Globalna nadmiarowość routingu dla aplikacji internetowych o krytycznym znaczeniu
Ważne
Projektowanie implementacji nadmiarowości, które zajmują się globalnymi awariami platformy dla architektury o znaczeniu krytycznym, może być złożone i kosztowne. Ze względu na potencjalne problemy, które mogą wystąpić w tym projekcie, należy dokładnie rozważyć kompromisy.
W większości przypadków nie potrzebujesz architektury opisanej w tym artykule.
Systemy o krytycznym znaczeniu dążą do zminimalizowania pojedynczych punktów awarii, tworząc nadmiarowość i możliwości samonaprawiania w rozwiązaniu, jak najwięcej. Każdy ujednolicony punkt wejścia systemu może być uważany za punkt awarii. Jeśli ten składnik wystąpi awaria, cały system będzie w trybie offline dla użytkownika. Podczas wybierania usługi routingu ważne jest, aby wziąć pod uwagę niezawodność samej usługi.
W architekturze bazowej dla aplikacji o znaczeniu krytycznym usługa Azure Front Door została wybrana ze względu na jej umowy dotyczące wysokiego czasu pracy (SLA) i bogaty zestaw funkcji:
- Kierowanie ruchu do wielu regionów w modelu aktywny-aktywny
- Przezroczyste przejście w tryb failover przy użyciu dowolnego emisji TCP
- Udostępnianie zawartości statycznej z węzłów brzegowych przy użyciu zintegrowanych sieci dostarczania zawartości (CDN)
- Blokowanie nieautoryzowanego dostępu za pomocą zintegrowanej zapory aplikacji internetowej
Usługa Front Door została zaprojektowana w celu zapewnienia najwyższej odporności i dostępności nie tylko dla naszych klientów zewnętrznych, ale także dla wielu właściwości w firmie Microsoft. Aby uzyskać więcej informacji na temat możliwości usługi Front Door, zobacz Przyspieszanie i zabezpieczanie aplikacji internetowej za pomocą usługi Azure Front Door.
Możliwości usługi Front Door są bardziej niż wystarczające, aby spełnić większość wymagań biznesowych, jednak w przypadku dowolnego rozproszonego systemu oczekiwano awarii. Jeśli wymagania biznesowe wymagają wyższej złożonej umowy SLA lub zerowego czasu przestoju w przypadku awarii, musisz opierać się na alternatywnej ścieżce ruchu przychodzącego. Jednak dążenie do wyższej umowy SLA wiąże się ze znacznymi kosztami, obciążeniem operacyjnym i może obniżyć ogólną niezawodność. Starannie rozważ kompromisy i potencjalne problemy, które alternatywna ścieżka może wprowadzać w innych składnikach, które znajdują się na ścieżce krytycznej. Nawet jeśli wpływ niedostępności jest znaczący, złożoność może przeważyć nad korzyścią.
Jedną z metod jest zdefiniowanie ścieżki pomocniczej z alternatywnymi usługami, które stają się aktywne tylko wtedy, gdy usługa Azure Front Door jest niedostępna. Równoważność funkcji z usługą Front Door nie powinna być traktowana jako trudne wymaganie. Określanie priorytetów funkcji, które są absolutnie potrzebne do celów ciągłości działalności biznesowej, nawet potencjalnie działających w ograniczonej pojemności.
Innym podejściem jest użycie technologii innych firm na potrzeby routingu globalnego. Takie podejście wymaga wielochmurowego wdrożenia aktywne-aktywne z sygnaturami hostowanymi u co najmniej dwóch dostawców chmury. Mimo że platforma Azure może być skutecznie zintegrowana z innymi platformami w chmurze, takie podejście nie jest zalecane ze względu na złożoność operacyjną na różnych platformach w chmurze.
W tym artykule opisano niektóre strategie routingu globalnego przy użyciu usługi Azure Traffic Manager jako alternatywnego routera w sytuacjach, gdy usługa Azure Front Door nie jest dostępna.
Metoda
Ten diagram architektury przedstawia ogólne podejście z wieloma nadmiarowymi ścieżkami ruchu.
