Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Migrowanie wysoce wydajnych baz danych klasy Exadata do chmury staje się coraz bardziej konieczne dla klientów firmy Microsoft. Pakiety oprogramowania łańcucha dostaw zwykle ustawiają poprzeczkę wysoką ze względu na intensywne wymagania dotyczące operacji we/wy magazynu z mieszanym obciążeniem odczytu i zapisu sterowanym przez jeden węzeł obliczeniowy. Infrastruktura platformy Azure w połączeniu z usługą Azure NetApp Files jest w stanie zaspokoić potrzeby tego wysoce wymagającego obciążenia. W tym artykule przedstawiono przykład tego, jak to zapotrzebowanie zostało spełnione dla jednego klienta i jak platforma Azure może spełnić wymagania krytycznych obciążeń Oracle.
Wydajność oracle w skali przedsiębiorstwa
Podczas eksplorowania górnych limitów wydajności ważne jest rozpoznawanie i zmniejszanie wszelkich ograniczeń, które mogą fałszywie wypaczyć wyniki. Jeśli na przykład celem jest udowodnienie możliwości wydajności systemu magazynu, klient powinien być skonfigurowany tak, aby procesor CPU nie stał się czynnikiem ograniczającym przed osiągnięciem limitów wydajności magazynu. W tym celu testowanie zaczęło się od typu wystąpienia E104ids_v5, ponieważ ta maszyna wirtualna jest wyposażona nie tylko w interfejs sieciowy 100 Gb/s, ale z równie dużym (100 Gb/s) limitem ruchu wychodzącego.
Testowanie miało miejsce w dwóch fazach:
- Pierwsza faza koncentruje się na testowaniu przy użyciu obecnie standardowego narzędzia SLOB2 Kevina Clossona (Silly Little Oracle Benchmark) — wersja 2.5.4. Celem jest dążenie do jak największej liczby operacji we/wy oracle z jednej maszyny wirtualnej do wielu woluminów usługi Azure NetApp Files, a następnie skalowanie w poziomie przy użyciu większej liczby baz danych w celu zademonstrowania skalowania liniowego.
- Po przetestowaniu limitów skalowania nasze testy przerzuciły się na tańsze, ale niemal jako zdolne E96ds_v5 dla fazy testowania klienta przy użyciu rzeczywistego obciążenia aplikacji łańcucha dostaw i rzeczywistych danych.
SLOB2 — wydajność skalowania w górę
Na poniższych wykresach przedstawiono profil wydajności pojedynczego E104ids_v5 maszyny wirtualnej platformy Azure z pojedynczą bazą danych Oracle 19c dla ośmiu woluminów usługi Azure NetApp Files z ośmioma punktami końcowymi magazynu. Woluminy są rozłożone na trzy grupy dysków USŁUGI ASM: dane, dzienniki i archiwum. Do grupy dysków danych przydzielono pięć woluminów, dwa woluminy do grupy dysków dziennika i jeden wolumin do grupy dysków archiwum. Wszystkie wyniki przechwycone w tym artykule zostały zebrane przy użyciu produkcyjnych regionów platformy Azure i aktywnych usług produkcyjnych platformy Azure.
Aby wdrożyć rozwiązanie Oracle na maszynach wirtualnych platformy Azure przy użyciu wielu woluminów usługi Azure NetApp Files w wielu punktach końcowych magazynu, użyj grupy woluminów aplikacji dla programu Oracle.
Architektura pojedynczego hosta
Na poniższym diagramie przedstawiono architekturę, na którą przeprowadzono testowanie. Zanotuj bazę danych Oracle rozłożoną na wiele woluminów i punktów końcowych usługi Azure NetApp Files.

We/wy magazynu z jednym hostem
Na poniższym diagramie przedstawiono losowo wybrane obciążenie o 100% z współczynnikiem trafień buforu bazy danych wynoszącym około 8%. SloB2 mógł obsługiwać około 850 000 żądań we/wy na sekundę przy zachowaniu opóźnienia sekwencyjnego odczytu pliku bazy danych podrzędnego. W przypadku rozmiaru bloku bazy danych o rozmiarze 8K, który wynosi około 6800 mil/s przepływności magazynu.

Przepływność pojedynczego hosta
Na poniższym diagramie pokazano, że w przypadku obciążeń we/wy intensywnie korzystających z przepustowości, takich jak pełne skanowanie tabeli lub działania RMAN, usługa Azure NetApp Files może zapewnić pełną przepustowość samej maszyny wirtualnej E104ids_v5.

Uwaga
Ponieważ wystąpienie obliczeniowe ma teoretyczną maksymalną przepustowość, dodanie dodatkowych wyników współbieżności aplikacji powoduje tylko zwiększone opóźnienie po stronie klienta. Dzięki temu obciążenia SLOB2 przekraczają docelowy przedział czasu ukończenia, dlatego liczba wątków została ograniczona do sześciu.
Wydajność skalowania w poziomie SLOB2
Na poniższych wykresach przedstawiono profil wydajności trzech E104ids_v5 maszyn wirtualnych platformy Azure z pojedynczą bazą danych Oracle 19c, a każdy z własnym zestawem woluminów usługi Azure NetApp Files i identycznym układem grupy dysków usługi ASM zgodnie z opisem w sekcji Skalowanie wydajności w górę. Grafika pokazuje, że w przypadku usługi Azure NetApp Files z wieloma woluminami/wieloma punktami końcowymi wydajność można łatwo skalować w poziomie z spójnością i przewidywalnością.
