Architektury dla wersji Oracle Database Enterprise Edition na platformie Azure
Dotyczy: ✔️ maszyny wirtualne z systemem Linux
Platforma Azure jest domem dla wszystkich obciążeń Oracle, w tym obciążeń, które muszą nadal działać optymalnie na platformie Azure za pomocą rozwiązania Oracle. Jeśli masz pakiet diagnostyczny Oracle lub automatyczne repozytorium obciążeń (AWR), możesz zebrać dane dotyczące obciążeń. Te dane służą do oceny obciążenia Oracle, rozmiaru zasobów i migrowania obciążenia na platformę Azure. Różne metryki udostępniane przez firmę Oracle w tych raportach mogą zapewnić zrozumienie wydajności aplikacji i użycia platformy.
Ten artykuł ułatwia przygotowanie obciążenia Oracle do uruchomienia na platformie Azure i zapoznanie się z najlepszymi rozwiązaniami architektury w celu zapewnienia optymalnej wydajności chmury. Dane udostępniane przez firmę Oracle w pliku Statspack, a tym bardziej w malejącym, AWR, pomagają w opracowywaniu jasnych oczekiwań. Te oczekiwania obejmują limity dostrajania fizycznego dzięki architekturze, zalety dostrajania logicznego kodu bazy danych oraz ogólny projekt bazy danych.
Różnice między dwoma środowiskami
Podczas migracji aplikacji lokalnych na platformę Azure należy pamiętać o kilku ważnych różnicach między dwoma środowiskami.
Jedną z ważnych różnic jest to, że w implementacji platformy Azure zasoby, takie jak maszyny wirtualne, dyski i sieci wirtualne, są współużytkowane przez innych klientów. Ponadto zasoby mogą być ograniczane na podstawie wymagań. Zamiast skupiać się na unikaniu awarii, platforma Azure koncentruje się bardziej na przetrwaniu awarii. Pierwsze podejście próbuje zwiększyć średni czas między awariami (MTBF) a drugim próbuje skrócić średni czas odzyskiwania (MTTR).
W poniższej tabeli wymieniono niektóre różnice między implementacją lokalną a implementacją platformy Azure bazy danych Oracle.
| Implementacja lokalna | Implementacja platformy Azure | |
|---|---|---|
| Sieć | SIEĆ LAN/sieć WAN | Sieci zdefiniowane programowo (sieci SDN) |
| Grupa zabezpieczeń | Narzędzia ograniczeń adresów IP/portów | Sieciowa grupa zabezpieczeń |
| Sprężystość | MTBF | MTTR |
| Planowana konserwacja | Poprawianie/uaktualnianie | Zestawy dostępności z poprawkami/uaktualnieniami zarządzanymi przez platformę Azure |
| Zasób | Dedykowane | Udostępnione innym klientom |
| Regiony | Centra danych | Pary regionów |
| Storage | Dyski san/fizyczne | Magazyn zarządzany przez platformę Azure |
| Skaluj | Skalowanie w pionie | Skalowanie w poziomie |
Wymagania
Przed rozpoczęciem migracji należy wziąć pod uwagę następujące wymagania:
- Określanie rzeczywistego użycia procesora CPU. Licencje oracle według rdzeni, co oznacza, że ustalanie rozmiaru procesorów wirtualnych może być niezbędne, aby pomóc w zmniejszeniu kosztów.
- Określ rozmiar bazy danych, magazyn kopii zapasowych i szybkość wzrostu.
- Określ wymagania we/wy, które można oszacować na podstawie pakietu Oracle Statspack i raportów AWR. Możesz również oszacować wymagania z narzędzi do monitorowania magazynu dostępnych w systemie operacyjnym.
