Trenowanie modelu interpretacji języka konwersacji
Po zakończeniu etykietowania wypowiedzi możesz rozpocząć trenowanie modelu. Trenowanie to proces, w którym model uczy się na podstawie oznaczonych wypowiedzi.
Aby wytrenować model, uruchom zadanie szkoleniowe. Tylko pomyślnie ukończone zadania tworzą model. Zadania szkoleniowe wygasają po siedmiu dniach, po tym czasie nie będzie już można pobrać szczegółów zadania. Jeśli zadanie trenowania zostało ukończone pomyślnie i model został utworzony, nie będzie to miało wpływu na wygasające zadanie. Jednocześnie można uruchamiać tylko jedno zadanie szkoleniowe i nie można uruchamiać innych zadań w tym samym projekcie.
Czas trenowania może wynosić od kilku sekund podczas pracy z prostymi projektami do kilku godzin, gdy osiągniesz maksymalny limit wypowiedzi.
Ocena modelu jest wyzwalana automatycznie po pomyślnym zakończeniu trenowania. Proces oceny rozpoczyna się od użycia wytrenowanego modelu do uruchamiania przewidywań na wypowiedziach w zestawie testowym i porównuje przewidywane wyniki z podanymi etykietami (co ustanawia punkt odniesienia prawdy).
Wymagania wstępne
- Pomyślnie utworzono projekt ze skonfigurowanym kontem usługi Azure Blob Storage
- Oznaczone wypowiedzi
Równoważenie danych treningowych
Należy starać się zachować zrównoważony schemat, jeśli chodzi o dane treningowe. Uwzględnienie dużych ilości jednej intencji, a bardzo niewiele innych spowoduje model, który jest mocno stronniczy wobec konkretnych intencji.
Aby rozwiązać ten problem, może być konieczne wyłączenie próbkowania zestawu treningowego lub dodanie go do niego. Próbkowanie w dół można wykonać za pomocą następujących czynności:
- Pozbądanie się pewnej wartości procentowej danych treningowych losowo.
- W bardziej systematyczny sposób analizując zestaw danych i usuwając nadmiernie reprezentowane zduplikowane wpisy.
Możesz również dodać do zestawu treningowego, wybierając pozycję Sugerowanie wypowiedzi na karcie Etykietowanie danych w programie Language Studio. Konwersacyjna Language Understanding wyśle połączenie do usługi Azure OpenAI w celu wygenerowania podobnych wypowiedzi.

Należy również wyszukać niezamierzone "wzorce" w zestawie treningowym. Jeśli na przykład zestaw szkoleniowy dla określonej intencji to małe litery lub zaczyna się od określonej frazy. W takich przypadkach trenowany model może nauczyć się tych niezamierzonych uprzedzeń w zestawie treningowym zamiast uogólniać.
Zalecamy wprowadzenie różnorodności liter i interpunkcji w zestawie treningowym. Jeśli oczekuje się, że model obsługuje odmiany, upewnij się, że masz zestaw szkoleniowy, który odzwierciedla również te różnorodność. Na przykład uwzględnij niektóre wypowiedzi we właściwej wielkości liter, a niektóre we wszystkich małych literach.
Dzielenie danych
Przed rozpoczęciem procesu trenowania oznaczone wypowiedziami w projekcie są podzielone na zestaw szkoleniowy i zestaw testowy. Każdy z nich pełni inną funkcję. Zestaw szkoleniowy jest używany podczas trenowania modelu. Jest to zestaw, z którego model uczy się oznaczonych wypowiedziami. Zestaw testów to zestaw ślepy, który nie jest wprowadzany do modelu podczas trenowania, ale tylko podczas oceny.
Po pomyślnym wytrenowanym modelu można użyć go do przewidywania z wypowiedzi w zestawie testowym. Te przewidywania są używane do obliczania metryk oceny. Zaleca się upewnienie się, że wszystkie intencje i jednostki są odpowiednio reprezentowane zarówno w zestawie treningowym, jak i testowym.
Omówienie języka konwersacyjnego obsługuje dwie metody dzielenia danych:
- Automatyczne dzielenie zestawu testowego z danych treningowych: system podzieli oznakowane dane między zestawy treningowe i testowe zgodnie z wybranymi wartościami procentowymi. Zalecany podział procentowy wynosi 80% w przypadku trenowania i 20% do testowania.
Uwaga
Jeśli wybierzesz opcję Automatycznie rozdzielając zestaw testowy z danych treningowych , tylko dane przypisane do zestawu treningowego zostaną podzielone zgodnie z podanymi wartościami procentowymi.
- Użyj ręcznego podziału danych treningowych i testowych: ta metoda umożliwia użytkownikom definiowanie, które wypowiedzi powinny należeć do tego zestawu. Ten krok jest włączony tylko w przypadku dodania wypowiedzi do zestawu testów podczas etykietowania.
Tryby trenowania
Funkcja CLU obsługuje dwa tryby trenowania modeli
Trenowanie standardowe używa szybkich algorytmów uczenia maszynowego do stosunkowo szybkiego trenowania modeli. Jest to obecnie dostępne tylko dla języka angielskiego i jest wyłączone dla każdego projektu, który nie używa języka angielskiego (USA) ani angielskiego (Wielka Brytania) jako jego języka podstawowego. Ta opcja szkoleniowa jest bezpłatna. Trenowanie standardowe umożliwia dodawanie wypowiedzi i testowanie ich szybko bez ponoszenia kosztów. Wyświetlone wyniki oceny powinny prowadzić cię do tego, gdzie należy wprowadzić zmiany w projekcie i dodać więcej wypowiedzi. Po kilku iteracjach i wprowadzeniu ulepszeń przyrostowych można rozważyć użycie zaawansowanego trenowania w celu wytrenowania innej wersji modelu.
Zaawansowane szkolenie wykorzystuje najnowszą technologię uczenia maszynowego do dostosowywania modeli przy użyciu danych. Oczekuje się, że pokaże to lepsze wyniki wydajności dla modeli i umożliwi korzystanie z wielojęzycznych możliwości clu. Zaawansowane szkolenie jest wyceniane inaczej. Aby uzyskać szczegółowe informacje, zobacz informacje o cenach .
Użyj wyników oceny, aby kierować decyzjami. Czasami określonego przykładu można przewidzieć niepoprawnie w zaawansowanym trenowaniu, a nie w przypadku korzystania ze standardowego trybu trenowania. Jeśli jednak ogólne wyniki oceny są lepsze przy użyciu zaawansowanych, zaleca się użycie końcowego modelu. Jeśli tak nie jest i nie chcesz używać żadnych funkcji wielojęzycznych, możesz nadal korzystać z modelu wytrenowanego w trybie standardowym.
Uwaga
Należy spodziewać się różnicy w zachowaniach współczynników ufności intencji między trybami trenowania, ponieważ każdy algorytm skalibruje wyniki w inny sposób.
Trenowanie modelu
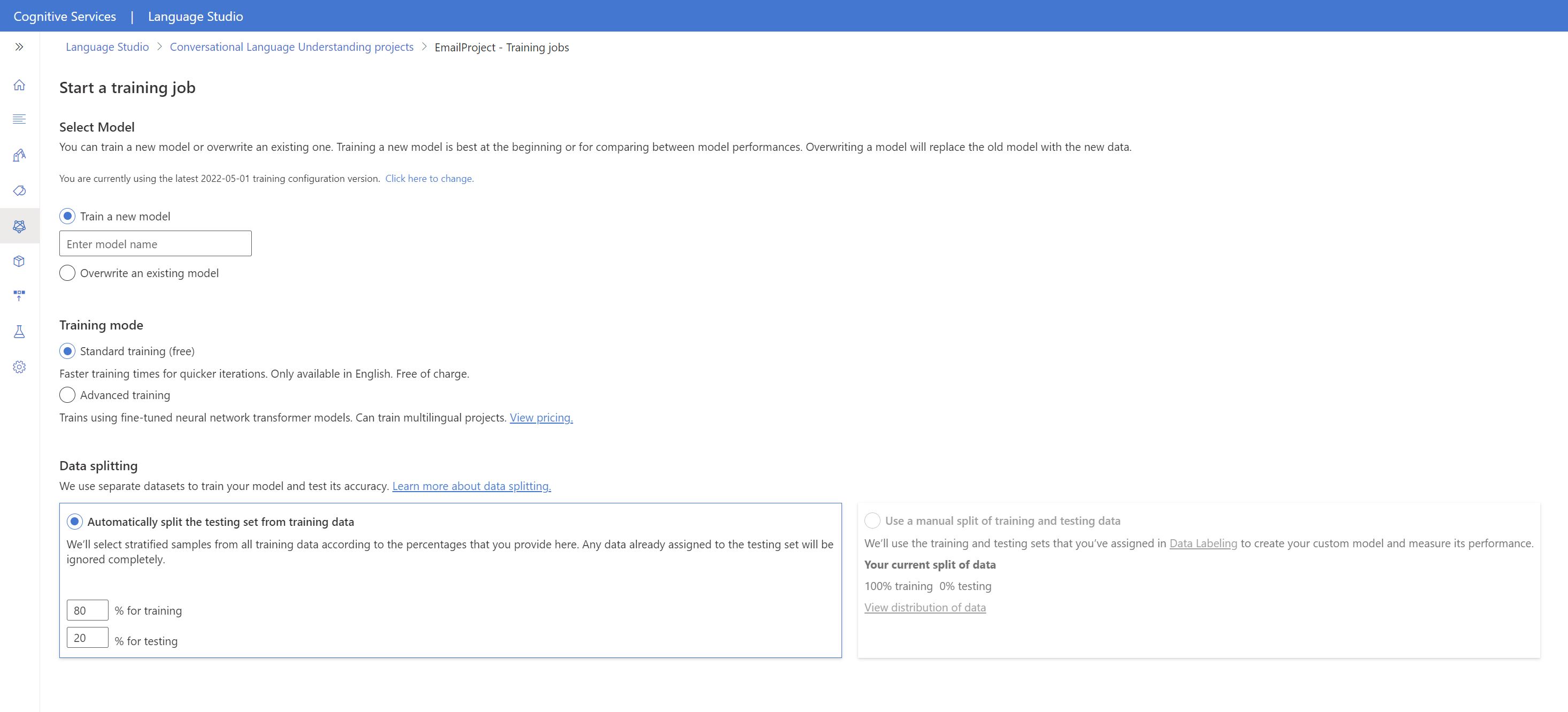
Aby rozpocząć trenowanie modelu z poziomu programu Language Studio:
Wybierz pozycję Train model (Trenowanie modelu ) z menu po lewej stronie.
Wybierz pozycję Start a training job (Uruchom zadanie szkoleniowe ) z górnego menu.
Wybierz pozycję Train a new model (Trenowanie nowego modelu ) i wprowadź nową nazwę modelu w polu tekstowym. W przeciwnym razie, aby zastąpić istniejący model modelem wytrenowanym na nowych danych, wybierz pozycję Zastąp istniejący model , a następnie wybierz istniejący model. Zastąpienie wytrenowanego modelu jest nieodwracalne, ale nie wpłynie to na wdrożone modele do momentu wdrożenia nowego modelu.
Wybierz tryb trenowania. Możesz wybrać standardowe szkolenie w celu szybszego trenowania, ale jest dostępne tylko dla języka angielskiego. Możesz też wybrać opcję Zaawansowane szkolenie , które jest obsługiwane w innych językach i projektach wielojęzycznych, ale obejmuje dłuższe czasy trenowania. Dowiedz się więcej o trybach trenowania.
Wybierz metodę dzielenia danych . Możesz wybrać opcję Automatycznie dzielenie zestawu testów na podstawie danych treningowych , w których system podzieli wypowiedzi między zestawy treningowe i testowe, zgodnie z określonymi wartościami procentowymi. Możesz też użyć ręcznego podziału danych treningowych i testowych. Ta opcja jest włączona tylko w przypadku dodania wypowiedzi do zestawu testowego po oznaczeniu wypowiedzi.
Wybierz przycisk Train (Trenuj ).
Wybierz identyfikator zadania szkoleniowego z listy. Zostanie wyświetlony panel, w którym można sprawdzić postęp trenowania, stan zadania i inne szczegóły dotyczące tego zadania.
Uwaga
- Tylko pomyślnie ukończone zadania szkoleniowe będą generować modele.
- Trenowanie może zająć trochę czasu od kilku minut do kilku godzin na podstawie liczby wypowiedzi.
- Jednocześnie może być uruchomione tylko jedno zadanie trenowania. Nie można uruchomić innych zadań szkoleniowych w ramach tego samego projektu, dopóki uruchomione zadanie nie zostanie ukończone.
- Uczenie maszynowe używane do trenowania modeli jest regularnie aktualizowane. Aby wytrenować w poprzedniej wersji konfiguracji, wybierz pozycję Wybierz tutaj, aby zmienić stronę Rozpocznij zadanie trenowania i wybierz poprzednią wersję.

Anulowanie zadania trenowania
Aby anulować zadanie szkoleniowe z poziomu programu Language Studio
- Na stronie Trenowanie modelu wybierz zadanie trenowania, które chcesz anulować, a następnie wybierz pozycję Anuluj w górnym menu.