Aby sprawdzić, czy aplikacje i usługi działają prawidłowo, możesz użyć wzorca monitorowania punktu końcowego kondycji. Ten wzorzec określa użycie kontroli funkcjonalnych w aplikacji. Narzędzia zewnętrzne mogą uzyskiwać dostęp do tych kontroli w regularnych odstępach czasu za pośrednictwem uwidocznionych punktów końcowych.
Kontekst i problem
Dobrym rozwiązaniem jest monitorowanie aplikacji internetowych i usług zaplecza. Monitorowanie pomaga zagwarantować, że aplikacje i usługi są dostępne i działają prawidłowo. Wymagania biznesowe często obejmują monitorowanie.
Czasami trudniej jest monitorować usługi w chmurze niż usługi lokalne. Jednym z powodów jest to, że nie masz pełnej kontroli nad środowiskiem hostingu. Innym jest to, że usługi zwykle zależą od innych usług, które dostawcy platformy i inni zapewniają.
Wiele czynników wpływa na aplikacje hostowane w chmurze. Przykłady obejmują opóźnienie sieci, wydajność i dostępność bazowych systemów obliczeniowych i magazynowych oraz przepustowość sieci między nimi. Usługa może zakończyć się niepowodzeniem w całości lub częściowo z powodu któregokolwiek z tych czynników. Aby zapewnić wymagany poziom dostępności, należy sprawdzić w regularnych odstępach czasu, czy usługa działa prawidłowo. Umowa dotycząca poziomu usług (SLA) może określać poziom, który należy spełnić.
Rozwiązanie
Zaimplementuj monitorowanie kondycji, wysyłając żądania do punktu końcowego w aplikacji. Aplikacja powinna wykonać niezbędne kontrole, a następnie zwrócić wskazanie stanu.
Kontrola monitorowania kondycji zwykle obejmuje dwa czynniki:
- Sprawdzanie (jeśli istnieje) wykonywane przez aplikację lub usługę w odpowiedzi na żądanie do punktu końcowego weryfikacji kondycji
- Analiza wyników za pomocą narzędzia lub struktury wykonującej kontrolę kondycji
Kod odpowiedzi wskazuje stan aplikacji. Opcjonalnie kod odpowiedzi zawiera również stan składników i usług używanych przez aplikację. Narzędzie do monitorowania lub struktura przeprowadza sprawdzanie opóźnienia lub czasu odpowiedzi.
Na poniższej ilustracji przedstawiono omówienie wzorca.
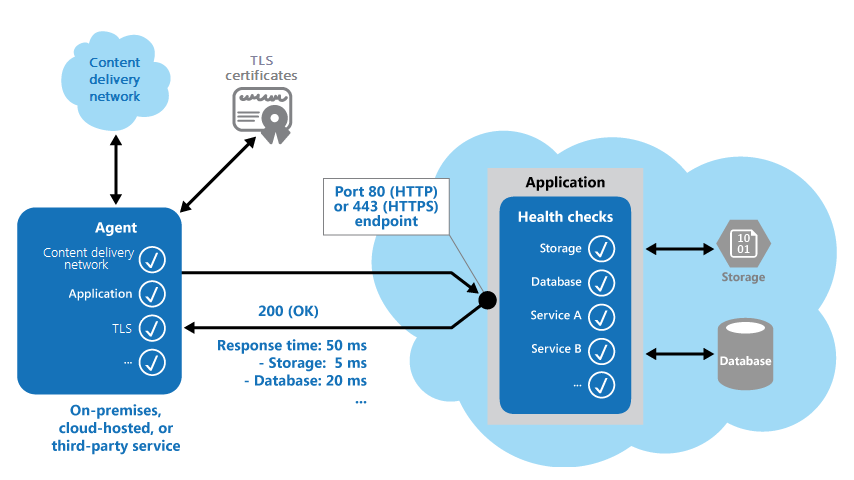
Kod monitorowania kondycji w aplikacji może również uruchamiać inne kontrole w celu określenia:
- Czas dostępności i odpowiedzi magazynu w chmurze lub bazy danych.
- Stan innych zasobów lub usług używanych przez aplikację. Te zasoby i usługi mogą znajdować się w aplikacji lub poza nią.
Dostępne są usługi i narzędzia, które monitorują aplikacje internetowe, przesyłając żądanie do konfigurowalnego zestawu punktów końcowych. Następnie te usługi i narzędzia oceniają wyniki względem zestawu konfigurowalnych reguł. Stosunkowo łatwo jest utworzyć punkt końcowy usługi wyłącznie w celu przeprowadzania niektórych testów funkcjonalnych w systemie.
Typowe kontrole wykonywane przez narzędzia do monitorowania obejmują:
- Sprawdzenie poprawności kodu odpowiedzi. Na przykład odpowiedź HTTP 200 (OK) wskazuje, że aplikacja odpowiedziała bez błędu. System monitorowania może również sprawdzać inne kody odpowiedzi w celu uzyskania pełniejszych wyników.
- Sprawdzanie zawartości odpowiedzi na wykrywanie błędów, nawet jeśli kod stanu to 200 (OK). Sprawdzając zawartość, można wykryć błędy, które mają wpływ tylko na sekcję zwróconej strony internetowej lub odpowiedzi usługi. Możesz na przykład sprawdzić tytuł strony lub wyszukać określoną frazę wskazującą, że aplikacja zwróciła poprawną stronę.
- Mierzenie czasu odpowiedzi. Wartość zawiera opóźnienie sieci i czas, przez który aplikacja mogła wysłać żądanie. Rosnąca wartość może wskazywać na początki problemu z aplikacją lub siecią.
- Sprawdzanie zasobów lub usług znajdujących się poza aplikacją. Przykładem jest sieć dostarczania zawartości używana przez aplikację do dostarczania zawartości z globalnych pamięci podręcznych.
- Sprawdzanie wygaśnięcia certyfikatów TLS.
- Mierzenie czasu odpowiedzi wyszukiwania DNS dla adresu URL aplikacji. Ta kontrola mierzy opóźnienie DNS i błędy DNS.
- Sprawdzanie poprawności adresu URL zwracanego przez wyszukiwanie DNS. Sprawdzając poprawność, możesz upewnić się, że wpisy są poprawne. Możesz również zapobiec przekierowywaniu złośliwych żądań, które może spowodować atak na serwer DNS.
Jeśli to możliwe, warto również uruchomić te testy z różnych lokalizacji lokalnych lub hostowanych, a następnie porównać czasy odpowiedzi. Najlepiej monitorować aplikacje z lokalizacji, które znajdują się blisko klientów. Następnie uzyskasz dokładny widok wydajności z każdej lokalizacji. Ta praktyka zapewnia bardziej niezawodny mechanizm sprawdzania. Wyniki mogą również pomóc w podejmowaniu następujących decyzji:
- Gdzie wdrożyć aplikację
- Czy wdrożyć je w więcej niż jednym centrum danych
Aby upewnić się, że aplikacja działa poprawnie dla wszystkich klientów, uruchom testy dla wszystkich wystąpień usług używanych przez klientów. Jeśli na przykład magazyn klienta jest rozłożony na więcej niż jedno konto magazynu, proces monitorowania powinien sprawdzać każde konto.
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o zaimplementowaniu tego wzorca należy wziąć pod uwagę następujące kwestie:
Zastanów się, jak zweryfikować odpowiedź. Na przykład określ, czy kod stanu 200 (OK) jest wystarczający, aby sprawdzić, czy aplikacja działa prawidłowo. Sprawdzanie kodu stanu jest minimalną implementacją tego wzorca. Kod stanu zapewnia podstawową miarę dostępności aplikacji. Jednak kod dostarcza niewiele informacji o operacjach, trendach i możliwych nadchodzących problemach w aplikacji.
Określ liczbę punktów końcowych do uwidocznienia dla aplikacji. Jednym z podejść jest uwidocznienie co najmniej jednego punktu końcowego dla podstawowych usług używanych przez aplikację i drugiego dla usług o niższym priorytecie. Dzięki temu podejściu można przypisać różne poziomy ważności do każdego wyniku monitorowania. Rozważ również uwidacznianie dodatkowych punktów końcowych. Można uwidocznić jeden dla każdej usługi podstawowej, aby zwiększyć stopień szczegółowości monitorowania. Na przykład kontrola kondycji może sprawdzać bazę danych, magazyn i zewnętrzną usługę geokodowania używaną przez aplikację. Każdy z nich może wymagać innego poziomu czasu pracy i czasu odpowiedzi. Usługa geokodowania lub inne zadanie w tle może być niedostępne przez kilka minut. Ale aplikacja może nadal być w dobrej kondycji.
Zdecyduj, czy używać tego samego punktu końcowego do monitorowania i ogólnego dostępu. Możesz użyć tego samego punktu końcowego dla obu tych elementów, ale zaprojektować określoną ścieżkę do kontroli kondycji. Na przykład można użyć /health w ogólnym punkcie końcowym dostępu. W tym podejściu narzędzia do monitorowania mogą uruchamiać niektóre testy funkcjonalne w aplikacji. Przykłady obejmują zarejestrowanie nowego użytkownika, zalogowanie się i złożenie zamówienia testowego. Jednocześnie można również sprawdzić, czy ogólny punkt końcowy dostępu jest dostępny.
Określ typ informacji do zebrania w usłudze w odpowiedzi na żądania monitorowania. Należy również określić, jak zwrócić te informacje. Większość istniejących narzędzi oraz struktur bierze pod uwagę wyłącznie kod stanu HTTP zwracany przez punkt końcowy. Aby zwrócić dodatkowe informacje i sprawdzić ich poprawność, może być konieczne utworzenie niestandardowego narzędzia lub usługi na potrzeby monitorowania.
Dowiedz się, ile informacji należy zebrać. Wykonywanie nadmiernego przetwarzania podczas sprawdzania może przeciążyć aplikację i wpłynąć na innych użytkowników. Czas przetwarzania może również przekroczyć limit czasu systemu monitorowania. W związku z tym system może oznaczyć aplikację jako niedostępną. Większość aplikacji obejmuje instrumentację, taką jak procedury obsługi błędów i liczniki wydajności. Te narzędzia mogą rejestrować wydajność i szczegółowe informacje o błędach, które mogą być wystarczające. Rozważ użycie tych danych zamiast zwracania dodatkowych informacji z kontroli kondycji.
Rozważ buforowanie stanu punktu końcowego. Częste uruchamianie sprawdzania kondycji może być kosztowne. Jeśli na przykład stan kondycji jest zgłaszany za pośrednictwem pulpitu nawigacyjnego, nie chcesz, aby każde żądanie do pulpitu nawigacyjnego wyzwoliło kontrolę kondycji. Zamiast tego okresowo sprawdzaj kondycję systemu i buforuj stan. Następnie można uwidocznić punkt końcowy zwracający buforowany stan.
Planowanie konfigurowania zabezpieczeń punktów końcowych monitorowania. Konfigurując zabezpieczenia, można chronić punkty końcowe przed dostępem publicznym, co może:
- Uwidocznij aplikację na złośliwe ataki.
- Ryzyko ujawnienia poufnych informacji.
- Przyciągaj ataki typu "odmowa usługi" (DoS).
Zazwyczaj zabezpieczenia są konfigurowane w konfiguracji aplikacji. Następnie możesz łatwo zaktualizować ustawienia bez ponownego uruchamiania aplikacji. Rozważ użycie co najmniej jednej z następujących metod:
Zabezpiecz punkt końcowy, wymagając uwierzytelnienia. Jeśli usługa monitorowania lub narzędzie obsługuje uwierzytelnianie, możesz użyć klucza zabezpieczeń uwierzytelniania w nagłówku żądania. Możesz również przekazać poświadczenia za pomocą żądania. W przypadku korzystania z uwierzytelniania należy wziąć pod uwagę sposób uzyskiwania dostępu do punktów końcowych kontroli kondycji. Na przykład usługa aplikacja systemu Azure service ma wbudowaną kontrolę kondycji, która integruje się z funkcjami uwierzytelniania i autoryzacji usługi App Service.
Użyj nieoczywistego lub ukrytego punktu końcowego. Na przykład uwidocznij punkt końcowy na innym adresie IP niż domyślny adres URL aplikacji. Skonfiguruj punkt końcowy na niestandardowym porcie HTTP. Rozważ również użycie złożonej ścieżki do strony testowej. Zazwyczaj można określić dodatkowe adresy i porty punktu końcowego w konfiguracji aplikacji. W razie potrzeby można dodać wpisy dla tych punktów końcowych do serwera DNS. Następnie należy unikać bezpośredniego określania adresu IP.
Uwidocznij w punkcie końcowym metodę, która przyjmuje parametry takie jak wartość klucza lub wartość trybu operacji. Po nadejściu żądania kod może uruchamiać określone testy, które zależą od wartości parametru. Kod może zwrócić błąd 404 (Nie znaleziono), jeśli nie rozpozna wartości parametru. Umożliwia definiowanie wartości parametrów w konfiguracji aplikacji.
Użyj oddzielnego punktu końcowego, który wykonuje podstawowe testy funkcjonalne bez naruszania działania aplikacji. Dzięki temu podejściu można zmniejszyć wpływ ataku dos. Najlepiej jest unikać testów, które mogą spowodować ujawnienie poufnych informacji. Czasami należy zwrócić informacje, które mogą być przydatne dla osoby atakującej. W takim przypadku należy rozważyć sposób ochrony punktu końcowego i danych przed nieautoryzowanym dostępem. Poleganie na zaciemnianiu nie wystarczy. Rozważ również użycie połączenia HTTPS i szyfrowanie danych poufnych, chociaż takie podejście zwiększa obciążenie serwera.
Zdecyduj, jak upewnić się, że agent monitorowania działa prawidłowo. Jedną z metod jest uwidocznienie punktu końcowego zwracającego wartość z konfiguracji aplikacji lub losowej wartości, której można użyć do przetestowania agenta. Upewnij się również, że system monitorowania przeprowadza kontrole same w sobie. Możesz użyć testu samodzielnego lub wbudowanego, aby uniemożliwić systemowi monitorowania wystawianie wyników fałszywie dodatnich.
Kiedy używać tego wzorca
Ten wzorzec jest przydatny w przypadku:
- Monitorowanie witryn internetowych i aplikacji internetowych pod kątem dostępności.
- Monitorowanie witryn internetowych i aplikacji internetowych pod kątem prawidłowego działania.
- Monitorowanie warstwy środkowej lub usług udostępnionych w celu wykrywania i izolowania błędów, które mogą zakłócać działanie innych aplikacji.
- Uzupełnienie istniejących instrumentacji w aplikacji, takich jak liczniki wydajności i procedury obsługi błędów. Sprawdzanie weryfikacji kondycji nie zastępuje wymagań aplikacji dotyczących rejestrowania i inspekcji. Instrumentacja może dostarczyć cennych informacji dla istniejącej struktury monitorującej liczniki i dzienniki błędów w celu wykrycia awarii lub innych problemów. Instrumentacja nie może jednak podać informacji, jeśli aplikacja jest niedostępna.
Projekt obciążenia
Architekt powinien ocenić, w jaki sposób wzorzec monitorowania punktu końcowego kondycji może być używany w projekcie obciążenia, aby sprostać celom i zasadom opisanym w filarach platformy Azure Well-Architected Framework. Na przykład:
| Filar | Jak ten wzorzec obsługuje cele filaru |
|---|---|
| Decyzje projektowe dotyczące niezawodności pomagają obciążeniu stać się odporne na awarię i zapewnić, że zostanie przywrócony do w pełni funkcjonalnego stanu po wystąpieniu awarii. | Te punkty końcowe obsługują alerty dotyczące niezawodności obciążenia i działania związane z pulpitami nawigacyjnymi. Mogą być one również używane jako sygnał do samonaprawiania korygowania. - RE:07 Samonaprawiania i samozachowawczy - RE:10 Strategia monitorowania i zgłaszania alertów |
| Doskonałość operacyjna pomaga zapewnić jakość obciążeń dzięki ustandaryzowanym procesom i spójności zespołu. | Standaryzacja punktów końcowych kondycji, które mają być uwidaczniane, oraz poziom szczegółowości wyników w całym obciążeniu pomoże Ci sklasyfikować problemy. - System monitorowania OE:07 |
| Wydajność pomagawydajnie sprostać zapotrzebowaniu dzięki optymalizacjom skalowania, danych, kodu. | Punkty końcowe kondycji zwiększają logikę równoważenia obciążenia, rozsyłając ruch tylko do węzłów zweryfikowanych jako w dobrej kondycji. Dzięki dodatkowej konfiguracji można również uzyskać metryki dotyczące dostępnej pojemności węzła. - PE:05 Skalowanie i partycjonowanie |
Podobnie jak w przypadku każdej decyzji projektowej, należy rozważyć wszelkie kompromisy w stosunku do celów innych filarów, które mogą zostać wprowadzone przy użyciu tego wzorca.
Przykład
Aby zgłosić kondycję składników infrastruktury aplikacji, można użyć oprogramowania pośredniczącego i bibliotek kontroli kondycji ASP.NET. Ta struktura umożliwia raportowanie kontroli kondycji w spójny sposób. Implementuje wiele praktyk opisanych w tym artykule. Na przykład testy kondycji ASP.NET obejmują kontrole zewnętrzne, takie jak łączność z bazą danych i konkretne pojęcia, takie jak sondy gotowości i aktualności.
W usłudze GitHub jest dostępnych kilka przykładowych implementacji korzystających z kontroli kondycji ASP.NET.
Monitorowanie punktów końcowych w aplikacjach hostowanych na platformie Azure
Opcje monitorowania punktów końcowych w aplikacjach platformy Azure obejmują:
- Użyj wbudowanych funkcji monitorowania platformy Azure, takich jak Azure Monitor.
- Użyj usługi innej firmy lub platformy, takiej jak Microsoft System Center Operations Manager.
- Utwórz narzędzie niestandardowe lub usługę działającą na własnym serwerze lub serwerze hostowanym.
Mimo że platforma Azure oferuje kompleksowe opcje monitorowania, możesz użyć dodatkowych usług i narzędzi, aby uzyskać dodatkowe informacje. Aplikacja Szczegółowe informacje, funkcja Monitor, jest przeznaczona dla zespołów programistycznych. Ta funkcja ułatwia zrozumienie sposobu działania aplikacji i sposobu jej użycia. Aplikacja Szczegółowe informacje monitoruje współczynniki żądań, czasy odpowiedzi, współczynniki awarii i współczynniki zależności. Może to pomóc w ustaleniu, czy usługi zewnętrzne spowalniają Cię.
Warunki, które można monitorować, zależą od mechanizmu hostingu wybranego dla aplikacji. Wszystkie opcje w tej sekcji obsługują reguły alertów. Reguła alertu używa internetowego punktu końcowego określonego w ustawieniach usługi. Ten punkt końcowy powinien odpowiadać bez opóźnień, aby system alertów mógł wykryć, że aplikacja działa poprawnie. Aby uzyskać więcej informacji, zobacz Tworzenie nowej reguły alertu.
Jeśli wystąpi duża awaria, ruch klienta powinien być kierowany do wdrożenia aplikacji dostępnego w innych regionach lub strefach. Taka sytuacja jest dobrym przypadkiem w przypadku łączności obejmującej wiele lokalizacji i globalnego równoważenia obciążenia. Wybór zależy od tego, czy aplikacja jest wewnętrzna, czy zewnętrzna. Usługi takie jak Azure Front Door, Azure Traffic Manager lub sieci dostarczania zawartości mogą kierować ruch między regionami na podstawie danych zapewnianych przez sondy kondycji.
Traffic Manager to usługa routingu i równoważenia obciążenia. Może używać szeregu reguł i ustawień do dystrybuowania żądań do określonych wystąpień aplikacji. Oprócz żądań routingu usługa Traffic Manager może regularnie wysyłać polecenia ping do adresu URL, portu i ścieżki względnej. Określasz obiekty docelowe polecenia ping w celu określenia, które wystąpienia aplikacji są aktywne i odpowiadają na żądania. Jeśli usługa Traffic Manager wykryje kod stanu 200 (OK), oznacza aplikację jako dostępną. Każdy inny kod stanu powoduje, że usługa Traffic Manager rozpoznaje aplikację jako offline. Konsola usługi Traffic Manager wyświetla stan każdej aplikacji. Każdą regułę można skonfigurować tak, aby przekierowywać żądania do innych wystąpień aplikacji, które odpowiadają.
Usługa Traffic Manager czeka przez pewien czas na odebranie odpowiedzi z adresu URL monitorowania. Upewnij się, że kod weryfikacyjny kondycji jest uruchamiany w tym czasie. Zezwalaj na opóźnienie sieci dla rundy z usługi Traffic Manager do aplikacji i z powrotem.
Następne kroki
Poniższe wskazówki są przydatne do implementowania tego wzorca:
- Wskazówki dotyczące monitorowania kondycji w aplikacjach opartych na mikrousługach
- Monitorowanie kondycji aplikacji pod kątem niezawodności, części struktury Azure Well-Architected Framework
- Tworzenie nowej reguły alertu