Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() Azure SQL Database
Azure SQL Database
W tym artykule opisano sposób migrowania bazy danych w usłudze Azure SQL Database z modelu zakupów opartego na jednostkach DTU do modelu zakupów opartego na rdzeniach wirtualnych.
Migrowanie bazy danych
Migrowanie bazy danych z modelu zakupu opartego na jednostkach DTU do modelu zakupu opartego na rdzeniach wirtualnych jest podobne do skalowania między poziomami usługowymi w warstwach usług Podstawowa, Standardowa i Premium, z podobnym czasem trwania i minimalnym przestojem na końcu procesu migracji. pl-PL: Baza danych zmigrowana do modelu zakupów opartego na vCore może zostać zmigrowana z powrotem do modelu zakupów opartego na DTU w dowolnym momencie przy użyciu tych samych kroków, z wyjątkiem baz danych migrowanych do warstwy usługi Hyperscale.
Bazę danych można migrować do innego modelu zakupów przy użyciu witryny Azure Portal, programu PowerShell, interfejsu wiersza polecenia platformy Azure i języka Transact-SQL.
Aby przeprowadzić migrację bazy danych do innego modelu zakupów przy użyciu witryny Azure Portal, wykonaj następujące kroki:
Przejdź do bazy danych SQL w witrynie Azure Portal.
Wybierz Obliczenia i przechowywanie w obszarze Ustawienia.
Użyj listy rozwijanej w obszarze Warstwa usługi, aby wybrać nowy model zakupów i warstwę usług:
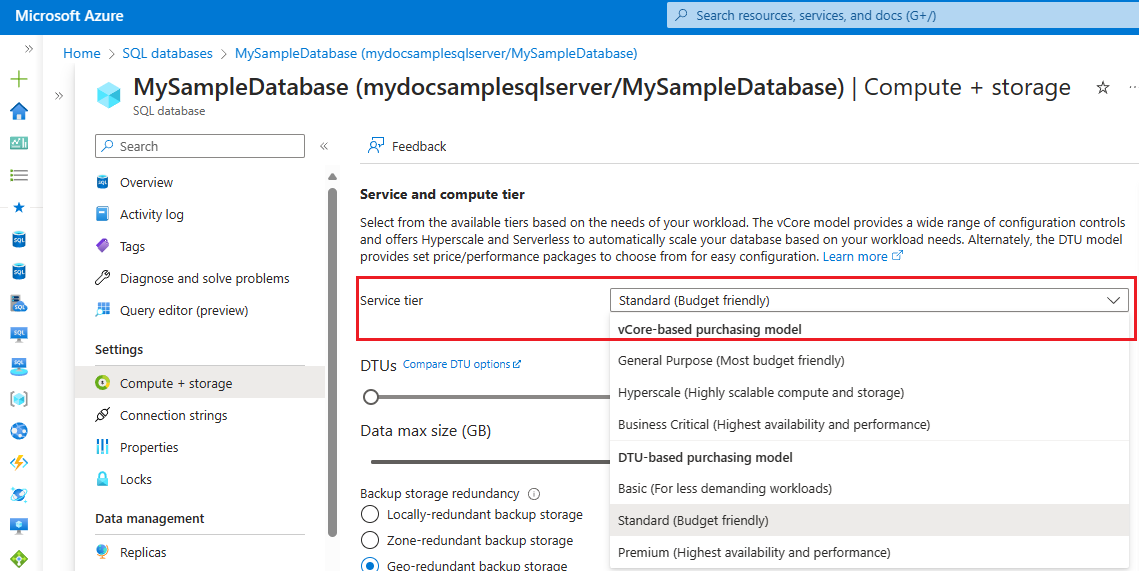

Wybierz warstwę usługi vCore i cel usługi
W przypadku większości scenariuszy migracji jednostek DTU do rdzeni wirtualnych bazy danych i pul elastycznych w warstwach usług Podstawowa i Standardowa są mapowane na warstwę usługi Ogólnego Przeznaczenia. Bazy danych i elastyczne pule w warstwie usługi Premium są mapowane na warstwę usługi Krytyczne dla działania firmy. W zależności od scenariusza i wymagań aplikacji warstwa usługi Hiperskala może być często używana jako cel migracji dla baz danych i elastycznych pul we wszystkich warstwach usług DTU.