Architektura wielu hostów
Na poniższym diagramie przedstawiono architekturę, na którą przeprowadzono testowanie. Zwróć uwagę na trzy bazy danych Oracle rozmieszczone w wielu woluminach i punktach końcowych usługi Azure NetApp Files. Punkty końcowe mogą być przeznaczone dla jednego hosta, jak pokazano w przypadku maszyny wirtualnej Oracle 1 lub współużytkowanej między hostami, jak pokazano w przypadku maszyn wirtualnych Oracle VM2 i Oracle VM 3.

We/Wy magazynu z wieloma hostami
Na poniższym diagramie przedstawiono losowo wybrane obciążenie o 100% z współczynnikiem trafień buforu bazy danych wynoszącym około 8%. SLOB2 mógł prowadzić około 850 000 żądań we/wy na sekundę we wszystkich trzech hostach indywidualnie. SloB2 był w stanie to osiągnąć podczas wykonywania równolegle do łącznie około 2500 000 żądań we/wy na sekundę, a każdy host nadal utrzymuje podmilisekundowe opóźnienie odczytu pliku bazy danych sekwencyjnego odczytu. W przypadku rozmiaru bloku bazy danych o rozmiarze 8K to około 20 000 MiB/s między trzema hostami.

Przepływność wielu hostów
Na poniższym diagramie pokazano, że w przypadku obciążeń sekwencyjnych usługa Azure NetApp Files może nadal dostarczać pełne możliwości przepustowości samej maszyny wirtualnej E104ids_v5 nawet wtedy, gdy jest skalowana na zewnątrz. SloB2 był w stanie prowadzić operacje we/wy w sumie ponad 30 000 MiB/s na trzech hostach podczas uruchamiania równolegle.

Wydajność w świecie rzeczywistym
Po przetestowaniu limitów skalowania za pomocą sloB2 testy zostały przeprowadzone przy użyciu zestawu aplikacji łańcucha dostaw w języku rzeczywistym względem oprogramowania Oracle w plikach Usługi Azure NetApp z doskonałymi wynikami. Następujące dane z raportu AWR (Automatic Workload Repository) oracle to wyróżnione spojrzenie na sposób wykonania określonego zadania krytycznego.
Ta baza danych ma znaczącą dodatkową liczbę operacji we/wy oprócz obciążenia aplikacji z powodu włączenia funkcji flashback i ma rozmiar bloku bazy danych o rozmiarze 16 tys. W sekcji profilu we/wy raportu AWR widać, że istnieje duży współczynnik zapisów w porównaniu z odczytami.
| - | Odczyt i zapis na sekundę | Odczyt na sekundę | Zapis na sekundę |
|---|---|---|---|
| Suma (MB) | 4,988.1 | 1,395.2 | 3,592.9 |
Pomimo zdarzenia oczekiwania sekwencyjnego odczytu pliku bazy danych pokazującego większe opóźnienie o 2,2 ms niż w testach SLOB2, ten klient odnotował piętnaście minut skrócenia czasu wykonywania zadania z bazy danych RAC w usłudze Exadata do pojedynczej bazy danych wystąpień na platformie Azure.
Ograniczenia zasobów platformy Azure
Wszystkie systemy ostatecznie osiągnęły ograniczenia zasobów, tradycyjnie znane jako dławiki. Obciążenia baz danych, szczególnie wymagające, takie jak pakiety aplikacji łańcucha dostaw, to jednostki intensywnie korzystające z zasobów. Znalezienie tych ograniczeń zasobów i ich praca jest niezbędna do pomyślnego wdrożenia. Ta sekcja zawiera informacje o różnych ograniczeniach, które mogą wystąpić w takim środowisku i sposobie ich działania. W każdej podsekcji należy oczekiwać, że poznasz zarówno najlepsze rozwiązania, jak i uzasadnienie.
Maszyny wirtualne
W tej sekcji szczegółowo przedstawiono kryteria, które należy wziąć pod uwagę podczas wybierania maszyn wirtualnych w celu uzyskania najlepszej wydajności, oraz uzasadnienie wyboru dokonanego na potrzeby testowania. Usługa Azure NetApp Files to usługa magazynu dołączonego do sieci (NAS), dlatego odpowiednie ustalanie rozmiaru przepustowości sieci ma kluczowe znaczenie dla optymalnej wydajności.
Mikroukłady
Pierwszym interesującym tematem jest wybór mikroukładu. Upewnij się, że dowolna wybrana jednostka SKU maszyny wirtualnej jest oparta na jednym mikroukładie ze względów spójności. Wariant intela maszyn wirtualnych E_v5 działa na trzeciej generacji Intel Xeon Platinum 8370C (Ice Lake). Wszystkie maszyny wirtualne w tej rodzinie są wyposażone w jeden interfejs sieciowy o przepustowości 100 Gb/s. Natomiast seria E_v3, wymieniona na przykład, jest oparta na czterech oddzielnych mikroukładach z różnymi przepustowościami sieci fizycznej. Cztery mikroukłady używane w rodzinie E_v3 (Broadwell, Skylake, Cascade Lake, Haswell) mają różne szybkości procesora, które wpływają na charakterystykę wydajności maszyny.
Zapoznaj się z dokumentacją usługi Azure Compute uważnie zwracając uwagę na opcje mikroukładu. Zapoznaj się również z najlepszymi rozwiązaniami dotyczącymi jednostek SKU maszyn wirtualnych platformy Azure dla usługi Azure NetApp Files. Wybranie maszyny wirtualnej z jednym mikroukładem jest preferowane w celu uzyskania najlepszej spójności.
