Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Nowoczesne systemy biznesowe zarządzają coraz większymi ilościami danych heterogenicznych. Ta heterogeniczność oznacza, że pojedynczy magazyn danych zwykle nie jest najlepszym podejściem. Zamiast tego często lepiej jest przechowywać różne typy danych w różnych magazynach danych, z których każdy koncentruje się na konkretnym obciążeniu lub wzorcu użycia. Termin trwałości poliglotycznej służy do opisywania rozwiązań korzystających z różnych technologii przechowywania danych. Dlatego ważne jest, aby zrozumieć główne modele magazynowania i ich kompromisy.
Wybór odpowiedniego magazynu danych dla Twoich wymagań jest kluczową decyzją projektową. Istnieje dosłownie setki implementacji do wyboru spośród baz danych SQL i NoSQL. Magazyny danych są często podzielone na kategorie według struktury danych i typów operacji, które obsługują. W tym artykule opisano kilka najczęściej używanych modeli magazynowania. Należy pamiętać, że określona technologia magazynu danych może obsługiwać wiele modeli magazynu. Na przykład systemy zarządzania relacyjnymi bazami danych (RDBMS) mogą również obsługiwać magazyn kluczy/wartości lub grafów. W rzeczywistości istnieje ogólny trend tzw. obsługi wielomodelowej, gdzie pojedynczy system baz danych obsługuje kilka modeli. Ale nadal warto zrozumieć różne modele na wysokim poziomie.
Nie wszystkie magazyny danych w danej kategorii zawierają ten sam zestaw funkcji. Większość magazynów danych zapewnia funkcje po stronie serwera do wykonywania zapytań i przetwarzania danych. Czasami ta funkcjonalność jest wbudowana w silnik pamięci danych. W innych przypadkach możliwości przechowywania i przetwarzania danych są oddzielone i mogą istnieć kilka opcji przetwarzania i analizy. Magazyny danych obsługują również różne interfejsy programowe i zarządzania.
Ogólnie rzecz biorąc, należy zacząć od rozważenia, który model magazynu najlepiej nadaje się do Twoich wymagań. Następnie rozważ określony magazyn danych w tej kategorii na podstawie czynników, takich jak zestaw funkcji, koszt i łatwość zarządzania.
Notatka
Dowiedz się więcej na temat identyfikowania i analizowania wymagań związanych z usługami danych dotyczącymi wdrażania chmury w ramach Microsoft Cloud Adoption Framework for Azure. Podobnie możesz dowiedzieć się więcej na temat wybierania narzędzi do przechowywania i usług.
Systemy zarządzania relacyjnymi bazami danych
Relacyjne bazy danych organizują dane jako serię tabel dwuwymiarowych z wierszami i kolumnami. Większość dostawców zapewnia dialekt języka Structured Query Language (SQL) do pobierania danych i zarządzania nimi. System RDBMS zwykle implementuje transakcyjnie spójny mechanizm, który jest zgodny z modelem ACID (Atomic, Consistent, Isolated, Durable) na potrzeby aktualizowania informacji.
System RDBMS zwykle obsługuje model schematu na zapis, w którym struktura danych jest definiowana przed upływem czasu, a wszystkie operacje odczytu lub zapisu muszą używać schematu.
Model ten jest bardzo przydatny, gdy ważne są silne gwarancje spójności — wszystkie zmiany są niepodzielne, a transakcje zawsze pozostawiają dane w spójnym stanie. Jednak system RDBMS zazwyczaj nie może skalować w poziomie bez fragmentowania danych w jakiś sposób. Ponadto dane w systemie RDBMS muszą być znormalizowane, co nie jest odpowiednie dla każdego zestawu danych.
Usługi platformy Azure
- Azure SQL Database | (Podstawowe wytyczne zabezpieczeń)
-
Azure Database for MySQL (punkt odniesienia zabezpieczeń) - Azure Database for PostgreSQL | (punkt odniesienia zabezpieczeń)
Obciążenia
- Rekordy są często tworzone i aktualizowane.
- Wiele operacji należy wykonać w jednej transakcji.
