtensions
{
public static async Task<T> GetAsync<T>(this IDatabase cache, string key)
{
return Deserialize<T>(await cache.StringGetAsync(key));
}
public static async Task<object> GetAsync(this IDatabase cache, string key)
{
return Deserialize<object>(await cache.StringGetAsync(key));
}
public static async Task SetAsync(this IDatabase cache, string key, object value)
{
await cache.StringSetAsync(key, Serialize(value));
}
static byte[] Serialize(object o)
{
byte[] objectDataAsStream = null;
if (o != null)
{
var jsonString = JsonSerializer.Serialize(o);
objectDataAsStream = Encoding.ASCII.GetBytes(jsonString);
}
return objectDataAsStream;
}
static T Deserialize<T>(byte[] stream)
{
T result = default(T);
if (stream != null)
{
var jsonString = Encoding.ASCII.GetString(stream);
result = JsonSerializer.Deserialize<T>(jsonString);
}
return result;
}
}
Poniższy kod ilustruje metodę o nazwie RetrieveBlogPost , która używa tych metod rozszerzenia do odczytu i zapisu obiektu z możliwością BlogPost serializacji do pamięci podręcznej zgodnie ze wzorcem odkładania do pamięci podręcznej:
// The BlogPost type
public class BlogPost
{
private HashSet<string> tags;
public BlogPost(int id, string title, int score, IEnumerable<string> tags)
{
this.Id = id;
this.Title = title;
this.Score = score;
this.tags = new HashSet<string>(tags);
}
public int Id { get; set; }
public string Title { get; set; }
public int Score { get; set; }
public ICollection<string> Tags => this.tags;
}
...
private async Task<BlogPost> RetrieveBlogPost(string blogPostKey)
{
BlogPost blogPost = await cache.GetAsync<BlogPost>(blogPostKey);
if (blogPost == null)
{
blogPost = await GetBlogPostFromDataSourceAsync(blogPostKey);
await cache.SetAsync(blogPostKey, blogPost);
}
return blogPost;
}
Usługa Redis obsługuje potokowanie poleceń, jeśli aplikacja kliencka wysyła wiele żądań asynchronicznych. Usługa Redis może multipleksować żądania przy użyciu tego samego połączenia, a nie odbierać poleceń i odpowiadać na nie w ścisłej kolejności.
Takie podejście pomaga zmniejszyć opóźnienia dzięki bardziej wydajnemu wykorzystaniu sieci. Poniższy fragment kodu przedstawia przykład, który pobiera szczegóły dwóch klientów jednocześnie. Kod przesyła dwa żądania, a następnie wykonuje inne przetwarzanie (nie pokazane) przed oczekiwaniem na otrzymanie wyników.
Wait Metoda obiektu pamięci podręcznej jest podobna do metody .NET FrameworkTask.Wait:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
var task1 = cache.StringGetAsync("customer:1");
var task2 = cache.StringGetAsync("customer:2");
...
var customer1 = cache.Wait(task1);
var customer2 = cache.Wait(task2);
Aby uzyskać dodatkowe informacje na temat pisania aplikacji klienckich, które mogą używać usługi Azure Cache for Redis, zobacz dokumentację usługi Azure Cache for Redis. Więcej informacji można również znaleźć w witrynie StackExchange.Redis.
Strona Potoki i multipleksery w tej samej witrynie internetowej zawiera więcej informacji na temat operacji asynchronicznych i potoków przy użyciu usługi Redis i biblioteki StackExchange.
Korzystanie z buforowania usługi Redis
Najprostszym zastosowaniem usługi Redis do buforowania jest pary klucz-wartość, w których wartość jest niezinterpretowanym ciągiem dowolnej długości, który może zawierać dowolne dane binarne. (Zasadniczo jest to tablica bajtów, które mogą być traktowane jako ciąg). Ten scenariusz został przedstawiony w sekcji Implementowanie aplikacji klienckich pamięci podręcznej Redis Cache we wcześniejszej części tego artykułu.
Należy pamiętać, że klucze zawierają również niezinterpretowane dane, dzięki czemu można użyć dowolnych informacji binarnych jako klucza. Tym dłuższy jest jednak czas przechowywania klucza, tym więcej miejsca zajmie, a tym dłużej będzie trzeba wykonywać operacje wyszukiwania. W celu zapewnienia użyteczności i łatwości konserwacji należy starannie zaprojektować przestrzeń kluczy i używać znaczących (ale nie pełnych) kluczy.
