Diagnozowanie i rozwiązywanie problemów z wyjątkami zbyt dużej szybkości żądań usługi Azure Cosmos DB (429)
DOTYCZY: ![]() NoSQL
NoSQL
Ten artykuł zawiera znane przyczyny i rozwiązania dla różnych błędów kodu stanu 429 dla interfejsu API dla noSQL. Jeśli używasz interfejsu API dla bazy danych MongoDB, zobacz artykuł Rozwiązywanie typowych problemów z interfejsem API dla bazy danych MongoDB , aby dowiedzieć się, jak debugować kod stanu 16500.
Wyjątek "Zbyt duża liczba żądań", znany również jako kod błędu 429, wskazuje, że żądania względem usługi Azure Cosmos DB są ograniczone.
W przypadku korzystania z aprowizowanej przepływności ustawisz przepływność mierzoną w jednostkach żądań na sekundę (RU/s) wymaganą dla obciążenia. Operacje bazy danych względem usługi, takie jak odczyty, zapisy i zapytania, zużywają pewną liczbę jednostek żądania (RU). Dowiedz się więcej o jednostkach żądań.
W danej sekundzie, jeśli operacje zużywają więcej niż aprowizowane jednostki żądania, usługa Azure Cosmos DB zwróci wyjątek 429. Każda sekunda liczba jednostek żądań dostępnych do użycia jest resetowana.
Przed podjęciem akcji w celu zmiany jednostek RU/s należy zrozumieć główną przyczynę ograniczania szybkości i rozwiązać podstawowy problem.
Napiwek
Wskazówki zawarte w tym artykule dotyczą baz danych i kontenerów korzystających z aprowizowanej przepływności — automatycznego skalowania i przepływności ręcznej.
Istnieją różne komunikaty o błędach, które odpowiadają różnym typom wyjątków 429:
- Duża liczba żądań. Może być potrzebnych więcej jednostek żądań, więc nie wprowadzono żadnych zmian.
- Żądanie nie zostało ukończone z powodu wysokiej liczby żądań metadanych.
- Żądanie nie zostało ukończone z powodu błędu usługi przejściowej.
Szybkość żądań jest duża
Jest to najbardziej typowy scenariusz. Występuje, gdy jednostki żądania używane przez operacje na danych przekraczają aprowizowaną liczbę jednostek RU/s. Jeśli używasz przepływności ręcznej, występuje to w przypadku użycia większej liczby jednostek RU/s niż aprowizowana przepływność ręczna. Jeśli używasz skalowania automatycznego, dzieje się tak, gdy używasz więcej niż maksymalna aprowizowana liczba jednostek RU/s. Jeśli na przykład masz zasób aprowizowany z ręczną przepływnością 400 RU/s, zobaczysz 429, gdy zużywasz więcej niż 400 jednostek żądań w ciągu jednej sekundy. Jeśli masz zasób aprowizowany przy użyciu maksymalnej wartości RU/s autoskalowania 4000 RU/s (skaluje się między 400 RU/s - 4000 RU/s), zobaczysz 429 odpowiedzi, gdy zużywasz więcej niż 4000 jednostek żądań w ciągu jednej sekundy.
Napiwek
Wszystkie operacje są naliczane na podstawie liczby używanych zasobów. Te opłaty są mierzone w jednostkach żądań. Te opłaty obejmują żądania, które nie zostały ukończone pomyślnie z powodu błędów aplikacji, takich jak 400, 412, 449itp. Patrząc na ograniczanie przepustowości lub użycie, warto sprawdzić, czy jakiś wzorzec uległ zmianie w użyciu, co spowodowałoby wzrost tych operacji. W szczególności sprawdź tagi 412 lub 449 (rzeczywisty konflikt).
Aby uzyskać więcej informacji na temat aprowizowanej przepływności, zobacz Aprowizowanie przepływności w usłudze Azure Cosmos DB.
Krok 1. Sprawdź metryki, aby określić procent żądań z błędem 429
Wyświetlanie komunikatów o błędach 429 niekoniecznie oznacza, że występuje problem z bazą danych lub kontenerem. Niewielka wartość procentowa 429 odpowiedzi jest normalna niezależnie od tego, czy używasz przepływności ręcznej, czy automatycznej, i jest znakiem, że maksymalizujesz aprowizowaną jednostkę RU/s.
Jak badać
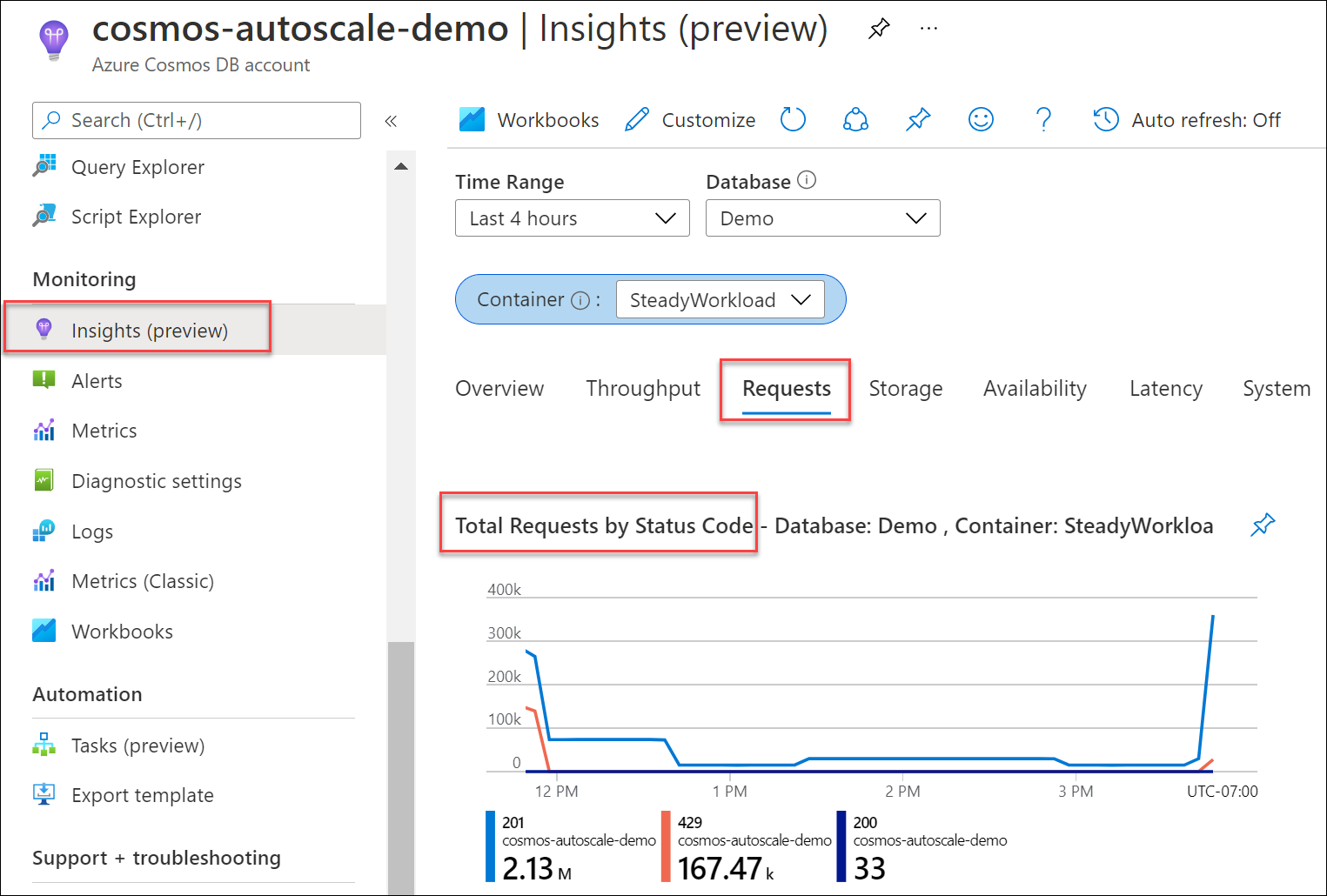
Określ, jaki procent żądań do bazy danych lub kontenera spowodował 429 odpowiedzi, w porównaniu z ogólną liczbą żądań zakończonych powodzeniem. Na koncie usługi Azure Cosmos DB przejdź do pozycji Insights Requests Total Requests by Status Code (Łączna liczba żądań szczegółowych>według>kodu stanu). Filtruj do określonej bazy danych i kontenera.
Domyślnie zestawy SDK klienta usługi Azure Cosmos DB i narzędzia do importowania danych, takie jak usługa Azure Data Factory i biblioteka funkcji wykonawczej operacji zbiorczych, automatycznie ponawiają żądania na 429s. Ponawiają próby zazwyczaj do dziewięciu razy. W związku z tym, chociaż w metrykach może zostać wyświetlonych 429 odpowiedzi, te błędy mogą nawet nie zostać zwrócone do aplikacji.
Zalecane rozwiązanie
Ogólnie rzecz biorąc, w przypadku obciążenia produkcyjnego, jeśli widzisz od 1 do 5% żądań z 429 odpowiedziami, a końcowe opóźnienie jest akceptowalne, jest to znak dobrej kondycji, że ru/s są w pełni wykorzystywane. Nie trzeba podejmować żadnych działań. W przeciwnym razie przejdź do następnych kroków rozwiązywania problemów.
Ważne
Ten zakres 1–5% zakłada, że partycje konta są równomiernie dystrybuowane. Jeśli partycje nie są równomiernie rozproszone, partycja problemu może zwrócić dużą ilość błędów 429, podczas gdy ogólna szybkość może być niska.
Jeśli używasz autoskalowania, możesz zobaczyć 429 odpowiedzi w bazie danych lub kontenerze, nawet jeśli liczba jednostek RU/s nie została przeskalowana do maksymalnej liczby jednostek RU/s. Zobacz sekcję Częstotliwość żądań jest duża z autoskalowaniem , aby uzyskać wyjaśnienie.
Jednym z typowych pytań, które pojawia się, jest "Dlaczego widzę 429 odpowiedzi w metrykach usługi Azure Monitor, ale nie ma ich we własnym monitorowaniu aplikacji?" Jeśli metryki usługi Azure Monitor pokazują, że masz 429 odpowiedzi, ale nie widzisz ich we własnej aplikacji, jest to spowodowane tym, że domyślnie zestawy SDK automatically retried internally on the 429 responses klienta usługi Azure Cosmos DB i żądanie zakończyło się kolejnymi ponownymi próbami. W związku z tym kod stanu 429 nie jest zwracany do aplikacji. W takich przypadkach ogólna szybkość odpowiedzi 429 jest zwykle minimalna i można je bezpiecznie zignorować, zakładając, że ogólna szybkość wynosi od 1 do 5% i końcowe opóźnienie jest akceptowalna dla aplikacji.
Krok 2. Określenie, czy istnieje gorąca partycja
Gorąca partycja pojawia się, gdy jeden lub kilka kluczy partycji logicznych zużywa nieproporcjonalną ilość całkowitej liczby jednostek RU/s z powodu większego woluminu żądań. Może to być spowodowane przez projekt klucza partycji, który nie dystrybuuje równomiernie żądań. Powoduje to kierowanie wielu żądań do małego podzbioru partycji logicznych (co oznacza fizyczne), które stają się "gorące". Ponieważ wszystkie dane partycji logicznej znajdują się na jednej partycji fizycznej, a łączna liczba jednostek RU/s jest równomiernie rozłożona między partycje fizyczne, gorąca partycja może prowadzić do 429 odpowiedzi i nieefektywnego wykorzystania przepływności.
Oto kilka przykładów strategii partycjonowania, które prowadzą do gorących partycji:
- Masz kontener przechowujący dane urządzenia IoT dla obciążenia z dużym obciążeniem zapisu podzielonym na partycje według
date. Wszystkie dane dla jednej daty będą znajdować się na tej samej partycji logicznej i fizycznej. Ze względu na to, że wszystkie zapisane dane każdego dnia mają taką samą datę, co dzień spowoduje to powstanie gorącej partycji.- Zamiast tego w tym scenariuszu klucz partycji, taki jak
id(identyfikator GUID lub identyfikator urządzenia), albo syntetyczny klucz partycji łączącyididatedaje większą kardynalność wartości i lepszą dystrybucję woluminu żądania.
- Zamiast tego w tym scenariuszu klucz partycji, taki jak
- Masz scenariusz z wieloma dzierżawami z kontenerem podzielonym na partycje według
tenantId. Jeśli jedna dzierżawa jest o wiele bardziej aktywna niż inne, powoduje to gorącą partycję. Jeśli na przykład największa dzierżawa ma 100 000 użytkowników, ale większość dzierżaw ma mniej niż 10 użytkowników, podczas partycjonowaniatenantIDprzez usługę będziesz mieć gorącą partycję.- W przypadku tego poprzedniego scenariusza rozważ utworzenie dedykowanego kontenera dla największej dzierżawy podzielonej na partycje przez bardziej szczegółową właściwość, taką jak
UserId.
- W przypadku tego poprzedniego scenariusza rozważ utworzenie dedykowanego kontenera dla największej dzierżawy podzielonej na partycje przez bardziej szczegółową właściwość, taką jak
Jak zidentyfikować gorącą partycję
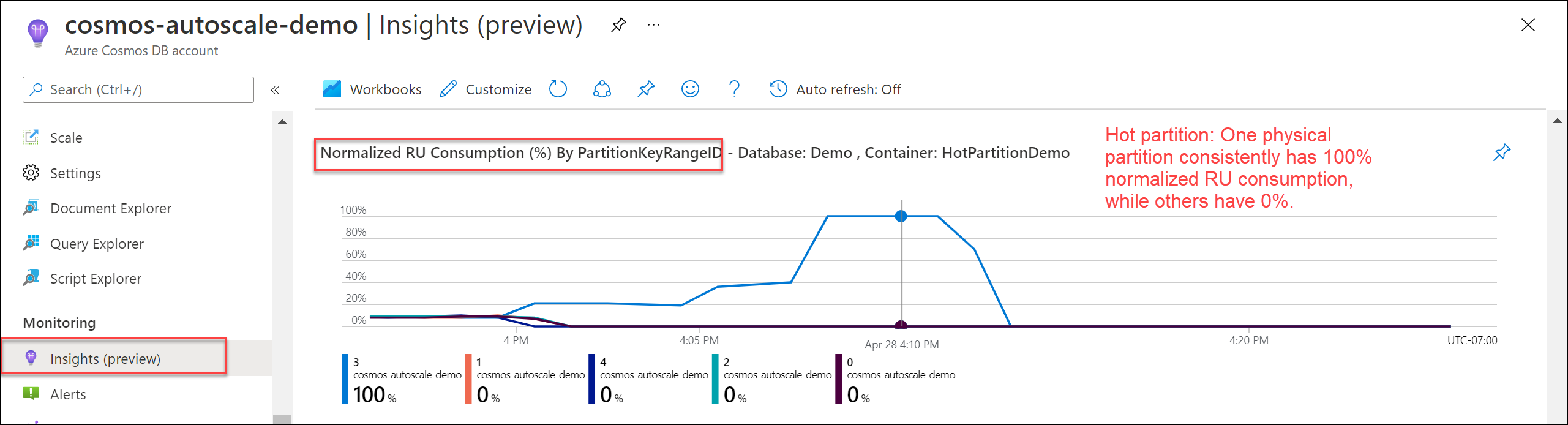
Aby sprawdzić, czy istnieje gorąca partycja, przejdź do pozycji Szczegółowe informacje>>Znormalizowane użycie jednostek RU (%) według PartitionKeyRangeID. Filtruj do określonej bazy danych i kontenera.
Każda partycja PartitionKeyRangeId mapuje na jedną partycję fizyczną. Jeśli istnieje jeden identyfikator PartitionKeyRangeId, który ma znacznie wyższe znormalizowane użycie jednostek RU niż inne (na przykład jeden jest stale w 100%, ale inne są w 30% lub mniej), może to być oznaką gorącej partycji. Dowiedz się więcej o metryce Znormalizowane użycie jednostek RU.
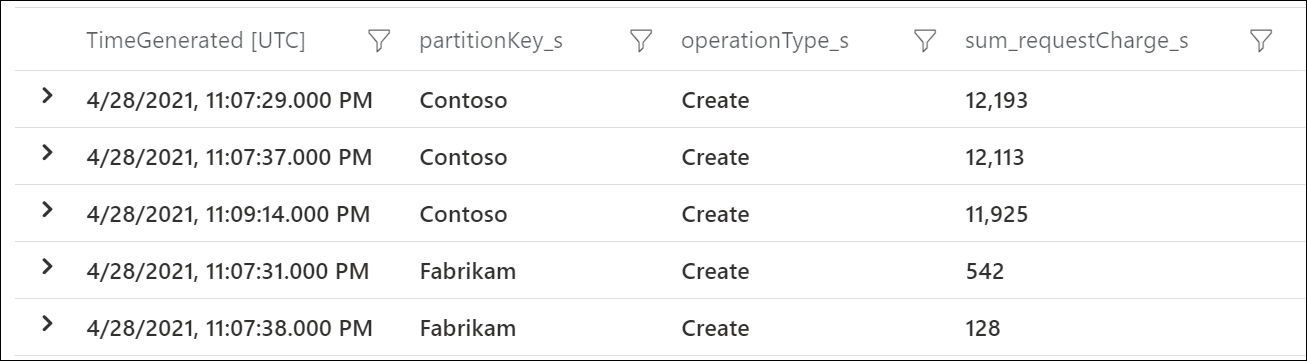
Aby sprawdzić, które klucze partycji logicznej zużywają najwięcej jednostek RU/s, użyj dzienników diagnostycznych platformy Azure. To przykładowe zapytanie sumuje łączną liczbę jednostek żądania zużywanych na sekundę dla każdego klucza partycji logicznej.
Ważne
Włączenie dzienników diagnostycznych powoduje naliczanie oddzielnej opłaty za usługę Log Analytics, która jest rozliczana na podstawie ilości pozyskanych danych. Zaleca się włączenie dzienników diagnostycznych przez ograniczony czas na debugowanie i wyłączenie, gdy nie jest już wymagane. Aby uzyskać szczegółowe informacje, zobacz stronę cennika.
CDBPartitionKeyRUConsumption
| where TimeGenerated >= ago(24hour)
| where CollectionName == "CollectionName"
| where isnotempty(PartitionKey)
// Sum total request units consumed by logical partition key for each second
| summarize sum(RequestCharge) by PartitionKey, OperationName, bin(TimeGenerated, 1s)
| order by sum_RequestCharge desc
Te przykładowe dane wyjściowe pokazują, że w określonej minucie klucz partycji logicznej o wartości "Contoso" zużywał około 12 000 RU/s, podczas gdy klucz partycji logicznej o wartości "Fabrikam" zużywał mniej niż 600 RU/s. Jeśli ten wzorzec był spójny w okresie, w którym wystąpiło ograniczanie szybkości, oznaczałoby to gorącą partycję.
Napiwek
W każdym obciążeniu wystąpią naturalne różnice w woluminie żądań w różnych partycjach logicznych. Należy określić, czy gorąca partycja jest spowodowana podstawową niesymetrycznością z powodu wyboru klucza partycji (co może wymagać zmiany klucza) lub tymczasowego skoku ze względu na naturalne różnice w wzorcach obciążeń.
Zalecane rozwiązanie
Zapoznaj się ze wskazówkami dotyczącymi wyboru dobrego klucza partycji.
Jeśli istnieje wysoki procent liczby ograniczonych żądań i brak gorącej partycji:
- Liczbę jednostek RU/s można zwiększyć w bazie danych lub kontenerze przy użyciu zestawów SDK klienta, witryny Azure Portal, programu PowerShell, interfejsu wiersza polecenia lub szablonu usługi ARM. Postępuj zgodnie z najlepszymi rozwiązaniami dotyczącymi skalowania aprowizowanej przepływności (RU/s), aby określić właściwą wartość RU/s do ustawienia.
Jeśli istnieje duża liczba żądań z ograniczoną szybkością i istnieje podstawowa gorąca partycja:
- Długoterminowe, aby uzyskać najlepsze koszty i wydajność, rozważ zmianę klucza partycji. Nie można zaktualizować klucza partycji, więc wymaga to migracji danych do nowego kontenera przy użyciu innego klucza partycji. Usługa Azure Cosmos DB obsługuje w tym celu narzędzie do migracji danych na żywo.
- Krótkoterminowo można tymczasowo zwiększyć ogólną liczbę jednostek RU/s zasobu, aby umożliwić większą przepływność na gorącą partycję. Nie jest to zalecane jako strategia długoterminowa, ponieważ prowadzi do nadmiernej aprowizacji jednostek RU/s i wyższych kosztów.
- Krótkoterminowo można użyć funkcji redystrybucji przepływności między partycjami (wersja zapoznawcza), aby przypisać więcej jednostek RU/s do partycji fizycznej, która jest gorąca. Jest to zalecane tylko wtedy, gdy gorąca partycja fizyczna jest przewidywalna i spójna.
Napiwek
Po zwiększeniu przepływności operacja skalowania w górę zostanie ukończona natychmiast lub będzie wymagać wykonania do 5–6 godzin, w zależności od liczby jednostek RU/s, do których chcesz przeprowadzić skalowanie w górę. Jeśli chcesz poznać największą liczbę jednostek RU/s, możesz ustawić bez wyzwalania operacji skalowania asynchronicznego (co wymaga, aby usługa Azure Cosmos DB aprowizować więcej partycji fizycznych), pomnożyć liczbę unikatowych identyfikatorów PartitionKeyRangeIds przez 10 0000 RU/s. Jeśli na przykład masz aprowizowaną 30 000 RU/s i 5 partycji fizycznych (6000 RU/s przydzielonych na partycję fizyczną), możesz zwiększyć do 50 000 RU/s (10 000 RU/s na partycję fizyczną) w natychmiastowej operacji skalowania w górę. Zwiększenie do >50 000 RU/s wymaga operacji asynchronicznej skalowania w górę. Dowiedz się więcej o najlepszych rozwiązaniach dotyczących skalowania aprowizowanej przepływności (RU/s).
Krok 3. Określanie żądań zwracanych odpowiedzi 429
Jak badać żądania przy użyciu odpowiedzi 429
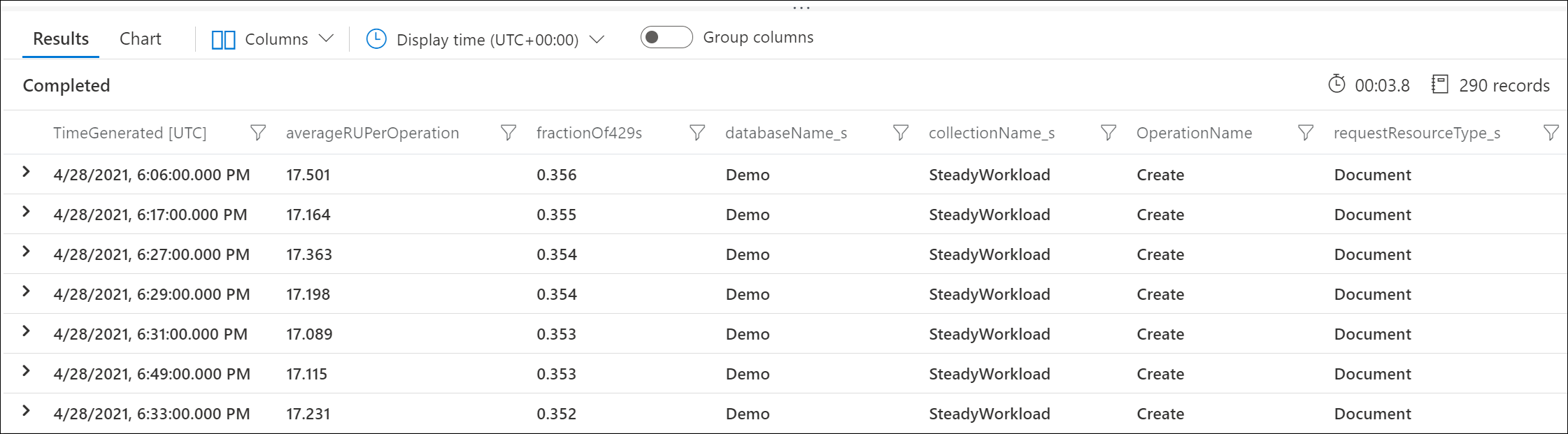
Użyj dzienników diagnostycznych platformy Azure, aby określić, które żądania zwracają 429 odpowiedzi i liczbę użytych jednostek RU. To przykładowe zapytanie agreguje się na poziomie minuty.
Ważne
Włączenie dzienników diagnostycznych powoduje naliczanie oddzielnej opłaty za usługę Log Analytics, która jest rozliczana na podstawie ilości pozyskanych danych. Zaleca się włączenie dzienników diagnostycznych przez ograniczony czas na debugowanie i wyłączenie, gdy nie jest już wymagane. Aby uzyskać szczegółowe informacje, zobacz stronę cennika.
CDBDataPlaneRequests
| where TimeGenerated >= ago(24h)
| summarize throttledOperations = dcountif(ActivityId, StatusCode == 429), totalOperations = dcount(ActivityId), totalConsumedRUPerMinute = sum(RequestCharge) by DatabaseName, CollectionName, OperationName, RequestResourceType, bin(TimeGenerated, 1min)
| extend averageRUPerOperation = 1.0 * totalConsumedRUPerMinute / totalOperations
| extend fractionOf429s = 1.0 * throttledOperations / totalOperations
| order by fractionOf429s desc
Na przykład w tych przykładowych danych wyjściowych pokazano, że w każdej minucie 30% żądań tworzenia dokumentów było ograniczonych, przy czym każde żądanie zużywa średnio 17 jednostek RU.
Zalecane rozwiązanie
Korzystanie z planisty pojemności usługi Azure Cosmos DB
Możesz użyć planisty pojemności usługi Azure Cosmos DB, aby zrozumieć, jaka jest najlepsza aprowizowana przepływność na podstawie obciążenia (woluminu i typu operacji i rozmiaru dokumentów). Możesz dostosować dalsze obliczenia, podając przykładowe dane w celu uzyskania dokładniejszego oszacowania.
429 odpowiedzi dotyczące żądań tworzenia, zastępowania lub upsert dokumentów
- Domyślnie w interfejsie API dla NoSQL wszystkie właściwości są domyślnie indeksowane. Dostosuj zasady indeksowania, aby indeksować tylko wymagane właściwości. Spowoduje to obniżenie liczby jednostek żądań wymaganych na operację tworzenia dokumentu, co zmniejszy prawdopodobieństwo wyświetlania odpowiedzi 429 lub pozwoli osiągnąć wyższe operacje na sekundę dla tej samej liczby aprowizowanych jednostek RU/s.
429 odpowiedzi dotyczące żądań dokumentów zapytań
- Postępuj zgodnie ze wskazówkami, aby rozwiązać problemy z zapytaniami z wysoką opłatą za jednostki RU
429 odpowiedzi dotyczące wykonywania procedur składowanych
- Procedury składowane są przeznaczone dla operacji wymagających transakcji zapisu w wartości klucza partycji. Nie zaleca się używania procedur składowanych dla dużej liczby operacji odczytu lub zapytań. Aby uzyskać najlepszą wydajność, należy wykonać te operacje odczytu lub zapytań po stronie klienta przy użyciu zestawów SDK usługi Azure Cosmos DB.
Szybkość żądań jest duża z autoskalowaniem
Wszystkie wskazówki zawarte w tym artykule dotyczą przepływności ręcznej i automatycznej.
W przypadku korzystania z autoskalowania pojawia się często zadawane pytanie: "Czy nadal można zobaczyć 429 odpowiedzi z autoskalowaniem?"
Tak. Istnieją dwa główne scenariusze, w których może się to zdarzyć.
Scenariusz 1: Gdy ogólna liczba jednostek RU/s przekracza maksymalną liczbę jednostek RU/s bazy danych lub kontenera, usługa odpowiednio ograniczy żądania. Jest to analogiczne do przekroczenia ogólnej przepływności aprowizowanej ręcznie bazy danych lub kontenera.
Scenariusz 2: Jeśli istnieje gorąca partycja, oznacza to, że wartość klucza partycji logicznej, która ma nieproporcjonalnie wyższą ilość żądań w porównaniu z innymi wartościami klucza partycji, istnieje możliwość przekroczenia budżetu jednostek RU/s bazowej partycji fizycznej. Najlepszym rozwiązaniem, aby uniknąć gorących partycji, jest wybranie właściwego klucza partycji, który zapewni równomierny rozkład magazynowania i przepływności. Jest to podobne do tego, gdy w przypadku korzystania z przepływności ręcznej występuje gorąca partycja.
Jeśli na przykład wybierzesz opcję 20 000 RU/s maksymalnej przepływności i masz 200 GB miejsca do magazynowania z czterema partycjami fizycznymi, każda partycja fizyczna może być automatycznie skalowana do 5000 RU/s. Jeśli na określonym kluczu partycji logicznej istnieje gorąca partycja, zobaczysz 429 odpowiedzi, gdy podstawowa partycja fizyczna, w której się znajduje, przekracza 5000 RU/s, czyli przekracza znormalizowane wykorzystanie 100%.
Postępuj zgodnie ze wskazówkami w krokach 1, Krok 2 i Krok 3 , aby debugować te scenariusze.
Innym typowym pytaniem jest: Dlaczego znormalizowane użycie jednostek RU wynosi 100%, ale autoskalowanie nie zostało przeskalowane do maksymalnej liczby jednostek RU/s?
Zwykle występuje to w przypadku obciążeń, które mają tymczasowe lub sporadyczne skoki użycia. W przypadku korzystania z automatycznego skalowania usługa Azure Cosmos DB skaluje wartość RU/s tylko do maksymalnej przepływności, gdy znormalizowane użycie jednostek RU wynosi 100% dla trwałego, ciągłego okresu w 5-sekundowym interwale. Dzięki temu logika skalowania jest przyjazna dla użytkownika, ponieważ gwarantuje, że pojedyncze, chwilowe skoki nie prowadzą do niepotrzebnego skalowania i wyższych kosztów. Gdy występują chwilowe skoki, system zwykle skaluje w górę do wartości wyższej niż wcześniej skalowana do ru/s, ale niższa niż maksymalna liczba jednostek RU/s. Dowiedz się więcej na temat interpretowania metryki znormalizowanych użycia jednostek RU przy użyciu autoskalowania.
Ograniczanie szybkości żądań metadanych
Ograniczanie szybkości metadanych może wystąpić, gdy wykonujesz dużą liczbę operacji metadanych na bazach danych i/lub kontenerach. Operacje metadanych obejmują:
- Tworzenie, odczytywanie, aktualizowanie lub usuwanie kontenera lub bazy danych
- Wyświetlanie listy baz danych lub kontenerów na koncie usługi Azure Cosmos DB
- Zapytanie o oferty, aby wyświetlić bieżącą aprowizowaną przepływność
Istnieje limit jednostek RU zarezerwowanych dla systemu dla tych operacji, więc zwiększenie aprowizowania jednostek RU/s bazy danych lub kontenera nie będzie miało wpływu i nie jest zalecane. Zobacz Limity usługi płaszczyzny sterowania.
Jak badać
Przejdź do pozycji Szczegółowe żądania>metadanych systemu>według kodu stanu. W razie potrzeby przefiltruj do określonej bazy danych i kontenera.
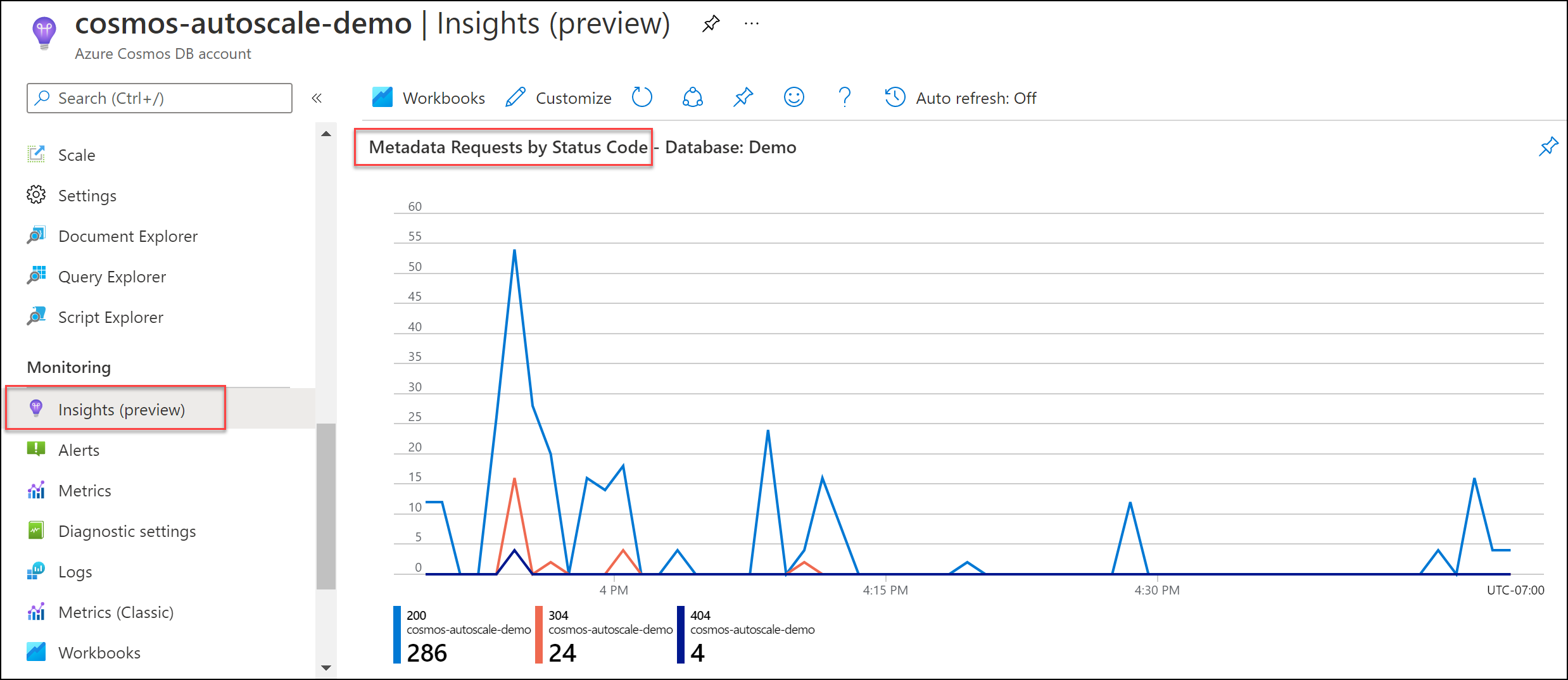
Zalecane rozwiązanie
Jeśli aplikacja musi wykonywać operacje na metadanych, rozważ zaimplementowanie zasad wycofywania w celu wysyłania tych żądań z niższą szybkością.
Użyj statycznych wystąpień klienta usługi Azure Cosmos DB. Po zainicjowaniu elementu DocumentClient lub CosmosClient zestaw SDK usługi Azure Cosmos DB pobiera metadane dotyczące konta, w tym informacje o poziomie spójności, bazach danych, kontenerach, partycjach i ofertach. Ten proces inicjowania może zużyć dużą liczbę jednostek żądania i nie należy wykonywać go często. Używaj jednego wystąpienia DocumentClient przez cały cykl życia aplikacji.
Buforuj nazwy baz danych i kontenerów. Pobierz nazwy baz danych i kontenerów z konfiguracji lub buforuj je podczas uruchamiania. Wywołania takie jak ReadDatabaseAsync/ReadDocumentCollectionAsync lub CreateDatabaseQuery/CreateDocumentCollectionQuery spowodują wywołania metadanych do usługi, które zużywają limit jednostek RU zarezerwowanych przez system. Te operacje powinny być wykonywane rzadko.
Ograniczanie szybkości z powodu błędu usługi przejściowej
Ten błąd 429 jest zwracany, gdy żądanie napotka błąd usługi przejściowej. Zwiększenie jednostek RU/s w bazie danych lub kontenerze nie będzie miało wpływu i nie jest zalecane.
Zalecane rozwiązanie
Ponów próbę żądania. Jeśli błąd będzie się powtarzać przez kilka minut, utwórz bilet pomocy technicznej w witrynie Azure Portal.
Następne kroki
- Monitoruj znormalizowane użycie jednostek RU/s bazy danych lub kontenera.
- Diagnozowanie i rozwiązywanie problemów podczas korzystania z zestawu .NET SDK usługi Azure Cosmos DB.
- Dowiedz się więcej o wytycznych dotyczących wydajności platformy .NET w wersji 3 i .NET w wersji 2.
- Diagnozowanie i rozwiązywanie problemów podczas korzystania z zestawu JAVA SDK usługi Azure Cosmos DB w wersji 4.
- Dowiedz się więcej na temat wytycznych dotyczących wydajności zestawu Java v4 SDK.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla