Jak modelować i partycjonować dane w usłudze Azure Cosmos DB przy użyciu przykładu wziętego z życia
DOTYCZY: ![]() NoSQL
NoSQL
W tym artykule przedstawiono kilka pojęć związanych z usługą Azure Cosmos DB, takich jak modelowanie danych, partycjonowanie i aprowizowana przepływność , aby zademonstrować sposób rozwiązywania rzeczywistych problemów z projektowaniem danych.
Jeśli zwykle pracujesz z relacyjnymi bazami danych, prawdopodobnie masz wbudowane nawyki i intuicje dotyczące projektowania modelu danych. Ze względu na określone ograniczenia, ale także unikatowe mocne strony usługi Azure Cosmos DB, większość z tych najlepszych rozwiązań nie przekłada się dobrze i może przeciągnąć Cię do nieoptymalnych rozwiązań. Celem tego artykułu jest przeprowadzenie pełnego procesu modelowania rzeczywistego przypadku użycia w usłudze Azure Cosmos DB, od modelowania elementów po kolokację jednostek i partycjonowanie kontenerów.
Pobierz lub wyświetl wygenerowany przez społeczność kod źródłowy ilustrujący koncepcje z tego artykułu.
Ważne
Współautor społeczności przyczynił się do tego przykładu kodu, a zespół usługi Azure Cosmos DB nie obsługuje jego konserwacji.
Scenariusz
W tym ćwiczeniu rozważymy domenę platformy blogowania, w której użytkownicy mogą tworzyć wpisy. Użytkownicy mogą również lubić i dodawać komentarze do tych wpisów.
Napiwek
Podkreśliliśmy kilka słów kursywą. Te słowa identyfikują rodzaj "rzeczy", które nasz model będzie musiał manipulować.
Dodawanie kolejnych wymagań do naszej specyfikacji:
- Na pierwszej stronie jest wyświetlany kanał informacyjny ostatnio utworzonych wpisów,
- Możemy pobrać wszystkie wpisy dla użytkownika, wszystkie komentarze do wpisu i wszystkie polubień dla wpisu,
- Wpisy są zwracane z nazwą użytkownika swoich autorów i liczbą komentarzy i polubień, które mają,
- Komentarze i polubienia są również zwracane z nazwą użytkownika użytkowników, którzy je utworzyli,
- Gdy są wyświetlane jako listy, wpisy muszą przedstawiać tylko obcięte podsumowanie ich zawartości.
Identyfikowanie głównych wzorców dostępu
Aby rozpocząć, udostępniamy pewną strukturę naszej początkowej specyfikacji, identyfikując wzorce dostępu naszego rozwiązania. Podczas projektowania modelu danych dla usługi Azure Cosmos DB ważne jest, aby zrozumieć, które żądania ma obsługiwać nasz model, aby upewnić się, że model obsługuje te żądania wydajnie.
Aby ułatwić wykonywanie ogólnego procesu, kategoryzujemy te różne żądania jako polecenia lub zapytania, pożyczając słownictwo z CQRS. W usłudze CQRS polecenia to żądania zapisu (czyli intencje aktualizacji systemu), a zapytania są żądaniami tylko do odczytu.
Oto lista żądań uwidacznianych przez naszą platformę:
- [C1] Tworzenie/edytowanie użytkownika
- [Q1] Pobieranie użytkownika
- [C2] Tworzenie/edytowanie wpisu
- [Q2] Pobieranie wpisu
- [Q3] Wyświetlanie listy wpisów użytkownika w krótkim formularzu
- [C3] Tworzenie komentarza
- [Q4] Wyświetlanie listy komentarzy do wpisu
- [C4] Lubię to stanowisko
- [Q5] Wyświetlanie listy polubień wpisu
- [Q6]Wyświetl listę x najnowszych wpisów utworzonych w krótkim formularzu (kanał informacyjny)
Na tym etapie nie myśleliśmy o tym, co zawiera każda jednostka (użytkownik, wpis itp.). Ten krok jest zwykle jednym z pierwszych, które należy rozwiązać podczas projektowania w odniesieniu do magazynu relacyjnego. Najpierw zaczynamy od tego kroku, ponieważ musimy ustalić, jak te jednostki tłumaczą się pod względem tabel, kolumn, kluczy obcych itp. Jest to znacznie mniej istotne w przypadku bazy danych dokumentów, która nie wymusza żadnego schematu podczas zapisu.
Głównym powodem, dla którego ważne jest zidentyfikowanie wzorców dostępu od początku, jest to, że ta lista żądań będzie naszym zestawem testowym. Za każdym razem, gdy iterujemy nasz model danych, przechodzimy przez każde z żądań i sprawdzamy jego wydajność i skalowalność. Obliczamy jednostki żądań używane w każdym modelu i optymalizujemy je. Wszystkie te modele korzystają z domyślnych zasad indeksowania i można je zastąpić przez indeksowanie określonych właściwości, co może dodatkowo poprawić użycie jednostek ŻĄDANIA i opóźnienie.
Wersja 1: pierwsza wersja
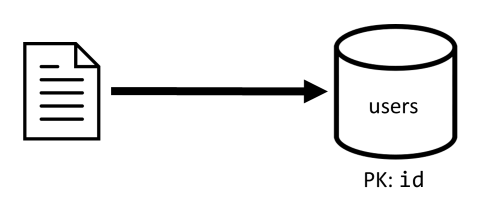
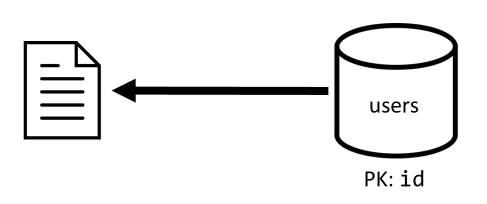
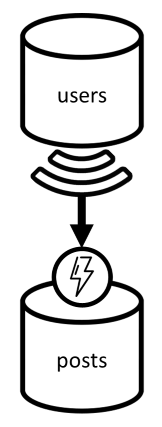
Zaczynamy od dwóch kontenerów: users i posts.
Kontener Użytkownicy
Ten kontener przechowuje tylko elementy użytkownika:
{
"id": "<user-id>",
"username": "<username>"
}
Dzielimy ten kontener na partycje za pomocą idmetody , co oznacza, że każda partycja logiczna w tym kontenerze zawiera tylko jeden element.
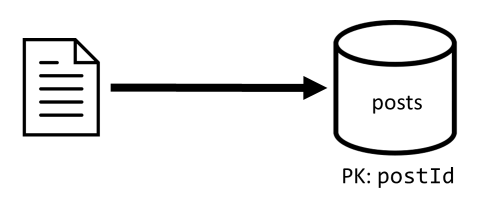
Publikowanie kontenera
Ten kontener hostuje jednostki, takie jak wpisy, komentarze i polubień:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"title": "<post-title>",
"content": "<post-content>",
"creationDate": "<post-creation-date>"
}
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"creationDate": "<like-creation-date>"
}
Dzielimy ten kontener na partycje za pomocą postIdmetody , co oznacza, że każda partycja logiczna w tym kontenerze zawiera jeden wpis, wszystkie komentarze dla tego wpisu i wszystkie polubień dla tego wpisu.
Wprowadziliśmy type właściwość w elementach przechowywanych w tym kontenerze, aby odróżnić trzy typy jednostek hostujących ten kontener.
Ponadto wybraliśmy odwołanie do powiązanych danych zamiast ich osadzania (zapoznaj się z tą sekcją , aby uzyskać szczegółowe informacje o tych pojęciach), ponieważ:
- nie ma górnego limitu liczby wpisów, które użytkownik może utworzyć,
- posty mogą być dowolnie długie,
- nie ma górnego limitu liczby komentarzy i polubień, które mogą zawierać posty,
- Chcemy mieć możliwość dodania komentarza lub polubienie wpisu bez konieczności aktualizowania samego wpisu.
Jak dobrze działa nasz model?
Nadszedł czas, aby ocenić wydajność i skalowalność naszej pierwszej wersji. Dla każdego z zidentyfikowanych wcześniej żądań mierzymy jego opóźnienie i liczbę jednostek żądań, z których korzysta. Ten pomiar jest wykonywany względem fikcyjnego zestawu danych zawierającego 100 000 użytkowników z 5 do 50 wpisów na użytkownika, a do 25 komentarzy i 100 polubień na post.
[C1] Tworzenie/edytowanie użytkownika
To żądanie jest proste do zaimplementowania, ponieważ po prostu utworzymy lub zaktualizujemy element w kontenerze users . Żądania są ładnie rozłożone na wszystkie partycje dzięki kluczowi id partycji.
| Opóźnienie | Opłata za jednostki RU | Wydajność |
|---|---|---|
7 Ms |
5.71 RU |
✅ |
[Q1] Pobieranie użytkownika
Pobieranie użytkownika odbywa się przez odczytanie odpowiedniego elementu z kontenera users .
| Opóźnienie | Opłata za jednostki RU | Wydajność |
|---|---|---|
2 Ms |
1 RU |
✅ |
[C2] Tworzenie/edytowanie wpisu
Podobnie jak [C1], musimy po prostu zapisać w kontenerze posts .
| Opóźnienie | Opłata za jednostki RU | Wydajność |
|---|---|---|
9 Ms |
8.76 RU |
✅ |
[Q2] Pobieranie wpisu
Zaczynamy od pobrania odpowiedniego dokumentu z kontenera posts . Ale to nie wystarczy, zgodnie z naszą specyfikacją musimy również zagregować nazwę użytkownika autora wpisu, liczbę komentarzy i liczbę polubień dla wpisu. Wymienione agregacje wymagają wydania 3 kolejnych zapytań SQL.
