Pomysły dotyczące rozwiązań
Ten artykuł jest pomysłem na rozwiązanie. Jeśli chcesz, abyśmy rozszerzyli zawartość o więcej informacji, takich jak potencjalne przypadki użycia, alternatywne usługi, zagadnienia dotyczące implementacji lub wskazówki dotyczące cen, daj nam znać, przekazując opinię w usłudze GitHub.
Zaimplementuj niestandardowe rozwiązanie do przetwarzania języka naturalnego (NLP) na platformie Azure. Użyj usługi Spark NLP do wykonywania zadań takich jak temat i wykrywanie tonacji i analiza.
Apache®, Apache Spark i logo płomienia są zastrzeżonymi znakami towarowymi lub znakami towarowymi fundacji Apache Software Foundation w Stany Zjednoczone i/lub innych krajach. Użycie tych znaków nie jest dorozumiane przez fundację Apache Software Foundation.
Architektura

Pobierz plik programu Visio z tą architekturą.
Przepływ pracy
- Usługi Azure Event Hubs, Azure Data Factory lub obie usługi odbierają dokumenty lub dane tekstowe bez struktury.
- Usługi Event Hubs i Data Factory przechowują dane w formacie pliku w usłudze Azure Data Lake Storage. Zalecamy skonfigurowanie struktury katalogów zgodnej z wymaganiami biznesowymi.
- Interfejs API usługi Azure przetwarzanie obrazów używa funkcji optycznego rozpoznawania znaków (OCR) do korzystania z danych. Następnie interfejs API zapisuje dane w warstwie z brązu. Ta platforma zużycia korzysta z architektury lakehouse.
- W warstwie z brązu różne funkcje równoważenia obciążenia sieciowego platformy Spark wstępnie przetwarzają tekst. Przykłady obejmują dzielenie, poprawianie pisowni, czyszczenie i zrozumienie gramatyki. Zalecamy uruchomienie klasyfikacji dokumentów w warstwie z brązu, a następnie zapisanie wyników w warstwie srebrnej.
- W warstwie srebrnej zaawansowane funkcje równoważenia obciążenia sieciowego platformy Spark wykonują zadania analizy dokumentów, takie jak rozpoznawanie jednostek nazwanych, podsumowanie i pobieranie informacji. W niektórych architekturach wynik jest zapisywany w warstwie złota.
- W warstwie złota platforma Spark NLP uruchamia różne analizy wizualne dotyczące danych tekstowych. Te analizy zapewniają wgląd w zależności języka i pomagają w wizualizacji etykiet NER.
- Użytkownicy wysyłają zapytania do danych tekstowych w warstwie złota jako ramkę danych i wyświetlają wyniki w usłudze Power BI lub aplikacjach internetowych.
Podczas kroków przetwarzania usługi Azure Databricks, Azure Synapse Analytics i Azure HDInsight są używane z usługą Spark NLP w celu zapewnienia funkcjonalności nlp.
Elementy
- Data Lake Storage to zgodny z platformą Hadoop system plików, który ma zintegrowaną hierarchiczną przestrzeń nazw oraz ogromną skalę i gospodarkę usługi Azure Blob Storage.
- Azure Synapse Analytics to usługa analityczna dla magazynów danych i systemów danych big data.
- Azure Databricks to usługa analizy danych big data, która jest łatwa w użyciu, ułatwia współpracę i jest oparta na platformie Apache Spark. Usługa Azure Databricks jest przeznaczona do nauki o danych i inżynierii danych.
- Usługa Event Hubs pozysuje strumienie danych generowane przez aplikacje klienckie. Usługa Event Hubs przechowuje dane przesyłane strumieniowo i zachowuje sekwencję odebranych zdarzeń. Użytkownicy mogą łączyć się z punktami końcowymi centrum w celu pobierania komunikatów do przetwarzania. Usługa Event Hubs integruje się z usługą Data Lake Storage, jak pokazuje to rozwiązanie.
- Usługa Azure HDInsight to zarządzana, w pełni spektrum, usługa analizy typu open source w chmurze dla przedsiębiorstw. Platformy typu open source można używać z usługą Azure HDInsight, takimi jak Hadoop, Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Storm i R.
- Usługa Data Factory automatycznie przenosi dane między kontami magazynu o różnych poziomach zabezpieczeń, aby zapewnić rozdzielenie obowiązków.
- przetwarzanie obrazów używa interfejsów API rozpoznawania tekstu do rozpoznawania tekstu na obrazach i wyodrębniania tych informacji. Interfejs API odczytu używa najnowszych modeli rozpoznawania i jest zoptymalizowany pod kątem dużych dokumentów z dużą ilością tekstu i hałaśliwych obrazów. Interfejs API OCR nie jest zoptymalizowany pod kątem dużych dokumentów, ale obsługuje więcej języków niż interfejs API odczytu. To rozwiązanie używa protokołu OCR do tworzenia danych w formacie hOCR .
Szczegóły scenariusza
Przetwarzanie języka naturalnego (NLP) ma wiele zastosowań: analizę tonacji, wykrywanie tematów, wykrywanie języka, wyodrębnianie kluczowych fraz i kategoryzacja dokumentów.
Apache Spark to platforma przetwarzania równoległego, która obsługuje przetwarzanie w pamięci w celu zwiększenia wydajności aplikacji analitycznych big data, takich jak NLP. Usługi Azure Synapse Analytics, Azure HDInsight i Azure Databricks oferują dostęp do platformy Spark i korzystają z jej mocy obliczeniowej.
W przypadku dostosowanych obciążeń NLP biblioteka open source Spark NLP służy jako wydajna struktura do przetwarzania dużej ilości tekstu. W tym artykule przedstawiono rozwiązanie dla niestandardowej równoważenia obciążenia sieciowego na dużą skalę na platformie Azure. Rozwiązanie używa funkcji nlp platformy Spark do przetwarzania i analizowania tekstu. Aby uzyskać więcej informacji na temat równoważenia obciążenia sieciowego platformy Spark, zobacz Funkcje i potoki nlp platformy Spark w dalszej części tego artykułu.
Potencjalne przypadki użycia
Klasyfikacja dokumentów: Platforma Spark NLP oferuje kilka opcji klasyfikacji tekstu:
- Wstępne przetwarzanie tekstu w algorytmach nlp platformy Spark i uczenia maszynowego opartych na usłudze Spark ML
- Wstępne przetwarzanie tekstu i osadzanie wyrazów w usłudze Spark NLP i algorytmach uczenia maszynowego, takich jak GloVe, BERT i ELMo
- Wstępne przetwarzanie tekstu i osadzanie zdań w usłudze Spark NLP oraz algorytmy i modele uczenia maszynowego, takie jak koder uniwersalnego zdania
- Wstępne przetwarzanie tekstu i klasyfikacja w funkcji NLP platformy Spark, która używa adnotacji ClassifierDL i jest oparta na tensorFlow
Wyodrębnianie jednostek nazw (NER): W rozwiązaniu Spark NLP z kilkoma wierszami kodu można wytrenować model NER korzystający z BERT i uzyskać najnowocześniejszej dokładności. NER to podzadanie wyodrębniania informacji. NER lokalizuje nazwane jednostki w tekście bez struktury i klasyfikuje je w wstępnie zdefiniowanych kategoriach, takich jak nazwiska osób, organizacje, lokalizacje, kody medyczne, wyrażenia czasowe, ilości, wartości pieniężne i wartości procentowe. Usługa Spark NLP używa najnowocześniejszego modelu NER z BERT. Model jest inspirowany byłym modelem NER, dwukierunkowym LSTM-CNN. Ten były model używa nowej architektury sieci neuronowej, która automatycznie wykrywa funkcje na poziomie słów i na poziomie znaków. W tym celu model korzysta z hybrydowej dwukierunkowej architektury LSTM i CNN, więc eliminuje potrzebę większości inżynierii cech.
Wykrywanie tonacji i emocji: usługa Spark NLP może automatycznie wykrywać pozytywne, negatywne i neutralne aspekty języka.
Część mowy (POS): ta funkcja przypisuje etykietę gramatyczną do każdego tokenu w tekście wejściowym.
Wykrywanie zdań (SD): sd opiera się na modelu sieci neuronowej ogólnego przeznaczenia na potrzeby wykrywania granic zdań, które identyfikuje zdania w tekście. Wiele zadań NLP pobiera zdanie jako jednostkę wejściową. Przykłady tych zadań obejmują tagowanie poS, analizowanie zależności, rozpoznawanie jednostek nazwanych i tłumaczenie maszynowe.
Funkcje i potoki równoważenia obciążenia sieciowego platformy Spark
Platforma Spark NLP udostępnia biblioteki Python, Java i Scala, które oferują pełną funkcjonalność tradycyjnych bibliotek NLP, takich jak spaCy, NLTK, Stanford CoreNLP i Open NLP. Usługa Spark NLP oferuje również funkcje, takie jak sprawdzanie pisowni, analiza tonacji i klasyfikacja dokumentów. Usługa Spark NLP usprawnia poprzednie działania, zapewniając najnowocześniejsze dokładność, szybkość i skalowalność.
Spark NLP jest zdecydowanie najszybszą biblioteką NLP typu open source. Ostatnie publiczne testy porównawcze pokazują, że platforma Spark NLP jest 38 i 80 razy szybsza niż spaCy, z porównywalną dokładnością trenowania modeli niestandardowych. Spark NLP to jedyna biblioteka typu open source, która może używać rozproszonego klastra Spark. Spark NLP to natywne rozszerzenie spark ML, które działa bezpośrednio na ramkach danych. W związku z tym przyspieszenie klastra powoduje kolejną kolejność wzrostu wydajności. Ponieważ każdy potok równoważenia obciążenia sieciowego platformy Spark jest potokiem spark ML, usługa Spark NLP jest dobrze odpowiednia do tworzenia ujednoliconych potoków nlp i uczenia maszynowego, takich jak klasyfikacja dokumentów, przewidywanie ryzyka i potoki poleceń.
Oprócz doskonałej wydajności usługa Spark NLP zapewnia również najnowocześniejsze dokładność dla rosnącej liczby zadań NLP. Zespół NLP platformy Spark regularnie odczytuje najnowsze istotne dokumenty akademickie i produkuje najdokładniejsze modele.
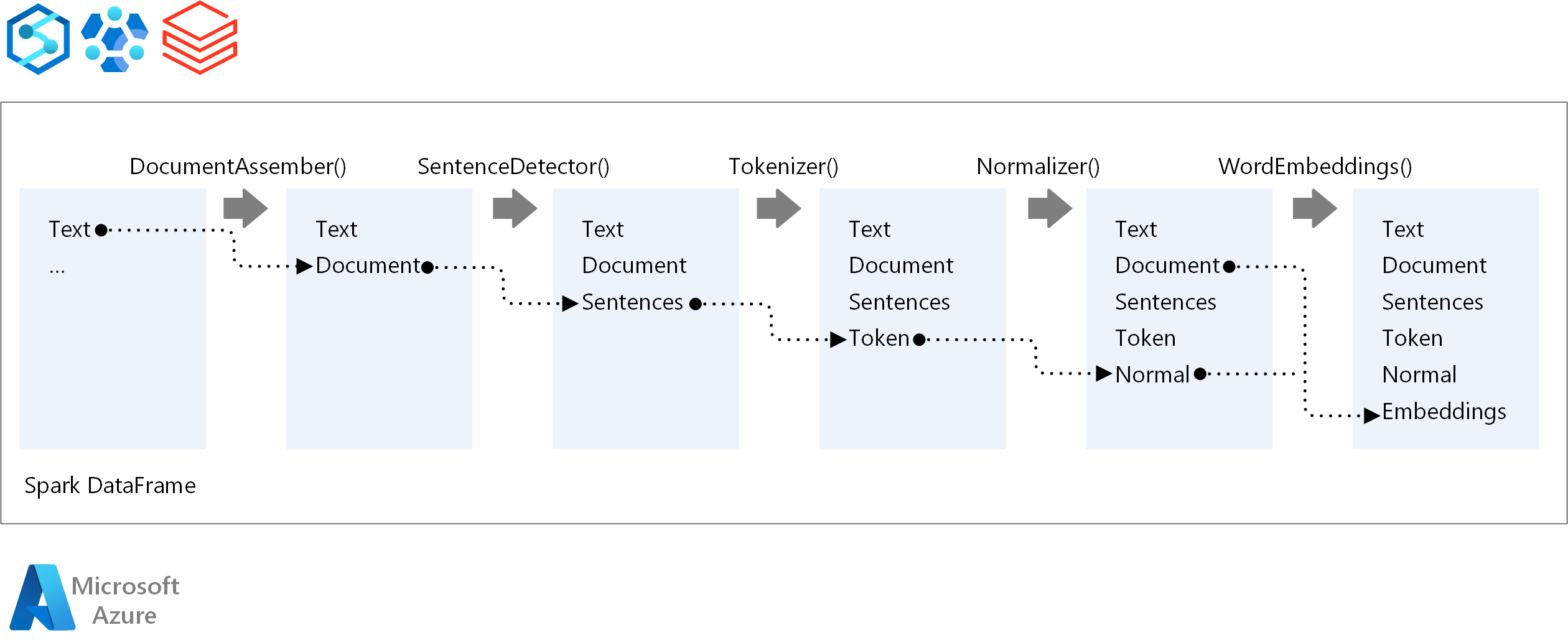
W przypadku kolejności wykonywania potoku NLP platforma Spark NLP jest zgodna z tą samą koncepcją programowania co tradycyjne modele uczenia maszynowego spark ML. Jednak usługa Spark NLP stosuje techniki NLP. Na poniższym diagramie przedstawiono podstawowe składniki potoku nlp platformy Spark.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Główny autor:
- Moritz Steller | Starszy architekt rozwiązań w chmurze
Następne kroki
Dokumentacja nlp platformy Spark:
Składniki platformy Azure:
Powiązane zasoby
- Technologia przetwarzania języka naturalnego
- Wzbogacanie sztucznej inteligencji przy użyciu obrazów i przetwarzania języka naturalnego w usłudze Azure Cognitive Search
- Analizowanie kanałów informacyjnych za pomocą analizy niemal w czasie rzeczywistym przy użyciu przetwarzania obrazów i języka naturalnego
- Sugerowanie tagów zawartości przy użyciu nlp przy użyciu uczenia głębokiego