Na przykład użyj kluczy strukturalnych, takich jak "customer:100", aby reprezentować klucz klienta o identyfikatorze 100, a nie po prostu "100". Ten schemat umożliwia łatwe rozróżnienie między wartościami, które przechowują różne typy danych. Można na przykład użyć klucza "orders:100", aby reprezentować klucz zamówienia o identyfikatorze 100.
Oprócz jednowymiarowych ciągów binarnych wartość pary klucz-wartość usługi Redis może również przechowywać więcej informacji strukturalnych, w tym listy, zestawy (posortowane i niesortowane) oraz skróty. Usługa Redis udostępnia kompleksowy zestaw poleceń, który może manipulować tymi typami, a wiele z tych poleceń jest dostępnych dla aplikacji .NET Framework za pośrednictwem biblioteki klienta, takiej jak StackExchange. Strona Wprowadzenie do typów danych i abstrakcji usługi Redis w witrynie internetowej usługi Redis zawiera bardziej szczegółowe omówienie tych typów oraz poleceń, których można użyć do manipulowania nimi.
W tej sekcji podsumowano niektóre typowe przypadki użycia dla tych typów danych i poleceń.
Wykonywanie operacji niepodzielnych i wsadowych
Usługa Redis obsługuje serię niepodzielnych operacji get-and-set na wartościach ciągów. Te operacje usuwają możliwe zagrożenia wyścigu, które mogą wystąpić podczas używania oddzielnych GET poleceń i SET . Dostępne operacje obejmują:
INCR, ,INCRBYDECRiDECRBY, które wykonują niepodzielne operacje przyrostowe i dekrementacji na wartościach danych liczbowych liczb całkowitych. Biblioteka StackExchange udostępnia przeciążone wersjeIDatabase.StringIncrementAsyncmetod iIDatabase.StringDecrementAsyncdo wykonywania tych operacji i zwraca wynikowej wartości przechowywanej w pamięci podręcznej. Poniższy fragment kodu ilustruje sposób użycia tych metod:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... await cache.StringSetAsync("data:counter", 99); ... long oldValue = await cache.StringIncrementAsync("data:counter"); // Increment by 1 (the default) // oldValue should be 100 long newValue = await cache.StringDecrementAsync("data:counter", 50); // Decrement by 50 // newValue should be 50GETSET, który pobiera wartość skojarzona z kluczem i zmienia ją na nową wartość. Biblioteka StackExchange udostępnia tę operacjęIDatabase.StringGetSetAsyncza pośrednictwem metody . Poniższy fragment kodu przedstawia przykład tej metody. Ten kod zwraca bieżącą wartość skojarzona z kluczem "data:counter" z poprzedniego przykładu. Następnie resetuje wartość tego klucza z powrotem do zera, wszystkie w ramach tej samej operacji:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... string oldValue = await cache.StringGetSetAsync("data:counter", 0);MGETiMSET, które mogą zwracać lub zmieniać zestaw wartości ciągu jako pojedynczą operację. MetodyIDatabase.StringGetAsynciIDatabase.StringSetAsyncsą przeciążone w celu obsługi tej funkcji, jak pokazano w poniższym przykładzie:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... // Create a list of key-value pairs var keysAndValues = new List<KeyValuePair<RedisKey, RedisValue>>() { new KeyValuePair<RedisKey, RedisValue>("data:key1", "value1"), new KeyValuePair<RedisKey, RedisValue>("data:key99", "value2"), new KeyValuePair<RedisKey, RedisValue>("data:key322", "value3") }; // Store the list of key-value pairs in the cache cache.StringSet(keysAndValues.ToArray()); ... // Find all values that match a list of keys RedisKey[] keys = { "data:key1", "data:key99", "data:key322"}; // values should contain { "value1", "value2", "value3" } RedisValue[] values = cache.StringGet(keys);
Można również połączyć wiele operacji w jedną transakcję Redis zgodnie z opisem w sekcji Transakcje i partie usługi Redis we wcześniejszej części tego artykułu. Biblioteka StackExchange zapewnia obsługę transakcji za pośrednictwem interfejsu ITransaction .
Obiekt można utworzyć ITransaction przy użyciu IDatabase.CreateTransaction metody . Polecenia są wywoływane do transakcji przy użyciu metod dostarczonych przez ITransaction obiekt .
Interfejs ITransaction zapewnia dostęp do zestawu metod podobnych do tych, do których uzyskuje się dostęp za pomocą interfejsu IDatabase , z tą różnicą, że wszystkie metody są asynchroniczne. Oznacza to, że są wykonywane tylko po wywołaniu ITransaction.Execute metody. Wartość zwrócona przez metodę ITransaction.Execute wskazuje, czy transakcja została utworzona pomyślnie (prawda), czy też zakończyła się niepowodzeniem (false).
Poniższy fragment kodu przedstawia przykład, który zwiększa i dekrementuje dwa liczniki w ramach tej samej transakcji:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = transaction.Execute();
Console.WriteLine("Transaction {0}", result ? "succeeded" : "failed");
Console.WriteLine("Result of increment: {0}", tx1.Result);
Console.WriteLine("Result of decrement: {0}", tx2.Result);
Pamiętaj, że transakcje usługi Redis są w przeciwieństwie do transakcji w relacyjnych bazach danych. Metoda Execute po prostu kolejkuje wszystkie polecenia, które składają się na transakcję do uruchomienia, a jeśli którykolwiek z nich jest źle sformułowany, transakcja zostanie zatrzymana. Jeśli wszystkie polecenia zostały pomyślnie kolejkowane, każde polecenie jest uruchamiane asynchronicznie.
Jeśli jakiekolwiek polecenie zakończy się niepowodzeniem, inne nadal kontynuują przetwarzanie. Jeśli musisz sprawdzić, czy polecenie zostało ukończone pomyślnie, musisz pobrać wyniki polecenia przy użyciu właściwości Result odpowiedniego zadania, jak pokazano w powyższym przykładzie. Odczytywanie właściwości Result spowoduje zablokowanie wątek wywołujący do momentu ukończenia zadania.
Aby uzyskać więcej informacji, zobacz Transakcje w usłudze Redis.
Podczas wykonywania operacji wsadowych można użyć IBatch interfejsu biblioteki StackExchange. Ten interfejs zapewnia dostęp do zestawu metod podobnych do tych, do których uzyskuje się dostęp za pomocą interfejsu IDatabase , z tą różnicą, że wszystkie metody są asynchroniczne.
Obiekt można IBatch utworzyć przy użyciu IDatabase.CreateBatch metody , a następnie uruchomić partię przy użyciu IBatch.Execute metody , jak pokazano w poniższym przykładzie. Ten kod po prostu ustawia wartość ciągu, zwiększa i dekrementuje te same liczniki używane w poprzednim przykładzie i wyświetla wyniki:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
IBatch batch = cache.CreateBatch();
batch.StringSetAsync("data:key1", 11);
var t1 = batch.StringIncrementAsync("data:counter1");
var t2 = batch.StringDecrementAsync("data:counter2");
batch.Execute();
Console.WriteLine("{0}", t1.Result);
Console.WriteLine("{0}", t2.Result);
Ważne jest, aby zrozumieć, że w przeciwieństwie do transakcji, jeśli polecenie w partii nie powiedzie się, ponieważ jest źle sformułowane, inne polecenia mogą nadal działać. Metoda IBatch.Execute nie zwraca żadnych wskazówek dotyczących powodzenia ani niepowodzenia.
Wykonywanie operacji wyzwalania i zapominania o pamięci podręcznej
Usługa Redis obsługuje operacje wyzwalania i zapominania przy użyciu flag poleceń. W takiej sytuacji klient po prostu inicjuje operację, ale nie interesuje się wynikiem i nie czeka na ukończenie polecenia. W poniższym przykładzie pokazano, jak wykonać polecenie INCR jako ogień i zapomnieć operacji:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
Określanie automatycznie wygasających kluczy
Podczas przechowywania elementu w pamięci podręcznej Redis można określić limit czasu, po którym element zostanie automatycznie usunięty z pamięci podręcznej. Możesz również wykonać zapytanie, ile więcej czasu ma klucz przed jego wygaśnięciem TTL , używając polecenia . To polecenie jest dostępne dla aplikacji StackExchange przy użyciu IDatabase.KeyTimeToLive metody .
Poniższy fragment kodu pokazuje, jak ustawić czas wygaśnięcia 20 sekund na kluczu i wysłać zapytanie o pozostały okres istnienia klucza:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns a null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
Możesz również ustawić czas wygaśnięcia na określoną datę i godzinę przy użyciu polecenia EXPIRE, które jest dostępne w bibliotece StackExchange jako metodę KeyExpireAsync :
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration date of midnight on 1st January 2015
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2015, 1, 1, 0, 0, 0, DateTimeKind.Utc));
...
Wskazówka
Element z pamięci podręcznej można usunąć ręcznie przy użyciu polecenia DEL, które jest dostępne za pośrednictwem biblioteki StackExchange jako IDatabase.KeyDeleteAsync metody.
Używanie tagów do skorelowania elementów buforowanych
Zestaw usługi Redis to kolekcja wielu elementów, które współużytkuje jeden klucz. Zestaw można utworzyć przy użyciu polecenia SADD. Elementy w zestawie można pobrać przy użyciu polecenia SMEMBERS. Biblioteka StackExchange implementuje polecenie SADD za pomocą IDatabase.SetAddAsync metody , a polecenie SMEMBERS za pomocą IDatabase.SetMembersAsync metody .
Istniejące zestawy można również połączyć w celu utworzenia nowych zestawów przy użyciu poleceń SDIFF (różnica zestawu), SINTER (set intersection) i SUNION (set union). Biblioteka StackExchange łączy te operacje w metodzie IDatabase.SetCombineAsync . Pierwszy parametr tej metody określa operację zestawu do wykonania.
Poniższe fragmenty kodu pokazują, jak zestawy mogą być przydatne do szybkiego przechowywania i pobierania kolekcji powiązanych elementów. Ten kod używa typu opisanego BlogPost w sekcji Implementowanie aplikacji klienckich pamięci podręcznej Redis Cache we wcześniejszej części tego artykułu.
BlogPost Obiekt zawiera cztery pola — identyfikator, tytuł, wynik klasyfikacji i kolekcję tagów. Pierwszy fragment kodu poniżej przedstawia przykładowe dane używane do wypełniania listy BlogPost obiektów w języku C#:
List<string[]> tags = new List<string[]>
{
new[] { "iot","csharp" },
new[] { "iot","azure","csharp" },
new[] { "csharp","git","big data" },
new[] { "iot","git","database" },
new[] { "database","git" },
new[] { "csharp","database" },
new[] { "iot" },
new[] { "iot","database","git" },
new[] { "azure","database","big data","git","csharp" },
new[] { "azure" }
};
List<BlogPost> posts = new List<BlogPost>();
int blogKey = 0;
int numberOfPosts = 20;
Random random = new Random();
for (int i = 0; i < numberOfPosts; i++)
{
blogKey++;
posts.Add(new BlogPost(
blogKey, // Blog post ID
string.Format(CultureInfo.InvariantCulture, "Blog Post #{0}",
blogKey), // Blog post title
random.Next(100, 10000), // Ranking score
tags[i % tags.Count])); // Tags--assigned from a collection
// in the tags list
}
Tagi dla każdego BlogPost obiektu można przechowywać jako zestaw w pamięci podręcznej Redis Cache i kojarzyć każdy zestaw z identyfikatorem BlogPost. Dzięki temu aplikacja może szybko znaleźć wszystkie tagi należące do określonego wpisu w blogu. Aby włączyć wyszukiwanie w przeciwnym kierunku i znaleźć wszystkie wpisy w blogu, które udostępniają określony tag, możesz utworzyć inny zestaw, który zawiera wpisy w blogu odwołujące się do identyfikatora tagu w kluczu:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Tags are easily represented as Redis Sets
foreach (BlogPost post in posts)
{
string redisKey = string.Format(CultureInfo.InvariantCulture,
"blog:posts:{0}:tags", post.Id);
// Add tags to the blog post in Redis
await cache.SetAddAsync(
redisKey, post.Tags.Select(s => (RedisValue)s).ToArray());
// Now do the inverse so we can figure out which blog posts have a given tag
foreach (var tag in post.Tags)
{
await cache.SetAddAsync(string.Format(CultureInfo.InvariantCulture,
"tag:{0}:blog:posts", tag), post.Id);
}
}
Struktury te umożliwiają bardzo wydajne wykonywanie wielu typowych zapytań. Na przykład możesz znaleźć i wyświetlić wszystkie tagi dla wpisu w blogu 1 w następujący sposób:
// Show the tags for blog post #1
foreach (var value in await cache.SetMembersAsync("blog:posts:1:tags"))
{
Console.WriteLine(value);
}
Wszystkie tagi wspólne dla wpisu w blogu 1 i wpisu w blogu 2 można znaleźć, wykonując operację na przecięciu zestawu w następujący sposób:
// Show the tags in common for blog posts #1 and #2
foreach (var value in await cache.SetCombineAsync(SetOperation.Intersect, new RedisKey[]
{ "blog:posts:1:tags", "blog:posts:2:tags" }))
{
Console.WriteLine(value);
}
Możesz również znaleźć wszystkie wpisy w blogu zawierające określony tag:
// Show the ids of the blog posts that have the tag "iot".
foreach (var value in await cache.SetMembersAsync("tag:iot:blog:posts"))
{
Console.WriteLine(value);
}
Znajdowanie ostatnio używanych elementów
Typowym zadaniem wymaganym przez wiele aplikacji jest znalezienie ostatnio używanych elementów. Na przykład witryna blogów może chcieć wyświetlić informacje o ostatnio przeczytanych wpisach w blogu.
Tę funkcję można zaimplementować przy użyciu listy usługi Redis. Lista usługi Redis zawiera wiele elementów, które współdzielą ten sam klucz. Lista działa jako podwójna kolejka. Elementy można wypchnąć na końcu listy przy użyciu poleceń LPUSH (wypychanie w lewo) i RPUSH (wypychanie po prawej stronie). Elementy można pobrać z dowolnego końca listy przy użyciu poleceń LPOP i RPOP. Zestaw elementów można również zwrócić przy użyciu poleceń LRANGE i RRANGE.
Poniższe fragmenty kodu pokazują, jak można wykonywać te operacje przy użyciu biblioteki StackExchange. Ten kod używa BlogPost typu z poprzednich przykładów. Jako wpis w blogu jest odczytywany przez użytkownika, IDatabase.ListLeftPushAsync metoda wypycha tytuł wpisu w blogu do listy skojarzonej z kluczem "blog:recent_posts" w pamięci podręcznej Redis.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:recent_posts";
BlogPost blogPost = ...; // Reference to the blog post that has just been read
await cache.ListLeftPushAsync(
redisKey, blogPost.Title); // Push the blog post onto the list
W miarę odczytywania kolejnych wpisów w blogu ich tytuły są wypychane na tę samą listę. Lista jest uporządkowana przez sekwencję, w której dodano tytuły. Ostatnio przeczytane wpisy w blogu znajdują się na lewym końcu listy. (Jeśli ten sam wpis w blogu jest odczytywany więcej niż raz, będzie miał wiele wpisów na liście).
Tytuły ostatnio odczytanych wpisów można wyświetlić przy użyciu IDatabase.ListRange metody . Ta metoda przyjmuje klucz zawierający listę, punkt początkowy i punkt końcowy. Poniższy kod pobiera tytuły 10 wpisów w blogu (elementy od 0 do 9) po lewej stronie listy:
// Show latest ten posts
foreach (string postTitle in await cache.ListRangeAsync(redisKey, 0, 9))
{
Console.WriteLine(postTitle);
}
Pamiętaj, że ListRangeAsync metoda nie usuwa elementów z listy. W tym celu można użyć IDatabase.ListLeftPopAsync metod i IDatabase.ListRightPopAsync .
Aby zapobiec zwiększaniu listy na czas nieokreślony, można okresowo przycinać elementy, przycinając listę. Poniższy fragment kodu pokazuje, jak usunąć wszystkie elementy z listy, ale pięć elementów z lewej strony:
await cache.ListTrimAsync(redisKey, 0, 5);
Implementowanie tablicy liderów
Domyślnie elementy w zestawie nie są przechowywane w żadnej określonej kolejności. Zestaw uporządkowany można utworzyć przy użyciu polecenia ZADD ( IDatabase.SortedSetAdd metody w bibliotece StackExchange). Elementy są uporządkowane przy użyciu wartości liczbowej nazywanej oceną, która jest dostarczana jako parametr polecenia.
Poniższy fragment kodu dodaje tytuł wpisu w blogu do uporządkowanej listy. W tym przykładzie każdy wpis w blogu zawiera również pole oceny zawierające klasyfikację wpisu w blogu.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // Reference to a blog post that has just been rated
await cache.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
Tytuły i wyniki w blogu można pobrać w kolejności rosnącej oceny przy użyciu IDatabase.SortedSetRangeByRankWithScores metody :
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(redisKey))
{
Console.WriteLine(post);
}
Uwaga / Notatka
Biblioteka StackExchange udostępnia również metodę IDatabase.SortedSetRangeByRankAsync , która zwraca dane w kolejności oceny, ale nie zwraca wyników.
Można również pobrać elementy w kolejności malejącej wyników i ograniczyć liczbę elementów zwracanych przez podanie dodatkowych parametrów IDatabase.SortedSetRangeByRankWithScoresAsync do metody. W następnym przykładzie zostaną wyświetlone tytuły i wyniki 10 najlepszych wpisów w blogu:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
W następnym przykładzie IDatabase.SortedSetRangeByScoreWithScoresAsync użyto metody , za pomocą której można ograniczyć elementy zwracane do tych, które należą do danego zakresu wyników:
// Blog posts with scores between 5000 and 100000
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
Komunikat przy użyciu kanałów
Oprócz działania jako pamięci podręcznej danych serwer Redis udostępnia komunikaty za pośrednictwem mechanizmu wydawcy/subskrybenta o wysokiej wydajności. Aplikacje klienckie mogą subskrybować kanał, a inne aplikacje lub usługi mogą publikować komunikaty w kanale. Subskrybowanie aplikacji będzie następnie odbierać te komunikaty i może je przetwarzać.
Usługa Redis udostępnia polecenie SUBSKRYBUJ dla aplikacji klienckich, które mają być używane do subskrybowania kanałów. To polecenie oczekuje nazwy co najmniej jednego kanału, na którym aplikacja będzie akceptować komunikaty. Biblioteka StackExchange zawiera ISubscription interfejs, który umożliwia aplikacji .NET Framework subskrybowanie i publikowanie w kanałach.
Obiekt można ISubscription utworzyć przy użyciu GetSubscriber metody połączenia z serwerem Redis. Następnie nasłuchujesz komunikatów w kanale przy użyciu SubscribeAsync metody tego obiektu. Poniższy przykład kodu przedstawia sposób subskrybowania kanału o nazwie "messages:blogPosts":
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
await subscriber.SubscribeAsync("messages:blogPosts", (channel, message) => Console.WriteLine("Title is: {0}", message));
Pierwszy parametr Subscribe metody to nazwa kanału. Ta nazwa jest zgodna z tymi samymi konwencjami, które są używane przez klucze w pamięci podręcznej. Nazwa może zawierać dowolne dane binarne, ale zalecamy użycie stosunkowo krótkich, znaczących ciągów, aby zapewnić dobrą wydajność i łatwość konserwacji.
Należy również pamiętać, że przestrzeń nazw używana przez kanały jest oddzielona od przestrzeni nazw używanej przez klucze. Oznacza to, że możesz mieć kanały i klucze o tej samej nazwie, chociaż może to utrudnić konserwację kodu aplikacji.
Drugi parametr to delegat akcji. Ten delegat jest uruchamiany asynchronicznie za każdym razem, gdy nowy komunikat pojawi się w kanale. W tym przykładzie po prostu zostanie wyświetlony komunikat w konsoli (komunikat będzie zawierać tytuł wpisu w blogu).
Aby opublikować w kanale, aplikacja może użyć polecenia Redis PUBLISH. Biblioteka StackExchange udostępnia metodę IServer.PublishAsync wykonywania tej operacji. W następnym fragmencie kodu pokazano, jak opublikować komunikat w kanale "messages:blogPosts":
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
BlogPost blogPost = ...;
subscriber.PublishAsync("messages:blogPosts", blogPost.Title);
Istnieje kilka kwestii, które należy zrozumieć na temat mechanizmu publikowania/subskrybowania:
- Wielu subskrybentów może subskrybować ten sam kanał i wszyscy otrzymają komunikaty opublikowane w tym kanale.
- Subskrybenci otrzymują tylko komunikaty, które zostały opublikowane po zasubskrybowaniu. Kanały nie są buforowane, a po opublikowaniu komunikatu infrastruktura redis wypycha komunikat do każdego subskrybenta, a następnie usuwa go.
- Domyślnie komunikaty są odbierane przez subskrybentów w kolejności, w której są wysyłane. W wysoce aktywnym systemie z dużą liczbą komunikatów i wielu subskrybentów i wydawców gwarantowane sekwencyjne dostarczanie komunikatów może spowolnić wydajność systemu. Jeśli każdy komunikat jest niezależny, a kolejność jest nieważna, można włączyć współbieżne przetwarzanie przez system Redis, co może pomóc zwiększyć czas odpowiedzi. Można to osiągnąć w kliencie StackExchange, ustawiając wartość PreserveAsyncOrder połączenia używanego przez subskrybenta na wartość false:
ConnectionMultiplexer redisHostConnection = ...;
redisHostConnection.PreserveAsyncOrder = false;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
Zagadnienia dotyczące serializacji
Po wybraniu formatu serializacji rozważ kompromis między wydajnością, współdziałaniem, przechowywaniem wersji, zgodnością z istniejącymi systemami, kompresją danych i obciążeniem pamięci. Podczas oceny wydajności należy pamiętać, że testy porównawcze są bardzo zależne od kontekstu. Mogą one nie odzwierciedlać rzeczywistego obciążenia i mogą nie uwzględniać nowszych bibliotek ani wersji. Nie ma jednego "najszybszego" serializatora dla wszystkich scenariuszy.
Niektóre opcje do rozważenia obejmują:
protokołu (nazywane również protobuf) to format serializacji opracowany przez firmę Google na potrzeby wydajnego serializowania danych ustrukturyzowanych. Używa on silnie typiowanych plików definicji do definiowania struktur komunikatów. Te pliki definicji są następnie kompilowane do kodu specyficznego dla języka w celu serializacji i deserializacji komunikatów. Protobuf może być używany za pośrednictwem istniejących mechanizmów RPC lub może wygenerować usługę RPC.
Apache Thrift używa podobnego podejścia z silnie typizowanych plików definicji i kroku kompilacji w celu wygenerowania kodu serializacji i usług RPC.
Apache Avro zapewnia podobne funkcje do protokołu i thrift, ale nie ma kroku kompilacji. Zamiast tego serializowane dane zawsze zawierają schemat opisujący strukturę.
JSON to otwarty standard, który używa pól tekstowych czytelnych dla człowieka. Ma szeroką obsługę międzyplatformową. Kod JSON nie używa schematów komunikatów. Będąc formatem opartym na tekście, nie jest bardzo wydajny za pośrednictwem przewodu. W niektórych przypadkach może jednak zwracać buforowane elementy bezpośrednio do klienta za pośrednictwem protokołu HTTP. W takim przypadku przechowywanie danych JSON może obniżyć koszt deserializacji z innego formatu, a następnie serializowanie do formatu JSON.
binarny kod JSON (BSON) to binarny format serializacji, który używa struktury podobnej do formatu JSON. Format BSON został zaprojektowany tak, aby był lekki, łatwy do skanowania i szybko serializował i deserializował dane w stosunku do formatu JSON. Ładunki są porównywalne do formatu JSON. W zależności od danych ładunek BSON może być mniejszy lub większy niż ładunek JSON. Format BSON zawiera kilka dodatkowych typów danych, które nie są dostępne w formacie JSON, w szczególności BinData (dla tablic bajtowych) i Date.
MessagePack to format binarnej serializacji, który jest zaprojektowany jako kompaktowy przy przesyłaniu danych przez sieć. Nie ma schematów komunikatów ani sprawdzania typów komunikatów.
Bond to międzyplatformowa struktura do pracy ze schematyzowanymi danymi. Obsługuje serializacji i deserializacji między językami. Istotne różnice między innymi systemami wymienionymi w tym miejscu to obsługa dziedziczenia, aliasów typów i typów ogólnych.
gRPC to system RPC typu open source opracowany przez firmę Google. Domyślnie używa protokołu jako języka definicji i podstawowego formatu wymiany komunikatów.
Dalsze kroki
- dokumentacja usługi Azure Cache for Redis
- Azure Cache for Redis — często zadawane pytania
- Wzorzec asynchroniczny oparty na zadaniach
- Dokumentacja usługi Redis
- StackExchange.Redis
- Przewodnik po partycjonowaniu danych
Powiązane zasoby
Następujące wzorce mogą być również istotne dla danego scenariusza podczas implementowania buforowania w aplikacjach:
Wzorzec odkładania do pamięci podręcznej: ten wzorzec opisuje sposób ładowania danych na żądanie do pamięci podręcznej z magazynu danych. Ten wzorzec pomaga również zachować spójność między danymi przechowywanymi w pamięci podręcznej a danymi w oryginalnym magazynie danych.
Wzorzec fragmentowania zawiera informacje o implementowaniu partycjonowania poziomego, aby zwiększyć skalowalność podczas przechowywania i uzyskiwania dostępu do dużych ilości danych.