Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Azure
Zapewnij możliwość obsługi błędów przejściowych w aplikacji podczas próby nawiązania połączenia z usługą lub zasobem sieciowym poprzez niewidoczne ponawianie operacji, która zakończyła się niepowodzeniem. Może to poprawić stabilność aplikacji.
Kontekst i problem
Aplikacja, która komunikuje się z elementami działającymi w chmurze, musi być wrażliwa na błędy przejściowe mogące wystąpić w tym środowisku. Błędy obejmują chwilową utratę łączności sieciowej ze składnikami i usługami, tymczasową niedostępność usługi lub przekroczenia limitu czasu, gdy usługa jest zajęta.
Te błędy zwykle są automatycznie usuwane, a jeśli akcja, która wyzwoliła taki błąd, zostanie powtórzona z odpowiednim opóźnieniem, prawdopodobnie zakończy się pomyślnie. Na przykład usługa bazy danych, która przetwarza dużą liczbę współbieżnych żądań, może zaimplementować strategię ograniczania przepustowości, która tymczasowo odrzuca wszelkie dalsze żądania, dopóki obciążenie nie zostanie złagodne. Próba uzyskania dostępu do bazy danych przez aplikację może zakończyć się niepowodzeniem, ale ponowna próba po określonym opóźnieniu może się powieść.
Rozwiązanie
W chmurze powinny być oczekiwane błędy przejściowe, a aplikacja powinna być zaprojektowana tak, aby obsługiwała je elegancko i w sposób przejrzysty. W ten sposób minimalizuje skutki, jakie mogą mieć błędy w zadaniach biznesowych wykonywanych przez aplikację. Najczęstszym wzorcem projektowania do rozwiązania jest wprowadzenie mechanizmu ponawiania prób.
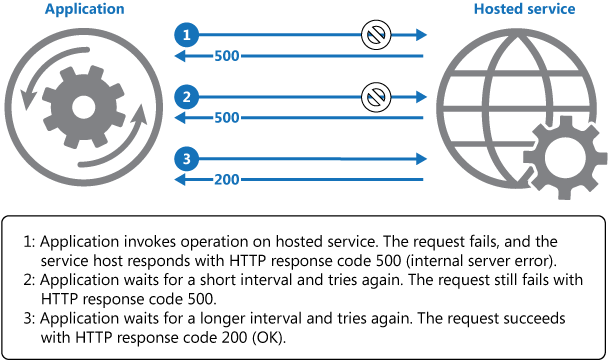
Na powyższym diagramie przedstawiono wywołanie operacji w hostowanej usłudze przy użyciu mechanizmu ponawiania prób. Jeśli żądanie nie zakończy się pomyślnie po wykonaniu wstępnie zdefiniowanej liczby prób, aplikacja powinna potraktować błąd jako wyjątek i odpowiednio go obsłużyć.
Uwaga
Ze względu na powszechny charakter błędów przejściowych wbudowane mechanizmy ponawiania prób są teraz dostępne w wielu bibliotekach klienckich i usługach w chmurze, z pewnym stopniem możliwości konfiguracji dla maksymalnej liczby ponownych prób, opóźnienia między ponownymi próbami i innymi parametrami. Microsoft Entity Framework udostępnia funkcje ponawiania nieudanych operacji bazy danych.
Strategie dotyczące ponawiania prób
Jeśli aplikacja wykryje błąd podczas próby wysłania żądania do usługi zdalnej, może go obsłużyć za pomocą następujących strategii:
Anulowanie. Jeśli błąd wskazuje na to, że awaria nie jest przejściowa, lub jest mało prawdopodobne, że nie wystąpi on podczas ponownej próby, aplikacja powinna anulować operację i zgłosić wyjątek.
Spróbuj natychmiast. Jeśli zgłoszony błąd jest nietypowy lub rzadki, na przykład pakiet sieciowy ulega uszkodzeniu podczas przesyłania, najlepszym sposobem działania może być natychmiastowe ponowienie próby wykonania żądania.
Ponowienie próby po opóźnieniu. Jeśli błąd jest spowodowany jedną z bardziej typowych awarii łączności lub zajętości, sieć lub usługa może potrzebować krótkiego okresu, podczas gdy problemy z łącznością są poprawiane lub lista prac jest czyszczone, więc programowe opóźnienie ponawiania jest dobrą strategią. W wielu przypadkach okres między ponownymi próbami należy wybrać tak, aby rozłożyć żądania z wielu wystąpień aplikacji tak równomiernie, jak to możliwe, aby zmniejszyć prawdopodobieństwo, że zajęta usługa będzie nadal przeciążona.
Jeśli żądanie nadal kończy się niepowodzeniem, aplikacja może poczekać i dopiero wtedy podjąć kolejną próbę. Jeśli to konieczne, ten proces można powtarzać z rosnącymi opóźnieniami między ponownymi próbami, dopóki nie zostanie podjęta określona maksymalna liczba żądań. Opóźnienie można zwiększyć przyrostowo lub wykładniczo, w zależności od typu błędu i prawdopodobieństwa, że zostanie on w tym czasie usunięty.
Aplikacja powinna opakować wszystkie próby uzyskania dostępu do zdalnej usługi w kodzie, który implementuje zasady ponawiania dopasowane do jednej z wymienionych powyżej strategii. Żądania wysyłane do różnych usług mogą podlegać różnym zasadom.
Aplikacja powinna rejestrować szczegóły błędów i operacji kończących się niepowodzeniem. Te informacje są przydatne dla operatorów. Oznacza to, że w celu uniknięcia operatorów powodzi z alertami dotyczącymi operacji, w których następnie ponowione próby zakończyły się powodzeniem, najlepiej jest rejestrować wczesne błędy jako wpisy informacyjne i tylko niepowodzenie ostatniej próby ponawiania jako rzeczywisty błąd. Oto przykład sposobu, w jaki wygląda ten model rejestrowania.
Jeśli usługa jest regularnie niedostępna lub zajęta, często spowodowane jest to wyczerpanymi zasobami. Częstotliwość takich błędów można zmniejszyć, skalując usługę w poziomie. Jeśli na przykład usługa bazy danych jest stale przeciążona, korzystne może być podzielenie bazy danych na partycje i rozłożenie obciążenia na wiele serwerów.
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie implementacji tego wzorca należy rozważyć następujące kwestie.
Wpływ na wydajność
Zasady ponawiania powinny być dostosowane do wymagań biznesowych aplikacji i charakteru niepowodzenia. W przypadku niektórych niekrytycznych operacji lepiej jest szybko zakończyć się niepowodzeniem, a nie kilka razy ponowić próbę i wpłynąć na przepływność aplikacji. Na przykład w interaktywnej aplikacji internetowej, która uzyskuje dostęp do usługi zdalnej, lepiej jest zakończyć się niepowodzeniem po mniejszej liczbie ponownych prób tylko z krótkim opóźnieniem między próbami ponawiania prób i wyświetlenie odpowiedniego komunikatu dla użytkownika (na przykład "spróbuj ponownie później"). W przypadku aplikacji wsadowych bardziej odpowiednie może być zwiększenie liczby ponownych prób z wykładniczo rosnącym opóźnieniem między nimi.
Agresywne zasady ponawiania z minimalnym opóźnieniem między próbami i dużą liczbą ponownych prób mogą jeszcze bardziej obniżyć wydajność zajętej usługi, która jest bliska wykorzystania dostępnych zasobów lub je wykorzystuje. Te zasady ponawiania mogą mieć również wpływ na czas odpowiedzi aplikacji, jeśli stale podejmowana jest w niej próba wykonania operacji kończącej się niepowodzeniem.
Jeśli żądanie nadal kończy się niepowodzeniem po znacznej liczbie ponownych prób, lepiej jest, aby aplikacja zapobiec dalszym żądaniom przechodzącym do tego samego zasobu i natychmiast zgłosić błąd. Po wygaśnięciu danego okresu aplikacja może wstępnie zezwolić na niewielką liczbę żądań w celu sprawdzenia, czy zakończą się one pomyślnie. Aby uzyskać więcej informacji na temat tej strategii, zobacz wzorzec obwodu zabezpieczającego.
Idempotentność
Rozważ, czy operacja jest idempotentna. Jeśli tak, ponawianie próby jest z założenia bezpieczne. Jeśli nie, ponowne próby mogą spowodować wykonanie operacji więcej niż jeden raz i wystąpienie niezamierzonych skutków ubocznych. Na przykład usługa może odebrać żądanie, pomyślnie je przetworzyć, ale wysłanie przez nią odpowiedzi może zakończyć się niepowodzeniem. W takie sytuacji logika ponawiania może ponownie wysłać żądanie, zakładając, że pierwsze żądanie nie zostało odebrane.
Typ wyjątku
Żądanie do usługi może zakończyć się niepowodzeniem z różnych powodów, powodując różne wyjątki w zależności od charakteru awarii. Niektóre wyjątki wskazują błędy, które można szybko usunąć, a niektóre wskazują dłużej trwające błędy. W przypadku zasad ponawiania przydatne jest dostosowanie czasu między ponownymi próbami na podstawie typu wyjątku.
Spójność transakcji
Należy wziąć pod uwagę, w jaki sposób operacja będąca częścią transakcji wpłynie na ogólną spójność transakcji. Dostosuj zasady ponawiania na potrzeby operacji transakcyjnych, aby zmaksymalizować prawdopodobieństwo powodzenia i ograniczyć prawdopodobieństwo konieczności wycofania wszystkich kroków transakcji.
Wskazówki ogólne
Upewnij się, że cały kod ponawiania prób został w pełni przetestowany pod kątem różnych warunków awarii. Sprawdź, czy nie ma poważnego wpływu na wydajność lub niezawodność aplikacji, czy nie są powodowane nadmierne obciążenia usług i zasobów, ani czy nie generowane są stany wyścigu lub wąskie gardła.
Logikę ponawiania należy implementować tylko w tych miejscach w kodzie, w których zrozumiały jest pełny kontekst operacji kończącej się niepowodzeniem. Jeśli na przykład zadanie zawierające zasady ponawiania wywołuje inne zadanie, które również zawiera zasady ponawiania, ta dodatkowa warstwa ponownych prób może spowodować duże opóźnienia przetwarzania. Lepszym rozwiązaniem może być skonfigurowanie zadania niższego poziomu w celu szybkiego kończenia działania i raportowania przyczyny błędu z powrotem do zadania, które je wywołało. To zadanie wyższego poziomu może następnie obsłużyć błąd na podstawie własnych zasad.
Zarejestruj wszystkie błędy łączności, które powodują ponowienie próby, aby można było zidentyfikować podstawowe problemy z aplikacją, usługami lub zasobami.
Sprawdź błędy, które z największym prawdopodobieństwem mogą wystąpić w przypadku usługi lub zasobu, aby dowiedzieć się, czy mogą być one długotrwałe lub powodujące zakończenie działania. Jeśli tak, to lepiej obsłużyć takie błędy jako wyjątek. Aplikacja może zarejestrować lub zgłosić wyjątek, a następnie podjąć próbę kontynuowania działania, wywołując alternatywną usługę (jeśli taka jest dostępna) lub oferując funkcjonalność o obniżonym poziomie. Aby uzyskać więcej informacji na temat sposobu wykrywania i obsługi długotrwałych błędów, zobacz Wzorzec wyłącznika.
Kiedy używać tego wzorca
Użyj tego wzorca, gdy w aplikacji mogą występować błędy przejściowe podczas współdziałania z usługą zdalną lub uzyskiwania dostępu do zasobu zdalnego. Takie błędy są zwykle krótkotrwałe, a powtórzenie żądania, które wcześniej zakończyło się niepowodzeniem, może zakończyć się pomyślnie w kolejnej próbie.
Ten wzorzec może nie być przydatny w następujących sytuacjach:
- Gdy błąd jest prawdopodobnie długotrwały, ponieważ może to mieć wpływ na czas odpowiedzi aplikacji. Aplikacja może marnować czas i zasoby, podejmując próbę powtórzenia żądania, które prawdopodobnie zakończy się niepowodzeniem.
- Na potrzeby obsługi awarii, które nie zostały spowodowane błędami przejściowymi, czyli na przykład wyjątków wewnętrznych spowodowanych przez błędy logiki biznesowej aplikacji.
- Jako alternatywa dla rozwiązywania problemów ze skalowalnością w systemie. Jeśli w aplikacji występują częste błędy związane z zajętością, zwykle świadczy to o tym, że konieczne jest skalowanie w górę usługi lub zasobu, do którego uzyskiwany jest dostęp.
Projekt obciążenia
Architekt powinien ocenić, w jaki sposób wzorzec ponawiania prób może być używany w projekcie obciążenia, aby sprostać celom i zasadom opisanym w filarach platformy Azure Well-Architected Framework. Na przykład:
| Filar | Jak ten wzorzec obsługuje cele filaru |
|---|---|
| Decyzje projektowe dotyczące niezawodności pomagają obciążeniu stać się odporne na awarię i zapewnić, że zostanie przywrócony do w pełni funkcjonalnego stanu po wystąpieniu awarii. | Łagodzenie błędów przejściowych w systemie rozproszonym jest podstawową techniką poprawy odporności obciążenia. - RE:07 Instynkt samozachowawczy - RE:07 Błędy przejściowe |
Podobnie jak w przypadku każdej decyzji projektowej, należy rozważyć wszelkie kompromisy w stosunku do celów innych filarów, które mogą zostać wprowadzone przy użyciu tego wzorca.
Przykład
Zapoznaj się z przewodnikiem Implementowanie zasad ponawiania prób za pomocą platformy .NET , aby uzyskać szczegółowy przykład użycia zestawu Azure SDK z wbudowaną obsługą mechanizmu ponawiania prób.
Następne kroki
Przed napisaniem niestandardowej logiki ponawiania rozważ użycie ogólnej struktury, takiej jak Polly for .NET lub Resilience4j for Java.
Podczas przetwarzania poleceń, które zmieniają dane biznesowe, należy pamiętać, że ponowne próby mogą spowodować dwukrotne wykonanie akcji, co może być problematyczne, jeśli ta akcja jest podobna do ładowania karty kredytowej klienta. Użycie wzorca idempotencji opisanego w tym wpisie w blogu może pomóc w radzeniu sobie z tymi sytuacjami.
Powiązane zasoby
Wzorzec niezawodnej aplikacji internetowej pokazuje, jak zastosować wzorzec ponawiania prób do aplikacji internetowych zbieżnych w chmurze.
W przypadku większości usług platformy Azure zestawy SDK klienta obejmują wbudowaną logikę ponawiania prób.
Wzorzec wyłącznika. Jeśli prawdopodobne jest, że błąd będzie trwał dłużej, bardziej odpowiednie może być zaimplementowanie wzorca wyłącznika. Połączenie wzorców ponawiania prób i wyłącznika zapewnia kompleksowe podejście do obsługi błędów.