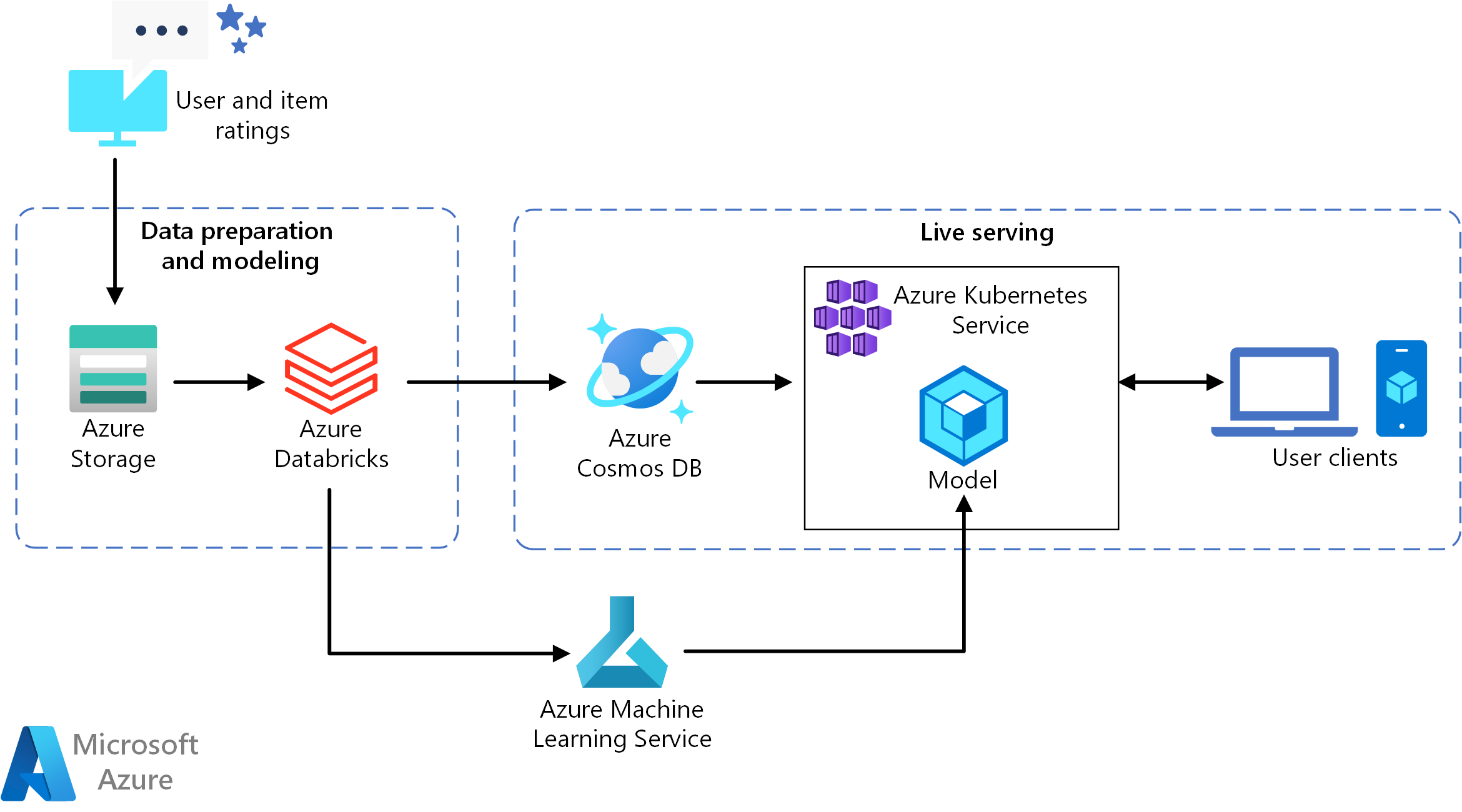
Ta architektura referencyjna przedstawia sposób trenowania modelu rekomendacji przy użyciu usługi Azure Databricks, a następnie wdrażania modelu jako interfejsu API przy użyciu usług Azure Cosmos DB, Azure Machine Learning i Azure Kubernetes Service (AKS). Aby zapoznać się z implementacją referencyjną tej architektury, zobacz Tworzenie interfejsu API rekomendacji w czasie rzeczywistym w usłudze GitHub.
Architektura
Pobierz plik programu Visio z tą architekturą.
Ta architektura referencyjna służy do trenowania i wdrażania interfejsu API usługi rekomendacji w czasie rzeczywistym, który może udostępnić 10 najważniejszych rekomendacji dotyczących filmów dla użytkownika.
Przepływ danych
- Śledzenie zachowań użytkowników. Na przykład usługa zaplecza może rejestrować się, gdy użytkownik ocenia film lub klika produkt lub artykuł z wiadomościami.
- Załaduj dane do usługi Azure Databricks z dostępnego źródła danych.
- Przygotuj dane i podziel je na zestawy trenowania i testowania w celu wytrenowania modelu. (W tym przewodniku opisano opcje dzielenia danych).
- Dopasuj model filtrowania współpracy platformy Spark do danych.
- Oceń jakość modelu przy użyciu metryk klasyfikacji i klasyfikacji. (Ten przewodnik zawiera szczegółowe informacje o metrykach, których można użyć do oceny rekomendacji).
- Wstępnie skompiluj 10 najważniejszych zaleceń na użytkownika i zapisz je jako pamięć podręczną w usłudze Azure Cosmos DB.
- Wdrażanie usługi interfejsu API w usłudze AKS przy użyciu interfejsów API usługi Machine Learning w celu konteneryzowania i wdrażania interfejsu API.
- Gdy usługa zaplecza pobiera żądanie od użytkownika, wywołaj interfejs API zaleceń hostowany w usłudze AKS, aby uzyskać 10 najważniejszych zaleceń i wyświetlić je użytkownikowi.
Składniki
- Azure Databricks. Databricks to środowisko programistyczne używane do przygotowywania danych wejściowych i trenowania modelu rekomendacji w klastrze Spark. Usługa Azure Databricks udostępnia również interaktywny obszar roboczy do uruchamiania i współpracy nad notesami na potrzeby dowolnych zadań przetwarzania danych lub uczenia maszynowego.
- Azure Kubernetes Service (AKS). Usługa AKS służy do wdrażania i operacjonalizacji interfejsu API usługi modelu uczenia maszynowego w klastrze Kubernetes. Usługa AKS hostuje model konteneryzowany, zapewniając skalowalność spełniającą wymagania dotyczące przepływności, zarządzanie tożsamościami i dostępem oraz rejestrowanie i monitorowanie kondycji.
- Azure Cosmos DB. Azure Cosmos DB to globalnie rozproszona usługa bazy danych używana do przechowywania 10 zalecanych filmów dla każdego użytkownika. Usługa Azure Cosmos DB jest odpowiednia dla tego scenariusza, ponieważ zapewnia małe opóźnienie (10 ms na 99. percentyl) w celu odczytania najważniejszych zalecanych elementów dla danego użytkownika.
- Uczenie maszynowe. Ta usługa służy do śledzenia modeli uczenia maszynowego i zarządzania nimi, a następnie tworzenia pakietów i wdrażania tych modeli w skalowalnym środowisku usługi AKS.
- Microsoft Recommenders. To repozytorium typu open source zawiera kod narzędzia i przykłady ułatwiające użytkownikom rozpoczęcie tworzenia, oceniania i operacjonalizacji systemu rekomendacji.
Szczegóły scenariusza
Ta architektura może być uogólniona w przypadku większości scenariuszy aparatu rekomendacji, w tym rekomendacji dotyczących produktów, filmów i wiadomości.
Potencjalne przypadki użycia
Scenariusz: Organizacja mediana chce udostępnić użytkownikom rekomendacje dotyczące filmów lub filmów wideo. Udostępniając spersonalizowane rekomendacje, organizacja spełnia kilka celów biznesowych, w tym zwiększone wskaźniki kliknięć, zwiększone zaangażowanie w witrynę internetową i większe zadowolenie użytkowników.
To rozwiązanie jest zoptymalizowane pod kątem branży detalicznej i branży mediów i rozrywki.
Kwestie wymagające rozważenia
Te zagadnienia implementują filary struktury Azure Well-Architected Framework, która jest zestawem wytycznych, które mogą służyć do poprawy jakości obciążenia. Aby uzyskać więcej informacji, zobacz Microsoft Azure Well-Architected Framework.
Wsadowe ocenianie modeli Spark w usłudze Azure Databricks opisuje architekturę referencyjną, która używa platformy Spark i usługi Azure Databricks do wykonywania zaplanowanych procesów oceniania wsadowego. Zalecamy takie podejście do generowania nowych zaleceń.
Efektywność wydajności
Efektywność wydajności to możliwość skalowania obciążenia w celu zaspokojenia zapotrzebowania użytkowników w wydajny sposób. Aby uzyskać więcej informacji, zobacz Omówienie filaru wydajności.
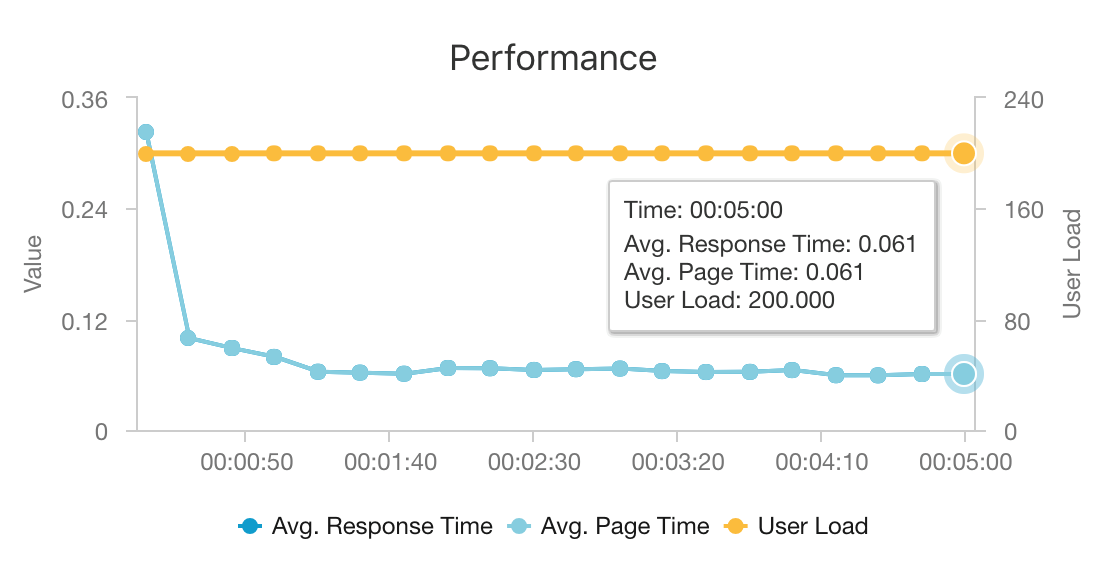
Wydajność jest główną kwestią w przypadku zaleceń w czasie rzeczywistym, ponieważ rekomendacje zwykle wchodzą w krytyczną ścieżkę żądania użytkownika w witrynie internetowej.
Połączenie usług AKS i Azure Cosmos DB umożliwia tej architekturze zapewnienie dobrego punktu wyjścia do udostępnienia zaleceń dotyczących średniej wielkości obciążenia z minimalnym obciążeniem. W ramach testu obciążeniowego z 200 równoczesnymi użytkownikami ta architektura udostępnia zalecenia dotyczące mediany opóźnienia około 60 ms i wykonuje przepływność 180 żądań na sekundę. Test obciążeniowy został uruchomiony względem domyślnej konfiguracji wdrożenia (klaster 3x D3 v2 AKS z 12 procesorami wirtualnymi, 42 GB pamięci i 11 000 jednostek żądań (RU) na sekundę aprowizowaną dla usługi Azure Cosmos DB.

Usługa Azure Cosmos DB jest zalecana w celu uzyskania gotowej do użycia dystrybucji globalnej i przydatności do spełnienia wszelkich wymagań dotyczących bazy danych, które ma twoja aplikacja. Aby nieco zmniejszyć opóźnienie, rozważ użycie usługi Azure Cache for Redis zamiast usługi Azure Cosmos DB do obsługi odnośników. Usługa Azure Cache for Redis może zwiększyć wydajność systemów, które w dużym stopniu korzystają z danych w magazynach zaplecza.
Skalowalność
Jeśli nie planujesz korzystać z platformy Spark lub masz mniejsze obciążenie, które nie wymaga dystrybucji, rozważ użycie maszyny wirtualnej Nauka o danych (DSVM) zamiast usługi Azure Databricks. Maszyna DSVM to maszyna wirtualna platformy Azure z platformami uczenia głębokiego i narzędziami do uczenia maszynowego i nauki o danych. Podobnie jak w przypadku usługi Azure Databricks, każdy model tworzony w maszynie DSVM może być zoperacjonalizowany jako usługa w usłudze AKS za pośrednictwem usługi Machine Learning.
Podczas trenowania aprowizuj większy klaster Spark o stałym rozmiarze w usłudze Azure Databricks lub skonfiguruj skalowanie automatyczne. Po włączeniu skalowania automatycznego usługa Databricks monitoruje obciążenie klastra i skaluje w górę i w dół zgodnie z potrzebami. Aprowizowanie lub skalowanie w poziomie większego klastra, jeśli masz duży rozmiar danych i chcesz skrócić czas potrzebny na przygotowanie danych lub zadania modelowania.
Przeskaluj klaster usługi AKS, aby spełnić wymagania dotyczące wydajności i przepływności. Zadbaj o skalowanie w górę liczby zasobników w celu pełnego wykorzystania klastra i skalowania węzłów klastra w celu zaspokojenia zapotrzebowania usługi. Możesz również ustawić skalowanie automatyczne w klastrze usługi AKS. Aby uzyskać więcej informacji, zobacz Wdrażanie modelu w klastrze usługi Azure Kubernetes Service.
Aby zarządzać wydajnością usługi Azure Cosmos DB, należy oszacować liczbę operacji odczytu wymaganych na sekundę i aprowizować wymaganą liczbę jednostek RU na sekundę (przepływność). Skorzystaj z najlepszych rozwiązań dotyczących partycjonowania i skalowania w poziomie.
Optymalizacja kosztów
Optymalizacja kosztów dotyczy sposobów zmniejszenia niepotrzebnych wydatków i poprawy wydajności operacyjnej. Aby uzyskać więcej informacji, zobacz Omówienie filaru optymalizacji kosztów.
Głównymi przyczynami kosztów w tym scenariuszu są:
- Rozmiar klastra usługi Azure Databricks wymagany do trenowania.
- Rozmiar klastra usługi AKS wymagany do spełnienia wymagań dotyczących wydajności.
- Aprowizowania jednostek RU usługi Azure Cosmos DB w celu spełnienia wymagań dotyczących wydajności.
Zarządzanie kosztami usługi Azure Databricks przez ponowne trenowanie rzadziej i wyłączanie klastra Spark, gdy nie jest używany. Koszty usług AKS i Azure Cosmos DB są powiązane z przepływnością i wydajnością wymaganą przez witrynę oraz będą skalowane w górę i w dół w zależności od ilości ruchu do witryny.
Wdrażanie tego scenariusza
Aby wdrożyć tę architekturę, postępuj zgodnie z instrukcjami usługi Azure Databricks w dokumencie konfiguracji. Pokrótce instrukcje wymagają:
- Tworzenie obszaru roboczego usługi Azure Databricks.
- Utwórz nowy klaster z następującą konfiguracją w usłudze Azure Databricks:
- Tryb klastra: Standardowa
- Wersja środowiska uruchomieniowego usługi Databricks: 4.3 (w tym Apache Spark 2.3.1, Scala 2.11)
- Wersja języka Python: 3
- Typ sterownika: Standard_DS3_v2
- Typ procesu roboczego: Standard_DS3_v2 (minimalna i maksymalna zgodnie z wymaganiami)
- Automatyczne kończenie: (zgodnie z wymaganiami)
- Konfiguracja platformy Spark: (zgodnie z wymaganiami)
- Zmienne środowiskowe: (zgodnie z wymaganiami)
- Utwórz osobisty token dostępu w obszarze roboczym usługi Azure Databricks. Aby uzyskać szczegółowe informacje, zobacz dokumentację uwierzytelniania usługi Azure Databricks.
- Sklonuj repozytorium Microsoft Recommenders do środowiska, w którym można wykonywać skrypty (na przykład komputer lokalny).
- Postępuj zgodnie z instrukcjami dotyczącymi szybkiej instalacji , aby zainstalować odpowiednie biblioteki w usłudze Azure Databricks.
- Postępuj zgodnie z instrukcjami dotyczącymi szybkiej instalacji, aby przygotować usługę Azure Databricks do operacji.
- Zaimportuj notes operacjonalizacji filmów ALS do obszaru roboczego. Po zalogowaniu się do obszaru roboczego usługi Azure Databricks wykonaj następujące czynności:
- Kliknij pozycję Strona główna po lewej stronie obszaru roboczego.
- Kliknij prawym przyciskiem myszy biały znak w katalogu głównym. Wybierz Importuj.
- Wybierz pozycję Adres URL i wklej następujące elementy w polu tekstowym:
https://github.com/Microsoft/Recommenders/blob/main/examples/05_operationalize/als_movie_o16n.ipynb - Kliknij przycisk Importuj.
- Otwórz notes w usłudze Azure Databricks i dołącz skonfigurowany klaster.
- Uruchom notes, aby utworzyć zasoby platformy Azure wymagane do utworzenia interfejsu API rekomendacji, który udostępnia zalecenia dotyczące filmu z 10 pierwszych 10 dla danego użytkownika.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Autorzy zabezpieczeń:
- Miguel Fierro | Menedżer badacze dancyh podmiotu zabezpieczeń
- Nikhil Joglekar | Menedżer produktu, algorytmy platformy Azure i nauka o danych
Aby wyświetlić niepubalne profile serwisu LinkedIn, zaloguj się do serwisu LinkedIn.
Następne kroki
- Tworzenie interfejsu API rekomendacji w czasie rzeczywistym
- Co to jest usługa Azure Databricks?
- Azure Kubernetes Service
- Azure Cosmos DB — Zapraszamy!
- Co to jest Azure Machine Learning?