Zarządzanie zasadami indeksowania w usłudze Azure Cosmos DB
DOTYCZY: ![]() NoSQL
NoSQL
W usłudze Azure Cosmos DB dane są indeksowane zgodnie z zasadami indeksowania zdefiniowanymi dla każdego kontenera. Domyślne zasady indeksowania dla nowo utworzonych kontenerów wymuszają indeksy zakresu dla wszelkich ciągów i liczb. Te zasady można zastąpić własnymi niestandardowymi zasadami indeksowania.
Uwaga
Metoda aktualizowania zasad indeksowania opisanych w tym artykule dotyczy tylko usługi Azure Cosmos DB for NoSQL. Dowiedz się więcej na temat indeksowania w usłudze Azure Cosmos DB dla bazy danych MongoDB i indeksowania pomocniczego w usłudze Azure Cosmos DB dla bazy danych Apache Cassandra.
Przykłady zasad indeksowania
Oto kilka przykładów zasad indeksowania pokazanych w formacie JSON. Są one udostępniane w witrynie Azure Portal w formacie JSON. Te same parametry można ustawić za pomocą interfejsu wiersza polecenia platformy Azure lub dowolnego zestawu SDK.
Zasady rezygnacji dotyczące selektywnego wykluczania niektórych ścieżek właściwości
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/path/to/single/excluded/property/?"
},
{
"path": "/path/to/root/of/multiple/excluded/properties/*"
}
]
}
Zasady zgody na selektywne dołączanie niektórych ścieżek właściwości
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/path/to/included/property/?"
},
{
"path": "/path/to/root/of/multiple/included/properties/*"
}
],
"excludedPaths": [
{
"path": "/*"
}
]
}
Uwaga
Zazwyczaj zalecamy korzystanie z zasad indeksowania rezygnacji . Usługa Azure Cosmos DB aktywnie indeksuje wszelkie nowe właściwości, które mogą zostać dodane do modelu danych.
Używanie indeksu przestrzennego tylko dla określonej ścieżki właściwości
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
}
],
"spatialIndexes": [
{
"path": "/path/to/geojson/property/?",
"types": [
"Point",
"Polygon",
"MultiPolygon",
"LineString"
]
}
]
}
Przykłady zasad indeksowania wektorów
Oprócz dołączania lub wykluczania ścieżek dla poszczególnych właściwości można również określić indeks wektorowy. Ogólnie rzecz biorąc, indeksy wektorów powinny być określane za każdym razem, gdy VectorDistance funkcja systemowa jest używana do mierzenia podobieństwa między wektorem zapytania a właściwością wektora.
Uwaga
Aby korzystać z wyszukiwania wektorowego w usłudze Azure Cosmos DB for NoSQL for NoSQL, musisz zarejestrować się w funkcji indeksu wektorowego w usłudze Azure Cosmos DB for NoSQL.>
Ważne
Zasady indeksowania wektorów muszą znajdować się w tej samej ścieżce zdefiniowanej w zasadach wektorów kontenera. Dowiedz się więcej o zasadach wektorów kontenerów).
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
},
{
"path": "/vector/*"
}
],
"vectorIndexes": [
{
"path": "/vector",
"type": "quantizedFlat"
}
]
}
Ważne
Ścieżka wektorowa dodana do sekcji "excludedPaths" zasad indeksowania w celu zapewnienia zoptymalizowanej wydajności wstawiania. Dodanie ścieżki wektora do "excludedPaths" spowoduje wyższe obciążenie jednostek RU i opóźnienie dla wstawiania wektorów.
Można zdefiniować następujące typy zasad indeksu wektorowego:
| Type | Opis | Maksymalna liczba wymiarów |
|---|---|---|
flat |
Przechowuje wektory na tym samym indeksie co inne właściwości indeksowane. | 505 |
quantizedFlat |
Kwantyzuje (kompresuje) wektory przed zapisaniem w indeksie. Może to poprawić opóźnienie i przepływność kosztem niewielkiej dokładności. | 4096 |
diskANN |
Tworzy indeks na podstawie nazwy DiskANN na potrzeby szybkiego i wydajnego przybliżonego wyszukiwania. | 4096 |
Typy flat indeksów i quantizedFlat wykorzystują indeks usługi Azure Cosmos DB do przechowywania i odczytywania każdego wektora podczas wykonywania wyszukiwania wektorowego. Wyszukiwania wektorowe z indeksem flat to wyszukiwania siłowe i generują 100% dokładności. Istnieje jednak ograniczenie 505 wymiarów dla wektorów w indeksie płaskim.
Indeks quantizedFlat przechowuje kwantyzowane lub skompresowane wektory w indeksie. Wyszukiwania wektorowe z indeksem quantizedFlat są również wyszukiwaniem siłowym, jednak ich dokładność może być nieco mniejsza niż 100%, ponieważ wektory są kwantyzowane przed dodaniem do indeksu. Jednak wyszukiwanie wektorów z quantized flat użyciem powinno mieć mniejsze opóźnienie, wyższą przepływność i niższy koszt jednostek RU niż wyszukiwanie wektorów w indeksie flat . Jest to dobra opcja w scenariuszach, w których używasz filtrów zapytań, aby zawęzić wyszukiwanie wektorów do stosunkowo małego zestawu wektorów.
Indeks diskANN jest oddzielnym indeksem zdefiniowanym specjalnie dla wektorów korzystających z nazwy DiskANN, zestawu wysoce wydajnych algorytmów indeksowania wektorowego opracowanych przez firmę Microsoft Research. Indeksy DiskANN mogą oferować jedne z najniższych opóźnień, najwyższych zapytań na sekundę (QPS) i najniższych kosztów zapytań ru przy wysokiej dokładności. Jednak ponieważ diskANN jest przybliżonym indeksem najbliższych sąsiadów (ANN), dokładność może być niższa niż quantizedFlat lub flat.
Przykłady zasad indeksowania złożonego
Oprócz dołączania lub wykluczania ścieżek dla poszczególnych właściwości można również określić indeks złożony. Aby wykonać zapytanie, które ma klauzulę ORDER BY dla wielu właściwości, indeks złożony jest wymagany dla tych właściwości. Jeśli zapytanie zawiera filtry wraz z sortowaniem wielu właściwości, może być konieczne użycie więcej niż jednego indeksu złożonego.
Indeksy złożone mają również korzyść wydajności dla zapytań, które mają wiele filtrów lub zarówno filtru, jak i klauzuli ORDER BY.
Uwaga
Ścieżki złożone mają niejawną /? wartość, ponieważ indeksowana jest tylko wartość skalarna w tej ścieżce. Symbol /* wieloznaczny nie jest obsługiwany w ścieżkach złożonych. Nie należy określać /? ani /* w ścieżce złożonej. W ścieżkach złożonych jest również rozróżniana wielkość liter.
Indeks złożony zdefiniowany dla (name asc, age desc)
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
Indeks złożony w nazwach i wieku jest wymagany dla następujących zapytań:
Zapytanie nr 1:
SELECT *
FROM c
ORDER BY c.name ASC, c.age DESC
Zapytanie nr 2:
SELECT *
FROM c
ORDER BY c.name DESC, c.age ASC
Ten indeks złożony przynosi korzyści następującym zapytaniom i optymalizuje filtry:
Zapytanie nr 3:
SELECT *
FROM c
WHERE c.name = "Tim"
ORDER BY c.name DESC, c.age ASC
Zapytanie nr 4:
SELECT *
FROM c
WHERE c.name = "Tim" AND c.age > 18
Indeks złożony zdefiniowany dla (name ASC, age ASC) i (name ASC, age DESC)
W ramach tych samych zasad indeksowania można zdefiniować wiele indeksów złożonych.
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"ascending"
}
],
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
Indeks złożony zdefiniowany dla (name ASC, age ASC)
Opcjonalnie można określić kolejność. Jeśli nie zostanie określony, kolejność jest rosnąca.
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name"
},
{
"path":"/age"
}
]
]
}
Wyklucz wszystkie ścieżki właściwości, ale aktywne indeksowanie
Możesz użyć tych zasad, w których funkcja Czas wygaśnięcia (TTL) jest aktywna, ale żadne inne indeksy nie są niezbędne do używania usługi Azure Cosmos DB jako czystego magazynu klucz-wartość.
{
"indexingMode": "consistent",
"includedPaths": [],
"excludedPaths": [{
"path": "/*"
}]
}
Brak indeksowania
Te zasady wyłączają indeksowanie. Jeśli indexingMode ustawiono wartość none, nie można ustawić czasu wygaśnięcia w kontenerze.
{
"indexingMode": "none"
}
Aktualizowanie zasad indeksowania
W usłudze Azure Cosmos DB zasady indeksowania można zaktualizować przy użyciu dowolnej z następujących metod:
- Z witryny Azure Portal
- Przy użyciu interfejsu wiersza polecenia platformy Azure
- Korzystanie z programu PowerShell
- Korzystanie z jednego z zestawów SDK
Aktualizacja zasad indeksowania wyzwala przekształcenie indeksu. Postęp tej transformacji można również śledzić z zestawów SDK.
Uwaga
Podczas aktualizowania zasad indeksowania operacje zapisu w usłudze Azure Cosmos DB są nieprzerwane. Dowiedz się więcej o przekształceniach indeksowania
Ważne
Usunięcie indeksu zaczyna obowiązywać natychmiast, podczas gdy dodawanie nowego indeksu zajmuje trochę czasu, ponieważ wymaga przekształcenia indeksowania. Podczas zastępowania jednego indeksu innym (na przykład zastąpienie pojedynczego indeksu właściwości indeksem złożonym) najpierw dodaj nowy indeks, a następnie zaczekaj na zakończenie przekształcenia indeksu przed usunięciem poprzedniego indeksu z zasad indeksowania. W przeciwnym razie negatywnie wpłynie to na możliwość wykonywania zapytań względem poprzedniego indeksu i może spowodować przerwanie aktywnych obciążeń odwołujących się do poprzedniego indeksu.
Korzystanie z witryny Azure Portal
Kontenery usługi Azure Cosmos DB przechowują swoje zasady indeksowania jako dokument JSON, który witryna Azure Portal umożliwia bezpośrednią edycję.
Zaloguj się w witrynie Azure Portal.
Utwórz nowe konto usługi Azure Cosmos DB lub wybierz istniejące konto.
Otwórz okienko Eksplorator danych i wybierz kontener, nad którym chcesz pracować.
Wybierz pozycję Skaluj i ustawienia.
Zmodyfikuj dokument JSON zasad indeksowania, jak pokazano w tych przykładach.
Wybierz Zapisz, gdy skończysz.
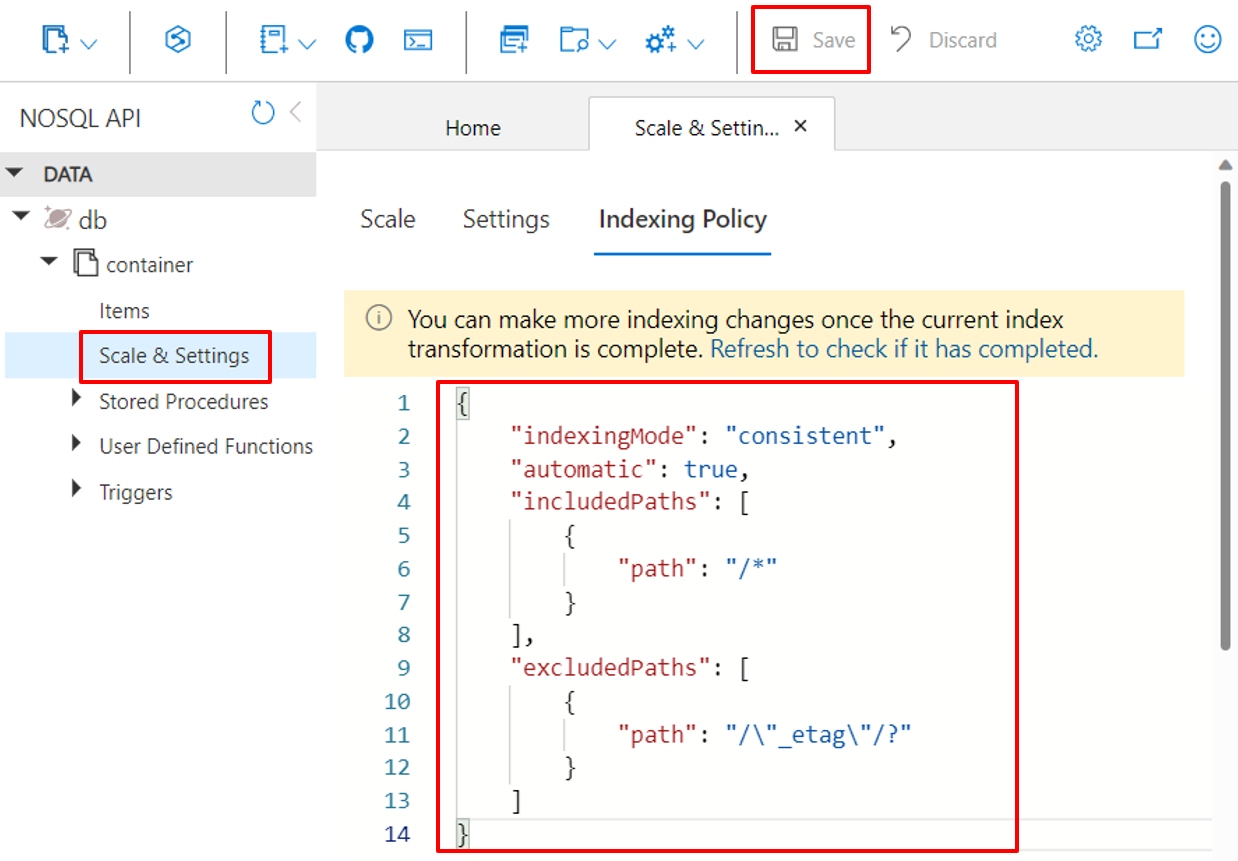
Korzystanie z interfejsu wiersza polecenia platformy Azure
Aby utworzyć kontener z niestandardowymi zasadami indeksowania, zobacz Tworzenie kontenera z niestandardowymi zasadami indeksowania przy użyciu interfejsu wiersza polecenia.
Użyj PowerShell
Aby utworzyć kontener z niestandardowymi zasadami indeksowania, zobacz Tworzenie kontenera z niestandardowymi zasadami indeksowania przy użyciu programu PowerShell.
Korzystanie z zestawu SDK dla platformy .NET
Obiekt ContainerProperties z zestawu .NET SDK w wersji 3 uwidacznia właściwość umożliwiającą IndexingMode zmianę IndexingPolicy i dodawanie lub usuwanie IncludedPaths i ExcludedPaths. Aby uzyskać więcej informacji, zobacz Szybki start: biblioteka klienta usługi Azure Cosmos DB for NoSQL dla platformy .NET.
// Retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync();
// Set the indexing mode to consistent
containerResponse.Resource.IndexingPolicy.IndexingMode = IndexingMode.Consistent;
// Add an included path
containerResponse.Resource.IndexingPolicy.IncludedPaths.Add(new IncludedPath { Path = "/*" });
// Add an excluded path
containerResponse.Resource.IndexingPolicy.ExcludedPaths.Add(new ExcludedPath { Path = "/name/*" });
// Add a spatial index
SpatialPath spatialPath = new SpatialPath
{
Path = "/locations/*"
};
spatialPath.SpatialTypes.Add(SpatialType.Point);
containerResponse.Resource.IndexingPolicy.SpatialIndexes.Add(spatialPath);
// Add a composite index
containerResponse.Resource.IndexingPolicy.CompositeIndexes.Add(new Collection<CompositePath> { new CompositePath() { Path = "/name", Order = CompositePathSortOrder.Ascending }, new CompositePath() { Path = "/age", Order = CompositePathSortOrder.Descending } });
// Update container with changes
await client.GetContainer("database", "container").ReplaceContainerAsync(containerResponse.Resource);
Aby śledzić postęp przekształcania indeksu, przekaż RequestOptions obiekt, który ustawia PopulateQuotaInfo właściwość na truewartość . Pobierz wartość z nagłówka x-ms-documentdb-collection-index-transformation-progress odpowiedzi.
// retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync(new ContainerRequestOptions { PopulateQuotaInfo = true });
// retrieve the index transformation progress from the result
long indexTransformationProgress = long.Parse(containerResponse.Headers["x-ms-documentdb-collection-index-transformation-progress"]);
Zestaw SDK V3 fluent API umożliwia pisanie tej definicji w zwięzły i wydajny sposób podczas definiowania niestandardowych zasad indeksowania podczas tworzenia nowego kontenera:
await client.GetDatabase("database").DefineContainer(name: "container", partitionKeyPath: "/myPartitionKey")
.WithIndexingPolicy()
.WithIncludedPaths()
.Path("/*")
.Attach()
.WithExcludedPaths()
.Path("/name/*")
.Attach()
.WithSpatialIndex()
.Path("/locations/*", SpatialType.Point)
.Attach()
.WithCompositeIndex()
.Path("/name", CompositePathSortOrder.Ascending)
.Path("/age", CompositePathSortOrder.Descending)
.Attach()
.Attach()
.CreateIfNotExistsAsync();
Korzystanie z zestawu Java SDK
Obiekt DocumentCollection z zestawu JAVA SDK uwidacznia getIndexingPolicy() metody i setIndexingPolicy() . Obiekt IndexingPolicy , który manipuluje, umożliwia zmianę trybu indeksowania i dodawanie lub usuwanie dołączonych i wykluczonych ścieżek. Aby uzyskać więcej informacji, zobacz Szybki start: tworzenie aplikacji Java do zarządzania danymi usługi Azure Cosmos DB for NoSQL.
// Retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), null);
containerResponse.subscribe(result -> {
DocumentCollection container = result.getResource();
IndexingPolicy indexingPolicy = container.getIndexingPolicy();
// Set the indexing mode to consistent
indexingPolicy.setIndexingMode(IndexingMode.Consistent);
// Add an included path
Collection<IncludedPath> includedPaths = new ArrayList<>();
IncludedPath includedPath = new IncludedPath();
includedPath.setPath("/*");
includedPaths.add(includedPath);
indexingPolicy.setIncludedPaths(includedPaths);
// Add an excluded path
Collection<ExcludedPath> excludedPaths = new ArrayList<>();
ExcludedPath excludedPath = new ExcludedPath();
excludedPath.setPath("/name/*");
excludedPaths.add(excludedPath);
indexingPolicy.setExcludedPaths(excludedPaths);
// Add a spatial index
Collection<SpatialSpec> spatialIndexes = new ArrayList<SpatialSpec>();
Collection<SpatialType> collectionOfSpatialTypes = new ArrayList<SpatialType>();
SpatialSpec spec = new SpatialSpec();
spec.setPath("/locations/*");
collectionOfSpatialTypes.add(SpatialType.Point);
spec.setSpatialTypes(collectionOfSpatialTypes);
spatialIndexes.add(spec);
indexingPolicy.setSpatialIndexes(spatialIndexes);
// Add a composite index
Collection<ArrayList<CompositePath>> compositeIndexes = new ArrayList<>();
ArrayList<CompositePath> compositePaths = new ArrayList<>();
CompositePath nameCompositePath = new CompositePath();
nameCompositePath.setPath("/name");
nameCompositePath.setOrder(CompositePathSortOrder.Ascending);
CompositePath ageCompositePath = new CompositePath();
ageCompositePath.setPath("/age");
ageCompositePath.setOrder(CompositePathSortOrder.Descending);
compositePaths.add(ageCompositePath);
compositePaths.add(nameCompositePath);
compositeIndexes.add(compositePaths);
indexingPolicy.setCompositeIndexes(compositeIndexes);
// Update the container with changes
client.replaceCollection(container, null);
});
Aby śledzić postęp przekształcania indeksu w kontenerze, przekaż RequestOptions obiekt, który żąda wypełnienia informacji o limitach przydziału. Pobierz wartość z nagłówka x-ms-documentdb-collection-index-transformation-progress odpowiedzi.
// set the RequestOptions object
RequestOptions requestOptions = new RequestOptions();
requestOptions.setPopulateQuotaInfo(true);
// retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), requestOptions);
containerResponse.subscribe(result -> {
// retrieve the index transformation progress from the response headers
String indexTransformationProgress = result.getResponseHeaders().get("x-ms-documentdb-collection-index-transformation-progress");
});
Korzystanie z zestawu SDK Node.js
Interfejs ContainerDefinition z zestawu Node.js SDK uwidacznia właściwość umożliwiającą zmianę indexingMode indexingPolicy i dodawanie lub usuwanie includedPaths i excludedPaths. Aby uzyskać więcej informacji, zobacz Szybki start — biblioteka klienta usługi Azure Cosmos DB for NoSQL dla Node.js.
Pobierz szczegóły kontenera:
const containerResponse = await client.database('database').container('container').read();
Ustaw tryb indeksowania na spójny:
containerResponse.body.indexingPolicy.indexingMode = "consistent";
Dodaj dołączona ścieżkę, w tym indeks przestrzenny:
containerResponse.body.indexingPolicy.includedPaths.push({
includedPaths: [
{
path: "/age/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.String
},
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.Number
}
]
},
{
path: "/locations/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Spatial,
dataType: cosmos.DocumentBase.DataType.Point
}
]
}
]
});
Dodaj wykluczona ścieżkę:
containerResponse.body.indexingPolicy.excludedPaths.push({ path: '/name/*' });
Zaktualizuj kontener za pomocą zmian:
const replaceResponse = await client.database('database').container('container').replace(containerResponse.body);
Aby śledzić postęp przekształcania indeksu w kontenerze, przekaż RequestOptions obiekt, który ustawia populateQuotaInfo właściwość na truewartość . Pobierz wartość z nagłówka x-ms-documentdb-collection-index-transformation-progress odpowiedzi.
// retrieve the container's details
const containerResponse = await client.database('database').container('container').read({
populateQuotaInfo: true
});
// retrieve the index transformation progress from the response headers
const indexTransformationProgress = replaceResponse.headers['x-ms-documentdb-collection-index-transformation-progress'];
Używanie zestawu Python SDK
W przypadku korzystania z zestawu Python SDK w wersji 3 konfiguracja kontenera jest zarządzana jako słownik. Z tego słownika można uzyskać dostęp do zasad indeksowania i wszystkich jego atrybutów. Aby uzyskać więcej informacji, zobacz Szybki start: biblioteka klienta usługi Azure Cosmos DB for NoSQL dla języka Python.
Pobierz szczegóły kontenera:
containerPath = 'dbs/database/colls/collection'
container = client.ReadContainer(containerPath)
Ustaw tryb indeksowania na spójny:
container['indexingPolicy']['indexingMode'] = 'consistent'
Zdefiniuj zasady indeksowania przy użyciu dołączonej ścieżki i indeksu przestrzennego:
container["indexingPolicy"] = {
"indexingMode":"consistent",
"spatialIndexes":[
{"path":"/location/*","types":["Point"]}
],
"includedPaths":[{"path":"/age/*","indexes":[]}],
"excludedPaths":[{"path":"/*"}]
}
Zdefiniuj zasady indeksowania przy użyciu wykluczonej ścieżki:
container["indexingPolicy"] = {
"indexingMode":"consistent",
"includedPaths":[{"path":"/*","indexes":[]}],
"excludedPaths":[{"path":"/name/*"}]
}
Dodaj indeks złożony:
container['indexingPolicy']['compositeIndexes'] = [
[
{
"path": "/name",
"order": "ascending"
},
{
"path": "/age",
"order": "descending"
}
]
]
Zaktualizuj kontener za pomocą zmian:
response = client.ReplaceContainer(containerPath, container)
Następne kroki
Więcej informacji na temat indeksowania znajdziesz w następujących artykułach:
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla