Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() Azure SQL Database
Azure SQL Database
Ten artykuł zawiera omówienie zarządzania zasobami w usłudze Azure SQL Database. Zawiera on informacje na temat tego, co się stanie po osiągnięciu limitów zasobów i opisuje mechanizmy zapewniania ładu zasobów, które są używane do wymuszania tych limitów.
Aby uzyskać informacje o określonych limitach zasobów na warstwę cenową dla pojedynczych baz danych, zapoznaj się z jednym z następujących elementów:
- Limity zasobów pojedynczej bazy danych oparte na jednostkach DTU
- Limity zasobów pojedynczej bazy danych oparte na rdzeniach wirtualnych
W przypadku limitów zasobów puli elastycznej zapoznaj się z jedną z następujących czynności:
- Limity zasobów elastycznej puli opartej na jednostkach DTU
- Limity zasobów elastycznej puli opartej na rdzeniach wirtualnych
W przypadku limitów dedykowanej puli SQL usługi Azure Synapse Analytics zobacz:
- Limity pojemności
- Limity pamięci i współbieżności.
Limity rdzeni wirtualnych subskrypcji na region
Od marca 2024 r. subskrypcje mają następujące limity rdzeni wirtualnych na region na subskrypcję:
| Typ subskrypcji | Domyślne limity rdzeni wirtualnych |
|---|---|
| Umowa Korporacyjna (EA) | 2000 |
| Bezpłatne wersje próbne | 10 |
| Firma Microsoft dla startupów | 100 |
| MSDN/ MPN / Imagine / AzurePass / Azure for Students | 40 |
| Płatność zgodnie z rzeczywistym użyciem | 150 |
Rozważ następujące źródła:
- Te limity mają zastosowanie do nowych i istniejących subskrypcji.
- Bazy danych i pule elastyczne aprowidowane za pomocą modelu zakupów JEDNOSTEK DTU są liczone względem limitu przydziału rdzeni wirtualnych i na odwrót. Każdy użyty rdzeń wirtualny jest uznawany za równoważny 100 jednostek DTU używanych dla limitu przydziału na poziomie serwera.
- Domyślne limity obejmują zarówno rdzenie wirtualne skonfigurowane dla aprowizowanych baz danych obliczeniowych/ elastycznych pul, jak i maksymalne rdzenie wirtualne skonfigurowane dla baz danych bezserwerowych.
- Użycie subskrypcji — pobierz wywołanie interfejsu API REST w celu określenia bieżącego użycia rdzeni wirtualnych dla subskrypcji.
- Aby zażądać wyższego limitu przydziału rdzeni wirtualnych niż domyślny, prześlij nowe żądanie pomocy technicznej w witrynie Azure Portal. Aby uzyskać więcej informacji, zobacz Zwiększanie limitu przydziału żądań dla usług Azure SQL Database i SQL Managed Instance.
Limity serwerów logicznych
| Zasób | Ograniczenie |
|---|---|
| Bazy danych na serwer logiczny | pięć tysięcy |
| Domyślna liczba serwerów logicznych na subskrypcję w regionie | 250 |
| Maksymalna liczba serwerów logicznych na subskrypcję w regionie | 250 |
| Maksymalna liczba elastycznych pul na serwer logiczny | Ograniczone przez liczbę jednostek DTU lub rdzeni wirtualnych. Jeśli na przykład każda pula ma 1000 jednostek DTU, serwer może obsługiwać 54 pule. |
Ważne
Ponieważ liczba baz danych zbliża się do limitu na serwer logiczny, mogą wystąpić następujące elementy:
- Zwiększenie opóźnienia w uruchamianiu
masterzapytań względem bazy danych. Obejmuje to widoki statystyk wykorzystania zasobów, takich jaksys.resource_stats. - Zwiększenie opóźnienia operacji zarządzania i renderowania punktów widoków portalu, które obejmują wyliczanie baz danych na serwerze.
Co się stanie po osiągnięciu limitów zasobów
Procesor obliczeniowy
Gdy wykorzystanie procesora CPU w bazie danych staje się wysokie, zwiększa się opóźnienie zapytań, a zapytania mogą nawet przekraczać limit czasu. W tych warunkach zapytania mogą być kolejkowane przez usługę i udostępniane zasoby do wykonania, gdy zasoby stają się bezpłatne.
Jeśli obserwujesz wysokie wykorzystanie zasobów obliczeniowych, opcje ograniczania ryzyka obejmują:
- Zwiększenie rozmiaru obliczeniowego bazy danych lub elastycznej puli w celu zapewnienia bazy danych większej ilości zasobów obliczeniowych. Zobacz Skalowanie zasobów pojedynczej bazy danych i Skalowanie zasobów elastycznej puli.
- Optymalizowanie zapytań w celu zmniejszenia wykorzystania zasobów procesora CPU dla każdego zapytania. Aby uzyskać więcej informacji, zobacz Podpowiedzi i dostrajanie zapytań.
Przechowywanie danych
Gdy używane miejsce danych osiągnie maksymalny limit rozmiaru danych, na poziomie bazy danych lub na poziomie elastycznej puli, wstawia i aktualizuje, które zwiększają rozmiar danych, a klienci otrzymują komunikat o błędzie . Instrukcje SELECT i DELETE pozostają nienaruszone.
W warstwach usług Premium i Krytyczne dla działania firmy klienci otrzymują również komunikat o błędzie, jeśli łączne użycie magazynu według danych, dziennika transakcji i tempdb pojedynczej bazy danych lub elastycznej puli przekracza maksymalny rozmiar magazynu lokalnego. Aby uzyskać więcej informacji, zobacz Zarządzanie miejscem do magazynowania.
Jeśli obserwujesz wysokie wykorzystanie miejsca do magazynowania, dostępne są następujące opcje ograniczania ryzyka:
- Zwiększ maksymalny rozmiar bazy danych lub elastycznej puli albo przeprowadź skalowanie w górę do celu usługi przy użyciu większego maksymalnego limitu rozmiaru danych. Zobacz Skalowanie zasobów pojedynczej bazy danych i Skalowanie zasobów elastycznej puli.
- Jeśli baza danych znajduje się w elastycznej puli, alternatywnie bazę danych można przenieść poza pulę, aby jej miejsce do magazynowania nie było współużytkowane z innymi bazami danych.
- Zmniejsz bazę danych, aby odzyskać nieużywane miejsce. Aby uzyskać więcej informacji, zobacz Zarządzanie miejscem na pliki dla baz danych.
- W pulach elastycznych zmniejszanie bazy danych zapewnia więcej miejsca do magazynowania dla innych baz danych w puli.
- Sprawdź, czy wysokie wykorzystanie miejsca jest spowodowane wzrostem rozmiaru magazynu wersji trwałych (PVS). PvS jest częścią każdej bazy danych i służy do implementowania przyspieszone odzyskiwanie bazy danych. Aby określić bieżący rozmiar pvS, zobacz Rozwiązywanie problemów z przyspieszonym odzyskiwaniem bazy danych. Częstą przyczyną dużego rozmiaru PVS jest transakcja, która jest otwarta przez długi czas (godziny), uniemożliwiając czyszczenie starszych wersji wierszy w pvS.
- W przypadku baz danych i elastycznych pul w warstwach Premium i Krytyczne dla działania firmy usług, które zużywają duże ilości miejsca, może wystąpić błąd braku miejsca, mimo że używane miejsce w bazie danych lub elastycznej puli jest poniżej maksymalnego limitu rozmiaru danych. Może się tak zdarzyć, jeśli
tempdbpliki dziennika transakcji zużywają dużą ilość miejsca do maksymalnego limitu magazynu lokalnego. Przełącz bazę danych lub elastyczną pulę w tryb failover , aby zresetowaćtempdbgo do początkowego mniejszego rozmiaru lub zmniejszyć dziennik transakcji w celu zmniejszenia użycia magazynu lokalnego.
Sesje, procesy robocze i żądania
Sesje, procesy robocze i żądania są definiowane w następujący sposób:
- Sesja reprezentuje proces połączony z aparatem bazy danych.
- Żądanie jest logiczną reprezentacją zapytania lub partii. Żądanie jest wystawiane przez klienta połączonego z sesją. W czasie wiele żądań może być wystawianych w tej samej sesji.
- Wątek procesu roboczego, nazywany również procesem roboczym lub wątkiem, jest logiczną reprezentacją wątku systemu operacyjnego. Żądanie może mieć wiele procesów roboczych wykonywanych przy użyciu równoległego planu wykonywania zapytań lub pojedynczego procesu roboczego wykonywanego przy użyciu szeregowego (pojedynczego wątkowego) planu wykonywania. Pracownicy są również zobowiązani do obsługi działań poza żądaniami: na przykład proces roboczy jest wymagany do przetworzenia żądania logowania podczas nawiązywania połączenia sesji.
Aby uzyskać więcej informacji na temat tych pojęć, zobacz przewodnik dotyczący architektury wątków i zadań .
Maksymalna liczba procesów roboczych jest określana przez warstwę usługi i rozmiar obliczeniowy. Po osiągnięciu limitów sesji lub procesów roboczych nowe żądania są odrzucane, a klienci otrzymują komunikat o błędzie. Chociaż liczba połączeń może być kontrolowana przez aplikację, liczba współbieżnych procesów roboczych jest często trudniej oszacować i kontrolować. Jest to szczególnie istotne w okresach szczytowego obciążenia, gdy osiągnięto limity zasobów bazy danych, a pracownicy stosują się z powodu dłuższych zapytań, dużych łańcuchów blokujących lub nadmiernego równoległości zapytań.
Uwaga
Początkowa oferta usługi Azure SQL Database obsługuje tylko pojedyncze zapytania wątkowe. W tym czasie liczba żądań była zawsze równoważna liczbie procesów roboczych. Komunikat o błędzie 10928 w usłudze Azure SQL Database zawiera tylko sformułowanie The request limit for the database is *N* and has been reached dla celów zgodności z poprzednimi wersjami. Osiągnięta wartość limitu to w rzeczywistości liczba procesów roboczych.
Jeśli ustawienie maksymalnego stopnia równoległości (MAXDOP) jest równe zero lub jest większe niż jeden, liczba procesów roboczych może być znacznie wyższa niż liczba żądań, a limit może zostać osiągnięty znacznie wcześniej niż wtedy, gdy wartość MAXDOP jest równa jednej.
- Dowiedz się więcej o błędzie 10928 w temacie Błędy nadzoru nad zasobami.
- Dowiedz się więcej o wyczerpaniu limitu żądań w błędach 10928 i 10936.
Możesz ograniczyć zbliżanie się lub osiąganie limitów procesów roboczych lub sesji, wykonując następujące czynności:
- Zwiększenie warstwy usługi lub rozmiaru obliczeniowego bazy danych lub elastycznej puli. Zobacz Skalowanie zasobów pojedynczej bazy danych i Skalowanie zasobów elastycznej puli.
- Optymalizacja zapytań w celu zmniejszenia wykorzystania zasobów, jeśli przyczyną zwiększenia liczby procesów roboczych jest rywalizacja o zasoby obliczeniowe. Aby uzyskać więcej informacji, zobacz Podpowiedzi i dostrajanie zapytań.
- Optymalizacja obciążenia zapytania w celu zmniejszenia liczby wystąpień i czasu trwania blokowania zapytań. Aby uzyskać więcej informacji, zobacz Opis i rozwiązywanie problemów z blokowaniem.
- Zmniejszenie ustawienia MAXDOP, jeśli jest to konieczne.
Znajdź limity procesów roboczych i sesji dla usługi Azure SQL Database według warstwy usługi i rozmiaru zasobów obliczeniowych:
- Limity zasobów dla pojedynczych baz danych podczas używania modelu zakupu opartego na rdzeniach wirtualnych
- Limity zasobów dla elastycznych pul podczas używania modelu zakupu opartego na rdzeniach wirtualnych
- Resource limits for single databases using the DTU purchasing model (Limity zasobów dla pojedynczych baz danych przy użyciu modelu zakupu DTU)
- limity zasobów dla elastycznych pul przy użyciu modelu zakupów jednostek DTU
Dowiedz się więcej na temat rozwiązywania problemów z określonymi błędami dotyczącymi limitów sesji lub procesów roboczych w artykule Błędy nadzoru nad zasobami.
Połączenia zewnętrzne
Liczba równoczesnych połączeń z zewnętrznymi punktami końcowymi wykonywana za pośrednictwem sp_invoke_external_rest_endpoint jest ograniczona do 10% wątków roboczych z twardym limitem maksymalnie 150 procesów roboczych.
Pamięć
W przeciwieństwie do innych zasobów (procesora CPU, procesów roboczych, magazynu), osiągnięcie limitu pamięci nie wpływa negatywnie na wydajność zapytań i nie powoduje błędów i błędów. Zgodnie ze szczegółowym opisem w przewodnikudotyczącym architektury zarządzania pamięcią
Po uruchomieniu aparatu bazy danych, gdy obciążenie rozpoczyna odczytywanie danych z magazynu, aparat bazy danych agresywnie buforuje dane w pamięci. Po tym początkowym okresie zwiększania często widać avg_memory_usage_percent kolumny i i avg_instance_memory_percent w sys.dm_db_resource_stats, a sql_instance_memory_percent metryka usługi Azure Monitor zbliża się do 100%, szczególnie w przypadku baz danych, które nie są bezczynne, i nie mieszczą się w pełni w pamięci.
Uwaga
sql_instance_memory_percent Metryka odzwierciedla całkowite zużycie pamięci przez aparat bazy danych. Ta metryka może nie osiągnąć 100% nawet wtedy, gdy obciążenia o wysokiej intensywności są uruchomione. Dzieje się tak, ponieważ niewielka część dostępnej pamięci jest zarezerwowana dla krytycznych alokacji pamięci innych niż pamięć podręczna danych, takich jak stosy wątków i moduły wykonywalne.
Oprócz pamięci podręcznej danych pamięć jest używana w innych składnikach aparatu bazy danych. Gdy zapotrzebowanie na pamięć i cała dostępna pamięć jest używana przez pamięć podręczną danych, aparat bazy danych zmniejsza rozmiar pamięci podręcznej danych, aby udostępnić pamięć innym składnikom i dynamicznie zwiększa pamięć podręczną danych, gdy inne składniki zwalniają pamięć.
W rzadkich przypadkach wystarczająco wymagające obciążenie może spowodować niewystarczający stan pamięci, co prowadzi do błędów braku pamięci. Błędy braku pamięci mogą wystąpić na dowolnym poziomie wykorzystania pamięci z zakresu od 0% do 100%. Błędy braku pamięci są bardziej narażone na mniejsze rozmiary obliczeniowe, które mają proporcjonalnie mniejsze limity pamięci i / lub obciążenia korzystające z większej ilości pamięci do przetwarzania zapytań, takich jak w gęstych elastycznych pulach.
Jeśli wystąpią błędy braku pamięci, dostępne są następujące opcje ograniczania ryzyka:
- Przejrzyj szczegóły warunku OOM w sys.dm_os_out_of_memory_events.
- Zwiększenie warstwy usługi lub rozmiaru obliczeniowego bazy danych lub elastycznej puli. Zobacz Skalowanie zasobów pojedynczej bazy danych i Skalowanie zasobów elastycznej puli.
- Optymalizowanie zapytań i konfiguracji w celu zmniejszenia wykorzystania pamięci. Typowe rozwiązania opisano w poniższej tabeli.
| Rozwiązanie | opis |
|---|---|
| Zmniejszenie rozmiaru przydziałów pamięci | Aby uzyskać więcej informacji o udzielaniu pamięci, zobacz wpis w blogu Opis przyznawania pamięci programu SQL Server. Typowym rozwiązaniem, które pozwala uniknąć zbyt dużych dotacji na pamięć, jest zapewnienie aktualności statystyk. Dzięki temu można dokładniej oszacować zużycie pamięci przez aparat zapytań, unikając dużych przydziałów pamięci. Domyślnie w bazach danych przy użyciu poziomu zgodności 140 lub nowszego aparat bazy danych może automatycznie dostosować rozmiar przydziału pamięci przy użyciu pamięci trybu usługi Batch udziela opinii. Podobnie w bazach danych korzystających z poziomu zgodności 150 i nowszych aparat bazy danych używa również opinii o udzielaniu opinii dotyczących pamięci trybu wiersza, aby uzyskać bardziej typowe zapytania trybu wiersza. Ta wbudowana funkcja pomaga uniknąć błędów braku pamięci z powodu dużych przydziałów pamięci. |
| Zmniejszenie rozmiaru pamięci podręcznej planu zapytań | Aparat bazy danych buforuje plany zapytań w pamięci, aby uniknąć kompilowania planu zapytania dla każdego wykonania zapytania. Aby uniknąć wdężenia pamięci podręcznej planu zapytań spowodowanego buforowaniem planów, które są używane tylko raz, upewnij się, że używasz sparametryzowanych zapytań i rozważ włączenie konfiguracji w zakresie OPTIMIZE_FOR_AD_HOC_WORKLOADS bazy danych. |
| Zmniejszenie rozmiaru pamięci blokady | Aparat bazy danych używa pamięci na potrzeby blokad. Jeśli to możliwe, unikaj dużych transakcji, które mogą uzyskać dużą liczbę blokad i spowodować wysokie użycie pamięci blokady. |
Użycie zasobów według obciążeń użytkownika i procesów wewnętrznych
Usługa Azure SQL Database wymaga zasobów obliczeniowych w celu zaimplementowania podstawowych funkcji usługi, takich jak wysoka dostępność i odzyskiwanie po awarii, tworzenie kopii zapasowych i przywracanie bazy danych, monitorowanie, magazyn zapytań, automatyczne dostrajanie itp. System odkłada ograniczoną część ogólnych zasobów dla tych procesów wewnętrznych przy użyciu mechanizmów zapewniania ładu zasobów, dzięki czemu pozostałe zasoby są dostępne dla obciążeń użytkowników. Czasami, gdy procesy wewnętrzne nie korzystają z zasobów obliczeniowych, system udostępnia je obciążeniom użytkowników.
Łączne użycie procesora CPU i pamięci według obciążeń użytkownika i procesów wewnętrznych jest zgłaszane w widokach sys.dm_db_resource_stats i sys.resource_stats , w kolumnach avg_instance_cpu_percent i avg_instance_memory_percent . Te dane są również zgłaszane za pośrednictwem sql_instance_cpu_percent metryk i sql_instance_memory_percent usługi Azure Monitor dla pojedynczych baz danych i pul elastycznych na poziomie puli.
Uwaga
sql_instance_cpu_percent Metryki usługi sql_instance_memory_percent Azure Monitor są dostępne od lipca 2023 r. Są one w pełni równoważne z wcześniej dostępnymi sqlserver_process_core_percent i sqlserver_process_memory_percent odpowiednio metrykami. Pozostałe dwie metryki pozostaną dostępne, ale zostaną usunięte w przyszłości. Aby uniknąć przerw w monitorowaniu bazy danych, nie używaj starszych metryk.
Te metryki nie są dostępne dla baz danych przy użyciu celów usługi Podstawowa, S1 i S2. Te same dane są dostępne w następujących dynamicznych widokach zarządzania.
Użycie procesora CPU i pamięci przez obciążenia użytkowników w każdej bazie danych jest zgłaszane w widokach sys.dm_db_resource_stats i sys.resource_stats , w avg_cpu_percent kolumnach i avg_memory_usage_percent . W przypadku pul elastycznych użycie zasobów na poziomie puli jest zgłaszane w widoku sys.elastic_pool_resource_stats (w przypadku scenariuszy raportowania historycznego) i w sys.dm_elastic_pool_resource_stats na potrzeby monitorowania w czasie rzeczywistym. Użycie procesora CPU obciążenia użytkownika jest również zgłaszane za pośrednictwem cpu_percent metryki usługi Azure Monitor dla pojedynczych baz danych i pul elastycznych na poziomie puli.
Bardziej szczegółowy podział ostatniego użycia zasobów przez obciążenia użytkownika i procesy wewnętrzne są raportowane w widokach sys.dm_resource_governor_resource_pools_history_ex i sys.dm_resource_governor_workload_groups_history_ex . Aby uzyskać szczegółowe informacje na temat pul zasobów i grup obciążeń, do których odwołuje się te widoki, zobacz Zarządzanie zasobami. Te widoki raportują wykorzystanie zasobów przez obciążenia użytkowników i określone procesy wewnętrzne w skojarzonych pulach zasobów i grupach obciążeń.
Napiwek
Podczas monitorowania lub rozwiązywania problemów z wydajnością obciążenia należy wziąć pod uwagę ). Wydajność może być zauważalnie dotknięta, jeśli którakolwiek z tych metryk znajduje się w zakresie od 70 do 100%.
Użycie procesora CPU użytkownika jest definiowane jako wartość procentowa w stosunku do limitu procesora CPU obciążenia użytkownika w każdym celu usługi. Podobnie łączne użycie procesora CPU jest definiowane jako wartość procentowa limitu procesora CPU dla wszystkich obciążeń. Ponieważ te dwa limity są różne, użytkownik i łączne użycie procesora CPU są mierzone na różnych skalach i nie są bezpośrednio porównywalne ze sobą.
Jeśli użycie procesora PRZEZ użytkownika osiągnie 100%, oznacza to, że obciążenie użytkownika w pełni korzysta z dostępnej dla niego pojemności procesora CPU w wybranym celu usługi, nawet jeśli całkowite użycie procesora CPU pozostanie poniżej 100%.
Gdy całkowite użycie procesora CPU osiągnie zakres 70–100%, możliwe jest, aby zobaczyć spłaszczanie przepływności obciążenia użytkownika i zwiększenie opóźnienia zapytań, nawet jeśli użycie procesora PRZEZ użytkownika pozostaje znacznie poniżej 100%. Jest to bardziej prawdopodobne w przypadku korzystania z mniejszych celów usługi z umiarkowaną alokacją zasobów obliczeniowych, ale stosunkowo intensywnymi obciążeniami użytkowników, takimi jak w gęstych elastycznych pulach. Może to również wystąpić w przypadku mniejszych celów usługi, gdy procesy wewnętrzne tymczasowo wymagają większej ilości zasobów, na przykład podczas tworzenia nowej repliki bazy danych lub tworzenia kopii zapasowej bazy danych.
Podobnie, gdy użycie procesora przez użytkownika osiągnie zakres 70–100%, przepływność obciążenia użytkownika zmniejsza się i zwiększa opóźnienie zapytań, nawet jeśli całkowite użycie procesora CPU jest znacznie poniżej limitu.
Jeśli użycie procesora CPU użytkownika lub całkowite użycie procesora CPU jest wysokie, opcje ograniczania ryzyka są takie same jak w sekcji Procesor obliczeniowy i obejmują zwiększenie celu usługi i/lub optymalizację obciążenia użytkownika.
Uwaga
Nawet w przypadku całkowicie bezczynnej bazy danych lub elastycznej puli całkowite użycie procesora NIGDY nie jest zerowe z powodu działań aparatu bazy danych w tle. Może się wahać w szerokim zakresie w zależności od konkretnych działań w tle, rozmiaru obliczeniowego i poprzedniego obciążenia użytkownika.
Nadzór nad zasobami
Aby wymusić limity zasobów, usługa Azure SQL Database korzysta z implementacji ładu zasobów opartej na zarządcy zasobów programu SQL Server, zmodyfikowanej i rozszerzonej do uruchamiania w chmurze. W usłudze SQL Database wiele pul zasobów i grup obciążeń z limitami zasobów ustawionymi zarówno na poziomie puli, jak i grupy, zapewnia zrównoważoną bazę danych jako usługę. Obciążenia użytkowników i obciążenia wewnętrzne są klasyfikowane w oddzielnych pulach zasobów i grupach obciążeń. Obciążenie użytkownika w replikach pomocniczych podstawowych i możliwych do odczytu, w tym replik geograficznych, jest klasyfikowane do SloSharedPool1 puli zasobów i UserPrimaryGroup.DBId[N] grup obciążeń, gdzie [N] oznacza wartość identyfikatora bazy danych. Ponadto istnieje wiele pul zasobów i grup obciążeń dla różnych obciążeń wewnętrznych.
Oprócz używania zarządcy zasobów do zarządzania zasobami w a aparatu bazy danych usługa Azure SQL Database używa również obiektów zadań systemu Windows do zarządzania zasobami na poziomie procesu oraz Menedżera zasobów serwera plików systemu Windows (FSRM) na potrzeby zarządzania limitami przydziału magazynu.
Zarządzanie zasobami usługi Azure SQL Database jest hierarchiczne. Od góry do dołu limity są wymuszane na poziomie systemu operacyjnego i na poziomie woluminu magazynu przy użyciu mechanizmów zarządzania zasobami systemu operacyjnego i zarządcy zasobów, a następnie na poziomie puli zasobów przy użyciu zarządcy zasobów, a następnie na poziomie grupy obciążeń przy użyciu zarządcy zasobów. Limity ładu zasobów obowiązujące dla bieżącej bazy danych lub elastycznej puli są zgłaszane w widoku sys.dm_user_db_resource_governance .
Nadzór nad we/wy danych
Zarządzanie we/wy danych to proces w usłudze Azure SQL Database używany do ograniczania zarówno operacji we/wy odczytu, jak i zapisu fizycznego we/wy względem plików danych bazy danych. Limity liczby operacji we/wy na sekundę są ustawiane dla każdego poziomu usługi w celu zminimalizowania efektu "hałaśliwego sąsiada", zapewnienia sprawiedliwości alokacji zasobów w usłudze wielodostępnej oraz utrzymania możliwości bazowego sprzętu i magazynu.
W przypadku pojedynczych baz danych limity grup obciążeń są stosowane do wszystkich operacji we/wy magazynu względem bazy danych. W przypadku pul elastycznych limity grup obciążeń mają zastosowanie do każdej bazy danych w puli. Ponadto limit puli zasobów jest dodatkowo stosowany do skumulowanego we/wy puli elastycznej. W systemie operacje we/wy tempdbpodlegają limitom grup obciążeń, z wyjątkiem warstwy usługi Podstawowa, Standardowa i Ogólnego przeznaczenia, gdzie obowiązują wyższe tempdb limity operacji we/wy. Ogólnie rzecz biorąc, limity puli zasobów mogą nie być osiągalne przez obciążenie względem bazy danych (pojedynczej lub w puli), ponieważ limity grup obciążeń są niższe niż limity puli zasobów i szybciej ograniczają przepływność/operacje we/wy na sekundę. Jednak limity puli można osiągnąć przez połączone obciążenie dla wielu baz danych w tej samej puli.
Jeśli na przykład zapytanie generuje 1000 operacji we/wy na sekundę bez nadzoru nad zasobami we/wy, ale maksymalny limit liczby operacji we/wy grupy obciążeń jest ustawiony na 900 operacji we/wy, zapytanie nie może wygenerować więcej niż 900 operacji we/wy na sekundę. Jeśli jednak maksymalny limit operacji we/wy puli zasobów wynosi 1500 operacji we/wy na sekundę, a łączna liczba operacji we/wy ze wszystkich grup obciążeń skojarzonych z pulą zasobów przekracza 1500 operacji we/wy na sekundę, operacje we/wy tego samego zapytania mogą zostać zmniejszone poniżej limitu liczby operacji we/wy grupy roboczej wynoszącej 900 operacji we/wy.
Wartości maksymalne liczby operacji we/wy na sekundę i przepływności zwracane przez widok sys.dm_user_db_resource_governance działają jako limity/limity, a nie jako gwarancje. Ponadto zarządzanie zasobami nie gwarantuje żadnego konkretnego opóźnienia magazynu. Najlepsze osiągalne opóźnienia, liczba operacji we/wy na sekundę i przepływność dla danego obciążenia użytkownika zależą nie tylko od limitów ładu zasobów we/wy, ale także od kombinacji używanych rozmiarów we/wy i możliwości magazynu bazowego. Usługa SQL Database używa operacji we/wy, które różnią się rozmiarem od 512 bajtów do 4 MB. Na potrzeby wymuszania limitów liczby operacji we/wy na sekundę każde we/wy jest uwzględniane niezależnie od rozmiaru, z wyjątkiem baz danych z plikami danych w usłudze Azure Storage. W takim przypadku operacje we/wy większe niż 256 KB są uwzględniane jako wiele operacji we/wy o rozmiarze 256 KB w celu dostosowania ich do ewidencjonowania operacji we/wy usługi Azure Storage.
W przypadku baz danych w warstwie Podstawowa, Standardowa i Ogólnego przeznaczenia, które używają plików danych w usłudze Azure Storage, primary_group_max_io wartość może nie być osiągalna, jeśli baza danych nie ma wystarczającej liczby plików danych, aby zbiorczo zapewnić tę liczbę operacji we/wy na sekundę, lub jeśli dane nie są równomiernie dystrybuowane między plikami lub jeśli warstwa wydajności bazowych obiektów blob ogranicza liczbę operacji we/wy na sekundę/przepływność poniżej limitów ładu zasobów. Podobnie w przypadku małych operacji we/wy dziennika generowanych przez częste zatwierdzenia transakcji primary_max_log_rate wartość może nie być osiągalna przez obciążenie ze względu na limit operacji we/wy na sekundę w bazowym obiekcie blob usługi Azure Storage. W przypadku baz danych korzystających z usługi Azure Premium Storage usługa Azure SQL Database używa wystarczająco dużych obiektów blob magazynu do uzyskania wymaganych operacji we/wy na sekundę/przepływności, niezależnie od rozmiaru bazy danych. W przypadku większych baz danych tworzonych jest wiele plików danych w celu zwiększenia całkowitej pojemności operacji we/wy na sekundę/przepływności.
Wartości wykorzystania zasobów, takie jak avg_data_io_percent i avg_log_write_percent, zgłaszane w sys.dm_db_resource_stats, sys.resource_stats, sys.dm_elastic_pool_resource_stats i widoki sys.elastic_pool_resource_stats, są obliczane jako wartości procentowe maksymalnego limitu ładu zasobów. W związku z tym, gdy czynniki inne niż limit liczby operacji we/wy na sekundę/przepływności zasobów ograniczają liczbę operacji we/wy na sekundę i opóźnienia w miarę wzrostu obciążenia, mimo że zgłoszone wykorzystanie zasobów pozostaje poniżej 100%.
Aby monitorować operacje we/wy odczytu i zapisu na sekundę, przepływność i opóźnienia dla pliku bazy danych, użyj funkcji sys.dm_io_virtual_file_stats(). Ta funkcja przedstawia wszystkie operacje we/wy względem bazy danych, w tym operacje we/wy w tle, które nie są uwzględniane w stosunku do avg_data_io_percentmetody , ale używają operacji we/wy na sekundę i przepływności bazowego magazynu oraz mogą mieć wpływ na zaobserwowane opóźnienie magazynu. Funkcja zgłasza dodatkowe opóźnienia, które mogą być wprowadzane przez zarządzanie zasobami we/wy dla operacji odczytu i zapisu, odpowiednio w io_stall_queued_read_ms kolumnach i io_stall_queued_write_ms .
Zarządzanie szybkością dzienników transakcji
Zarządzanie szybkością dzienników transakcji jest procesem w usłudze Azure SQL Database używanym do ograniczania wysokich stawek pozyskiwania dla obciążeń, takich jak zbiorcze wstawianie, select INTO i kompilacje indeksu. Te limity są śledzone i wymuszane na poziomie podrzędnym do szybkości generowania rekordów dziennika, ograniczając przepływność niezależnie od liczby obiektów we/wy, które mogą być wystawiane względem plików danych. Współczynniki generowania dzienników transakcji są obecnie skalowane liniowo w górę do punktu zależnego od sprzętu i warstwy usług.
Współczynniki rejestrowania są ustawiane tak, aby można je było osiągnąć i utrzymać w różnych scenariuszach, podczas gdy ogólny system może zachować jego funkcjonalność przy minimalnym wpływie na obciążenie użytkownika. Zarządzanie szybkością rejestrowania zapewnia, że kopie zapasowe dziennika transakcji pozostają w ramach opublikowanych umów SLA dotyczących możliwości odzyskiwania. Ten nadzór zapobiega również nadmiernej zaległości replik pomocniczych, które w przeciwnym razie mogą prowadzić do dłuższego niż oczekiwano przestoju podczas pracy w trybie failover.
Rzeczywiste fizyczne obiekty we/wy do plików dziennika transakcji nie są zarządzane ani ograniczone. W miarę generowania rekordów dziennika każda operacja jest oceniana i oceniana pod kątem tego, czy ma być opóźniona w celu zachowania maksymalnej żądanej szybkości rejestrowania (MB/s na sekundę). Opóźnienia nie są dodawane, gdy rekordy dziennika są opróżniane do magazynu, a nie ład szybkości dzienników jest stosowany podczas generowania szybkości dzienników.
Rzeczywiste współczynniki generowania dzienników nałożone w czasie wykonywania mają również wpływ na mechanizmy przesyłania opinii, tymczasowo zmniejszając dozwolone współczynniki rejestrowania, aby system mógł się ustabilizować. Zarządzanie miejscem na pliki dziennika, unikanie wyczerpania warunków miejsca w dzienniku i mechanizmów replikacji danych może tymczasowo zmniejszyć ogólne limity systemu.
Kształtowanie ruchu zarządcy liczby dzienników jest widoczne za pośrednictwem następujących typów oczekiwania (uwidocznionych w widokach sys.dm_exec_requests i sys.dm_os_wait_stats ):
| Typ oczekiwania | Uwagi |
|---|---|
LOG_RATE_GOVERNOR |
Ograniczanie bazy danych |
POOL_LOG_RATE_GOVERNOR |
Ograniczanie puli |
INSTANCE_LOG_RATE_GOVERNOR |
Ograniczanie poziomu wystąpienia |
HADR_THROTTLE_LOG_RATE_SEND_RECV_QUEUE_SIZE |
Kontrola opinii, replikacja fizyczna grupy dostępności w warstwie Premium/Krytyczne dla działania firmy nie jest zachowywana |
HADR_THROTTLE_LOG_RATE_LOG_SIZE |
Kontrola opinii, ograniczanie szybkości w celu uniknięcia stanu braku miejsca w dzienniku |
HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO |
Kontrola opinii na temat replikacji geograficznej, ograniczanie szybkości rejestrowania w celu uniknięcia dużego opóźnienia danych i niedostępności serwerów geograficznych |
W przypadku napotkania limitu szybkości dzienników, który utrudnia żądaną skalowalność, należy wziąć pod uwagę następujące opcje:
- Przeprowadź skalowanie w górę do wyższego poziomu usług, aby uzyskać maksymalną szybkość rejestrowania warstwy usługi lub przełączyć się na inną warstwę usługi.
- W przypadku sprzętu zoptymalizowanego pod kątem pamięci serii Premium i premium warstwa usługi aprowizowana w warstwie Hiperskala zapewnia 150 szybkości dzienników MiB/s na bazę danych i 150 MiB/s na pulę elastyczną.
- W przypadku innych serii sprzętowych warstwa usługi Hiperskala zapewnia 100 szybkości dzienników MiB/s na bazę danych i 125 MiB/s na pulę elastyczną.
- Jeśli ładowane dane są przejściowe, takie jak dane przejściowe w procesie ETL, można je załadować do bazy danych
tempdb(z czym wiąże się minimalne rejestrowanie). - W przypadku scenariuszy analitycznych załaduj je do tabeli klastrowanego magazynu kolumn lub tabeli z indeksami używającymi kompresji danych. Zmniejsza to wymaganą szybkość rejestrowania. Ta technika zwiększa wykorzystanie procesora CPU i ma zastosowanie tylko do zestawów danych, które korzystają z klastrowanych indeksów magazynu kolumn lub kompresji danych.
Nadzór nad miejscem do magazynowania
W warstwach usług Premium i Krytyczne dla działania firmy dane klientów, w tym pliki danych, pliki dziennika transakcji i tempdb pliki, są przechowywane w lokalnym magazynie SSD maszyny hostujące bazę danych lub elastyczną pulę. Lokalny magazyn SSD zapewnia wysoką przepływność i operacje we/wy na sekundę oraz małe opóźnienie we/wy. Oprócz danych klientów magazyn lokalny jest używany dla systemu operacyjnego, oprogramowania do zarządzania, monitorowania danych i dzienników oraz innych plików niezbędnych do działania systemu.
Rozmiar magazynu lokalnego jest skończony i zależy od możliwości sprzętowych, które określają maksymalny limit magazynu lokalnego lub magazyn lokalny przeznaczony dla danych klientów. Ten limit jest ustawiony w celu zmaksymalizowania magazynu danych klienta, zapewniając jednocześnie bezpieczną i niezawodną operację systemu. Aby znaleźć maksymalną wartość magazynu lokalnego dla każdego celu usługi, zobacz dokumentację limitów zasobów dla pojedynczych baz danych i pul elastycznych.
Możesz również znaleźć tę wartość i ilość magazynu lokalnego aktualnie używanego przez daną bazę danych lub pulę elastyczną, korzystając z następującego zapytania:
SELECT server_name, database_name, slo_name, user_data_directory_space_quota_mb, user_data_directory_space_usage_mb
FROM sys.dm_user_db_resource_governance
WHERE database_id = DB_ID();
| Kolumna | opis |
|---|---|
server_name |
Nazwa serwera logicznego |
database_name |
Nazwa bazy danych |
slo_name |
Nazwa celu usługi, w tym generowanie sprzętu |
user_data_directory_space_quota_mb |
Maksymalny rozmiar magazynu lokalnego w MB |
user_data_directory_space_usage_mb |
Bieżące użycie magazynu lokalnego według plików danych, plików dziennika transakcji i tempdb plików w MB. Aktualizowane co pięć minut. |
To zapytanie powinno być wykonywane w bazie danych użytkownika, a nie w master bazie danych. W przypadku pul elastycznych zapytanie można wykonać w dowolnej bazie danych w puli. Zgłoszone wartości dotyczą całej puli.
Ważne
W warstwach usług Premium i Krytyczne dla działania firmy, jeśli obciążenie próbuje zwiększyć łączne zużycie magazynu lokalnego przez pliki danych, pliki dziennika transakcji i tempdb pliki powyżej maksymalnego limitu magazynu lokalnego, wystąpi błąd braku miejsca. Dzieje się tak nawet wtedy, gdy miejsce używane w pliku bazy danych nie osiągnęło maksymalnego rozmiaru pliku.
Lokalny magazyn SSD jest również używany przez bazy danych w warstwach usług innych niż Premium i Krytyczne dla działania firmy dla bazy danych i pamięci podręcznej tempdb RBPEX w warstwie Hiperskala. W miarę tworzenia, usuwania i zwiększania lub zmniejszania rozmiaru bazy danych łączne użycie magazynu lokalnego na maszynie zmienia się wraz z upływem czasu. Jeśli system wykryje, że dostępny magazyn lokalny na maszynie jest niski, a baza danych lub elastyczna pula jest zagrożona wyczerpaniem miejsca, przenosi bazę danych lub elastyczną pulę na inną maszynę z wystarczającą ilością dostępnego magazynu lokalnego.
Ten ruch występuje w trybie online, podobnie jak operacja skalowania bazy danych, i ma podobny wpływ, w tym krótki (sekund) tryb failover na końcu operacji. To przejście w tryb failover kończy otwarte połączenia i cofa transakcje, co potencjalnie wpływa na aplikacje korzystające z bazy danych w tym czasie.
Ponieważ wszystkie dane są kopiowane do lokalnych woluminów magazynu na różnych maszynach, przenoszenie większych baz danych w warstwach Premium i Krytyczne dla działania firmy może wymagać znacznego czasu. W tym czasie, jeśli użycie miejsca lokalnego przez bazę danych lub elastyczną pulę lub tempdb baza danych szybko rośnie, ryzyko wyczerpania miejsca wzrasta. System inicjuje przenoszenie bazy danych w zrównoważony sposób, aby zminimalizować błędy braku miejsca, unikając niepotrzebnych trybów failover.
tempdb Rozmiary
Limity rozmiaru usługi tempdb Azure SQL Database zależą od modelu zakupów i wdrażania.
Aby dowiedzieć się więcej, zapoznaj się z tempdb limitami rozmiaru dla:
- Model zakupów rdzeni wirtualnych: pojedyncze bazy danych, bazy danych w puli
- Model zakupów jednostek DTU: pojedyncze bazy danych, bazy danych w puli.
Wcześniej dostępny sprzęt
Ta sekcja zawiera szczegółowe informacje na temat wcześniej dostępnego sprzętu.
- Sprzęt 4. generacji został wycofany i nie jest dostępny do aprowizacji, skalowania upscalingowego ani skalowania w dół. Przeprowadź migrację bazy danych do obsługiwanej generacji sprzętu w celu uzyskania szerszego zakresu skalowalności rdzeni wirtualnych i magazynu, przyspieszonej sieci, najlepszej wydajności operacji we/wy i minimalnego opóźnienia. Aby uzyskać więcej informacji, zobacz Temat Pomoc techniczna zakończyła się dla sprzętu 4. generacji w usłudze Azure SQL Database.
Eksplorator usługi Azure Resource Graph umożliwia zidentyfikowanie wszystkich zasobów usługi Azure SQL Database, które obecnie korzystają ze sprzętu gen4, lub sprawdzić sprzęt używany przez zasoby dla określonego serwera logicznego w witrynie Azure Portal.
Aby wyświetlić wyniki w Eksploratorze usługi Azure Resource Graph, musisz mieć co najmniej read uprawnienia do obiektu lub grupy obiektów platformy Azure.
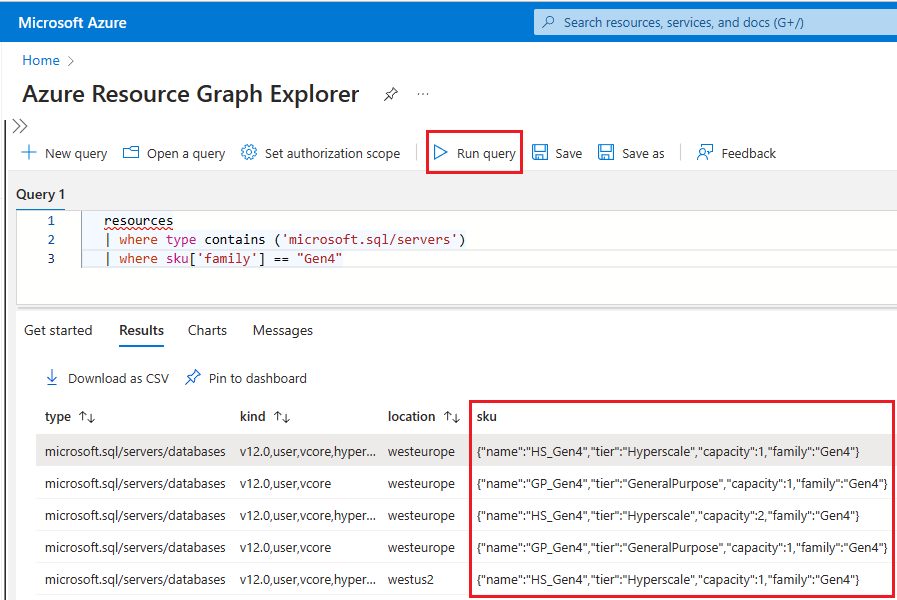
Aby użyć Eksploratora usługi Resource Graph do identyfikowania zasobów usługi Azure SQL, które nadal korzystają ze sprzętu gen4, wykonaj następujące kroki:
Przejdź do portalu Azure Portal.
Resource graphWyszukaj w polu wyszukiwania i wybierz usługę Resource Graph Explorer z wyników wyszukiwania.W oknie zapytania wpisz następujące zapytanie, a następnie wybierz pozycję Uruchom zapytanie:
resources | where type contains ('microsoft.sql/servers') | where sku['family'] == "Gen4"W okienku Wyniki są wyświetlane wszystkie aktualnie wdrożone zasoby na platformie Azure korzystające ze sprzętu Gen4.
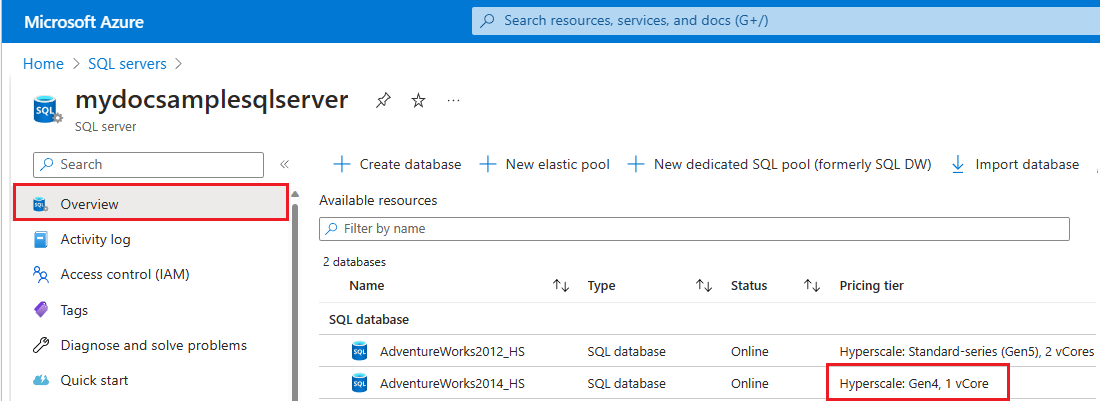
Aby sprawdzić sprzęt używany przez zasoby dla określonego serwera logicznego na platformie Azure, wykonaj następujące kroki:
- Przejdź do portalu Azure Portal.
-
SQL serversWyszukaj w polu wyszukiwania i wybierz pozycję Serwery SQL z wyników wyszukiwania, aby otworzyć stronę serwerów SQL i wyświetlić wszystkie serwery dla wybranych subskrypcji. - Wybierz interesujący go serwer, aby otworzyć stronę Przegląd serwera.
- Przewiń w dół do dostępnych zasobów i sprawdź kolumnę Warstwa cenowa dla zasobów korzystających ze sprzętu gen4.
Aby przeprowadzić migrację zasobów do sprzętu serii standardowej, zapoznaj się ze zmianą sprzętu.
Powiązana zawartość
- Aby uzyskać informacje na temat ogólnych limitów platformy Azure, zobacz Limity subskrypcji i usług platformy Azure, limity przydziału i ograniczenia.
- Aby uzyskać informacje o jednostkach DTU i jednostkach eDTU, zobacz Jednostki DTU i eDTU.
- Aby uzyskać informacje o
tempdblimitach rozmiaru, zobacz pojedyncze bazy danych rdzeni wirtualnych, bazy danych z pulą rdzeni wirtualnych, pojedyncze bazy danych jednostek DTU i bazy danych jednostek DTU w puli.