Dostępna przepustowość sieci
Ważne jest, aby zrozumieć różnicę między dostępną przepustowością interfejsu sieciowego maszyny wirtualnej a mierzoną przepustowością zastosowaną względem tej samej przepustowości. Gdy dokumentacja usługi Azure Compute zwraca się do limitów przepustowości sieci, te limity są stosowane tylko w przypadku ruchu wychodzącego (zapisu). Ruch przychodzący (odczyt) nie jest mierzony i w związku z tym jest ograniczony tylko przez fizyczną przepustowość samej karty sieciowej. Przepustowość sieci większości maszyn wirtualnych przekracza limit ruchu wychodzącego stosowany względem maszyny.
Ponieważ woluminy usługi Azure NetApp Files są dołączone do sieci, limit ruchu wychodzącego można rozumieć jako stosowany względem zapisów, natomiast ruch przychodzący jest definiowany jako obciążenia odczytu i podobne do odczytu. Chociaż limit ruchu wychodzącego większości maszyn jest większy niż przepustowość sieci karty sieciowej, tego samego nie można powiedzieć dla E104_v5 używanych podczas testowania tego artykułu. E104_v5 ma kartę sieciową 100 Gb/s z limitem ruchu wychodzącego ustawionym na 100 Gb/s. Dla porównania, E96_v5, z karty sieciowej 100 Gb/s ma limit ruchu wychodzącego 35 Gb/s z ruchu przychodzącego bez pobierania na 100 Gb/s. W miarę zmniejszania rozmiaru maszyn wirtualnych limity ruchu wychodzącego zmniejszają się, ale ruch przychodzący pozostaje nieskrępowany przez logicznie nałożone limity.
Limity ruchu wychodzącego są dostępne dla całej maszyny wirtualnej i są stosowane jako takie dla wszystkich obciążeń opartych na sieci. W przypadku korzystania z funkcji Oracle Data Guard wszystkie operacje zapisu są dwukrotnie archiwizowane w dziennikach i muszą być uwzględniane w zagadnieniach dotyczących limitu ruchu wychodzącego. Dotyczy to również dziennika archiwum z wieloma miejscami docelowymi i RMAN, jeśli są używane. Podczas wybierania maszyn wirtualnych zapoznaj się z takimi narzędziami wiersza polecenia jak ethtool, które uwidacznia konfigurację karty sieciowej, ponieważ platforma Azure nie dokumentuje konfiguracji interfejsu sieciowego.
Współbieżność sieci
Maszyny wirtualne platformy Azure i woluminy usługi Azure NetApp Files są wyposażone w określoną przepustowość. Jak pokazano wcześniej, tak długo, jak maszyna wirtualna ma wystarczającą ilość miejsca pracy procesora CPU, obciążenie może teoretycznie wykorzystywać dostępną przepustowość — która mieści się w granicach zastosowanego limitu karty sieciowej i ruchu wychodzącego. W praktyce jednak ilość osiągalnej przepływności jest określana na współbieżność obciążenia w sieci, czyli liczbę przepływów sieciowych i punktów końcowych sieci.
Przeczytaj sekcję Limity przepływów sieciowych w dokumencie Przepustowość sieci maszyny wirtualnej, aby lepiej zrozumieć. Na wynos: więcej przepływów sieci łączących klienta z magazynem zapewnia większą wydajność.
Oracle obsługuje dwóch oddzielnych klientów NFS, Jądra NFS i Direct NFS (dNFS). System plików NFS jądra do późnego czasu obsługiwał pojedynczy przepływ sieci między dwoma punktami końcowymi (obliczenia — magazyn). Bezpośredni system plików NFS, tym bardziej wydajny z tych dwóch, obsługuje zmienną liczbę przepływów sieciowych — testy wykazały setki unikatowych połączeń na punkt końcowy - zwiększając lub malejąco w miarę zapotrzebowania na obciążenie. Ze względu na skalowanie przepływów sieci między dwoma punktami końcowymi system plików NFS bezpośrednich jest zdecydowanie preferowany w systemie plików NFS jądra i w związku z tym zalecaną konfiguracją. Grupa produktów Usługi Azure NetApp Files nie zaleca używania systemu plików NFS jądra z obciążeniami Oracle. Aby uzyskać więcej informacji, zapoznaj się z tematem Korzyści wynikające z używania usługi Azure NetApp Files z bazą danych Oracle Database.
Współbieżność wykonywania
Korzystanie z systemu plików NFS bezpośrednich, jeden mikroukład w celu zapewnienia spójności i zrozumienie ograniczeń przepustowości sieci zajmuje Cię tylko do tej pory. W końcu aplikacja napędza wydajność. Weryfikacje koncepcji przy użyciu sloB2 i weryfikacje koncepcji przy użyciu rzeczywistego zestawu aplikacji łańcucha dostaw względem rzeczywistych danych klientów były w stanie zwiększyć znaczną ilość przepływności tylko dlatego, że aplikacje działały w wysokim stopniu współbieżności; pierwsza z nich używa znacznej liczby wątków na schemat, z których korzysta wiele połączeń z wielu serwerów aplikacji. Krótko mówiąc, obciążenie dysków współbieżności, niska współbieżność — niska przepływność, wysoka przepływność — wysoka przepływność, tak długo, jak infrastruktura jest w miejscu, aby obsługiwać to samo.
Przyspieszona sieć
Przyspieszona sieć obsługuje wirtualizację we/wy z pojedynczym elementem głównym (SR-IOV) dla maszyny wirtualnej, co znacznie zwiększa wydajność sieci. Ta ścieżka o wysokiej wydajności pomija hosta na ścieżce danych, co zmniejsza opóźnienie, zakłócenia i użycie procesora w przypadku najbardziej wymagających obciążeń sieciowych na obsługiwanych typach maszyn wirtualnych. Podczas wdrażania maszyn wirtualnych za pomocą narzędzi do zarządzania konfiguracją, takich jak terraform lub wiersz polecenia, należy pamiętać, że przyspieszona sieć nie jest domyślnie włączona. Aby uzyskać optymalną wydajność, włącz przyspieszoną sieć. Pamiętaj, że przyspieszona sieć jest włączona lub wyłączona w interfejsie sieciowym przez interfejs sieciowy. Przyspieszona funkcja sieci jest funkcją, która może być włączona lub wyłączona dynamicznie.
Uwaga
Ten artykuł zawiera odwołania do terminu SLAVE, termin, którego firma Microsoft już nie używa. Po usunięciu tego terminu z oprogramowania usuniemy go również z artykułu.
Autorytatywne podejście do przyspieszonej sieci jest włączone dla karty sieciowej za pośrednictwem terminalu systemu Linux. Jeśli przyspieszona sieć jest włączona dla karty sieciowej, druga wirtualna karta sieciowa jest skojarzona z pierwszą kartą sieciową. Ta druga karta sieciowa jest konfigurowana przez system z włączoną flagą SLAVE . Jeśli nie ma karty sieciowej z flagą SLAVE , przyspieszona sieć nie jest włączona dla tego interfejsu.
W scenariuszu, w którym skonfigurowano wiele kart sieciowych, należy określić, który SLAVE interfejs jest skojarzony z kartą sieciową używaną do instalowania woluminu NFS. Dodawanie kart interfejsu sieciowego do maszyny wirtualnej nie ma wpływu na wydajność.
Użyj poniższego procesu, aby zidentyfikować mapowanie między skonfigurowanym interfejsem sieciowym a skojarzonym z nim interfejsem wirtualnym. Ten proces sprawdza, czy przyspieszona sieć jest włączona dla określonej karty sieciowej na maszynie z systemem Linux i wyświetla fizyczną szybkość ruchu przychodzącego, jaką może potencjalnie osiągnąć karta sieciowa.
-
ip aWykonaj polecenie:
-
/sys/class/net/Wyświetl katalog identyfikatora karty sieciowej, który weryfikujesz (eth0w przykładzie) igrepdla wyrazu niższego:ls /sys/class/net/eth0 | grep lower lower_eth1 -
ethtoolWykonaj polecenie względem urządzenia Ethernet zidentyfikowane jako niższe urządzenie w poprzednim kroku.
Maszyna wirtualna platformy Azure: limity przepustowości sieci i dysku
Podczas czytania dokumentacji limitów wydajności maszyn wirtualnych platformy Azure wymagany jest poziom wiedzy. Należy pamiętać o:
- Tymczasowe przepływność magazynu i liczby operacji we/wy na sekundę odnoszą się do możliwości wydajności efemerycznego magazynu lokalnego bezpośrednio dołączonego do maszyny wirtualnej.
- Przepływność dysku bez buforowania i numery we/wy odnoszą się konkretnie do usługi Azure Disk (Premium, Premium v2 i Ultra) i nie mają wpływu na magazyn dołączony do sieci, taki jak Azure NetApp Files.
- Dołączanie dodatkowych kart sieciowych do maszyny wirtualnej nie ma wpływu na limity wydajności ani możliwości wydajności maszyny wirtualnej (udokumentowane i przetestowane jako prawdziwe).
- Maksymalna przepustowość sieci odnosi się do limitów ruchu wychodzącego (czyli zapisów, gdy jest zaangażowany program Azure NetApp Files) stosowanych względem przepustowości sieci maszyny wirtualnej. Nie są stosowane żadne limity ruchu przychodzącego (czyli odczyty, gdy jest zaangażowana usługa Azure NetApp Files). Biorąc pod uwagę wystarczającą ilość procesora CPU, wystarczającą liczbę współbieżności sieci i wystarczająco bogate punkty końcowe, które maszyna wirtualna teoretycznie może napędzać ruch przychodzący do limitów karty sieciowej. Jak wspomniano w sekcji Dostępna przepustowość sieci, użyj takich narzędzi
ethtool, aby wyświetlić przepustowość karty sieciowej.
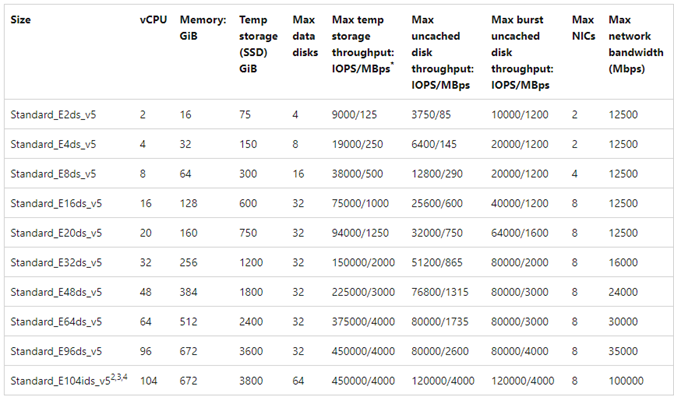
Przykładowy wykres jest wyświetlany do celów referencyjnych:
Azure NetApp Files
Usługa Azure NetApp Files usługi magazynu platformy Azure oferuje w pełni zarządzane rozwiązanie magazynu o wysokiej dostępności umożliwiające obsługę wymagających obciążeń Oracle wprowadzonych wcześniej.
