Monitorowanie maszyn wirtualnych za pomocą usługi Azure Monitor: alerty
Ten artykuł jest częścią przewodnika Monitorowanie maszyn wirtualnych i ich obciążeń w usłudze Azure Monitor. Alerty w usłudze Azure Monitor aktywnie powiadamiają o interesujących danych i wzorcach w danych monitorowania. Nie ma wstępnie skonfigurowanych reguł alertów dla maszyn wirtualnych, ale możesz utworzyć własne na podstawie zebranych danych z agenta usługi Azure Monitor. W tym artykule przedstawiono pojęcia dotyczące alertów specyficzne dla maszyn wirtualnych i typowych reguł alertów używanych przez innych klientów usługi Azure Monitor.
W tym scenariuszu opisano sposób implementowania pełnego monitorowania środowiska platformy Azure i hybrydowej maszyny wirtualnej:
Aby rozpocząć monitorowanie pierwszej maszyny wirtualnej platformy Azure, zobacz Monitorowanie maszyn wirtualnych platformy Azure.
Aby szybko włączyć zalecany zestaw alertów, zobacz Włączanie zalecanych reguł alertów dla maszyny wirtualnej platformy Azure.
Ważne
Większość reguł alertów ma koszt zależny od typu reguły, liczby wymiarów, które zawiera i jak często jest uruchamiany. Przed utworzeniem reguł alertów zobacz sekcję Reguły alertów w cenniku usługi Azure Monitor.
Zbieranie danych
Reguły alertów sprawdzają dane, które zostały już zebrane w usłudze Azure Monitor. Przed utworzeniem reguły alertu należy upewnić się, że dane są zbierane dla określonego scenariusza. Zobacz Monitorowanie maszyn wirtualnych za pomocą usługi Azure Monitor: zbieranie danych, aby uzyskać wskazówki dotyczące konfigurowania zbierania danych dla różnych scenariuszy, w tym wszystkich reguł alertów w tym artykule.
Zalecane reguły alertów
Usługa Azure Monitor udostępnia zestaw zalecanych reguł alertów, które można szybko włączyć dla dowolnej maszyny wirtualnej platformy Azure. Te reguły są doskonałym punktem wyjścia do podstawowego monitorowania. Jednak samodzielnie nie zapewnią wystarczającego alertu dla większości implementacji przedsiębiorstwa z następujących powodów:
- Zalecane alerty dotyczą tylko maszyn wirtualnych platformy Azure, a nie maszyn hybrydowych.
- Zalecane alerty obejmują tylko metryki hosta, a nie metryki gościa lub dzienniki. Te metryki są przydatne do monitorowania kondycji samej maszyny. Zapewniają one jednak minimalny wgląd w obciążenia i aplikacje działające na maszynie.
- Zalecane alerty są skojarzone z poszczególnymi maszynami, które tworzą nadmierną liczbę reguł alertów. Zamiast polegać na tej metodzie dla każdej maszyny, zobacz Scaling alert rules for strategies on using a minimal number of alert rules for multiple machines (Skalowanie reguł alertów dla wielu maszyn).
Typy alertów
Najczęstszymi typami reguł alertów w usłudze Azure Monitor są alerty metryk i alerty przeszukiwania dzienników. Typ reguły alertu tworzonej dla określonego scenariusza zależy od tego, gdzie znajdują się dane, których dotyczy alert.
Mogą wystąpić przypadki, w których dane dla określonego scenariusza alertów są dostępne zarówno w metrykach, jak i dziennikach. Jeśli tak, musisz określić typ reguły do użycia. Możesz również mieć elastyczność w sposobie zbierania określonych danych i pozwolić decyzji o typie reguły alertu na decyzję dotyczącą metody zbierania danych.
Alerty dotyczące metryk
Typowe zastosowania alertów metryk:
- Alert, gdy określona metryka przekracza próg. Przykładem jest wysokie użycie procesora CPU maszyny.
Źródła danych dla alertów metryk:
- Metryki hosta dla maszyn wirtualnych platformy Azure, które są zbierane automatycznie
- Metryki zebrane przez agenta usługi Azure Monitor z systemu operacyjnego gościa
Alerty przeszukiwania dzienników
Typowe zastosowania alertów przeszukiwania dzienników:
- Alert po znalezieniu określonego zdarzenia lub wzorca zdarzeń z dziennika zdarzeń systemu Windows lub dziennika systemowego. Te reguły alertów zwykle mierzą wiersze tabeli zwracane z zapytania.
- Alert oparty na obliczeniu danych liczbowych na wielu maszynach. Te reguły alertów zwykle mierzą obliczenie kolumny liczbowej w wynikach zapytania.
Źródła danych dla alertów przeszukiwania dzienników:
- Wszystkie dane zebrane w obszarze roboczym usługi Log Analytics
Skalowanie reguł alertów
Ponieważ może istnieć wiele maszyn wirtualnych, które wymagają tego samego monitorowania, nie chcesz tworzyć poszczególnych reguł alertów dla każdego z nich. Chcesz również upewnić się, że istnieją różne strategie ograniczania liczby reguł alertów, którymi należy zarządzać, w zależności od typu reguły. Każda z tych strategii zależy od zrozumienia docelowego zasobu reguły alertu.
Reguły alertów metryk
Maszyny wirtualne obsługują wiele reguł alertów dotyczących metryk zasobów zgodnie z opisem w temacie Monitorowanie wielu zasobów. Ta funkcja umożliwia utworzenie pojedynczej reguły alertu dotyczącego metryk, która ma zastosowanie do wszystkich maszyn wirtualnych w grupie zasobów lub subskrypcji w tym samym regionie.
Zacznij od zalecanych alertów i utwórz odpowiednią regułę dla każdej z nich przy użyciu subskrypcji lub grupy zasobów jako zasobu docelowego. Jeśli masz maszyny w wielu regionach, musisz utworzyć zduplikowane reguły dla każdego regionu.
W miarę identyfikowania wymagań dotyczących większej liczby reguł alertów dotyczących metryk należy postępować zgodnie z tą samą strategią przy użyciu subskrypcji lub grupy zasobów co zasób docelowy:
- Zminimalizuj liczbę reguł alertów, którymi chcesz zarządzać.
- Upewnij się, że są one automatycznie stosowane do wszystkich nowych maszyn.
Reguły alertów przeszukiwania dzienników
Jeśli ustawisz zasób docelowy reguły alertu przeszukiwania dzienników na określoną maszynę, zapytania są ograniczone do danych skojarzonych z tą maszyną, co daje poszczególne alerty. To rozwiązanie wymaga oddzielnej reguły alertu dla każdej maszyny.
Jeśli ustawisz zasób docelowy reguły alertu przeszukiwania dzienników na obszar roboczy usługi Log Analytics, masz dostęp do wszystkich danych w tym obszarze roboczym. Z tego powodu można otrzymywać alerty dotyczące danych ze wszystkich maszyn w grupie roboczej z jedną regułą. Ten układ umożliwia utworzenie pojedynczego alertu dla wszystkich maszyn. Następnie można użyć wymiarów, aby utworzyć oddzielny alert dla każdej maszyny.
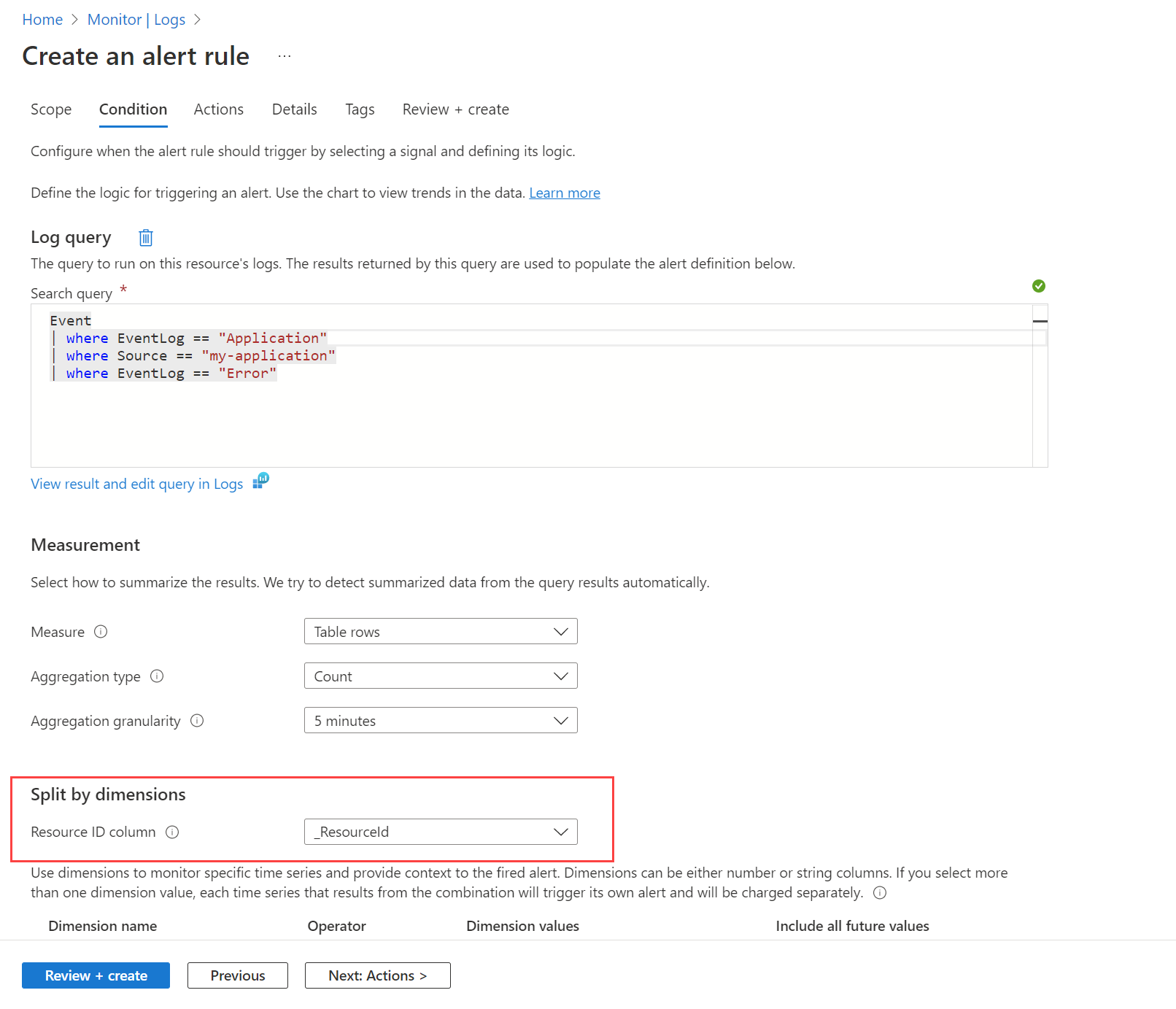
Na przykład możesz chcieć otrzymywać alerty po utworzeniu zdarzenia błędu w dzienniku zdarzeń systemu Windows przez dowolną maszynę. Najpierw należy utworzyć regułę zbierania danych zgodnie z opisem w temacie Zbieranie zdarzeń i liczników wydajności z maszyn wirtualnych za pomocą agenta usługi Azure Monitor w celu wysłania tych zdarzeń do Event tabeli w obszarze roboczym usługi Log Analytics. Następnie utworzysz regułę alertu, która wykonuje zapytania względem tej tabeli przy użyciu obszaru roboczego jako zasobu docelowego i warunku pokazanego na poniższej ilustracji.
Zapytanie zwraca rekord dla wszystkich komunikatów o błędach na dowolnej maszynie. Użyj opcji Podziel według wymiarów i określ _ResourceId, aby poinstruować regułę o utworzeniu alertu dla każdej maszyny, jeśli w wynikach zostanie zwróconych wiele maszyn.
Wymiary
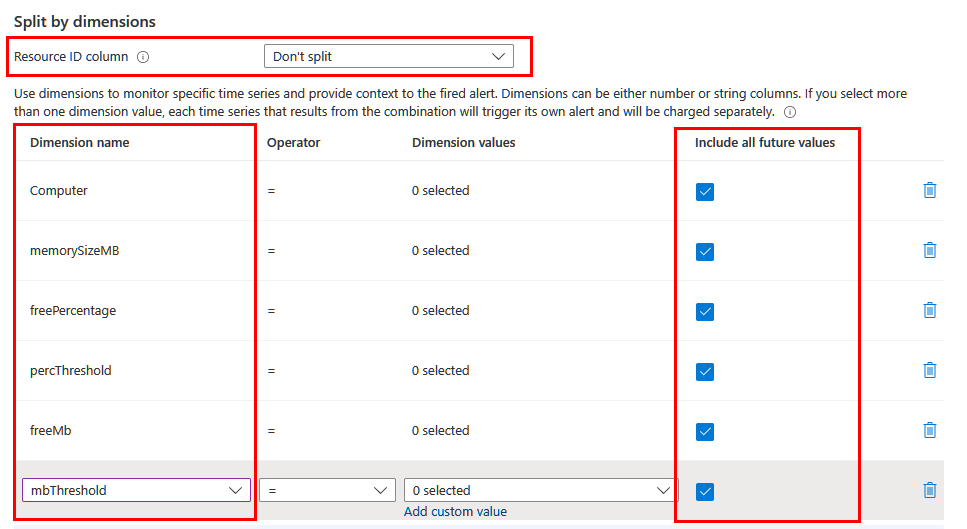
W zależności od informacji, które chcesz uwzględnić w alercie, może być konieczne podzielenie przy użyciu różnych wymiarów. W takim przypadku upewnij się, że wymagane wymiary są przewidywane w zapytaniu przy użyciu operatora projektu lub rozszerzenia . Ustaw pole kolumny Identyfikator zasobu na Nie podziel i uwzględnij wszystkie znaczące wymiary na liście. Upewnij się, że wybrano opcję Uwzględnij wszystkie przyszłe wartości , aby uwzględnić dowolną wartość zwróconą z zapytania.