- Relacje są wymuszane przy użyciu ograniczeń bazy danych.
- Indeksy są używane do optymalizowania wydajności zapytań.
Typ danych
- Dane są wysoce znormalizowane.
- Schematy bazy danych są wymagane i wymuszane.
- Relacje wiele-do-wielu między obiektami danych w bazie danych.
- Ograniczenia są definiowane w schemacie i nakładane na dowolne dane w bazie danych.
- Dane wymagają wysokiej integralności. Indeksy i relacje muszą być dokładnie utrzymywane.
- Dane wymagają silnej spójności. Transakcje działają w sposób zapewniający, że wszystkie dane są spójne na poziomie 100% dla wszystkich użytkowników i procesów.
- Rozmiar pojedynczych wpisów danych jest mały i średni.
Przykłady
- Zarządzanie spisem
- Zarządzanie zamówieniami
- Baza danych raportowania
- Rachunkowość
Magazyny klucz/wartość
Przechowalnia klucz/wartość kojarzy każdą wartość danych z unikatowym kluczem. Większość magazynów kluczy/wartości obsługuje tylko proste operacje zapytań, wstawiania i usuwania. Aby zmodyfikować wartość (częściowo lub całkowicie), aplikacja musi zastąpić istniejące dane dla całej wartości. W większości implementacji odczyt lub zapis pojedynczej wartości jest operacją atomową.
Aplikacja może przechowywać dowolne dane jako zestaw wartości. Wszystkie informacje o schemacie muszą być udostępniane przez aplikację. Magazyn danych klucz/wartość po prostu pobiera lub przechowuje wartość za pomocą klucza.
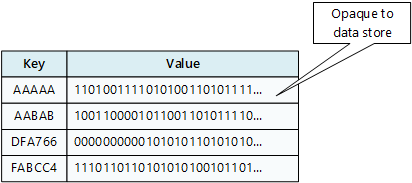
Magazyny klucz-wartość są wysoce zoptymalizowane pod kątem aplikacji wykonujących proste wyszukiwania, ale są mniej odpowiednie, jeśli musisz wykonywać zapytania o dane w różnych magazynach klucz-wartość. Bazy danych klucz/wartość nie są zoptymalizowane pod kątem zapytań według wartości.
Pojedynczy magazyn kluczy/wartości może być niezwykle skalowalny, ponieważ magazyn danych może łatwo dystrybuować dane między wieloma węzłami na oddzielnych maszynach.
Usługi platformy Azure
- Azure Cosmos DB for Table and Azure Cosmos DB for NoSQL | (Punkt odniesienia zabezpieczeń usługi Azure Cosmos DB)
- Azure Cache for Redis | (punkt odniesienia zabezpieczeń)
- Azure Table Storage | (punkt odniesienia zabezpieczeń)
Obciążenia
- Dostęp do danych jest uzyskiwany przy użyciu pojedynczego klucza, takiego jak słownik.
- Nie są wymagane żadne złączenia, blokady ani unie.
- Nie są używane żadne mechanizmy agregacji.
- Indeksy pomocnicze zwykle nie są używane.
Typ danych
- Każdy klucz jest skojarzony z pojedynczą wartością.
- Nie stosuje się wymuszania schematu.
- Brak relacji między jednostkami.
Przykłady
- Buforowanie danych
- Zarządzanie sesjami
- Preferencje użytkownika i zarządzanie profilami
- Rekomendacje dotyczące produktów i obsługa reklam
Bazy danych dokumentów
Baza danych dokumentów przechowuje kolekcję dokumentów , gdzie każdy dokument składa się z nazwanych pól i danych. Dane mogą być prostymi wartościami lub złożonymi elementami, takimi jak listy i podkolekcje. Dokumenty są pobierane przez unikatowe klucze.
Zazwyczaj dokument zawiera dane dla pojedynczej jednostki, takie jak klient lub zamówienie. Dokument może zawierać informacje, które byłyby rozmieszczone w kilku tabelach relacyjnych w systemie RDBMS. Dokumenty nie muszą mieć tej samej struktury. Aplikacje mogą przechowywać różne dane w dokumentach w miarę zmiany wymagań biznesowych.
diagram sklepu dokumentów 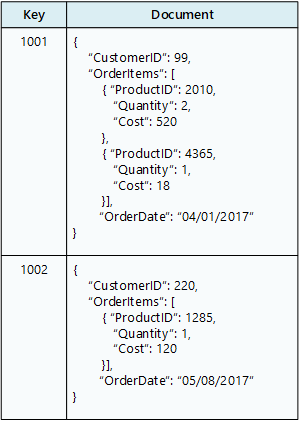
Usługa platformy Azure
Obciążenia
- Operacje wstawiania i aktualizowania są typowe.
- Brak niezgodności obiektowo-relacyjnej impedancji. Dokumenty mogą lepiej dopasować struktury obiektów używane w kodzie aplikacji.
- Poszczególne dokumenty są pobierane i zapisywane jako pojedynczy blok.
- Dane wymagają indeksu w wielu polach.
Typ danych
- Danymi można zarządzać w zdenormalizowany sposób.
- Rozmiar poszczególnych danych dokumentu jest stosunkowo mały.
- Każdy typ dokumentu może używać własnego schematu.
- Dokumenty mogą zawierać pola opcjonalne.
- Dane dokumentu są częściowo ustrukturyzowane, co oznacza, że typy danych każdego pola nie są ściśle zdefiniowane.
Przykłady
- Katalog produktów
- Zarządzanie zawartością
- Zarządzanie spisem
Grafowe bazy danych
Grafowa baza danych przechowuje dwa typy informacji, węzłów i krawędzi. Krawędzie określają relacje między węzłami. Węzły i krawędzie mogą mieć właściwości, które zawierają informacje o tym węźle lub krawędzi, podobnie jak w kolumnach w tabeli. Krawędzie mogą również mieć kierunek wskazujący charakter relacji.
Grafowe bazy danych mogą wydajnie wykonywać zapytania w sieci węzłów i krawędzi oraz analizować relacje między jednostkami. Na poniższym diagramie przedstawiono bazę danych personelu organizacji ustrukturyzowaną jako graf. Jednostki to pracownicy i działy, a krawędzie wskazują relacje raportowania i działy, w których pracują pracownicy.
diagram 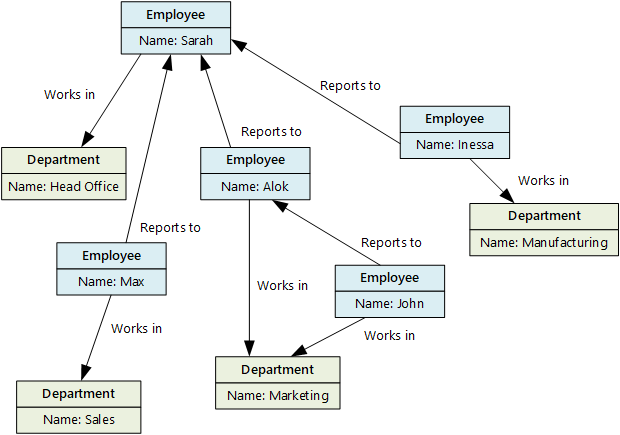
Ta struktura ułatwia wykonywanie zapytań, takich jak "Znajdź wszystkich pracowników, którzy zgłaszają się bezpośrednio lub pośrednio do Sarah" lub "Kto pracuje w tym samym dziale co Jan?" W przypadku dużych grafów z dużą częścią jednostek i relacji można bardzo szybko wykonywać bardzo złożone analizy. Wiele grafowych baz danych udostępnia język zapytań, którego można użyć do wydajnego przechodzenia przez sieć relacji.
Usługi platformy Azure
- Azure Cosmos DB for Apache Gremlin | (punkt odniesienia zabezpieczeń)
programu SQL Server (punkt odniesienia zabezpieczeń)
Obciążenia
- Złożone relacje między elementami danych obejmującymi wiele przeskoków między powiązanymi elementami danych.
- Relacja między elementami danych jest dynamiczna i zmienia się w czasie.
- Relacje między obiektami są traktowane priorytetowo, bez konieczności stosowania kluczy obcych i złączeń do ich przeszukiwania.
Typ danych
- Węzły i relacje.
- Węzły są podobne do wierszy tabeli lub dokumentów JSON.
- Relacje są równie ważne jak węzły i są widoczne bezpośrednio w języku zapytań.
- Obiekty złożone, takie jak osoba z wieloma numerami telefonów, mają tendencję do podziału na oddzielne, mniejsze węzły, połączone z relacjami umożliwiającymi przechodzenie.
Przykłady
- Schematy organizacyjne
- Grafy społeczne
- Wykrywanie oszustw
- Silniki rekomendacji
Analiza danych
Magazyny analizy danych zapewniają bardzo równoległe rozwiązania do pozyskiwania, przechowywania i analizowania danych. Dane są dystrybuowane na wielu serwerach w celu zmaksymalizowania skalowalności. Duże formaty plików danych, takie jak pliki ograniczników (CSV), parqueti ORC są szeroko używane w analizie danych. Dane historyczne są zwykle przechowywane w magazynach danych, takich jak magazyn obiektów blob lub Azure Data Lake Storage Gen2, które są następnie dostępne przez usługę Azure Synapse, usługę Databricks lub usługę HDInsight jako tabele zewnętrzne. Typowy scenariusz użycia danych przechowywanych jako pliki Parquet dla poprawy wydajności opisano w artykule Używanie tabel zewnętrznych z usługą Synapse SQL.
Usługi platformy Azure
- azure Synapse Analytics | (punkt odniesienia zabezpieczeń)
-
Azure Data Lake (punkt odniesienia zabezpieczeń) - | Azure Data Explorer (punkt odniesienia zabezpieczeń)
- Azure Analysis Services usług Azure Analysis Services
- usługi HDInsight | (punkt odniesienia zabezpieczeń)
- Azure Databricks | (punkt odniesienia zabezpieczeń)
Obciążenia
- Analiza danych
- BI w przedsiębiorstwie
Typ danych
- Dane historyczne z wielu źródeł.
- Zwykle zdenormalizowane do schematu "gwiazdy" lub "płatka śniegu", które składają się z tabel faktów i wymiarów.
- Nowe dane są zwykle ładowane zgodnie z harmonogramem.
- Tabele wymiarów często zawierają wiele historycznych wersji jednostki, nazywanych powoli zmieniającym się wymiarem.
Przykłady
- Magazyn danych przedsiębiorstwa
Bazy danych typu kolumna-rodzina
Baza danych rodziny kolumn organizuje dane w wiersze i kolumny. W najprostszej formie baza danych rodziny kolumn może wyglądać bardzo podobnie do relacyjnej bazy danych, przynajmniej koncepcyjnie. Prawdziwa siła bazy danych rodziny kolumn leży w jej zdenormalizowanym podejściu do struktury danych rozrzednionych.
Bazę danych rodziny kolumn można traktować jako bazę danych tabelarycznych z wierszami i kolumnami, ale kolumny są podzielone na grupy znane jako rodziny kolumn . Każda rodzina kolumn zawiera zestaw kolumn, które są logicznie powiązane i są zwykle pobierane lub manipulowane jako jednostka. Inne dane, do których uzyskuje się dostęp oddzielnie, mogą być przechowywane w osobnych rodzinach kolumn. W obrębie rodziny kolumn można dynamicznie dodawać nowe kolumny, a wiersze mogą być rozrzedłe (czyli wiersz nie musi mieć wartości dla każdej kolumny).
Na poniższym diagramie przedstawiono przykład z dwiema rodzinami kolumn, Identity i Contact Info. Dane dla pojedynczej jednostki mają ten sam klucz wiersza w każdej rodzinie kolumn. Ta struktura, w której wiersze dla dowolnego obiektu w rodzinie kolumn mogą się różnić dynamicznie, jest ważną zaletą podejścia rodziny kolumn, dzięki czemu ta forma magazynu danych jest bardzo odpowiednia do przechowywania danych strukturalnych, nietrwałych.
 bazy danych z rodziną kolumn
bazy danych z rodziną kolumn
W przeciwieństwie do magazynu kluczy/wartości lub bazy danych dokumentów, większość baz danych typu column-family przechowuje dane w kolejności klucza, a nie poprzez hashowanie. Wiele implementacji umożliwia tworzenie indeksów dla określonych kolumn w rodzinie kolumn. Indeksy umożliwiają pobieranie danych na podstawie wartości kolumny, a nie klucza wiersza.
Operacje odczytu i zapisu dla wiersza są zwykle niepodzielne w ramach jednej rodziny kolumn, chociaż niektóre implementacje zapewniają niepodzielność w całym wierszu, obejmującą wiele rodzin kolumn.
Usługi platformy Azure
- Azure Cosmos DB for Apache Cassandra | (Punkt odniesienia zabezpieczeń)
- HBase w usłudze HDInsight | (punkt odniesienia zabezpieczeń)
Obciążenia
- Większość baz danych rodziny kolumn bardzo szybko wykonuje operacje zapisu.
- Operacje aktualizacji i usuwania są rzadkie.
- Zaprojektowano tak, aby zapewnić wysoką przepływność i dostęp o małych opóźnieniach.
- Obsługuje łatwy dostęp do zapytań do określonego zestawu pól w znacznie większym rekordzie.
- Wysoce skalowalne.
Typ danych
- Dane są przechowywane w tabelach składających się z kolumny klucza i co najmniej jednej rodziny kolumn.
- Określone kolumny mogą się różnić w zależności od poszczególnych wierszy.
- Dostęp do poszczególnych komórek jest uzyskiwany za pośrednictwem poleceń get i put
- Wiele wierszy jest zwracanych przy użyciu polecenia skanowania.
Przykłady
- Zalecenia
- Personalizacja
- Dane czujnika
- Telemetria
- Wiadomości
- Analiza mediów społecznościowych
- Analiza sieci Web
- Monitorowanie działań
- Pogoda i inne dane szeregów czasowych
Bazy danych aparatu wyszukiwania
Baza danych aparatu wyszukiwania umożliwia aplikacjom wyszukiwanie informacji przechowywanych w zewnętrznych magazynach danych. Baza danych aparatu wyszukiwania może indeksować ogromne ilości danych i zapewniać niemal w czasie rzeczywistym dostęp do tych indeksów.
Indeksy mogą być wielowymiarowe i mogą obsługiwać wyszukiwania bez tekstu w dużych ilościach danych tekstowych. Indeksowanie można wykonywać przy użyciu modelu ściągania, wyzwalanego przez bazę danych aparatu wyszukiwania lub przy użyciu modelu wypychania zainicjowanego przez kod aplikacji zewnętrznej.
Wyszukiwanie może być dokładne lub rozmyte. Wyszukiwanie rozmyte znajduje dokumenty zgodne z zestawem terminów i oblicza, jak ściśle pasują do nich. Niektóre wyszukiwarki obsługują również analizę językową, która może zwracać dopasowania na podstawie synonimów, rozszerzeń gatunku (na przykład dopasowywania dogs do pets) i cięcia wyrazów (dopasowywanie wyrazów z tym samym rdzeniem).
Usługa platformy Azure
Obciążenia
- Indeksy danych z wielu źródeł i usług.
- Zapytania są ad hoc i mogą być złożone.
- Wyszukiwanie pełnotekstowe jest wymagane.
- Wymagane jest zapytanie samoobsługowe ad hoc.
Typ danych
- Tekst częściowo ustrukturyzowany lub nieustrukturyzowany
- Tekst z odwołaniem do danych strukturalnych
Przykłady
- Katalogi produktów
- Wyszukiwanie w witrynie
- Przemysł drzewny
Bazy danych szeregów czasowych
Dane szeregów czasowych to zestaw wartości zorganizowanych według czasu. Bazy danych szeregów czasowych zwykle zbierają duże ilości danych w czasie rzeczywistym z dużej liczby źródeł. Aktualizacje są rzadkie, a usunięcia często wykonywane są jako operacje zbiorcze. Chociaż rekordy zapisywane w bazie danych szeregów czasowych są zwykle małe, często istnieje duża liczba rekordów, a całkowity rozmiar danych może szybko rosnąć.
Usługa platformy Azure
Obciążenia
- Rekordy są zwykle dołączane sekwencyjnie w kolejności czasu.
- Przytłaczająca część operacji (95-99%) to operacje zapisywania.
- Aktualizacje są rzadkie.
- Usunięcia są wykonywane zbiorczo i dotyczą ciągłych bloków lub rekordów.
- Dane są odczytywane sekwencyjnie w kolejności rosnącej lub malejącej, często równolegle.
Typ danych
- Sygnatura czasowa jest używana jako klucz podstawowy i mechanizm sortowania.
- Tagi mogą definiować dodatkowe informacje o typie, pochodzeniu i innych informacjach o wpisie.
Przykłady
- Monitorowanie i telemetria zdarzeń.
- Czujnik lub inne dane IoT.
Przechowywanie obiektów
Magazyn obiektów jest zoptymalizowany pod kątem przechowywania i pobierania dużych obiektów binarnych (obrazów, plików, strumieni wideo i audio, dużych obiektów danych aplikacji i dokumentów, obrazów dysków maszyny wirtualnej). Duże pliki danych są również często używane w tym modelu, na przykład plik ogranicznika (CSV), parqueti ORC. Magazyny obiektów mogą zarządzać bardzo dużą ilością danych bez struktury.
Usługa platformy Azure
-
Azure Blob Storage (punkt odniesienia zabezpieczeń) - azure Data Lake Storage Gen2 | (punkt odniesienia zabezpieczeń)
Obciążenia
- Rozpoznane za pomocą klucza.
- Zawartość jest zazwyczaj zasobem, takim jak ogranicznik, obraz lub plik wideo.
- Zawartość musi być trwała i zewnętrzna dla dowolnej warstwy aplikacji.
Typ danych
- Rozmiar danych jest duży.
- Wartość jest nieprzezroczysta.
Przykłady
- Obrazy, filmy wideo, dokumenty pakietu Office, pliki PDF
- Statyczny kod HTML, JSON, CSS
- Pliki dziennika i audytu
- Kopie zapasowe bazy danych
Pliki udostępnione
Czasami użycie prostych plików prostych może być najbardziej skutecznym sposobem przechowywania i pobierania informacji. Korzystanie z udostępniania plików umożliwia uzyskiwanie dostępu do plików w sieci. Biorąc pod uwagę odpowiednie mechanizmy zabezpieczeń i współbieżnej kontroli dostępu, udostępnianie danych w ten sposób może umożliwić rozproszonym usługom zapewnienie wysoce skalowalnego dostępu do danych na potrzeby wykonywania podstawowych operacji niskiego poziomu, takich jak proste żądania odczytu i zapisu.
Usługa platformy Azure
Obciążenia
- Migracja z istniejących aplikacji, które współdziałają z systemem plików.
- Wymaga interfejsu SMB.
Typ danych
- Pliki w hierarchicznym zestawie folderów.
- Dostępny z standardowymi bibliotekami we/wy.
Przykłady
- Starsze pliki
- Udostępniona zawartość dostępna pomiędzy wieloma maszynami wirtualnymi lub wystąpieniami aplikacji
Ułatwia to zrozumienie różnych modeli magazynowania danych, następnym krokiem jest ocena obciążenia i aplikacji oraz podjęcie decyzji, który magazyn danych będzie spełniał określone potrzeby. Użyj drzewa decyzyjnego dotyczącego przechowywania danych, aby ułatwić ten proces.
Następne kroki
- Rozwiązania i Usługi Azure Cloud Storage
- Przejrzyj swoje opcje przechowywania
- Wprowadzenie do usługi Azure Storage
- Wprowadzenie do usługi Azure Data Explorer