Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() Azure SQL Database
Azure SQL Database
W tym artykule wyjaśniono funkcję automatycznej kopii zapasowej z bazami danych w warstwie Hiperskala w usłudze Azure SQL Database.
Bazy danych w warstwie Hiperskala używają unikatowej architektury z wysoce skalowalnymi warstwami wydajności magazynu i obliczeń. Kopie zapasowe w warstwie Hiperskala są oparte na migawkach i są niemal natychmiastowe. Kopie zapasowe dzienników są przechowywane w długoterminowym magazynie platformy Azure na potrzeby okresu przechowywania kopii zapasowych.
Architektura Hiperskala nie wymaga takiego samego ciągu zależności dla kopii zapasowych jak kopie zapasowe oparte na plikach używane w SQL Server i innych poziomach bazy danych SQL, ale nadal spełnia te same wymagania dotyczące RTO i RPO. Dziennik transakcji zachowuje się w ten sam sposób i pozwala na przywracanie stanu do określonego punktu w czasie. W warstwie Hiperskala częstotliwość tworzenia kopii zapasowych, koszty magazynowania, planowanie, nadmiarowość magazynu i możliwości przywracania różnią się od innych baz danych w usłudze Azure SQL Database.
Wydajność tworzenia kopii zapasowych i przywracania
Separacja magazynu i zasobów obliczeniowych umożliwia hiperskala wypychanie operacji tworzenia kopii zapasowych i przywracania do warstwy magazynu w celu wyeliminowania zużycia zasobów w replikach obliczeniowych. Kopie zapasowe bazy danych nie mają wpływu na wydajność replik obliczeniowych podstawowych lub pomocniczych.
Operacje tworzenia i przywracania kopii zapasowych baz danych w warstwie Hiperskala są szybkie niezależnie od rozmiaru danych, ponieważ używają migawek magazynu. Tworzenie kopii zapasowej jest praktycznie natychmiastowe.
Bazę danych można przywrócić do dowolnego punktu w czasie w okresie przechowywania kopii zapasowej, wykonując następujące czynności:
- Przywracanie do odpowiednich migawek plików.
- Stosowanie dzienników transakcji w celu zapewnienia spójności transakcyjnej przywróconej bazy danych.
W związku z tym przywracanie nie jest operacją rozmiaru danych, która pozostaje taka sama. Przywracanie bazy danych w warstwie Hiperskala w tym samym regionie świadczenia usługi Azure kończy się w minutach zamiast godzin lub dni, nawet w przypadku baz danych z wieloma terabajtami.
Zmiana nadmiarowości magazynu podczas wystawiania przywracania może spowodować wydłużenie czasu przywracania, ponieważ przywracanie jest rozmiarem danych, dlatego czas jest proporcjonalny do rozmiaru bazy danych.
Tworzenie nowych baz danych przez przywrócenie istniejącej kopii zapasowej lub skopiowanie bazy danych umożliwia również rozdzielenie zasobów obliczeniowych i magazynu w warstwie Hiperskala. Kopie można tworzyć do celów programistycznych lub testowych, nawet w przypadku baz danych z wieloma terabajtami, w ciągu kilku minut w tym samym regionie, gdy używasz tego samego typu magazynu.
Przechowywanie kopii zapasowej
Domyślne krótkoterminowe przechowywanie kopii zapasowych baz danych w warstwie Hiperskala wynosi 7 dni.
Krótkoterminowe przechowywanie kopii zapasowych w zakresie od 1 do 35 dni i długoterminowe przechowywanie kopii zapasowych (LTR) dla baz danych hiperskali jest ogólnie dostępne od września 2023 r. Aby uzyskać więcej informacji, zobacz Długoterminowe przechowywanie — Azure SQL Database i Azure SQL Managed Instance.
Planowanie kopii zapasowych
Dla baz danych w warstwie Hiperskala nie są używane tradycyjne pełne i różnicowe kopie zapasowe oraz kopie zapasowe dziennika transakcji. Zamiast tego są tworzone zwykłe migawki magazynu dla plików danych.
Wygenerowane dzienniki transakcji są zachowywane zgodnie ze skonfigurowanym okresem przechowywania. W czasie przywracania odpowiednie rekordy dziennika transakcji są stosowane do przywróconej migawki magazynu. Wynikiem jest transakcyjnie spójna baza danych bez utraty danych zgodnie z określonym punktem w czasie w okresie przechowywania.
Monitorowanie użycia magazynu kopii zapasowych
W warstwie Hiperskala metryki usługi Azure Monitor raportują następujące informacje o użyciu:
- Rozmiar magazynu kopii zapasowej danych (rozmiar kopii zapasowej migawki)
- Rozmiar magazynu danych (przydzielony rozmiar bazy danych)
- Rozmiar magazynu kopii zapasowej dziennika (rozmiar kopii zapasowej dziennika transakcji)
Aby wyświetlić metryki magazynu kopii zapasowych i danych w witrynie Azure Portal, wykonaj następujące kroki:
- Przejdź do bazy danych w warstwie Hiperskala, dla której chcesz monitorować metryki tworzenia kopii zapasowych i magazynu danych.
- W sekcji Monitorowanie wybierz stronę Metryki.
- Z listy rozwijanej Metryka wybierz metryki Magazynu kopii zapasowych danych, Rozmiar magazynu danych i Magazyn kopii zapasowych dzienników z odpowiednią regułą agregacji.
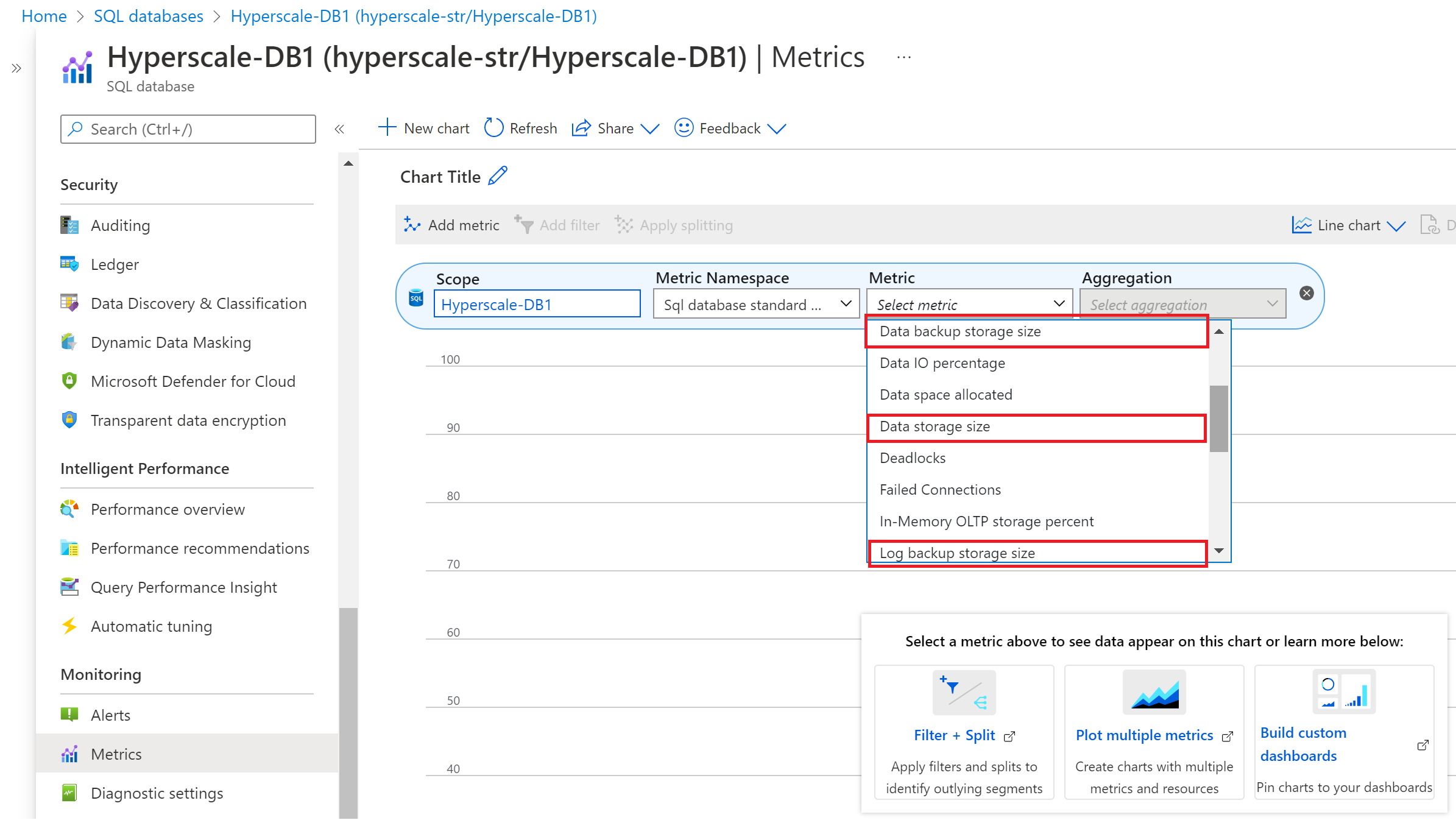
Zmniejszenie użycia magazynu kopii zapasowych
Użycie magazynu kopii zapasowych dla bazy danych w warstwie Hiperskala zależy od okresu przechowywania, wyboru regionu, nadmiarowości magazynu kopii zapasowych i typu obciążenia. Rozważ niektóre z następujących technik dostrajania, aby zmniejszyć użycie magazynu kopii zapasowych dla bazy danych w warstwie Hiperskala:
- Zmniejsz okres przechowywania kopii zapasowych do minimum dla Twoich potrzeb.
- Unikaj wykonywania dużych operacji zapisu, takich jak konserwacja indeksu, częściej niż jest to konieczne. Aby uzyskać zalecenia dotyczące konserwacji indeksu, zobacz Optymalizowanie konserwacji indeksu w celu zwiększenia wydajności zapytań i zmniejszenia zużycia zasobów.
- W przypadku dużych operacji ładowania danych rozważ użycie kompresji danych, jeśli jest to konieczne.
-
tempdbUżyj bazy danych zamiast tabel stałych w logice aplikacji, aby przechowywać tymczasowe wyniki i/lub dane przejściowe. - Użyj lokalnie nadmiarowego lub strefowo nadmiarowego magazynu kopii zapasowych, gdy możliwości przywracania geograficznego są niepotrzebne (na przykład środowiska deweloperskie/testowe).
Koszty magazynu kopii zapasowych
Koszty magazynowania kopii zapasowych w warstwie Hiperskala zależą od wyboru regionu i nadmiarowości magazynu kopii zapasowych. Zależy to również od typu obciążenia.
Obciążenia z dużą intensywnością zapisu częściej zmieniają strony danych, co powoduje zwiększenie migawek magazynu. Takie obciążenia generują również więcej dzienników transakcji, przyczyniając się do ogólnych kosztów tworzenia kopii zapasowych. Opłata za magazyn kopii zapasowych jest naliczana na podstawie gigabajtów zużywanych miesięcznie. Ilość magazynu kopii zapasowych równa rozmiarowi bazy danych jest świadczona bez dodatkowych opłat. Aby uzyskać szczegółowe informacje o cenach, zobacz stronę cennika usługi Azure SQL Database.
W przypadku warstwy Hiperskala rozliczany magazyn kopii zapasowych jest obliczany w następujący sposób:
Total billable backup storage size = (data backup storage size + log backup storage size)
Rozmiar magazynu danych nie jest uwzględniany w rozliczanej kopii zapasowej, ponieważ jest już rozliczany jako przydzielony magazyn bazy danych.
Usunięte bazy danych w warstwie Hiperskala generują koszty tworzenia kopii zapasowych w celu obsługi odzyskiwania do punktu w czasie przed usunięciem. W przypadku usuniętej bazy danych w warstwie Hiperskala rozliczany magazyn kopii zapasowych jest obliczany w następujący sposób:
Total billable backup storage size for deleted Hyperscale database = (data storage size + data backup size + log backup storage size) * (remaining backup retention period after deletion / configured backup retention period)
Rozmiar magazynu danych jest uwzględniony w formule, ponieważ przydzielony magazyn bazy danych nie jest rozliczany oddzielnie dla usuniętej bazy danych. W przypadku usuniętej bazy danych dane są przechowywane po usunięciu w celu włączenia odzyskiwania w skonfigurowanym okresie przechowywania kopii zapasowych.
Rozliczany magazyn kopii zapasowych dla usuniętej bazy danych stopniowo zmniejsza się w miarę upływu czasu po jego usunięciu. Staje się zero, gdy kopie zapasowe nie są już zachowywane, a odzyskiwanie nie jest już możliwe. Jeśli jest to trwałe usunięcie i nie potrzebujesz już kopii zapasowych, możesz zoptymalizować koszty, zmniejszając czas przechowywania przed usunięciem bazy danych.
Monitorowanie kosztów tworzenia kopii zapasowych
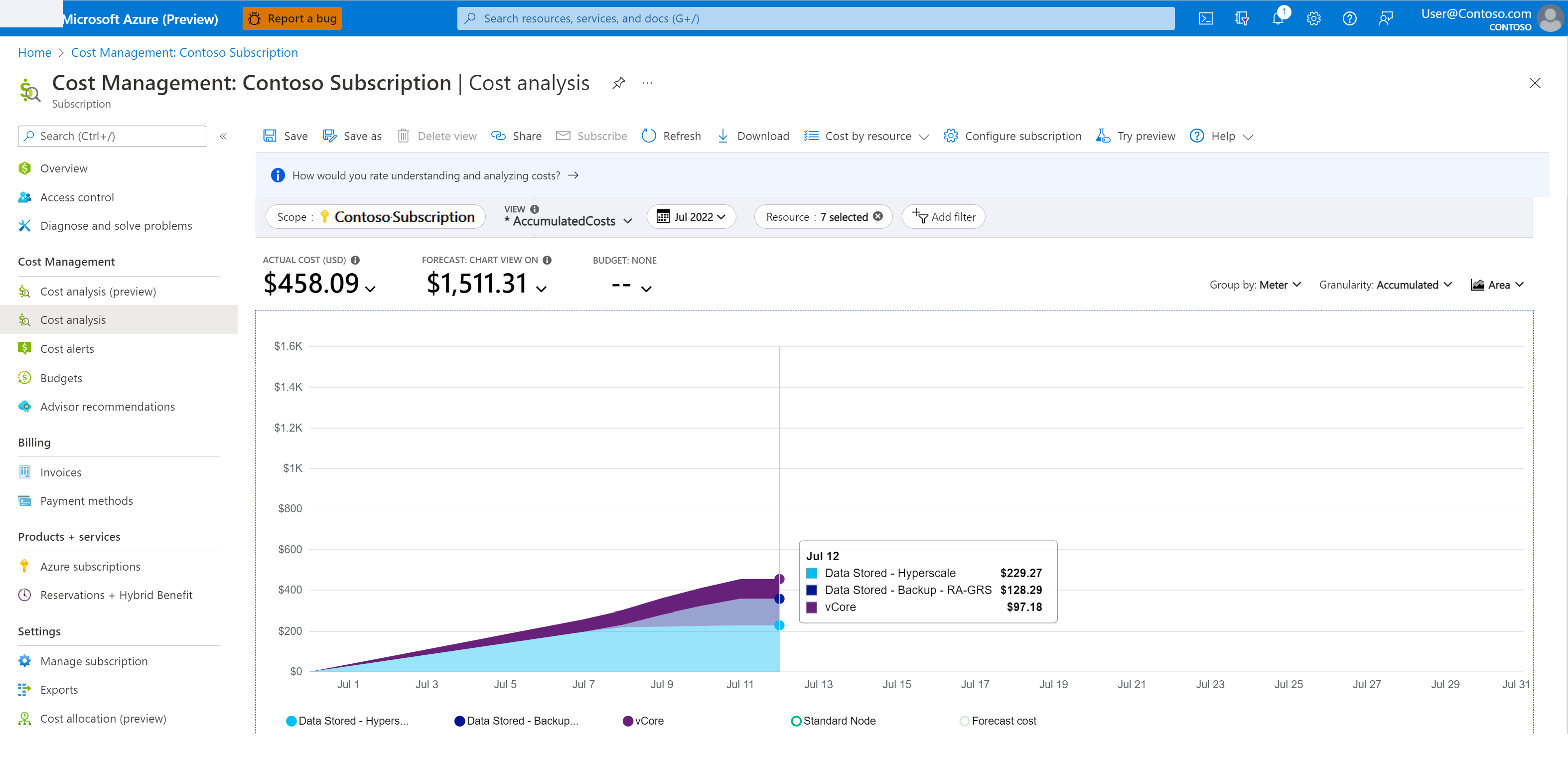
Aby zrozumieć koszty magazynu kopii zapasowych:
W witrynie Azure Portal przejdź do strony Zarządzanie kosztami i rozliczenia.
Wybierz pozycję Analiza kosztów usługi Cost Management
W polu Zakres wybierz żądaną subskrypcję.
Przefiltruj okres i usługę, którą chcesz wykonać, wykonując następujące kroki:
- Dodaj filtr dla nazwy usługi.
- Z listy rozwijanej wybierz pozycję sql-database .
- Dodaj kolejny filtr miernika.
- Aby monitorować koszty tworzenia kopii zapasowych na potrzeby odzyskiwania do punktu w czasie, wybierz z listy rozwijanej pozycję Dane przechowywane — kopia zapasowa — RA .
Poniższy zrzut ekranu przedstawia przykładową analizę kosztów.
Nadmiarowość magazynu danych i kopii zapasowych
Warstwa Hiperskala obsługuje konfigurowalną nadmiarowość magazynu. Podczas tworzenia bazy danych w warstwie Hiperskala możesz wybrać preferowany typ magazynu: magazyn geograficznie nadmiarowy dostępny do odczytu (RA-GZRS), magazyn geograficznie nadmiarowy dostępny do odczytu (RA-GRS), magazyn strefowo nadmiarowy (ZRS) lub magazyn lokalnie nadmiarowy (LRS).
- Magazyn geograficznie nadmiarowy: kopiuje kopie zapasowe synchronicznie w trzech strefach dostępności platformy Azure w regionie podstawowym. podobnie jak magazyn strefowo nadmiarowy (ZRS). Ponadto dane są kopiowane asynchronicznie do pojedynczej lokalizacji fizycznej w sparowanym regionie pomocniczym. Jest ona obecnie dostępna tylko w niektórych regionach.
Aby uzyskać więcej informacji na temat replikowania kopii zapasowych dla innych typów magazynu, zobacz Nadmiarowość magazynu kopii zapasowych.
Ponieważ hiperskala używa migawek magazynu do tworzenia kopii zapasowych, dane i kopie zapasowe współużytkuje to samo konto magazynu. W związku z tym wybrana nadmiarowość magazynu kopii zapasowych ma zastosowanie zarówno dla danych, jak i kopii zapasowych.
Uwaga
Podczas tworzenia bazy danych w warstwie Hiperskala należy dokładnie rozważyć nadmiarowość magazynu kopii zapasowych, ponieważ można ją ustawić tylko podczas tworzenia bazy danych. Nie można zmodyfikować tego ustawienia po aprowizacji zasobu.
Użyj aktywnej replikacji geograficznej, aby zaktualizować ustawienia nadmiarowości magazynu kopii zapasowych dla istniejącej bazy danych w warstwie Hiperskala z minimalnym przestojem. Alternatywnie możesz użyć kopii bazy danych.
Ostrzeżenie
- Przywracanie geograficzne jest wyłączone natychmiast po zaktualizowaniu bazy danych w celu korzystania z magazynu lokalnie nadmiarowego lub strefowo nadmiarowego.
- Magazyn strefowo nadmiarowy jest obecnie dostępny tylko w niektórych regionach.
- Magazyn geograficznie nadmiarowy jest obecnie dostępny tylko w niektórych regionach.
Przywracanie bazy danych w warstwie Hiperskala do innego regionu
Może być konieczne przywrócenie bazy danych w warstwie Hiperskala do regionu innego niż bieżący region. Typowe przyczyny to operacja odzyskiwania po awarii lub przechodzenie do szczegółów lub relokacja. Podstawową metodą jest wykonywanie przywracania geograficznego bazy danych. Te same kroki, których należy użyć do przywrócenia dowolnej innej bazy danych w usłudze Azure SQL Database do innego regionu:
- Utwórz serwer w regionie docelowym, jeśli nie masz jeszcze odpowiedniego serwera. Ten serwer powinien być własnością tej samej subskrypcji co oryginalny (źródłowy) serwer.
- Postępuj zgodnie z instrukcjami w sekcji przywracania geograficznego strony dotyczącej przywracania bazy danych w usłudze Azure SQL Database z automatycznych kopii zapasowych.
Uwaga
Ponieważ źródło i element docelowy znajdują się w oddzielnych regionach, baza danych nie może współużytkować magazynu migawek ze źródłową bazą danych, tak jak w przypadku przywracania innych niż geograficzne. Przywracanie niezwiązane z obszarem geograficznym kończy się szybko niezależnie od rozmiaru bazy danych.
Przywracanie geograficzne bazy danych w warstwie Hiperskala jest operacją zależną od rozmiaru danych, nawet jeśli obiekt docelowy znajduje się w sparowanym regionie magazynu replikowanego geograficznie. W związku z tym przywracanie geograficzne zajmie znacznie dłuższy czas w porównaniu z przywracaniem do punktu w czasie w tym samym regionie.
Jeśli obiekt docelowy znajduje się w sparowanym regionie, transfer danych będzie znajdować się w regionie. Ten transfer będzie znacznie szybszy niż transfer danych między regionami. Jednak nadal będzie to operacja rozmiaru danych.
Jeśli wolisz, możesz skopiować bazę danych do innego regionu. Użyj tej metody, jeśli przywracanie geograficzne nie jest dostępne, ponieważ nie jest obsługiwane w przypadku wybranego typu nadmiarowości magazynu. Aby uzyskać szczegółowe informacje, zobacz Kopiowanie bazy danych dla warstwy Hiperskala.
Powiązana zawartość
Kopie zapasowe bazy danych są istotną częścią każdej strategii ciągłości biznesowej i odzyskiwania po awarii, ponieważ pomagają chronić dane przed przypadkowym uszkodzeniem lub usunięciem.
- Omówienie ciągłości działalności biznesowej w usłudze Azure SQL Database
- Zarządzanie długoterminowym przechowywaniem kopii zapasowych usługi Azure SQL Database
- Przywracanie bazy danych z kopii zapasowej w usłudze Azure SQL Database
- Przywracanie bazy danych do wcześniejszego punktu w czasie przy użyciu programu PowerShell