Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Kasandra
Kasandra
![]() Gremlin
Gremlin
![]() Stół
Stół
Usługa Azure Monitor dla usługi Azure Cosmos DB udostępnia widok metryk do monitorowania konta i tworzenia pulpitów nawigacyjnych. Metryki usługi Azure Cosmos DB są zbierane domyślnie. Ta funkcja nie wymaga jawnego włączenia ani skonfigurowania niczego.
Definicja metryki
Znormalizowane zużycie jednostek RU to metryka z zakresu od 0% do 100%, która służy do mierzenia wykorzystania zaprovisionowanej przepustowości w bazie danych lub kontenerze. Metryka jest emitowana w 1-minutowych odstępach czasu i jest definiowana jako maksymalne użycie jednostek żądań na sekundę (RU/s) we wszystkich zakresach kluczy partycji w interwale czasu. Każdy zakres kluczy partycji jest mapowany na jedną partycję fizyczną i jest przypisany do przechowywania danych dla zakresu możliwych wartości skrótu. Ogólnie rzecz biorąc, im większy jest znormalizowany procent RU, tym bardziej wykorzystałeś przepływność przydzieloną. Metryka może również służyć do wyświetlania wykorzystania poszczególnych zakresów kluczy partycji w bazie danych lub kontenerze.
Załóżmy na przykład, że masz kontener, w którym ustawiono maksymalną przepływność autoskalowania 20 000 RU/s (skalowanie między 2000 a 20 000 RU/s) i masz dwa zakresy kluczy partycji (partycje fizyczne) P1 i P2. Ponieważ usługa Azure Cosmos DB dystrybuuje aprowizowaną przepływność równomiernie we wszystkich zakresach kluczy partycji, P1 i P2 mogą być skalowane w zakresie od 1000 do 10 000 RU/s. Załóżmy, że w 1-minutowym interwale, w danej sekundzie P1 zużywało 6000 jednostek RU i P2 zużywało 8000 jednostek RU. Znormalizowane użycie jednostek RU P1 wynosi 60% i 80% dla P2. Całkowite znormalizowane użycie jednostek RU całego kontenera wynosi MAX(60%, 80%) = 80%.
Jeśli interesuje Cię wyświetlanie użycia jednostek żądania w sekundowych interwałach, wraz z typem operacji, możesz przystąpić do dzienników diagnostycznych i wysłać zapytanie do tabeli PartitionKeyRUConsumption. Aby uzyskać ogólne omówienie operacji i kodu stanu wykonywanego przez aplikację w zasobie usługi Azure Cosmos DB, możesz użyć wbudowanej metryki Azure Monitor Total Requests (API for NoSQL), Mongo Requests, Gremlin Requests lub Cassandra Requests . Później możesz filtrować te żądania według kodu stanu 429 i podzielić je według typu operacji.
Czego można oczekiwać i zrobić, gdy znormalizowane jednostki RU/s są wyższe
Gdy znormalizowane użycie jednostek RU osiągnie 100% dla danego zakresu kluczy partycji, a klient nadal wysyła żądania w oknie czasowym trwającym 1 sekundę do tego konkretnego zakresu kluczy partycji, otrzymuje błąd związany z ograniczeniem szybkości (429).
Niekoniecznie oznacza to, że występuje problem z zasobem. Domyślnie zestawy SDK klienta Azure Cosmos DB i narzędzia do importowania danych, takie jak Azure Data Factory i biblioteka wykonywania operacji zbiorczych, automatycznie ponawiają próby dla kodu stanu HTTP 429 (Zbyt wiele żądań). Ponawiają próby zazwyczaj do dziewięciu razy. W rezultacie, chociaż w miarach mogą być widoczne błędy 429, te błędy mogą nawet nie zostać przesłane z powrotem do aplikacji.
Ogólnie rzecz biorąc, w przypadku obciążenia produkcyjnego, jeśli widzisz od 1 do 5% żądań z kodem 429, a całkowite opóźnienie jest akceptowalne, jest to pozytywny znak, że RU/s są w pełni wykorzystywane. W tym przypadku metryka znormalizowanego użycia jednostek RU osiąga tylko 100% oznacza, że w danej sekundzie co najmniej jeden zakres kluczy partycji używał całej aprowizowanej przepływności. Jest to dopuszczalne, ponieważ ogólny wskaźnik błędów 429 jest nadal niski. Nie są wymagane żadne dalsze działania.
Aby określić, jaki procent żądań do bazy danych lub kontenera skutkował kodem 429, z poziomu konta Azure Cosmos DB przejdź do sekcji Insights, następnie Requests i Total Requests by Status Code. Filtruj do określonej bazy danych i kontenera. W przypadku interfejsu API dla języka Gremlin użyj metryki Żądania języka Gremlin.

Jeśli znormalizowana metryka użycia jednostek RU jest stale 100% w wielu zakresach kluczy partycji, a szybkość 429 jest większa niż 5%, zaleca się zwiększenie przepływności. Aby dowiedzieć się, których operacji jest najwięcej i jakie jest ich szczytowe użycie, możesz skorzystać z metryk i dzienników diagnostycznych usługi Azure Monitor. Aby dowiedzieć się więcej o najlepszych rozwiązaniach, zobacz Najlepsze rozwiązania dotyczące skalowania aprowizowanej przepływności (RU/s).
Nie zawsze występuje błąd ograniczania szybkości 429 tylko dlatego, że znormalizowana jednostka RU osiągnęła 100%. Wynika to z faktu, że znormalizowana jednostka RU jest pojedynczą wartością, która reprezentuje maksymalne użycie we wszystkich zakresach kluczy partycji. Jeden zakres kluczy partycji może być zajęty, ale inne zakresy kluczy partycji mogą obsługiwać żądania bez problemów. Na przykład pojedyncza operacja taka jak procedura składowania, która zużywa wszystkie jednostki RU/s w obrębie zakresu klucza partycji, powoduje krótki i gwałtowny skok w metryce znormalizowanego użycia jednostek RU. W takich przypadkach nie ma żadnych natychmiastowych błędów ograniczania szybkości, jeśli ogólna szybkość żądania jest niska lub żądania są wysyłane do innych partycji w różnych zakresach kluczy partycji.
Aby dowiedzieć się więcej, zobacz Diagnozowanie i rozwiązywanie problemów z wyjątkami 429.
Jak monitorować gorące partycje
Metryka znormalizowanego użycia jednostek ŻĄDANIA może służyć do monitorowania, czy obciążenie ma gorącą partycję. Gorąca partycja pojawia się, gdy jeden lub kilka kluczy partycji logicznych zużywa nieproporcjonalną ilość całkowitej liczby jednostek RU/s z powodu większego woluminu żądań. Może to być spowodowane przez projekt klucza partycji, który nie dystrybuuje równomiernie żądań. Powoduje to kierowanie wielu żądań do niewielkiego podzbioru partycji logicznych (co oznacza zakresy kluczy partycji), które stają się gorące. Ponieważ wszystkie dane logicznej partycji znajdują się w jednym zakresie kluczy, a całkowita liczba jednostek żądań na sekundę (RU/s) jest równomiernie rozłożona między wszystkie zakresy kluczy partycji, gorąca partycja może prowadzić do błędu HTTP 429 „Zbyt wiele żądań” i nieefektywnego wykorzystania przepustowości.
Jak zidentyfikować gorącą partycję
Aby sprawdzić, czy istnieje gorąca partycja, przejdź do >>Znormalizowane użycie jednostek RU (%) według PartitionKeyRangeID. Filtruj do określonej bazy danych i kontenera.
Każda partycja PartitionKeyRangeId mapuje na jedną partycję fizyczną. Jeśli istnieje jeden identyfikator PartitionKeyRangeId, który ma wyższe znormalizowane zużycie jednostek zasobów RU niż inne (na przykład jeden utrzymuje się na poziomie 100%, podczas gdy inne pozostają na poziomie 30% lub niższym), może to wskazywać na "gorącą" partycję.
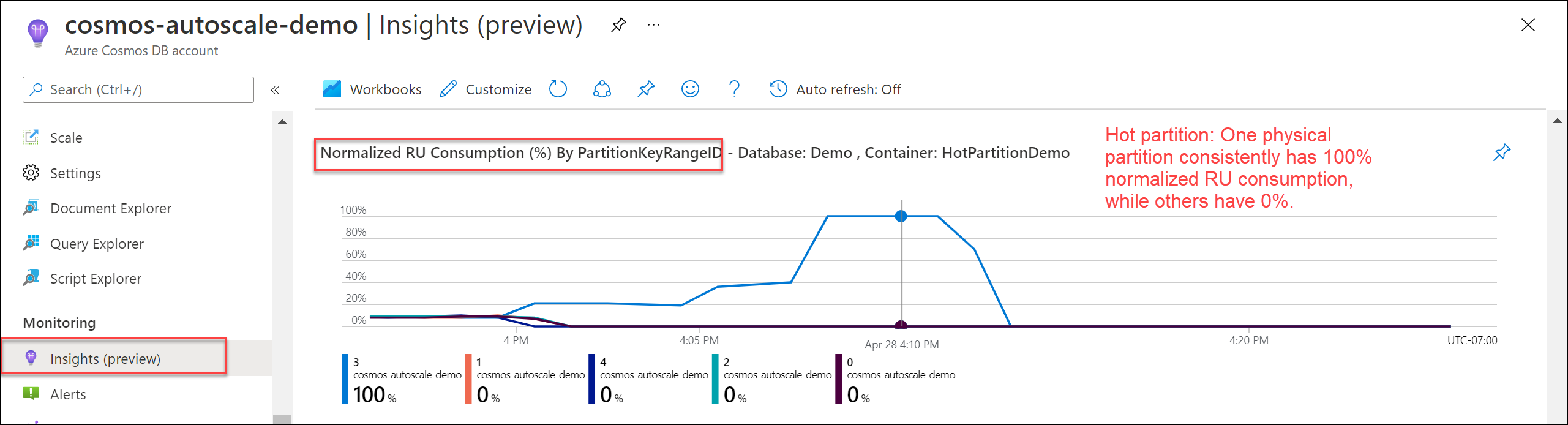
Aby zidentyfikować partycje logiczne, które zużywają najwięcej jednostek RU/s, zobacz Jak zidentyfikować gorącą partycję.
Znormalizowane zużycie jednostek RU i automatyczne skalowanie
Znormalizowana metryka zużycia jednostek RU jest wyświetlana jako 100%, jeśli co najmniej jeden zakres kluczy partycji wykorzystuje wszystkie przydzielone jednostki RU/s w dowolnej sekundzie w danym przedziale czasowym. Jednym z typowych pytań jest to, dlaczego znormalizowane użycie jednostek RU wynosi 100%, ale usługa Azure Cosmos DB nie przeskalowała jednostek RU/s do maksymalnej przepływności z autoskalowaniem?
Uwaga
Poniższe informacje opisują bieżącą implementację autoskalowania i mogą ulec zmianie w przyszłości.
W przypadku korzystania z automatycznego skalowania usługa Azure Cosmos DB skaluje wartość RU/s tylko do maksymalnej przepływności, gdy znormalizowane użycie jednostek RU wynosi 100% dla trwałego, ciągłego okresu w 5-sekundowym interwale. Dzięki temu logika skalowania jest przyjazna dla użytkownika, ponieważ gwarantuje, że pojedyncze, chwilowe skoki nie prowadzą do niepotrzebnego skalowania i wyższych kosztów. Gdy występują chwilowe skoki, system zwykle skaluje w górę do wartości wyższej niż wcześniej skalowana do ru/s, ale niższa niż maksymalna liczba jednostek RU/s.
Załóżmy na przykład, że masz kontener z maksymalną przepływnością skalowania automatycznego 20 000 RU/s (skaluje się między 2000 a 20 000 RU/s) i dwoma zakresami kluczy partycji. Każdy zakres kluczy partycji może być skalowany w zakresie od 1000 do 10 000 RU/s. Ponieważ automatyczne skalowanie aprowizuje wszystkie wymagane zasoby z góry, w dowolnym momencie można użyć maksymalnie 20 000 RU/s.
Teraz załóżmy, że masz okresowe skoki ruchu.
Przez jedną sekundę partycja 1 zwiększa się do 10 000 RU/s, a następnie spada do 1000 RU/s w ciągu najbliższych czterech sekund.
Jednocześnie partycja 2 skokowo rośnie do 8000 RU/s, a następnie spada do 1000 RU/s i pozostaje na tym poziomie przez kolejne cztery sekundy.
W ten sposób działają metryki:
Znormalizowane zużycie jednostek RU (które pokazuje maksymalne użycie w interwale we wszystkich partycjach) wskazuje na wykorzystanie 100%, ponieważ partycja 1 osiągnęła maksymalne zużycie na jedną sekundę.
Jednak aprowizowana przepływność i metryki jednostek RU skalowane automatycznie nie są skalowane w górę do maksymalnej liczby jednostek RU/s tylko z powodu 1-sekundowego skoku. Skaluje się na podstawie 5-sekundowego interwału, aby był opłacalny. W poprzednim przykładzie zużycie RU przez partycję 1 i partycję 2 nie osiągają 10 000 RU/s w oparciu o 5-sekundowy interwał.
W rezultacie, mimo że autoskalowanie nie skalowało się do maksimum, nadal można było użyć całkowitej dostępnej liczby jednostek RU/s w tym gwałtownym momencie. Aby zweryfikować użycie jednostek RU/s, możesz zdecydować się na użycie funkcji dzienników diagnostycznych, aby wykonać zapytanie dotyczące ogólnego użycia jednostek RU/s na poziomie sekundowym we wszystkich zakresach kluczy partycji.
CDBPartitionKeyRUConsumption
| where TimeGenerated >= (todatetime('2022-01-28T20:35:00Z')) and TimeGenerated <= todatetime('2022-01-28T20:40:00Z')
| where DatabaseName == "MyDatabase" and CollectionName == "MyContainer"
| summarize sum(RequestCharge) by bin(TimeGenerated, 1sec), PartitionKeyRangeId
| render timechart
Ogólnie rzecz biorąc, w przypadku obciążenia produkcyjnego przy użyciu automatycznego skalowania, jeśli widzisz od 1 do 5% żądań z kodem 429, a całkowite opóźnienie jest akceptowalne, jest to dobry znak, że RU/s są w pełni wykorzystywane. Nawet jeśli znormalizowane użycie jednostek RU od czasu do czasu osiągnie 100%, a autoskalowanie nie skaluje się w górę do maksymalnej wartości RU/s, jest to ok, ponieważ ogólna szybkość 429s jest niska. Nie trzeba podejmować żadnych działań.
Napiwek
Jeśli korzystasz z autoskalowania i zauważysz, że znormalizowane zużycie RU jest ciągle na poziomie 100%, a proces jest stale skalowany do maksymalnej ilości RU/s, może to wskazywać, że ręczne zarządzanie przepływnością może być bardziej opłacalne. Aby określić, czy automatyczne skalowanie czy przepływność ręczna jest najlepsza dla obciążenia, zobacz Jak wybrać między standardową (ręczną) i aprowizowaną przepływnością autoskalowania. Usługa Azure Cosmos DB wysyła również zalecenia dotyczące kosztów na podstawie wzorców obciążeń, aby zalecić ręczne lub automatyczne skalowanie przepływności.
Wyświetlanie metryki znormalizowanych jednostek żądania
Zaloguj się w witrynie Azure Portal.
Wybierz pozycję Monitoruj na pasku nawigacyjnym po lewej stronie, a następnie wybierz pozycję Metryki.
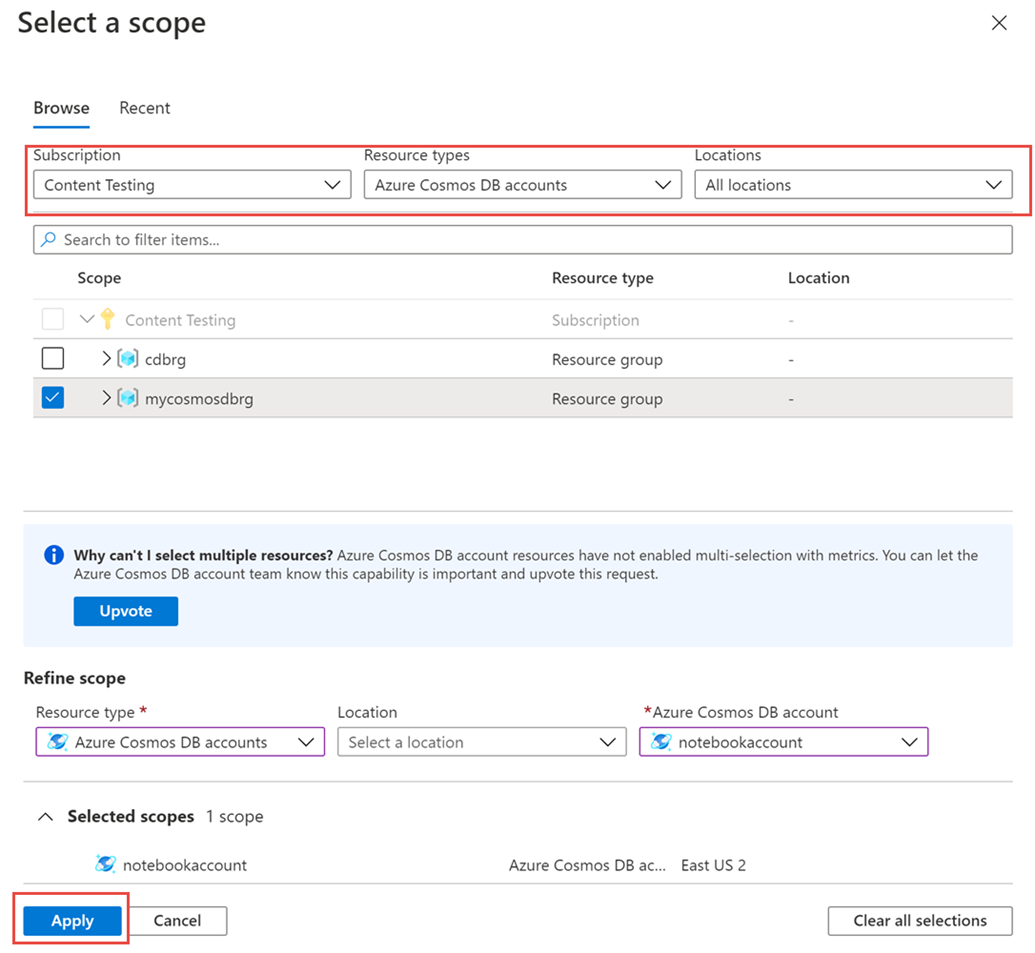
W okienku > Wybierz zasób> wybierz wymaganą subskrypcję i grupę zasobów. W polu Typ zasobu wybierz pozycję Konta usługi Azure Cosmos DB, wybierz jedno z istniejących kont usługi Azure Cosmos DB, a następnie wybierz pozycję Zastosuj.
Następnie możesz wybrać metrykę z listy dostępnych metryk. Możesz wybrać metryki specyficzne dla jednostek żądania, magazynu, opóźnienia, dostępności, bazy danych Cassandra i innych. Aby dowiedzieć się szczegółowo o wszystkich dostępnych metrykach na tej liście, zobacz artykuł Metryki według kategorii . W tym przykładzie wybierzmy metryki Znormalizowane użycie jednostek RU i Wartość maksymalna jako wartość agregacji.
Oprócz tych szczegółów można również wybrać zakres czasu i stopień szczegółowości czasu metryk. Maksymalnie można wyświetlić metryki z ostatnich 30 dni. Po zastosowaniu filtru zostanie wyświetlony wykres na podstawie filtru.
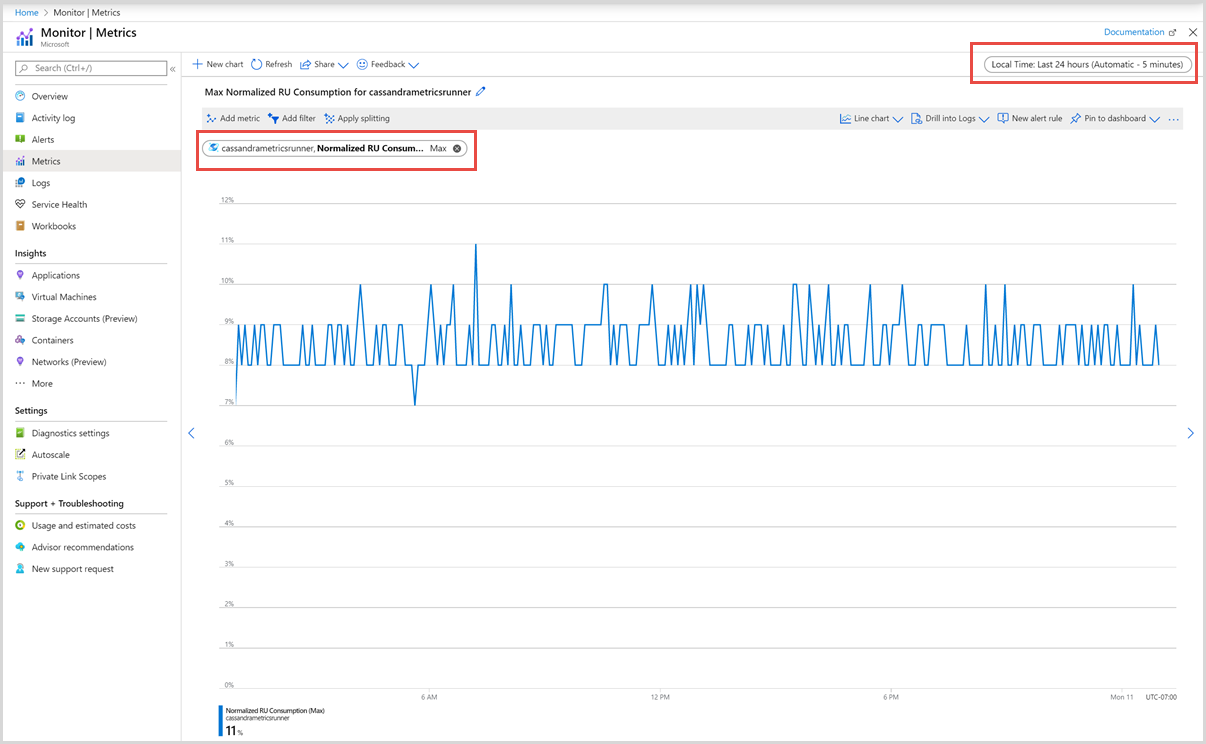



Filtry dla metryki znormalizowanych jednostek RU
Możesz również filtrować metryki i wykres wyświetlany według określonej wartości CollectionName, DatabaseName, PartitionKeyRangeID i Region. Aby filtrować metryki, wybierz pozycję Dodaj filtr i wybierz wymaganą właściwość, taką jak CollectionName i odpowiadającą ci wartość. Następnie na wykresie jest wyświetlana metryka znormalizowanego użycia jednostek RU dla kontenera dla wybranego okresu.
Metryki można grupować przy użyciu opcji Zastosuj dzielenie . W przypadku baz danych z udostępnioną przepływnością metryka znormalizowanej jednostki RU pokazuje tylko dane na poziomie szczegółowości bazy danych, ale nie wyświetla żadnych danych na kolekcję. W przypadku bazy danych z udostępnioną przepływnością nie będą widoczne żadne dane podczas stosowania podziału według nazwy kolekcji.
Metryka znormalizowanych użycia jednostek żądania dla każdego kontenera jest wyświetlana, jak pokazano na poniższej ilustracji:

Następne kroki
- Monitorowanie danych usługi Azure Cosmos DB przy użyciu ustawień diagnostycznych usługi Azure Monitor Log Analytics
- Jak przeprowadzać inspekcję operacji płaszczyzny sterowania usługi Azure Cosmos DB
- Diagnozowanie i rozwiązywanie problemów z wyjątkami zbyt dużej szybkości żądań usługi Azure Cosmos DB (429)