Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważna
Szukasz rozwiązania bazy danych dla scenariuszy o dużej skali z umową SLA gwarantującą poziom dostępności na poziomie 99,999%, natychmiastowym skalowaniem automatycznym i automatycznym przełączaniem awaryjnym między wieloma regionami? Rozważmy usługę Azure Cosmos DB dla noSQL.
Czy chcesz zaimplementować graf przetwarzania analitycznego online (OLAP) lub przeprowadzić migrację istniejącej aplikacji Apache Gremlin? Rozważ użycie programu Graph w usłudze Microsoft Fabric.
Ten artykuł zawiera zalecenia dotyczące korzystania z modeli danych grafu. Te najlepsze rozwiązania są niezbędne do zapewnienia skalowalności i wydajności systemu grafowej bazy danych w miarę rozwoju danych. Wydajny model danych jest szczególnie ważny w przypadku grafów na dużą skalę.
Requirements
Proces opisany w tym przewodniku jest oparty na następujących założeniach:
- Jednostki w przestrzeni problemowej są identyfikowane. Te jednostki mają być używane niepodzielnie przy każdym żądaniu. Innymi słowy, system bazy danych nie jest przeznaczony do pobierania danych pojedynczej jednostki w wielu żądaniach zapytań.
- Istnieje wiedza na temat wymagań dotyczących odczytu i zapisu dla systemu bazy danych. Te wymagania prowadzą do optymalizacji wymaganych dla modelu danych grafu.
- Zasady standardu grafu właściwości z platformy Apache są dobrze zrozumiałe.
Kiedy potrzebuję grafowej bazy danych?
Rozwiązanie grafowej bazy danych może być optymalnie używane, jeśli jednostki i relacje w domenie danych mają dowolną z następujących cech:
- Jednostki są bardzo połączone za pośrednictwem relacji opisowych. Korzyścią w tym scenariuszu jest to, że relacje są zapisywane w pamięci.
- Istnieją cykliczne relacje lub jednostki odwołujące się do siebie. Ten schemat jest często wyzwaniem podczas używania relacyjnych lub dokumentowych baz danych.
- Istnieją dynamicznie ewoluujące relacje między jednostkami. Ten wzorzec ma szczególnie zastosowanie do danych hierarchicznych lub ze strukturą drzewa z wieloma poziomami.
- Istnieją relacje wiele-do-wielu między jednostkami.
- Istnieją wymagania dotyczące zapisu i odczytu zarówno dla jednostek, jak i relacji.
Jeśli powyższe kryteria są spełnione, podejście do grafowej bazy danych prawdopodobnie zapewnia zalety złożoności zapytań, skalowalności modelu danych i wydajności zapytań.
Następnym krokiem jest ustalenie, czy graf będzie używany do celów analitycznych lub transakcyjnych. Jeśli wykres ma być używany do dużych obciążeń obliczeniowych i przetwarzania danych, warto rozważyć zastosowanie konektora Spark usługi Cosmos DB i biblioteki GraphX.
Jak używać obiektów grafu
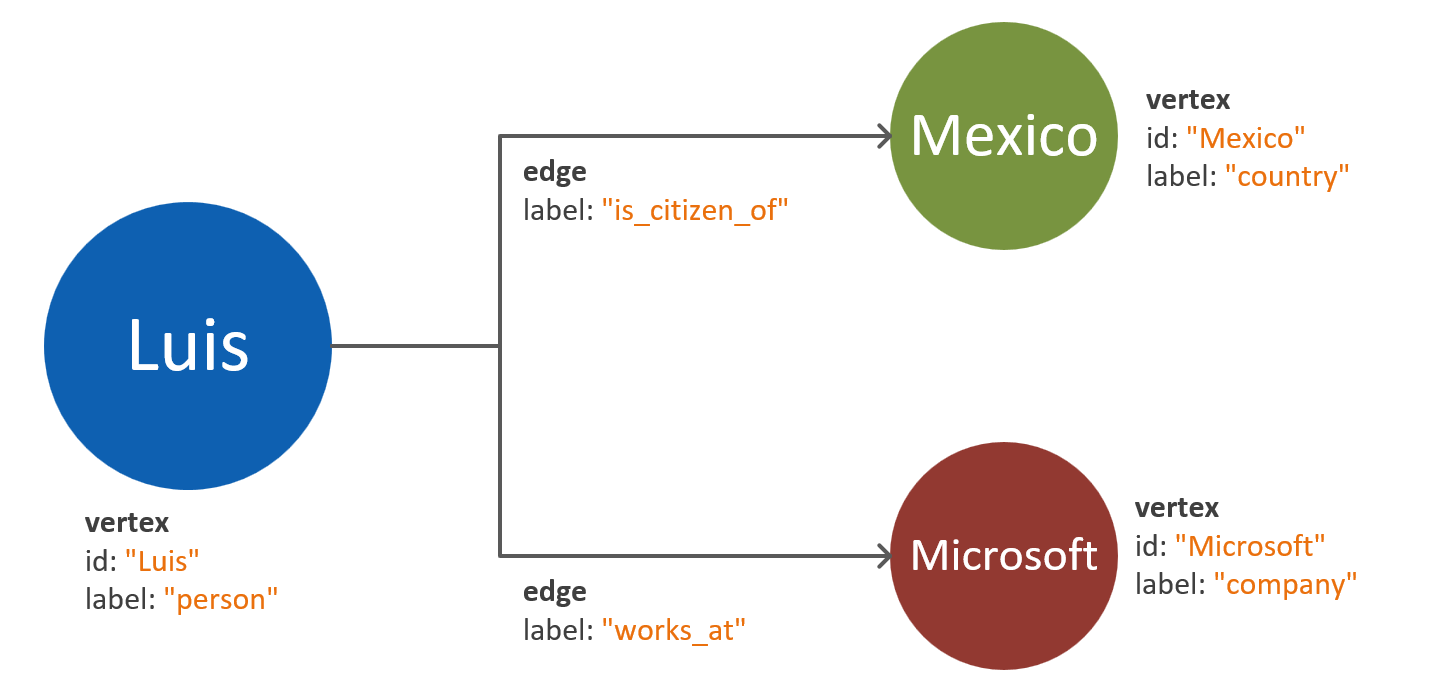
Standard grafu właściwości z platformy Apache definiuje dwa typy obiektów: wierzchołki i krawędzie.
Poniżej przedstawiono najlepsze rozwiązania dotyczące właściwości w obiektach grafu:
| Obiekt | Majątek | Typ | Notatki |
|---|---|---|---|
| Wierzchołki | identyfikator | String | Unikatowo wymuszane dla każdej partycji. Jeśli podczas wstawiania nie zostanie dostarczona wartość, przechowywany jest automatycznie wygenerowany identyfikator GUID. |
| Wierzchołki | Etykieta | String | Ta właściwość służy do definiowania typu jednostki reprezentowanej przez wierzchołek. Jeśli wartość nie zostanie podana, użyta zostanie domyślna wartość vertex. |
| Wierzchołki | Properties | Ciąg, wartość logiczna, liczba | Lista oddzielnych właściwości przechowywanych jako pary klucz-wartość w każdym wierzchołku. |
| Wierzchołki | Klucz partycji | Ciąg, wartość logiczna, liczba | Ta właściwość definiuje miejsce przechowywania wierzchołka i jego krawędzi wychodzących. Przeczytaj więcej na temat partycjonowania grafu. |
| Krawędzie | identyfikator | String | Unikatowo wymuszane dla każdej partycji. Automatycznie generowane domyślnie. Krawędzie zwykle nie muszą być jednoznacznie pobierane przy użyciu identyfikatora. |
| Krawędzie | Etykieta | String | Ta właściwość służy do definiowania typu relacji, którą mają dwa wierzchołki. |
| Krawędzie | Properties | Ciąg, wartość logiczna, liczba | Lista oddzielnych właściwości przechowywanych jako pary klucz-wartość w każdej krawędzi. |
Uwaga / Notatka
Krawędzie nie wymagają wartości klucza partycji, ponieważ wartość jest przypisywana automatycznie na podstawie ich wierzchołka źródłowego. Dowiedz się więcej w temacie Using a partitioned graph in Azure Cosmos DB (Korzystanie z partycjonowanego grafu w usłudze Azure Cosmos DB).
Wytyczne dotyczące modelowania jednostek i relacji
Poniższe wytyczne ułatwiają modelowanie danych dla grafowej bazy danych usługi Azure Cosmos DB dla Apache Gremlin. W tych wytycznych przyjęto założenie, że istnieje istniejąca definicja domeny danych i zapytania dotyczące tej domeny.
Uwaga / Notatka
Poniższe kroki są prezentowane jako zalecenia. Należy ocenić i przetestować ostateczny model przed rozważeniem go jako gotowego do produkcji. Ponadto zalecenia są specyficzne dla implementacji interfejsu API języka Gremlin usługi Azure Cosmos DB.
Modelowanie wierzchołków i właściwości
Pierwszym krokiem modelu danych w grafie jest zmapowanie każdej zidentyfikowanej jednostki na obiekt wierzchołka. Mapowanie "jeden do jednego" wszystkich jednostek do wierzchołków powinno być krokiem początkowym i może ulec zmianie.
Jedną z typowych pułapek jest mapowania właściwości pojedynczej jednostki jako oddzielnych wierzchołków. Rozważmy następujący przykład, w którym ta sama jednostka jest reprezentowana na dwa różne sposoby:
Właściwości oparte na wierzchołku: W tym podejściu jednostka używa trzech oddzielnych wierzchołków i dwóch krawędzi, aby opisać jej właściwości. Chociaż takie podejście może zmniejszyć nadmiarowość, zwiększa złożoność modelu. Zwiększenie złożoności modelu może spowodować dodatkowe opóźnienie, złożoność zapytań i koszt obliczeń. Ten model może również stanowić wyzwania związane z partycjonowaniem.
Wierzchołki z osadzonymi właściwościami: To podejście wykorzystuje listę par klucz-wartość do reprezentowania wszystkich właściwości obiektu wewnątrz wierzchołka. Takie podejście zmniejsza złożoność modelu, co prowadzi do prostszych zapytań i bardziej wydajnych przechodzenia.

Uwaga / Notatka
Na powyższych diagramach przedstawiono uproszczony model grafu, który porównuje tylko dwa sposoby dzielenia właściwości jednostki.
Wzorzec osadzonych wierzchołków właściwości zwykle zapewnia bardziej wydajne i skalowalne podejście. Domyślne podejście do nowego modelu danych grafu powinno skłaniać się ku temu wzorcowi.
Istnieją jednak scenariusze, w których odwoływanie się do właściwości może zapewnić korzyści. Jeśli na przykład odwoływana właściwość jest często aktualizowana. Użyj oddzielnego wierzchołka, aby reprezentować właściwość, która stale się zmienia, aby zminimalizować liczbę operacji zapisu, których wymaga aktualizacja.
Modele relacji z kierunkami krawędzi
Po modelowaniu wierzchołków można dodać krawędzie, aby oznaczyć relacje między nimi. Pierwszym aspektem, który należy ocenić, jest kierunek relacji.
Krawędzie mają domyślny kierunek, po którym następuje przechodzenie podczas korzystania z out() funkcji lub outE() . Ten naturalny kierunek prowadzi do efektywnego działania, ponieważ wszystkie wierzchołki są przechowywane wraz z ich krawędziami wychodzącymi.
Przechodzenie w przeciwnym kierunku krawędzi za pomocą funkcji in() zawsze powoduje zapytanie obejmujące wiele partycji. Dowiedz się więcej o partycjonowaniu grafu. Jeśli wymagane jest częste przechodzenie przy użyciu funkcji in(), dodaj krawędzie w obu kierunkach.
Kierunek krawędzi można określić przy użyciu predykatu .to() lub .from() z krokiem .addE() języka Gremlin. Lub przy użyciu biblioteki wykonawczej do operacji zbiorczych dla interfejsu Gremlin API.
Uwaga / Notatka
Krawędzie mają określony domyślnie kierunek.
Etykiety relacji
Używanie opisowych etykiet relacji może zwiększyć wydajność operacji rozpoznawania krawędzi. Ten wzorzec można zastosować w następujący sposób:
- Użyj niegenerycznych terminów, aby oznaczyć relację.
- Skojarz etykietę wierzchołka źródłowego z etykietą wierzchołka docelowego z nazwą relacji.
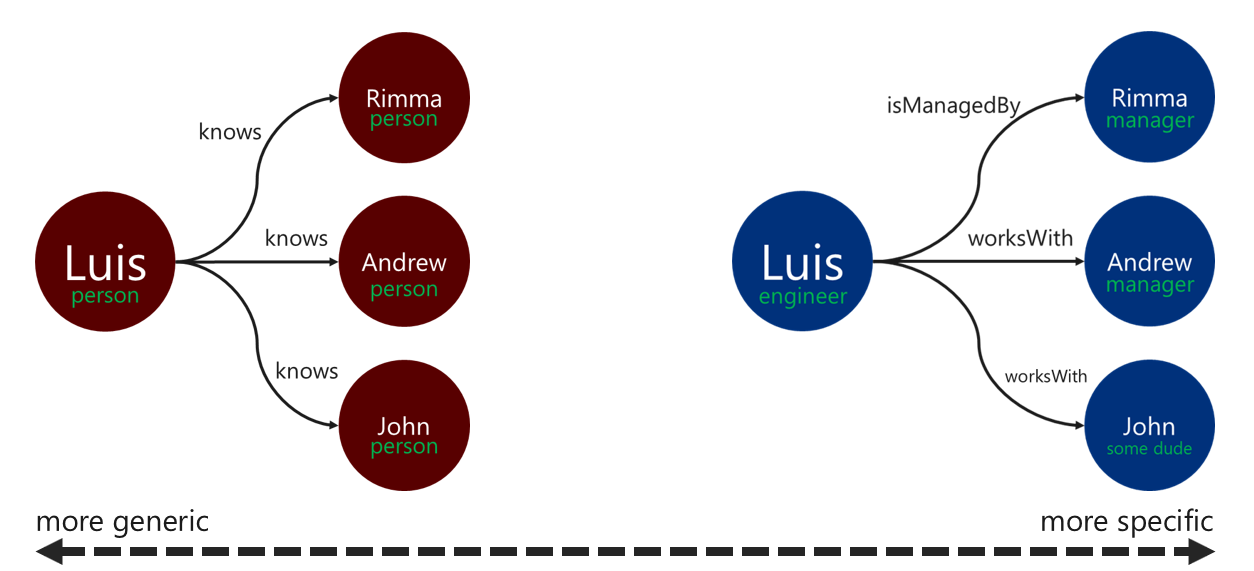
Im bardziej szczegółowa jest etykieta, której przechodzący używa do filtrowania krawędzi, tym lepiej. Ta decyzja może również mieć znaczący wpływ na koszt zapytania. Koszt zapytania można ocenić w dowolnym momencie, korzystając z executionProfile kroku.