Aby wybrać cel usługi lub rozmiar obliczeniowy, dla zmigrowanej bazy danych w modelu rdzeni wirtualnych można użyć podstawowej, ale przybliżonej reguły kciuka: co 100 jednostek DTU w warstwach Podstawowa lub Standardowa wymaga co najmniej 1 rdzeni wirtualnych, a co 125 jednostek DTU w warstwie Premium wymaga co najmniej 1 rdzeni wirtualnych.
Napiwek
Ta reguła jest przybliżona, ponieważ nie uwzględnia określonego typu sprzętu używanego dla bazy danych DTU lub elastycznej puli.
W modelu DTU system może wybrać dowolną dostępną konfigurację sprzętową dla bazy danych lub elastycznej puli. Ponadto w modelu DTU masz tylko pośrednią kontrolę nad liczbą rdzeni wirtualnych (procesorów logicznych), wybierając wyższą lub niższą liczbę jednostek DTU lub eDTU.
W modelu rdzeni wirtualnych klienci muszą dokonać wyraźnego wyboru zarówno konfiguracji sprzętu, jak i liczby rdzeni wirtualnych (procesorów logicznych). Chociaż model DTU nie oferuje tych opcji, typ sprzętu i liczba logicznych CPU używanych dla każdej bazy danych i elastycznej puli zasobów są widoczne za pośrednictwem dynamicznych widoków zarządzania. Dzięki temu można dokładniej określić pasujący parametr usługi vCore.
Poniższe podejście wykorzystuje te informacje do określenia celu usługi rdzeni wirtualnych z podobną alokacją zasobów w celu uzyskania podobnego poziomu wydajności po migracji do modelu rdzeni wirtualnych.
Mapowanie jednostek DTU na rdzenie wirtualne
Następujące zapytanie Języka Transact-SQL, wykonywane w kontekście bazy danych DTU do zmigrowania, zwraca zgodną (prawdopodobnie ułamkową) liczbę rdzeni wirtualnych w każdej konfiguracji sprzętu w modelu rdzeni wirtualnych. Tę liczbę można zaokrąglić do najbliższej liczby rdzeni wirtualnych dostępnych dla baz danych i elastycznych pul w każdej konfiguracji sprzętu w modelu rdzeni wirtualnych. Klienci mogą wybrać cel usługi rdzeni wirtualnych, który jest najbliższym dopasowaniem dla bazy danych DTU lub elastycznej puli.
Przykładowe scenariusze migracji korzystające z tego podejścia zostały opisane w sekcji Przykłady .
Wykonaj to zapytanie w kontekście bazy danych, która ma zostać zmigrowana, a nie w master bazie danych. Podczas migracji elastycznej puli, wykonaj zapytanie w kontekście dowolnej z baz danych w tej puli.
;WITH dtu_vcore_map
AS (
SELECT rg.slo_name,
CAST(DATABASEPROPERTYEX(DB_NAME(), 'Edition') AS NVARCHAR(40)) COLLATE DATABASE_DEFAULT AS dtu_service_tier,
CASE
WHEN slo.slo_name LIKE '%SQLG4%' THEN 'Gen4' --Gen4 is retired.
WHEN slo.slo_name LIKE '%SQLGZ%' THEN 'Gen4' --Gen4 is retired.
WHEN slo.slo_name LIKE '%SQLG5%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%SQLG6%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%SQLG7%' THEN 'standard_series'
WHEN slo.slo_name LIKE '%GPGEN8%' THEN 'standard_series'
END COLLATE DATABASE_DEFAULT AS dtu_hardware_gen,
s.scheduler_count * CAST(rg.instance_cap_cpu / 100. AS DECIMAL(3, 2)) AS dtu_logical_cpus,
CAST((jo.process_memory_limit_mb / s.scheduler_count) / 1024. AS DECIMAL(4, 2)) AS dtu_memory_per_core_gb
FROM sys.dm_user_db_resource_governance AS rg
CROSS JOIN (
SELECT COUNT(1) AS scheduler_count
FROM sys.dm_os_schedulers
WHERE status COLLATE DATABASE_DEFAULT = 'VISIBLE ONLINE'
) AS s
CROSS JOIN sys.dm_os_job_object AS jo
CROSS APPLY (SELECT UPPER(rg.slo_name) COLLATE DATABASE_DEFAULT AS slo_name) slo
WHERE rg.dtu_limit > 0
AND DB_NAME() COLLATE DATABASE_DEFAULT <> 'master'
AND rg.database_id = DB_ID()
)
SELECT dtu_logical_cpus,
dtu_memory_per_core_gb,
dtu_service_tier,
CASE
WHEN dtu_service_tier = 'Basic' THEN 'General Purpose'
WHEN dtu_service_tier = 'Standard' THEN 'General Purpose or Hyperscale'
WHEN dtu_service_tier = 'Premium' THEN 'Business Critical or Hyperscale'
END AS vcore_service_tier,
CASE
WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus * 1.7
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus
END AS standard_series_vcores,
5.05 AS standard_series_memory_per_core_gb,
CASE
WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus * 0.8
END AS Fsv2_vcores,
1.89 AS Fsv2_memory_per_core_gb,
CASE
WHEN dtu_hardware_gen = 'Gen4' THEN dtu_logical_cpus * 1.4
WHEN dtu_hardware_gen = 'standard_series' THEN dtu_logical_cpus * 0.9
END AS M_vcores,
29.4 AS M_memory_per_core_gb
FROM dtu_vcore_map;
Dodatkowe czynniki
Oprócz liczby rdzeni wirtualnych (procesorów logicznych) i typu sprzętu kilka innych czynników może mieć wpływ na wybór celu usługi rdzeni wirtualnych:
Mapowanie zapytania Transact-SQL odpowiada celom jednostek DTU i usług rdzeni wirtualnych pod względem ich pojemności procesora CPU, dlatego wyniki są dokładniejsze dla obciążeń powiązanych z procesorem CPU.
Dla tego samego typu sprzętu i tej samej liczby rdzeni wirtualnych, limity zasobów dla przepustowości IOPS oraz dziennika transakcji dla baz danych z rdzeniami wirtualnymi często są wyższe niż dla baz danych opartych na DTU. W przypadku obciążeń związanych z operacjami we/wy może być możliwe obniżenie liczby rdzeni wirtualnych w modelu rdzeni wirtualnych w celu osiągnięcia tego samego poziomu wydajności. Rzeczywiste limity zasobów dla baz danych DTU i vCore są uwidocznione w widoku sys.dm_user_db_resource_governance. Porównanie tych wartości między bazą danych lub pulą jednostek DTU do zmigrowania a bazą danych lub pulą rdzeni wirtualnych z celem serwisowym, który mniej więcej odpowiada, może pomóc dokładniej wybrać cel serwisowy rdzeni wirtualnych.
Zapytanie mapowania zwraca również ilość pamięci na rdzeń dla bazy danych DTU lub elastycznej puli do zmigrowania oraz dla każdej konfiguracji sprzętu w modelu vCore. Zapewnienie podobnej lub większej całkowitej ilości pamięci po migracji do rdzeni wirtualnych jest ważne w przypadku obciążeń wymagających dużej pamięci podręcznej danych w celu osiągnięcia wystarczającej wydajności lub obciążeń wymagających dużych przydziałów pamięci na potrzeby przetwarzania zapytań. W przypadku takich obciążeń w zależności od rzeczywistej wydajności może być konieczne zwiększenie liczby rdzeni wirtualnych w celu uzyskania wystarczającej całkowitej ilości pamięci.
Historyczne wykorzystanie zasobów bazy danych DTU należy wziąć pod uwagę podczas wybierania celu usługi rdzeni wirtualnych. Bazy danych DTU ze stale niedostatecznie wykorzystywanymi zasobami CPU mogą wymagać mniejszej liczby rdzeni wirtualnych (vCores) niż liczba zwracana przez zapytanie mapowania. Z drugiej strony bazy danych DTU, w których wysokie zużycie procesora CPU powoduje niewystarczającą wydajność obciążenia, mogą wymagać więcej rdzeni wirtualnych niż zwracają zapytania.
W przypadku migrowania baz danych z sporadycznymi lub nieprzewidywalnymi wzorcami użycia rozważ użycie bezserwerowej warstwy obliczeniowej dla warstwy obliczeniowej usługi Azure SQL Database . Maksymalna liczba współbieżnych pracowników w trybie bezserwerowym wynosi 75% limitu w aprowizowanych obliczeniach dla tej samej liczby skonfigurowanych maksymalnych rdzeni wirtualnych (vCores). Ponadto maksymalna ilość pamięci dostępnej w trybie bezserwerowym wynosi 3 GB razy maksymalną liczbę skonfigurowanych rdzeni wirtualnych, co jest mniejsze niż pamięć na rdzeń dla skonfigurowanych zasobów obliczeniowych. Na przykład maksymalna pamięć gen5 wynosi 120 GB, gdy maksymalnie 40 rdzeni wirtualnych jest skonfigurowanych w trybie bezserwerowym, a 204 GB dla aprowizowanego procesora obliczeniowego z 40 rdzeniami wirtualnymi.
W modelu rdzeni wirtualnych obsługiwany maksymalny rozmiar bazy danych może się różnić w zależności od sprzętu. W przypadku dużych baz danych sprawdź obsługiwane maksymalne rozmiary w modelu rdzeni wirtualnych dla pojedynczych baz danych i pul elastycznych.
W przypadku pul elastycznych limity zasobów dla pul elastycznych przy użyciu modelu zakupu jednostek DTU i modeli zakupu vCore różnią się pod względem maksymalnej obsługiwanej liczby baz danych na pulę. Należy to wziąć pod uwagę podczas migracji elastycznych pul z wieloma bazami danych.
Niektóre konfiguracje sprzętowe mogą nie być dostępne w każdym regionie. Sprawdź dostępność w obszarze Konfiguracja sprzętu dla usługi SQL Database.
Wytyczne dotyczące dopasowania jednostek DTU do rdzeni wirtualnych podane w tej części pomagają w początkowym oszacowaniu docelowego zadania usługi bazy danych.
Optymalna konfiguracja docelowej bazy danych jest zależna od obciążenia. W związku z tym, aby osiągnąć optymalny stosunek ceny/wydajności po migracji, może być konieczne użycie elastyczności modelu rdzeni wirtualnych w celu dostosowania liczby rdzeni wirtualnych, konfiguracji sprzętu i warstw usług i obliczeń. Może być również konieczne dostosowanie parametrów konfiguracji bazy danych, takich jak maksymalny stopień równoległości i/lub zmiana poziomu zgodności bazy danych w celu włączenia ostatnich ulepszeń aparatu bazy danych.
Przykłady migracji z DTU na rdzenie wirtualne
Uwaga
Wartości w poniższych przykładach są przeznaczone tylko do celów ilustracyjnych. Rzeczywiste wartości zwracane w opisanych scenariuszach mogą być inne.
Migrowanie standardowej bazy danych S9
Zapytanie mapowania zwraca następujący wynik (niektóre kolumny nie są wyświetlane w celu zwięzłości):
| dtu_logical_cpus | pamięć_dtu_na_rdzeń_gb | standard_series_vcores | seria_standardowa_pamięć_na_rdzeń_gb |
|---|---|---|---|
| 24.00 | 5,40 | 24.000 | 5,05 |
Widzimy, że standardowa baza danych DTU ma 24 procesory logiczne (rdzenie wirtualne), z 5,4 GB pamięci na rdzeń wirtualny. Bezpośrednim odpowiednikiem tego jest baza danych ogólnego przeznaczenia z 2 rdzeniami wirtualnymi na sprzęcie serii Standard (Gen5), z celem usługi GP_Gen5_24.
Migrowanie standardowej bazy danych S0
Zapytanie mapowania zwraca następujący wynik (niektóre kolumny nie są wyświetlane w celu zwięzłości):
| dtu_logical_cpus | pamięć_dtu_na_rdzeń_gb | standard_series_vcores | seria_standardowa_pamięć_na_rdzeń_gb |
|---|---|---|---|
| 0.25 | 1.3 | 0.500 | 5,05 |
Widzimy, że baza danych DTU ma odpowiednik 0,25 procesorów logicznych (rdzeni wirtualnych), z 1,3 GB pamięci na rdzeń wirtualny. Najmniejsze cele usługi rdzeni wirtualnych w konfiguracji sprzętowej serii standardowej (Gen5), GP_Gen5_2, oferują więcej mocy obliczeniowej niż standardowa baza danych S0, dlatego nie jest możliwe ich bezpośrednie porównanie. Preferowana jest opcja GP_Gen5_2 . Ponadto jeśli obciążenie jest odpowiednie dla bezserwerowej warstwy obliczeniowej, GP_S_Gen5_1 byłoby bliżej dopasowane.
Migrowanie bazy danych Premium P15
Zapytanie mapowania zwraca następujący wynik (niektóre kolumny nie są wyświetlane w celu zwięzłości):
| dtu_logical_cpus | pamięć_dtu_na_rdzeń_gb | standard_series_vcores | seria_standardowa_pamięć_na_rdzeń_gb |
|---|---|---|---|
| 42.00 | 4.86 | 42.000 | 5,05 |
Widzimy, że baza danych DTU ma 42 procesory logiczne (rdzenie wirtualne), z 4,86 GB pamięci na rdzeń wirtualny. Chociaż nie ma celu usługi rdzeni wirtualnych z 42 rdzeniami, cel usługi BC_Gen5_40 jest prawie równoważny pod względem wydajności procesora CPU i pamięci i jest dobrym dopasowaniem.
Migrowanie podstawowej puli elastycznej 200 eDTU
Zapytanie mapowania zwraca następujący wynik (niektóre kolumny nie są wyświetlane w celu zwięzłości):
| dtu_logical_cpus | pamięć_dtu_na_rdzeń_gb | standard_series_vcores | seria_standardowa_pamięć_na_rdzeń_gb |
|---|---|---|---|
| 4,00 | 5,40 | 4000 | 5,05 |
Widzimy, że elastyczna pula DTU ma 4 logiczne procesory CPU (rdzenie wirtualne), z 5,4 GB pamięci na rdzeń wirtualny. Sprzęt serii Standard wymaga 4 rdzeni wirtualnych, ale parametr usługi obsługuje maksymalnie 200 baz danych na pulę, podczas gdy elastyczna pula 200 eDTU w wersji Podstawowa obsługuje maksymalnie 500 baz danych. Jeśli migrowana elastyczna pula ma ponad 200 baz danych, pasujący cel usługi rdzeni wirtualnych musi być GP_Gen5_6, który obsługuje maksymalnie 500 baz danych.
Migrowanie baz danych replikowanych geograficznie
Migracja z modelu opartego na jednostkach DTU do modelu zakupów opartego na rdzeniach wirtualnych jest podobna do uaktualniania lub obniżania relacji replikacji geograficznej między bazami danych w warstwach usług Standardowa i Premium. Podczas migracji nie trzeba zatrzymywać replikacji geograficznej dla warstw Ogólnego Przeznaczenia i Krytyczne dla Biznesu, ale należy przestrzegać następujących reguł sekwencjonowania:
- Podczas uaktualniania należy najpierw uaktualnić pomocniczą bazę danych, a następnie uaktualnić bazę podstawową.
- Podczas obniżania poziomu należy odwrócić kolejność: najpierw obniż podstawową bazę danych, a następnie pomocniczą.
Aby przekonwertować bazę danych na warstwę usługi Hiperskala, replikacja geograficzna powinna zostać tymczasowo usunięta. Możliwość konwertowania zreplikowanej geograficznie bazy danych spoza usługi Hyperscale na Hyperscale przy użyciu T-SQL, API REST, PowerShell lub Azure CLI jest obecnie funkcją w wersji zapoznawczej. Aby uzyskać więcej informacji, zobacz Konwertowanie istniejącej bazy danych na Hiperskalę.
W przypadku korzystania z replikacji geograficznej między dwiema elastycznymi pulami zalecamy wyznaczenie jednej puli jako podstawowej i drugiej jako pomocniczej. W takim przypadku podczas migracji elastycznych pul należy użyć tych samych wskazówek dotyczących sekwencjonowania. Jeśli jednak masz elastyczne pule zawierające zarówno podstawowe, jak i pomocnicze bazy danych, należy traktować pulę z wyższym wykorzystaniem jako podstawową i odpowiednio postępować zgodnie z regułami sekwencjonowania.
Poniższa tabela zawiera wskazówki dotyczące określonych scenariuszy migracji:
| Bieżąca warstwa usługi | Docelowa warstwa usługi | Typ migracji | Akcje użytkownika |
|---|---|---|---|
| Standard | Ogólnego przeznaczenia | Boczny | Można przeprowadzić migrację w dowolnej kolejności, ale należy zapewnić odpowiednie rozmiary rdzeni wirtualnych zgodnie z wcześniejszym opisem |
| Premium | Krytyczne dla działania firmy | Boczny | Można przeprowadzić migrację w dowolnej kolejności, ale należy zapewnić odpowiednie rozmiary rdzeni wirtualnych zgodnie z wcześniejszym opisem |
| Standard | Krytyczne dla działania firmy | Modernizacja | Najpierw należy przeprowadzić migrację drugorzędną |
| Krytyczne dla działania firmy | Standard | Zmiana na starszą lub mniej zaawansowaną wersję | Najpierw przeprowadź migrację podstawowego elementu. |
| Premium | Ogólnego przeznaczenia | Zmiana na starszą lub mniej zaawansowaną wersję | Najpierw przeprowadź migrację podstawowego elementu. |
| Ogólnego przeznaczenia | Premium | Modernizacja | Najpierw należy przeprowadzić migrację drugorzędną |
| Krytyczne dla działania firmy | Ogólnego przeznaczenia | Zmiana na starszą lub mniej zaawansowaną wersję | Najpierw przeprowadź migrację podstawowego elementu. |
| Ogólnego przeznaczenia | Krytyczne dla działania firmy | Modernizacja | Najpierw należy przeprowadzić migrację drugorzędną |
| Standard | Hiperskala | Boczny | Wyłączenie replikacji geograficznej przed migracją do Hyperscale |
| Premium | Hiperskala | Boczny | Wyłączenie replikacji geograficznej przed migracją do Hyperscale |
Migrowanie grup przełączania awaryjnego
Migracja grup trybu failover z wieloma bazami danych wymaga indywidualnej migracji podstawowych i pomocniczych baz danych. W trakcie tego procesu mają zastosowanie te same zagadnienia i reguły sekwencjonowania. Po przekonwertowaniu baz danych na model zakupów oparty na rdzeniach wirtualnych grupa trybu failover pozostanie aktywna z tymi samymi ustawieniami zasad.
Utwórz wtórną bazę danych do replikacji geograficznej
Dodatkową bazę danych replikacji geograficznej (pomocniczą geograficzną) można utworzyć tylko przy użyciu tej samej warstwy usługi, która była używana dla podstawowej bazy danych. W przypadku baz danych o wysokim współczynniku generowania dzienników zalecamy utworzenie pomocniczego obszaru geograficznego o takim samym rozmiarze obliczeniowym jak podstawowy.
W przypadku utworzenia drugorzędnego regionu geograficznego w elastycznej puli dla pojedynczej podstawowej bazy danych upewnij się, że maxVCore ustawienie puli jest zgodne z rozmiarem obliczeniowym podstawowej bazy danych. Jeśli tworzysz obszar pomocniczy dla obszaru głównego w innej elastycznej puli, zalecamy, aby pule miały te same maxVCore ustawienia.
Migrowanie z jednostek DTU do rdzeni wirtualnych przy użyciu kopiowania bazy danych
Kopia bazy danych tworzy transakcyjnie spójną migawkę danych w określonym momencie po rozpoczęciu operacji kopiowania. Nie synchronizuje danych między źródłem a obiektem docelowym po tym punkcie w czasie.
Dowolną bazę danych z rozmiarem obliczeniowym opartym na jednostkach DTU można skopiować do bazy danych o rozmiarze obliczeniowym opartym na rdzeniach wirtualnych przy użyciu PowerShell, Azure CLI lub Transact-SQL, bez ograniczeń lub specjalnego sekwencjonowania, o ile docelowy rozmiar obliczeniowy obsługuje maksymalny rozmiar bazy danych źródłowej. Kopiowanie bazy danych do innej warstwy usługi nie jest obsługiwane w witrynie Azure Portal.