Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Azure Storage
Tworzenie indeksów dla pól magazynu danych, do których często odwołują się zapytania. Ten wzorzec może poprawić wydajność zapytań, umożliwiając aplikacjom szybsze odnajdywanie danych do pobrania z magazynu danych.
Kontekst i problem
W wielu magazynach dane są porządkowane na potrzeby kolekcji jednostek za pomocą klucza podstawowego. Aplikacja może użyć tego klucza w celu zlokalizowania i pobrania danych. Na ilustracji przedstawiono przykład magazynu danych zawierającego informacje o klientach. Kluczem podstawowym jest tu identyfikator klienta. Na ilustracji informacje o klientach zostały uporządkowane według klucza podstawowego (Identyfikator klienta).
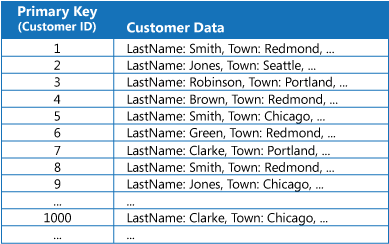
Klucz podstawowy jest przydatny w przypadku zapytań, które pobierają dane na podstawie wartości tego klucza, jednak aplikacja może nie być w stanie użyć klucza podstawowego, jeśli musi pobrać dane na podstawie jakiegoś innego pola. W przykładzie z klientami aplikacja nie może pobrać danych o klientach przy użyciu klucza podstawowego Identyfikator klienta, jeśli zapytanie odwołuje się wyłącznie do wartości innego atrybutu, takiego jak miejscowość zamieszkania klienta. Aby wykonać takie zapytanie, aplikacja być może będzie musiała pobrać i sprawdzić każdy rekord klienta, co może być procesem powolnym.
Wiele systemów zarządzania relacyjnymi bazami danych obsługuje indeksy pomocnicze. Indeks pomocniczy to osobna struktura danych uporządkowana według jednego lub kilku niepodstawowych (pomocniczych) pól kluczy. Wskazuje on, gdzie są przechowywane dane dla każdej indeksowanej wartości. Elementy w indeksie pomocniczym zwykle są sortowane według wartości kluczy pomocniczych w celu umożliwienia szybkiego wyszukiwania danych. Te indeksy są zazwyczaj obsługiwane automatycznie przez system zarządzania bazami danych.
Indeksów pomocniczych można utworzyć tyle, ile potrzeba do obsługi różnych zapytań wykonywanych przez aplikację. Na przykład w przypadku tabeli Klienci w relacyjnej bazie danych, gdzie identyfikator klienta jest kluczem podstawowym, warto dodać indeks pomocniczy dla pola miejscowości, jeśli aplikacja często wyszukuje klientów według miejscowości zamieszkania.
Jednak mimo że indeksy pomocnicze są powszechne w systemach relacyjnych, niektóre magazyny danych NoSQL używane przez aplikacje w chmurze nie zapewniają równoważnej funkcji.
Rozwiązanie
Jeśli magazyn danych nie obsługuje indeksów pomocniczych, można emulować je ręcznie, tworząc własne tabele indeksów. Tabela indeksów porządkuje dane według określonego klucza. Do tworzenia struktury tabeli indeksów najczęściej są używane trzy strategie, w zależności od wymaganej liczby indeksów pomocniczych i rodzajów zapytań wykonywanych przez aplikację.
Pierwsza strategia polega na zduplikowaniu danych z każdej tabeli indeksów i uporządkowaniu ich według różnych kluczy (pełna denormalizacja). Na kolejnej ilustracji przedstawiono tabele indeksów, w których te same informacje o klientach zostały uporządkowane według miejscowości i nazwiska.
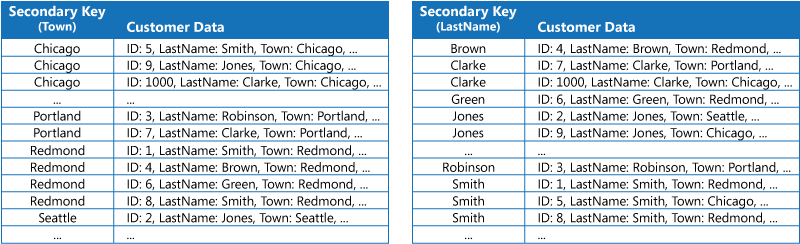
Ta strategia jest odpowiednia, jeśli dane są względnie statyczne w porównaniu do liczby zapytań wykonywanych przy użyciu każdego klucza. Jeśli dane są bardziej dynamiczne, koszty przetwarzania związane z obsługą każdej tabeli indeksów stają się zbyt duże, aby ta metoda była użyteczna. Ponadto, jeśli wolumin danych jest wysoki, ilość miejsca wymaganego do przechowywania zduplikowanych danych jest znacząca.
Druga strategia polega na utworzeniu znormalizowanych tabel indeksów uporządkowanych według różnych kluczy i odwołujących się do danych oryginalnych przy użyciu klucza podstawowego (zamiast duplikowania ich), jak pokazano na poniższej ilustracji. Dane oryginalne są nazywane tabelą faktów.
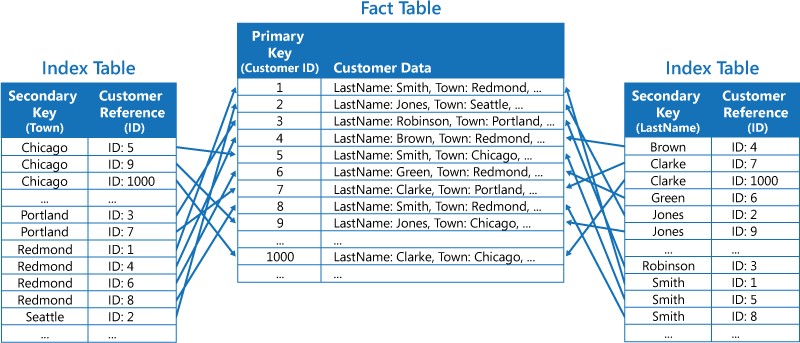
Ta technika pozwala zaoszczędzić miejsce i obniżyć koszty związane z obsługą zduplikowanych danych. Wada tego rozwiązania polega na tym, że aplikacja musi wykonać dwie operacje wyszukiwania, aby znaleźć dane przy użyciu klucza pomocniczego. Musi ona znaleźć klucz podstawowy dla danych w tabeli indeksów, a następnie przy użyciu tego klucza podstawowego wyszukać dane w tabeli faktów.
Trzecia strategia polega na utworzeniu częściowo znormalizowanych tabel indeksów uporządkowanych według różnych kluczy, które duplikują często pobierane pola. W celu uzyskania dostępu do rzadziej używanych pól należy odwołać się do tabeli faktów. Na kolejnej ilustracji pokazano duplikowanie często używanych danych w każdej tabeli indeksów.
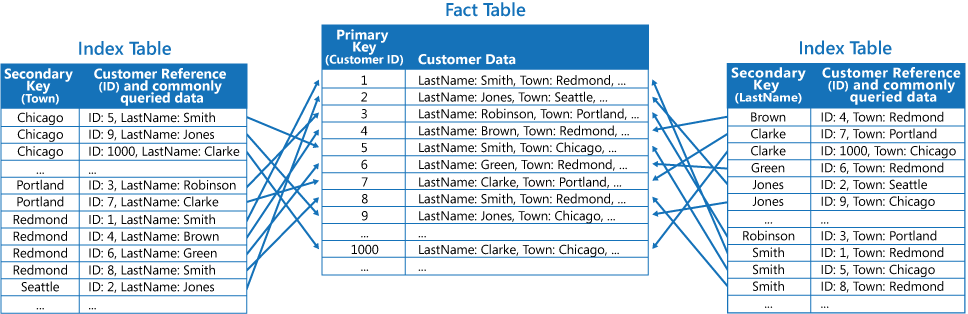
Ta strategia pozwala uzyskać równowagę między dwoma pierwszymi metodami. Dane dla często wykonywanych zapytań mogą zostać szybko pobrane za pomocą jednego wyszukiwania, a potrzebne miejsce i koszty utrzymania nie są tak duże, jak w przypadku duplikowania całego zestawu danych.
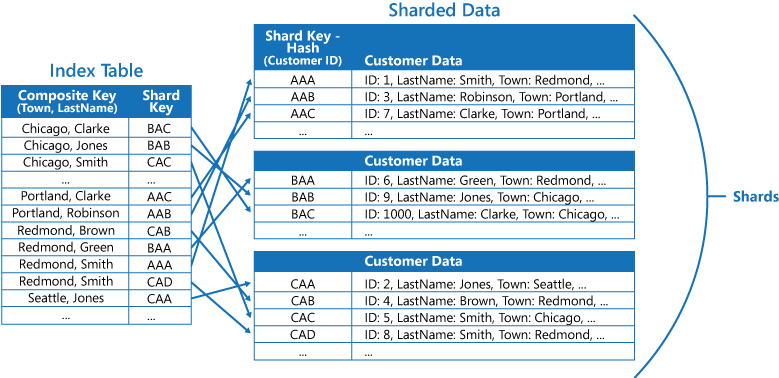
Jeśli aplikacja często wykonuje zapytania o dane, określając kombinację wartości (na przykład "Znajdź wszystkich klientów mieszkających w Redmond i mających nazwisko Smith"), możesz zaimplementować klucze do elementów w tabeli indeksów jako połączenie atrybutu Town i atrybutu LastName. Następna ilustracja przedstawia tabelę indeksów utworzoną na podstawie kluczy złożonych. Klucze są sortowane według miejscowości, a następnie według nazwiska w przypadku rekordów, które mają taką samą wartość miejscowości.

Tabele indeksów mogą przyspieszyć operacje zapytań względem danych pofragmentowanych i są szczególnie przydatne, gdy dla klucza fragmentu jest wyznaczana wartość skrótu. Na kolejnej ilustracji przedstawiono przykład, w którym klucz fragmentu jest skrótem identyfikatora klienta. W tabeli indeksów dane można uporządkować według wartości bez skrótu (miejscowość i nazwisko), a następnie podać klucz fragmentu z wartością skrótu jako dane wyszukiwania. Dzięki temu aplikacja nie musi wielokrotnie obliczać kluczy skrótów (co jest kosztowną operacją), jeśli musi pobrać dane znajdujące się w pewnym zakresie lub musi pobrać dane w kolejności klucza bez skrótu. Na przykład zapytanie, takie jak "Znajdź wszystkich klientów mieszkających w Redmond", można szybko rozwiązać, lokalizując pasujące elementy w tabeli indeksów, gdzie wszystkie są przechowywane w ciągłym bloku. Następnie można odwołać się do danych klientów, używając kluczy fragmentów przechowywanych w tabeli indeksów.
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
Koszty związane z obsługą indeksów pomocniczych mogą być znaczące. Należy przeanalizować i dobrze poznać zapytania wykonywane przez aplikację. Tabele indeksów należy tworzyć tylko wtedy, gdy będą one używane regularnie. Nie należy tworzyć teoretycznych tabel indeksów w celu obsługi zapytań, których aplikacja nie wykonuje lub które wykonuje tylko od czasu do czasu.
Duplikowanie danych w tabeli indeksów może znacząco zwiększyć koszty magazynowania i pracę wymaganą do obsługi wielu kopii danych.
Zaimplementowanie tabeli indeksów jako znormalizowanej struktury, która odwołuje się do danych oryginalnych, wymaga od aplikacji wykonania dwóch operacji wyszukiwania w celu odnalezienia danych. Pierwsza operacja przeszukuje tabelę indeksów w celu pobrania klucza podstawowego, a druga pobiera dane przy użyciu tego klucza podstawowego.
Jeśli system zawiera wiele tabel indeksów dla dużych zestawów danych, może być trudno zachować spójność między tabelami indeksów a oryginalnymi danymi. Czasami można zaprojektować aplikację z zastosowaniem modelu spójności ostatecznej. Na przykład w celu wstawiania, aktualizacji lub usuwania danych aplikacja może wysyłać komunikat do kolejki i za pomocą osobnego zadania wykonywać daną operację i obsługiwać tabele indeksów, które odwołują się do tych danych, w sposób asynchroniczny. Aby uzyskać więcej informacji na temat wdrażania spójności ostatecznej, zobacz Data consistency primer (Podstawy spójności danych).
Napiwek
Tabele magazynu platformy Microsoft Azure obsługują aktualizacje transakcyjne dla zmian wprowadzonych w danych przechowywanych w tej samej partycji (określane jako transakcje grupy jednostek). Jeśli istnieje możliwość przechowywania danych dla tabeli faktów i co najmniej jednej tabeli indeksów w tej samej partycji, funkcja ta może pomóc w zapewnieniu spójności.
Tabele indeksów można partycjonować, czyli fragmentować.
Kiedy używać tego wzorca
Wzorzec ten umożliwia poprawienie wydajności zapytań, gdy aplikacja często musi pobierać dane przy użyciu klucza innego niż klucz podstawowy (lub klucz fragmentu).
Ten wzorzec może nie być przydatny w następujących sytuacjach:
- Dane są nietrwałe. Tabela indeksów może bardzo szybko stać się nieaktualna, co powoduje, że jest nieefektywna, a koszty jej utrzymania przewyższają oszczędności uzyskane dzięki jej zastosowaniu.
- Pole wybrane jako klucz pomocniczy dla tabeli indeksów nie wyróżnia danych i może mieć tylko niewielki zestaw wartości (na przykład płeć).
- Proporcje wartości danych dla pola wybranego jako klucz pomocniczy dla tabeli indeksów są wysoce nierówne. Jeśli na przykład 90% rekordów zawiera tę samą wartość w polu, to tworzenie i obsługa tabeli indeksów w celu wyszukiwania danych na podstawie tego pola może wygenerować większe koszty niż sekwencyjne skanowanie danych. Jeśli jednak zapytania bardzo często dotyczą wartości, które znajdują się w pozostałych 10%, ten indeks może być przydatny. Należy dobrze poznać zapytania, które wykonuje aplikacja, oraz częstotliwość ich wykonywania.
Projekt obciążenia
Architekt powinien ocenić, jak wzorzec tabeli indeksów może być używany w projekcie obciążenia, aby sprostać celom i zasadom opisanym w filarach platformy Azure Well-Architected Framework. Na przykład:
| Filar | Jak ten wzorzec obsługuje cele filaru |
|---|---|
| Decyzje projektowe dotyczące niezawodności pomagają obciążeniu stać się odporne na awarię i zapewnić, że zostanie przywrócony do w pełni funkcjonalnego stanu po wystąpieniu awarii. | Ponieważ klienci są wskazywani na ich fragmenty, partycje lub punkt końcowy za pośrednictwem procesu wyszukiwania, można użyć tego wzorca, aby ułatwić przejście w tryb failover na potrzeby dostępu do danych. - PARTYcjonowanie danych RE:06 - RE:09 Odzyskiwanie po awarii |
| Wydajność pomagawydajnie sprostać zapotrzebowaniu dzięki optymalizacjom skalowania, danych, kodu. | Klienci są wskazywani na ich fragmenty, partycje lub punkt końcowy, co może umożliwić dynamiczne partycjonowanie danych na potrzeby optymalizacji wydajności. - PE:05 Skalowanie i partycjonowanie - PE:08 Wydajność danych |
Podobnie jak w przypadku każdej decyzji projektowej, należy rozważyć wszelkie kompromisy w stosunku do celów innych filarów, które mogą zostać wprowadzone przy użyciu tego wzorca.
Przykład
Tabele usługi Azure Storage zapewniają wysoce skalowalny magazyn danych klucz/wartość dla aplikacji uruchamianych w chmurze. Aplikacje przechowują i pobierają wartości danych, określając klucz. Te wartości danych mogą zawierać wiele pól, ale struktura elementu danych jest nieprzejrzysta w przechowalni tabel, który traktuje każdy przedmiot jako tablicę bajtów.
Tabele magazynu platformy Azure obsługują również fragmentowanie. Klucz fragmentowania zawiera dwa elementy: klucz partycji i klucz wiersza. Elementy, które mają ten sam klucz partycji, są przechowywane w tej samej partycji (fragmencie), a w obrębie fragmentu elementy są przechowywane w kolejności klucza wiersza. Magazyn tabel jest zoptymalizowany pod kątem wykonywania zapytań, które pobierają dane zawarte w ciągłym zakresie wartości klucza wiersza w partycji. W przypadku konstruowania aplikacji w chmurze, które przechowują informacje w tabelach platformy Azure, strukturę danych należy tworzyć, mając tę funkcję na uwadze.
Rozważmy na przykład aplikację, która przechowuje informacje dotyczące filmów. Aplikacja często wykonuje zapytania o filmy według gatunku (takie jak akcja, dokument, historyczny, komedia i dramat). Można utworzyć tabelę platformy Azure z partycjami dla każdego gatunku, używając tego gatunku jako klucza partycji i określając tytuł filmu jako klucz wiersza, jak pokazano na poniższej ilustracji.
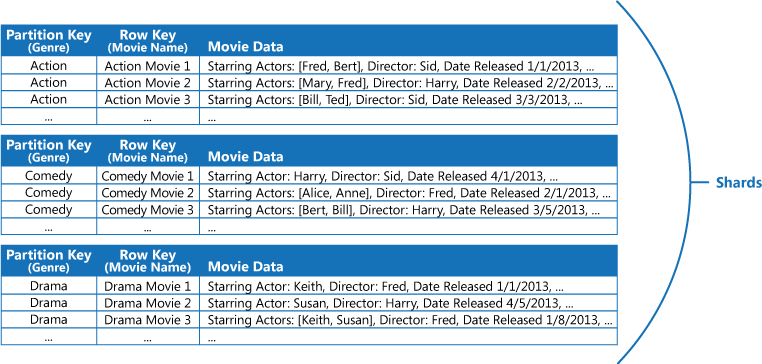
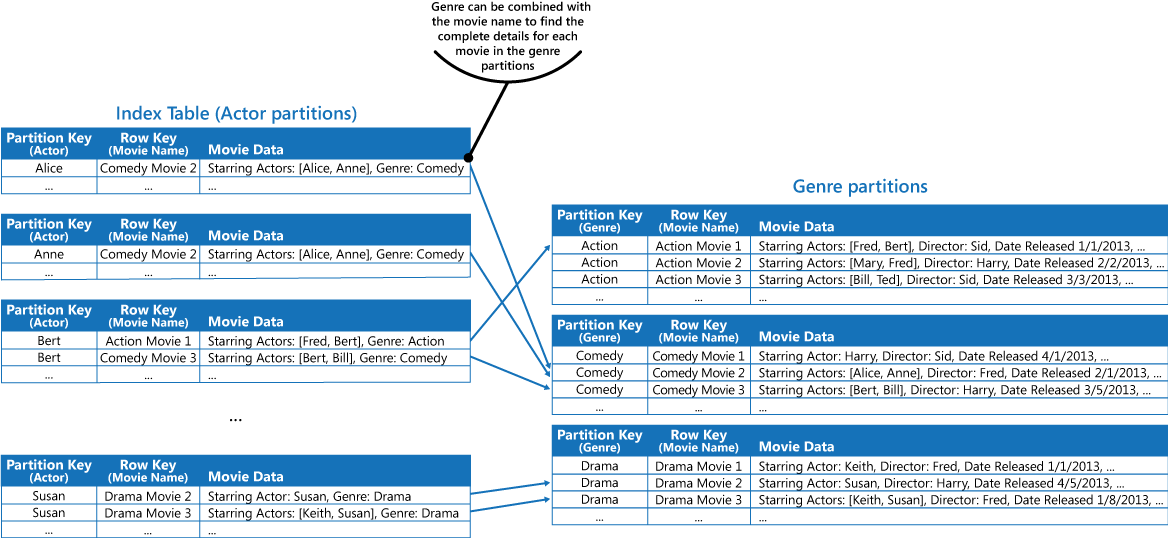
Ta metoda jest mniej skuteczna, jeśli aplikacja musi również wykonywać zapytania według aktorów występujących w danych filmach. W takim przypadku można utworzyć oddzielną tabelę platformy Azure, która będzie tabelą indeksów. Kluczem partycji jest aktor, a kluczem wiersza jest tytuł filmu. Dane dla każdego aktora będą przechowywane w osobnych partycjach. Jeśli w filmie występuje więcej niż jeden aktor, ten sam film pojawi się w wielu partycjach.
Można duplikować dane filmów w wartościach przechowywanych w każdej partycji, stosując pierwszą metodę opisaną powyżej w sekcji Rozwiązanie. Istnieje jednak duże prawdopodobieństwo, że każdy film zostanie zreplikowany kilka razy (raz dla każdego aktora), więc bardziej efektywne może być częściowe zdenormalizowanie danych w celu obsługi najczęściej wykonywanych zapytań (na przykład o nazwiska innych aktorów) i umożliwienie aplikacji pobierania pozostałych szczegółów przez uwzględnienie klucza partycji potrzebnego do znalezienia pełnych informacji w partycjach gatunku. Takie podejście jest opisane jako trzecia opcja w sekcji Rozwiązanie. Kolejna ilustracja przedstawia tę metodę.
Następne kroki
- Podstawy spójności danych. Tabelę indeksów należy aktualizować, gdy zmieniają się dane, które indeksuje. W chmurze przeprowadzanie operacji aktualizacji indeksu w ramach tej samej transakcji, która modyfikuje dane, może być niemożliwe lub nieodpowiednie. W takim przypadku lepsza jest metoda spójności ostatecznej. Ten artykuł zawiera informacje dotyczące zagadnień związanych ze spójnością ostateczną.
Powiązane zasoby
Podczas implementowania tego wzorca mogą być również istotne następujące wzorce:
- Wzorzec fragmentowania. Wzorzec indeksowania tabeli jest często używany w połączeniu z danymi partycjonowanymi za pomocą fragmentów. Artykuł Wzorzec fragmentowania zawiera więcej informacji na temat dzielenia magazynu danych na zestaw fragmentów.
- Materialized View pattern (Wzorzec zmaterializowanego widoku). Zamiast indeksować dane w celu obsługi zapytań, które podsumowują dane, bardziej odpowiednie może być utworzenie zmaterializowanego widoku danych. Ten artykuł opisuje sposób obsługi wydajnych zapytań podsumowujących za pomocą generowania wstępnie wypełnionych widoków danych.