Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ponieważ aplikacje i usługi natywne dla chmury stają się bardziej złożone, wdrażanie zmian i nowych wersji dla nich może być trudne. Awarie są często spowodowane wadliwymi wdrożeniami lub wydaniami. Jednak błędy mogą wystąpić również po wdrożeniu, gdy aplikacja zacznie odbierać rzeczywisty ruch, zwłaszcza w przypadku złożonych obciążeń uruchamianych w wysoce rozproszonych wielodostępnych środowiskach w chmurze i obsługiwanych przez wiele zespołów programistycznych. Te środowiska wymagają większej liczby miar odporności, takich jak logika ponawiania prób i skalowanie automatyczne, które zwykle są trudne do przetestowania podczas procesu programowania.
Dlatego ciągła walidacja w środowisku podobnym do środowiska produkcyjnego jest ważna, dzięki czemu można znaleźć i rozwiązać wszelkie problemy lub błędy tak szybko, jak to możliwe. Zespoły ds. obciążeń powinny testować na wczesnym etapie procesu programowania (przesunięcie w lewo) i ułatwić deweloperom testowanie w środowisku zbliżonym do środowiska produkcyjnego.
Obciążenia o znaczeniu krytycznym mają wymagania dotyczące wysokiej dostępności, z celami 3, 4 lub 5 dziewiątek (odpowiednio 99,9%, 99,99%lub 99,999%). Kluczowe jest zaimplementowanie rygorystycznych testów automatycznych w celu osiągnięcia tych celów.
Ciągła walidacja zależy od każdego obciążenia i charakterystyki architektury. Ten artykuł zawiera przewodnik przygotowywania i integrowania testowania obciążenia platformy Azure i programu Azure Chaos Studio w regularnym cyklu programowania.
1 — Definiowanie testów na podstawie oczekiwanych progów
Ciągłe testowanie to złożony proces, który wymaga odpowiedniego przygotowania. To, co zostanie przetestowane, a oczekiwane wyniki muszą być jasne.
W pe:06 — Zalecenia dotyczące testowania wydajnościowego i RE:08 — Zalecenia dotyczące projektowania strategii testowania niezawodności, platforma Azure Well-Architected Framework zaleca rozpoczęcie od zidentyfikowania kluczowych scenariuszy, zależności, oczekiwanego użycia, dostępności, wydajności i celów skalowalności.
Następnie należy zdefiniować zestaw mierzalnych wartości progowych , aby określić oczekiwaną wydajność kluczowych scenariuszy.
Wskazówka
Przykłady wartości progowych obejmują oczekiwaną liczbę logowania użytkownika, żądania na sekundę dla danego interfejsu API i operacje na sekundę dla procesu w tle.
Należy użyć wartości progowych, aby opracować model kondycji dla aplikacji, zarówno na potrzeby testowania, jak i obsługi aplikacji w środowisku produkcyjnym.
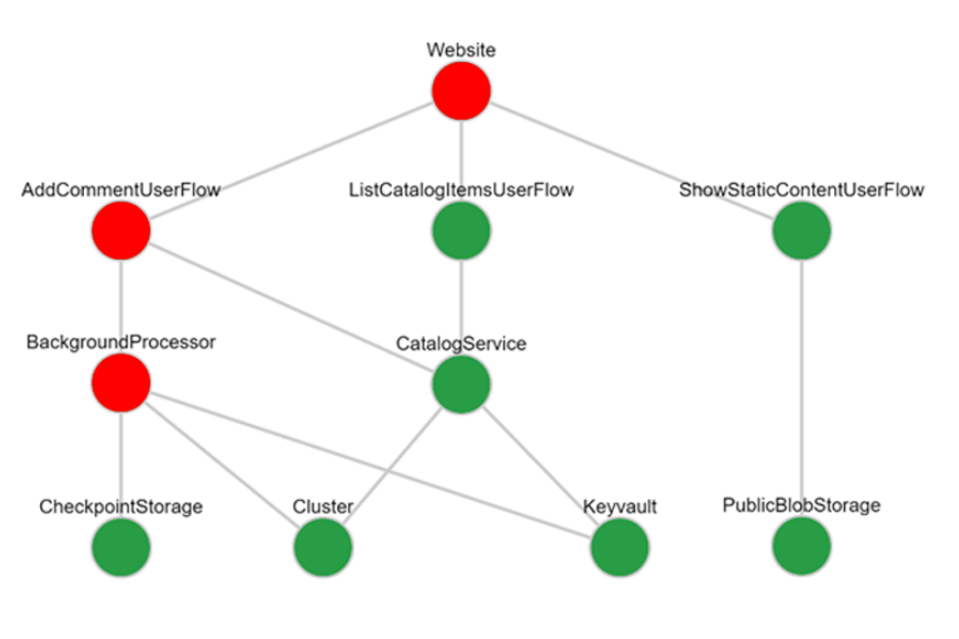
Następnie użyj wartości, aby zdefiniować test obciążeniowy , który generuje realistyczny ruch na potrzeby testowania wydajności punktu odniesienia aplikacji, weryfikowania oczekiwanych operacji skalowania itd. Trwały sztuczny ruch użytkowników jest wymagany w środowiskach przedprodukcyjnych, ponieważ bez użycia trudno jest ujawnić problemy ze środowiskiem uruchomieniowym.
Testowanie obciążenia gwarantuje, że zmiany wprowadzone w aplikacji lub infrastrukturze nie powodują problemów, a system nadal spełnia oczekiwane kryteria wydajności i testu. Nieudany przebieg testu, który nie spełnia kryteriów testu, wskazuje, że musisz dostosować punkt odniesienia lub że wystąpił nieoczekiwany błąd.
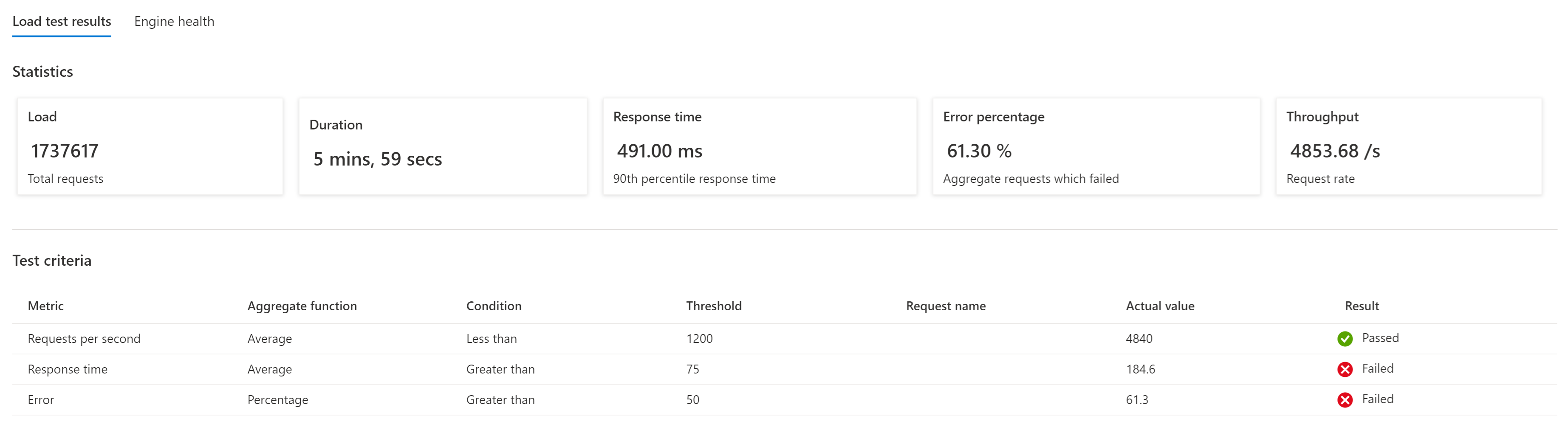
Mimo że testy automatyczne reprezentują codzienne użycie, należy regularnie uruchamiać ręczne testy obciążeniowe , aby sprawdzić, jak system reaguje na nieoczekiwane szczyty.
Drugą częścią ciągłej walidacji jest wstrzyknięcie błędów (inżynieria chaosu). Ten krok sprawdza odporność systemu, testując sposób reagowania na błędy. Ponadto wszystkie miary odporności, takie jak logika ponawiania, skalowanie automatyczne i inne, działają zgodnie z oczekiwaniami.
2 — Implementowanie walidacji za pomocą testowania obciążenia i programu Chaos Studio
Platforma Microsoft Azure udostępnia te usługi zarządzane do implementowania testowania obciążenia i inżynierii chaosu:
- Testowanie obciążenia platformy Azure generuje syntetyczne obciążenie użytkowników dla aplikacji i usług.
- Usługa Azure Chaos Studio umożliwia przeprowadzanie eksperymentów w chaosie przez systematyczne wstrzykiwanie błędów do składników aplikacji i infrastruktury.
Można wdrażać i konfigurować zarówno program Chaos Studio, jak i testowanie obciążenia za pośrednictwem witryny Azure Portal, ale w kontekście ciągłej walidacji ważniejsze jest, aby interfejsy API wdrażały, konfigurowały i uruchamiały testy w sposób programistyczny i zautomatyzowany. Dzięki tym dwóm narzędziom można obserwować, jak system reaguje na problemy i zdolność do samodzielnego leczenia w odpowiedzi na awarie infrastruktury lub aplikacji.
Poniższy film wideo przedstawia połączoną implementację Chaosu i Testowania Obciążenia oraz jej integrację w Azure DevOps.
Jeśli tworzysz obciążenie o znaczeniu krytycznym, skorzystaj z architektur referencyjnych, szczegółowych wskazówek, przykładowych implementacji i artefaktów kodu dostarczonych w ramach projektu usługi Azure Mission-Critical i platformy Azure Well-Architected Framework.
Implementacja Mission-Critical wdraża usługę testowania obciążenia za pośrednictwem narzędzia Terraform i zawiera kolekcję skryptów wrapperów PowerShell Core do interakcji z usługą przez API. Te skrypty można osadzać bezpośrednio w rurociągu wdrażania.
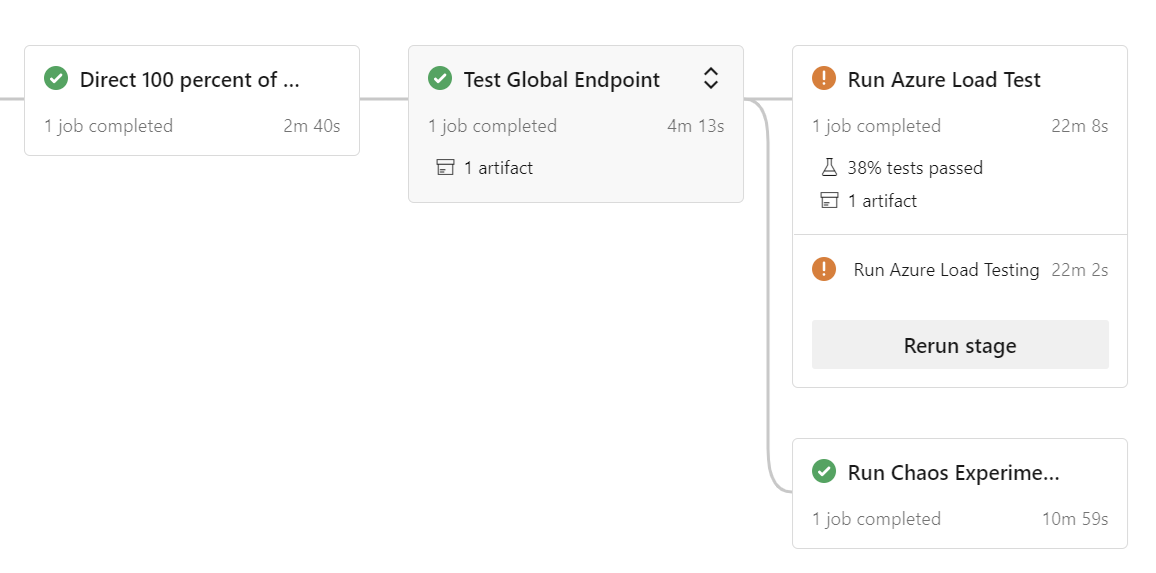
Jedną z opcji w implementacji referencyjnej jest wykonanie testu obciążeniowego bezpośrednio z poziomu kompleksowego potoku (e2e), który jest używany do uruchamiania poszczególnych (specyficznych dla gałęzi) środowisk deweloperskich:

Potok automatycznie uruchomi test obciążeniowy z eksperymentami chaosu (w zależności od wyboru) lub bez eksperymentów chaosu:
Uwaga / Notatka
Uruchamianie eksperymentów chaosu podczas testu obciążeniowego może spowodować większe opóźnienia, wyższe czasy odpowiedzi i tymczasowo zwiększone współczynniki błędów. Zauważysz wyższe liczby do momentu zakończenia operacji skalowania w poziomie lub przejścia w tryb failover w porównaniu z przebiegiem bez eksperymentów chaosu.
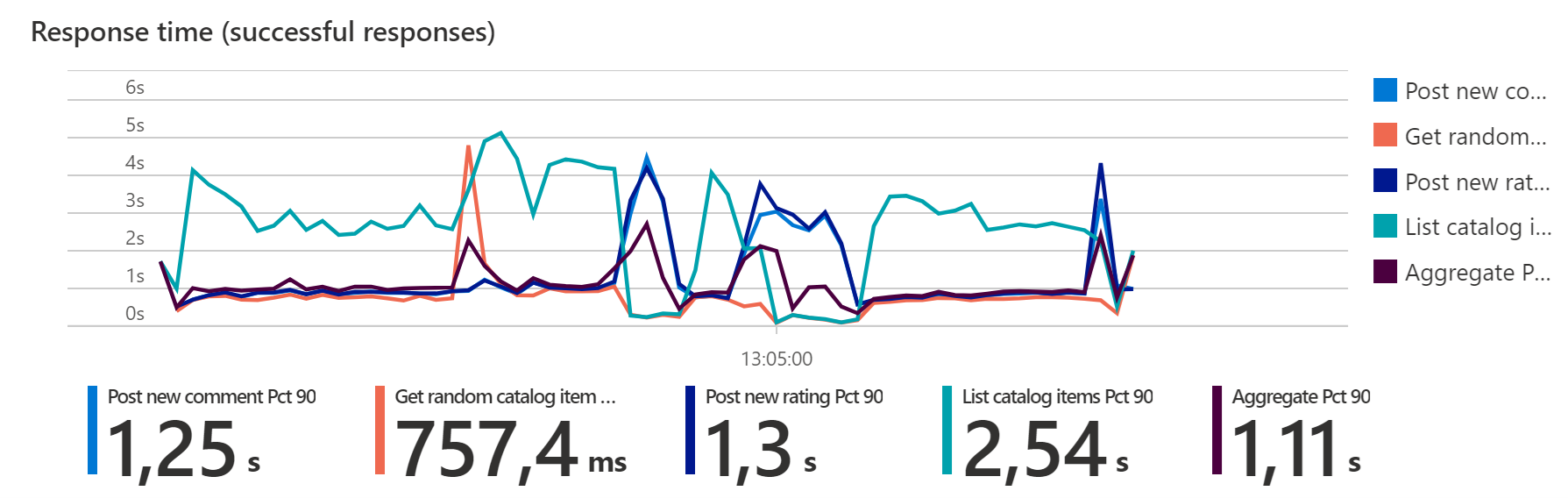
W zależności od tego, czy testowanie chaosu jest włączone oraz od wyboru eksperymentów, definicje linii bazowej mogą się różnić, ponieważ tolerancja błędów może być inna w stanie „normalnym” i „chaosie”.
3 — Dostosowywanie progów i ustanawianie punktu odniesienia
Na koniec dostosuj progi testu obciążenia dla regularnych przebiegów , aby sprawdzić, czy aplikacja (nadal) zapewnia oczekiwaną wydajność i nie generuje żadnych błędów. Istnieje oddzielny punkt odniesienia do testowania chaosu, który toleruje oczekiwane skoki liczby błędów i tymczasowe zmniejszenie wydajności. To działanie jest ciągłe i musi być powtarzane regularnie. Na przykład po wprowadzeniu nowych funkcji, zmianie jednostek SKU usługi i innych.
Usługa Azure Load Testing udostępnia wbudowaną funkcję nazywaną kryteriami testowania , która umożliwia określenie określonych kryteriów, które muszą przejść test. Ta funkcja może służyć do implementowania różnych punktów odniesienia.

Ta funkcja jest dostępna za pośrednictwem portalu Azure oraz interfejsu API testowania obciążenia, a skrypty otoki opracowane w ramach Azure Mission-critical zapewniają opcję przekazania definicji linii bazowej opartej na formacie JSON.
Zdecydowanie zalecamy integrację tych testów bezpośrednio w potoki CI/CD i uruchamianie ich we wczesnych etapach rozwoju funkcji. Aby zapoznać się z przykładem, zobacz implementację wzorcową w referencyjnej implementacji o znaczeniu krytycznym dla platformy Azure.
Podsumowując, awaria jest nieunikniona w każdym złożonym systemie rozproszonym, dlatego rozwiązanie musi być zaprojektowane (i przetestowane), aby obsługiwać błędy. Wskazówki dotyczące obciążeń o krytycznym znaczeniu dla platformyWell-Architected Framework i implementacje referencyjne mogą pomóc w projektowaniu i obsłudze wysoce niezawodnych aplikacji w celu uzyskania maksymalnej wartości z chmury firmy Microsoft.
Następny krok
Zapoznaj się z obszarem projektowania wdrażania i testowania dla obciążeń o znaczeniu krytycznym.