Opcje konfiguracji
Dobrym pomysłem jest wygenerowanie raportu AWR i uzyskanie z niego pewnych metryk, aby ułatwić podejmowanie decyzji dotyczących konfiguracji. Następnie istnieją cztery potencjalne obszary, które można dostosować, aby zwiększyć wydajność w środowisku platformy Azure:
- Rozmiar maszyny wirtualnej
- Przepływność sieci
- Typy dysków i konfiguracje
- Ustawienia pamięci podręcznej dysku
Generowanie raportu AWR
Jeśli masz istniejącą bazę danych Oracle Enterprise Edition i planujesz migrację na platformę Azure, masz kilka opcji. Jeśli masz pakiet diagnostyczny dla wystąpień Oracle, możesz uruchomić raport Oracle AWR, aby uzyskać metryki, takie jak liczba operacji we/wy na sekundę, mb/s i giBs. W przypadku tych baz danych bez licencji pakietu diagnostycznego lub bazy danych Oracle Standard Edition można zebrać te same ważne metryki z raportem Statspack po zebraniu ręcznych migawek. Główne różnice między tymi dwiema metodami raportowania polegają na tym, że usługa AWR jest automatycznie zbierana i udostępnia więcej informacji o bazie danych niż statspack.
Rozważ uruchomienie raportu AWR zarówno podczas regularnych, jak i szczytowych obciążeń, aby można było porównać. Aby zebrać dokładniejsze obciążenie, rozważ raport okna rozszerzonego o jeden tydzień, w przeciwieństwie do jednego dnia. Funkcja AWR udostępnia średnie w ramach obliczeń w raporcie. Domyślnie repozytorium AWR zachowuje osiem dni danych i tworzy migawki w interwałach godzinowych.
W przypadku migracji centrum danych należy zebrać raporty dotyczące ustalania rozmiaru w systemach produkcyjnych. Szacowanie pozostałych kopii bazy danych używanych do testowania, testowania i programowania użytkowników według wartości procentowych. Na przykład szacuje się, że 50 procent rozmiaru produkcji.
Aby uruchomić raport AWR z wiersza polecenia, użyj następującego polecenia:
sqlplus / as sysdba
@$ORACLE_HOME/rdbms/admin/awrrpt.sql;
Kluczowe metryki
Raport wyświetli monit o podanie następujących informacji:
- Typ raportu: HTML lub TEXT. Typ HTML zawiera więcej informacji.
- Liczba dni wyświetlania migawek. Na przykład w przypadku interwałów jednogodzinnych raport jednotygodniowy generuje 168 identyfikatorów migawek.
- Początek
SnapshotIDokna raportu. - Zakończenie
SnapshotIDokna raportu. - Nazwa raportu tworzonego przez skrypt AWR.
Jeśli używasz raportu AWR w rzeczywistym klastrze aplikacji (RAC), raport wiersza polecenia jest plikiem awrgrpt.sql , a nie awrrpt.sql. Raport g tworzy raport dla wszystkich węzłów w bazie danych RAC w jednym raporcie. Ten raport eliminuje konieczność uruchamiania jednego raportu w każdym węźle RAC.
Z raportu AWR można uzyskać następujące metryki:
- Nazwa bazy danych, nazwa wystąpienia i nazwa hosta
- Wersja bazy danych pod kątem możliwości obsługi firmy Oracle
- Procesor/rdzenie
- SGA/PGA i doradcy, aby poinformować Cię, czy nie są zaniżone
- Łączna ilość pamięci w GB
- Procent zajętości procesora CPU
- Procesory DB
- We/Wy (odczyt/zapis)
- Mb/s (odczyt/zapis)
- Przepływność sieci
- Szybkość opóźnienia sieci (niska/wysoka)
- Najważniejsze zdarzenia oczekiwania
- Ustawienia parametrów dla bazy danych
- Niezależnie od tego, czy baza danych jest RAC, Exadata, czy też korzysta z zaawansowanych funkcji lub konfiguracji
Rozmiar maszyny wirtualnej
Poniżej przedstawiono kilka kroków, które można wykonać, aby skonfigurować rozmiar maszyny wirtualnej w celu uzyskania optymalnej wydajności.
Szacowanie rozmiaru maszyny wirtualnej na podstawie użycia procesora CPU, pamięci i operacji we/wy z raportu AWR
Spójrz na pięć najważniejszych zdarzeń pierwszego planu, które wskazują, gdzie znajdują się wąskie gardła systemu. Na przykład na poniższym diagramie synchronizacja plików dziennika znajduje się u góry. Wskazuje liczbę oczekiwań, które są wymagane przed zapisem buforu dziennika do pliku dziennika ponownego wykonania. Te wyniki wskazują, że wymagana jest lepsza wydajność magazynu lub dysków. Ponadto na diagramie przedstawiono również liczbę rdzeni procesora i ilość pamięci.
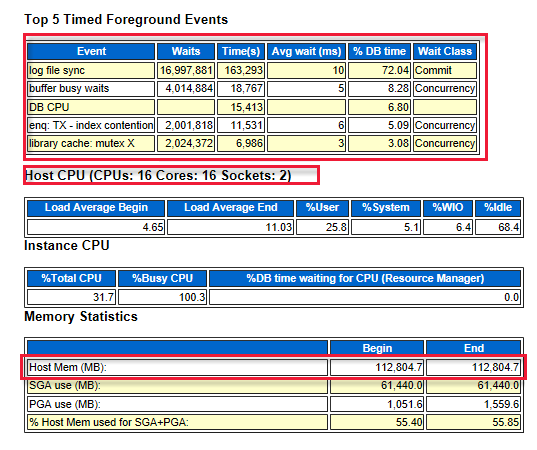
Na poniższym diagramie przedstawiono łączną liczbę operacji we/wy odczytu i zapisu. W czasie raportu zapisano 59 GB i 247,3 GB.

Wybieranie maszyny wirtualnej
Na podstawie informacji zebranych z raportu AWR następnym krokiem jest wybranie maszyny wirtualnej o podobnym rozmiarze, która spełnia Twoje wymagania. Aby uzyskać więcej informacji na temat dostępnych maszyn wirtualnych, zobacz Rozmiary maszyn wirtualnych zoptymalizowane pod kątem pamięci.
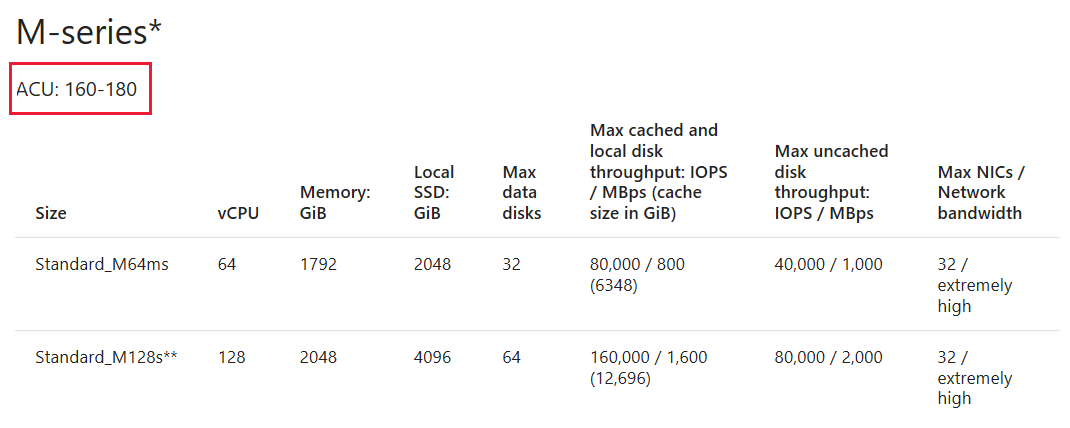
Dostrajanie rozmiaru maszyny wirtualnej przy użyciu podobnej serii maszyn wirtualnych na podstawie usługi ACU
Po wybraniu maszyny wirtualnej zwróć uwagę na jednostkę obliczeniową platformy Azure (ACU) dla maszyny wirtualnej. Możesz wybrać inną maszynę wirtualną na podstawie wartości ACU, która lepiej odpowiada Twoim wymaganiom. Aby uzyskać więcej informacji, zobacz Jednostka obliczeniowa platformy Azure.
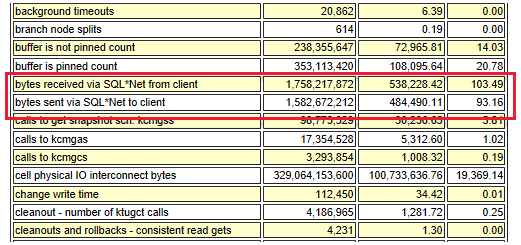
Przepływność sieci
Na poniższym diagramie przedstawiono relację między przepływnością a operacją we/wy na sekundę:

Łączna przepływność sieci jest szacowana na podstawie następujących informacji:
- SQL*Ruch sieciowy
- Liczba serwerów (strumień wychodzący, taki jak Oracle Data Guard), liczba mb/s
- Inne czynniki, takie jak replikacja aplikacji
W zależności od wymagań dotyczących przepustowości sieci istnieją różne typy bram do wyboru. Te typy obejmują podstawowe, VpnGw i Azure ExpressRoute. Aby uzyskać więcej informacji, zobacz Cennik usługi VPN Gateway.