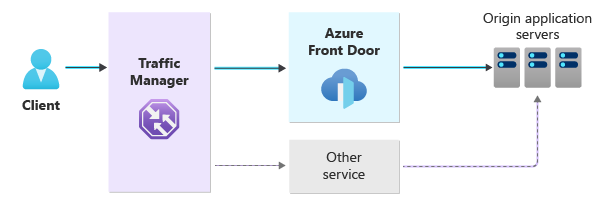
W tym podejściu wprowadzimy kilka składników i przedstawimy wskazówki, które spowodują znaczące zmiany związane z dostarczaniem aplikacji internetowych:
Usługa Azure Traffic Manager kieruje ruch do usługi Azure Front Door lub do wybranej usługi alternatywnej.
Usługa Azure Traffic Manager to globalny moduł równoważenia obciążenia oparty na systemie DNS. Rekord CNAME domeny wskazuje usługę Traffic Manager, która określa miejsce docelowe na podstawie sposobu konfigurowania metody routingu. Użycie routingu priorytetowego spowoduje, że ruch będzie domyślnie przepływać przez usługę Azure Front Door. Usługa Traffic Manager może automatycznie przełączać ruch do alternatywnej ścieżki, jeśli usługa Azure Front Door jest niedostępna.
Ważne
To rozwiązanie ogranicza ryzyko związane z awariami usługi Azure Front Door, ale jest podatne na awarie usługi Azure Traffic Manager jako globalny punkt awarii.
Możesz również rozważyć użycie innego globalnego systemu routingu ruchu, takiego jak globalny moduł równoważenia obciążenia. Jednak usługa Traffic Manager działa dobrze w wielu sytuacjach.
Istnieją dwie ścieżki ruchu przychodzącego:
Usługa Azure Front Door udostępnia podstawową ścieżkę i procesy oraz kieruje cały ruch aplikacji.
Inny router jest używany jako kopia zapasowa usługi Azure Front Door. Ruch przepływa tylko przez tę ścieżkę pomocniczą, jeśli usługa Front Door jest niedostępna.
Określona usługa wybrana dla routera pomocniczego zależy od wielu czynników. Możesz użyć usług natywnych dla platformy Azure lub usług innych firm. W tych artykułach udostępniamy opcje natywne dla platformy Azure, aby uniknąć dodawania dodatkowej złożoności operacyjnej do rozwiązania. Jeśli używasz usług innych firm, musisz użyć wielu płaszczyzn sterowania do zarządzania rozwiązaniem.
Serwery aplikacji pochodzenia muszą być gotowe do akceptowania ruchu z obu usług. Zastanów się, jak zabezpieczyć ruch do źródła oraz jakie obowiązki zapewniają usługa Front Door i inne usługi nadrzędne. Upewnij się, że aplikacja może obsługiwać ruch z niezależnie od tego, przez którą ścieżkę przepływa ruch.
Kompromisy
Chociaż ta strategia ograniczania ryzyka może sprawić, że aplikacja będzie dostępna podczas przestojów platformy, istnieją pewne znaczące kompromisy. Należy rozważyć potencjalne korzyści związane ze znanymi kosztami i podjąć świadomą decyzję o tym, czy korzyści są warte tych kosztów.
Koszt finansowy: podczas wdrażania wielu nadmiarowych ścieżek w aplikacji należy rozważyć koszt wdrażania i uruchamiania zasobów. Udostępniamy dwa przykładowe scenariusze dla różnych przypadków użycia, z których każdy ma inny profil kosztów.
Złożoność operacyjna: za każdym razem, gdy dodajesz dodatkowe składniki do rozwiązania, zwiększasz obciążenie związane z zarządzaniem. Każda zmiana jednego składnika może mieć wpływ na inne składniki.
Załóżmy, że zdecydujesz się korzystać z nowych możliwości usługi Azure Front Door. Musisz sprawdzić, czy alternatywna ścieżka ruchu zapewnia również równoważną możliwość, a jeśli nie, musisz zdecydować, jak obsłużyć różnicę w zachowaniu między dwiema ścieżkami ruchu. W rzeczywistych aplikacjach te złożoność może mieć wysoki koszt i może stanowić poważne zagrożenie dla stabilności systemu.
Wydajność: Ten projekt wymaga dodatkowych odnośników CNAME podczas rozpoznawania nazw. W większości aplikacji nie jest to istotne problem, ale należy ocenić, czy wydajność aplikacji ma wpływ na wprowadzenie dodatkowych warstw do ścieżki ruchu przychodzącego.
