Projektowanie komunikacji międzyusługowej dla mikrousług
Komunikacja między mikrousługami musi być wydajna i niezawodna. W przypadku korzystania z wielu małych usług w celu ukończenia jednej działalności biznesowej może to być wyzwanie. W tym artykule przyjrzymy się kompromisom między asynchronicznymi komunikatami a synchronicznymi interfejsami API. Następnie przyjrzymy się niektórym wyzwaniom związanym z projektowaniem odpornej komunikacji międzyusługowej.
Wyzwania
Oto niektóre z głównych wyzwań wynikających z komunikacji między usługami. Siatki usług, opisane w dalszej części tego artykułu, zostały zaprojektowane pod kątem obsługi wielu z tych wyzwań.
Odporność. Może istnieć dziesiątki, a nawet setki wystąpień dowolnej mikrousługi. Wystąpienie może zakończyć się niepowodzeniem z dowolnej liczby powodów. Może wystąpić awaria na poziomie węzła, taka jak awaria sprzętowa lub ponowny rozruch maszyny wirtualnej. Wystąpienie może ulec awarii lub być przeciążone żądaniami i nie może przetworzyć żadnych nowych żądań. Każde z tych zdarzeń może spowodować niepowodzenie wywołania sieciowego. Istnieją dwa wzorce projektowe, które mogą pomóc zwiększyć odporność wywołań sieciowych typu service-to-service:
Ponowienie próby. Wywołanie sieciowe może zakończyć się niepowodzeniem z powodu błędu przejściowego, który odchodzi samodzielnie. Zamiast awarii wręcz, obiekt wywołujący powinien zazwyczaj ponowić operację określoną liczbę razy lub do czasu upływu skonfigurowanego limitu czasu. Jeśli jednak operacja nie jest idempotentna, ponawianie prób może powodować niezamierzone skutki uboczne. Oryginalne wywołanie może zakończyć się powodzeniem, ale obiekt wywołujący nigdy nie otrzymuje odpowiedzi. Jeśli obiekt wywołujący ponawia próbę, operacja może zostać wywołana dwukrotnie. Ogólnie rzecz biorąc, nie można bezpiecznie ponowić próby metod POST lub PATCH, ponieważ nie mają one gwarancji, że są one idempotentne.
Wyłącznik. Zbyt wiele żądań, które zakończyły się niepowodzeniem, może powodować wąskie gardło, ponieważ oczekujące żądania gromadzą się w kolejce. Te zablokowane żądania mogą przechowywać krytyczne zasoby systemu, takie jak pamięć, wątki, połączenia bazy danych itd., co może powodować awarie kaskadowe. Wzorzec wyłącznika może uniemożliwić usłudze wielokrotne próby wykonania operacji, która może zakończyć się niepowodzeniem.
Równoważenie obciążenia. Gdy usługa "A" wywołuje usługę "B", żądanie musi dotrzeć do uruchomionego wystąpienia usługi "B". W usłudze Service Kubernetes typ zasobu zapewnia stabilny adres IP dla grupy zasobników. Ruch sieciowy do adresu IP usługi jest przekazywany do zasobnika za pomocą reguł iptable. Domyślnie wybierany jest losowy zasobnik. Siatka usług (patrz poniżej) może zapewnić bardziej inteligentne algorytmy równoważenia obciążenia na podstawie zaobserwowanego opóźnienia lub innych metryk.
Śledzenie rozproszone. Pojedyncza transakcja może obejmować wiele usług. Może to utrudnić monitorowanie ogólnej wydajności i kondycji systemu. Nawet jeśli każda usługa generuje dzienniki i metryki, bez konieczności łączenia ich ze sobą, są one ograniczone.
Przechowywanie wersji usługi. Gdy zespół wdraża nową wersję usługi, musi unikać przerywania wszelkich innych usług lub klientów zewnętrznych, które od niej zależą. Ponadto możesz chcieć uruchamiać wiele wersji usługi obok siebie i kierować żądania do określonej wersji. Aby uzyskać więcej informacji na temat tego problemu, zobacz Przechowywanie wersji interfejsu API.
Szyfrowanie TLS i wzajemne uwierzytelnianie TLS. Ze względów bezpieczeństwa możesz chcieć zaszyfrować ruch między usługami przy użyciu protokołu TLS i użyć wzajemnego uwierzytelniania TLS do uwierzytelniania wywołujących.
Synchroniczne a asynchroniczne komunikaty
Istnieją dwa podstawowe wzorce obsługi komunikatów, których mikrousługi mogą używać do komunikowania się z innymi mikrousługami.
Komunikacja synchroniczna. W tym wzorcu usługa wywołuje interfejs API udostępniany przez inną usługę przy użyciu protokołu takiego jak HTTP lub gRPC. Ta opcja jest synchronicznym wzorcem obsługi komunikatów, ponieważ obiekt wywołujący czeka na odpowiedź od odbiorcy.
Przekazywanie komunikatów asynchronicznych. W tym wzorcu usługa wysyła komunikat bez oczekiwania na odpowiedź, a co najmniej jedna usługa przetwarza komunikat asynchronicznie.
Ważne jest, aby odróżnić asynchroniczne operacje we/wy i protokół asynchroniczny. Asynchroniczne we/wy oznacza, że wątek wywołujący nie jest blokowany podczas wykonywania operacji we/wy. Jest to ważne dla wydajności, ale jest to szczegóły implementacji pod względem architektury. Protokół asynchroniczny oznacza, że nadawca nie czeka na odpowiedź. HTTP to protokół synchroniczny, mimo że klient HTTP może używać asynchronicznego we/wy podczas wysyłania żądania.
Istnieją kompromisy dla każdego wzorca. Żądanie/odpowiedź jest dobrze zrozumiałym paradygmatem, więc projektowanie interfejsu API może wydawać się bardziej naturalne niż projektowanie systemu obsługi komunikatów. Jednak asynchroniczna obsługa komunikatów ma pewne zalety, które mogą być przydatne w architekturze mikrousług:
Zmniejszone sprzężenie. Nadawca wiadomości nie musi wiedzieć o użytkowniku.
Wielu subskrybentów. Korzystając z modelu pub/sub, wielu odbiorców może subskrybować odbieranie zdarzeń. Zobacz Styl architektury opartej na zdarzeniach.
Izolacja awarii. Jeśli konsument ulegnie awarii, nadawca nadal może wysyłać komunikaty. Komunikaty zostaną odebrane po odzyskaniu przez użytkownika. Ta możliwość jest szczególnie przydatna w architekturze mikrousług, ponieważ każda usługa ma własny cykl życia. Usługa może stać się niedostępna lub zostać zastąpiona nowszą wersją w danym momencie. Asynchroniczne komunikaty mogą obsługiwać sporadyczne przestoje. Z drugiej strony synchroniczne interfejsy API wymagają dostępności usługi podrzędnej lub operacja kończy się niepowodzeniem.
Czas odpowiedzi. Usługa nadrzędna może odpowiedzieć szybciej, jeśli nie czeka na usługi podrzędne. Jest to szczególnie przydatne w architekturze mikrousług. Jeśli istnieje łańcuch zależności usług (usługa A wywołuje usługę B, która wywołuje język C itd.), oczekiwanie na wywołania synchroniczne może dodać niedopuszczalne opóźnienia.
Wyrównywanie obciążenia. Kolejka może działać jako bufor, aby wyrównać obciążenie, dzięki czemu odbiorcy mogą przetwarzać komunikaty we własnym tempie.
Przepływy pracy. Kolejki mogą służyć do zarządzania przepływem pracy, sprawdzając komunikat po każdym kroku przepływu pracy.
Istnieją jednak również pewne wyzwania związane z efektywnym używaniem asynchronicznych komunikatów.
Sprzęganie z infrastrukturą obsługi komunikatów. Użycie konkretnej infrastruktury obsługi komunikatów może spowodować ścisłe sprzężenie z daną infrastrukturą. Później będzie trudno przełączyć się na inną infrastrukturę obsługi komunikatów.
Opóźnienie. Całkowite opóźnienie operacji może stać się wysokie, jeśli kolejki komunikatów zapełniają się.
Koszt Przy wysokiej przepływności koszt pieniężny infrastruktury obsługi komunikatów może być znaczący.
Złożoność. Obsługa komunikatów asynchronicznych nie jest prostym zadaniem. Na przykład należy obsługiwać zduplikowane komunikaty, deduplikując lub tworząc idempotentne operacje. Trudno jest również zaimplementować semantyka żądań odpowiedzi przy użyciu asynchronicznej obsługi komunikatów. Aby wysłać odpowiedź, potrzebujesz innej kolejki oraz sposobu korelowania komunikatów żądania i odpowiedzi.
Przepływność. Jeśli komunikaty wymagają semantyki kolejki, kolejka może stać się wąskim gardłem w systemie. Każdy komunikat wymaga co najmniej jednej operacji kolejki i jednej operacji dequeue. Ponadto semantyka kolejek zwykle wymaga pewnego rodzaju blokowania wewnątrz infrastruktury obsługi komunikatów. Jeśli kolejka jest usługą zarządzaną, może wystąpić dodatkowe opóźnienie, ponieważ kolejka jest zewnętrzna dla sieci wirtualnej klastra. Możesz rozwiązać te problemy, tworząc partie komunikatów, ale to komplikuje kod. Jeśli komunikaty nie wymagają semantyki kolejki, może być możliwe użycie strumienia zdarzeń zamiast kolejki. Aby uzyskać więcej informacji, zobacz Styl architektury opartej na zdarzeniach.
Dostarczanie przy użyciu drona: wybieranie wzorców obsługi komunikatów
To rozwiązanie korzysta z przykładu Drone Delivery. Jest idealnym rozwiązaniem dla przemysłu lotniczego i lotniczego.
Mając na uwadze te zagadnienia, zespół programistyczny dokonał następujących wyborów projektowych dla aplikacji Drone Delivery:
Usługa pozyskiwania uwidacznia publiczny interfejs API REST używany przez aplikacje klienckie do planowania, aktualizowania lub anulowania dostaw.
Usługa pozyskiwania używa usługi Event Hubs do wysyłania komunikatów asynchronicznych do usługi Scheduler. Komunikaty asynchroniczne są niezbędne do zaimplementowania bilansowania obciążenia wymaganego do pozyskiwania.
Wszystkie usługi Account, Delivery, Package, Drone i Third-Party Transport udostępniają wewnętrzne interfejsy API REST. Usługa Scheduler wywołuje te interfejsy API w celu wykonania żądania użytkownika. Jednym z powodów korzystania z synchronicznych interfejsów API jest to, że harmonogram musi uzyskać odpowiedź z każdej z usług podrzędnych. Awaria w dowolnej z usług podrzędnych oznacza, że cała operacja nie powiodła się. Jednak potencjalnym problemem jest ilość opóźnień wprowadzonych przez wywołanie usług zaplecza.
Jeśli jakakolwiek usługa podrzędna ma nieprzejrzałą awarię, cała transakcja powinna być oznaczona jako nieudana. Aby obsłużyć ten przypadek, usługa Scheduler wysyła asynchroniczny komunikat do nadzorcy, aby nadzorca mógł zaplanować transakcje wyrównujące.
Usługa dostarczania uwidacznia publiczny interfejs API, którego klienci mogą używać do uzyskiwania stanu dostawy. W artykule Brama interfejsu API omawiamy sposób, w jaki brama interfejsu API może ukryć podstawowe usługi od klienta, więc klient nie musi wiedzieć, które usługi uwidaczniają, które interfejsy API.
Gdy dron jest w locie, usługa Drone wysyła zdarzenia, które zawierają bieżącą lokalizację i stan drona. Usługa dostarczania nasłuchuje tych zdarzeń w celu śledzenia stanu dostawy.
Gdy stan dostawy zmieni się, usługa dostarczania wysyła zdarzenie stanu dostawy, takie jak
DeliveryCreatedlubDeliveryCompleted. Każda usługa może subskrybować te zdarzenia. W bieżącym projekcie usługa Historia dostarczania jest jedynym subskrybentem, ale później mogą istnieć inni subskrybenci. Na przykład zdarzenia mogą przejść do usługi analizy w czasie rzeczywistym. Ponieważ harmonogram nie musi czekać na odpowiedź, dodanie kolejnych subskrybentów nie ma wpływu na główną ścieżkę przepływu pracy.
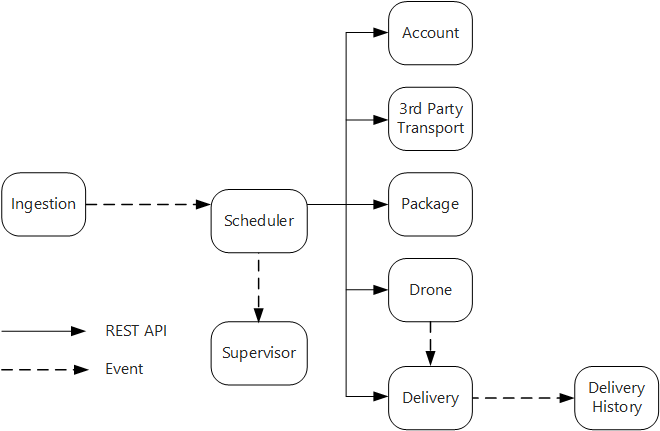
Zwróć uwagę, że zdarzenia stanu dostarczania pochodzą ze zdarzeń lokalizacji dronów. Na przykład gdy dron osiągnie lokalizację dostawy i odejścia pakiet, usługa dostarczania przełoży to na zdarzenie DeliveryCompleted. Jest to przykład myślenia pod względem modeli domeny. Jak opisano wcześniej, zarządzanie dronami należy do oddzielnego ograniczonego kontekstu. Zdarzenia dronów przekazują fizyczną lokalizację drona. Z kolei zdarzenia dostarczania reprezentują zmiany stanu dostawy, która jest inną jednostką biznesową.
Korzystanie z siatki usług
Siatka usług to warstwa oprogramowania, która obsługuje komunikację między usługami. Siatki usług zostały zaprojektowane tak, aby rozwiązać wiele problemów wymienionych w poprzedniej sekcji i przenieść odpowiedzialność za te kwestie z dala od samych mikrousług i do warstwy udostępnionej. Siatka usług działa jako serwer proxy, który przechwytuje komunikację sieciową między mikrousługami w klastrze. Obecnie koncepcja siatki usług dotyczy głównie orkiestratorów kontenerów, a nie architektur bezserwerowych.
Uwaga
Siatka usług to przykład wzorca ambasadora — usługa pomocnika, która wysyła żądania sieciowe w imieniu aplikacji.
W tej chwili główne opcje siatki usługi na platformie Kubernetes to Linkerd i Istio. Obie te technologie szybko ewoluują. Jednak niektóre funkcje, które zarówno Linkerd, jak i Istio mają wspólne cechy:
Równoważenie obciążenia na poziomie sesji na podstawie zaobserwowanych opóźnień lub liczby zaległych żądań. Może to zwiększyć wydajność w przypadku równoważenia obciążenia warstwy 4 udostępnianego przez platformę Kubernetes.
Routing w warstwie 7 na podstawie ścieżki adresu URL, nagłówka hosta, wersji interfejsu API lub innych reguł na poziomie aplikacji.
Ponów próbę żądań, które zakończyły się niepowodzeniem. Siatka usługi rozumie kody błędów HTTP i może automatycznie ponowić próby niepomyślnie żądań. Możesz skonfigurować maksymalną liczbę ponownych prób wraz z upływem limitu czasu w celu ograniczenia maksymalnego opóźnienia.
Wyłącznik. Jeśli wystąpienie stale kończy się niepowodzeniem, siatka usługi tymczasowo oznaczy je jako niedostępne. Po upływie okresu wycofywania spróbuje ponownie wystąpienie. Wyłącznik można skonfigurować na podstawie różnych kryteriów, takich jak liczba kolejnych awarii,
Siatka usług przechwytuje metryki dotyczące wywołań międzyusługowych, takich jak wolumin żądań, opóźnienie, współczynniki błędów i współczynniki powodzenia oraz rozmiary odpowiedzi. Siatka usług umożliwia również śledzenie rozproszone przez dodanie informacji korelacji dla każdego przeskoku w żądaniu.
Wzajemne uwierzytelnianie TLS dla wywołań typu service-to-service.
Czy potrzebujesz siatki usług? To zależy. Bez siatki usług należy wziąć pod uwagę każde z wyzwań wymienionych na początku tego artykułu. Możesz rozwiązać problemy, takie jak ponawianie prób, wyłącznik i śledzenie rozproszone bez siatki usługi, ale siatka usług przenosi te obawy z poszczególnych usług i do dedykowanej warstwy. Z drugiej strony siatka usług zwiększa złożoność instalacji i konfiguracji klastra. Mogą wystąpić konsekwencje dla wydajności, ponieważ żądania są teraz kierowane przez serwer proxy usługi Service Mesh i dlatego, że dodatkowe usługi są teraz uruchomione w każdym węźle w klastrze. Przed wdrożeniem siatki usług w środowisku produkcyjnym należy wykonać dokładne testowanie wydajności i obciążenia.
Transakcje rozproszone
Typowym wyzwaniem w mikrousługach jest prawidłowa obsługa transakcji obejmujących wiele usług. Często w tym scenariuszu powodzenie transakcji jest wszystkie lub nic — jeśli jedna z uczestniczących usług ulegnie awarii, cała transakcja musi zakończyć się niepowodzeniem.
Należy wziąć pod uwagę dwa przypadki:
Usługa może napotkać przejściowe awarie, takie jak przekroczenie limitu czasu sieci. Te błędy można często rozwiązać po prostu, ponawiając próbę wywołania. Jeśli operacja nadal kończy się niepowodzeniem po określonej liczbie prób, zostanie uznana za nieprzejrzałą awarię.
Nieprzejrzała awaria to każda awaria, która jest mało prawdopodobne, aby odejść samodzielnie. Błędy nieprzejrzane obejmują normalne warunki błędu, takie jak nieprawidłowe dane wejściowe. Obejmują one również nieobsługiwane wyjątki w kodzie aplikacji lub awarii procesu. Jeśli wystąpi ten typ błędu, cała transakcja biznesowa musi być oznaczona jako niepowodzenie. Może być konieczne cofnięcie innych kroków w tej samej transakcji, która już się powiodła.
Po nieprzejętnej awarii bieżąca transakcja może znajdować się w stanie częściowo zakończonym niepowodzeniem, w którym co najmniej jeden krok został już ukończony pomyślnie. Jeśli na przykład usługa Drone już zaplanowała drona, należy anulować drona. W takim przypadku aplikacja musi cofnąć kroki, które zakończyły się pomyślnie, przy użyciu transakcji wyrównywałej. W niektórych przypadkach ta akcja musi być wykonywana przez system zewnętrzny, a nawet przez proces ręczny. W projekcie należy pamiętać, że środki wyrównywujące również podlegają awarii.
Jeśli logika transakcji wyrównywczych jest złożona, rozważ utworzenie oddzielnej usługi odpowiedzialnej za ten proces. W aplikacji Drone Delivery usługa Scheduler umieszcza nieudane operacje w dedykowanej kolejce. Oddzielna mikrousługa, nazywana nadzorcą, odczytuje z tej kolejki i wywołuje interfejs API anulowania w usługach, które muszą zrekompensować. Jest to odmiana wzorca nadzorcy agenta harmonogramu. Usługa Nadzorca może również wykonywać inne działania, takie jak powiadamianie użytkownika za pomocą tekstu lub wiadomości e-mail lub wysyłanie alertu do pulpitu nawigacyjnego operacji.
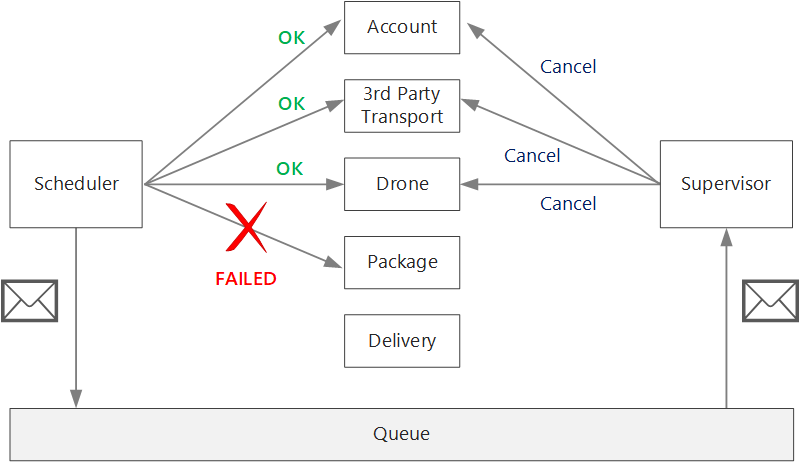
Sama usługa Scheduler może zakończyć się niepowodzeniem (na przykład z powodu awarii węzła). W takim przypadku nowe wystąpienie może uruchamiać się i przejmować. Jednak wszelkie transakcje, które były już w toku, muszą zostać wznowione.
Jednym z podejść jest zapisanie punktu kontrolnego w trwałym magazynie po zakończeniu każdego kroku przepływu pracy. Jeśli wystąpienie usługi Scheduler ulegnie awarii w środku transakcji, nowe wystąpienie może użyć punktu kontrolnego, aby wznowić, w którym poprzednie wystąpienie zostało przerwane. Jednak pisanie punktów kontrolnych może spowodować obciążenie związane z wydajnością.
Inną opcją jest zaprojektowanie wszystkich operacji jako idempotentnych. Operacja jest idempotentna, jeśli może być wywoływana wiele razy bez wytwarzania dodatkowych skutków ubocznych po pierwszym wywołaniu. Zasadniczo usługa podrzędna powinna ignorować zduplikowane wywołania, co oznacza, że usługa musi być w stanie wykryć zduplikowane wywołania. Implementacja metod idempotentnych nie zawsze jest prosta. Aby uzyskać więcej informacji, zobacz Operacje idempotentne.
Następne kroki
W przypadku mikrousług, które komunikują się bezpośrednio ze sobą, ważne jest, aby tworzyć dobrze zaprojektowane interfejsy API.