Ponieważ limity wydajności magazynu skalowalnego w górę w bazie danych Oracle są dobrze zrozumiałe, ten artykuł celowo koncentruje się na wydajności magazynu skalowalnego w poziomie. Skalowanie wydajności magazynu oznacza zapewnienie pojedynczego wystąpienia Oracle dostępu do wielu woluminów usługi Azure NetApp Files, w których te woluminy są dystrybuowane za pośrednictwem wielu punktów końcowych magazynu.
Dzięki skalowaniu obciążenia bazy danych w wielu woluminach w taki sposób wydajność bazy danych nie jest wyższa zarówno od górnego limitu woluminu, jak i punktu końcowego. Gdy magazyn nie nakłada już ograniczeń wydajności, architektura maszyny wirtualnej (limity procesora CPU, karty sieciowej i ruchu wychodzącego maszyny wirtualnej) staje się punktem dławijącym, z jakim należy się zmagać. Jak wspomniano w sekcji maszyny wirtualnej, wybór E104ids_v5 i E96ds_v5 wystąpień zostały wykonane, mając na uwadze.
Niezależnie od tego, czy baza danych jest umieszczana na jednym dużym woluminie pojemności, czy rozłożona na wiele mniejszych woluminów, całkowity koszt finansowy jest taki sam. Zaletą dystrybucji operacji we/wy w wielu woluminach i punktach końcowych w przeciwieństwie do pojedynczego woluminu i punktu końcowego jest unikanie limitów przepustowości — możesz użyć całkowicie tego, za co płacisz.
Ważne
Aby wdrożyć przy użyciu usługi Azure NetApp Files w konfiguracji, skontaktuj się ze specjalistą multiple volume:multiple endpoint usługi Azure NetApp Files lub architektem rozwiązań w chmurze, aby uzyskać pomoc.
baza danych
Baza danych Oracle w wersji 19c jest bieżącą długoterminową wersją wydania firmy Oracle i używaną do tworzenia wszystkich wyników testów omówionych w tym dokumencie.
Aby uzyskać najlepszą wydajność, wszystkie woluminy bazy danych zostały zainstalowane przy użyciu bezpośredniego systemu plików NFS, system plików NFS jądra jest zalecany z powodu ograniczeń wydajności. Aby uzyskać porównanie wydajności między dwoma klientami, zapoznaj się z tematem Wydajność bazy danych Oracle na pojedynczych woluminach usługi Azure NetApp Files. Należy pamiętać, że zastosowano wszystkie odpowiednie poprawki systemu plików dNFS (identyfikator pomocy technicznej oracle 1495104), zgodnie z najlepszymi rozwiązaniami opisanymi w raporcie Oracle Databases on Microsoft Azure using Azure NetApp Files (Bazy danych Oracle database on Microsoft Azure using Azure NetApp Files ).
Chociaż oracle i Azure NetApp Files obsługują zarówno NFSv3, jak i NFSv4.1, ponieważ NFSv3 jest bardziej dojrzałym protokołem jest ogólnie postrzegany jako o największej stabilności i jest bardziej niezawodną opcją dla środowisk, które są wysoce wrażliwe na zakłócenia. Testowanie opisane w tym artykule zostało ukończone w systemie plików NFSv3.
Ważne
Niektóre z zalecanych poprawek, które dokumenty Oracle w identyfikatorze pomocy technicznej 1495104 mają kluczowe znaczenie dla utrzymania integralności danych podczas korzystania z systemu plików dNFS. Stosowanie takich poprawek jest zdecydowanie zalecane w środowiskach produkcyjnych.
Automatyczne zarządzanie magazynem (ASM) jest obsługiwane w przypadku woluminów NFS. Chociaż zwykle jest to związane z magazynem opartym na blokach, w którym usługa ASM zastępuje zarządzanie woluminami logicznymi (LVM) i system plików, usługa ASM odgrywa cenną rolę w scenariuszach NFS z wieloma woluminami i jest godna silnej uwagi. Jedną z takich zalet usługi ASM, dynamicznego dodawania i ponownego równoważenia w nowo dodanych woluminach i punktach końcowych systemu plików NFS, upraszcza zarządzanie umożliwiające rozszerzenie wydajności i pojemności. Mimo że usługa ASM sama w sobie nie zwiększa wydajności bazy danych, jej użycie pozwala uniknąć gorących plików i konieczność ręcznego utrzymania dystrybucji plików — korzyść jest łatwa do zobaczenia.
Konfiguracja usługi ASM za pośrednictwem systemu plików dNFS została użyta do wygenerowania wszystkich wyników testów omówionych w tym artykule. Na poniższym diagramie przedstawiono układ plików ASM w woluminach usługi Azure NetApp Files i alokację plików do grup dysków usługi ASM.

Istnieją pewne ograniczenia dotyczące korzystania z usługi ASM za pośrednictwem zainstalowanych woluminów systemu plików NFS usługi Azure NetApp Files, jeśli chodzi o migawki magazynu, które można przezwyciężyć z pewnymi zagadnieniami dotyczącymi architektury. Skontaktuj się ze specjalistą ds. usługi Azure NetApp Files lub architektem rozwiązań w chmurze, aby uzyskać szczegółowy przegląd tych zagadnień.
Syntetyczne narzędzia do testowania i możliwości dostrajania
W tej sekcji opisano architekturę testów, możliwości dostrajania i szczegóły konfiguracji w szczegółach. Chociaż poprzednia sekcja koncentruje się na przyczynach podejmowania decyzji dotyczących konfiguracji, ta sekcja koncentruje się konkretnie na "tym, co" decyzji dotyczących konfiguracji.
Wdrożenie automatyczne
- Maszyny wirtualne bazy danych są wdrażane przy użyciu skryptów powłoki bash dostępnych w usłudze GitHub.
- Układ i alokacja wielu woluminów i punktów końcowych usługi Azure NetApp Files są wykonywane ręcznie. Aby uzyskać pomoc, musisz pracować ze specjalistą ds. usługi Azure NetApp Files lub architektem rozwiązań w chmurze.
- Instalacja siatki, konfiguracja usługi ASM, tworzenie i konfiguracja bazy danych oraz środowisko SLOB2 na każdej maszynie jest konfigurowane przy użyciu rozwiązania Ansible pod kątem spójności.
- Równoległe wykonania testów SLOB2 na wielu hostach są również wykonywane przy użyciu rozwiązania Ansible w celu zapewnienia spójności i jednoczesnego wykonywania.
Konfiguracja maszyny wirtualnej
| Konfigurowanie | Wartość |
|---|---|
| region świadczenia platformy Azure | Europa Zachodnia |
| Jednostka SKU maszyny wirtualnej | E104ids_v5 |
| Liczba kart sieciowych | 1 UWAGA: Dodawanie wirtualnych kart sieciowych nie ma wpływu na liczbę systemów |
| Maksymalna przepustowość sieci wychodzącej (Mb/s) | 100 000 |
| Magazyn tymczasowy (SSD): GiB | 3,800 |
Konfiguracja systemu
Wszystkie wymagane ustawienia konfiguracji systemu Oracle dla wersji 19c zostały zaimplementowane zgodnie z dokumentacją oracle.
Następujące parametry zostały dodane do /etc/sysctl.conf pliku systemu Linux:
sunrpc.max_tcp_slot_table_entries: 128sunrpc.tcp_slot_table_entries = 128
Azure NetApp Files
Wszystkie woluminy usługi Azure NetApp Files zostały zainstalowane z następującymi opcjami instalacji systemu plików NFS.
nfs rw,hard,rsize=262144,wsize=262144,sec=sys,vers=3,tcp
Parametry bazy danych
| Parametry | Wartość |
|---|---|
db_cache_size |
2g |
large_pool_size |
2g |
pga_aggregate_target |
3g |
pga_aggregate_limit |
3g |
sga_target |
25g |
shared_io_pool_size |
500 m |
shared_pool_size |
5g |
db_files |
500 |
filesystemio_options |
SETALL |
job_queue_processes |
0 |
db_flash_cache_size |
0 |
_cursor_obsolete_threshold |
130 |
_db_block_prefetch_limit |
0 |
_db_block_prefetch_quota |
0 |
_db_file_noncontig_mblock_read_count |
0 |
Konfiguracja SLOB2
Wszystkie generowanie obciążeń na potrzeby testowania zostało ukończone przy użyciu narzędzia SLOB2 w wersji 2.5.4.
Czternaście schematów SLOB2 zostało załadowanych do standardowej przestrzeni tabel Oracle i wykonane względem, w połączeniu z wyświetlonymi ustawieniami pliku konfiguracji slob2 umieścić zestaw danych SLOB2 na 7 TiB. Poniższe ustawienia odzwierciedlają losowe wykonywanie odczytu dla sloB2. Parametr SCAN_PCT=0 konfiguracji został zmieniony na SCAN_PCT=100 podczas testowania sekwencyjnego.
UPDATE_PCT=0SCAN_PCT=0RUN_TIME=600SCALE=450GSCAN_TABLE_SZ=50GWORK_UNIT=32REDO_STRESS=LITETHREADS_PER_SCHEMA=1DATABASE_STATISTICS_TYPE=awr
W przypadku losowego testowania odczytu wykonano dziewięć wykonań SLOB2. Liczba wątków została zwiększona o sześć, a każda iteracja testowa zaczyna się od jednego.
W przypadku testów sekwencyjnych wykonano siedem wykonań SLOB2. Liczba wątków została zwiększona o dwa, a każda iteracja testowa zaczyna się od jednego. Liczba wątków została ograniczona do sześciu ze względu na osiągnięcie maksymalnej przepustowości sieci.
Metryki AWR
Wszystkie metryki wydajności zostały zgłoszone za pośrednictwem repozytorium automatycznego obciążenia Oracle (AWR). Poniżej przedstawiono metryki przedstawione w wynikach:
- Przepływność: suma średniej przepływności odczytu i przepływności zapisu z sekcji Profil ładowania AWR
- Średnia liczba żądań we/wy odczytu z sekcji Profil ładowania AWR
- Db file sekquential read wait average wait time from the AWR Foreground Wait Events (Sekwencyjny czas oczekiwania na odczyt w pliku db) w sekcji Zdarzenia oczekiwania na pierwszym planie usługi AWR
Migrowanie z wbudowanych specjalnie zaprojektowanych systemów do chmury
Oracle Exadata to zaprojektowana system — kombinacja sprzętu i oprogramowania, które jest uważane za najbardziej zoptymalizowane rozwiązanie do uruchamiania obciążeń Oracle. Mimo że chmura ma znaczne zalety w ogólnym schemacie świata technicznego, te wyspecjalizowane systemy mogą wyglądać niesamowicie atrakcyjnie dla tych, którzy przeczytali i wyświetlili optymalizacje, które firma Oracle zbudowała wokół konkretnych obciążeń.
Jeśli chodzi o uruchamianie programu Oracle w usłudze Exadata, wybrano kilka typowych powodów, dla których wybrano narzędzie Exadata:
- 1–2 duże obciążenia we/wy, które są naturalne w przypadku funkcji exadata i ponieważ te obciążenia wymagają znaczących funkcji inżynierów exadata, pozostałe bazy danych uruchomione wraz z nimi zostały skonsolidowane w exadata.
