Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() Azure SQL Database
Azure SQL Database
W tym artykule opisano funkcję automatycznej kopii zapasowej dla usługi Azure SQL Database.
Aby zmienić ustawienia kopii zapasowej, zobacz Zmienianie ustawień. Aby przywrócić kopię zapasową, zobacz Odzyskiwanie przy użyciu automatycznych kopii zapasowych bazy danych.
Co to jest kopia zapasowa bazy danych?
Kopie zapasowe bazy danych są istotną częścią każdej strategii ciągłości biznesowej i odzyskiwania po awarii, ponieważ pomagają chronić dane przed uszkodzeniem lub usunięciem. Te kopie zapasowe umożliwiają przywracanie bazy danych do punktu w czasie w skonfigurowanym okresie przechowywania. Jeśli reguły ochrony danych wymagają, aby kopie zapasowe są dostępne przez dłuższy czas (do 10 lat), można skonfigurować długoterminowe przechowywanie (LTR) zarówno dla pojedynczych baz danych, jak i baz danych w puli.
W przypadku warstw usług innych niż Hiperskala, Azure SQL Database używa technologii silnika SQL Server do tworzenia kopii zapasowych i przywracania danych. Bazy danych w warstwie Hiperskala używają kopii zapasowych i przywracania na podstawie migawek magazynu. W przypadku tradycyjnej technologii tworzenia kopii zapasowych programu SQL Server większe bazy danych mają długi czas tworzenia/przywracania kopii zapasowych. Dzięki użyciu migawek hiperskala zapewnia natychmiastowe możliwości tworzenia kopii zapasowych i szybkiego przywracania niezależnie od rozmiaru bazy danych. Aby dowiedzieć się więcej, zobacz Kopie zapasowe Hiperskala.
Częstotliwość wykonywania kopii zapasowych
Usługa Azure SQL Database tworzy:
- Pełne kopie zapasowe co tydzień.
- Różnicowe kopie zapasowe co 12 lub 24 godziny.
- Kopie zapasowe dziennika transakcji są wykonywane co około 10 minut.
Dokładna częstotliwość tworzenia kopii zapasowych dziennika transakcji zależy od rozmiaru obliczeniowego i ilości aktywności bazy danych. Podczas przywracania bazy danych usługa określa, które pełne, różnicowe kopie zapasowe i kopie zapasowe dziennika transakcji muszą zostać przywrócone.
Architektura hiperskalowa nie wymaga pełnych, różnicowych ani kopii zapasowych dzienników zdarzeń. Aby dowiedzieć się więcej, zobacz Kopie zapasowe Hiperskala.
Nadmiarowość magazynu kopii zapasowych
Mechanizm nadmiarowości w magazynowaniu przechowuje wiele kopii przechowywanych danych, dzięki czemu są chronione przed zaplanowanymi i nieplanowanymi zdarzeniami. Te zdarzenia mogą obejmować przejściowe awarie sprzętu, awarie sieci lub zasilania albo ogromne klęski żywiołowe.
Domyślnie nowe bazy danych w usłudze Azure SQL Database przechowują kopie zapasowe w obiektach magazynu geo-nadmiarowego, które są replikowane do sparowanego regionu. Nadmiarowość geograficzna pomaga chronić przed awariami, które wpływają na magazyn kopii zapasowych w regionie podstawowym. Umożliwia również przywracanie baz danych w innym regionie w przypadku awarii regionalnej.
Witryna Azure Portal udostępnia opcję środowiska obciążenia, która pomaga wstępnie ustawić niektóre ustawienia konfiguracji. Te ustawienia można zastąpić. Ta opcja dotyczy wyłącznie strony portalu Create SQL Database.
- Wybranie środowiska obciążenia programistycznego powoduje ustawienie opcji Nadmiarowość magazynu kopii zapasowych w celu korzystania z magazynu lokalnie nadmiarowego. Magazyn lokalnie nadmiarowy wiąże się z mniejszym kosztem i jest odpowiedni dla środowisk przedprodukcyjnych, które nie wymagają nadmiarowości magazynu strefowego ani magazynu replikowanego geograficznie.
- Wybranie środowiska obciążenia produkcyjnego powoduje ustawienie nadmiarowości magazynu kopii zapasowych na magazyn geograficznie nadmiarowy— wartość domyślna.
- Opcja Środowisko obciążenia zmienia również początkowe ustawienie obliczeń, choć można je nadpisać. W przeciwnym przypadku opcja Środowisko obciążenia nie ma wpływu na licencjonowanie ani inne ustawienia konfiguracji bazy danych.
Aby upewnić się, że kopie zapasowe pozostają w tym samym regionie, w którym wdrożono bazę danych, możesz zmienić nadmiarowość magazynu kopii zapasowych z domyślnego magazynu geograficznie nadmiarowego na inne typy magazynów, które przechowują dane w regionie. Skonfigurowana nadmiarowość magazynu kopii zapasowych jest stosowana zarówno do kopii zapasowych krótkoterminowego przechowywania (STR) i kopii zapasowych LTR. Aby dowiedzieć się więcej na temat nadmiarowości pamięci, zobacz Nadmiarowość danych.
Nadmiarowość magazynu kopii zapasowych można skonfigurować podczas tworzenia bazy danych i zaktualizować ją w późniejszym czasie. Zmiany wprowadzone w istniejącej bazie danych mają zastosowanie tylko do przyszłych kopii zapasowych. Po zaktualizowaniu nadmiarowości magazynu kopii zapasowych istniejącej bazy danych zmiany mogą potrwać do 48 godzin.
Możesz wybrać jedną z następujących opcji nadmiarowości magazynowania dla kopii zapasowych:
Magazyn lokalnie nadmiarowy (LRS): Tworzy kopie zapasowe synchronicznie trzy razy w jednej fizycznej lokalizacji w regionie podstawowym. Nie zalecamy używania LRS jako najtańszej opcji przechowywania danych dla aplikacji wymagających odporności na awarie regionalne lub gwarancji wysokiej trwałości danych.

Magazyn strefowo nadmiarowy (ZRS): kopiuje kopie zapasowe synchronicznie w trzech strefach dostępności platformy Azure w regionie podstawowym. Jest ona obecnie dostępna tylko w niektórych regionach.

Magazyn geograficznie nadmiarowy (GRS): kopiuje kopie zapasowe synchronicznie trzy razy w jednej lokalizacji fizycznej w regionie podstawowym przy użyciu magazynu LRS. Następnie dane są trzykrotnie w sposób asynchroniczny kopiowane do jednej lokalizacji fizycznej w sparowanym regionie pomocniczym.
Wynik to:
- Trzy synchroniczne kopie w regionie głównym.
- Trzy kopie synchroniczne w skojarzonym regionie, które zostały asynchronicznie skopiowane z regionu podstawowego do regionu pomocniczego.

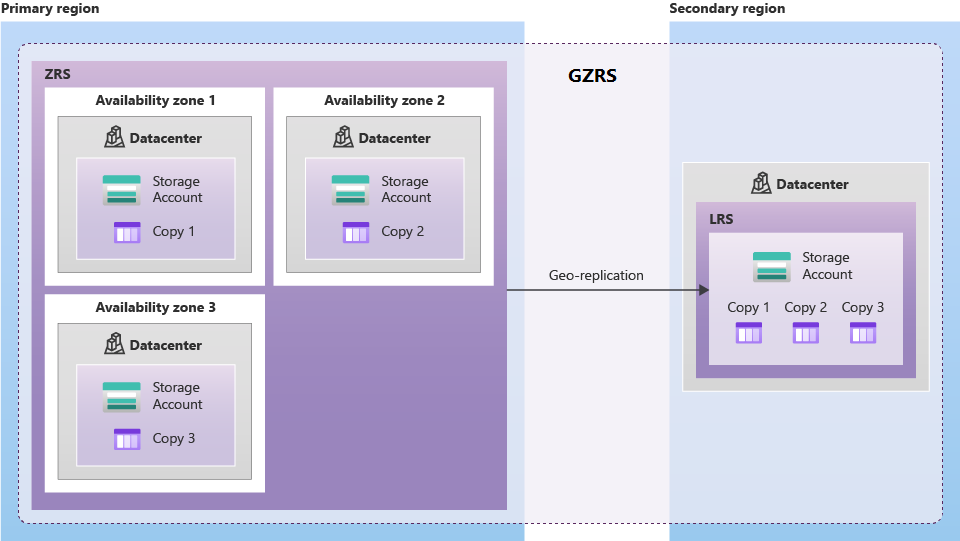
Geo-Zone magazynu nadmiarowego (GZRS) (wersja zapoznawcza): magazyn geograficznie nadmiarowy (GZRS) łączy wysoką dostępność zapewnianą przez nadmiarowość w strefach dostępności (ZRS) z ochroną przed awariami regionalnymi zapewnianymi przez replikację geograficzną (GRS). Kopiuje kopie zapasowe synchronicznie w trzech strefach dostępności platformy Azure w regionie podstawowym oraz asynchronicznie, trzykrotnie do jednej lokalizacji fizycznej w sparowanym regionie pomocniczym. Ta funkcja jest obecnie dostępna w wersji zapoznawczej.
Firma Microsoft zaleca używanie rozwiązania magazynowego GZRS dla aplikacji wymagających maksymalnej spójności, trwałości oraz dostępności, wysokiej wydajności i odporności w zakresie odzyskiwania po awarii.
Wynik to:
Trzy synchroniczne kopie w strefach dostępności w regionie głównym.
Trzy synchroniczne kopie w sparowanym regionie, które są asynchronicznie kopiowane z regionu podstawowego do regionu pomocniczego.
Na poniższym diagramie przedstawiono sposób replikowania danych z GZRS lub RA-GZRS.
Ostrzeżenie
- Geo-restore jest wyłączane natychmiast po zaktualizowaniu bazy danych do wykorzystania lokalnie redundantnego lub strefowo redundantnego magazynu.
- Diagramy nadmiarowości magazynu pokazują wszystkie regiony z wieloma strefami dostępności (multi-az). Istnieją jednak niektóre regiony, które oferują tylko jedną strefę dostępności i nie obsługują ZRS.
- Nadmiarowość magazynu kopii zapasowych dla baz danych w warstwie Hiperskala można ustawić tylko podczas tworzenia. Nie można zmodyfikować tego ustawienia po aprowizacji zasobu. Aby zaktualizować ustawienia nadmiarowości zapasowego magazynowania dla istniejącej bazy danych z Hiperskalą, minimalizując przestój, należy użyć aktywnej replikacji geograficznej. Alternatywnie możesz użyć kopii bazy danych. Dowiedz się więcej na temat kopii zapasowych Hiperskala i redundancji magazynowania.
Korzystanie z kopii zapasowych
W następujących scenariuszach można użyć automatycznie utworzonych kopii zapasowych:
Przywróć istniejącą bazę danych do punktu w czasie w okresie przechowywania przy użyciu witryny Azure Portal, programu Azure PowerShell, interfejsu wiersza polecenia platformy Azure lub interfejsu API REST. Ta operacja tworzy nową bazę danych na tym samym serwerze co oryginalna baza danych, ale używa innej nazwy, aby uniknąć zastępowania oryginalnej bazy danych.
Po zakończeniu przywracania możesz opcjonalnie usunąć oryginalną bazę danych i zmienić nazwę przywróconej bazy danych na oryginalną nazwę bazy danych. Alternatywnie zamiast usuwać oryginalną bazę danych, możesz ją zmienić , a następnie zmienić nazwę przywróconej bazy danych na oryginalną nazwę bazy danych.
Przywróć usuniętą bazę danych do konkretnego momentu w czasie w trakcie okresu przechowywania, włączając czas, kiedy baza danych została usunięta. Usuniętą bazę danych można przywrócić tylko na tym samym serwerze, na którym utworzono oryginalną bazę danych. Przed usunięciem bazy danych usługa wykonuje ostateczną kopię zapasową dziennika transakcji, aby zapobiec utracie danych.
Przywracanie bazy danych do innego regionu geograficznego. Przywracanie geograficzne umożliwia odzyskiwanie po awarii regionalnej, gdy nie można uzyskać dostępu do bazy danych ani kopii zapasowych w regionie podstawowym. Tworzy nową bazę danych na dowolnym istniejącym serwerze w dowolnym regionie świadczenia usługi Azure.
Ważne
Przywracanie geograficzne jest dostępne tylko dla baz danych skonfigurowanych z magazynem kopii zapasowych zapewniającym geograficzną nadmiarowość. Jeśli obecnie nie używasz replikowanych geograficznie kopii zapasowych bazy danych, możesz to zmienić, konfigurując nadmiarowość magazynu kopii zapasowych.
Przywracanie bazy danych z konkretnej długoterminowej kopii zapasowej pojedynczej bazy danych lub bazy danych w puli, jeśli baza danych została skonfigurowana przy użyciu zasad LTR. LTR umożliwia przywrócenie starszej wersji bazy danych przy użyciu witryny Azure Portal, interfejsu wiersza polecenia platformy Azure lub programu Azure PowerShell w celu spełnienia żądania zgodności lub uruchomienia starszej wersji aplikacji. Aby uzyskać więcej informacji, zobacz Długoterminowe przechowywanie.
Ostrzeżenie
Podczas przywracania bazy danych, gdy nadmiarowość źródłowego magazynu kopii zapasowych jest konfigurowana jako Geo-Zone Redundant Storage (GZRS), konfiguracja ta jest dziedziczona przez nową bazę danych, jeśli nadmiarowość magazynu kopii zapasowych dla docelowej bazy danych nie jest określona jawnie. Obejmuje to wszelkie operacje przywracania, takie jak przywracanie do punktu w czasie, kopiowanie bazy danych, przywracanie geograficzne, przywracanie z długoterminowej kopii zapasowej. W trakcie tej operacji, jeśli docelowy region świadczenia usługi Azure nie obsługuje konkretnej nadmiarowości magazynu kopii zapasowych, operacja przywracania zakończy się niepowodzeniem z odpowiednim komunikatem o błędzie. Można temu zapobiec, jawnie określając dostępne opcje magazynu dla regionu.
Automatyczne kopie zapasowe w replikach pomocniczych
Automatyczne kopie zapasowe są teraz pobierane z repliki pomocniczej w warstwie usługi Krytyczne dla Biznesu. Ponieważ dane są replikowane między procesami programu SQL Server w każdym węźle, usługa tworzenia kopii zapasowej wykonuje kopię zapasową z replik pomocniczych, których nie można odczytać. Układ ten zapewnia, że replika nadrzędna pozostaje dedykowana głównemu obciążeniu, a replika podrzędna z możliwością odczytu jest przeznaczona dla obciążeń wyłącznie do odczytu. Automatyczne kopie zapasowe w warstwie usługi Krytyczne dla działania firmy są pobierane z repliki pomocniczej przez większość czasu. Jeśli automatyczna kopia zapasowa nie powiedzie się w replice pomocniczej, usługa tworzenia kopii zapasowej pobiera kopię zapasową z repliki podstawowej.
Automatyczne kopie zapasowe replik pomocniczych:
- Są domyślnie włączone.
- Są uwzględniane bez dodatkowych kosztów poza ceną poziomu usług.
- Zapewnij lepszą wydajność i przewidywalność w warstwie usługi Business Critical.
Uwaga
Utwórz zgłoszenie pomocy technicznej w Microsoft, aby wyłączyć tę funkcję dla twojej instancji.
Przywróć funkcje i możliwości
W tej tabeli przedstawiono podsumowanie możliwości i funkcji przywracania do punktu w czasie (PITR), geoprzywracania oraz długoterminowej archiwizacji.
Aby uzyskać informacje na temat czasów odzyskiwania, zobacz RTO i RPO.
| Właściwość kopii zapasowej | PITR | Przywracanie danych geograficznie | Od lewej do prawej (LTR) |
|---|---|---|---|
| Typy kopii zapasowych SQL | Pełny, różnicowy, log. | Najnowsze kopie geograficznie replikowane kopii zapasowych pitr. | Tylko pełne kopie zapasowe. |
| Przechowywanie | Domyślnie ustawione na 7 dni, można skonfigurować w zakresie od 1 do 35 dni (z wyjątkiem baz danych w warstwie Podstawowa, które można skonfigurować w zakresie od 1 do 7 dni). | Włączone domyślnie tak samo jak źródło.2 | Nie jest włączone domyślnie. Przechowywanie wynosi do 10 lat. |
| Azure Storage | Domyślnie geograficznie nadmiarowy. Opcjonalnie można skonfigurować magazyn strefowo nadmiarowy lub lokalnie nadmiarowy. | Dostępne, gdy nadmiarowość magazynu kopii zapasowych PITR jest ustawiona na nadmiarowość geograficzną. Niedostępne, gdy magazyn kopii zapasowych PITR jest strefowo nadmiarowy lub lokalnie nadmiarowy. | Domyślnie geograficznie nadmiarowy. Możesz skonfigurować magazyn strefowo nadmiarowy lub lokalnie nadmiarowy. |
| Konfigurowanie kopii zapasowych jako niezmiennych | Nieobsługiwany | Nieobsługiwany | Nieobsługiwany |
| Przywracanie nowej bazy danych w tym samym regionie | Wsparcie | Wsparcie | Wsparcie |
| Przywracanie nowej bazy danych w innym regionie | Nieobsługiwany | Obsługiwane w dowolnym regionie świadczenia platformy Azure | Obsługiwane w dowolnym regionie świadczenia platformy Azure |
| Przywracanie nowej bazy danych w innej subskrypcji | Nieobsługiwany | Nieobsługiwane 3 | Nieobsługiwane 3 |
| Przywracanie za pośrednictwem witryny Azure Portal | Tak | Tak | Tak |
| Przywracanie za pomocą programu PowerShell | Tak | Tak | Tak |
| Przywracanie za pomocą interfejsu wiersza polecenia platformy Azure | Tak | Tak | Tak |
1 W przypadku aplikacji o krytycznym znaczeniu dla działania firmy, które wymagają dużych baz danych i muszą zapewnić ciągłość działania, użyj grup przełączania awaryjnego.
2 Wszystkie kopie zapasowe PITR są domyślnie przechowywane w magazynie geograficznie nadmiarowym, więc przywracanie geograficzne jest domyślnie włączone.
3 Obejście polega na przywróceniu do nowego serwera i użyciu Resource Move do przeniesienia serwera do innej subskrypcji lub użyciu kopii bazy danych między subskrypcjami.
Przywracanie bazy danych z kopii zapasowej
Aby wykonać przywracanie, zobacz Przywracanie bazy danych z kopii zapasowych. Konfigurację kopii zapasowej i operacje przywracania można eksplorować, korzystając z poniższych przykładów.
| Operacja | Azure Portal | Interfejs Azure CLI | Azure PowerShell |
|---|---|---|---|
| Zmienianie przechowywania kopii zapasowych |
SQL Database Zarządzana instancja SQL |
SQL Database Zarządzana instancja SQL |
SQL Database Zarządzana instancja SQL |
| Zmienianie długoterminowego przechowywania kopii zapasowych |
SQL Database Zarządzana instancja SQL |
SQL Database Zarządzana instancja SQL |
SQL Database Zarządzana instancja SQL |
| Przywracanie bazy danych z punktu w czasie |
SQL Database Zarządzana instancja SQL |
SQL Database Zarządzana instancja SQL |
SQL Database Zarządzana instancja SQL |
| Przywracanie usuniętej bazy danych |
SQL Database Zarządzana instancja SQL |
SQL Database Zarządzana instancja SQL |
SQL Database Zarządzana instancja SQL |
Eksportowanie bazy danych
Automatyczne kopie zapasowe wykonywane przez usługę platformy Azure nie są dostępne do bezpośredniego pobierania ani uzyskiwania do niego dostępu. Można ich używać tylko na potrzeby operacji przywracania za pośrednictwem platformy Azure.
Istnieją alternatywy dla eksportowania usługi Azure SQL Database. Jeśli musisz wyeksportować bazę danych do archiwizacji lub przenieść na inną platformę, możesz wyeksportować schemat bazy danych i dane do pliku BACPAC . Plik BACPAC to plik ZIP z rozszerzeniem BACPAC zawierającym metadane i dane z bazy danych. Plik BACPAC może być przechowywany w usłudze Azure Blob Storage lub w magazynie lokalnym w lokalizacji lokalnej, a później zaimportowany z powrotem do usługi Azure SQL Database, usługi Azure SQL Managed Instance lub wystąpienia programu SQL Server.
Możesz również zaimportować lub wyeksportować usługę Azure SQL Database przy użyciu łącza prywatnego lub zaimportować lub wyeksportować bazę danych Azure SQL Database bez zezwalania usługom platformy Azure na dostęp do serwera.
Planowanie kopii zapasowych
Pierwsza pełna kopia zapasowa jest planowana natychmiast po utworzeniu lub przywróceniu nowej bazy danych. Ta kopia zapasowa zwykle kończy się w ciągu 30 minut, ale może to potrwać dłużej, gdy baza danych jest duża. Na przykład początkowa kopia zapasowa może trwać dłużej w przywróconej bazie danych lub kopii bazy danych, która zwykle będzie większa niż nowa baza danych.
Po utworzeniu pierwszej pełnej kopii zapasowej wszystkie kolejne kopie zapasowe są zaplanowane i zarządzane automatycznie. Dokładne terminy wykonywania wszystkich kopii zapasowych bazy danych są określane przez usługę SQL Database, ponieważ równoważy ona całkowite obciążenie systemu. Nie można zmienić harmonogramu zadań tworzenia kopii zapasowej ani ich wyłączyć.
Ważne
- W przypadku nowej, przywróconej lub skopiowanej bazy danych funkcja przywracania do punktu w czasie staje się dostępna po utworzeniu początkowej kopii zapasowej dziennika transakcji, która następuje po utworzeniu początkowej pełnej kopii zapasowej.
- Bazy danych w warstwie Hiperskala są chronione natychmiast po utworzeniu, w przeciwieństwie do innych baz danych, w których początkowa kopia zapasowa zajmuje trochę czasu. Ochrona jest natychmiastowa, nawet jeśli baza danych Hiperskala została utworzona z dużą ilością danych poprzez kopiowanie lub przywracanie. Aby dowiedzieć się więcej, zapoznaj się z automatycznymi kopiami zapasowymi w warstwie Hiperskala.
Użycie magazynu kopii zapasowych
Dzięki technologii tworzenia i przywracania kopii zapasowych programu SQL Server przywracanie bazy danych do punktu w czasie wymaga nieprzerwanego łańcucha kopii zapasowych. Ten łańcuch składa się z jednej pełnej kopii zapasowej, opcjonalnie jednej różnicowej kopii zapasowej i co najmniej jednej kopii zapasowej dziennika transakcji.
Usługa Azure SQL Database planuje co tydzień jedną pełną kopię zapasową. Aby zapewnić PITR na cały okres przechowywania, system musi przechowywać dodatkowe pełne, różnicowe i transakcyjne kopie zapasowe dzienników przez maksymalnie tydzień dłużej niż skonfigurowany okres przechowywania.
Innymi słowy, dla dowolnego punktu w czasie okresu przechowywania musi istnieć pełna kopia zapasowa starsza niż najstarszy czas okresu przechowywania. Musi również istnieć nieprzerwany łańcuch różnicowych kopii zapasowych oraz kopii zapasowych dziennika transakcji od tej pełnej kopii zapasowej aż do następnej pełnej kopii zapasowej.
Bazy danych w warstwie Hiperskala używają innego mechanizmu planowania kopii zapasowych. Aby uzyskać więcej informacji, zobacz Planowanie kopii zapasowych w warstwie Hiperskala.
Kopie zapasowe, które nie są już potrzebne do zapewnienia funkcji PITR, są automatycznie usuwane. Ponieważ różnicowe kopie zapasowe i kopie zapasowe dzienników wymagają wcześniejszej pełnej kopii zapasowej, aby można je było przywrócić, wszystkie trzy typy kopii zapasowych są usuwane razem w zestawach tygodniowych.
W przypadku wszystkich baz danych, w tym baz danych zaszyfrowanych za pomocą funkcji TDE, wszystkie pełne i różnicowe kopie zapasowe są kompresowane, aby zmniejszyć kompresję i koszty magazynu kopii zapasowych. Średni współczynnik kompresji kopii zapasowej wynosi od 3 do 4 razy. Jednak może być niższa lub wyższa w zależności od charakteru danych i tego, czy kompresja danych jest używana w bazie danych.
Ważne
W przypadku baz danych zaszyfrowanych za pomocą funkcji TDE pliki kopii zapasowych dzienników nie są kompresowane ze względu na wydajność. Kopie zapasowe dzienników dla nieszyfrowanych baz danych TDE są kompresowane.
Usługa Azure SQL Database oblicza łączną ilość używanego magazynu kopii zapasowych jako wartość skumulowaną. Co godzinę ta wartość jest zgłaszana do potoku rozliczeń platformy Azure. Rurociąg jest odpowiedzialny za agregowanie tego godzinowego użycia w celu obliczenia twojego zużycia pod koniec każdego miesiąca. Po usunięciu bazy danych zużycie zmniejsza się w miarę starzenia się kopii zapasowych i usuwania. Po usunięciu wszystkich kopii zapasowych, a usługa PITR nie jest już możliwa, rozliczenia zostaną zatrzymane.
Ważne
Kopie zapasowe bazy danych są zachowywane, aby zapewnić odzyskiwanie do punktu w czasie (PITR), nawet jeśli baza danych została usunięta. Chociaż usuwanie i ponowne tworzenie bazy danych może zmniejszyć koszty magazynowania i zasobów obliczeniowych, może to zwiększyć koszty magazynu kopii zapasowych. Przyczyną jest to, że usługa zachowuje kopie zapasowe dla każdej usuniętej bazy danych za każdym razem, gdy zostanie ona usunięta.
Monitorowanie użycia
W przypadku baz danych vCore w usłudze Azure SQL Database, przechowywanie, z którego korzysta każdy typ kopii zapasowej (pełny, różnicowy i dziennika), jest raportowane w okienku monitorowania bazy danych jako oddzielna metryka. Poniższy zrzut ekranu przedstawia sposób monitorowania użycia magazynu kopii zapasowych dla pojedynczej bazy danych.

Aby uzyskać instrukcje dotyczące monitorowania użycia w warstwie Hiperskala, zobacz Monitorowanie użycia kopii zapasowych w warstwie Hiperskala.
Optymalizacja zużycia przestrzeni na kopie zapasowe
Zużycie magazynu kopii zapasowej do maksymalnego rozmiaru danych przechowywanych dla bazy danych nie jest obciążane kosztami. Nadmierne użycie magazynu kopii zapasowych zależy od obciążenia i maksymalnego rozmiaru poszczególnych baz danych. Rozważ niektóre z następujących technik dostrajania, aby zmniejszyć użycie magazynu kopii zapasowych:
- Zmniejsz okres przechowywania kopii zapasowych do minimum dla Twoich potrzeb.
- Unikaj wykonywania dużych operacji zapisu, takich jak ponowne kompilowanie indeksów, częściej niż jest to konieczne.
- W przypadku operacji ładowania dużych danych rozważ użycie klastrowanych indeksów magazynu kolumn i przestrzeganie powiązanych najlepszych rozwiązań. Rozważ również zmniejszenie liczby indeksów nieklastrowanych.
- W warstwie usługi Ogólnego przeznaczenia aprowizowany magazyn danych jest mniej kosztowny niż cena magazynu kopii zapasowych. Jeśli koszty przechowywania kopii zapasowych są stale wysokie, warto rozważyć zwiększenie miejsca na przechowywanie danych, aby zaoszczędzić na kopiach zapasowych.
- Użyj
tempdbzamiast stałych tabel w logice aplikacji do przechowywania tymczasowych wyników lub danych przejściowych. - Używaj lokalnie nadmiarowego magazynu kopii zapasowych, jeśli to możliwe (na przykład środowisk deweloperskich/testowych).
Przechowywanie kopii zapasowej
Usługa Azure SQL Database zapewnia krótkoterminowe i długoterminowe przechowywanie kopii zapasowych. Krótkoterminowe przechowywanie umożliwia wykonywanie punktowego przywracania w czasie (PITR) w okresie przechowywania bazy danych. Długoterminowe przechowywanie zapewnia kopie zapasowe dla różnych wymagań dotyczących zgodności.
Przechowywanie krótkoterminowe
W przypadku wszystkich nowych, przywróconych i kopiowanych baz danych usługa Azure SQL Database domyślnie zachowuje wystarczającą liczbę kopii zapasowych, aby umożliwić przywracanie do punktu w czasie w ciągu ostatnich 7 dni. Usługa wykonuje regularne pełne, różnicowe i dzienniki kopie zapasowe, aby upewnić się, że bazy danych można przywracać do dowolnego punktu w czasie w okresie przechowywania zdefiniowanym dla bazy danych.
Różnicowe kopie zapasowe można skonfigurować tak, aby występowały raz w 12 godzinach lub raz w ciągu 24 godzin. Częstotliwość różnicowej kopii zapasowej 24-godzinnej może zwiększyć czas wymagany do przywrócenia bazy danych w porównaniu z częstotliwością 12-godzinną. W modelu rdzeni wirtualnych domyślna częstotliwość różnicowych kopii zapasowych wynosi raz na 12 godzin. W modelu DTU domyślna częstotliwość wynosi raz w ciągu 24 godzin.
Podczas tworzenia bazy danych można określić opcję redundancji magazynu kopii zapasowej, a następnie zmienić ją w późniejszym czasie. Jeśli zmienisz opcję nadmiarowości kopii zapasowej po utworzeniu bazy danych, nowe kopie zapasowe będą używać nowej opcji nadmiarowości. Kopie zapasowe wykonane przy użyciu poprzedniej opcji nadmiarowości STR nie są przenoszone ani kopiowane. Pozostają one na oryginalnym koncie magazynu do momentu wygaśnięcia okresu przechowywania, który może wynosić od 1 do 35 dni.
Okres przechowywania kopii zapasowych dla każdej aktywnej bazy danych można zmienić w przedziale od 1 do 35 dni, z wyjątkiem baz danych podstawowych, które można skonfigurować z zakresu od 1 do 7 dni. Zgodnie z opisem w temacie Zużycie magazynu kopii zapasowych, kopie zapasowe przechowywane w celu umożliwienia przywracania do punktu w czasie (PITR) mogą być starsze niż okres przechowywania. Jeśli musisz przechowywać kopie zapasowe przez dłuższy niż maksymalny okres przechowywania krótkoterminowego wynoszący 35 dni, możesz włączyć długoterminowe przechowywanie.
Jeśli usuniesz bazę danych, system przechowuje kopie zapasowe w taki sam sposób, jak w przypadku bazy danych online z określonym okresem przechowywania. Nie można zmienić okresu przechowywania kopii zapasowych dla usuniętej bazy danych.
Ważne
Jeśli usuniesz serwer, wszystkie bazy danych na tym serwerze również zostaną usunięte i nie można ich odzyskać. Nie można przywrócić usuniętego serwera. Jeśli jednak skonfigurowano długoterminowe przechowywanie bazy danych, kopie zapasowe LTR nie zostaną usunięte. Następnie można użyć tych kopii zapasowych do przywracania baz danych na innym serwerze w tej samej subskrypcji, do momentu, w którym wykonano kopię zapasową LTR. Aby dowiedzieć się więcej, zobacz Przywracanie długoterminowej kopii zapasowej.
Długoterminowe przechowywanie
W przypadku usługi SQL Database można skonfigurować pełne kopie zapasowe długoterminowego przechowywania przez maksymalnie 10 lat w usłudze Azure Blob Storage. Po skonfigurowaniu zasad LTR pełne kopie zapasowe są automatycznie kopiowane do innego kontenera magazynu co tydzień.
Aby spełnić różne wymagania dotyczące zgodności, możesz wybrać różne okresy przechowywania dla cotygodniowych, miesięcznych i/lub rocznych pełnych kopii zapasowych. Częstotliwość zależy od zasad. Na przykład ustawienie W=0, M=1 spowoduje utworzenie miesięcznej kopii LTR. Aby uzyskać więcej informacji na temat długoterminowego przechowywania, zobacz Długoterminowe przechowywanie.
Aktualizacja nadmiarowości magazynu kopii zapasowych dla istniejącej bazy danych ma zastosowanie tylko do przyszłych kopii zapasowych i nie dotyczy już istniejących. Wszystkie istniejące kopie zapasowe LTR dla bazy danych nadal znajdują się w istniejącym blobie magazynowym. Nowe kopie zapasowe są replikowane na podstawie skonfigurowanej nadmiarowości magazynu kopii zapasowych.
Zużycie magazynu zależy od wybranych częstotliwości i okresów przechowywania kopii zapasowych LTR. Aby oszacować koszt magazynu LTR, można użyć kalkulatora cen LTR.
Podczas przywracania bazy danych Hiperskala z kopii zapasowej LTR funkcja skalowania odczytu jest wyłączona. Aby włączyć, skaluj odczyt w przywróconej bazie danych, zaktualizuj bazę danych po jej utworzeniu. Należy określić docelowy cel poziomu usługi podczas przywracania z kopii zapasowej LTR.
Długoterminowe przechowywanie można włączyć dla baz danych w warstwie Hiperskala utworzonych lub zmigrowanych z innych warstw usług. Jeśli spróbujesz włączyć LTR dla bazy danych w warstwie Hiperskala, w której nie jest jeszcze obsługiwana, zostanie wyświetlony następujący błąd: "Wystąpił błąd podczas włączania długoterminowego przechowywania kopii zapasowych dla tej bazy danych. Skontaktuj się z pomocą techniczną firmy Microsoft, aby włączyć długoterminowe przechowywanie kopii zapasowych. W takim przypadku skontaktuj się z pomocą techniczną firmy Microsoft i utwórz bilet pomocy technicznej, aby rozwiązać ten problem.
Koszty magazynu kopii zapasowych
Cena magazynu kopii zapasowych zależy od modelu zakupów (DTU lub rdzenia wirtualnego), wybranej opcji nadmiarowości magazynu kopii zapasowych i regionu. Opłata za magazyn kopii zapasowych jest naliczana na podstawie gigabajtów zużywanych miesięcznie, z taką samą stawką dla wszystkich kopii zapasowych.
Aby uzyskać informacje o cenach, zobacz stronę cennika usługi Azure SQL Database.
Uwaga
Faktura za platformę Azure pokazuje tylko nadmierne użycie magazynu kopii zapasowych, a nie całe użycie magazynu kopii zapasowych. Na przykład w hipotetycznym scenariuszu, jeśli aprowizujesz 4 TB magazynu danych, otrzymasz 4 TB wolnego miejsca do magazynowania kopii zapasowych. Jeśli używasz łącznie 5,8 TB miejsca do magazynowania kopii zapasowych, faktura platformy Azure zawiera tylko 1,8 TB, ponieważ opłaty są naliczane tylko za nadmiarowy magazyn kopii zapasowych, który został użyty.
Model jednostki DTU
W modelu DTU, w przypadku baz danych i pul elastycznych, nie są naliczane dodatkowe opłaty za magazyn kopii zapasowych PITR przy domyślnym okresie przechowywania wynoszącym 7 dni lub więcej. Koszt przechowywania kopii zapasowych PITR stanowi część ceny bazy danych lub puli.
Ważne
W modelu DTU za magazyn kopii zapasowych LTR naliczane są opłaty na podstawie rzeczywistego zużycia magazynu przez kopie zapasowe LTR.
Model rdzenia wirtualnego
Usługa Azure SQL Database oblicza całkowitą rozliczaną przestrzeń przechowywania kopii zapasowych jako sumę wartości we wszystkich plikach kopii zapasowych. Co godzinę ta wartość jest zgłaszana do potoku rozliczeń platformy Azure. Proces agreguje to godzinowe użycie w celu uzyskania zużycia pamięci kopii zapasowych na koniec każdego miesiąca.
Jeśli baza danych zostanie usunięta, zużycie magazynu kopii zapasowych stopniowo spadnie wraz ze starzeniem się starszych kopii zapasowych i usunięciem. Ponieważ różnicowe kopie zapasowe i kopie zapasowe dzienników wymagają wcześniejszej pełnej kopii zapasowej, aby można je było przywrócić, wszystkie trzy typy kopii zapasowych są usuwane razem w zestawach tygodniowych. Po usunięciu wszystkich kopii zapasowych rozliczenia zostaną zatrzymane.
Koszt magazynu kopii zapasowych jest obliczany inaczej dla baz danych w warstwie Hiperskala. Aby uzyskać więcej informacji, zobacz Koszty przechowywania kopii zapasowych w zakresie hiperskali.
W przypadku pojedynczych baz danych magazyn kopii zapasowych wynosi 100 procent maksymalnego rozmiaru magazynu danych dla bazy danych bez dodatkowych opłat. Następujące równanie służy do obliczania całkowitego rozliczanego użycia magazynu kopii zapasowych:
Total billable backup storage size = (size of full backups + size of differential backups + size of log backups) – maximum data storage
W przypadku elastycznych pul przestrzeń na kopie zapasowe wynosi 100 procent maksymalnego rozmiaru magazynu puli bez dodatkowych opłat. W przypadku baz danych w puli całkowity rozmiar rozliczanego magazynu kopii zapasowych jest agregowany na poziomie puli i jest obliczany w następujący sposób:
Total billable backup storage size = (total size of all full backups + total size of all differential backups + total size of all log backups) - maximum pool data storage
Łączna opłata za przechowywanie kopii zapasowych, jeśli dotyczy, jest naliczana w gigabajtach miesięcznie zgodnie ze stawką redundancji przechowywania kopii zapasowych, którą wykorzystano. Zużycie przestrzeni magazynowej na kopie zapasowe zależy od obciążenia i rozmiaru poszczególnych baz danych, pul elastycznych i wystąpień zarządzanych. Silnie zmodyfikowane bazy danych mają większe różnicowe kopie zapasowe i kopie zapasowe dzienników, ponieważ rozmiar tych kopii zapasowych jest proporcjonalny do ilości zmienionych danych. W związku z tym takie bazy danych mają wyższe opłaty za tworzenie kopii zapasowych.
W uproszczonym przykładzie przyjęto założenie, że baza danych zgromadziła 744 GB magazynu kopii zapasowych i że ta ilość pozostaje stała przez cały miesiąc, ponieważ baza danych jest całkowicie bezczynna. Aby przekonwertować to skumulowane użycie magazynu na użycie godzinowe, podziel je na 744,0 (31 dni miesięcznie 24 godziny dziennie). Usługa SQL Database raportuje do potoku rozliczeń platformy Azure, że baza danych zużywała 1 GB kopii zapasowej PITR co godzinę ze stałą szybkością. Rozliczenia platformy Azure agregują to użycie i pokazują użycie 744 GB przez cały miesiąc. Koszt jest oparty na stawce dla gigabajtów miesięcznie w Twoim regionie.
Oto kolejny przykład. Załóżmy, że ta sama nieaktywna baza danych ma wydłużenie okresu przechowywania z 7 dni do 14 dni w środku miesiąca. Ten wzrost powoduje podwojenie całkowitego magazynu kopii zapasowych do 1488 GB. Usługa SQL Database zgłasza 1 GB użycia przez godziny od 1 do 372 (pierwsza połowa miesiąca). Będzie zgłaszało użycie jako 2 GB w godzinach od 373 do 744 (druga połowa miesiąca). To użycie zostanie zagregowane do końcowego rachunku w wysokości 1116 GB miesięcznie.
Rzeczywiste scenariusze rozliczeń kopii zapasowych są bardziej złożone. Ponieważ szybkość zmian w bazie danych zależy od obciążenia i jest zmienna w czasie, rozmiar każdej różnicowej i kopii zapasowej dziennika również będzie się różnić. Zużycie godzinowe magazynu kopii zapasowych zmienia się odpowiednio.
Każda różnicowa kopia zapasowa zawiera również wszystkie zmiany wprowadzone w bazie danych od czasu ostatniej pełnej kopii zapasowej. Dlatego całkowity rozmiar wszystkich różnicowych kopii zapasowych stopniowo wzrasta w ciągu tygodnia. Następnie gwałtownie spada, gdy starszy zestaw pełnych, różnicowych oraz kopii zapasowych dzienników transakcji przestaje być używany.
Załóżmy na przykład, że duże działanie zapisu, takie jak ponowne kompilowanie indeksu, jest uruchamiane tuż po zakończeniu pełnej kopii zapasowej. Modyfikacje wprowadzone przez ponowną kompilację indeksu zostaną następnie uwzględnione:
- W kopiach zapasowych dziennika transakcji wykonanych w czasie trwania odbudowy.
- W następnej różnicowej kopii zapasowej.
- W każdej różnicowej kopii zapasowej wykonanej do chwili wykonania kolejnej pełnej kopii zapasowej.
W przypadku ostatniego scenariusza w większych bazach danych optymalizacja w usłudze tworzy pełną kopię zapasową zamiast różnicowej kopii zapasowej, jeśli różnicowa kopia zapasowa byłaby zbyt duża. Zmniejsza to rozmiar wszystkich różnicowych kopii zapasowych do momentu utworzenia następującej pełnej kopii zapasowej.
W miarę upływu czasu można monitorować całkowite użycie magazynu kopii zapasowych dla każdego typu kopii zapasowej (pełnej, różnicowej, dziennika transakcji), zgodnie z opisem w temacie Monitorowanie zużycia.
Monitorowanie kosztów
Aby zrozumieć koszty magazynu kopii zapasowych, przejdź do obszaru Zarządzanie kosztami i rozliczenia w witrynie Azure Portal. Wybierz pozycję Cost Management, a następnie wybierz pozycję Analiza kosztów. Wybierz żądaną subskrypcję dla Zakres, a następnie przefiltruj według okresu i usługi, które Cię interesują w następujący sposób:
Dodaj filtr dla nazwy usługi.
Z listy rozwijanej wybierz pozycję sql database dla pojedynczej bazy danych lub elastycznej puli baz danych.
Dodaj kolejny filtr dla podkategorii miernika.
Aby monitorować koszty tworzenia kopii zapasowych PITR, na liście rozwijanej wybierz magazyn kopii zapasowych pojedynczej bazy danych lub elastycznej puli baz danych. Mierniki są wyświetlane tylko wtedy, gdy ma miejsce zużycie miejsca na kopie zapasowe.
Aby monitorować koszty tworzenia kopii zapasowych LTR, na liście rozwijanej wybierz pozycję ltr backup storage dla pojedynczej bazy danych lub elastycznej puli baz danych. Mierniki są wyświetlane tylko wtedy, gdy ma miejsce zużycie miejsca na kopie zapasowe.
Podkategorie magazynu i zasobów obliczeniowych mogą cię również zainteresować, ale nie są one skojarzone z kosztami magazynu kopii zapasowych.

Ważne
Wskaźniki są widoczne tylko dla liczników, które są obecnie używane. Jeśli licznik jest niedostępny, prawdopodobnie kategoria nie jest obecnie używana. Na przykład liczniki pamięci masowej nie będą widoczne dla zasobów, które nie korzystają z pamięci masowej. Jeśli nie ma zużycia przestrzeni magazynowej na kopie zapasowe PITR ani LTR, te mierniki nie będą widoczne.
Aby uzyskać więcej informacji, zobacz Zarządzanie kosztami usługi Azure SQL Database.
Zaszyfrowane kopie zapasowe
Jeśli baza danych jest zaszyfrowana za pomocą TDE, kopie zapasowe są automatycznie szyfrowane w spoczynku, w tym kopie zapasowe LTR. Wszystkie nowe bazy danych w usłudze Azure SQL są domyślnie skonfigurowane z włączonym szyfrowaniem TDE. Aby uzyskać więcej informacji na temat funkcji TDE, zobacz Transparent Data Encryption with SQL Database (Szyfrowanie transparent data encryption za pomocą usługi SQL Database).
Integralność kopii zapasowej
Zespół inżynierów usługi Azure SQL stale przeprowadza automatyczne testy przywracania zautomatyzowanych kopii zapasowych baz danych. Podczas przywracania do punktu w czasie bazy danych podlegają kontrolom spójności DBCC CHECKDB.
Wszelkie problemy występujące podczas sprawdzania integralności powodują wyświetlenie alertu dla zespołu inżynierów. Aby uzyskać więcej informacji, zobacz Integralność danych w usłudze SQL Database.
Wszystkie kopie zapasowe bazy danych są wykonywane z opcją CHECKSUM, aby zapewnić dodatkową integralność kopii zapasowej.
Ochrona kopii zapasowych
Kopie zapasowe usługi Azure SQL Database są zarządzane w całości w ramach subskrypcji platformy Azure należących do firmy Microsoft przy użyciu bezpiecznych, wewnętrznych kont usługi Azure Storage. Te kopie zapasowe nie są dostępne zewnętrznie, zapewniając silną izolację i ochronę danych. W firmie Microsoft tylko usługi zaplecza, takie jak usługa Backup-Restore, mają dostęp do tworzenia, kopiowania lub przywracania tych kopii zapasowych. Inżynierowie firmy Microsoft, w tym deweloperzy, nie mają stałego dostępu. Aby zminimalizować ekspozycję i zmaksymalizować bezpieczeństwo, firma Microsoft może uzyskać dostęp just-In-Time (JIT) w ramach rygorystycznych kontroli inspekcji, gdy jest to absolutnie konieczne do rozwiązywania określonych problemów klientów.
Kopie zapasowe są automatycznie usuwane po wygaśnięciu okresu przechowywania.
Zgodność za pomocą przechowywania kopii zapasowych
Jeśli domyślny czas przechowywania nie spełnia wymagań dotyczących zgodności, możesz zmienić okres przechowywania PITR. Aby uzyskać więcej informacji, zobacz Zmienianie okresu przechowywania kopii zapasowych pitr.
Podczas migrowania bazy danych z warstwy opartej na DTU do warstwy opartej na rdzeniach wirtualnych, retencja punktu odzyskiwania jest zachowywana, aby zapewnić, że zasady odzyskiwania danych aplikacji nie zostaną naruszone.
Uwaga
Artykuł Zmiana ustawień automatycznego tworzenia kopii zapasowych zawiera kroki usuwania danych osobowych z urządzenia lub usługi i może służyć do wspierania zobowiązań wynikających z RODO. Aby uzyskać ogólne informacje o RODO, zobacz sekcję RODO w Centrum zaufania Microsoft i sekcję RODO w portalu zaufania usług.
Używanie usługi Azure Policy do wymuszania nadmiarowości magazynu kopii zapasowych
Jeśli masz wymagania dotyczące rezydencji danych, które wymagają przechowywania wszystkich danych w jednym regionie świadczenia usługi Azure, możesz wymusić strefowo nadmiarowe lub lokalnie nadmiarowe kopie zapasowe bazy danych SQL przy użyciu usługi Azure Policy.
Azure Policy to usługa, której można użyć do tworzenia, przypisywania i zarządzania zasadami, które stosują reguły do zasobów platformy Azure. Usługa Azure Policy pomaga zachować zgodność tych zasobów ze standardami firmowymi i umowami dotyczącymi poziomu usług. Aby uzyskać więcej informacji, zobacz Omówienie usługi Azure Policy.
Wbudowane zasady redundancji zasobów kopii zapasowych
Aby wymusić wymagania dotyczące rezydencji danych na poziomie organizacji, możesz przypisać zasady do subskrypcji przy użyciu witryny Azure Portal lub programu Azure PowerShell.
Jeśli na przykład włączysz politykę "Azure SQL DB powinien unikać używania kopii zapasowej GRS", bazy danych nie można utworzyć z domyślną pamięcią jako globalnie nadmiarową pamięcią, i użytkownicy nie będą mogli używać GRS z komunikatami o błędach: "Konfigurowanie typu konta pamięci kopii zapasowej na 'Standard_RAGRS' nie powiodło się podczas tworzenia lub aktualizacji bazy danych".
Aby uzyskać pełną listę wbudowanych definicji zasad dla usługi SQL Database, zapoznaj się z dokumentacją zasad.
Ważne
Zasady platformy Azure nie są wymuszane podczas tworzenia bazy danych za pośrednictwem języka T-SQL. Aby określić miejsce przechowywania danych podczas tworzenia bazy danych przy użyciu języka T-SQL, użyj parametru LOCAL lub ZONE jako danych wejściowych dla parametru BACKUP_STORAGE_REDUNDANCY w instrukcji CREATE DATABASE.
Powiązana zawartość
- Aby dowiedzieć się więcej o innych rozwiązaniach ciągłości działania usługi SQL Database, zobacz Omówienie ciągłości działania.
- Aby zmienić ustawienia kopii zapasowej, zobacz Zmienianie ustawień.
- Aby przywrócić kopię zapasową, zobacz Odzyskiwanie przy użyciu kopii zapasowych lub Przywracanie bazy danych do punktu w czasie przy użyciu programu PowerShell.
- Aby uzyskać informacje o sposobie konfigurowania, zarządzania i przywracania z długoterminowego przechowywania automatycznych kopii zapasowych w usłudze Azure Blob Storage, zobacz Zarządzanie długoterminowym przechowywaniem kopii zapasowych.
- W przypadku usługi Azure SQL Managed Instance zobacz Automatyczne kopie zapasowe dla usługi SQL Managed Instance.