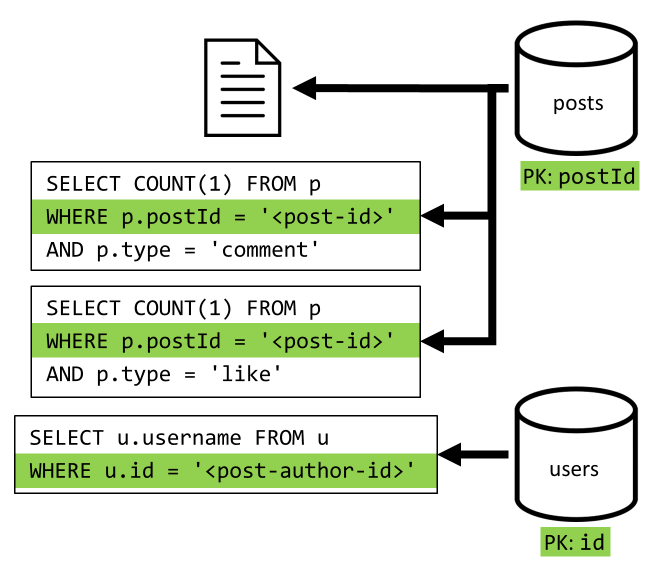
Każda z większej liczby zapytań filtruje klucz partycji odpowiedniego kontenera, co jest dokładnie tym, co chcemy zmaksymalizować wydajność i skalowalność. Ale w końcu musimy wykonać cztery operacje, aby zwrócić pojedynczy wpis, więc poprawimy to w następnej iteracji.
| Opóźnienie | Opłata za jednostki RU | Wydajność |
|---|---|---|
9 Ms |
19.54 RU |
⚠ |
[Q3] Wyświetlanie listy wpisów użytkownika w krótkim formularzu
Najpierw musimy pobrać żądane wpisy z zapytaniem SQL, które pobiera wpisy odpowiadające temu konkretnemu użytkownikowi. Musimy jednak również wydać więcej zapytań, aby zagregować nazwę użytkownika autora oraz liczbę komentarzy i polubień.
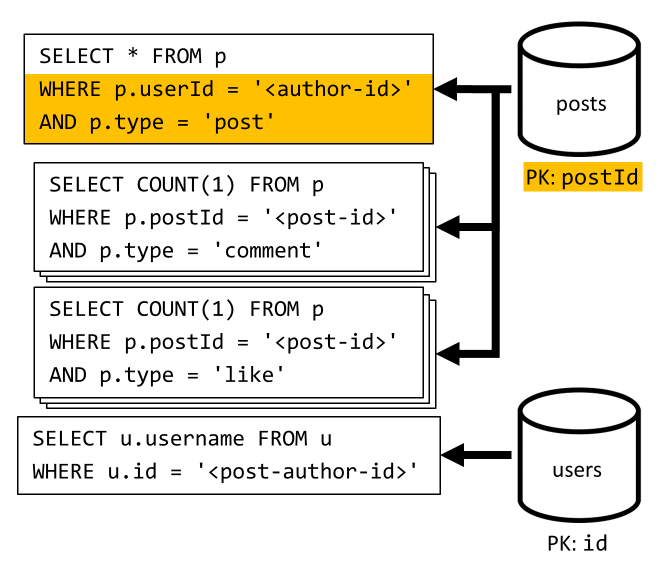
Ta implementacja przedstawia wiele wad:
- zapytania agregujące liczbę komentarzy i polubień muszą być wystawiane dla każdego wpisu zwróconego przez pierwsze zapytanie,
- zapytanie główne nie filtruje klucza
postspartycji kontenera, co prowadzi do fan-out i skanowania partycji w kontenerze.
| Opóźnienie | Opłata za jednostki RU | Wydajność |
|---|---|---|
130 Ms |
619.41 RU |
⚠ |
[C3] Tworzenie komentarza
Komentarz jest tworzony przez zapisanie odpowiedniego elementu w kontenerze posts .
| Opóźnienie | Opłata za jednostki RU | Wydajność |
|---|---|---|
7 Ms |
8.57 RU |
✅ |
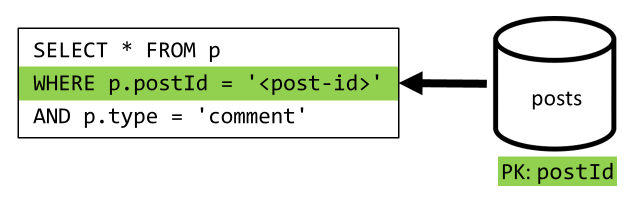
[Q4] Wyświetlanie listy komentarzy do wpisu
Zaczynamy od zapytania, które pobiera wszystkie komentarze dla tego wpisu i po raz kolejny, musimy również agregować nazwy użytkowników oddzielnie dla każdego komentarza.
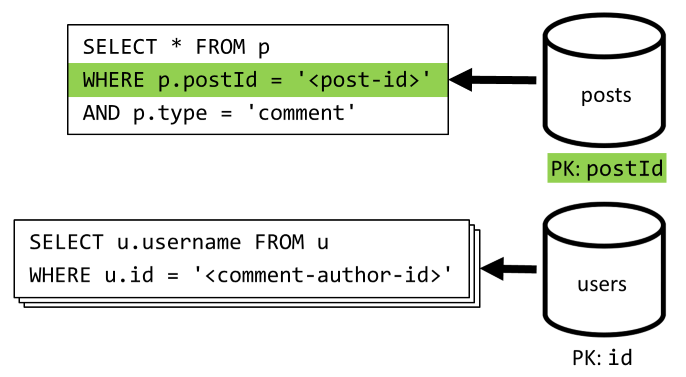
Chociaż główne zapytanie filtruje klucz partycji kontenera, agregowanie nazw użytkowników oddzielnie karze ogólną wydajność. Poprawimy to później.
| Opóźnienie | Opłata za jednostki RU | Wydajność |
|---|---|---|
23 Ms |
27.72 RU |
⚠ |
[C4] Lubię to stanowisko
Podobnie jak [C3], tworzymy odpowiedni element w kontenerze posts .
| Opóźnienie | Opłata za jednostki RU | Wydajność |
|---|---|---|
6 Ms |
7.05 RU |
✅ |
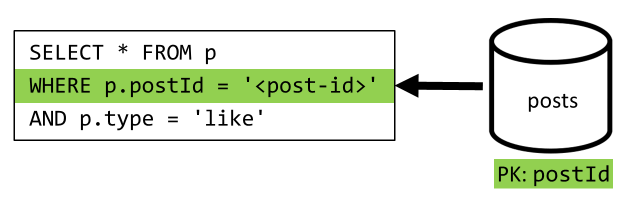
[Q5] Wyświetlanie listy polubień wpisu
Podobnie jak [Q4], wysyłamy zapytania dotyczące polubień tego wpisu, a następnie agregujemy ich nazwy użytkowników.
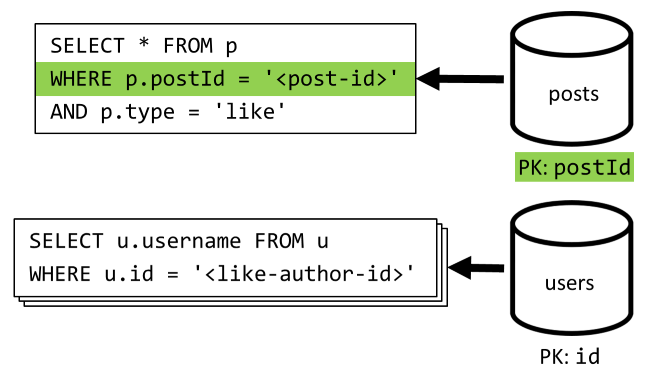
| Opóźnienie | Opłata za jednostki RU | Wydajność |
|---|---|---|
59 Ms |
58.92 RU |
⚠ |
[Q6] Wyświetl listę x najnowszych wpisów utworzonych w krótkim formularzu (kanał informacyjny)
Pobieramy najnowsze wpisy, wykonując posts zapytanie dotyczące kontenera posortowanego według malejącej daty utworzenia, a następnie agregujemy nazwy użytkowników i liczby komentarzy i polubień dla każdego z wpisów.
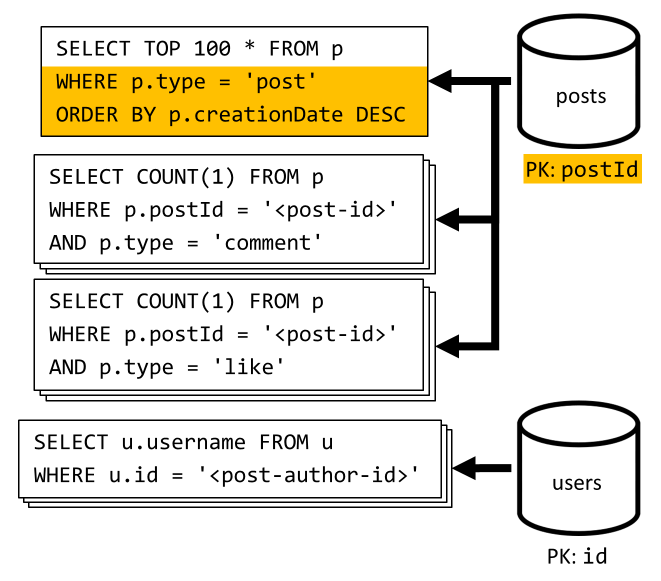
Po raz kolejny nasze początkowe zapytanie nie filtruje klucza posts partycji kontenera, co wyzwala kosztowny fan-out. Jest to jeszcze gorsze, ponieważ celujemy w większy zestaw wyników i sortujemy wyniki za pomocą ORDER BY klauzuli , co sprawia, że jest droższe pod względem jednostek żądania.
| Opóźnienie | Opłata za jednostki RU | Wydajność |
|---|---|---|
306 Ms |
2063.54 RU |
⚠ |
Zastanawianie się nad wydajnością wersji 1
Patrząc na problemy z wydajnością, które napotkaliśmy w poprzedniej sekcji, możemy zidentyfikować dwie główne klasy problemów:
- niektóre żądania wymagają wydania wielu zapytań w celu zebrania wszystkich danych, które należy zwrócić,
- niektóre zapytania nie filtrują klucza partycji kontenerów docelowych, co prowadzi do zwiększenia skalowalności.
Rozwiążmy każdy z tych problemów, zaczynając od pierwszego.
Wersja 2: Wprowadzenie do denormalizacji w celu zoptymalizowania zapytań odczytu
Powodem, dla którego musimy w niektórych przypadkach wysłać więcej żądań, jest to, że wyniki początkowego żądania nie zawierają wszystkich danych, które musimy zwrócić. Denormalizowanie danych rozwiązuje ten rodzaj problemu w naszym zestawie danych podczas pracy z magazynem danych nierelacyjnych, takim jak Usługa Azure Cosmos DB.
W naszym przykładzie modyfikujemy elementy wpisu, aby dodać nazwę użytkownika autora wpisu, liczbę komentarzy i liczbę polubień:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Modyfikujemy również komentarz i lubimy elementy, aby dodać nazwę użytkownika, który je utworzył:
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"userUsername": "<comment-author-username>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"userUsername": "<liker-username>",
"creationDate": "<like-creation-date>"
}
Denormalizowanie komentarza i polubień
Chcemy osiągnąć to, że za każdym razem, gdy dodamy komentarz lub polubienie commentCount , zwiększamy również wartość lub likeCount w odpowiednim poście. W miarę postId partycjonowania kontenera posts nowy element (komentarz lub polubienie) i odpowiadający mu wpis znajdują się w tej samej partycji logicznej. W związku z tym możemy użyć procedury składowanej do wykonania tej operacji.
Podczas tworzenia komentarza ([C3]) zamiast dodawać nowy element w kontenerze wywołujemy następującą procedurę składowaną w posts tym kontenerze:
function createComment(postId, comment) {
var collection = getContext().getCollection();
collection.readDocument(
`${collection.getAltLink()}/docs/${postId}`,
function (err, post) {
if (err) throw err;
post.commentCount++;
collection.replaceDocument(
post._self,
post,
function (err) {
if (err) throw err;
comment.postId = postId;
collection.createDocument(
collection.getSelfLink(),
comment
);
}
);
})
}
Ta procedura składowana przyjmuje identyfikator wpisu i treść nowego komentarza jako parametry, a następnie:
- pobiera wpis
- zwiększa wartość
commentCount - zastępuje wpis
- dodaje nowy komentarz
Ponieważ procedury składowane są wykonywane jako transakcje niepodzielne, wartość commentCount i rzeczywista liczba komentarzy zawsze pozostaje zsynchronizowana.
Oczywiście wywołujemy podobną procedurę składowaną podczas dodawania likeCountnowych polubień, aby zwiększać wartość .
Denormalizowanie nazw użytkowników
Nazwy użytkowników wymagają innego podejścia, ponieważ użytkownicy nie tylko znajdują się w różnych partycjach, ale w innym kontenerze. Gdy musimy zdenormalizować dane między partycjami i kontenerami, możemy użyć źródła zmian kontenera źródłowego.
W naszym przykładzie używamy zestawienia zmian kontenera do reagowania users za każdym razem, gdy użytkownicy aktualizują swoje nazwy użytkowników. W takim przypadku propagujemy zmianę, wywołując inną procedurę składowaną w kontenerze posts :
function updateUsernames(userId, username) {
var collection = getContext().getCollection();
collection.queryDocuments(
collection.getSelfLink(),
`SELECT * FROM p WHERE p.userId = '${userId}'`,
function (err, results) {
if (err) throw err;
for (var i in results) {
var doc = results[i];
doc.userUsername = username;
collection.upsertDocument(
collection.getSelfLink(),
doc);
}
});
}
Ta procedura składowana przyjmuje identyfikator użytkownika i nową nazwę użytkownika jako parametry, a następnie:
- pobiera wszystkie elementy pasujące do
userIdelementu (które mogą być wpisami, komentarzami lub polubień) - dla każdego z tych elementów
- zastępuje element
userUsername - zastępuje element
- zastępuje element
Ważne
Ta operacja jest kosztowna, ponieważ wymaga wykonania tej procedury składowanej na każdej partycji kontenera posts . Zakładamy, że większość użytkowników wybiera odpowiednią nazwę użytkownika podczas rejestracji i nigdy jej nie zmieni, więc ta aktualizacja będzie działać bardzo rzadko.
Jakie są wzrosty wydajności wersji 2?
Porozmawiajmy o niektórych wzrostach wydajności wersji 2.
[Q2] Pobieranie wpisu
Teraz, gdy nasza denormalizacja jest w miejscu, musimy pobrać tylko jeden element, aby obsłużyć to żądanie.
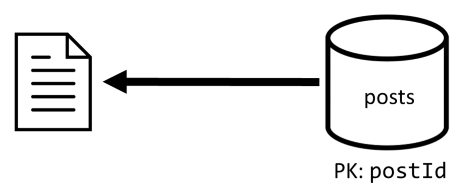
| Opóźnienie | Opłata za jednostki RU | Wydajność |
|---|---|---|
2 Ms |
1 RU |
✅ |
[Q4] Wyświetlanie listy komentarzy do wpisu
Tutaj ponownie możemy oszczędzić dodatkowe żądania, które pobierały nazwy użytkowników i kończy się jednym zapytaniem, które filtruje klucz partycji.
| Opóźnienie | Opłata za jednostki RU | Wydajność |
|---|---|---|
4 Ms |
7.72 RU |
✅ |
[Q5] Wyświetlanie listy polubień wpisu
Dokładnie taka sama sytuacja w przypadku wyświetlania listy polubień.
| Opóźnienie | Opłata za jednostki RU | Wydajność |
|---|---|---|
4 Ms |
8.92 RU |
✅ |
Wersja 3: Upewnienie się, że wszystkie żądania są skalowalne
Nadal istnieją dwa żądania, które nie zostały w pełni zoptymalizowane podczas przeglądania naszych ogólnych ulepszeń wydajności. Te żądania to [Q3] i [Q6].. Są to żądania obejmujące zapytania, które nie filtrują klucza partycji kontenerów, których dotyczą.
[Q3] Wyświetlanie listy wpisów użytkownika w krótkim formularzu
To żądanie już korzysta z ulepszeń wprowadzonych w wersji 2, co pozwala zaoszczędzić więcej zapytań.

Jednak pozostałe zapytanie nadal nie filtruje klucza partycji kontenera posts .
Sposób myślenia o tej sytuacji jest prosty:
- To żądanie musi filtrować,
userIdponieważ chcemy pobrać wszystkie wpisy dla określonego użytkownika. - Nie działa dobrze, ponieważ jest wykonywany względem
postskontenera, który nie mauserIdpartycjonowania. - Stwierdzając oczywiste, że rozwiązalibyśmy problem z wydajnością, wykonując to żądanie względem kontenera podzielonego na partycje za pomocą
userIdpolecenia . - Okazuje się, że mamy już taki kontener:
userskontener!
Wprowadzamy więc drugi poziom denormalizacji przez duplikowanie całych wpisów do kontenera users . Dzięki temu efektywnie uzyskujemy kopię naszych wpisów, tylko partycjonowaną wzdłuż innego wymiaru, dzięki czemu są bardziej wydajne w celu pobrania ich przez userIdelement .
Kontener users zawiera teraz dwa rodzaje elementów:
{
"id": "<user-id>",
"type": "user",
"userId": "<user-id>",
"username": "<username>"
}
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
W tym przykładzie:
- Wprowadziliśmy
typepole w elemencie użytkownika, aby odróżnić użytkowników od wpisów, - Dodaliśmy
userIdrównież pole w elemencie użytkownika, które jest nadmiarowe zidpolem, ale jest wymagane, ponieważuserskontener jest teraz podzielony na partycjeuserId(a nieidtak jak poprzednio)
Aby osiągnąć tę denormalizację, po raz kolejny użyjemy zestawienia zmian. Tym razem reagujemy na zestawienie zmian kontenera w celu wysłania nowego lub zaktualizowanego posts wpisu do kontenera users . Ponieważ lista wpisów nie wymaga zwrócenia pełnej zawartości, możemy je obcinać w procesie.
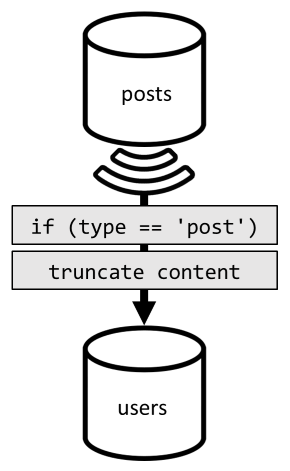
Teraz możemy kierować zapytanie do users kontenera, filtrując według klucza partycji kontenera.

| Opóźnienie | Opłata za jednostki RU | Wydajność |
|---|---|---|
4 Ms |
6.46 RU |
✅ |
[Q6] Wyświetl listę x najnowszych wpisów utworzonych w krótkim formularzu (kanał informacyjny)
Musimy tu radzić sobie z podobną sytuacją: nawet po oszczędniu większej liczby zapytań pozostawionych przez denormalizację wprowadzoną w wersji 2 pozostałe zapytanie nie filtruje klucza partycji kontenera:
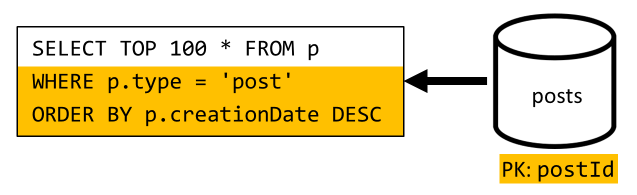
Zgodnie z tym samym podejściem maksymalizowanie wydajności i skalowalności tego żądania wymaga osiągnięcia tylko jednej partycji. Tylko trafienie jednej partycji jest możliwe, ponieważ musimy zwrócić tylko ograniczoną liczbę elementów. Aby wypełnić stronę główną naszej platformy blogowania, wystarczy pobrać 100 najnowszych wpisów bez konieczności stronicowania całego zestawu danych.
Dlatego aby zoptymalizować to ostatnie żądanie, wprowadzamy trzeci kontener do naszego projektu, całkowicie dedykowany do obsługi tego żądania. Zdenormalizujemy nasze wpisy w tym nowym feed kontenerze:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Pole type partycjonuje ten kontener, który jest zawsze post w naszych elementach. Dzięki temu wszystkie elementy w tym kontenerze znajdą się w tej samej partycji.
Aby osiągnąć denormalizację, musimy po prostu podłączyć potok zestawienia zmian, który wcześniej wprowadziliśmy w celu wysłania wpisów do tego nowego kontenera. Należy pamiętać o tym, że musimy mieć pewność, że przechowujemy tylko 100 najnowszych postów; w przeciwnym razie zawartość kontenera może wzrosnąć poza maksymalny rozmiar partycji. To ograniczenie można zaimplementować, wywołując wyzwalacz po każdym dodaniu dokumentu w kontenerze:
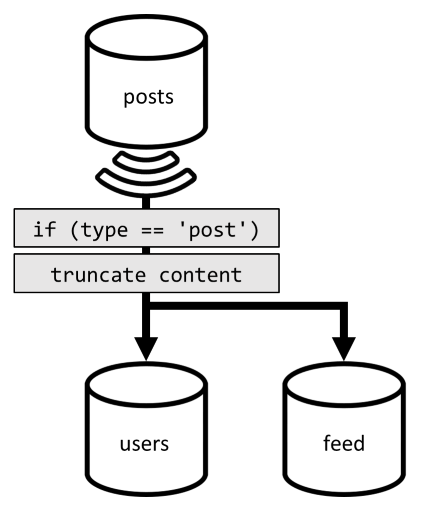
Oto treść wyzwalacza końcowego, która obcina kolekcję:
function truncateFeed() {
const maxDocs = 100;
var context = getContext();
var collection = context.getCollection();
collection.queryDocuments(
collection.getSelfLink(),
"SELECT VALUE COUNT(1) FROM f",
function (err, results) {
if (err) throw err;
processCountResults(results);
});
function processCountResults(results) {
// + 1 because the query didn't count the newly inserted doc
if ((results[0] + 1) > maxDocs) {
var docsToRemove = results[0] + 1 - maxDocs;
collection.queryDocuments(
collection.getSelfLink(),
`SELECT TOP ${docsToRemove} * FROM f ORDER BY f.creationDate`,
function (err, results) {
if (err) throw err;
processDocsToRemove(results, 0);
});
}
}
function processDocsToRemove(results, index) {
var doc = results[index];
if (doc) {
collection.deleteDocument(
doc._self,
function (err) {
if (err) throw err;
processDocsToRemove(results, index + 1);
});
}
}
}
Ostatnim krokiem jest przekierowanie zapytania do nowego feed kontenera:
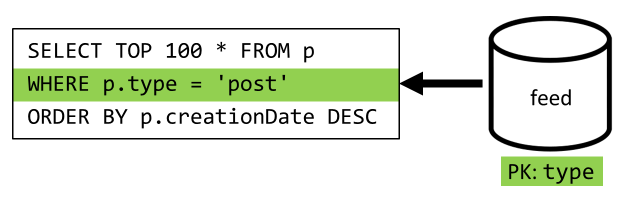
| Opóźnienie | Opłata za jednostki RU | Wydajność |
|---|---|---|
9 Ms |
16.97 RU |
✅ |
Podsumowanie
Przyjrzyjmy się ogólnym ulepszeniom wydajności i skalowalności, które wprowadziliśmy w różnych wersjach naszego projektu.
| Wersja 1 | Wersja 2 | V3 | |
|---|---|---|---|
| [C1] | 7 ms/ 5.71 RU |
7 ms/ 5.71 RU |
7 ms/ 5.71 RU |
| [Q1] | 2 ms/ 1 RU |
2 ms/ 1 RU |
2 ms/ 1 RU |
| [C2] | 9 ms/ 8.76 RU |
9 ms/ 8.76 RU |
9 ms/ 8.76 RU |
| [Q2] | 9 ms/ 19.54 RU |
2 ms/ 1 RU |
2 ms/ 1 RU |
| [Q3] | 130 ms/ 619.41 RU |
28 ms/ 201.54 RU |
4 ms/ 6.46 RU |
| [C3] | 7 ms/ 8.57 RU |
7 ms/ 15.27 RU |
7 ms/ 15.27 RU |
| [Q4] | 23 ms/ 27.72 RU |
4 ms/ 7.72 RU |
4 ms/ 7.72 RU |
| [C4] | 6 ms/ 7.05 RU |
7 ms/ 14.67 RU |
7 ms/ 14.67 RU |
| [Q5] | 59 ms/ 58.92 RU |
4 ms/ 8.92 RU |
4 ms/ 8.92 RU |
| [Q6] | 306 ms/ 2063.54 RU |
83 ms/ 532.33 RU |
9 ms/ 16.97 RU |
Zoptymalizowaliśmy scenariusz z dużą liczbą operacji odczytu
Być może zauważyliśmy, że skupiliśmy nasze wysiłki na rzecz poprawy wydajności żądań odczytu (zapytań) kosztem żądań zapisu (poleceń). W wielu przypadkach operacje zapisu wyzwalają teraz kolejną denormalizację za pośrednictwem źródeł zmian, co sprawia, że są bardziej kosztowne obliczeniowo i dłuższe w celu zmaterializowania.
Uzasadniamy to skupienie się na wydajności odczytu przez fakt, że platforma blogów (podobnie jak większość aplikacji społecznościowych) jest bardzo ciężka do odczytu. Obciążenie z dużym obciążeniem odczytu wskazuje, że liczba żądań odczytu, które musi obsłużyć, jest zwykle o różnej wielkości większa niż liczba żądań zapisu. Dlatego warto sprawić, aby żądania zapisu bardziej kosztowne do wykonania w celu umożliwienia, aby żądania odczytu mogły być tańsze i wydajniejsze.
Jeśli przyjrzymy się najbardziej ekstremalnej optymalizacji, [Q6] poszedł z 2000+ jednostek RU do zaledwie 17 jednostek RU; osiągnęliśmy to, denormalizując posty kosztem około 10 jednostek RU na element. Ponieważ będziemy służyć o wiele więcej żądań kanału informacyjnego niż tworzenie lub aktualizacje postów, koszt tej denormalizacji jest niewielki, biorąc pod uwagę ogólne oszczędności.
Denormalizacja może być stosowana przyrostowo
Ulepszenia skalowalności, które omówiliśmy w tym artykule, obejmują denormalizację i duplikowanie danych w zestawie danych. Należy zauważyć, że te optymalizacje nie muszą być wprowadzane w dniu 1. Zapytania filtrujące klucze partycji działają lepiej na dużą skalę, ale zapytania obejmujące wiele partycji mogą być akceptowalne, jeśli są one wywoływane rzadko lub w przypadku ograniczonego zestawu danych. Jeśli dopiero tworzysz prototyp lub uruchamiasz produkt z małą i kontrolowaną bazą użytkowników, prawdopodobnie możesz oszczędzić te ulepszenia na później. Ważne jest monitorowanie wydajności modelu, dzięki czemu możesz zdecydować, czy i kiedy należy je wprowadzić.
Kanał informacyjny zmian używany do ciągłego dystrybuowania aktualizacji do innych kontenerów przechowuje wszystkie te aktualizacje. Ta trwałość umożliwia zażądanie wszystkich aktualizacji od czasu utworzenia kontenera i zdenormalizowanych widoków bootstrap jako jednorazowej operacji nadrabiania zaległości, nawet jeśli system ma już wiele danych.
Następne kroki
Po wprowadzeniu do praktycznego modelowania i partycjonowania danych warto zapoznać się z następującymi artykułami, aby zapoznać się z omówioną koncepcją:
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla