Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Azure
Kontrolowanie zużycia zasobów używanych przez instancję aplikacji, pojedynczego najemcę lub całą usługę. Dzięki temu system może nadal działać i spełniać cele poziomu usług (SLO), nawet gdy wzrost zapotrzebowania powoduje ekstremalne obciążenie zasobów.
Kontekst i problem
Obciążenie aplikacji w chmurze zwykle różni się w czasie w zależności od liczby aktywnych użytkowników lub typów wykonywanych działań. Na przykład więcej użytkowników będzie zazwyczaj aktywnych w godzinach pracy lub pod koniec każdego miesiąca system może wykonywać analizy wymagające dużego nakładu mocy obliczeniowych. Mogą również wystąpić sytuacje nagłego i nieprzewidzianego wzrostu aktywności. Jeśli wymagania dotyczące przetwarzania systemu przekroczą pojemność dostępnych zasobów, wystąpią słabe wyniki i nawet mogą zakończyć się niepowodzeniem. Jeśli system musi zapewniać określny poziom usług, taka awaria może być niedopuszczalna.
Istnieje wiele strategii umożliwiających obsługę różnego obciążenia w chmurze, w zależności od celów biznesowych aplikacji. Jedną ze strategii jest użycie skalowania automatycznego do dopasowania przydzielonych zasobów do potrzeb użytkownika w danym momencie. Ma to potencjał, aby spójnie zaspokoić zapotrzebowanie użytkowników, jednocześnie optymalizując koszty działania. Jednak chociaż skalowanie automatyczne może wyzwolić aprowizację większej liczby zasobów, ta aprowizacja nie jest natychmiastowa. Jeśli zapotrzebowanie rośnie szybko, przez pewien czas może występować niedobór zasobów.
Rozwiązanie
Strategia alternatywna do automatycznego skalowania polega na umożliwieniu aplikacjom korzystania z zasobów tylko do określonego limitu, a następnie po osiągnięciu tego limitu ograniczenia ich wydajności. System powinien monitorować, jak używane są zasoby, i gdy użycie przekracza wartość progową, ograniczać żądania od jednego lub większej liczby użytkowników. Dzięki temu system może nadal działać i spełniać wszelkie cele poziomu usług (SLO), które są spełnione. Aby uzyskać więcej informacji dotyczących monitorowania użycia zasobów, zobacz Instrumentation and Telemetry Guidance (Wskazówki dotyczące instrumentacji i telemetrii).
System może mieć zaimplementowanych kilka strategii ograniczania przepustowości, w tym:
Odrzucanie żądań pojedynczego użytkownika, który uzyskiwał dostęp do interfejsów API systemu więcej niż n razy na sekundę w danym okresie. System musi dokonywać pomiaru wykorzystania zasobów przez każdego najemcę lub użytkownika uruchamiającego aplikację. Aby uzyskać więcej informacji, zobacz Instrukcje Meteringu Usługi.
Wyłączanie lub ograniczanie funkcjonalności wybranych mniej ważnych usług, aby istotne usługi mogły być bez przeszkód uruchamiane z wystarczającą ilością zasobów. Jeśli na przykład aplikacja przesyła strumieniowo wideo, może przełączyć rozdzielczość na niższą.
Wykorzystywanie wyrównywania obciążeń do wygładzania poziomu aktywności (to podejście zostało omówione bardziej szczegółowo w sekcji Wzorzec wyrównywania obciążeń przy użyciu kolejki). W środowisku wielodostępnym takie podejście zmniejszy wydajność dla każdego tenanta. Jeśli system musi obsługiwać różnych najemców z różnymi umowami SLA (Service Level Agreements), praca dla najemców o wysokiej wartości może zostać wykonana natychmiast. Żądania dotyczące pozostałych dzierżaw mogą być wstrzymywane i obsługiwane po rozładowaniu zaległości. Wzorzec kolejki priorytetowej może służyć do zaimplementowania tego podejścia, podobnie jak udostępnianie różnych punktów końcowych dla różnych poziomów/priorytetów usług.
Odkładanie operacji wykonywanych na rzecz aplikacji lub najemców o niższym priorytecie. Te operacje mogą zostać wstrzymane lub ograniczone poprzez wygenerowanie wyjątku w celu poinformowania najemcy, że system jest zajęty i należy ponowić próbę wykonania operacji później.
Należy zachować ostrożność podczas integracji z niektórymi usługami innych firm, które mogą stać się niedostępne lub zwracać błędy. Zmniejsz liczbę przetwarzanych współbieżnych żądań, aby dzienniki nie wypełniały się niepotrzebnie błędami. Można również uniknąć kosztów związanych z niepotrzebnie ponawianiem próby przetwarzania żądań, które mogłyby zakończyć się niepowodzeniem z powodu tej usługi innej firmy. Następnie, po pomyślnym przetworzeniu żądań, wróć do zwykłego przetwarzania nieograniczonych żądań. Jedną z bibliotek implementujących tę funkcję jest NServiceBus.
Rysunek przedstawia wykres warstwowy wykorzystania zasobów (zestawienie pamięci, procesora CPU, przepustowości i innych czynników) w czasie przez aplikacje, które wykorzystują trzy funkcje. Funkcja to obszar funkcjonalności, na przykład składnik wykonujący określony zestaw zadań, fragment kodu wykonujący złożone obliczenia lub element zapewniający usługę, jak np. wewnątrzpamięciowa pamięć podręczna. Te funkcje oznaczono jako A, B i C.
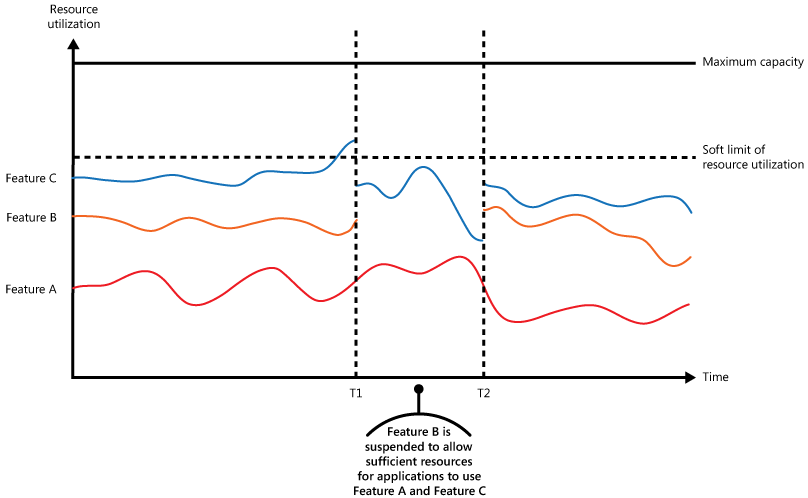
Obszar bezpośrednio pod linią funkcji oznacza zasoby, które są używane przez aplikacje podczas wywoływania tej funkcji. Na przykład obszar poniżej linii dla funkcji A przedstawia zasoby używane przez aplikacje, które wykorzystują funkcję A, a obszar między liniami dla funkcji A i B odpowiada zasobom używanym przez aplikacje wywołujące funkcję B. Agregacja obszarów dla każdej z funkcji pokazuje łączne wykorzystanie zasobów systemu.
Na poprzedniej ilustracji przedstawiono efekty odroczenia operacji. Tuż przed upływem czasu T1 łączna ilość zasobów przydzielonych do wszystkich aplikacji korzystających z tych funkcji osiągnie próg. Ten próg reprezentuje limit użycia zasobów. Na tym etapie dochodzi do niebezpieczeństwa wyczerpania przez aplikacje dostępnych zasobów. W tym systemie funkcja B jest mniej istotna niż funkcja A lub funkcja C, więc zostaje tymczasowo wyłączona, zaś zasoby, które wykorzystywała zostają zwolnione. Między momentami T1 a T2 aplikacje używające funkcji A i funkcji C działają normalnie. Po pewnym czasie wykorzystanie zasobów przez te dwie funkcje zmniejsza się do poziomu, gdy w momencie T2 ilość dostępnych zasobów jest wystarczająco duża, aby ponownie włączyć funkcję B.
Podejścia wykorzystujące automatyczne skalowanie i ograniczanie wydajności można również łączyć, aby zapewnić, że aplikacje będą działać dynamicznie i w ramach umów SLA. Jeśli oczekuje się, że zapotrzebowanie pozostanie wysokie, dławienie zapewnia tymczasowe rozwiązanie podczas skalowania poziomego systemu. Na tym etapie można przywrócić pełną funkcjonalność systemu.
Następny rysunek przedstawia wykres warstwowy całkowitego wykorzystania zasobów w czasie przez wszystkie aplikacje uruchomione w systemie oraz ilustruje, w jaki sposób można połączyć ograniczanie wydajności z automatycznym skalowaniem.
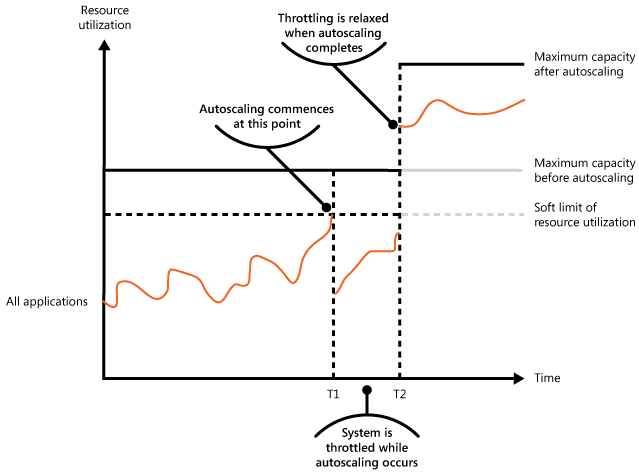
W momencie T1 zostaje osiągnięta wartość progowa określająca zmienny limit wykorzystania zasobów. W tym momencie system może rozpocząć skalowanie w poziomie. Jeśli jednak nowe zasoby nie zostaną udostępnione wystarczająco szybko, istniejące zasoby mogą zostać wyczerpane, a system może ulec awarii. Aby temu zapobiec, wydajność systemu zostaje tymczasowo ograniczona zgodnie z wcześniejszym opisem. Po zakończeniu skalowania automatycznego i udostępnieniu dodatkowych zasobów ograniczanie przepustowości może być złagodzone.
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrażania tego wzorca należy rozważyć następujące kwestie:
Ograniczanie aplikacji oraz strategia do zastosowania to decyzje architektoniczne, które mają wpływ na cały projekt systemu. Ograniczanie wydajności powinno zostać przeanalizowane na wczesnym etapie procesu projektowania aplikacji, ponieważ nie jest łatwo je dodać po zaimplementowaniu systemu.
Ograniczanie wydajności musi się odbywać szybko. System musi mieć zdolność wykrywania wzrostu aktywności i odpowiednio reagować. System musi również pozwalać na szybkie przywrócenie pierwotnego stanu po tym, jak obciążenie spadnie. Wymaga to ciągłego przechwytywania i monitorowania odpowiednich danych dotyczących wydajności.
Jeśli usługa musi tymczasowo odrzucić żądanie użytkownika, powinien zwrócić określony kod błędu, taki jak 429 ("Zbyt wiele żądań") i 503 ("Zbyt zajęty serwer"), aby aplikacja kliencka mogła zrozumieć, że przyczyną odmowy obsługi żądania jest ograniczenie przepustowości.
- HTTP 429 wskazuje, że aplikacja wywołująca wysłała zbyt wiele żądań w przedziale czasu i przekroczyła wstępnie określony limit.
- Http 503 wskazuje, że usługa nie jest gotowa do obsługi żądania. Częstą przyczyną jest to, że w usłudze występują bardziej tymczasowe skoki obciążenia niż oczekiwano.
Aplikacja kliencka może oczekiwać przez pewien czas przed ponowieniem próby żądania. Należy Retry-After uwzględnić nagłówek HTTP, aby obsługiwać klienta podczas wybierania strategii ponawiania prób.
Ograniczanie wydajności może służyć jako tymczasowy środek podczas automatycznego skalowania systemu. W niektórych przypadkach lepszym rozwiązaniem jest ograniczenie przepustowości, a nie skalowanie, jeśli nagły wzrost aktywności jest nagły i nie powinien trwać, ponieważ skalowanie może znacznie zwiększyć koszty działania.
Jeśli ograniczanie przepustowości jest używane jako tymczasowa miara podczas automatycznego skalowania systemu, a zapotrzebowanie na zasoby rośnie bardzo szybko, system może nie być w stanie kontynuować działania — nawet w przypadku działania w trybie ograniczania. Jeśli to nie jest dopuszczalne, należy wziąć pod uwagę zapewnienie większych rezerw wydajności i skonfigurowanie bardziej agresywnego automatycznego skalowania.
Normalizuj koszty zasobów dla różnych operacji, ponieważ zwykle nie mają równych kosztów wykonywania. Na przykład limity ograniczania przepustowości mogą być niższe dla operacji odczytu i wyższe w przypadku operacji zapisu. Nie biorąc pod uwagę kosztów operacji, może to spowodować wyczerpanie pojemności i uwidocznić potencjalny wektor ataku.
Pożądana jest dynamiczna zmiana konfiguracji zachowania dławienia podczas działania. Jeśli system napotka nietypowe obciążenie, którego zastosowana konfiguracja nie może obsłużyć, ograniczenia przepustowości mogą wymagać zwiększenia lub zmniejszenia, aby ustabilizować system i nadążyć za bieżącym ruchem. Kosztowne, ryzykowne i powolne wdrożenia nie są w tym momencie pożądane. Korzystając z wzorca Zewnętrznego Magazynu Konfiguracji, konfiguracja ograniczania jest wyodrębniona i może być zmieniana oraz stosowana bez potrzeby wdrażania.
Kiedy używać tego wzorca
Użyj tego wzorca:
Aby zapewnić, że system nadal spełnia cele poziomu usług (SLO).
Aby zapobiec monopolizowaniu przez pojedynczego najemcę zasobów dostępnych w aplikacji.
Do obsługi nagłego wzrostu aktywności.
Do optymalizowania kosztów systemu poprzez ograniczenie maksymalnych poziomów zasobów potrzebnych do zapewnienia jego funkcjonowania.
Aby zmniejszyć przetwarzanie obliczeniowe o niskiej wartości w okresach wysokiego wskaźnika emisji dwutlenku węgla w sieci energetycznej.
Projektowanie obciążenia
Architekt powinien ocenić, w jaki sposób wzorzec ograniczania przepustowości może być używany w projekcie obciążenia w celu rozwiązania celów i zasad omówionych w filarach Azure Well-Architected Framework. Na przykład:
| Filar | Jak ten wzorzec obsługuje cele filaru |
|---|---|
| Decyzje projektowe dotyczące niezawodności pomagają obciążeniu stać się odporne na awarię i zapewnić, że zostanie przywrócony do w pełni funkcjonalnego stanu po wystąpieniu awarii. | Należy zaprojektować limity, aby zapobiec wyczerpaniu zasobów, które mogą prowadzić do awarii. Możesz również użyć tego wzorca jako mechanizmu sterującego w bezproblemowym planie degradacji. - RE:07 Instynkt samozachowawczy |
| Decyzje dotyczące projektowania zabezpieczeń pomagają zapewnić poufność, integralność i dostępność danych i systemów obciążenia. | Możesz zaprojektować limity, aby zapobiec wyczerpaniu zasobów, które mogą wynikać z zautomatyzowanego nadużywania systemu. - SE:06 Kontrolki sieci - SE:08 Wzmacnianie zabezpieczeń zasobów |
| Optymalizacja kosztów koncentruje się na utrzymaniu i poprawiezwrotu z nakładu pracy. | Wymuszone limity mogą informować o modelowaniu kosztów, a nawet bezpośrednio powiązać z modelem biznesowym aplikacji. Umożliwiają one również jasne górne granice wykorzystania, które można uwzględnić w określaniu rozmiaru zasobów. - CO:02 Model kosztów - CO:12 Koszty skalowania |
| Wydajność pomagawydajnie sprostać zapotrzebowaniu dzięki optymalizacjom skalowania, danych, kodu. | Gdy system jest pod dużym obciążeniem, ten wzorzec pomaga ograniczyć przeciążenie, które może prowadzić do wąskich gardeł wydajności. Można go również używać do proaktywnego unikania problemów z hałaśliwym sąsiadem. - PE:02 Planowanie pojemności - PE:05 Skalowanie i partycjonowanie |
Podobnie jak w przypadku każdej decyzji projektowej, należy rozważyć wszelkie kompromisy w stosunku do celów innych filarów, które mogą zostać wprowadzone przy użyciu tego wzorca.
Przykład
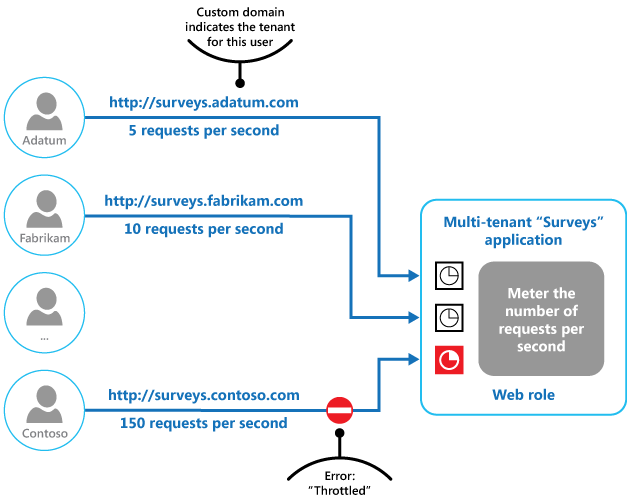
Na rysunku końcowym pokazano, jak można zaimplementować ograniczanie przepustowości w systemie wielodostępnym. Użytkownicy każdej z organizacji posiadającej dzierżawę mają dostęp do aplikacji hostowanej w chmurze, gdzie wypełniają i wysyłają ankiety. Aplikacja zawiera instrumentację, która monitoruje szybkość, z jaką użytkownicy przesyłają żądania do aplikacji.
Aby uniemożliwić użytkownikom jednej dzierżawy wpływanie na czas odpowiedzi i dostępność aplikacji dla pozostałych użytkowników, zastosowano limit liczby przesyłanych żądań na sekundę dla użytkowników pojedynczej dzierżawy. Aplikacja blokuje żądania, które przekraczają ten limit.
Następne kroki
Podczas implementowania tego wzorca mogą być istotne następujące wskazówki:
- Instrumentation and Telemetry Guidance (Wskazówki dotyczące instrumentacji i telemetrii). Ograniczanie wydajności zależy od zbieranych informacji na temat stopnia wykorzystania usługi. Opisuje sposób generowania i rejestrowania niestandardowych informacji dotyczących monitorowania.
- Wskazówki dotyczące pomiarów usługi. Opisuje sposób pomiaru użycia usług w celu uzyskania zrozumienia sposobu ich używania. Te informacje mogą być przydatne w wyborze sposobu ograniczenia wydajności usługi.
- Autoscaling Guidance (Wskazówki dotyczące skalowania automatycznego). Ograniczanie wydajności może służyć jako tymczasowy środek podczas automatycznego skalowania systemu lub w celu usunięcia potrzeby automatycznego skalowania systemu. Zawiera informacje o strategiach automatycznego skalowania.
Powiązane zasoby
Podczas implementowania tego wzorca mogą być również istotne następujące wzorce:
- Wzorzec wyrównywania obciążeń przy użyciu kolejki. Wyrównywanie obciążeń przy użyciu kolejki jest często stosowanym mechanizmem przy implementowaniu ograniczania wydajności. Kolejka może pełnić rolę bufora ułatwiającego wyrównywanie szybkości, z jaką żądania wysyłane przez aplikacje są dostarczane do usługi.
- Wzorzec kolejki priorytetowej. System może wykorzystywać kolejkę priorytetową jako część strategii ograniczania przepływności w celu utrzymania wydajności aplikacji krytycznych i aplikacji o większym znaczeniu, jednocześnie zmniejszając wydajność mniej ważnych aplikacji.
- Wzorzec zewnętrznego magazynu konfiguracji. Scentralizowanie i zewnętrzne polityki ograniczania przepustowości zapewniają możliwość zmiany konfiguracji w trybie wykonywania bez potrzeby ponownego wdrażania. Usługi mogą subskrybować zmiany konfiguracji, które natychmiast stosują nową konfigurację, aby ustabilizować system.