Progi dynamiczne
Kolejną zaletą korzystania z reguł alertów przeszukiwania dzienników jest możliwość uwzględnienia złożonej logiki w zapytaniu w celu określenia wartości progowej. Próg można zakodować na stałe, zastosować go do wszystkich zasobów lub obliczyć dynamicznie na podstawie określonego pola lub wartości obliczeniowej. Próg jest stosowany do zasobów tylko zgodnie z określonymi warunkami. Można na przykład utworzyć alert na podstawie dostępnej pamięci, ale tylko dla maszyn z określoną ilością całkowitej pamięci.
Typowe reguły alertów
W poniższej sekcji wymieniono typowe reguły alertów dla maszyn wirtualnych w usłudze Azure Monitor. Szczegółowe informacje dotyczące alertów metryk i alertów przeszukiwania dzienników są udostępniane dla każdego z nich. Aby uzyskać wskazówki dotyczące typu alertu, zobacz Typy alertów. Jeśli nie znasz procesu tworzenia reguł alertów w usłudze Azure Monitor, zapoznaj się z instrukcjami tworzenia nowej reguły alertu.
Uwaga
Szczegółowe informacje na temat alertów wyszukiwania dzienników podanych w tym miejscu są używane przy użyciu danych zebranych przy użyciu Szczegółowe informacje maszyny wirtualnej, która udostępnia zestaw typowych liczników wydajności dla systemu operacyjnego klienta. Ta nazwa jest niezależna od typu systemu operacyjnego.
Maszyna niedostępna
Jednym z najczęstszych wymagań dotyczących monitorowania maszyny wirtualnej jest utworzenie alertu, jeśli przestanie działać. Najlepszą metodą jest utworzenie reguły alertu dotyczącego metryk w usłudze Azure Monitor przy użyciu metryki dostępności maszyny wirtualnej, która jest obecnie dostępna w publicznej wersji zapoznawczej. Aby zapoznać się z przewodnikiem po tej metryce, zobacz Tworzenie reguły alertu dotyczącego dostępności dla maszyny wirtualnej platformy Azure.
Zgodnie z opisem w temacie Scaling alert rules (Skalowanie reguł alertów) utwórz regułę alertu dotyczącego dostępności przy użyciu subskrypcji lub grupy zasobów jako zasobu docelowego. Reguła dotyczy wielu maszyn wirtualnych, w tym nowych maszyn utworzonych po regule alertu.
Puls agenta
Puls agenta jest nieco inny niż alert niedostępny maszyny, ponieważ korzysta z agenta usługi Azure Monitor do wysyłania pulsu. Puls agenta może otrzymywać alerty, jeśli maszyna jest uruchomiona, ale agent nie odpowiada.
Reguły alertów metryk
W każdym obszarze roboczym usługi Log Analytics znajduje się metryka o nazwie Puls . Każda maszyna wirtualna połączona z tym obszarem roboczym wysyła wartość metryki pulsu co minutę. Ponieważ komputer jest wymiarem metryki, można uruchomić alert, gdy dowolny komputer nie wyśle pulsu. Ustaw typ agregacji na Count (Liczba) i Wartość Threshold (Próg), aby dopasować poziom szczegółowości oceny.
Reguły alertów przeszukiwania dzienników
Alerty przeszukiwania dzienników używają tabeli Puls, która powinna mieć rekord pulsu co minutę z każdej maszyny.
Użyj reguły z następującym zapytaniem:
Heartbeat
| summarize TimeGenerated=max(TimeGenerated) by Computer, _ResourceId
| extend Duration = datetime_diff('minute',now(),TimeGenerated)
| summarize MinutesSinceLastHeartbeat = min(Duration) by Computer, bin(TimeGenerated,5m), _ResourceId
Alerty procesora CPU
W tej sekcji opisano alerty procesora CPU.
Reguły alertów metryk
| Obiekt docelowy | Metric |
|---|---|
| Gospodarz | Procentowe użycie procesora CPU (uwzględnione w zalecanych alertach) |
| Gość systemu Windows | \Processor Information(_Total)% czas procesora |
| Gość systemu Linux | procesor/usage_active |
Reguły alertów przeszukiwania dzienników
Wykorzystanie procesora CPU
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Processor" and Name == "UtilizationPercentage"
| summarize CPUPercentageAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Alerty dotyczące pamięci
W tej sekcji opisano alerty dotyczące pamięci.
Reguły alertów metryk
| Obiekt docelowy | Metric |
|---|---|
| Gospodarz | Dostępne bajty pamięci (wersja zapoznawcza) (uwzględnione w zalecanych alertach) |
| Gość systemu Windows | \Memory% zatwierdzonych bajtów w użyciu \Memory\Available Bytes |
| Gość systemu Linux | mem/dostępny mem/available_percent |
Reguły alertów przeszukiwania dzienników
Dostępna pamięć w MB
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| summarize AvailableMemoryInMBAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Dostępna pamięć w procentach
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| extend TotalMemory = toreal(todynamic(Tags)["vm.azm.ms/memorySizeMB"]) | extend AvailableMemoryPercentage = (toreal(Val) / TotalMemory) * 100.0
| summarize AvailableMemoryInPercentageAverage = avg(AvailableMemoryPercentage) by bin(TimeGenerated, 15m), Computer, _ResourceId
Alerty dotyczące dysków
W tej sekcji opisano alerty dotyczące dysków.
Reguły alertów metryk
| Obiekt docelowy | Metric |
|---|---|
| Gość systemu Windows | \Dysk logiczny (_Total)% wolnego miejsca \Dysk logiczny(_Total)\Wolne megabajty |
| Gość systemu Linux | dysk/wolny dysk/free_percent |
Reguły alertów przeszukiwania dzienników
Używany dysk logiczny — wszystkie dyski na każdym komputerze
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Używany dysk logiczny — poszczególne dyski
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Operacje we/wy na sekundę dysku logicznego
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "TransfersPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskIOPSAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Szybkość danych dysku logicznego
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "BytesPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskBytesPerSecondAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Alerty sieci
Reguły alertów metryk
| Obiekt docelowy | Metric |
|---|---|
| Gospodarz | Łączna liczba w sieci— łączna liczba wyprzedań sieci (uwzględniona w zalecanych alertach) |
| Gość systemu Windows | \Network Interface\Bytes Sent/sec \Dysk logiczny(_Total)\Wolne megabajty |
| Gość systemu Linux | dysk/wolny dysk/free_percent |
Reguły alertów przeszukiwania dzienników
Odebrane bajty interfejsów sieciowych — wszystkie interfejsy
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| summarize BytesReceivedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Odebrane bajty interfejsów sieciowych — poszczególne interfejsy
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesReceievedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Wysłane bajty interfejsów sieciowych — wszystkie interfejsy
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Wysłane bajty interfejsów sieciowych — poszczególne interfejsy
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Zdarzenia systemu Windows i Linux
Poniższy przykład tworzy alert po utworzeniu określonego zdarzenia systemu Windows. Używa reguły alertu pomiaru metryki, aby utworzyć oddzielny alert dla każdego komputera.
Utwórz regułę alertu dla określonego zdarzenia systemu Windows. W tym przykładzie pokazano zdarzenie w dzienniku aplikacji. Określ próg 0 i kolejne naruszenia większe niż 0.
Event | where EventLog == "Application" | where EventID == 123 | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)Utwórz regułę alertu dla zdarzeń syslog z określoną ważnością. W poniższym przykładzie przedstawiono zdarzenia autoryzacji błędów. Określ próg 0 i kolejne naruszenia większe niż 0.
Syslog | where Facility == "auth" | where SeverityLevel == "err" | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)
Niestandardowe liczniki wydajności
Utwórz alert dotyczący maksymalnej wartości licznika.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = max(CounterValue) by ComputerUtwórz alert o średniej wartości licznika.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = avg(CounterValue) by Computer
Następne kroki
Analizowanie danych monitorowania zebranych dla maszyn wirtualnych