- Skomplikowane lub trudne obciążenia OLTP, które wymagają skalowania RAC i są trudne do zaprojektowania z zastrzeżonym sprzętem bez dogłębnej wiedzy na temat optymalizacji Oracle lub mogą być długu technicznego, którego nie można zoptymalizować.
- Nieużywane istniejące dane Exadata z różnymi obciążeniami: istnieje to albo z powodu poprzednich migracji, zakończenia życia w poprzedniej usłudze Exadata lub z powodu chęci pracy/testowania danych w firmie Exadata.
Ważne jest, aby każda migracja z systemu Exadata była zrozumiała z perspektywy obciążeń i jak prosta lub złożona może być migracja. Pomocnicza potrzeba jest zrozumienie przyczyny zakupu exadata z perspektywy stanu. Umiejętności exadata i RAC są na wyższym żądaniem i mogą napędzać zalecenie zakupu jednego przez uczestników projektu technicznego.
Ważne
Niezależnie od scenariusza, ogólne obciążenie bazy danych pochodzące z usługi Exadata powinno dotyczyć bardziej używanych funkcji własnościowych usługi Exadata, tym bardziej skomplikowane jest migracja i planowanie. Środowiska, które nie korzystają z zastrzeżonych funkcji exadata, mają możliwości prostszego procesu migracji i planowania.
Istnieje kilka narzędzi, których można użyć do oceny tych możliwości obciążenia:
- Automatyczne repozytorium obciążeń (AWR):
- Wszystkie bazy danych Exadata mają licencję na korzystanie z raportów AWR oraz połączonych funkcji wydajności i diagnostyki.
- Zawsze jest włączone i zbiera dane, których można użyć do wyświetlania historycznych informacji o obciążeniu i oceny użycia. Wartości szczytowe mogą ocenić wysokie użycie w systemie,
- Większe raporty AWR okna mogą ocenić ogólne obciążenie, zapewniając cenny wgląd w użycie funkcji i sposób efektywnego migrowania obciążenia do danych innych niż Exadata. Szczytowe raporty AWR w przeciwieństwie do najlepszych rozwiązań do optymalizacji wydajności i rozwiązywania problemów.
- Globalny raport AWR (RAC-Aware) dla exadata zawiera również sekcję specyficzną dla danych Exadata, która przechodzi do szczegółów określonego użycia funkcji Exadata i udostępnia cenne informacje o pamięci podręcznej flash informacji, rejestrowanie flash, operacje we/wy i inne użycie funkcji przez bazę danych i węzeł komórki.
Oddzielenie od danych Exadata
Podczas identyfikowania obciążeń Oracle Exadata do migracji do chmury należy wziąć pod uwagę następujące pytania i punkty danych:
- Czy obciążenie zużywa wiele funkcji exadata poza korzyściami sprzętowymi?
- Inteligentne skanowania
- Indeksy magazynu
- Pamięć podręczna flash
- Rejestrowanie flash
- Kompresja kolumnowa hybrydowa
- Czy obciążenie przy użyciu funkcji Exadata jest wydajnie odciążane? W pierwszym czasie zdarzeń pierwszego planu, jaki jest stosunek (ponad 10% czasu bazy danych) obciążenia przy użyciu:
- Skanowanie tabeli inteligentnej komórki (optymalne)
- Wieloblokowy odczyt fizyczny (mniej optymalny)
- Odczyt fizyczny pojedynczego bloku komórki (najmniej optymalny)
- Kompresja kolumnowa hybrydowa (HCC/EHCC): Jakie są skompresowane i nieskompresowane współczynniki:
- Czy wydatki na bazę danych przekraczają 10% czasu bazy danych na kompresowanie i dekompresowanie danych?
- Sprawdź wzrost wydajności predykatów przy użyciu kompresji w zapytaniach: czy wartość zyskała wartość w porównaniu z ilością zapisaną przy kompresji?
- Fizyczne we/wy komórki: sprawdź podane oszczędności:
- kwota skierowana do węzła bazy danych w celu zrównoważenia procesora CPU.
- identyfikowanie liczby bajtów zwracanych przez skanowanie inteligentne. Te wartości można odjąć w operacji we/wy dla procentu operacji odczytu fizycznego pojedynczego bloku komórki po przeprowadzeniu migracji poza dane Exadata.
- Zwróć uwagę na liczbę odczytów logicznych z pamięci podręcznej. Ustal, czy pamięć podręczna flash będzie wymagana w rozwiązaniu IaaS w chmurze dla obciążenia.
- Porównaj fizyczne bajty odczytu i zapisu z łączną ilością wykonaną w pamięci podręcznej. Czy można podnieść pamięć w celu wyeliminowania wymagań dotyczących odczytu fizycznego (niektóre z nich mogą zmniejszyć dół SGA w celu wymuszenia odciążania danych Exadata)?
- W obszarze Statystyka systemu zidentyfikuj, na jakie obiekty mają wpływ statystyki. W przypadku dostrajania kodu SQL dalsze indeksowanie, partycjonowanie lub inne dostrajanie fizyczne może znacznie zoptymalizować obciążenie.
- Sprawdź parametry inicjowania pod kątem parametrów podkreślenia (_) lub przestarzałych, które powinny być uzasadnione z powodu wpływu na poziom bazy danych, który może powodować wydajność.
Konfiguracja serwera Exadata
W programie Oracle w wersji 12.2 lub nowszej dodatek specyficzny dla usługi Exadata zostanie uwzględniony w raporcie globalnym AWR. Ten raport zawiera sekcje, które zapewniają wyjątkową wartość migracji z usługi Exadata.
Szczegóły wersji i systemu exadata
Szczegóły alertów węzła komórki
Dyski nieliniowe exadata
Dane odstają dla wszystkich statystyk systemu operacyjnego Exadata
Żółty/różowy: Niepokój. Funkcja Exadata nie działa optymalnie.
Czerwony: wydajność exadata ma znaczący wpływ na wydajność.
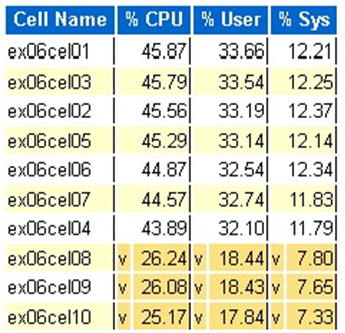
Statystyka procesora CPU systemu operacyjnego Exadata: najważniejsze komórki
- Te statystyki są zbierane przez system operacyjny w komórkach i nie są ograniczone do tej bazy danych lub wystąpień
- A
vi ciemnożółte tło wskazują wartość odstający poniżej niskiego zakresu - A
^i jasnożółte tło wskazują wartość odstający powyżej wysokiego zakresu - Górne komórki według procentowego procesora CPU są wyświetlane i są w kolejności malejącej procentowej procesora CPU
- Średnia: 39,34% procesora CPU, 28,57% użytkownik, 10,77% sys
Odczyty bloków fizycznych z pojedynczą komórką
Użycie pamięci podręcznej flash
Tymczasowe we/wy
Wydajność pamięci podręcznej kolumnowej
Wierzchołka bazy danych według przepływności operacji we/wy
Chociaż można przeprowadzić oceny ustalania rozmiaru, istnieją pewne pytania dotyczące średnich i symulowanych szczytów wbudowanych w te wartości dla dużych obciążeń. Ta sekcja, znaleziona na końcu raportu AWR, jest wyjątkowo cenna, ponieważ pokazuje zarówno średnie użycie pamięci flash, jak i dysku najlepszych 10 baz danych w usłudze Exadata. Chociaż wiele z nich może zakładać, że chce mieć rozmiar baz danych pod kątem szczytowej wydajności w chmurze, nie ma to sensu w przypadku większości wdrożeń (ponad 95% znajduje się w średnim zakresie; przy symulowanym szczytzie obliczonym w poziomie średni zakres jest większy niż 98%). Ważne jest, aby płacić za to, co jest potrzebne, nawet w przypadku obciążeń najwyższego zapotrzebowania firmy Oracle i inspekcji najważniejszych baz danych według przepływności operacji we/wy może być wyrozumianie w celu zrozumienia potrzeb związanych z zasobami bazy danych.
Odpowiedni rozmiar Oracle przy użyciu AWR w usłudze Exadata
Podczas planowania pojemności dla systemów lokalnych jest to naturalne, że na sprzęcie wbudowane są znaczne nakłady pracy. Nadmierna aprowizacja sprzętu musi obsługiwać obciążenie Oracle przez kilka lat, niezależnie od dodatków obciążeń ze względu na wzrost danych, zmiany kodu lub uaktualnienia.
Jedną z zalet chmury jest skalowanie zasobów na hoście maszyny wirtualnej, a magazyn może być wykonywany w miarę wzrostu zapotrzebowania. Pomaga to zaoszczędzić koszty chmury i koszty licencjonowania, które są dołączone do użycia procesora (istotne w programie Oracle).
Ustalanie rozmiaru odpowiedniego polega na usunięciu sprzętu z tradycyjnej migracji metodą "lift and shift" i użyciu informacji o obciążeniu dostarczonych przez automatyczne repozytorium obciążeń (AWR) firmy Oracle w celu podniesienia i przeniesienia obciążenia do zasobów obliczeniowych i magazynu specjalnie zaprojektowanych w celu obsługi go w chmurze wybranego klienta. Odpowiedni proces określania rozmiaru gwarantuje, że architektura w przyszłości usunie dług techniczny infrastruktury, nadmiarowość architektury, która wystąpi, jeśli duplikowanie systemu lokalnego zostało zreplikowane do chmury i implementuje usługi w chmurze, gdy jest to możliwe.
Eksperci z dziedziny Microsoft Oracle oszacowali, że ponad 80% baz danych Oracle jest nadmiernie zaaprowizowanych i korzysta z tych samych kosztów lub oszczędności związanych z przejściem do chmury, jeśli upłynął odpowiedni czas na obciążenie bazy danych Oracle przed migracją do chmury. Ta ocena wymaga, aby specjaliści ds. baz danych w zespole zmienili swój sposób myślenia na temat sposobu, w jaki mogli oni przeprowadzić planowanie pojemności w przeszłości, ale warto zainwestować uczestników projektu w chmurę i strategię chmury firmy.
Następne kroki
- Uruchamianie najbardziej wymagających obciążeń Oracle na platformie Azure bez poświęcania wydajności lub skalowalności
- Architektury rozwiązań korzystające z usługi Azure NetApp Files — Oracle
- Projektowanie i implementowanie bazy danych Oracle na platformie Azure
- Narzędzie szacowania rozmiaru obciążeń Oracle do maszyn wirtualnych IaaS platformy Azure
- Architektury referencyjne dla wersji Oracle Database Enterprise Edition na platformie Azure
- Omówienie grup woluminów aplikacji usługi Azure NetApp Files dla platformy SAP HANA