Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Usługa Azure Cosmos DB for PostgreSQL nie jest już obsługiwana w przypadku nowych projektów. Nie używaj tej usługi dla nowych projektów. Zamiast tego użyj jednej z tych dwóch usług:
Użyj usługi Azure Cosmos DB for NoSQL dla rozproszonego rozwiązania bazy danych przeznaczonego dla scenariuszy o dużej skali z umową dotyczącą poziomu usług dostępności 99,999% (SLA), natychmiastowym skalowaniem automatycznym i automatycznym przejściem w tryb failover w wielu regionach.
Użyj funkcji Elastic Clusters usługi Azure Database for PostgreSQL na potrzeby fragmentowanej bazy danych PostgreSQL przy użyciu rozszerzenia Citus typu open source.
Kolokacja oznacza przechowywanie powiązanych informacji razem w tych samych węzłach. Zapytania mogą być szybkie, gdy wszystkie niezbędne dane są dostępne bez żadnego ruchu sieciowego. Kolokowanie powiązanych danych na różnych węzłach umożliwia równoległe uruchamianie zapytań w każdym węźle.
Kolokacja danych dla tabel rozproszonych z hashowaniem
W usłudze Azure Cosmos DB for PostgreSQL wiersz jest przechowywany w fragmencie, jeśli skrót wartości w kolumnie dystrybucji mieści się w zakresie skrótów tego fragmentu. Fragmenty z tym samym zakresem skrótów są zawsze umieszczane w tym samym węźle. Wiersze z równymi wartościami kolumn rozkładu są zawsze w tym samym węźle między tabelami. Koncepcja tabel rozproszonych skrótami jest również nazywana fragmentowaniem opartym na wierszach. W przypadku fragmentowania opartego na schemacie tabele w schemacie rozproszonym są zawsze kolokowane.
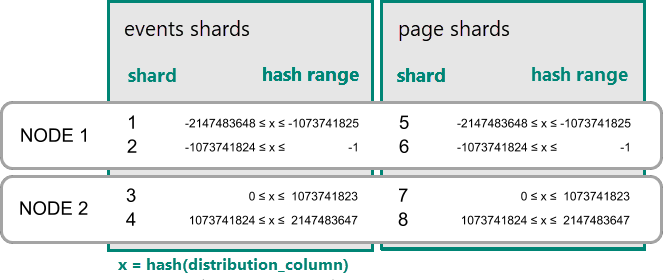
Praktyczny przykład kolokacji
Rozważmy następujące tabele, które mogą być częścią usługi analityki internetowej w modelu SaaS dla wielu najemców.
CREATE TABLE event (
tenant_id int,
event_id bigint,
page_id int,
payload jsonb,
primary key (tenant_id, event_id)
);
CREATE TABLE page (
tenant_id int,
page_id int,
path text,
primary key (tenant_id, page_id)
);
Teraz chcemy odpowiedzieć na zapytania, które mogą być wydawane przez pulpit nawigacyjny dostępny dla klienta. Przykładowe zapytanie to "Zwróć liczbę wizyt w ciągu ostatniego tygodnia dla wszystkich stron rozpoczynających się od '/blog' w najemcy sześć."
Jeśli nasze dane znajdowały się na jednym serwerze PostgreSQL, możemy łatwo wyrazić nasze zapytanie przy użyciu rozbudowanego zestawu operacji relacyjnych oferowanych przez program SQL:
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Jeśli zestaw roboczy dla tego zapytania mieści się w pamięci, tabela z jednym serwerem jest odpowiednim rozwiązaniem. Rozważmy możliwości skalowania modelu danych za pomocą usługi Azure Cosmos DB for PostgreSQL.
Dystrybuuj tabele według identyfikatora
Zapytania pojedynczego serwera zaczynają spowalniać wraz ze wzrostem liczby najemców i danych przechowywanych dla każdego z nich. Zestaw roboczy przestaje się mieścić w pamięci, a procesor staje się wąskim gardłem.
W takim przypadku możemy rozproszyć dane między wieloma węzłami przy użyciu usługi Azure Cosmos DB dla PostgreSQL. Pierwszym i najważniejszym wyborem, który musimy dokonać, gdy zdecydujemy się na fragment, jest kolumna rozkładu. Zacznijmy od naiwnego wyboru dla event_id tabeli zdarzeń i page_id tabeli page :
-- naively use event_id and page_id as distribution columns
SELECT create_distributed_table('event', 'event_id');
SELECT create_distributed_table('page', 'page_id');
Kiedy dane są rozproszone pomiędzy różnymi instancjami roboczymi, nie możemy wykonać łączenia tak, jak na pojedynczym węźle PostgreSQL. Zamiast tego musimy wydać dwa zapytania:
-- (Q1) get the relevant page_ids
SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6;
-- (Q2) get the counts
SELECT page_id, count(*) AS count
FROM event
WHERE page_id IN (/*…page IDs from first query…*/)
AND tenant_id = 6
AND (payload->>'time')::date >= now() - interval '1 week'
GROUP BY page_id ORDER BY count DESC LIMIT 10;
Następnie wyniki z dwóch kroków muszą zostać połączone przez aplikację.
Uruchamianie zapytań musi uwzględniać dane w fragmentach rozrzuconych między węzłami.
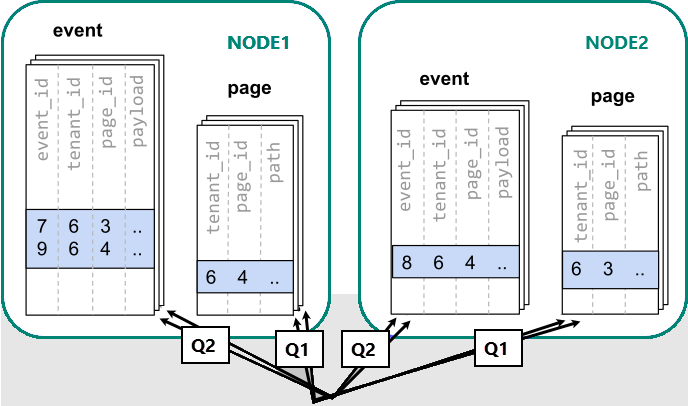
W takim przypadku dystrybucja danych tworzy znaczne wady:
- Obciążenie związane z wykonywaniem zapytań na każdym fragmencie i uruchamianiem wielu zapytań.
- Obciążenie zasobów związane z Q1 zwracającym wiele wierszy do klienta.
- Q2 powiększa się.
- Potrzeba pisania zapytań w wielu krokach wymaga zmian w aplikacji.
Dane są rozproszone, więc zapytania mogą być równoległe. Jest to korzystne tylko wtedy, gdy ilość pracy wykonywanej przez zapytanie jest znacznie większa niż obciążenie związane z wykonywaniem zapytań względem wielu fragmentów.
Dystrybuuj tabele według najemcy
W usłudze Azure Cosmos DB for PostgreSQL wiersze z tą samą wartością kolumny dystrybucji mają gwarancję, że znajdują się w tym samym węźle. Zaczynając od nowa, możemy utworzyć nasze tabele z tenant_id jako kolumną rozkładu.
-- co-locate tables by using a common distribution column
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with => 'event');
Teraz usługa Azure Cosmos DB for PostgreSQL może odpowiedzieć na oryginalne zapytanie pojedynczego serwera bez modyfikacji (Q1):
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Ze względu na filtrowanie i dołączanie do tenant_id usługa Azure Cosmos DB for PostgreSQL wie, że całe zapytanie można odpowiedzieć przy użyciu zestawu współlokowanych fragmentów zawierających dane dla tej konkretnej dzierżawy. Pojedynczy węzeł PostgreSQL może odpowiedzieć na zapytanie w jednym kroku.
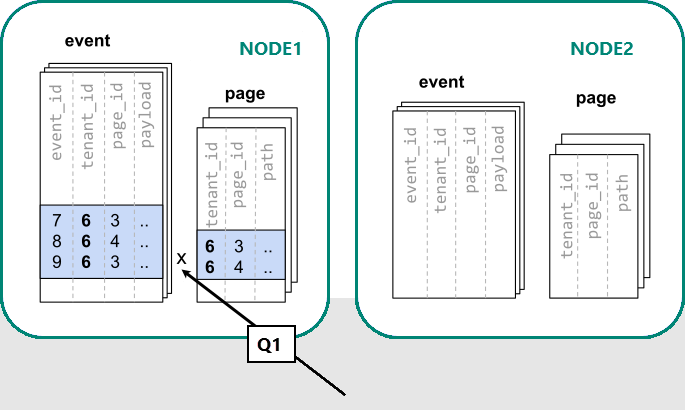
W niektórych przypadkach zapytania i schematy tabel muszą zostać zmienione w celu uwzględnienia identyfikatora dzierżawy w unikatowych ograniczeniach i warunkach sprzężenia. Ta zmiana jest zwykle prosta.