Zalecenia
- Opóźnienie sieci jest wyższe w porównaniu z wdrożeniem lokalnym. Zmniejszenie liczby rund sieciowych może znacznie poprawić wydajność.
- Aby zmniejszyć liczbę rund, skonsoliduj aplikacje, które mają wysokie transakcje lub czatty aplikacje na tej samej maszynie wirtualnej.
- Używaj maszyn wirtualnych z przyspieszoną siecią, aby uzyskać lepszą wydajność sieci.
- W przypadku niektórych dystrybucji systemu Linux rozważ włączenie obsługi trim/UNMAP.
- Zainstaluj program Oracle Enterprise Manager na oddzielnej maszynie wirtualnej.
- Ogromne strony nie są domyślnie włączone w systemie Linux. Rozważ włączenie ogromnych stron i ustawienie
use_large_pages = ONLYbazy danych Oracle DB. Takie podejście może pomóc zwiększyć wydajność. Aby uzyskać więcej informacji, zobacz USE_LARGE_PAGES.
Typy dysków i konfiguracje
Poniżej przedstawiono kilka wskazówek, które należy wziąć pod uwagę podczas rozważania dysków.
Domyślne dyski systemu operacyjnego: te typy dysków oferują trwałe dane i buforowanie. Są one zoptymalizowane pod kątem dostępu do systemu operacyjnego podczas uruchamiania i nie są przeznaczone dla obciążeń transakcyjnych lub magazynów danych (analitycznych).
Dyski zarządzane: platforma Azure zarządza kontami magazynu używanymi na potrzeby dysków maszyn wirtualnych. Należy określić typ dysku i rozmiar potrzebnego dysku. Typ jest najczęściej premium (SSD) dla obciążeń Oracle. Platforma Azure tworzy dysk i zarządza nim. Dysk zarządzany SSD w warstwie Premium jest dostępny tylko dla serii maszyn wirtualnych zoptymalizowanych pod kątem pamięci i zaprojektowanych. Po wybraniu określonego rozmiaru maszyny wirtualnej menu zawiera tylko dostępne jednostki SKU magazynu w warstwie Premium, które są oparte na tym rozmiarze maszyny wirtualnej.


Po skonfigurowaniu magazynu na maszynie wirtualnej warto przetestować dyski przed utworzeniem bazy danych. Znajomość szybkości we/wy pod względem opóźnienia i przepływności może pomóc określić, czy maszyny wirtualne obsługują oczekiwaną przepływność z docelowymi opóźnieniami. Istnieje kilka narzędzi do testowania obciążenia aplikacji, takich jak Oracle Orion, Sysbench, SLOB i Fio.
Uruchom ponownie test obciążeniowy po wdrożeniu bazy danych Oracle. Rozpocznij regularne i szczytowe obciążenia, a wyniki pokazują punkt odniesienia środowiska. Bądź realistyczny w teście obciążenia. Nie ma sensu uruchamiać obciążenia, które nie przypomina działania na maszynie wirtualnej w rzeczywistości.
Ponieważ Oracle może być bazą danych intensywnie korzystającą z operacji we/wy, ważne jest, aby rozmiar magazynu był oparty na szybkości operacji we/wy, a nie na rozmiar magazynu. Jeśli na przykład wymagana wartość operacji we/wy na sekundę wynosi 5000, ale potrzebujesz tylko 200 GB, nadal możesz uzyskać dysk premium klasy P30, mimo że jest dostarczany z ponad 200 GB miejsca do magazynowania.
Szybkość operacji we/wy na sekundę można uzyskać z raportu AWR. Dziennik ponownej instalacji, odczyty fizyczne i szybkość zapisu określają szybkość operacji we/wy na sekundę. Zawsze sprawdź, czy wybrana seria maszyn wirtualnych ma możliwość obsługi zapotrzebowania we/wy obciążenia. Jeśli maszyna wirtualna ma niższy limit operacji we/wy niż magazyn, maszyna wirtualna ustawia maksymalny limit.
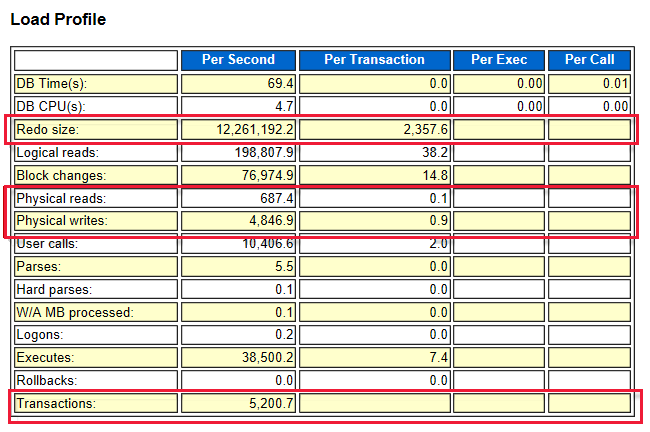
Na przykład rozmiar ponownego użycia wynosi 12 200 000 bajtów na sekundę, co jest równe 11,63 MB/s. Wartość operacji we/wy na sekundę wynosi 12 200 000 / 2358 = 5174.
Po zapoznaniu się z wymaganiami we/wy można wybrać kombinację dysków, które najlepiej nadają się do spełnienia tych wymagań.
Zalecenia dotyczące typu dysku
- W przypadku przestrzeni tabel danych rozłóż obciążenie we/wy na kilka dysków przy użyciu magazynu zarządzanego lub automatycznego zarządzania magazynem (ASM, Oracle Automatic Storage Management).
- Użyj zaawansowanej kompresji Oracle, aby zmniejszyć liczbę operacji we/wy zarówno dla danych, jak i indeksów.
- Rozdziel ponownie dzienniki, tymczasowe i cofnij przestrzenie tabel na oddzielnych dyskach danych.
- Nie umieszczaj żadnych plików aplikacji na domyślnych dyskach systemu operacyjnego. Te dyski nie są zoptymalizowane pod kątem szybkich czasów rozruchu maszyny wirtualnej i mogą nie zapewnić dobrej wydajności aplikacji.
- W przypadku korzystania z maszyn wirtualnych serii M w magazynie w warstwie Premium włącz akcelerator zapisu na dysku dzienników ponowień.
- Rozważ przeniesienie dzienników ponownego użycia z dużym opóźnieniem do dysku w warstwie Ultra.
Ustawienia pamięci podręcznej dysku
Chociaż istnieją trzy opcje buforowania hostów, buforowanie tylko do odczytu jest zalecane w przypadku obciążenia bazy danych Oracle. Odczyt/zapis może wprowadzić znaczące luki w zabezpieczeniach w pliku danych, ponieważ celem zapisu bazy danych jest zarejestrowanie go w pliku danych, a nie buforowanie informacji. W przypadku tylko do odczytu wszystkie żądania są buforowane na potrzeby przyszłych operacji odczytu. Wszystkie zapisy są nadal zapisywane na dysku.
Zalecenia dotyczące pamięci podręcznej dysków
Aby zmaksymalizować przepływność, zacznij od buforowania hostów tylko do odczytu, jeśli jest to możliwe. W przypadku magazynu w warstwie Premium należy wyłączyć bariery podczas instalowania systemu plików z opcjami tylko do odczytu. Zaktualizuj plik /etc/fstab za pomocą uniwersalnego unikatowego identyfikatora dysków.

- W przypadku dysków systemu operacyjnego użyj dysków SSD w warstwie Premium z buforowaniem hosta odczytu i zapisu.
- W przypadku dysków danych, które zawierają następujące elementy, użyj dysków SSD w warstwie Premium z buforowaniem hostów tylko do odczytu: pliki danych Oracle, pliki tymczasowe, pliki sterujące, pliki śledzenia zmian, BFILEs, pliki dla tabel zewnętrznych i dzienniki flashback.
- W przypadku dysków danych, które zawierają pliki dziennika ponownego zapisywania online oracle, użyj dysków SSD w warstwie Premium lub UltraDisk bez buforowania hosta, opcja Brak . Pliki dziennika ponownego tworzenia kopii zapasowych programu Oracle, które są archiwizowane i zestawy kopii zapasowych programu Oracle Recovery Manager, mogą również znajdować się z plikami dziennika ponownego wykonywania ponownie w trybie online. Buforowanie hostów jest ograniczone do 4095 GiB, więc nie przydzielaj dysku SSD w warstwie Premium większej niż P50 z buforowaniem hosta. Jeśli potrzebujesz więcej niż 4 TiB miejsca do magazynowania, usuń kilka dysków SSD w warstwie Premium za pomocą macierzy RAID-0. Użyj systemu Linux LVM2 lub Oracle Automatic Storage Management.
Jeśli obciążenia różnią się znacznie między dniem a wieczorem, a obciążenie we/wy może go obsługiwać, ssd P1-P20 w warstwie Premium ze wzrostem wydajności może zapewnić wydajność wymaganą podczas obciążeń wsadowych w nocy lub ograniczonych wymagań we/wy.
Zabezpieczenia
Po skonfigurowaniu i skonfigurowaniu środowiska platformy Azure należy zabezpieczyć sieć. Poniżej przedstawiono kilka rekomendacji:
Zasady sieciowej grupy zabezpieczeń: sieciową grupę zabezpieczeń można zdefiniować za pomocą podsieci lub karty interfejsu sieciowego. Łatwiej jest kontrolować dostęp na poziomie podsieci, zarówno w przypadku zabezpieczeń, jak i dla zapór aplikacji routingu wymuszonego.
Jumpbox: aby uzyskać bardziej bezpieczny dostęp, administratorzy nie powinni bezpośrednio łączyć się z usługą aplikacji ani bazą danych. Użyj serwera przesiadkowego między maszyną administratora i zasobami platformy Azure.
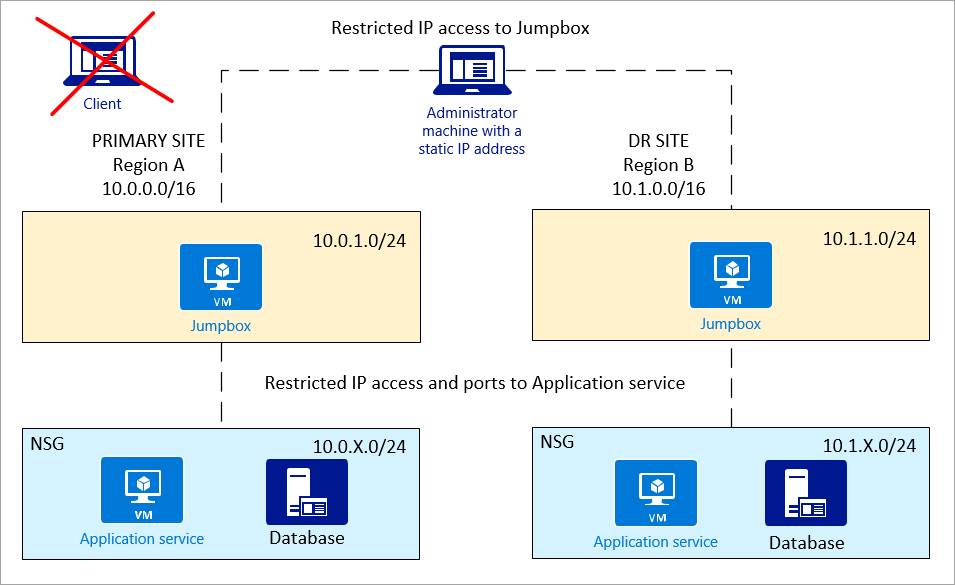
Komputer administratora powinien oferować dostęp tylko do serwera przesiadkowego z ograniczeniami adresów IP. Serwer przesiadkowy powinien mieć dostęp do aplikacji i bazy danych.
Sieć prywatna (podsieci): dobrym pomysłem jest posiadanie usługi aplikacji i bazy danych w oddzielnych podsieciach, dzięki czemu zasady sieciowej grupy zabezpieczeń mogą lepiej kontrolować.

Zasoby
- Configure Oracle ASM (Konfigurowanie programu Oracle ASM)
- Konfigurowanie funkcji Oracle Data Guard
- Konfigurowanie środowiska Oracle GoldenGate
- Tworzenie i odzyskiwanie kopii zapasowej Oracle
Następne kroki
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla