Modelowanie danych w usłudze Azure Cosmos DB
DOTYCZY: ![]() NoSQL
NoSQL
Chociaż bazy danych bez schematu, takie jak Usługa Azure Cosmos DB, ułatwiają przechowywanie danych bez struktury i częściowo ustrukturyzowanych oraz wykonywanie zapytań o nieustrukturyzowane, należy poświęcić trochę czasu na myślenie o modelu danych, aby jak najlepiej wykorzystać możliwości usługi pod względem wydajności i skalowalności i najniższych kosztów.
Jak będą przechowywane dane? Jak aplikacja będzie pobierać i wykonywać zapytania dotyczące danych? Czy aplikacja jest duża, czy duża liczba operacji zapisu?
Po przeczytaniu tego artykułu będziesz w stanie odpowiedzieć na następujące pytania:
- Co to jest modelowanie danych i dlaczego należy się tym przejmować?
- W jaki sposób modelowanie danych w usłudze Azure Cosmos DB różni się od relacyjnej bazy danych?
- Jak mogę wyrażać relacje danych w nierelacyjnej bazie danych?
- Kiedy osadzam dane i kiedy mogę połączyć się z danymi?
Liczby w formacie JSON
Usługa Azure Cosmos DB zapisuje dokumenty w formacie JSON. Oznacza to, że przed zapisaniem ich w formacie json należy dokładnie określić, czy konieczne jest przekonwertowanie liczb na ciągi. Wszystkie liczby powinny zostać przekonwertowane na wartość , jeśli istnieje prawdopodobieństwo, że znajdują się poza granicami liczby podwójnej precyzji zgodnie ze standardem StringIEEE 754 binary64. Specyfikacja Json określa przyczyny, dla których używanie liczb spoza tej granicy jest w ogóle złym rozwiązaniem w formacie JSON z powodu prawdopodobnych problemów ze współdziałaniem. Te problemy są szczególnie istotne w przypadku kolumny klucza partycji, ponieważ jest niezmienna i wymaga późniejszej zmiany migracji danych.
Osadzanie danych
Po rozpoczęciu modelowania danych w usłudze Azure Cosmos DB spróbuj traktować jednostki jako elementy samodzielne reprezentowane jako dokumenty JSON.
Dla porównania najpierw zobaczmy, jak możemy modeluje dane w relacyjnej bazie danych. W poniższym przykładzie pokazano, jak osoba może być przechowywana w relacyjnej bazie danych.
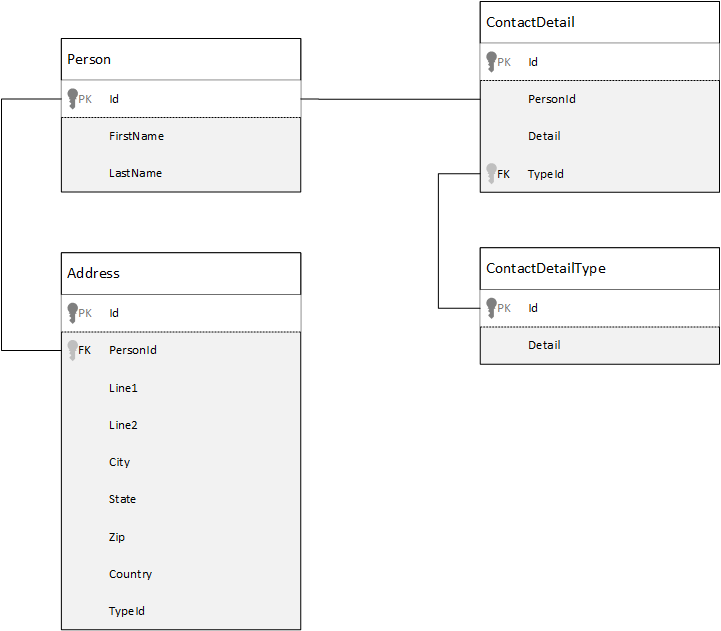
Strategia, podczas pracy z relacyjnymi bazami danych, polega na normalizacji wszystkich danych. Normalizacja danych zwykle wiąże się z przyjęciem jednostki, takiej jak osoba, i podzieleniem ich na odrębne składniki. W tym przykładzie osoba może mieć wiele rekordów szczegółów kontaktu i wiele rekordów adresów. Szczegóły kontaktowe można dalej podzielić, wyodrębniając typowe pola, takie jak typ. To samo dotyczy adresu, każdy rekord może być typu Home lub Business.
Podstawowym założeniem podczas normalizacji danych jest unikanie przechowywania nadmiarowych danych na każdym rekordzie i raczej odwoływanie się do danych. W tym przykładzie, aby odczytać osobę ze wszystkimi swoimi danymi kontaktowymi i adresami, musisz użyć funkcji JOINS, aby skutecznie tworzyć dane (lub denormalizować) dane w czasie wykonywania.
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
Operacje zapisu w wielu pojedynczych tabelach są wymagane do zaktualizowania danych kontaktowych i adresów pojedynczej osoby.
Teraz przyjrzyjmy się temu, jak modelujemy te same dane co jednostka samodzielna w usłudze Azure Cosmos DB.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
Korzystając z tego podejścia, zdenormalizowaliśmy rekord osoby, osadzając wszystkie informacje związane z tą osobą, takie jak ich dane kontaktowe i adresy, w jednym dokumencie JSON. Ponadto, ponieważ nie jesteśmy ograniczeni do stałego schematu, mamy elastyczność wykonywania takich czynności, jak posiadanie szczegółów kontaktowych różnych kształtów całkowicie.
Pobieranie kompletnego rekordu osoby z bazy danych jest teraz pojedynczą operacją odczytu dla pojedynczego kontenera i dla pojedynczego elementu. Aktualizowanie danych kontaktowych i adresów rekordu osoby jest również pojedynczą operacją zapisu względem pojedynczego elementu.
Dzięki denormalizacji danych aplikacja może wymagać wydania mniejszej liczby zapytań i aktualizacji w celu ukończenia typowych operacji.
Kiedy należy osadzić
Ogólnie rzecz biorąc, używaj wbudowanych modeli danych, gdy:
- Istnieją relacje między jednostkami.
- Istnieją relacje jeden do kilku między jednostkami.
- Istnieją osadzone dane, które zmieniają się rzadko.
- Istnieją osadzone dane, które nie będą rosnąć bez ograniczenia.
- Istnieją osadzone dane, do których często są wykonywane zapytania.
Uwaga
Zazwyczaj zdenormalizowane modele danych zapewniają lepszą wydajność odczytu .
Kiedy nie należy osadzać
Chociaż reguła kciuka w usłudze Azure Cosmos DB polega na denormalizacji wszystkiego i osadzaniu wszystkich danych w jednym elemencie, może to prowadzić do niektórych sytuacji, których należy unikać.
Weź ten fragment kodu JSON.
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
Może to być tak, jak wyglądałaby jednostka wpisu z osadzonymi komentarzami, gdyby modelowaliśmy typowy blog lub system CMS. Problem z tym przykładem polega na tym, że tablica komentarzy jest niezwiązana, co oznacza, że nie ma (praktycznego) limitu liczby komentarzy, które może zawierać dowolny pojedynczy wpis. Może to stać się problemem, ponieważ rozmiar elementu może być nieskończenie duży, więc jest to projekt, którego należy unikać.
Wraz ze wzrostem rozmiaru elementu będzie mieć wpływ na możliwość przesyłania danych za pośrednictwem przewodu i odczytywania i aktualizowania elementu na dużą skalę.
W takim przypadku lepiej byłoby rozważyć następujący model danych.
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
Ten model zawiera dokument dla każdego komentarza z właściwością zawierającą identyfikator wpisu. Dzięki temu wpisy mogą zawierać dowolną liczbę komentarzy i mogą być wydajnie powiększane. Użytkownicy, którzy chcą zobaczyć więcej niż najnowsze komentarze, wysyłają zapytanie do tego kontenera, przekazując identyfikator postId, który powinien być kluczem partycji dla kontenera komentarzy.
Innym przypadkiem, w którym osadzanie danych nie jest dobrym pomysłem, jest to, że osadzane dane są często używane między elementami i często się zmieniają.
Weź ten fragment kodu JSON.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
Może to reprezentować portfel akcji danej osoby. Wybraliśmy osadzanie informacji o zapasach w każdym dokumencie portfela. W środowisku, w którym powiązane dane zmieniają się często, jak aplikacja do handlu akcjami, osadzanie danych, które często zmieniają się, oznacza, że stale aktualizujesz każdy dokument portfela za każdym razem, gdy akcje są wymieniane.
Giełda zbzb może być wymieniana wieleset razy w ciągu jednego dnia, a tysiące użytkowników może mieć zbzb na swoim portfelu. W przypadku modelu danych, takiego jak w przykładzie, musielibyśmy aktualizować wiele tysięcy dokumentów portfela wiele razy dziennie, co prowadzi do systemu, który nie będzie dobrze skalowany.
Dane referencyjne
Osadzanie danych działa ładnie w wielu przypadkach, ale istnieją scenariusze, w których denormalizacja danych powoduje więcej problemów niż warto. Więc co teraz robimy?
Relacyjne bazy danych nie są jedynym miejscem, w którym można tworzyć relacje między jednostkami. W bazie danych dokumentów mogą istnieć informacje w jednym dokumencie, które odnoszą się do danych w innych dokumentach. Nie zalecamy tworzenia systemów, które byłyby lepiej dostosowane do relacyjnej bazy danych w usłudze Azure Cosmos DB lub jakiejkolwiek innej bazy danych dokumentów, ale proste relacje są poprawne i mogą być przydatne.
W formacie JSON wybraliśmy użycie przykładu portfela akcji z wcześniejszego, ale tym razem odwołujemy się do pozycji akcji w portfelu zamiast osadzania. W ten sposób, gdy pozycja zapasów zmienia się często przez cały dzień jedynym dokumentem, który należy zaktualizować, jest pojedynczy dokument giełdowy.
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
Bezpośrednią wadą tego podejścia jest jednak to, że aplikacja jest wymagana do wyświetlania informacji o każdym magazynie przechowywanym podczas wyświetlania portfela danej osoby; w takim przypadku należy wykonać wiele podróży do bazy danych, aby załadować informacje dla każdego dokumentu magazynowego. W tym miejscu podjęliśmy decyzję o poprawie wydajności operacji zapisu, które odbywają się często przez cały dzień, ale z kolei naruszono zabezpieczenia operacji odczytu, które potencjalnie mają mniejszy wpływ na wydajność tego konkretnego systemu.
Uwaga
Znormalizowane modele danych mogą wymagać większej liczby rund na serwerze.
Co z kluczami obcymi?
Ponieważ obecnie nie ma pojęcia ograniczenia, klucza obcego lub innego, wszystkie relacje między dokumentami, które znajdują się w dokumentach, są skutecznie "słabe linki" i nie zostaną zweryfikowane przez samą bazę danych. Jeśli chcesz upewnić się, że dane, do których odnosi się dokument, rzeczywiście istnieją, musisz to zrobić w aplikacji lub za pomocą wyzwalaczy po stronie serwera lub procedur składowanych w usłudze Azure Cosmos DB.
Kiedy należy się odwołać
Ogólnie rzecz biorąc, używaj znormalizowanych modeli danych, gdy:
- Reprezentowanie relacji jeden do wielu .
- Reprezentowanie relacji wiele-do-wielu .
- Powiązane zmiany danych często.
- Przywoływane dane mogą być niezwiązane.
Uwaga
Zazwyczaj normalizacja zapewnia lepszą wydajność zapisu .
Gdzie umieścić relację?
Wzrost relacji pomaga określić, w którym dokumencie ma być przechowywane odwołanie.
Jeśli zaobserwujemy kod JSON, który modeluje wydawców i książki.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over the world one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
Jeśli liczba książek na wydawcę jest niewielka z ograniczonym wzrostem, przechowywanie odwołania do książek w dokumencie wydawcy może być przydatne. Jeśli jednak liczba książek na wydawcę jest niezwiązana, ten model danych doprowadzi do niezmienności, rosnących tablic, jak w przykładowym dokumencie wydawcy.
Przełączanie elementów wokół nieco spowodowałoby model, który nadal reprezentuje te same dane, ale teraz pozwala uniknąć tych dużych kolekcji modyfikowalnych.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over the world one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
W tym przykładzie porzuciliśmy niezwiązaną kolekcję w dokumencie wydawcy. Zamiast tego mamy tylko odwołanie do wydawcy w każdym dokumencie książki.
Jak mogę modelować relacje wiele-do-wielu?
W relacyjnej bazie danych relacje wiele-do-wielu są często modelowane za pomocą tabel sprzężenia, które po prostu łączą rekordy z innych tabel.
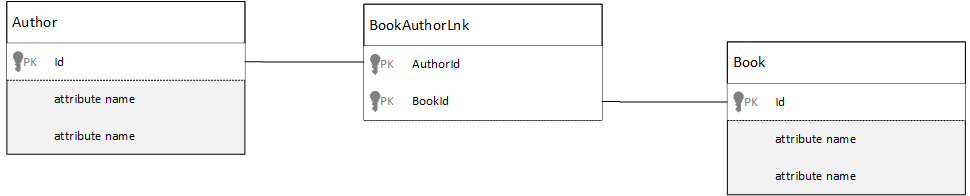
Możesz być kuszony, aby zreplikować to samo przy użyciu dokumentów i utworzyć model danych, który wygląda podobnie do poniższego.
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over the world one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
To zadziałałoby. Jednak załadowanie autora ze swoimi książkami lub załadowanie książki z jego autorem zawsze wymagałoby co najmniej dwóch dodatkowych zapytań względem bazy danych. Jedno zapytanie do dokumentu dołączania, a następnie inne zapytanie w celu pobrania rzeczywistego przyłączonego dokumentu.
Jeśli to sprzężenie jest przyklejane tylko do dwóch fragmentów danych, to dlaczego nie porzucić go całkowicie? Rozważmy następujący przykład.
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
Teraz, gdybym miał autora, natychmiast wiem, które książki napisali, i odwrotnie, gdybym miał załadowany dokument książki wiedziałbym identyfikatory autorów. Pozwala to zaoszczędzić zapytanie pośredniczące względem tabeli sprzężenia, zmniejszając liczbę rund serwera, które aplikacja musi wykonać.
Hybrydowe modele danych
Teraz przyjrzeliśmy się osadzaniu (lub denormalizacji) i odwoływania się (lub normalizacji) danych. Każde podejście ma wady i kompromisy.
To nie zawsze musi być albo lub, nie boi się mieszać rzeczy trochę.
Na podstawie konkretnych wzorców użycia i obciążeń aplikacji mogą występować przypadki, w których mieszanie osadzonych i przywołynych danych ma sens i może prowadzić do prostszej logiki aplikacji z mniejszą liczbą rund serwera przy zachowaniu dobrego poziomu wydajności.
Rozważmy następujący kod JSON.
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
W tym miejscu (głównie) wykonaliśmy model osadzony, w którym dane z innych jednostek są osadzone w dokumencie najwyższego poziomu, ale inne dane są przywoływane.
Jeśli spojrzysz na dokument książki, zobaczymy kilka interesujących pól, gdy przyjrzymy się tablicy autorów. id Istnieje pole, którego używamy do odwoływania się do dokumentu autora, standardowej praktyki w znormalizowanym modelu, ale mamy również i name thumbnailUrl. Moglibyśmy zablokować id i pozostawić aplikację, aby uzyskać dodatkowe informacje potrzebne z odpowiedniego dokumentu autora przy użyciu "linku", ale ponieważ nasza aplikacja wyświetla nazwę autora i obraz miniatury z każdą wyświetloną książką, możemy zapisać rundę na serwerze na liście, denormalizując niektóre dane od autora.
Oczywiście, jeśli nazwa autora zmieniła się lub chciała zaktualizować swoje zdjęcie, musielibyśmy zaktualizować każdą książkę, którą kiedykolwiek opublikowali, ale dla naszej aplikacji, na podstawie założenia, że autorzy nie zmieniają swoich nazwisk często, jest to akceptowalna decyzja projektowa.
W tym przykładzie istnieją wstępnie obliczone wartości agregacji w celu zapisania kosztownego przetwarzania na operacji odczytu. W tym przykładzie niektóre dane osadzone w dokumencie autora to dane obliczane w czasie wykonywania. Za każdym razem, gdy zostanie opublikowana nowa książka, tworzony jest dokument książki, a pole countOfBooks jest ustawiane na wartość obliczeniową na podstawie liczby dokumentów książki, które istnieją dla określonego autora. Ta optymalizacja byłaby dobra w systemach z dużym obciążeniem odczytu, na które możemy pozwolić sobie na wykonywanie obliczeń na zapisach w celu optymalizacji odczytów.
Możliwość posiadania modelu ze wstępnie obliczonymi polami jest możliwa, ponieważ usługa Azure Cosmos DB obsługuje transakcje obejmujące wiele dokumentów. Wiele sklepów NoSQL nie może wykonywać transakcji w dokumentach i dlatego opowiada się za decyzjami projektowymi, takimi jak "zawsze osadź wszystko", ze względu na to ograniczenie. Za pomocą usługi Azure Cosmos DB można używać wyzwalaczy po stronie serwera lub procedur składowanych, które wstawią książki i aktualizują autorów wszystkich w ramach transakcji ACID. Teraz nie musisz osadzać wszystkiego w jednym dokumencie, aby mieć pewność, że dane pozostają spójne.
Rozróżnianie różnych typów dokumentów
W niektórych scenariuszach warto mieszać różne typy dokumentów w tej samej kolekcji; zwykle ma to miejsce, gdy chcesz, aby wiele powiązanych dokumentów znajduje się w tej samej partycji. Można na przykład umieścić zarówno książki, jak i recenzje książek w tej samej kolekcji i podzielić ją na partycje według .bookId W takiej sytuacji zwykle chcesz dodać do dokumentów pole identyfikujące ich typ w celu ich odróżnienia.
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
},
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
Modelowanie danych dla usługi Azure Synapse Link i magazynu analitycznego usługi Azure Cosmos DB
Usługa Azure Synapse Link dla usługi Azure Cosmos DB to natywna dla chmury funkcja hybrydowego przetwarzania transakcyjnego i analitycznego (HTAP), która umożliwia uruchamianie analizy niemal w czasie rzeczywistym na danych operacyjnych w usłudze Azure Cosmos DB. Usługa Azure Synapse Link tworzy ścisłą i bezproblemową integrację między usługą Azure Cosmos DB i usługą Azure Synapse Analytics.
Ta integracja odbywa się za pośrednictwem magazynu analitycznego usługi Azure Cosmos DB— kolumnowej reprezentacji danych transakcyjnych, która umożliwia analizę na dużą skalę bez żadnego wpływu na obciążenia transakcyjne. Ten magazyn analityczny jest odpowiedni dla szybkich, ekonomicznych zapytań dotyczących dużych zestawów danych operacyjnych bez kopiowania danych i wpływania na wydajność obciążeń transakcyjnych. Po utworzeniu kontenera z włączonym magazynem analitycznym lub włączeniu magazynu analitycznego w istniejącym kontenerze wszystkie transakcyjne wstawki, aktualizacje i usunięcia są synchronizowane z magazynem analitycznym niemal w czasie rzeczywistym, nie są wymagane żadne zadania zestawienia zmian ani etL.
Usługa Azure Synapse Link umożliwia teraz bezpośrednie łączenie się z kontenerami usługi Azure Cosmos DB z usługi Azure Synapse Analytics i uzyskiwanie dostępu do magazynu analitycznego bez kosztów jednostek żądania (jednostek żądań). Usługa Azure Synapse Analytics obecnie obsługuje usługę Azure Synapse Link z usługą Synapse Apache Spark i bezserwerowymi pulami SQL. Jeśli masz globalnie rozproszone konto usługi Azure Cosmos DB, po włączeniu magazynu analitycznego dla kontenera będzie ono dostępne we wszystkich regionach dla tego konta.
Automatyczne wnioskowanie schematu magazynu analitycznego
Magazyn transakcyjny usługi Azure Cosmos DB jest uważany za dane częściowo ustrukturyzowane zorientowane na wiersz, magazyn analityczny ma format kolumnowy i ustrukturyzowany. Ta konwersja jest automatycznie dokonana dla klientów przy użyciu reguł wnioskowania schematu dla magazynu analitycznego. W procesie konwersji istnieją limity: maksymalna liczba zagnieżdżonych poziomów, maksymalna liczba właściwości, nieobsługiwane typy danych i inne.
Uwaga
W kontekście magazynu analitycznego uważamy następujące struktury za właściwość:
- Pary JSON "elements" lub "string-value" oddzielone znakami
:". - Obiekty JSON rozdzielane wartościami
{i}. - Tablice JSON rozdzielane przez
[i].
Możesz zminimalizować wpływ konwersji wnioskowania schematu i zmaksymalizować możliwości analityczne, korzystając z poniższych technik.
Normalizacja
Normalizacja staje się bezsensowna, ponieważ usługa Azure Synapse Link umożliwia łączenie między kontenerami przy użyciu języka T-SQL lub spark SQL. Oczekiwane korzyści wynikające z normalizacji to:
- Mniejsze zużycie danych w magazynie transakcyjnym i analitycznym.
- Mniejsze transakcje.
- Mniej właściwości na dokument.
- Struktury danych z mniejszą liczbą poziomów zagnieżdżonych.
Te dwa ostatnie czynniki, mniej właściwości i mniej poziomów, pomagają w wydajności zapytań analitycznych, ale także zmniejszają prawdopodobieństwo, że części danych nie są reprezentowane w magazynie analitycznym. Zgodnie z opisem w artykule dotyczącym reguł automatycznego wnioskowania schematu istnieją ograniczenia dotyczące liczby poziomów i właściwości reprezentowanych w magazynie analitycznym.
Innym ważnym czynnikiem normalizacji jest to, że pule bezserwerowe SQL w usłudze Azure Synapse obsługują zestawy wyników z maksymalnie 1000 kolumnami i uwidaczniają zagnieżdżone kolumny również są liczone w kierunku tego limitu. Innymi słowy, zarówno magazyn analityczny, jak i pule bezserwerowe synapse SQL mają limit 1000 właściwości.
Ale co zrobić, ponieważ denormalizacja jest ważną techniką modelowania danych dla usługi Azure Cosmos DB? Odpowiedzią jest to, że musisz znaleźć właściwą równowagę dla obciążeń transakcyjnych i analitycznych.
Klucz partycji
Klucz partycji usługi Azure Cosmos DB (PK) nie jest używany w magazynie analitycznym. Teraz możesz użyć partycjonowania niestandardowego magazynu analitycznego do kopii magazynu analitycznego przy użyciu dowolnego klucza PK. Ze względu na tę izolację można wybrać klucz PK dla danych transakcyjnych, koncentrując się na pozyskiwaniu danych i odczytach punktów, podczas gdy zapytania obejmujące wiele partycji można wykonywać za pomocą usługi Azure Synapse Link. Zobaczmy przykład:
W hipotetycznym globalnym scenariuszu IoT jest dobrym kluczem PK, device id ponieważ wszystkie urządzenia mają podobny wolumin danych i że nie będziesz mieć problemu z gorącą partycją. Jeśli jednak chcesz przeanalizować dane więcej niż jednego urządzenia, na przykład "wszystkie dane z wczoraj" lub "sumy na miasto", mogą wystąpić problemy, ponieważ są to zapytania obejmujące wiele partycji. Te zapytania mogą zaszkodzić wydajności transakcyjnej, ponieważ używają części przepływności w jednostkach żądań do uruchomienia. Jednak za pomocą usługi Azure Synapse Link można uruchamiać te zapytania analityczne bez kosztów jednostek żądań. Format kolumnowy magazynu analitycznego jest zoptymalizowany pod kątem zapytań analitycznych, a usługa Azure Synapse Link stosuje tę charakterystykę, aby zapewnić doskonałą wydajność w środowiskach uruchomieniowych usługi Azure Synapse Analytics.
Typy danych i nazwy właściwości
Artykuł dotyczący reguł wnioskowania automatycznego schematu zawiera listę obsługiwanych typów danych. Chociaż nieobsługiwany typ danych blokuje reprezentację w magazynie analitycznym, obsługiwane typy danych mogą być przetwarzane inaczej przez środowiska uruchomieniowe usługi Azure Synapse. Jednym z przykładów jest: W przypadku używania ciągów typu Data/godzina, które są zgodne ze standardem ISO 8601 UTC, pule platformy Spark w usłudze Azure Synapse będą reprezentować te kolumny jako ciąg i pule bezserwerowe SQL w usłudze Azure Synapse będą reprezentować te kolumny jako varchar(8000).
Innym wyzwaniem jest to, że nie wszystkie znaki są akceptowane przez platformę Azure Synapse Spark. Chociaż białe spacje są akceptowane, znaki takie jak dwukropek, akcent grobowy i przecinek nie są. Załóżmy, że dokument ma właściwość o nazwie "Imię, Nazwisko". Ta właściwość jest reprezentowana w magazynie analitycznym, a pula bezserwerowa synapse SQL może ją odczytać bez problemu. Ponieważ jednak znajduje się ona w magazynie analitycznym, platforma Azure Synapse Spark nie może odczytać żadnych danych z magazynu analitycznego, w tym wszystkich innych właściwości. Na koniec dnia nie można używać usługi Azure Synapse Spark, jeśli masz jedną właściwość, używając nieobsługiwanych znaków w nazwach.
Spłaszczanie danych
Wszystkie właściwości na poziomie głównym danych usługi Azure Cosmos DB będą reprezentowane w magazynie analitycznym jako kolumna, a wszystkie inne, które są bardziej szczegółowe poziomy modelu danych dokumentów, będą reprezentowane jako dane JSON, również w strukturach zagnieżdżonych. Zagnieżdżone struktury wymagają dodatkowego przetwarzania ze środowisk uruchomieniowych usługi Azure Synapse w celu spłaszczenia danych w formacie ustrukturyzowanym, co może być wyzwaniem w scenariuszach danych big data.
Dokument będzie miał tylko dwie kolumny w magazynie analitycznym i id contactDetails. Wszystkie inne dane email i phone, będą wymagały dodatkowego przetwarzania za pomocą funkcji SQL, aby były odczytywane indywidualnie.
{
"id": "1",
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555"}
]
}
Dokument będzie miał trzy kolumny w magazynie analitycznym, id, emaili phone. Wszystkie dane są bezpośrednio dostępne jako kolumny.
{
"id": "1",
"email": "thomas@andersen.com",
"phone": "+1 555 555-5555"
}
Warstwy danych
Usługa Azure Synapse Link umożliwia obniżenie kosztów z następujących perspektyw:
- Mniej zapytań uruchomionych w transakcyjnej bazie danych.
- Klucz PK zoptymalizowany pod kątem pozyskiwania danych i odczytów punktów, zmniejszając zużycie danych, scenariusze gorącej partycji i podziały partycji.
- Obsługa warstw danych od czasu wygaśnięcia analitycznego (attl) jest niezależna od transakcyjnego czasu wygaśnięcia (tttl). Dane transakcyjne można przechowywać w magazynie transakcyjnym przez kilka dni, tygodni, miesięcy i przechowywać dane w magazynie analitycznym przez lata lub na zawsze. Format kolumnowy magazynu analitycznego zapewnia naturalną kompresję danych z 50% do 90%. A koszt za GB wynosi ok. 10% rzeczywistej ceny sklepu transakcyjnego. Aby uzyskać więcej informacji na temat bieżących ograniczeń kopii zapasowych, zobacz Omówienie magazynu analitycznego.
- Brak zadań ETL uruchomionych w środowisku, co oznacza, że nie trzeba aprowizować jednostek żądań dla nich.
Kontrolowana nadmiarowość
Jest to świetna alternatywa dla sytuacji, gdy model danych już istnieje i nie można go zmienić. A istniejący model danych nie pasuje dobrze do magazynu analitycznego ze względu na reguły automatycznego wnioskowania schematu, takie jak limit poziomów zagnieżdżonych lub maksymalna liczba właściwości. Jeśli tak jest, możesz użyć zestawienia zmian usługi Azure Cosmos DB, aby replikować dane do innego kontenera, stosując wymagane przekształcenia dla przyjaznego modelu danych usługi Azure Synapse Link. Zobaczmy przykład:
Scenariusz
Kontener CustomersOrdersAndItems służy do przechowywania zamówień online, w tym szczegółów klienta i elementów: adres rozliczeniowy, adres dostawy, metoda dostawy, stan dostawy, cena przedmiotów itp. Reprezentowane są tylko pierwsze 1000 właściwości, a kluczowe informacje nie są uwzględniane w magazynie analitycznym, blokując użycie usługi Azure Synapse Link. Kontener ma bazy danych rekordów, których nie można zmienić i przemodelować danych.
Inną perspektywą problemu jest ilość danych big data. Miliardy wierszy są stale używane przez dział analizy, co uniemożliwia im używanie czasu wygaśnięcia do starego usuwania danych. Utrzymywanie całej historii danych w transakcyjnej bazie danych z powodu potrzeb analitycznych wymusza ich ciągłe zwiększanie aprowizacji jednostek żądań, co wpływa na koszty. Obciążenia transakcyjne i analityczne konkurują o te same zasoby w tym samym czasie.
Postępowanie
Rozwiązanie ze źródłem zmian
- Zespół inżynierów postanowił użyć zestawienia zmian, aby wypełnić trzy nowe kontenery:
Customers,OrdersiItems. Dzięki kanałowi informacyjnego zmian normalizują i spłaszczają dane. Niepotrzebne informacje są usuwane z modelu danych, a każdy kontener ma blisko 100 właściwości, unikając utraty danych z powodu automatycznych limitów wnioskowania schematu. - Te nowe kontenery mają włączony magazyn analityczny, a teraz dział analizy używa usługi Synapse Analytics do odczytywania danych, zmniejszając użycie jednostek żądań, ponieważ zapytania analityczne są wykonywane w usłudze Synapse Apache Spark i bezserwerowych pulach SQL.
- Kontener
CustomersOrdersAndItemsma teraz ustawiony czas wygaśnięcia, aby przechowywać dane tylko przez sześć miesięcy, co pozwala na zmniejszenie użycia kolejnych jednostek żądań, ponieważ w usłudze Azure Cosmos DB istnieje co najmniej jedna jednostka żądania na GB. Mniej danych, mniejsza liczba jednostek żądania.
Wnioski
Najważniejsze wnioski z tego artykułu to zrozumienie, że modelowanie danych w świecie, który jest wolny od schematu, jest tak ważne, jak zawsze.
Tak jak nie ma jednego sposobu reprezentowania kawałka danych na ekranie, nie ma jednego sposobu modelowania danych. Musisz zrozumieć swoją aplikację i sposób jej tworzenia, zużywania i przetwarzania danych. Następnie, stosując niektóre z przedstawionych tutaj wytycznych, można ustawić tworzenie modelu, który odpowiada bezpośrednim potrzebom aplikacji. Gdy aplikacje muszą ulec zmianie, możesz łatwo wykorzystać elastyczność bazy danych bez schematu, aby łatwo wprowadzić tę zmianę i rozwijać model danych.