Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Azure Monitor
Rozproszone aplikacje i usługi działające w chmurze są ze swej natury złożonymi elementami oprogramowania, które składają się na wiele ruchomych części. W środowisku produkcyjnym ważne jest, aby móc śledzić sposób korzystania użytkowników z systemu, śledzić wykorzystanie zasobów oraz monitorować kondycję i wydajność systemu. Możesz użyć tych informacji jako pomocy diagnostycznej do wykrywania i korygowania problemów, jak również jako pomocy do wykrywania potencjalnych problemów i zapobiegania ich występowaniu.
Scenariusze monitorowania i diagnostyki
Monitorowanie umożliwia uzyskanie wglądu w to, jak dobrze działa system. Monitorowanie jest kluczową częścią utrzymania celów jakości usług. Typowe scenariusze zbierania danych monitorowania obejmują:
- Zapewnienie, że system pozostaje w dobrej kondycji.
- Śledzenie dostępności systemu i jego elementów składowych.
- Utrzymanie wydajności w celu zapewnienia, że przepływność systemu nie spada nieoczekiwanie w miarę wzrostu ilości pracy.
- Zagwarantowanie, że system spełnia wszelkie umowy dotyczące poziomu usług (SLA) ustanowione z klientami.
- Ochrona prywatności i bezpieczeństwa systemu, użytkowników i ich danych.
- Śledzenie operacji wykonywanych na potrzeby inspekcji lub przepisów prawnych.
- Monitorowanie codziennego użycia systemu i obserwowanie trendów, które mogą prowadzić do problemów, jeśli nie zostaną rozwiązane.
- Śledzenie problemów, które występują, od początkowego raportu do analizy możliwych przyczyn, recyfikacji, konsekwencji aktualizacji oprogramowania i wdrażania.
- Śledzenie operacji i debugowanie wydań oprogramowania.
Uwaga / Notatka
Ta lista nie jest przeznaczona do kompleksowego. Ten dokument koncentruje się na tych scenariuszach jako najbardziej typowych sytuacjach monitorowania. Mogą istnieć inne osoby, które są mniej powszechne lub są specyficzne dla Twojego środowiska.
W poniższych sekcjach opisano te scenariusze bardziej szczegółowo. Informacje dotyczące każdego scenariusza zostały omówione w następującym formacie:
- Krótkie omówienie scenariusza.
- Typowe wymagania tego scenariusza.
- Nieprzetworzone dane instrumentacji wymagane do obsługi scenariusza i możliwe źródła tych informacji.
- Sposób analizowania i łączenia tych danych pierwotnych w celu wygenerowania znaczących informacji diagnostycznych.
Monitorowanie kondycji
System jest w dobrej kondycji, jeśli jest uruchomiony i może przetwarzać żądania. Celem monitorowania kondycji jest wygenerowanie migawki bieżącej kondycji systemu, dzięki czemu można sprawdzić, czy wszystkie składniki systemu działają zgodnie z oczekiwaniami.
Wymagania dotyczące monitorowania kondycji
Operator powinien szybko zostać powiadomiony (w ciągu kilku sekund), jeśli jakakolwiek część systemu zostanie uznana za niezdrową. Operator powinien mieć możliwość ustalenia, które części systemu działają normalnie i które części mają problemy. Kondycję systemu można wyróżnić za pomocą systemu sygnalizacji świetlnej:
- Czerwony oznacza złą kondycję (system został zatrzymany)
- Żółty w przypadku częściowo dobrej kondycji (system działa z ograniczoną funkcjonalnością)
- Zielony dla całkowicie zdrowego
Kompleksowy system monitorowania kondycji umożliwia operatorowi przechodzenie do szczegółów systemu w celu wyświetlenia stanu kondycji podsystemów i składników. Na przykład, jeśli ogólny system jest przedstawiony jako częściowo sprawny, operator powinien mieć możliwość przybliżania i określania, które funkcje są obecnie zdegradowane lub niedostępne.
Wymagania dotyczące źródeł danych, instrumentacji i zbierania danych
Nieprzetworzone dane wymagane do obsługi monitorowania kondycji można wygenerować w wyniku:
- Śledzenie wykonywania żądań użytkowników. Te informacje mogą służyć do określenia, które żądania zakończyły się pomyślnie, które zakończyły się niepowodzeniem i jak długo trwa każde żądanie.
- Syntetyczne monitorowanie użytkowników. Ten proces symuluje kroki wykonywane przez użytkownika i wykonuje wstępnie zdefiniowaną serię kroków. Wyniki każdego kroku powinny być przechwytywane.
- Rejestrowanie wyjątków, błędów i ostrzeżeń. Te informacje można przechwycić w wyniku instrukcji śledzenia osadzonych w kodzie aplikacji, a także pobierać informacje z dzienników zdarzeń wszystkich usług, do których odwołuje się system.
- Monitorowanie kondycji usług innych firm używanych przez system. To monitorowanie może wymagać pobierania i analizowania danych kondycji dostarczanych przez te usługi. Te informacje mogą mieć różne formaty.
- Monitorowanie punktu końcowego. Ten mechanizm został opisany bardziej szczegółowo w sekcji "Monitorowanie dostępności".
- Zbieranie informacji o wydajności środowiska, takich jak wykorzystanie procesora w tle lub aktywność we-wy (w tym działanie sieci).
Analizowanie danych dotyczących kondycji
Głównym celem monitorowania kondycji jest szybkie wskazanie, czy system jest uruchomiony. Natychmiastowa analiza bieżących danych może wyzwolić alert, jeśli kluczowy element zostanie wykryty jako uszkodzony (na przykład nie odpowiada na kolejną serię pingów). Operator może następnie podjąć odpowiednie działania naprawcze.
Bardziej zaawansowany system może obejmować element predykcyjny, który wykonuje zimną analizę ostatnich i bieżących obciążeń. Analiza zimna może wykryć trendy i określić, czy system prawdopodobnie pozostanie w dobrej kondycji, czy też system potrzebuje dodatkowych zasobów. Ten element predykcyjny powinien być oparty na krytycznych metrykach wydajności, takich jak:
- Szybkość żądań kierowanych do każdej usługi lub podsystemu.
- Czasy odpowiedzi tych żądań.
- Ilość danych przepływających do i z każdej usługi.
Jeśli wartość dowolnej metryki przekroczy zdefiniowany próg, system może zgłosić alert, aby umożliwić operatorowi lub skalowanie automatyczne (jeśli jest dostępne) podjęcie działań zapobiegawczych niezbędnych do utrzymania kondycji systemu. Te akcje mogą obejmować dodawanie zasobów, ponowne uruchamianie co najmniej jednej usługi, która kończy się niepowodzeniem lub stosowanie ograniczania przepustowości do żądań o niższym priorytcie.
Monitorowanie dostępności
Prawdziwie zdrowy system wymaga, aby dostępne są składniki i podsystemy tworzące system. Monitorowanie dostępności jest ściśle związane z monitorowaniem kondycji. Monitorowanie kondycji zapewnia natychmiastowy wgląd w bieżącą kondycję systemu, jednak monitorowanie dostępności dotyczy śledzenia dostępności systemu i jego składników w celu wygenerowania statystyk dotyczących czasu działania systemu.
W wielu systemach niektóre składniki (takie jak baza danych) są skonfigurowane z wbudowaną nadmiarowością, aby umożliwić szybkie przejście w tryb failover w przypadku poważnej awarii lub utraty łączności. W idealnym przypadku użytkownicy nie powinni mieć świadomości, że wystąpiła taka awaria. Jednak z perspektywy monitorowania dostępności konieczne jest zebranie jak największej ilości informacji na temat takich niepowodzeń w celu ustalenia przyczyny i podjęcia działań naprawczych, aby zapobiec ich cyklicznemu wystąpieniu.
Dane wymagane do śledzenia dostępności mogą zależeć od wielu czynników niższego poziomu. Wiele z tych czynników może być specyficznych dla aplikacji, systemu i środowiska. Skuteczny system monitorowania przechwytuje dane dostępności odpowiadające tym czynnikom niskiego poziomu, a następnie agreguje je w celu uzyskania ogólnego obrazu systemu. Na przykład w systemie handlu elektronicznego funkcjonalność biznesowa, która umożliwia klientowi składania zamówień, może zależeć od repozytorium, w którym są przechowywane szczegóły zamówienia, oraz system płatności, który obsługuje transakcje pieniężne za płacenie za te zamówienia. Dostępność części rozmieszczania zamówienia w systemie jest zatem funkcją dostępności repozytorium i podsystemu płatności.
Wymagania dotyczące monitorowania dostępności
Operator powinien również mieć możliwość wyświetlania historycznej dostępności każdego systemu i podsystemu, a także użyć tych informacji, aby wykryć wszelkie trendy, które mogą spowodować okresowe niepowodzenie co najmniej jednego podsystemu. Na przykład, operator może użyć danych dostępności, aby wykryć, że usługi zaczynają zawodzić o określonej porze dnia, kiedy przypadają godziny szczytu przetwarzania.
Rozwiązanie do monitorowania powinno zapewnić natychmiastowy i historyczny widok dostępności lub niedostępności każdego podsystemu. Powinno być również możliwe szybkie powiadamianie operatora, gdy co najmniej jedna usługa nie powiedzie się lub gdy użytkownicy nie mogą łączyć się z usługami. Jest to kwestia nie tylko monitorowania każdej usługi, ale także badania akcji, które wykonuje każdy użytkownik, jeśli te akcje kończą się niepowodzeniem podczas próby komunikowania się z usługą. W pewnym stopniu stopień awarii łączności jest normalny i może być spowodowany błędami przejściowymi. Jednak może być przydatne, aby umożliwić systemowi zgłaszanie alertu dotyczącego liczby awarii łączności z określonym podsystemem, które występują w określonym okresie.
Wymagania dotyczące źródeł danych, instrumentacji i zbierania danych
Podobnie jak w przypadku monitorowania kondycji, nieprzetworzone dane wymagane do obsługi monitorowania dostępności mogą być generowane w wyniku syntetycznego monitorowania użytkowników i rejestrowania wszelkich wyjątków, błędów i ostrzeżeń, które mogą wystąpić. Ponadto dane dotyczące dostępności można uzyskać z monitorowania punktu końcowego. Aplikacja może uwidocznić jeden lub więcej punktów końcowych zdrowia, z których każdy testuje dostęp do obszaru funkcjonalnego w systemie. System monitorowania może wysyłać polecenia ping do każdego punktu końcowego, postępując zgodnie ze zdefiniowanym harmonogramem i zbierając wyniki (powodzenie lub niepowodzenie).
Wszystkie przekroczenia limitu czasu, błędy łączności sieciowej i próby ponawiania połączenia muszą być rejestrowane. Wszystkie dane powinny być oznaczone znacznikiem czasu.
Analizowanie danych dotyczących dostępności
Dane instrumentacji muszą być agregowane i skorelowane w celu obsługi następujących typów analizy:
- Natychmiastowa dostępność systemu i podsystemów.
- Współczynniki błędów dostępności systemu i podsystemów. Najlepiej, aby operator mógł skorelować błędy z określonymi działaniami: co się działo, gdy system się nie powiódł?
- Historyczny widok współczynników awarii systemu lub podsystemów w dowolnym określonym przedziale czasu oraz obciążenie systemu (na przykład liczba żądań użytkownika) w przypadku wystąpienia awarii.
- Przyczyny niedostępności systemu lub podsystemów. Na przykład przyczyną może być brak działania usługi, utrata łączności, połączenie, ale upłynął limit czasu, a połączenie, ale zwraca błędy.
Procent dostępności usługi można obliczyć w danym okresie, używając następującej formuły:
%Availability = ((Total Time – Total Downtime) / Total Time ) * 100
Jest to przydatne dla celów umowy SLA. (Monitorowanie umowy SLA zostało szczegółowo opisane w dalszej części tego przewodnika). Definicja przestoju zależy od usługi. Na przykład usługa kompilacji usług Visual Studio Team Services definiuje przestój jako okres (łączna liczba minut), w których usługa kompilacji jest niedostępna. Minuta jest uznawana za niedostępną, jeśli wszystkie ciągłe żądania HTTP do usługi Build Service do wykonywania operacji inicjowanych przez klienta w ciągu minuty powodują wyświetlenie kodu błędu lub nie zwracają odpowiedzi.
Monitorowanie wydajności
W miarę jak system jest coraz bardziej obciążony (przez zwiększenie liczby użytkowników), rozmiar zestawów danych, do których ci użytkownicy uzyskują dostęp, rośnie, a możliwość awarii jednego lub większej liczby składników staje się bardziej prawdopodobna. Często awaria składnika jest poprzedzona obniżeniem wydajności. Jeśli możesz wykryć taką degradację, możesz podjąć aktywne kroki w celu rozwiązania tej sytuacji.
Wydajność systemu zależy od wielu czynników. Każdy czynnik jest zwykle mierzony za pomocą kluczowych wskaźników wydajności (KPI), takich jak liczba transakcji bazy danych na sekundę lub liczba żądań sieciowych, które zostały pomyślnie obsłużone w określonym przedziale czasu. Niektóre z tych wskaźników KPI mogą być dostępne jako konkretne miary wydajności, podczas gdy inne mogą pochodzić z kombinacji metryk.
Uwaga / Notatka
Określenie niskiej lub dobrej wydajności wymaga zrozumienia poziomu wydajności, na którym system powinien być w stanie działać. Wymaga to obserwowania systemu, gdy działa on pod typowym obciążeniem i przechwytywania danych dla każdego kluczowego wskaźnika wydajności w danym okresie. Może to obejmować uruchomienie systemu w ramach symulowanego obciążenia w środowisku testowym i zebranie odpowiednich danych przed wdrożeniem systemu w środowisku produkcyjnym.
Należy również upewnić się, że monitorowanie pod kątem wydajności nie staje się obciążeniem systemu. Dostosowanie poziomu szczegółowości danych zbieranych przez proces monitorowania wydajności pomoże zoptymalizować wydajność.
Wymagania dotyczące monitorowania wydajności
Aby sprawdzić wydajność systemu, operator zazwyczaj musi zobaczyć informacje, które obejmują:
- Wskaźniki szybkości odpowiedzi na żądania użytkowników.
- Liczba współbieżnych żądań użytkowników.
- Ilość ruchu sieciowego.
- Stawki, w których są wykonywane transakcje biznesowe.
- Średni czas przetwarzania żądań.
Przydatne może być również udostępnienie narzędzi, które umożliwiają operatorowi pomoc w wykrycie korelacji, takich jak:
- Liczba równoczesnych użytkowników w porównaniu z opóźnieniami żądań (czas rozpoczęcia przetwarzania żądania po wysłaniu żądania przez użytkownika).
- Liczba równoczesnych użytkowników w porównaniu ze średnim czasem odpowiedzi (jak długo trwa ukończenie żądania po rozpoczęciu przetwarzania).
- Liczba żądań w porównaniu z liczbą błędów przetwarzania.
Oprócz tych informacji funkcjonalnych wysokiego poziomu operator powinien mieć możliwość uzyskania szczegółowego widoku wydajności dla każdego składnika w systemie. Te dane są zwykle udostępniane za pomocą liczników wydajności niskiego poziomu, które śledzą informacje, takie jak:
- Wykorzystanie pamięci
- Liczba wątków
- Czas przetwarzania procesora CPU
- Długość kolejki żądań
- Współczynniki we/wy dysku lub sieci oraz błędy
- Liczba bajtów zapisanych lub odczytanych
- Wskaźniki oprogramowania pośredniczącego, takie jak długość kolejki
Wszystkie wizualizacje powinny zezwalać operatorowi na określenie okresu. Wyświetlane dane mogą być migawką bieżącej sytuacji lub historycznego widoku wydajności.
Operator powinien mieć możliwość zgłaszania alertu na podstawie dowolnej miary wydajności dla dowolnej określonej wartości w dowolnym określonym przedziale czasu.
Wymagania dotyczące źródeł danych, instrumentacji i zbierania danych
Możesz zebrać dane dotyczące wydajności wysokiego poziomu (takie jak przepływność, liczba równoczesnych użytkowników, liczba transakcji biznesowych i współczynniki błędów), monitorując postęp żądań użytkowników w miarę ich odbierania i przekazywania przez system. Obejmuje to włączenie instrukcji śledzenia w kluczowych punktach w kodzie aplikacji wraz z informacjami o chronometrażu. Wszystkie błędy, wyjątki i ostrzeżenia powinny być przechwytywane przy użyciu wystarczających danych do korelowania ich z żądaniami, które je spowodowały.
Jeśli to możliwe, należy również przechwytywać dane dotyczące wydajności dla jakichkolwiek systemów zewnętrznych używanych przez aplikację. Te systemy zewnętrzne mogą udostępniać własne liczniki wydajności lub inne funkcje do żądania danych wydajności. Jeśli nie jest to możliwe, zarejestruj informacje, takie jak godzina rozpoczęcia i godzina zakończenia każdego żądania skierowanego do systemu zewnętrznego, wraz ze stanem (powodzenie, niepowodzenie lub ostrzeżenie) operacji. Można na przykład użyć podejścia stopera do żądań czasu: uruchomienie czasomierza po uruchomieniu żądania, a następnie zatrzymanie czasomierza po zakończeniu żądania.
Dane wydajności niskiego poziomu dla poszczególnych składników systemu mogą być dostępne za pośrednictwem funkcji i usług, takich jak liczniki wydajności systemu Windows i diagnostyka Azure.
Analizowanie danych wydajności
Większość pracy analitycznej składa się z agregacji danych wydajności według typu żądania użytkownika lub podsystemu lub usługi, do której jest wysyłane każde żądanie. Przykładem żądania użytkownika jest dodanie elementu do koszyka zakupów lub wykonanie procesu wyewidencjonowania w systemie handlu elektronicznego.
Innym typowym wymaganiem jest podsumowanie danych wydajności w wybranych percentylach. Na przykład operator może określić czasy odpowiedzi dla 99 procent żądań, 95 procent żądań i 70 procent żądań. Mogą istnieć cele SLA lub inne cele wyznaczone dla każdego percentyla. Bieżące wyniki powinny być zgłaszane niemal w czasie rzeczywistym, aby pomóc w wykrywaniu natychmiastowych problemów. Wyniki powinny być również agregowane w dłuższym czasie w celach statystycznych.
W przypadku problemów z opóźnieniami wpływających na wydajność operator powinien być w stanie szybko zidentyfikować przyczynę wąskiego gardła, sprawdzając opóźnienie każdego kroku wykonywanego przez każde żądanie. W związku z tym dane dotyczące wydajności muszą zapewniać środki korelujące miary wydajności dla każdego kroku, aby powiązać je z określonym żądaniem.
W zależności od wymagań dotyczących wizualizacji może być przydatne generowanie i przechowywanie modułu danych zawierającego widoki danych pierwotnych. Ten moduł danych może zezwalać na złożone wykonywanie zapytań ad hoc i analizowanie informacji o wydajności.
Monitorowanie zabezpieczeń
Wszystkie systemy komercyjne zawierające poufne dane muszą implementować strukturę zabezpieczeń. Złożoność mechanizmu zabezpieczeń jest zwykle funkcją poufności danych. W systemie, który wymaga uwierzytelnienia użytkowników, należy zarejestrować:
- Wszystkie próby logowania, niezależnie od tego, czy kończą się niepowodzeniem, czy powodzeniem.
- Wszystkie operacje wykonywane przez — oraz szczegóły wszystkich zasobów, do których uzyskuje dostęp — uwierzytelnionego użytkownika.
- Po zakończeniu sesji i wylogowaniu się użytkownika.
Monitorowanie może pomóc wykrywać ataki na system. Na przykład duża liczba nieudanych prób logowania może wskazywać na atak siłowy. Nieoczekiwany wzrost liczby żądań może być wynikiem ataku typu "rozproszona odmowa usługi" (DDoS). Należy przygotować się do monitorowania wszystkich żądań do wszystkich zasobów niezależnie od źródła tych żądań. System, który ma lukę w zabezpieczeniach logowania, może przypadkowo uwidocznić zasoby na zewnątrz świata bez konieczności rzeczywistego logowania użytkownika.
Wymagania dotyczące monitorowania zabezpieczeń
Najważniejsze aspekty monitorowania zabezpieczeń powinny umożliwić operatorowi szybkie działanie:
- Wykrywanie prób włamań przez nieautoryzowany podmiot.
- Identyfikowanie prób wykonania operacji na danych, dla których nie udzielono im dostępu, przez jednostki.
- Ustal, czy system, czy część systemu, jest atakowany z zewnątrz lub wewnątrz. Na przykład złośliwy uwierzytelniony użytkownik może próbować doprowadzić do awarii systemu.
Aby spełnić te wymagania, operator powinien zostać powiadomiony, jeśli:
- Jedno konto wykonuje powtarzające się nieudane próby logowania w określonym przedziale czasu.
- Jedno uwierzytelnione konto wielokrotnie próbuje uzyskać dostęp do zabronionego zasobu w określonym okresie.
- W określonym okresie występuje duża liczba nieuwierzytelnionych lub nieautoryzowanych żądań.
Informacje podane operatorowi powinny zawierać adres hosta źródła dla każdego żądania. Jeśli naruszenia zabezpieczeń regularnie wynikają z określonego zakresu adresów, te hosty mogą zostać zablokowane.
Kluczową częścią utrzymania bezpieczeństwa systemu jest możliwość szybkiego wykrywania akcji, które odbiegają od zwykłego wzorca. Informacje takie jak liczba nieudanych lub pomyślnych żądań logowania można wyświetlić wizualnie, aby pomóc wykryć, czy w nietypowym czasie występuje wzrost aktywności. Przykładem tego działania jest zalogowanie się użytkowników o godzinie 3:00 i wykonanie dużej liczby operacji po rozpoczęciu dnia roboczego o godzinie 9:00.
Te informacje mogą również służyć do konfigurowania skalowania automatycznego opartego na czasie. Jeśli na przykład operator zauważy, że duża liczba użytkowników regularnie loguje się o określonej porze dnia, operator może zorganizować uruchomienie dodatkowych usług uwierzytelniania w celu obsługi ilości pracy, a następnie zamknąć te dodatkowe usługi po osiągnięciu szczytu.
Wymagania dotyczące źródeł danych, instrumentacji i zbierania danych
Zabezpieczenia to całościowy aspekt większości systemów rozproszonych. Odpowiednie dane mogą być generowane w wielu punktach w całym systemie. Należy rozważyć zastosowanie podejścia do zarządzania informacjami i zdarzeniami zabezpieczeń (SIEM), aby zebrać informacje związane z zabezpieczeniami, które wynikają z zdarzeń zgłaszanych przez aplikację, sprzęt sieciowy, serwery, zapory, oprogramowanie antywirusowe i inne elementy zapobiegania włamaniom.
Monitorowanie zabezpieczeń może obejmować dane z narzędzi, które nie są częścią aplikacji. Te narzędzia mogą obejmować narzędzia identyfikujące działania skanowania portów przez agencje zewnętrzne lub filtry sieciowe, które wykrywają próby uzyskania nieuwierzytelnionego dostępu do aplikacji i danych. W niektórych przypadkach narzędzia CI/CD są istotną częścią cyklu życia aplikacji, a narzędzia te powinny oznaczać nietypowe zachowanie.
We wszystkich przypadkach zebrane dane muszą umożliwić administratorowi określenie charakteru ataku i podjęcie odpowiednich środków zaradczych.
Analizowanie danych zabezpieczeń
Kluczową funkcją monitorowania zabezpieczeń jest to, że zbiera dane z wielu źródeł. Różne formaty i poziom szczegółowości często wymagają złożonej analizy przechwyconych danych, aby powiązać je ze sobą w spójny wątek informacji. Oprócz podstawowych przypadków (takich jak wykrywanie wielu nieudanych logowania się lub wielokrotne próby uzyskania nieautoryzowanego dostępu do krytycznych zasobów), złożone automatyczne przetwarzanie danych zabezpieczeń może nie być możliwe. Zamiast tego lepszym rozwiązaniem może być zapisanie tych danych, oznaczonych znacznikiem czasu, ale pozostawionych w oryginalnej postaci, do bezpiecznego repozytorium, aby umożliwić ekspertom dokonanie manualnej analizy.
Monitorowanie umowy SLA
Wiele komercyjnych systemów obsługujących płacących klientów zobowiązuje się do wydajności systemu w formie umów SLA. Zasadniczo umowy SLA określają, że system może obsłużyć zdefiniowaną ilość pracy w uzgodnionym przedziale czasu i bez utraty krytycznych informacji. Monitorowanie SLA polega na zapewnieniu, że system może spełniać mierzalne wymagania SLA.
Uwaga / Notatka
Monitorowanie umowy SLA jest ściśle związane z monitorowaniem wydajności. Jednak mając na uwadze, że monitorowanie wydajności dotyczy zapewnienia optymalnego działania systemu, monitorowanie umowy SLA podlega zobowiązaniu umownemu określającemu , co w sposób optymalny oznacza.
Umowy SLA są często definiowane pod względem:
- Ogólna dostępność systemu. Na przykład organizacja może zatwierdzić dostępność systemu przez 99,9 procent czasu. Oznacza to nie więcej niż 9 godzin przestoju rocznie lub około 10 minut tygodniowo.
- Przepływność operacyjna. Ten aspekt jest często wyrażany jako jeden lub więcej punktów odniesienia, takich jak zobowiązanie, że system może obsługiwać do 100 000 jednoczesnych żądań użytkowników lub przetwarzać 10 000 równoczesnych transakcji biznesowych.
- Czas odpowiedzi operacyjnej. System może również podejmować zobowiązania dotyczące szybkości przetwarzania żądań. Przykładem jest to, że 99% wszystkich transakcji biznesowych kończy się w ciągu dwóch sekund, a żadna pojedyncza transakcja nie trwa dłużej niż 10 sekund.
Uwaga / Notatka
Niektóre umowy dotyczące systemów komercyjnych mogą również obejmować umowy SLA dla obsługi klientów. Przykładem jest to, że wszystkie żądania pomocy technicznej wywołują odpowiedź w ciągu pięciu minut, a 99 procent wszystkich problemów jest w pełni rozwiązanych w ciągu jednego dnia roboczego. Skuteczne śledzenie problemów (opisane w dalszej części tej sekcji) jest kluczem do spełnienia umów SLA, takich jak te.
Wymagania dotyczące monitorowania umowy SLA
Na najwyższym poziomie operator powinien mieć możliwość błyskawicznego określenia, czy system spełnia uzgodnione umowy SLA, czy nie. Jeśli nie, operator powinien mieć możliwość przechodzenia do szczegółów i analizowania podstawowych czynników w celu określenia przyczyn wydajności podrzędnej.
Typowe wskaźniki wysokiego poziomu, które można przedstawić wizualnie, obejmują:
- Procent dostępności usługi.
- Przepływność aplikacji (mierzona pod względem pomyślnych transakcji lub operacji na sekundę).
- Liczba żądań aplikacji zakończonych powodzeniem/niepowodzeniem.
- Liczba błędów aplikacji i systemu, wyjątków i ostrzeżeń.
Wszystkie te wskaźniki powinny być filtrowane według określonego okresu.
Aplikacja w chmurze prawdopodobnie składa się z wielu podsystemów i składników. Operator powinien mieć możliwość wybrania wskaźnika wysokiego poziomu i sprawdzenia, jak składa się z kondycji podstawowych elementów. Jeśli na przykład czas pracy całego systemu spadnie poniżej dopuszczalnej wartości, operator powinien mieć możliwość powiększania i określania, które elementy przyczyniają się do tego błędu.
Uwaga / Notatka
Należy dokładnie zdefiniować czas pracy systemu. W systemie, który korzysta z nadmiarowości w celu zapewnienia maksymalnej dostępności, poszczególne wystąpienia elementów mogą zakończyć się niepowodzeniem, ale system może pozostać funkcjonalny. Czas bezawaryjnego działania systemu, przedstawiony przez monitorowanie kondycji, powinien wskazywać zagregowany czas bezawaryjnego działania każdego elementu, a niekoniecznie to, czy system rzeczywiście się zatrzymał. Ponadto awarie mogą być izolowane. Tak więc nawet jeśli określony system jest niedostępny, pozostała część systemu może pozostać dostępna, chociaż ze zmniejszoną funkcjonalnością. W systemie handlu elektronicznego awaria systemu może uniemożliwić klientowi składanie zamówień, ale klient może nadal mieć możliwość przeglądania katalogu produktów.
W celach ostrzegających system powinien mieć możliwość podniesienia zdarzenia, jeśli którykolwiek ze wskaźników wysokiego poziomu przekroczy określony próg. Szczegóły niższego poziomu różnych czynników tworzących wskaźnik wysokiego poziomu powinny być dostępne jako dane kontekstowe dla systemu zgłaszania alertów.
Wymagania dotyczące źródeł danych, instrumentacji i zbierania danych
Nieprzetworzone dane wymagane do obsługi monitorowania umowy SLA są podobne do danych pierwotnych wymaganych do monitorowania wydajności oraz niektórych aspektów monitorowania kondycji i dostępności. Aby uzyskać więcej informacji, zobacz te sekcje. Te dane można przechwycić, wykonując następujące czynności:
- Przeprowadzanie monitorowania punktów końcowych.
- Rejestrowanie wyjątków, błędów i ostrzeżeń.
- Śledzenie wykonywania żądań użytkowników.
- Monitorowanie dostępności dowolnych usług innych firm używanych przez system.
- Korzystanie z metryk wydajności i liczników.
Wszystkie dane muszą być oznaczone czasem i opatrzone znacznikiem czasu.
Analizowanie danych umowy SLA
Dane instrumentacji muszą być agregowane, aby wygenerować obraz ogólnej wydajności systemu. Zagregowane dane muszą również obsługiwać przechodzenie do szczegółów, aby umożliwić badanie wydajności podstawowych podsystemów. Na przykład powinno być możliwe:
- Oblicz łączną liczbę żądań użytkowników w określonym przedziale czasu i określ współczynnik powodzenia i niepowodzeń tych żądań.
- Połącz czasy odpowiedzi żądań użytkowników, aby wygenerować ogólny widok czasów odpowiedzi systemu.
- Przeanalizuj postęp żądań użytkowników, aby podzielić ogólny czas odpowiedzi żądania na czasy odpowiedzi poszczególnych elementów roboczych w tym żądaniu.
- Określ ogólną dostępność systemu jako procent czasu pracy dla dowolnego określonego okresu.
- Przeanalizuj dostępność procentowego czasu poszczególnych składników i usług w systemie. Może to obejmować analizowanie dzienników wygenerowanych przez usługi innych firm.
Wiele systemów komercyjnych jest zobowiązanych do raportowania rzeczywistych danych wydajności zgodnie z uzgodnionymi SLA przez określony okres, zazwyczaj miesięcznie. Te informacje mogą służyć do obliczania kredytów lub innych form spłat dla klientów, jeśli umowy SLA nie zostaną spełnione w tym okresie. Dostępność usługi można obliczyć przy użyciu techniki opisanej w sekcji Analizowanie danych dostępności.
W celach wewnętrznych organizacja może również śledzić liczbę i charakter zdarzeń, które spowodowały niepowodzenie usług. Dowiedz się, jak szybko rozwiązać te problemy lub całkowicie je wyeliminować, pomaga zmniejszyć przestoje i spełnić umowy SLA.
Inspekcja
W zależności od charakteru aplikacji mogą istnieć ustawowe lub inne przepisy prawne, które określają wymagania dotyczące inspekcji operacji użytkowników i rejestrowania dostępu do wszystkich danych. Inspekcja może dostarczyć dowodów, które łączą klientów z określonymi żądaniami. Niezaprzeczalność jest ważnym czynnikiem w wielu systemach e-biznesowych w celu zachowania zaufania między klientem a organizacją, która jest odpowiedzialna za system.
Wymagania dotyczące inspekcji
Analityk musi mieć możliwość śledzenia sekwencji operacji biznesowych wykonywanych przez użytkowników, aby umożliwić odtworzenie akcji użytkowników. Ten rekord może być niezbędny do celów dokumentacji lub w ramach dochodzenia kryminalistycznego.
Informacje inspekcji są wysoce poufne. Prawdopodobnie obejmuje ona dane identyfikujące użytkowników systemu wraz z zadaniami, które wykonują. Z tego powodu informacje audytowe najprawdopodobniej przyjmują formę raportów dostępnych tylko dla zaufanych analityków, a nie jako interaktywny system obsługujący przechodzenie do szczegółów operacji graficznych. Analityk powinien mieć możliwość generowania szeregu raportów. Na przykład raporty mogą wyświetlać listę działań wszystkich użytkowników występujących w określonym przedziale czasu, szczegółowo chronologię działania dla jednego użytkownika lub wyświetlić listę sekwencji operacji wykonywanych względem co najmniej jednego zasobu.
Wymagania dotyczące źródeł danych, instrumentacji i zbierania danych
Podstawowe źródła informacji dotyczących inspekcji mogą obejmować:
- System zabezpieczeń, który zarządza uwierzytelnianiem użytkowników.
- Śledzenie dzienników rejestrujących aktywność użytkownika.
- Dzienniki zabezpieczeń, które śledzą wszystkie możliwe do zidentyfikowania i niezidentyfikowalne żądania sieciowe.
Format danych inspekcji i sposób, w jaki są przechowywane, może być napędzany przez wymagania prawne. Jeśli przepisy wymagają zarejestrowania danych w oryginalnym formacie, może nie być możliwe w żaden sposób wyczyszczenie danych. W związku z tym dostęp do repozytorium, w którym się znajduje, musi być ściśle chroniony, aby zapobiec manipulowaniu.
Analizowanie danych inspekcji
Analityk musi mieć dostęp do nieprzetworzonych danych w całości w pierwotnej formie. Oprócz wymogu generowania typowych raportów inspekcji narzędzia do analizowania tych danych mogą być wyspecjalizowane i przechowywane poza systemem.
Monitorowanie użycia
Monitorowanie użycia śledzi sposób używania funkcji i składników aplikacji. Operator może używać zebranych danych do:
Ustal, które funkcje są intensywnie używane i określ wszelkie potencjalne hotspoty w systemie. Elementy o dużym natężeniu ruchu mogą korzystać z partycjonowania funkcjonalnego, a nawet replikacji w celu równomiernego rozłożenia obciążenia. Operator może również użyć tych informacji, aby ustalić, które funkcje są rzadko używane i są możliwymi kandydatami do wycofania lub zastąpienia w przyszłej wersji systemu.
Uzyskaj informacje o zdarzeniach operacyjnych systemu w normalnym użyciu. Na przykład w witrynie handlu elektronicznego można rejestrować informacje statystyczne dotyczące liczby transakcji i liczby klientów, którzy są za nie odpowiedzialni. Te informacje mogą służyć do planowania pojemności w miarę wzrostu liczby klientów.
Wykrywanie (prawdopodobnie pośrednio) zadowolenia użytkowników z wydajności lub funkcjonalności systemu. Jeśli na przykład duża liczba klientów w systemie handlu elektronicznego regularnie porzuca koszyki, może to być spowodowane problemem z funkcjonalnością zakupu.
Generowanie informacji rozliczeniowych. Aplikacja komercyjna lub wielodostępna usługa może pobierać opłaty za używane zasoby.
Wymuszanie przydziałów. Jeśli użytkownik w systemie wielodostępnym przekracza płatny limit przydziału czasu przetwarzania lub użycia zasobów w określonym okresie, dostęp może być ograniczony lub można ograniczyć przetwarzanie.
Wykrywanie hałaśliwych problemów z sąsiadami. Możliwość określenia, czy ruch jest równomiernie rozłożony, czy mały zestaw użytkowników generuje większość, może pomóc w badaniu błędów lub decyzjach dotyczących produktów. Jeśli pojedynczy użytkownik jest jedynym korzystającym z funkcji aplikacji i generuje niezwykle dużą ilość ruchu, może to oznaczać, że funkcja wymaga poprawy wydajności. Alternatywnie możesz zdecydować się na nałożenie dodatkowych limitów przydziału w celu rozwiązania problemu.
Wymagania dotyczące monitorowania użycia
Aby zbadać użycie systemu, operator zazwyczaj musi zobaczyć informacje, które obejmują:
- Liczba żądań przetwarzanych przez poszczególne podsystemy i kierowanych do każdego zasobu.
- Praca, którą wykonuje każdy użytkownik.
- Ilość miejsca do magazynowania danych zajmowanego przez każdego użytkownika.
- Zasoby, do których uzyskuje dostęp każdy użytkownik.
Operator powinien również mieć możliwość generowania grafów. Typowe przykłady wygenerowanych grafów obejmują wykres umożliwiający wyświetlanie najbardziej głodnych zasobów użytkowników oraz najczęściej używanych zasobów lub funkcji systemowych.
Wymagania dotyczące źródeł danych, instrumentacji i zbierania danych
Śledzenie użycia można wykonać na stosunkowo wysokim poziomie. Może zanotować czas rozpoczęcia i zakończenia każdego żądania oraz charakter żądania (odczyt, zapis i inne żądania, w zależności od danego zasobu). Te informacje można uzyskać, wykonując następujące czynności:
- Śledzenie aktywności użytkownika.
- Przechwytywanie liczników wydajności, które mierzą stopień wykorzystania poszczególnych zasobów.
- Monitorowanie zużycia zasobów przez każdego użytkownika.
W celach pomiarów musisz również mieć możliwość zidentyfikowania użytkowników odpowiedzialnych za wykonywanie operacji oraz zasobów, z których korzystają te operacje. Zebrane informacje powinny być wystarczająco szczegółowe, aby umożliwić dokładne rozliczanie.
Śledzenie problemów
Klienci i inni użytkownicy mogą zgłaszać problemy, jeśli w systemie wystąpią nieoczekiwane zdarzenia lub zachowanie. Śledzenie problemów dotyczy zarządzania tymi problemami, kojarzenia ich z wysiłkami w celu rozwiązania wszelkich podstawowych problemów w systemie i informowania klientów o możliwych rozwiązaniach.
Wymagania dotyczące śledzenia problemów
Operatorzy często wykonują śledzenie problemów przy użyciu oddzielnego systemu, który umożliwia im rejestrowanie i zgłaszanie szczegółów problemów zgłaszanych przez użytkowników. Te szczegóły mogą obejmować zadania, które użytkownik próbował wykonać, objawy problemu, sekwencję zdarzeń oraz wszelkie komunikaty o błędach lub ostrzeżeniach, które zostały wydane.
Wymagania dotyczące źródeł danych, instrumentacji i zbierania danych
Początkowe źródło danych do śledzenia problemów to użytkownik, który zgłosił problem w pierwszej kolejności. Użytkownik może podać dodatkowe dane, takie jak:
- Zrzut awaryjny (jeśli aplikacja zawiera składnik uruchamiany na pulpicie użytkownika).
- Zrzut ekranu.
- Data i godzina wystąpienia błędu wraz z innymi informacjami o środowisku, takimi jak lokalizacja użytkownika.
Te informacje mogą pomóc w wysiłkach debugowania i skonstruować listę prac dla przyszłych wersji oprogramowania.
Analizowanie danych śledzenia problemów
Różni użytkownicy mogą zgłosić ten sam problem. System śledzenia problemów powinien kojarzyć typowe raporty.
Postęp działań debugowania powinien być rejestrowany dla każdego zgłoszenia problemu. Po rozwiązaniu problemu klient może zostać poinformowany o rozwiązaniu.
Jeśli użytkownik zgłasza problem, który ma znane rozwiązanie w systemie śledzenia problemów, operator powinien mieć możliwość natychmiastowego informowania użytkownika o rozwiązaniu.
Śledzenie operacji i debugowanie wydań oprogramowania
Gdy użytkownik zgłasza problem, użytkownik często zdaje sobie sprawę tylko z natychmiastowego wpływu na jego operacje. Użytkownik może zgłaszać wyniki swoich doświadczeń tylko do operatora odpowiedzialnego za utrzymanie systemu. Te doświadczenia są zwykle tylko widocznym objawem jednego lub kilku podstawowych problemów. W wielu przypadkach analityk musi zagłębić się w chronologię podstawowych operacji, aby ustalić główną przyczynę problemu. Ten proces jest nazywany analizą głównej przyczyny.
Uwaga / Notatka
Analiza głównej przyczyny może ujawnić nieefektywność w projekcie aplikacji. W takich sytuacjach może być możliwe przerobienie elementów, których dotyczy problem, i wdrożenie ich w ramach kolejnej wersji. Ten proces wymaga dokładnej kontroli, a zaktualizowane składniki powinny być ściśle monitorowane.
Wymagania dotyczące śledzenia i debugowania
W przypadku śledzenia nieoczekiwanych zdarzeń i innych problemów ważne jest, aby dane monitorowania dostarczały wystarczające informacje, aby umożliwić analitykowi śledzenie z powrotem do źródeł tych problemów i odtworzenie sekwencji zdarzeń, które wystąpiły. Te informacje muszą być wystarczające, aby umożliwić analitykowi zdiagnozowanie głównej przyczyny problemów. Deweloper może następnie wprowadzić niezbędne modyfikacje, aby zapobiec ich powtarzaniu się.
Wymagania dotyczące źródeł danych, instrumentacji i zbierania danych
Rozwiązywanie problemów może obejmować śledzenie wszystkich metod (i ich parametrów) wywoływanych w ramach operacji w celu utworzenia drzewa, które przedstawia przepływ logiczny przez system, gdy klient wysyła określone żądanie. Wyjątki i ostrzeżenia generowane przez system w wyniku tego przepływu muszą zostać przechwycone i zarejestrowane.
Aby obsługiwać debugowanie, system może zapewnić punkty zaczepienia, które umożliwiają operatorowi przechwytywanie informacji o stanie w kluczowych punktach systemu. Lub system może dostarczać szczegółowe informacje krok po kroku w miarę postępu wybranych operacji. Przechwytywanie danych na tym poziomie szczegółowości może narzucić dodatkowe obciążenie systemu i powinno być procesem tymczasowym. Operator używa tego procesu głównie wtedy, gdy występuje bardzo nietypowa seria zdarzeń i jest trudna do replikacji, lub gdy nowe wydanie co najmniej jednego elementu w systemie wymaga starannego monitorowania, aby upewnić się, że elementy działają zgodnie z oczekiwaniami.
Potok monitorowania i diagnostyki
Monitorowanie systemów rozproszonych dużej skali stanowi znaczące wyzwanie. Każdy ze scenariuszy opisanych w poprzedniej sekcji nie musi być brany pod uwagę w izolacji. Istnieje prawdopodobnie znaczące nakładanie się danych monitorowania i diagnostyki, które są wymagane w każdej sytuacji, chociaż te dane mogą być przetwarzane i prezentowane na różne sposoby. Z tych powodów należy przyjąć całościowe podejście do monitorowania i diagnostyki.
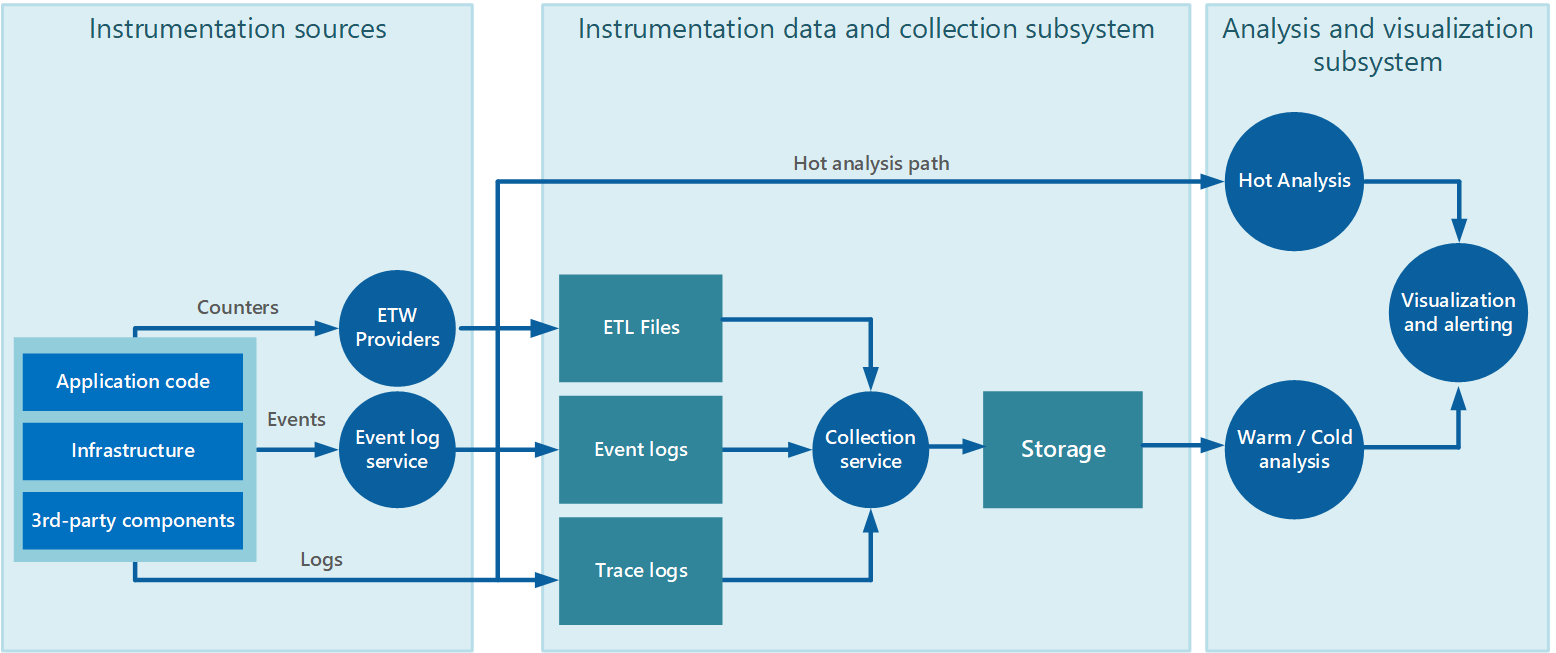
Cały proces monitorowania i diagnostyki można przewidzieć jako potok, który składa się z etapów przedstawionych na rysunku 1.
Etapy procesu monitorowania i diagnostyki w pipeline'ie
Rysunek 1. Etapy w potoku monitorowania i diagnostyki.
Rysunek 1 przedstawia sposób, w jaki dane monitorowania i diagnostyki mogą pochodzić z różnych źródeł danych. Etapy instrumentacji i zbierania dotyczą identyfikowania źródeł, z których należy przechwycić dane, określając, które dane mają zostać przechwycone, jak je przechwycić i jak sformatować te dane, aby można je było łatwo zbadać. Etap analizy/diagnostyki pobiera nieprzetworzone dane i używa ich do generowania znaczących informacji, których operator może użyć do określenia stanu systemu. Operator może użyć tych informacji, aby podejmować decyzje dotyczące możliwych działań do podjęcia, a następnie wprowadzać wyniki z powrotem do etapów instrumentacji i zbierania danych. Etap wizualizacji/alertów przedstawia czytelny widok stanu systemu. Może wyświetlać informacje niemal w czasie rzeczywistym przy użyciu serii pulpitów nawigacyjnych. Umożliwia również generowanie raportów, grafów i wykresów w celu zapewnienia historycznego widoku danych, które mogą pomóc w identyfikowaniu długoterminowych trendów. Jeśli informacje wskazują, że wskaźnik KPI prawdopodobnie przekroczy dopuszczalne granice, ten etap może również wyzwolić alert dla operatora. W niektórych przypadkach alert może być również używany do wyzwalania zautomatyzowanego procesu, który próbuje podjąć akcje naprawcze, takie jak skalowanie automatyczne.
Te kroki stanowią proces ciągłego przepływu, w którym etapy są wykonywane równolegle. Najlepiej, aby wszystkie fazy można było konfigurować dynamicznie. W niektórych przypadkach, zwłaszcza gdy system został nowo wdrożony lub występuje problemy, może być konieczne częstsze zbieranie rozszerzonych danych. W innym czasie powinno być możliwe przywrócenie przechwytywania podstawowego poziomu podstawowych informacji w celu sprawdzenia, czy system działa prawidłowo.
Ponadto cały proces monitorowania powinien być traktowany jako aktywne, bieżące rozwiązanie, które podlega dostrajaniu i ulepszeniom w wyniku opinii. Na przykład można zacząć od pomiaru wielu czynników w celu określenia kondycji systemu. Analiza w czasie może prowadzić do uściślenia, ponieważ odrzucasz miary, które nie są istotne, co pozwala dokładniej skoncentrować się na potrzebnych danych przy jednoczesnym zminimalizowaniu szumu w tle.
Źródła danych monitorowania i diagnostyki
Informacje używane przez proces monitorowania mogą pochodzić z kilku źródeł, jak pokazano na rysunku 1. Na poziomie aplikacji informacje pochodzą z dzienników śledzenia uwzględnionych w kodzie systemu. Deweloperzy powinni postępować zgodnie ze standardowym podejściem do śledzenia przepływu kontroli za pośrednictwem kodu. Na przykład wpis do metody może emitować komunikat śledzenia, który określa nazwę metody, bieżącą godzinę, wartość każdego parametru i inne istotne informacje. Rejestrowanie czasów wejścia i wyjścia może również okazać się przydatne.
Należy rejestrować wszystkie wyjątki i ostrzeżenia oraz zachować pełny ślad wszelkich zagnieżdżonych wyjątków i ostrzeżeń. W idealnym przypadku należy również przechwytywać informacje identyfikujące użytkownika, który uruchamia kod, wraz z informacjami korelacji działań (w celu śledzenia żądań przekazywanych przez system). Należy również rejestrować próby uzyskania dostępu do wszystkich zasobów, takich jak kolejki komunikatów, bazy danych, pliki i inne usługi zależne. Te informacje mogą być używane do celów pomiaru i inspekcji.
Wiele aplikacji używa bibliotek i struktur do wykonywania typowych zadań, takich jak uzyskiwanie dostępu do magazynu danych lub komunikacja za pośrednictwem sieci. Te struktury mogą być konfigurowalne w celu zapewnienia własnych komunikatów śledzenia i nieprzetworzonych informacji diagnostycznych, takich jak współczynniki transakcji i powodzenia transmisji danych i niepowodzenia.
Uwaga / Notatka
Wiele nowoczesnych struktur automatycznie publikuje zdarzenia wydajności i śledzenia. Przechwytywanie tych informacji obejmuje zapewnienie sposobu pobierania i przechowywania zdarzeń w celu ich przetworzenia i przeanalizowania.
System operacyjny, w którym działa aplikacja, może być źródłem informacji dotyczących całego systemu niskiego poziomu, takich jak liczniki wydajności wskazujące współczynniki we/wy, wykorzystanie pamięci i użycie procesora CPU. Błędy systemu operacyjnego (takie jak niepowodzenie poprawnego otwarcia pliku) mogą być również zgłaszane.
Należy również wziąć pod uwagę podstawową infrastrukturę i składniki, na których działa system. Maszyny wirtualne, sieci wirtualne i usługi magazynu mogą być źródłami ważnych liczników wydajności na poziomie infrastruktury i innych danych diagnostycznych.
Jeśli aplikacja korzysta z innych usług zewnętrznych, takich jak serwer internetowy lub system zarządzania bazami danych, te usługi mogą publikować własne informacje o śledzeniu, dzienniki i liczniki wydajności. Przykłady obejmują dynamiczne widoki zarządzania programu SQL Server na potrzeby śledzenia operacji wykonywanych względem bazy danych programu SQL Server oraz dzienników śledzenia usługi Application Insights na potrzeby rejestrowania żądań wysyłanych do usługi Azure App Service.
Ponieważ składniki systemu są modyfikowane i wdrażane są nowe wersje, ważne jest, aby móc przypisywać problemy, zdarzenia i metryki do każdej wersji. Te informacje powinny być powiązane z pipeline'em wydawniczym, aby problemy z wersją konkretnego komponentu mogły być szybko śledzone i naprawione.
Problemy z zabezpieczeniami mogą wystąpić w dowolnym momencie w systemie. Na przykład użytkownik może próbować zalogować się przy użyciu nieprawidłowego identyfikatora użytkownika lub hasła. Uwierzytelniony użytkownik może próbować uzyskać nieautoryzowany dostęp do zasobu. Użytkownik może też podać nieprawidłowy lub nieaktualny klucz w celu uzyskania dostępu do zaszyfrowanych informacji. Informacje dotyczące zabezpieczeń dla żądań zakończonych powodzeniem i niepowodzeniem powinny być zawsze rejestrowane.
Sekcja Instrumentacja aplikacji zawiera więcej wskazówek dotyczących informacji, które należy przechwycić. Można jednak użyć różnych strategii do zebrania tych informacji:
Monitorowanie aplikacji/systemu. Ta strategia używa źródeł wewnętrznych w aplikacji, strukturach aplikacji, systemie operacyjnym i infrastrukturze. Kod aplikacji może wygenerować własne dane monitorowania w godnych uwagi punktach w cyklu życia żądania klienta. Aplikacja może zawierać instrukcje śledzenia, które mogą być selektywnie włączane lub wyłączane w zależności od okoliczności. Może być również możliwe dynamiczne wstrzykiwanie diagnostyki przy użyciu platformy diagnostycznej. Te frameworki zwykle udostępniają wtyczki, które mogą dołączać do różnych punktów instrumentacji w twoim kodzie i przechwytywać dane śladowe w tych punktach.
Ponadto kod lub podstawowa infrastruktura mogą zgłaszać zdarzenia w krytycznych punktach. Agenci monitorowania, którzy są skonfigurowani do nasłuchiwania tych zdarzeń, mogą rejestrować informacje o zdarzeniu.
Monitorowanie rzeczywistego użytkownika. Takie podejście rejestruje interakcje między użytkownikiem a aplikacją i obserwuje przepływ każdego żądania i odpowiedzi. Te informacje mogą mieć dwa cele: mogą być używane do pomiaru użycia przez każdego użytkownika i mogą służyć do określenia, czy użytkownicy otrzymują odpowiednią jakość usługi (na przykład szybkie czasy odpowiedzi, małe opóźnienia i minimalne błędy). Przechwycone dane umożliwiają zidentyfikowanie obszarów problemów, w których najczęściej występują błędy. Możesz również użyć danych, aby zidentyfikować elementy, w których system spowalnia, prawdopodobnie z powodu hotspotów w aplikacji lub innej postaci wąskiego gardła. W przypadku dokładnego zaimplementowania tego podejścia możliwe może być odtworzenie przepływów użytkowników przez aplikację na potrzeby debugowania i testowania.
Ważne
Należy uznać dane przechwycone podczas monitorowania rzeczywistych użytkowników za wysoce wrażliwe, ponieważ mogą zawierać poufne materiały. Jeśli zapiszesz przechwycone dane, zapisz je bezpiecznie. Jeśli chcesz używać danych do monitorowania wydajności lub debugowania, najpierw usuń wszystkie dane osobowe.
Syntetyczne monitorowanie użytkowników. W tym podejściu napiszesz własnego klienta testowego, który symuluje użytkownika i wykonuje konfigurowalną, ale typową serię operacji. Możesz śledzić wydajność klienta testowego, aby ułatwić określenie stanu systemu. Można również użyć wielu wystąpień klienta testowego w ramach operacji testowania obciążenia, aby ustalić, jak system reaguje pod obciążeniem i jakiego rodzaju dane wyjściowe monitorowania są generowane w tych warunkach.
Uwaga / Notatka
Można zaimplementować monitorowanie rzeczywistych i syntetycznych użytkowników, włączając kod, który śledzi i mierzy czas wykonywania wywołań metod oraz innych krytycznych części aplikacji.
Profilowanie. Takie podejście jest ukierunkowane głównie na monitorowanie i poprawianie wydajności aplikacji. Zamiast działać na poziomie funkcjonalnym rzeczywistego i syntetycznego monitorowania użytkowników, przechwytuje informacje niższego poziomu podczas uruchamiania aplikacji. Profilowanie można zaimplementować przy użyciu okresowego próbkowania stanu wykonywania aplikacji (określanie fragmentu kodu, który aplikacja działa w danym punkcie w czasie). Można również użyć instrumentacji, która wstawia sondy do kodu w ważnych momentach (takich jak początek i koniec wywołania metody) oraz rejestruje metody wywoływane, w jakim czasie i jak długo trwało każde wywołanie. Następnie możesz przeanalizować te dane, aby określić, które części aplikacji mogą powodować problemy z wydajnością.
Monitorowanie punktu końcowego. Ta technika używa co najmniej jednego punktu końcowego diagnostycznego, który aplikacja uwidacznia specjalnie w celu włączenia monitorowania. Punkt końcowy udostępnia ścieżkę do kodu aplikacji i może zwracać informacje o kondycji systemu. Różne punkty końcowe mogą skupić się na różnych aspektach funkcjonalności. Możesz napisać własnego klienta diagnostycznego, który wysyła okresowe żądania do tych punktów końcowych i asymiluje odpowiedzi. Aby uzyskać więcej informacji, zobacz Wzorzec monitorowania punktu końcowego kondycji.
Zrzuty błędów użytkownika. Ta technika opiera się na aplikacji w celu zapewnienia płynnego sposobu zbierania migawki stanu aplikacji, jeśli nie może się ona odzyskać, i aby użytkownicy mogli dobrowolnie udostępnić tę migawkę. Chociaż nie ma gwarancji, że zawsze będzie działać, dane niskiego poziomu dostarczane przez zrzut pamięci błędów mogą być niezwykle przydatne do określenia głównej przyczyny błędów. Jest to szczególnie istotne, jeśli błędy, o których mowa występują rzadko lub jeśli błędy są izolowane do rzadko używanej funkcji w aplikacji.
W celu uzyskania maksymalnego pokrycia należy użyć kombinacji tych technik.
Instrumentacja aplikacji
Instrumentacja jest krytyczną częścią procesu monitorowania. Można podejmować znaczące decyzje dotyczące wydajności i kondycji systemu tylko wtedy, gdy najpierw przechwycisz dane, które umożliwiają podejmowanie tych decyzji. Informacje zebrane przy użyciu instrumentacji powinny być wystarczające, aby umożliwić ocenę wydajności, diagnozowanie problemów i podejmowanie decyzji bez konieczności logowania się do zdalnego serwera produkcyjnego w celu ręcznego śledzenia (i debugowania). Dane instrumentacji zwykle obejmują metryki i informacje zapisywane w dziennikach śledzenia.
Zawartość dziennika śledzenia może być wynikiem danych tekstowych zapisywanych przez aplikację lub dane binarne utworzone w wyniku zdarzenia śledzenia, jeśli aplikacja używa funkcji śledzenia dla systemu Windows (ETW). Można je również wygenerować na podstawie dzienników systemowych, które rejestrują zdarzenia wynikające z części infrastruktury, takich jak serwer internetowy. Komunikaty dziennika tekstowego są często zaprojektowane tak, aby były czytelne dla człowieka, ale powinny być również zapisywane w formacie, który umożliwia automatycznemu systemowi łatwe analizowanie ich.
Należy również kategoryzować dzienniki. Nie zapisuj wszystkich danych śledzenia w jednym dzienniku, ale używaj oddzielnych dzienników do rejestrowania danych wyjściowych śledzenia z różnych aspektów operacyjnych systemu. Następnie możesz szybko filtrować komunikaty dziennika, odczytując z odpowiedniego dziennika zamiast przetwarzania pojedynczego długiego pliku. Nigdy nie zapisuj informacji o różnych wymaganiach dotyczących zabezpieczeń (takich jak informacje inspekcji i dane debugowania) w tym samym dzienniku.
Uwaga / Notatka
Log może zostać zaimplementowany jako plik w systemie plików lub może być przechowywany w innym formacie, takim jak obiekt blob w blob storage. Informacje dziennika mogą być również przechowywane w bardziej ustrukturyzowany sposób, na przykład jako wiersze w tabeli.
Metryki zazwyczaj mierzą lub zliczają niektóre aspekty lub zasoby w systemie w określonym momencie, z co najmniej jednym skojarzonym tagiem lub wymiarem (czasami nazywanymi próbką). Pojedyncze wystąpienie metryki zwykle nie jest przydatne w izolacji. Zamiast tego metryki muszą być przechwytywane w czasie. Kluczowym problemem, który należy wziąć pod uwagę, jest to, które metryki należy rejestrować i jak często. Generowanie danych dla metryk zbyt często może spowodować znaczne dodatkowe obciążenie systemu, podczas gdy przechwytywanie metryk rzadko może spowodować pominięcie okoliczności, które prowadzą do znaczącego zdarzenia. Rozważania różnią się w zależności od metryki. Na przykład użycie procesora na serwerze może wahać się od sekundy do sekundy, ale wysokie wykorzystanie staje się problemem tylko wtedy, gdy utrzymuje się przez kilka minut.
Informacje dotyczące korelowania danych
Można łatwo monitorować poszczególne liczniki wydajności na poziomie systemu, przechwytywać metryki zasobów i uzyskiwać informacje o śledzonej aplikacji z różnych plików dziennika. Jednak niektóre formy monitorowania wymagają etapu analizy i diagnostyki w potoku monitorowania w celu skorelowania danych pobranych z kilku źródeł. Te dane mogą przybierać różne formy w danych pierwotnych, a proces analizy musi być zaopatrzony w wystarczającą ilość danych pomiarowych, aby móc mapować te różne formy. Na przykład na poziomie platformy aplikacji zadanie może zostać zidentyfikowane za pomocą identyfikatora wątku. W aplikacji ta sama praca może być skojarzona z identyfikatorem użytkownika dla użytkownika wykonującego to zadanie.
Jest mało prawdopodobne, że istnieje mapowanie 1:1 między wątkami a żądaniami użytkowników, ponieważ operacje asynchroniczne mogą używać tych samych wątków do wykonywania operacji na rzecz więcej niż jednego użytkownika. Aby jeszcze bardziej skomplikować sprawy, pojedyncze żądanie może być obsługiwane przez więcej niż jeden wątek, ponieważ wykonywanie przepływa przez system. Jeśli to możliwe, skojarz każde żądanie z unikatowym identyfikatorem działania, który jest propagowany przez system w ramach kontekstu żądania. (Technika generowania i dołączania identyfikatorów działań w informacjach śledzenia zależy od technologii używanej do przechwytywania danych śledzenia).
Wszystkie dane monitorowania powinny być opatrywane znacznikiem czasu w taki sam sposób. W celu zapewnienia spójności zarejestruj wszystkie daty i godziny przy użyciu uniwersalnego czasu koordynowanego (UTC). Ułatwia to śledzenie sekwencji zdarzeń.
Uwaga / Notatka
Komputery działające w różnych strefach czasowych i sieciach mogą nie być synchronizowane. Nie należy polegać na używaniu samych sygnatur czasowych do korelowania danych instrumentacji obejmujących wiele maszyn.
Informacje do uwzględnienia w danych instrumentacji
Podczas podejmowania decyzji, które dane instrumentacji należy zebrać, należy wziąć pod uwagę następujące kwestie:
Upewnij się, że informacje przechwycone przez zdarzenia śledzenia są czytelne dla maszyn i ludzi. Przyjęcie dobrze zdefiniowanych schematów dla tych informacji w celu ułatwienia zautomatyzowanego przetwarzania danych dziennika w systemach oraz zapewnienia spójności dla personelu ds. operacji i inżynierów odczytujących dzienniki. Uwzględnij informacje o środowisku, takie jak środowisko wdrażania, komputer, na którym jest uruchomiony proces, szczegóły procesu i stos wywołań.
Włącz profilowanie tylko wtedy, gdy jest to konieczne, ponieważ może narzucić znaczne obciążenie systemu. Profilowanie przy użyciu instrumentacji rejestruje zdarzenie (takie jak wywołanie metody) za każdym razem, gdy występuje, podczas gdy próbkowanie rejestruje tylko wybrane zdarzenia. Wybór może być oparty na czasie (raz na n sekund) lub na podstawie częstotliwości (raz na n żądań). Jeśli zdarzenia występują bardzo często, profilowanie za pomocą instrumentacji może spowodować zbyt duże obciążenie, co może wpłynąć na ogólną wydajność. W takim przypadku preferowane może być podejście do próbkowania. Jeśli jednak częstotliwość zdarzeń jest niska, próbkowanie może ich przegapić. W takim przypadku instrumentacja może być lepszym podejściem.
Podaj wystarczający kontekst, aby umożliwić deweloperowi lub administratorowi określenie źródła każdego żądania. Może to obejmować jakąś formę identyfikatora działania, która identyfikuje określone wystąpienie żądania. Może również zawierać informacje, których można użyć do skorelowania tego działania z wykonaną pracą obliczeniową i użytymi zasobami. Ta praca może przekraczać granice procesów i maszyn. W przypadku pomiaru kontekst powinien również zawierać (bezpośrednio lub pośrednio za pośrednictwem innych skorelowanych informacji) odwołanie do klienta, który spowodował złożenie żądania. Ten kontekst zawiera cenne informacje o stanie aplikacji w czasie przechwycenia danych monitorowania.
Rejestruj wszystkie żądania oraz lokalizacje lub regiony, z których są wysyłane te żądania. Te informacje mogą pomóc w ustaleniu, czy istnieją jakiekolwiek hotspoty specyficzne dla lokalizacji. Ta informacja może być również przydatna przy określaniu, czy należy ponownie partycjonować aplikację lub dane, których używa.
Rejestruj i przechwyć szczegółowe informacje o wyjątkach dokładnie. Często krytyczne informacje debugowania są tracone w wyniku złej obsługi wyjątków. Przechwyć pełne szczegóły wyjątków zgłaszanych przez aplikację, w tym wszelkie wyjątki wewnętrzne i inne informacje kontekstowe. Dołącz stos wywołań, jeśli to jest możliwe.
Zachowaj spójność danych przechwyconych przez różne elementy aplikacji, ponieważ może to pomóc w analizowaniu zdarzeń i korelowaniu ich z żądaniami użytkowników. Rozważ użycie kompleksowego i konfigurowalnego pakietu rejestrowania w celu zebrania informacji, zamiast polegać na deweloperach, aby przyjęli jednolite podejście podczas implementacji różnych części systemu. Zbierz dane z kluczowych liczników wydajności, takich jak liczba wykonywanych operacji we/wy, wykorzystanie sieci, liczba żądań, użycie pamięci i wykorzystanie procesora CPU. Niektóre usługi infrastruktury mogą udostępniać własne konkretne liczniki wydajności, takie jak liczba połączeń z bazą danych, szybkość wykonywania transakcji oraz liczba transakcji, które zakończyły się powodzeniem lub niepowodzeniem. Aplikacje mogą również definiować własne liczniki wydajności.
Rejestruje wszystkie wywołania wykonywane do usług zewnętrznych, takich jak systemy baz danych, usługi internetowe lub inne usługi na poziomie systemu, które są częścią infrastruktury. Rejestruj informacje o czasie potrzebnym do wykonania każdego wywołania oraz o powodzeniu lub niepowodzeniu wywołania. Jeśli to możliwe, przechwyć informacje o wszystkich ponownych próbach i niepowodzeniach dla wszelkich przejściowych błędów, które występują.
Zapewnianie zgodności z systemami telemetrii
W wielu przypadkach informacje generowane przez instrumentację są generowane jako seria zdarzeń i przekazywane do oddzielnego systemu telemetrii na potrzeby przetwarzania i analizy. System telemetrii jest zwykle niezależny od dowolnej konkretnej aplikacji lub technologii, ale oczekuje, że informacje będą zgodne z określonym formatem, który jest zwykle definiowany przez schemat. Schemat skutecznie określa kontrakt, który definiuje pola danych i typy, które system telemetrii może pozyskiwać. Schemat powinien być uogólniony, aby umożliwić pobieranie danych z różnych platform i urządzeń. Jednym z przykładów powszechnie używanej platformy i schematu jest OpenTelemetry.
Wspólny schemat powinien zawierać pola wspólne dla wszystkich zdarzeń instrumentacji, takie jak nazwa zdarzenia, czas zdarzenia, adres IP nadawcy oraz szczegóły wymagane do korelowania z innymi zdarzeniami (takie jak identyfikator użytkownika, identyfikator urządzenia i identyfikator aplikacji). Należy pamiętać, że dowolna liczba urządzeń może zgłaszać zdarzenia, więc schemat nie powinien zależeć od typu urządzenia. Ponadto różne urządzenia mogą zgłaszać zdarzenia dla tej samej aplikacji; aplikacja może obsługiwać roaming lub inną formę dystrybucji między urządzeniami.
Schemat może również zawierać pola domeny, które są istotne dla konkretnego scenariusza, który jest wspólny dla różnych aplikacji. Mogą to być informacje o wyjątkach, zdarzeniach uruchamiania i kończenia aplikacji oraz powodzeniu lub niepowodzeniu wywołań interfejsu API usługi internetowej. Wszystkie aplikacje korzystające z tego samego zestawu pól domeny powinny emitować ten sam zestaw zdarzeń, umożliwiając tworzenie zestawu typowych raportów i analiz.
Na koniec schemat może zawierać pola niestandardowe służące do przechwytywania szczegółów zdarzeń specyficznych dla aplikacji.
Najlepsze rozwiązania dotyczące instrumentowania aplikacji
Poniższa lista zawiera podsumowanie najlepszych rozwiązań dotyczących instrumentowania aplikacji rozproszonej działającej w chmurze.
Łatwe odczytywanie i łatwe analizowanie dzienników. Używaj rejestrowania strukturalnego, jeśli jest to możliwe. Bądź zwięzły i opisowy w komunikatach dziennika.
We wszystkich dziennikach zidentyfikuj źródło i podaj informacje o kontekście i czasie w momencie zapisywania każdego rekordu dziennika.
Użyj tej samej strefy czasowej i formatu dla wszystkich sygnatur czasowych. Pomaga to skorelować zdarzenia dla operacji obejmujących sprzęt i usługi działające w różnych regionach geograficznych.
Kategoryzuj dzienniki i zapisuj komunikaty do odpowiedniego pliku dziennika.
Nie ujawniaj poufnych informacji o systemie lub danych osobowych użytkowników. Wyczyść te informacje przed jego zarejestrowaniem, ale upewnij się, że odpowiednie szczegóły są zachowywane. Na przykład usuń identyfikator i hasło z dowolnych parametrów połączenia bazy danych, ale zapisz pozostałe informacje w dzienniku, aby analityk mógł określić, czy system uzyskuje dostęp do właściwej bazy danych. Rejestruj wszystkie wyjątki krytyczne, ale umożliwia administratorowi włączanie i wyłączanie rejestrowania dla niższych poziomów wyjątków i ostrzeżeń. Ponadto przechwyć i zarejestruj wszystkie informacje logiki ponawiania. Te dane mogą być przydatne podczas monitorowania przejściowej kondycji systemu.
Śledzenie wywołań procesów, takich jak żądania do zewnętrznych usług internetowych lub baz danych.
Nie mieszaj komunikatów dziennika z różnymi wymaganiami dotyczącymi zabezpieczeń w tym samym pliku dziennika. Na przykład nie zapisuj informacji dotyczących debugowania i inspekcji w tym samym dzienniku.
Z wyjątkiem zdarzeń audytowych, upewnij się, że wszystkie operacje rejestrowania są operacjami jednorazowymi, które nie blokują postępu operacji biznesowych. Zdarzenia inspekcji są wyjątkowe, ponieważ mają kluczowe znaczenie dla firmy i mogą być klasyfikowane jako podstawowa część operacji biznesowych.
Upewnij się, że rejestrowanie jest rozszerzalne i nie ma żadnych bezpośrednich zależności od konkretnego celu. Na przykład zamiast pisać informacje przy użyciu elementu System.Diagnostics.Trace, zdefiniuj abstrakcyjny interfejs (taki jak ILogger), który uwidacznia metody rejestrowania i który można zaimplementować za pomocą dowolnego odpowiedniego środka.
Upewnij się, że wszystkie dzienniki są bezpieczne na wypadek awarii i nigdy nie wywołują błędów kaskadowych. Rejestrowanie nie może zgłaszać żadnych wyjątków.
Traktuj instrumentację jako ciągły proces iteracyjny i regularnie przeglądaj dzienniki, a nie tylko wtedy, gdy występuje problem.
Zbieranie i przechowywanie danych
Etap zbierania w ramach procesu monitorowania dotyczy pozyskiwania informacji generowanych przez instrumentację, formatowania tych danych w taki sposób, aby ułatwić etap analizy/diagnostyki i zapisywania przekształconych danych w niezawodnej pamięci. Dane instrumentacji zbierane z różnych części systemu rozproszonego mogą być przechowywane w różnych lokalizacjach i w różnych formatach. Na przykład kod aplikacji może generować pliki dziennika śledzenia i generować dane dziennika zdarzeń aplikacji, natomiast liczniki wydajności monitorujące kluczowe aspekty infrastruktury używanej przez aplikację mogą być przechwytywane za pomocą innych technologii. Wszystkie skomponenty i usługi innych firm, które wykorzystuje Twoja aplikacja, mogą udostępniać informacje o instrumentacji w różnych formatach, korzystając z oddzielnych plików śledzenia, przechowywania blobów, a nawet niestandardowego magazynu danych.
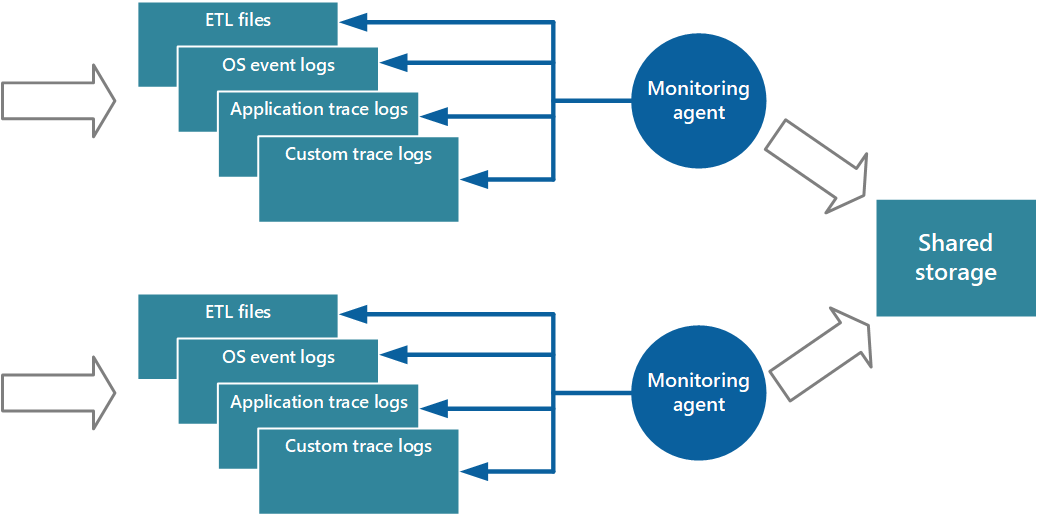
Zbieranie danych jest często wykonywane za pośrednictwem usługi zbierania, która może działać autonomicznie z poziomu aplikacji, która generuje dane instrumentacji. Rysunek 2 przedstawia przykład tej architektury z wyróżnieniem podsystemu zbierania danych instrumentacji.
Rysunek 2. Zbieranie danych instrumentacji.
Jest to uproszczony widok. Usługa zbierania nie musi być pojedynczym procesem i może składać się z wielu składników działających na różnych maszynach, zgodnie z opisem w poniższych sekcjach. Ponadto, jeśli analiza niektórych danych telemetrycznych musi być wykonywana szybko (analiza gorąca, jak opisano w sekcji Wsparcie dla analizy gorącej, ciepłej i zimnej w dalszej części tego dokumentu), lokalne składniki działające niezależnie od usługi zbierania mogą natychmiast wykonywać zadania analizy. Rysunek 2 przedstawia tę sytuację dla wybranych zdarzeń. Po zakończeniu przetwarzania analitycznego wyniki można wysyłać bezpośrednio do podsystemu wizualizacji i alertów. Dane poddane analizie ciepłej lub zimnej są przechowywane w magazynie podczas oczekiwania na przetwarzanie.
W przypadku aplikacji i usług platformy Azure diagnostyka azure udostępnia jedno z możliwych rozwiązań do przechwytywania danych. Diagnostyka Azure zbiera dane z następujących źródeł dla każdego węzła obliczeniowego, agreguje je, a następnie przekazuje je do usługi Azure Storage:
- Dzienniki IIS
- Dzienniki błędów żądań IIS
- Dzienniki zdarzeń systemu Windows
- Liczniki wydajności
- Zrzuty pamięci awaryjnej
- Dzienniki infrastruktury diagnostyki Azure
- Dzienniki błędów niestandardowych
- Źródło zdarzeń .NET
- ETW oparte na manifeście
Aby uzyskać więcej informacji, zobacz artykuł Azure: Telemetry Basics and Troubleshooting (Azure: Podstawy telemetrii i rozwiązywanie problemów).
Strategie zbierania danych instrumentacyjnych
Biorąc pod uwagę elastyczny charakter chmury i aby uniknąć konieczności ręcznego pobierania danych telemetrycznych z każdego węzła w systemie, należy zaplanować przesyłanie danych do centralnej lokalizacji i konsolidacji. W systemie obejmującym wiele centrów danych warto najpierw zbierać, konsolidować i przechowywać dane w poszczególnych regionach, a następnie agregować dane regionalne w jednym systemie centralnym.
Aby zoptymalizować wykorzystanie przepustowości, możesz wybrać opcję transferu mniej pilnych danych we fragmentach jako partii. Jednak dane nie mogą być opóźnione bez końca, zwłaszcza jeśli zawierają informacje ważne czasowo.
Pozyskiwanie i wysyłanie danych pomiarowych
Podsystem zbierania danych instrumentacji może aktywnie pobierać dane instrumentacji z różnych dzienników i innych źródeł dla każdego wystąpienia aplikacji ( modelu ściągania). Może również działać jako pasywny odbiornik, który oczekuje na przesłanie danych ze składników, które składają się na każde wystąpienie aplikacji (model wypychania).
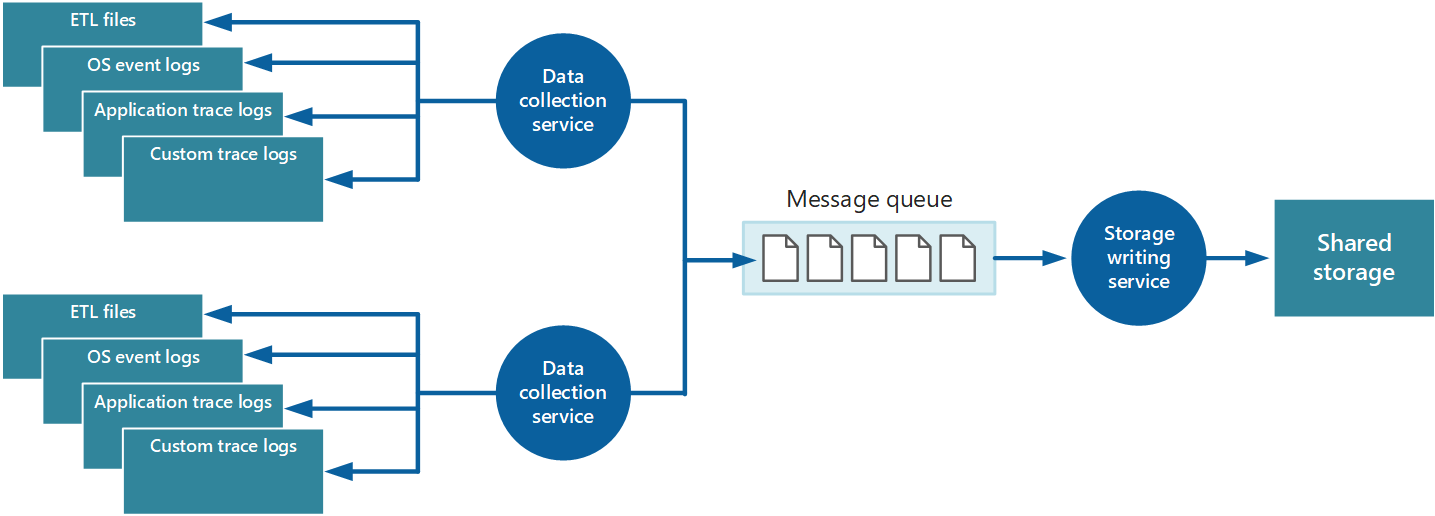
Jednym z podejść do wdrożenia modelu ściągania jest użycie agentów monitorujących uruchamianych lokalnie z każdym wystąpieniem aplikacji. Agent monitorowania jest oddzielnym procesem, który okresowo pobiera dane telemetryczne zebrane w węźle lokalnym i zapisuje te informacje bezpośrednio do scentralizowanej pamięci, udostępnianej przez wszystkie instancje aplikacji. Jest to mechanizm implementowany przez agenta usługi Azure Monitor . Każde wystąpienie obliczeniowe można skonfigurować do przechwytywania danych diagnostycznych i innych informacji śledzenia przechowywanych lokalnie. Agent monitorowania, który działa obok każdego wystąpienia, zbiera określone dane i wysyła je do usługi Azure Monitor. Niektóre elementy, takie jak dzienniki usług IIS, zrzuty awaryjne i niestandardowe dzienniki błędów, są zapisywane w magazynie Blob Storage. Dane z dziennika zdarzeń systemu Windows, zdarzeń ETW i liczników wydajności są rejestrowane w magazynie tabel. Rysunek 3 ilustruje ten mechanizm.
Rysunek 3. Używanie agenta monitorowania do pobierania informacji i zapisywania w magazynie współdzielonym.
Uwaga / Notatka
Używanie agenta monitorowania idealnie nadaje się do przechwytywania danych instrumentacji, które są naturalnie ściągane ze źródła danych. Przykładem są informacje z dynamicznych widoków zarządzania programu SQL Server lub długości kolejki usługi Azure Service Bus.
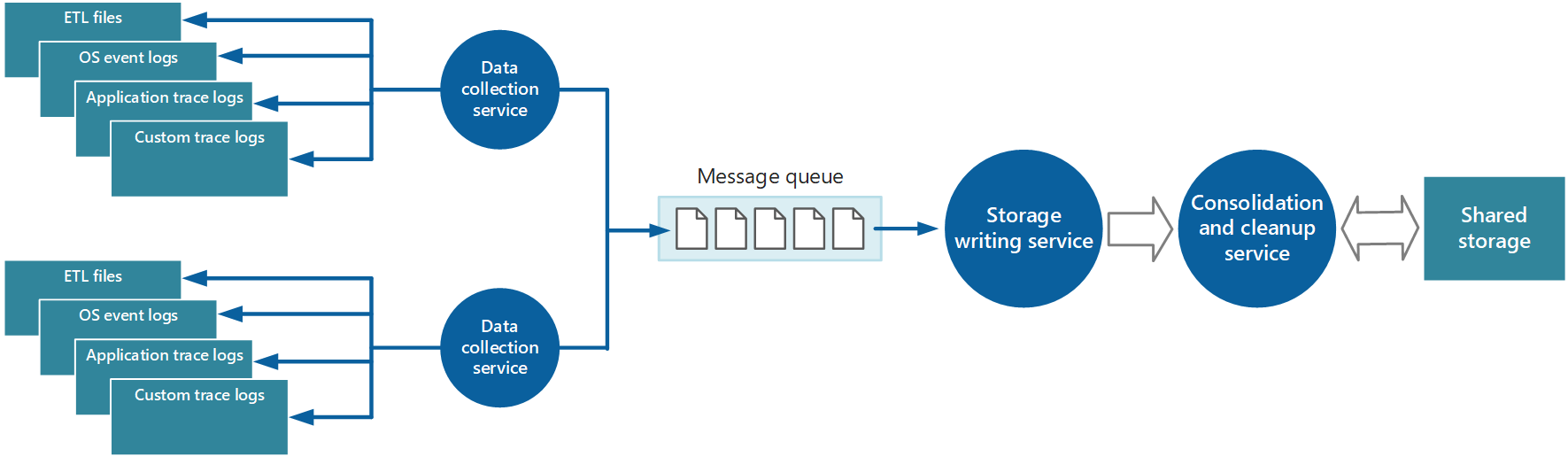
Można użyć właśnie opisanego podejścia do przechowywania danych telemetrycznych dla aplikacji o małej skali działającej na ograniczonej liczbie węzłów w jednej lokalizacji. Jednak złożona, wysoce skalowalna, globalna aplikacja w chmurze może generować ogromne ilości danych z setek wystąpień obliczeniowych, fragmentów baz danych i innych usług. Ta powódź danych może łatwo przytłoczyć przepustowość we/wy dostępną w jednej lokalizacji centralnej. W związku z tym rozwiązanie telemetryczne musi być skalowalne, aby zapobiec jego działania jako wąskie gardło podczas rozszerzania systemu. W idealnym przypadku rozwiązanie powinno obejmować pewien stopień nadmiarowości, aby zmniejszyć ryzyko utraty ważnych informacji monitorowania (takich jak inspekcja lub dane dotyczące rozliczeń), jeśli część systemu ulegnie awarii.
Aby rozwiązać te problemy, możesz zaimplementować kolejkowanie, jak pokazano na rysunku 4. W tej architekturze lokalny agent monitorowania (o ile można go odpowiednio skonfigurować) lub, jeśli nie, niestandardowa usługa zbierania danych publikuje dane w kolejce. Oddzielny proces działający asynchronicznie (usługa zapisu danych do magazynu zawarta na rysunku 4) pobiera dane z tej kolejki i zapisuje je w magazyn wspólny. Kolejka komunikatów jest odpowiednia dla tego scenariusza, ponieważ zapewnia "semantykę co najmniej raz", która pomaga zagwarantować, że dane umieszczone w kolejce nie zostaną utracone po ich opublikowaniu. Usługę zapisywania danych da się zaimplementować, używając osobnego procesu w tle.
Rysunek 4. Buforowanie danych instrumentacji przy użyciu kolejki.
Lokalna usługa zbierania danych może dodawać dane do kolejki natychmiast po odebraniu. Kolejka działa jako bufor, a usługa do zapisywania danych w magazynie może pobierać i zapisywać dane we własnym tempie. Domyślnie kolejka działa na zasadzie first-in, first-out. Można jednak określić priorytety komunikatów w celu przyspieszenia ich przez kolejkę, jeśli zawierają one dane, które muszą być obsługiwane szybciej. Aby uzyskać więcej informacji, zobacz Wzorzec kolejki priorytetu. Alternatywnie możesz użyć różnych kanałów (takich jak tematy usługi Service Bus), aby kierować dane do różnych miejsc docelowych w zależności od wymaganej formy przetwarzania analitycznego.
W celu zapewnienia skalowalności można uruchomić wiele wystąpień usługi zapisu magazynu. Jeśli istnieje duża liczba zdarzeń, możesz użyć centrum zdarzeń, aby wysłać dane do różnych zasobów obliczeniowych na potrzeby przetwarzania i magazynowania.
Konsolidowanie danych instrumentacji
Dane instrumentacji pobierane przez usługę zbierania danych z jednego wystąpienia aplikacji zapewniają zlokalizowany widok kondycji i wydajności tego wystąpienia. Aby ocenić ogólną kondycję systemu, należy skonsolidować niektóre aspekty danych w widokach lokalnych. Można to zrobić po zapisaniu danych, ale w niektórych przypadkach można je również osiągnąć w miarę zbierania danych. Zamiast być bezpośrednio zapisywane w magazynie udostępnionym, dane instrumentacji mogą przechodzić przez specjalną usługę konsolidacji danych, która agreguje dane i działa jako filtr oraz proces oczyszczania. Na przykład dane instrumentacji zawierające te same informacje korelacji, takie jak identyfikator działania, można połączyć. (Istnieje możliwość, że użytkownik rozpocznie wykonywanie operacji biznesowej w jednym węźle, a następnie zostaje przeniesiony do innego węzła w przypadku awarii węzła lub w zależności od konfiguracji równoważenia obciążenia). Ten proces może również wykrywać i usuwać zduplikowane dane (zawsze istnieje możliwość, jeśli usługa telemetrii używa kolejek komunikatów do wypychania danych instrumentacji do magazynu). Rysunek 5 przedstawia przykład tej struktury.
Rysunek 5. Używanie oddzielnej usługi do konsolidacji i czyszczenia danych instrumentacji.
Przechowywanie danych instrumentacji
Poprzednie dyskusje przedstawiały raczej uproszczony widok sposobu przechowywania danych instrumentacji. W rzeczywistości warto przechowywać różne typy informacji przy użyciu technologii, które są najbardziej odpowiednie do sposobu, w jaki każdy typ może być używany.
Na przykład magazyn obiektów blob i tabel platformy Azure ma pewne podobieństwa w sposobie uzyskiwania do nich dostępu. Jednak mają one ograniczenia w operacjach, które można wykonać za ich pomocą, a stopień szczegółowości przechowywanych danych jest zupełnie inny. Jeśli musisz wykonać więcej operacji analitycznych lub potrzebujesz możliwości wyszukiwania pełnotekstowego w danych, może być bardziej odpowiednie użycie magazynu danych zapewniającego możliwości, które są zoptymalizowane dla określonych typów zapytań i dostępu do danych. Przykład:
- Dane liczników wydajności mogą być przechowywane w bazie danych SQL, aby umożliwić analizę ad hoc.
- Dzienniki śledzenia mogą być lepiej przechowywane w usłudze Azure Cosmos DB.
- Informacje o zabezpieczeniach można zapisywać w systemie plików HDFS.
- Informacje, które wymagają wyszukiwania pełnotekstowego, można przechowywać za pośrednictwem usługi Elasticsearch (co może również przyspieszyć wyszukiwanie przy użyciu indeksowania zaawansowanego).
Możesz zaimplementować dodatkową usługę, która okresowo pobiera dane z udostępnionego magazynu, partycji i filtruje dane zgodnie z jego celem, a następnie zapisuje je w odpowiednim zestawie magazynów danych, jak pokazano na rysunku 6. Alternatywnym podejściem jest włączenie tej funkcjonalności w proces konsolidacji i czyszczenia oraz zapisywanie danych bezpośrednio do tych magazynów w momencie ich pobierania, zamiast zapisywania ich do pośredniego udostępnionego obszaru pamięci. Każde podejście ma swoje zalety i wady. Zaimplementowanie oddzielnej usługi partycjonowania zmniejsza obciążenie usługi konsolidacji i oczyszczania i umożliwia ponowne wygenerowanie co najmniej niektórych partycjonowanych danych w razie potrzeby (w zależności od ilości danych przechowywanych w magazynie udostępnionym). Jednak zużywa dodatkowe zasoby. Ponadto mogą wystąpić opóźnienia między odebraniem danych instrumentacji z każdego wystąpienia aplikacji a konwersją tych danych do informacji umożliwiających wykonanie akcji.
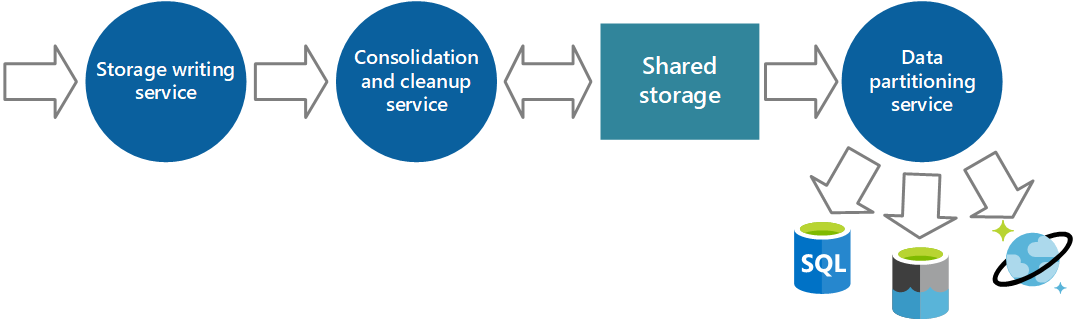
Rysunek 6 - Partycjonowanie danych zgodnie z wymaganiami analitycznymi i przechowywania.
Te same dane instrumentacji mogą być wymagane dla więcej niż jednego celu. Na przykład liczniki wydajności mogą służyć do zapewnienia historycznego widoku wydajności systemu w czasie. Te informacje mogą być łączone z innymi danymi użycia w celu wygenerowania informacji o rozliczeniach z klientem. W takich sytuacjach te same dane mogą być wysyłane do więcej niż jednego miejsca docelowego, takiego jak baza danych dokumentów, która może działać jako długoterminowy magazyn do przechowywania informacji rozliczeniowych oraz wielowymiarowy magazyn do obsługi złożonej analizy wydajności.
Należy również rozważyć, jak pilnie wymagane są dane. Dane, które zawierają informacje na temat alertów, muszą być szybko dostępne, dlatego powinny być przechowywane w szybkim magazynie danych i indeksowane lub ustrukturyzowane w celu zoptymalizowania zapytań, które wykonuje system zgłaszania alertów. W niektórych przypadkach może być konieczne, aby usługa telemetrii, która zbiera dane z każdego węzła, formatowała i zapisywała dane lokalnie, aby lokalne wystąpienie systemu alertów mogło szybko powiadomić o wszelkich problemach. Te same dane mogą być przekazane do usługi zapisywania do magazynu pokazanej na poprzednich diagramach oraz przechowywane centralnie, jeśli jest to wymagane również dla innych celów.
Informacje używane do bardziej przemyślanej analizy, raportowania i odnajdowania trendów historycznych są mniej pilne i mogą być przechowywane w sposób, który obsługuje wyszukiwanie danych i zapytania ad hoc. Aby uzyskać więcej informacji, zobacz sekcję Obsługa gorącej, ciepłej i zimnej analizy w dalszej części tego dokumentu.
Rotacja dzienników i przechowywanie danych
Instrumentacja może generować znaczne ilości danych. Te dane mogą być przechowywane w kilku miejscach, począwszy od nieprzetworzonych plików dziennika, plików śledzenia i innych informacji przechwyconych w każdym węźle do skonsolidowanego, oczyszczonego i podzielonego na partycje widoku tych danych przechowywanych w magazynie udostępnionym. W niektórych przypadkach po przetworzeniu i przesłaniu danych można usunąć oryginalne nieprzetworzone dane źródłowe z każdego węzła. W innych przypadkach może być konieczne lub przydatne zapisanie nieprzetworzonych informacji. Na przykład dane wygenerowane na potrzeby debugowania mogą być najlepiej pozostawione w postaci pierwotnej, ale można je szybko odrzucić po sprostowaniu wszystkich usterek.
Dane wydajności często mają dłuższy czas życia, dzięki czemu mogą być używane do odnajdowania trendów wydajności i planowania pojemności. Skonsolidowany widok tych danych jest zazwyczaj dostępny w trybie online przez określony czas, aby umożliwić szybki dostęp. Następnie można go zarchiwizować lub odrzucić. Dane zbierane do pomiarów i rozliczeń klientów być może muszą być przechowywane w nieskończoność. Ponadto wymagania prawne mogą dyktować, że informacje zebrane do celów inspekcji i zabezpieczeń również muszą być archiwizowane i zapisywane. Dane te są także poufne i mogą być szyfrowane lub w inny sposób chronione, aby zapobiec ich przetwarzaniu. Nigdy nie należy zapisywać haseł użytkowników ani innych informacji, które mogą być używane do popełniania oszustw związanych z tożsamością. Takie szczegóły powinny zostać wyczyszczone z danych przed ich zapisaniem.
Zaniżanie częstotliwości próbkowania
Jest to przydatne do przechowywania danych historycznych, dzięki czemu można zauważyć trendy długoterminowe. Zamiast zapisywać stare dane w całości, może być możliwe obniżenie próbki danych, aby zmniejszyć ich rozdzielczość i zmniejszyć koszty magazynowania. Na przykład zamiast zapisywać wskaźniki wydajności minut po minutach, można skonsolidować dane, które mają więcej niż miesiąc, aby utworzyć widok godzin po godzinie.
Najlepsze praktyki dotyczące zbierania i przechowywania informacji logowania
Poniższa lista zawiera podsumowanie najlepszych rozwiązań dotyczących przechwytywania i przechowywania informacji rejestrowania:
Agent monitorowania lub usługa zbierania danych powinna działać jako usługa poza procesem i powinna być prosta do wdrożenia.
Wszystkie dane wyjściowe z agenta monitorowania lub usługi zbierania danych powinny mieć format, który jest niezależny od komputera, systemu operacyjnego czy protokołu sieciowego. Na przykład emituj informacje w formacie samoopisującym, takim jak JSON, MessagePack lub Protobuf, a nie ETL/ETW. Użycie standardowego formatu umożliwia systemowi konstruowanie potoków przetwarzania; składniki, które odczytują, przekształcają i wysyłają dane w uzgodnionym formacie, można łatwo zintegrować.
Proces monitorowania i zbierania danych musi być bezpieczny i nie może wyzwalać żadnych kaskadowych warunków błędów.
W przypadku awarii przejściowej podczas wysyłania informacji do ujścia danych agent monitorowania lub usługa zbierania danych powinna być przygotowana do zmiany kolejności danych telemetrycznych, tak aby najnowsze informacje zostały wysłane jako pierwsze. (Agent monitorowania/usługa zbierania danych może zdecydować się usunąć starsze dane lub zapisać je lokalnie i przesłać później, aby nadrobić zaległości według własnego uznania).
Analizowanie danych i diagnozowanie problemów
Ważną częścią procesu monitorowania i diagnostyki jest analizowanie zebranych danych w celu uzyskania obrazu ogólnego dobrego samopoczucia systemu. Należy zdefiniować własne wskaźniki KPI i metryki wydajności. Ważne jest, aby zrozumieć, jak można strukturę danych zebranych w celu spełnienia wymagań analizy. Ważne jest również, aby zrozumieć, w jaki sposób dane przechwycone w różnych metrykach i plikach dziennika są skorelowane, ponieważ te informacje mogą być kluczem do śledzenia sekwencji zdarzeń i pomocy w diagnozowaniu pojawiających się problemów.
Zgodnie z opisem w sekcji Konsolidowanie danych instrumentacji dane dla każdej części systemu są zwykle przechwytywane lokalnie, ale zazwyczaj muszą być łączone z danymi wygenerowanymi w innych lokacjach uczestniczących w systemie. Te informacje wymagają starannej korelacji, aby zapewnić dokładne połączenie danych. Na przykład dane dotyczące użycia operacji mogą obejmować węzeł, który hostuje witrynę, z którą łączy się użytkownik, węzeł uruchamiający oddzielną usługę, do której uzyskuje się dostęp w ramach tej operacji, oraz magazyn danych umieszczony na innym węźle. Te informacje muszą być powiązane razem, aby zapewnić ogólny widok użycia zasobów i przetwarzania dla operacji. Niektóre wstępne przetwarzanie i filtrowanie danych mogą wystąpić w węźle, na którym są przechwytywane dane, natomiast agregacja i formatowanie są bardziej narażone na wystąpienie w węźle centralnym.
Obsługa gorącej, ciepłej i zimnej analizy
Analizowanie i ponowne formatowanie danych na potrzeby wizualizacji, raportowania i zgłaszania alertów może być złożonym procesem, który zużywa własny zestaw zasobów. Niektóre formy monitorowania są krytyczne dla czasu i wymagają natychmiastowej analizy danych, aby być skuteczne. Jest to nazywane analizą gorącą. Przykłady obejmują analizy wymagane do zgłaszania alertów i niektórych aspektów monitorowania zabezpieczeń (takich jak wykrywanie ataku na system). Dane wymagane do tych celów muszą być szybko dostępne i ustrukturyzowane do wydajnego przetwarzania. W niektórych przypadkach może być konieczne przeniesienie przetwarzania analizy do poszczególnych węzłów, w których przechowywane są dane.
Inne formy analizy są mniej krytyczne dla czasu i mogą wymagać pewnych obliczeń i agregacji po odebraniu danych pierwotnych. Jest to nazywane analizą ciepłą. Analiza wydajności często należy do tej kategorii. W takim przypadku izolowane pojedyncze zdarzenie związane z wydajnością jest mało prawdopodobne, aby było statystycznie znaczące. (Może to być spowodowane nagłym wzrostem lub usterką). Dane z serii zdarzeń powinny zapewnić bardziej niezawodny obraz wydajności systemu.
Analiza ciepła może również służyć do diagnozowania problemów z kondycją. Zdarzenie zdrowotne jest zwykle przetwarzane przez analizę na gorąco i może natychmiast wywołać alert. Operator powinien móc analizować przyczyny zdarzenia dotyczącego stanu technicznego, badając dane z tzw. ścieżki ciepłej. Dane te powinny zawierać informacje o zdarzeniach prowadzących do usterki, która spowodowała zdarzenie zdrowotne.
Niektóre typy monitorowania generują więcej danych długoterminowych. Tę analizę można wykonać w późniejszym terminie, prawdopodobnie zgodnie ze wstępnie zdefiniowanym harmonogramem. W niektórych przypadkach analiza może wymagać przeprowadzenia złożonego filtrowania dużych ilości danych przechwyconych w danym okresie. Jest to nazywane analizą zimną. Kluczowym wymaganiem jest to, że dane są przechowywane bezpiecznie po ich przechwyceniu. Na przykład monitorowanie użycia i inspekcja wymagają dokładnego obrazu stanu systemu w regularnych punktach w czasie, ale te informacje o stanie nie muszą być dostępne do przetwarzania natychmiast po zebraniu.
Operator może również użyć analizy zimnej w celu udostępnienia danych na potrzeby analizy kondycji predykcyjnej. Operator może zbierać informacje historyczne w określonym okresie i używać ich w połączeniu z bieżącymi danymi kondycji (pobranymi ze ścieżki gorącej), aby wykryć trendy, które mogą wkrótce powodować problemy z kondycją. W takich przypadkach może być konieczne zgłaszanie alertu, aby można było podjąć działania naprawcze.
Korelowanie danych
Dane zebrane przez instrumentację mogą zapewnić migawkę stanu systemu, ale celem analizy jest uczynienie tych danych użytecznymi. Przykład:
- Co spowodowało intensywne załadunek we/wy na poziomie systemu w danym momencie?
- Czy jest to wynik dużej liczby operacji bazy danych?
- Czy jest to odzwierciedlone w czasie odpowiedzi bazy danych, liczbie transakcji na sekundę i czasie odpowiedzi aplikacji w tym samym momencie?
Jeśli tak, jednym z działań korygujących, które mogą zmniejszyć obciążenie, może być podzielenie danych na więcej serwerów. Ponadto wyjątki mogą wystąpić w wyniku błędu na dowolnym poziomie systemu. Wyjątek na jednym poziomie często wyzwala kolejny błąd na wyższym poziomie.
Z tych powodów musisz mieć możliwość skorelowania różnych typów danych monitorowania na każdym poziomie, aby utworzyć ogólny widok stanu systemu i aplikacji, które są na nim uruchomione. Następnie możesz użyć tych informacji, aby podjąć decyzje dotyczące tego, czy system działa w sposób akceptowalny, czy nie, i określić, co można zrobić, aby poprawić jakość systemu.
Zgodnie z opisem w sekcji Informacje dotyczące korelowania danych należy upewnić się, że nieprzetworzone dane instrumentacji zawierają wystarczające informacje o kontekście i identyfikatorze działania, aby obsługiwać wymagane agregacje na potrzeby korelowania zdarzeń. Ponadto te dane mogą być przechowywane w różnych formatach i może być konieczne przeanalizowanie tych informacji w celu przekonwertowania ich na standardowy format analizy.
Rozwiązywanie i diagnozowanie problemów
Diagnostyka wymaga możliwości określenia przyczyny błędów lub nieoczekiwanego zachowania, w tym przeprowadzania analizy głównej przyczyny. Wymagane informacje zwykle obejmują:
- Szczegółowe informacje z dzienników zdarzeń i śladów dla całego systemu lub dla określonego podsystemu w określonym przedziale czasu.
- Pełne ślady stosu wynikające z wyjątków i błędów każdego określonego poziomu, które występują w systemie lub w określonym podsystemie w danym przedziale czasu.
- Zrzuty pamięci awaryjnej dla wszystkich awaryjnych procesów w całym systemie lub dla określonego podsystemu w danym przedziale czasowym.
- Dzienniki aktywności rejestrują operacje wykonywane przez wszystkich użytkowników lub wybranych użytkowników w określonym okresie.
Analizowanie danych na potrzeby rozwiązywania problemów często wymaga głębokiego zrozumienia technicznego architektury systemu i różnych składników tworzących rozwiązanie. W rezultacie duży stopień ręcznej interwencji jest często wymagany do interpretacji danych, ustalenia przyczyny problemów i zalecenia odpowiedniej strategii, aby je rozwiązać. Może być konieczne przechowywanie kopii tych informacji w oryginalnym formacie i udostępnienie jej do analizy zimnej przez eksperta.
Wizualizowanie danych i zgłaszanie alertów
Ważnym aspektem każdego systemu monitorowania jest możliwość prezentowania danych w taki sposób, że operator może szybko wykryć wszelkie trendy lub problemy. Ważne jest również możliwość szybkiego informowania operatora o wystąpieniu znaczącego zdarzenia, które może wymagać uwagi.
Prezentacja danych może mieć kilka formularzy, w tym wizualizacje przy użyciu pulpitów nawigacyjnych, alertów i raportowania.
Wizualizacja przy użyciu pulpitów nawigacyjnych
Najczęstszym sposobem wizualizacji danych jest użycie pulpitów nawigacyjnych, które mogą wyświetlać informacje jako serię wykresów, grafów lub innej ilustracji. Te elementy mogą być sparametryzowane, a analityk powinien mieć możliwość wybrania ważnych parametrów (takich jak okres) dla każdej konkretnej sytuacji.
Pulpity nawigacyjne można organizować hierarchicznie. Pulpity nawigacyjne najwyższego poziomu mogą dać ogólny widok każdego aspektu systemu, ale umożliwiają operatorowi przechodzenie do szczegółów. Na przykład pulpit nawigacyjny, który przedstawia ogólne operacje wejścia/wyjścia dysku w systemie, powinien umożliwić analitykowi wyświetlenie szybkości we/wy dla każdego pojedynczego dysku w celu ustalenia, czy co najmniej jedno konkretne urządzenie generuje nieproporcjonalną objętość ruchu. Najlepiej, aby pulpit nawigacyjny wyświetlał również powiązane informacje, takie jak źródło każdego żądania (użytkownika lub działania), które generuje te operacje we/wy. Te informacje mogą następnie służyć do określenia, czy (i jak) można równomiernie rozłożyć obciążenie na urządzeniach i czy system będzie działać lepiej, gdyby dodano więcej urządzeń.
Pulpit nawigacyjny może również używać kodowania kolorami lub innych wskazówek wizualnych, aby wskazać wartości, które wydają się nietypowe lub które znajdują się poza oczekiwanym zakresem. Przy użyciu poprzedniego przykładu:
- Dysk z szybkością we/wy zbliżającą się do maksymalnej pojemności w dłuższym okresie (dysk gorący) może być wyróżniony na czerwono.
- Dysk o szybkości operacji we/wy, który okresowo osiąga swój maksymalny limit przez krótkie okresy czasu (tzw. ciepły dysk), taki dysk może być wyróżniony kolorem żółtym.
- Dysk, który wykazuje normalne użycie, może być wyświetlany na zielono.
Aby system pulpitu nawigacyjnego działał efektywnie, musi mieć nieprzetworzone dane do pracy. Jeśli tworzysz własny system pulpitu nawigacyjnego lub korzystasz z pulpitu nawigacyjnego opracowanego przez inną organizację, musisz zrozumieć, które dane instrumentacji należy zbierać, na jakich poziomach szczegółowości i jak powinny być sformatowane dla pulpitu nawigacyjnego do użycia.
Oprócz wyświetlania informacji dobry pulpit nawigacyjny umożliwia również analitykowi zadawanie pytań dotyczących tych informacji. Niektóre systemy udostępniają narzędzia do zarządzania, których operator może używać do wykonywania tych zadań i eksplorowania danych bazowych. Alternatywnie, w zależności od repozytorium używanego do przechowywania tych informacji, może być możliwe bezpośrednie zapytanie o te dane lub zaimportowanie ich do narzędzi, takich jak program Microsoft Excel w celu dalszej analizy i raportowania.
Uwaga / Notatka
Należy ograniczyć dostęp do pulpitów nawigacyjnych autoryzowanym personelom, ponieważ te informacje mogą być poufne komercyjnie. Należy również chronić dane bazowe dla pulpitów nawigacyjnych, aby uniemożliwić użytkownikom ich zmianę.
Zgłaszanie alertów
Alerty to proces analizowania danych monitorowania i instrumentacji oraz generowania powiadomienia w przypadku wykrycia istotnego zdarzenia.
Alerty pomagają zapewnić, że system pozostanie w dobrej kondycji, responsywny i bezpieczny. Jest to ważna część każdego systemu, który zapewnia użytkownikom gwarancje dotyczące wydajności, dostępności i prywatności, w sytuacjach, gdy dane mogą wymagać natychmiastowego działania. Może być konieczne powiadomienie operatora o zdarzeniu, które wyzwoliło alert. Alerty mogą również służyć do wywoływania funkcji systemowych, takich jak skalowanie automatyczne.
Alerty zwykle zależą od następujących danych instrumentacji:
- Zdarzenia zabezpieczeń. Jeśli dzienniki zdarzeń wskazują, że występują powtarzające się błędy uwierzytelniania lub autoryzacji, system może zostać zaatakowany, a operator powinien zostać poinformowany.
- Metryki wydajności. System musi szybko reagować, jeśli określona metryka wydajności przekroczy określony próg.
- Informacje o dostępności. W przypadku wykrycia błędu może być konieczne szybkie ponowne uruchomienie co najmniej jednego podsystemu lub przełączenie w tryb failover do zasobu kopii zapasowej. Powtarzające się błędy w podsystemie mogą wskazywać na poważniejsze problemy.
Operatorzy mogą odbierać informacje o alertach przy użyciu wielu kanałów dostarczania, takich jak poczta e-mail, urządzenie pager lub wiadomość SMS. Alert może również zawierać wskazanie, jak krytyczna jest sytuacja. Wiele systemów alertów obsługuje grupy subskrybentów, a wszyscy operatorzy, którzy są członkami tej samej grupy, mogą odbierać ten sam zestaw alertów.
System alertów powinien być dostosowywalny, a odpowiednie wartości z bazowych danych instrumentacji można podać jako parametry. Takie podejście umożliwia operatorowi filtrowanie danych i skupienie się na tych progach lub kombinacjach wartości, które są interesujące. W niektórych przypadkach nieprzetworzone dane instrumentacji mogą być udostępniane systemowi alertów. W innych sytuacjach bardziej odpowiednie może być dostarczenie zagregowanych danych. (Na przykład alert może zostać wyzwolony, jeśli użycie procesora CPU dla węzła przekroczyło 90 procent w ciągu ostatnich 10 minut). Szczegóły podane w systemie zgłaszania alertów powinny również zawierać wszelkie odpowiednie podsumowanie i informacje kontekstowe. Te dane mogą pomóc zmniejszyć prawdopodobieństwo, że zdarzenia fałszywie dodatnie wyzwolą alert.
Raportowanie
Raportowanie służy do generowania ogólnego widoku systemu. Może zawierać dane historyczne oprócz bieżących informacji. Wymagania dotyczące raportowania dzielą się na dwie szerokie kategorie: raportowanie operacyjne i raportowanie zabezpieczeń.
Raportowanie operacyjne zwykle obejmuje następujące aspekty:
- Agregowanie statystyk, których można użyć do zrozumienia wykorzystania zasobów w ogólnym systemie lub określonych podsystemach w określonym okresie.
- Identyfikowanie trendów w zakresie używania zasobów dla całego systemu lub określonych podsystemów w określonym okresie.
- Monitorowanie wyjątków, które wystąpiły w całym systemie lub w określonych podsystemach w określonym okresie.
- Określenie wydajności aplikacji pod względem wdrożonych zasobów i zrozumienie, czy można zmniejszyć ilość zasobów (i powiązanych z nimi kosztów) bez niepotrzebnego wpływu na wydajność.
Raportowanie zabezpieczeń dotyczy śledzenia użycia systemu przez klientów. Można tutaj uwzględnić:
- Inspekcja operacji użytkownika. Wymaga to zarejestrowania poszczególnych żądań, które wykonuje każdy użytkownik wraz z datami i godzinami. Dane powinny być ustrukturyzowane, aby umożliwić administratorowi szybkie odtworzenie sekwencji operacji wykonywanych przez użytkownika w określonym przedziale czasu.
- Śledzenie użycia zasobów przez użytkownika. Wymaga to zarejestrowania, jak każde żądanie użytkownika uzyskuje dostęp do różnych zasobów, które tworzą system i jak długo. Administrator musi mieć możliwość użycia tych danych w celu wygenerowania raportu wykorzystania przez użytkownika w określonym przedziale czasu, prawdopodobnie na potrzeby rozliczeń.
W wielu przypadkach procesy wsadowe mogą generować raporty zgodnie ze zdefiniowanym harmonogramem. (Opóźnienie nie jest zwykle problemem). Jednak w razie potrzeby powinny one być również dostępne do generowania w sposób ad hoc. Jeśli na przykład przechowujesz dane w relacyjnej bazie danych, takiej jak Usługa Azure SQL Database, możesz użyć narzędzia, takiego jak usługi SQL Server Reporting Services, aby wyodrębnić i sformatować dane i przedstawić je jako zestaw raportów.
Dalsze kroki
- Omówienie usługi Azure Monitor
- Monitor, diagnose, and troubleshoot Microsoft Azure Storage (Monitorowanie, diagnozowanie i rozwiązywanie problemów z usługą Microsoft Azure Storage)
- Przegląd alertów na platformie Microsoft Azure
- Co to jest Application Insights?
- Diagnostyka wydajności maszyn wirtualnych platformy Azure
- Pobieranie i instalowanie narzędzi SQL Server Data Tools (SSDT) dla programu Visual Studio
Powiązane zasoby
- Wskazówki dotyczące skalowania automatycznego opisują, jak zmniejszyć obciążenie związane z zarządzaniem, zmniejszając potrzebę ciągłego monitorowania wydajności systemu przez operatora i podejmowania decyzji dotyczących dodawania lub usuwania zasobów.
- Wzorzec monitorowania punktów końcowych kondycji opisuje sposób implementowania testów funkcjonalnych w aplikacji, dostępnych dla narzędzi zewnętrznych poprzez udostępnione punkty końcowe w regularnych odstępach czasu.
- Wzorzec kolejki priorytetu pokazuje, jak określić priorytety komunikatów w kolejce, tak aby pilne żądania zostały odebrane i można je przetworzyć przed mniej pilnych komunikatów.