Koszt szansy sprzedaży: Projektowanie i implementowanie nadmiarowych ścieżek przychodzących wymaga znacznej inwestycji inżynieryjnej, co ostatecznie wiąże się z kosztem możliwości tworzenia funkcji i innych ulepszeń platformy.
Ostrzeżenie
Jeśli nie uważasz, jak projektujesz i implementujesz złożone rozwiązanie o wysokiej dostępności, możesz faktycznie pogorszyć dostępność. Zwiększenie liczby składników w architekturze zwiększa liczbę punktów awarii. Oznacza to również, że masz wyższy poziom złożoności operacyjnej. Podczas dodawania dodatkowych składników każda zmiana, którą wprowadzasz, musi zostać starannie sprawdzona, aby zrozumieć, jak wpływa ona na ogólne rozwiązanie.
Dostępność usługi Azure Traffic Manager
Usługa Azure Traffic Manager to niezawodna usługa, ale umowa dotycząca poziomu usług nie gwarantuje dostępności 100%. Jeśli usługa Traffic Manager jest niedostępna, użytkownicy mogą nie mieć dostępu do aplikacji, nawet jeśli usługa Azure Front Door i usługa alternatywna są dostępne. Ważne jest, aby zaplanować, w jaki sposób rozwiązanie będzie nadal działać w tych okolicznościach.
Usługa Traffic Manager zwraca buforowalne odpowiedzi DNS. Jeśli czas wygaśnięcia (TTL) na rekordach DNS zezwala na buforowanie, krótkie przerwy w działaniu usługi Traffic Manager mogą nie być problemem. Wynika to z faktu, że podrzędne metody rozpoznawania nazw DNS mogły buforowały poprzednią odpowiedź. Należy zaplanować długotrwałe awarie. Możesz ręcznie ponownie skonfigurować serwery DNS, aby skierować użytkowników do usługi Azure Front Door, jeśli usługa Traffic Manager jest niedostępna.
Spójność routingu ruchu
Ważne jest, aby zrozumieć możliwości i funkcje usługi Azure Front Door, z których korzystasz i na których polegasz. Po wybraniu alternatywnej usługi zdecyduj o minimalnych potrzebnych możliwościach i pomiń inne funkcje, gdy rozwiązanie jest w trybie obniżonej wydajności.
Podczas planowania alternatywnej ścieżki ruchu należy wziąć pod uwagę kilka kluczowych pytań:
- Czy używasz funkcji buforowania usługi Azure Front Door? Jeśli buforowanie jest niedostępne, czy serwery pochodzenia mogą nadążyć za ruchem?
- Czy używasz aparatu reguł usługi Azure Front Door do wykonywania niestandardowej logiki routingu lub ponownego zapisywania żądań?
- Czy używasz zapory aplikacji internetowej usługi Azure Front Door (WAF) do zabezpieczania aplikacji?
- Czy ograniczasz ruch na podstawie adresu IP lub lokalizacji geograficznej?
- Kto wystawia certyfikaty TLS i zarządzał nimi?
- Jak ograniczyć dostęp do serwerów aplikacji pochodzenia w celu zapewnienia dostępu do usługi Azure Front Door? Czy używasz usługi Private Link, czy korzystasz z publicznych adresów IP z tagami usługi i nagłówkami identyfikatorów?
- Czy serwery aplikacji akceptują ruch z dowolnego miejsca innego niż usługa Azure Front Door? Jeśli to zrobią, które protokoły akceptują?
- Czy klienci korzystają z obsługi protokołu HTTP/2 usługi Azure Front Door?
Zapora aplikacji internetowej
Jeśli używasz zapory aplikacji internetowej usługi Azure Front Door do ochrony aplikacji, rozważ, co się stanie, jeśli ruch nie przejdzie przez usługę Azure Front Door.
Jeśli alternatywna ścieżka zawiera również zaporę aplikacji internetowej, rozważ następujące pytania:
- Czy można go skonfigurować w taki sam sposób jak zapora aplikacji internetowej usługi Azure Front Door?
- Czy należy go dostroić i przetestować niezależnie, aby zmniejszyć prawdopodobieństwo wykrycia wyników fałszywie dodatnich?
Ostrzeżenie
Możesz zrezygnować z używania zapory aplikacji internetowej dla alternatywnej ścieżki ruchu przychodzącego. Takie podejście można uznać za obsługę celu niezawodności aplikacji. Nie jest to jednak dobra praktyka i nie zalecamy jej.
Rozważ kompromis w akceptowaniu ruchu z Internetu bez żadnych kontroli. Jeśli osoba atakująca wykryje niechronione ścieżki ruchu pomocniczego do aplikacji, może wysłać złośliwy ruch przez ścieżkę pomocniczą nawet wtedy, gdy ścieżka podstawowa zawiera zaporę aplikacji internetowej.
Najlepiej zabezpieczyć wszystkie ścieżki do serwerów aplikacji.
Nazwy domen i system DNS
Aplikacja o znaczeniu krytycznym powinna używać niestandardowej nazwy domeny. Będziesz kontrolować sposób przepływu ruchu do aplikacji i zmniejszyć zależności od jednego dostawcy.
Dobrym rozwiązaniem jest również użycie wysokiej jakości i odpornej usługi DNS dla nazwy domeny, takiej jak Azure DNS. Jeśli serwery DNS twojej nazwy domeny są niedostępne, użytkownicy nie mogą nawiązać połączenia z usługą.
Zaleca się użycie wielu rozpoznawania nazw DNS w celu jeszcze większej odporności.
Łączenie łańcuchów CNAME
Rozwiązania łączące usługę Traffic Manager, usługę Azure Front Door i inne usługi korzystają z wielowarstwowego procesu rozpoznawania rekordów CNAME SYSTEMU DNS, nazywanego również łańcuchem CNAME. Na przykład po rozwiązaniu własnej domeny niestandardowej może zostać wyświetlonych pięć lub więcej rekordów CNAME przed zwróceniem adresu IP.
Dodanie dodatkowych linków do łańcucha CNAME może mieć wpływ na wydajność rozpoznawania nazw DNS. Jednak odpowiedzi DNS są zwykle buforowane, co zmniejsza wpływ na wydajność.
Certyfikaty TLS
W przypadku aplikacji o krytycznym znaczeniu zaleca się aprowizację i używanie własnych certyfikatów TLS zamiast zarządzanych certyfikatów udostępnianych przez usługę Azure Front Door. Zmniejszysz liczbę potencjalnych problemów z tą złożoną architekturą.
Oto kilka korzyści:
Aby wystawiać i odnawiać zarządzane certyfikaty TLS, usługa Azure Front Door weryfikuje własność domeny. Proces weryfikacji domeny zakłada, że rekordy CNAME domeny wskazują bezpośrednio na usługę Azure Front Door. Ale to założenie często nie jest poprawne. Wystawianie i odnawianie zarządzanych certyfikatów TLS w usłudze Azure Front Door może nie działać bezproblemowo i zwiększa ryzyko awarii z powodu problemów z certyfikatem TLS.
Nawet jeśli inne usługi zapewniają zarządzane certyfikaty TLS, mogą nie być w stanie zweryfikować własności domeny.
Jeśli każda usługa niezależnie pobiera własne zarządzane certyfikaty TLS, mogą wystąpić problemy. Na przykład użytkownicy mogą nie spodziewać się wyświetlenia różnych certyfikatów TLS wystawionych przez różne urzędy lub z różnymi datami wygaśnięcia lub odciskami palca.
Jednak przed wygaśnięciem będą istnieć dodatkowe operacje związane z odnawianiem i aktualizowaniem certyfikatów.
Zabezpieczenia źródła
Podczas konfigurowania źródła tak, aby akceptował tylko ruch za pośrednictwem usługi Azure Front Door, uzyskujesz ochronę przed atakami DDoS warstwy 3 i 4. Ponieważ usługa Azure Front Door reaguje tylko na prawidłowy ruch HTTP, pomaga również zmniejszyć narażenie na wiele zagrożeń opartych na protokole. Jeśli zmienisz architekturę tak, aby zezwalała na alternatywne ścieżki ruchu przychodzącego, musisz ocenić, czy przypadkowo zwiększono narażenie źródła na zagrożenia.
Jeśli używasz usługi Private Link do nawiązywania połączenia z usługi Azure Front Door z serwerem pochodzenia, jak ruch przepływa przez alternatywną ścieżkę? Czy można używać prywatnych adresów IP do uzyskiwania dostępu do źródeł lub czy należy używać publicznych adresów IP?
Jeśli źródło używa tagu usługi Azure Front Door i nagłówka X-Azure-FDID, aby sprawdzić, czy ruch przepływał przez usługę Azure Front Door, rozważ ponowne skonfigurowanie źródeł, aby sprawdzić, czy ruch przepływał przez jedną z prawidłowych ścieżek. Musisz sprawdzić, czy nie otwarto przypadkowo źródła ruchu przez inne ścieżki, w tym z profilów usługi Azure Front Door innych klientów.
Podczas planowania zabezpieczeń źródła sprawdź, czy alternatywna ścieżka ruchu opiera się na aprowizacji dedykowanych publicznych adresów IP. Może to wymagać ręcznego wyzwolenia procesu w celu przełączenie ścieżki kopii zapasowej w tryb online.
Jeśli istnieją dedykowane publiczne adresy IP, zastanów się, czy należy wdrożyć usługę Azure DDoS Protection , aby zmniejszyć ryzyko ataków typu "odmowa usługi" na źródła. Należy również rozważyć, czy należy zaimplementować usługę Azure Firewall , czy inną zaporę, która może chronić Cię przed różnymi zagrożeniami sieci. Może być również konieczne więcej strategii wykrywania nieautoryzowanego dostępu. Te kontrolki mogą być ważnymi elementami bardziej złożonej architektury wielościeżkowej.
Modelowanie kondycji
Metodologia projektowania o krytycznym znaczeniu wymaga modelu kondycji systemu, który zapewnia ogólną obserwację rozwiązania i jego składników. W przypadku korzystania z wielu ścieżek ruchu przychodzącego należy monitorować kondycję każdej ścieżki. Jeśli ruch jest przekierowywany do pomocniczej ścieżki ruchu przychodzącego, model kondycji powinien odzwierciedlać fakt, że system nadal działa, ale działa w stanie obniżonej wydajności.
Uwzględnij następujące pytania w projekcie modelu kondycji:
- Jak różne składniki rozwiązania monitorują kondycję składników podrzędnych?
- Kiedy monitory kondycji powinny uwzględniać składniki podrzędne w złej kondycji?
- Jak długo trwa wykrywanie awarii?
- Jak długo trwa kierowanie ruchu przez alternatywną ścieżkę po wykryciu awarii?
Istnieje wiele globalnych rozwiązań do równoważenia obciążenia, które umożliwiają monitorowanie kondycji usługi Azure Front Door i wyzwalanie automatycznego przejścia w tryb failover na platformę kopii zapasowej, jeśli wystąpi awaria. Usługa Azure Traffic Manager jest odpowiednia w większości przypadków. Za pomocą usługi Traffic Manager można skonfigurować monitorowanie punktów końcowych w celu monitorowania usług podrzędnych, określając adres URL do sprawdzenia, jak często należy sprawdzić ten adres URL i kiedy należy wziąć pod uwagę złą kondycję usługi podrzędnej na podstawie odpowiedzi sondy. Ogólnie rzecz biorąc, krótszy interwał między sprawdzaniem, tym krótszy czas kierowania ruchu przez usługę Traffic Manager przez alternatywną ścieżkę dotarcia do serwera pochodzenia.
Jeśli usługa Front Door jest niedostępna, wiele czynników wpływa na czas przestoju ruchu, w tym:
- Czas wygaśnięcia (TTL) w rekordach DNS.
- Jak często usługa Traffic Manager uruchamia testy kondycji.
- Ile sond nie powiodło się, usługa Traffic Manager jest skonfigurowana do wyświetlenia, zanim przekierowuje ruch.
- Jak długo klienci i nadrzędne serwery DNS buforuje odpowiedzi DNS usługi Traffic Manager dla.
Musisz również określić, które z tych czynników znajdują się w twojej kontrolce i czy usługi nadrzędne poza kontrolą mogą mieć wpływ na środowisko użytkownika. Na przykład, nawet jeśli używasz niskiego czasu wygaśnięcia w rekordach DNS, nadrzędne pamięci podręczne DNS mogą nadal obsługiwać nieaktualne odpowiedzi dłużej niż powinny. To zachowanie może zaostrzyć skutki awarii lub sprawić, że aplikacja będzie niedostępna, nawet jeśli usługa Traffic Manager przełączyć się na wysyłanie żądań do alternatywnej ścieżki ruchu.
Napiwek
Rozwiązania o znaczeniu krytycznym wymagają zautomatyzowanych metod trybu failover wszędzie tam, gdzie jest to możliwe. Ręczne procesy trybu failover są uznawane za powolne, aby aplikacja pozostała elastyczna.
Zapoznaj się z tematem: Obszar projektowania o krytycznym znaczeniu: Modelowanie kondycji
Wdrażanie bez przestojów
Podczas planowania działania rozwiązania ze ścieżką nadmiarowego ruchu przychodzącego należy również zaplanować sposób wdrażania lub konfigurowania usług w przypadku ich obniżonej wydajności. W przypadku większości usług platformy Azure umowy SLA mają zastosowanie do czasu działania samej usługi, a nie do operacji zarządzania lub wdrożeń. Zastanów się, czy procesy wdrażania i konfiguracji muszą być odporne na awarie usług.
Należy również wziąć pod uwagę liczbę niezależnych płaszczyzn sterowania, z którymi należy korzystać w celu zarządzania rozwiązaniem. W przypadku korzystania z usług platformy Azure usługa Azure Resource Manager zapewnia ujednoliconą i spójną płaszczyznę sterowania. Jeśli jednak używasz usługi innej firmy do kierowania ruchu, może być konieczne użycie oddzielnej płaszczyzny sterowania do skonfigurowania usługi, która wprowadza dalszą złożoność operacyjną.
Ostrzeżenie
Użycie wielu płaszczyzn sterowania wprowadza złożoność i ryzyko dla rozwiązania. Każdy punkt różnicy zwiększa prawdopodobieństwo przypadkowego chybienia ustawienia konfiguracji lub zastosowania różnych konfiguracji do nadmiarowych składników. Upewnij się, że procedury operacyjne ograniczają to ryzyko.
Zapoznaj się z tematem: Obszar projektowania o krytycznym znaczeniu: wdrożenie bez przestoju
Ciągła walidacja
W przypadku rozwiązania o krytycznym znaczeniu rozwiązania testowe należy sprawdzić, czy rozwiązanie spełnia wymagania niezależnie od ścieżki, przez którą przepływa ruch aplikacji. Rozważ każdą część rozwiązania i sposób testowania jej dla każdego typu awarii.
Upewnij się, że procesy testowania zawierają następujące elementy:
- Czy można sprawdzić, czy ruch jest prawidłowo przekierowywany za pośrednictwem alternatywnej ścieżki, gdy ścieżka podstawowa jest niedostępna?
- Czy obie ścieżki mogą obsługiwać oczekiwany poziom ruchu produkcyjnego?
- Czy obie ścieżki są odpowiednio zabezpieczone, aby uniknąć otwierania lub uwidaczniania luk w zabezpieczeniach w stanie obniżonej wydajności?
Zapoznaj się z tematem: Obszar projektowania o krytycznym znaczeniu: Ciągła walidacja
Typowe scenariusze
Poniżej przedstawiono typowe scenariusze, w których można użyć tego projektu:
Globalne dostarczanie zawartości jest często stosowane do statycznych aplikacji do dostarczania zawartości, multimediów i handlu elektronicznego na dużą skalę. W tym scenariuszu buforowanie jest krytyczną częścią architektury rozwiązania, a błędy pamięci podręcznej mogą spowodować znaczne obniżenie wydajności lub niezawodności.
Globalny ruch przychodzący HTTP jest często stosowany do aplikacji dynamicznych i interfejsów API o krytycznym znaczeniu. W tym scenariuszu podstawowym wymaganiem jest niezawodne i wydajne kierowanie ruchu do serwera pochodzenia. Często zapora aplikacji internetowej jest ważną kontrolą zabezpieczeń używaną w tych rozwiązaniach.
Ostrzeżenie
Jeśli nie uważasz, jak projektujesz i implementujesz złożone rozwiązanie z wieloma ruchem przychodzącym, możesz faktycznie pogorszyć dostępność. Zwiększenie liczby składników w architekturze zwiększa liczbę punktów awarii. Oznacza to również, że masz wyższy poziom złożoności operacyjnej. Podczas dodawania dodatkowych składników każda zmiana, którą wprowadzasz, musi zostać starannie sprawdzona, aby zrozumieć, jak wpływa ona na ogólne rozwiązanie.
Następne kroki
Przejrzyj globalne scenariusze ruchu przychodzącego HTTP i globalnego dostarczania zawartości, aby dowiedzieć się, czy mają zastosowanie do twojego rozwiązania.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla