Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Usługa Azure Cosmos DB for PostgreSQL nie jest już obsługiwana w przypadku nowych projektów. Nie używaj tej usługi dla nowych projektów. Zamiast tego użyj jednej z tych dwóch usług:
Użyj usługi Azure Cosmos DB for NoSQL dla rozproszonego rozwiązania bazy danych przeznaczonego dla scenariuszy o dużej skali z umową dotyczącą poziomu usług dostępności 99,999% (SLA), natychmiastowym skalowaniem automatycznym i automatycznym przejściem w tryb failover w wielu regionach.
Użyj funkcji Elastic Clusters usługi Azure Database for PostgreSQL na potrzeby fragmentowanej bazy danych PostgreSQL przy użyciu rozszerzenia Citus typu open source.
Azure Data Factory to oparta na chmurze usługa ETL i usługa integracji danych. Umożliwia tworzenie przepływów pracy opartych na danych w celu przenoszenia i przekształcania danych na dużą skalę.
Za pomocą usługi Data Factory można tworzyć i planować oparte na danych przepływy pracy (nazywane potokami), które pozyskują dane z różnych magazynów danych. Potoki mogą działać lokalnie, na platformie Azure lub u innych dostawców chmury na potrzeby analizy i raportowania.
Usługa Data Factory zawiera ujście danych dla usługi Azure Cosmos DB for PostgreSQL. Ujście danych umożliwia przenoszenie danych (relacyjnych, NoSQL, plików data lake) do tabel usługi Azure Cosmos DB for PostgreSQL na potrzeby magazynowania, przetwarzania i raportowania.
Ważne
Usługa Data Factory nie obsługuje obecnie prywatnych punktów końcowych dla usługi Azure Cosmos DB for PostgreSQL.
Usługa Data Factory na potrzeby pozyskiwania danych w czasie rzeczywistym
Oto kluczowe powody, dla których należy wybrać usługę Azure Data Factory na potrzeby pozyskiwania danych do usługi Azure Cosmos DB for PostgreSQL:
- Łatwe w użyciu — oferuje środowisko wizualne bez użycia kodu do organizowania i automatyzowania przenoszenia danych.
- Zaawansowane — wykorzystuje pełną pojemność bazowej przepustowości sieci, do 5 GiB/s przepływności.
- Wbudowane łączniki — integruje wszystkie źródła danych z ponad 90 wbudowanymi łącznikami.
- Opłacalne — obsługuje w pełni zarządzaną, bezserwerową usługę w chmurze z płatnością za rzeczywiste użycie, skalowaną na żądanie.
Kroki korzystania z usługi Data Factory
W tym artykule utworzysz potok danych przy użyciu interfejsu użytkownika usługi Data Factory. Potok danych w tej fabryce danych kopiuje dane z Azure Blob Storage do bazy danych. Aby zapoznać się z listą magazynów danych obsługiwanych jako źródła i ujścia, zobacz tabelę zawierającą obsługiwane magazyny danych.
W usłudze Data Factory możesz użyć działania Kopiowania , aby skopiować dane między magazynami danych znajdującymi się lokalnie i w chmurze do usługi Azure Cosmos DB for PostgreSQL. Jeśli dopiero zaczynasz pracę z usługą Data Factory, zapoznaj się z szybkim przewodnikiem dotyczącym rozpoczynania pracy:
Po aprowizacji usługi Data Factory przejdź do fabryki danych i uruchom narzędzie Azure Data Factory Studio. Zostanie wyświetlona strona główna usługi Data Factory, jak pokazano na poniższej ilustracji:
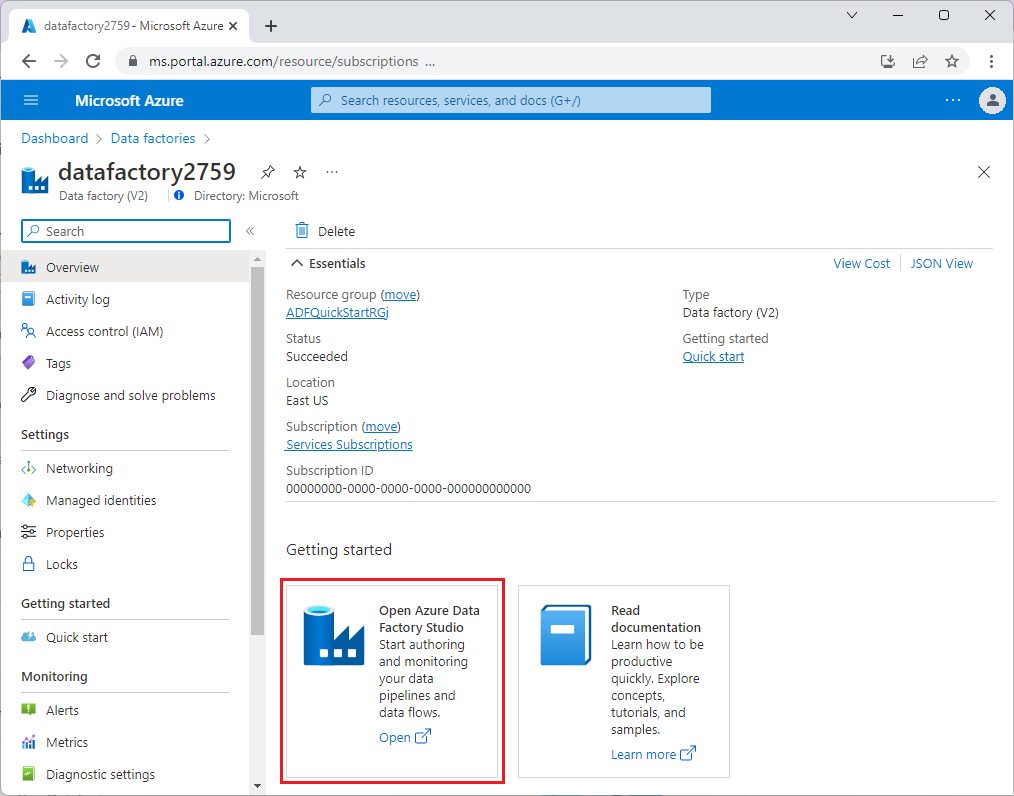
Na stronie głównej narzędzia Azure Data Factory Studio wybierz pozycję Orkiestruj.
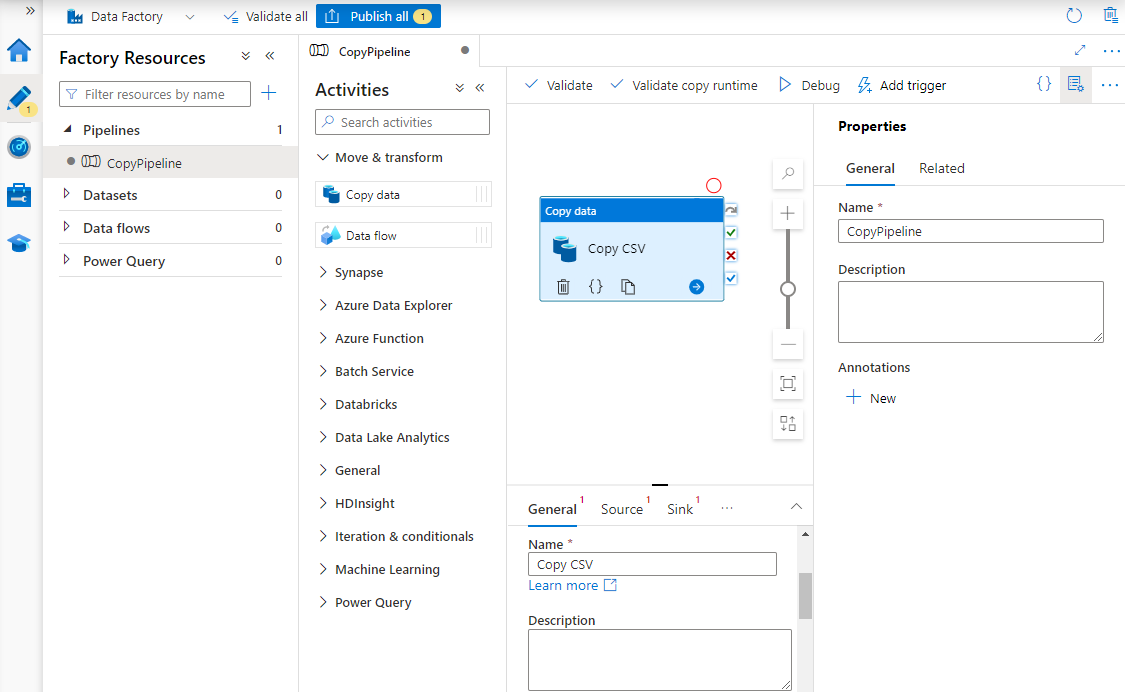
W Właściwościach wprowadź nazwę potoku.
W przyborniku Aktywności rozwiń kategorię Przenieś i przekształć, a następnie przeciągnij i upuść aktywność Kopiuj dane na płaszczyznę projektanta przepływu. W dolnej części okienka projektanta na karcie Ogólne wprowadź nazwę działania kopiowania.
Skonfiguruj źródło.
Na stronie Działania wybierz kartę Źródło . Wybierz pozycję Nowy , aby utworzyć źródłowy zestaw danych.
W oknie dialogowym Nowy zestaw danych wybierz pozycję Azure Blob Storage, a następnie wybierz pozycję Kontynuuj.
Wybierz typ formatu danych, a następnie wybierz pozycję Kontynuuj.
Na stronie Ustawianie właściwości w obszarze Połączona usługa wybierz pozycję Nowy.
Na stronie Nowa połączona usługa wprowadź nazwę połączonej usługi i wybierz konto magazynu z listy nazw kont magazynu.
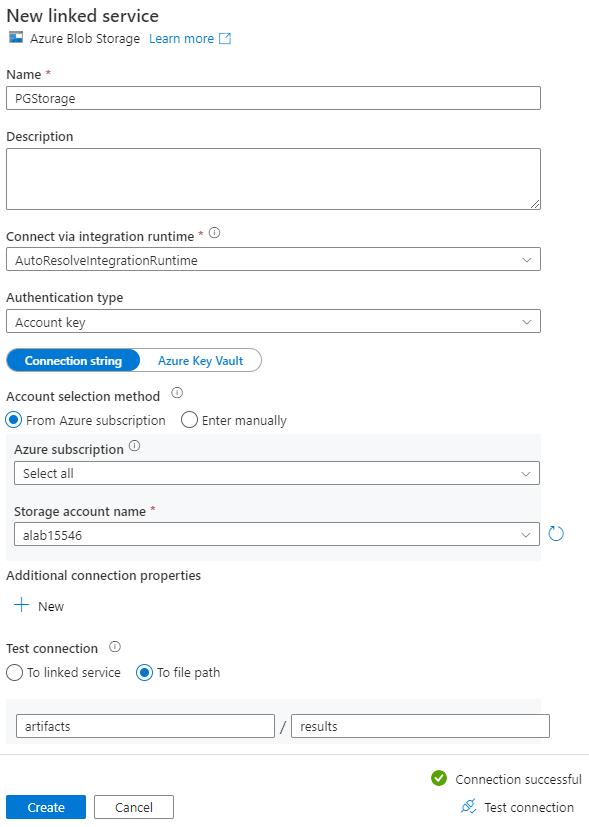
W obszarze Testuj połączenie wybierz pozycję Do ścieżki pliku, wprowadź kontener i katalog, z którymi chcesz nawiązać połączenie, a następnie wybierz pozycję Testuj połączenie.
Wybierz pozycję Utwórz , aby zapisać konfigurację.
Na ekranie Ustawianie właściwości wybierz przycisk OK.
Skonfiguruj odbiornik.
Na stronie Działania wybierz kartę Ujście . Wybierz pozycję Nowy , aby utworzyć zestaw danych ujścia.
W oknie dialogowym Nowy zestaw danych wybierz pozycję Azure Database for PostgreSQL, a następnie wybierz pozycję Kontynuuj.
Na stronie Ustawianie właściwości w obszarze Połączona usługa wybierz pozycję Nowy.
Na stronie Nowa połączona usługa wprowadź nazwę połączonej usługi i wybierz pozycję Wprowadź ręcznie w metodzie wyboru konta.
Wprowadź nazwę koordynatora klastra w polu W pełni kwalifikowana nazwa domeny. Nazwę koordynatora można skopiować ze strony Przegląd klastra usługi Azure Cosmos DB for PostgreSQL.
Pozostaw domyślny port 5432 w polu Port dla bezpośredniego połączenia z koordynatorem lub zastąp go portem 6432, aby nawiązać połączenie z zarządzanym portem PgBouncer .
Wprowadź nazwę bazy danych w klastrze i podaj poświadczenia, aby się z nią połączyć.
Wybierz pozycję SSL z listy rozwijanej Metoda szyfrowania.
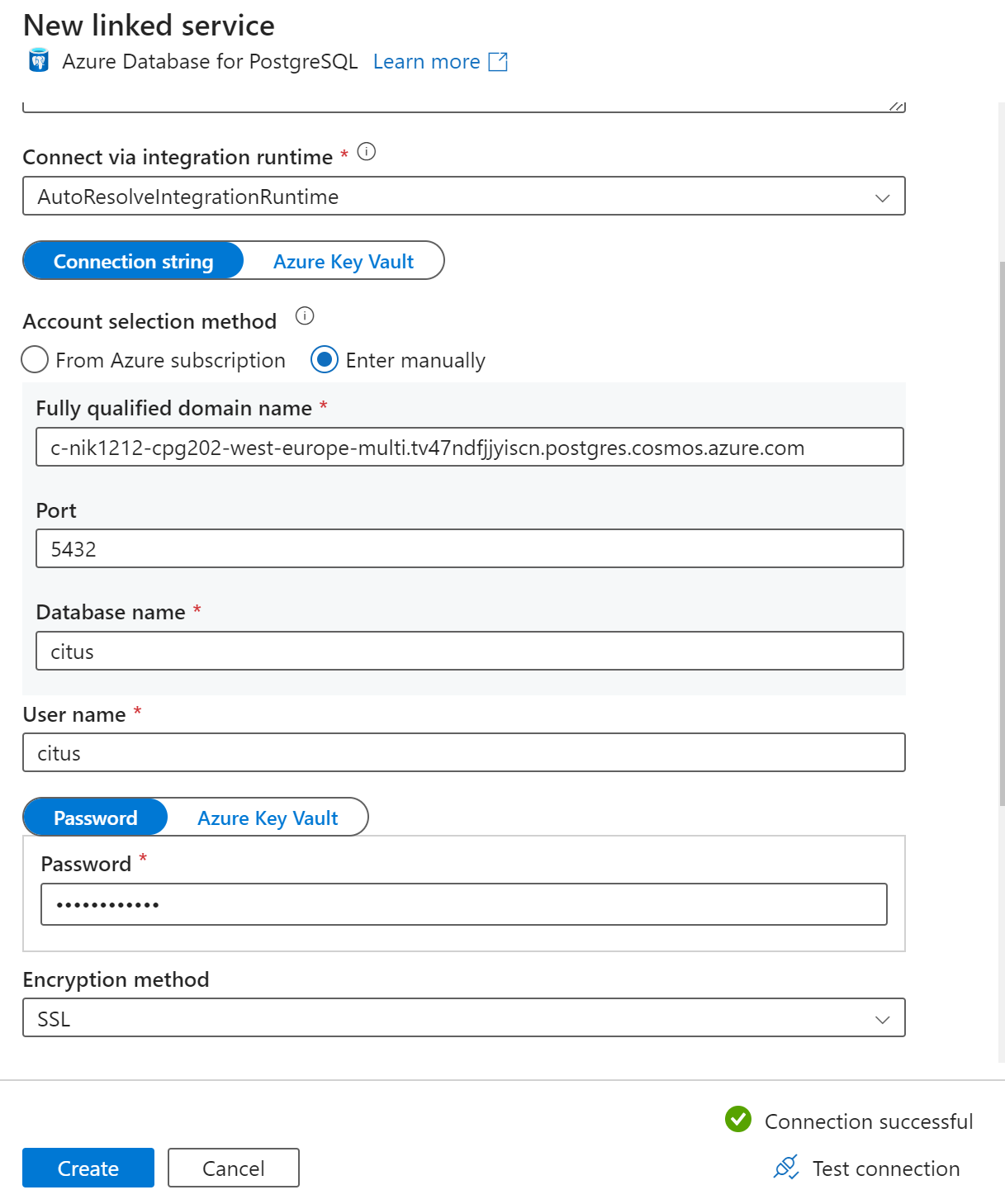
Wybierz pozycję Testuj połączenie w dolnej części panelu, aby zweryfikować konfigurację ujścia.
Wybierz pozycję Utwórz , aby zapisać konfigurację.
Na ekranie Ustawianie właściwości wybierz przycisk OK.
Na karcie Ujście na stronie Działania wybierz Otwórz obok listy rozwijanej Zestaw danych Ujście i wybierz nazwę tabeli w klastrze docelowym, do którego chcesz importować dane.
W obszarze Metoda zapisu wybierz polecenie Kopiuj.
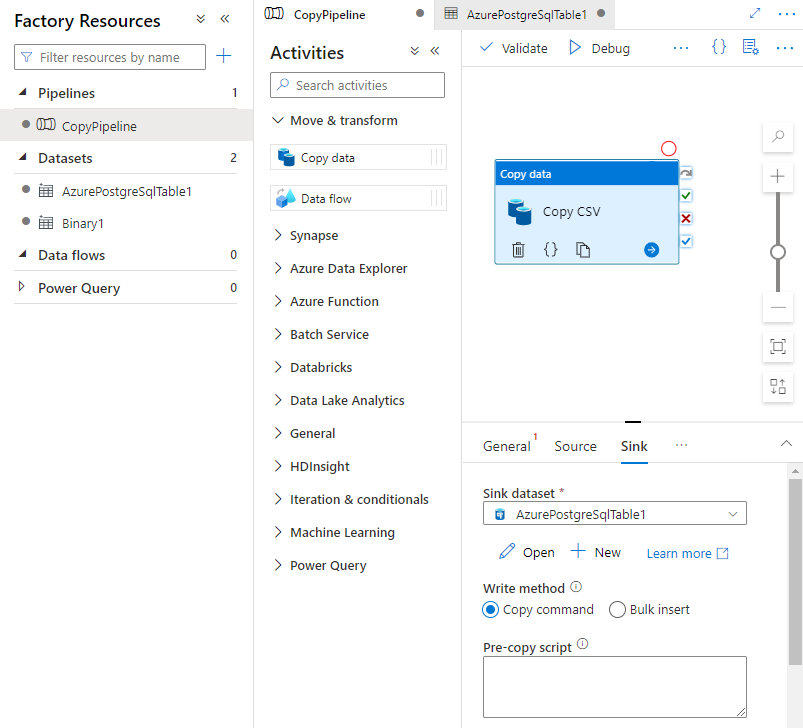
Na pasku narzędzi nad kanwą wybierz pozycję Weryfikuj , aby zweryfikować ustawienia potoku. Napraw wszelkie błędy, przekaż do ponownej walidacji i upewnij się, że potok został pomyślnie zweryfikowany.
Wybierz Debug na pasku narzędzi, aby wykonać pipeline.
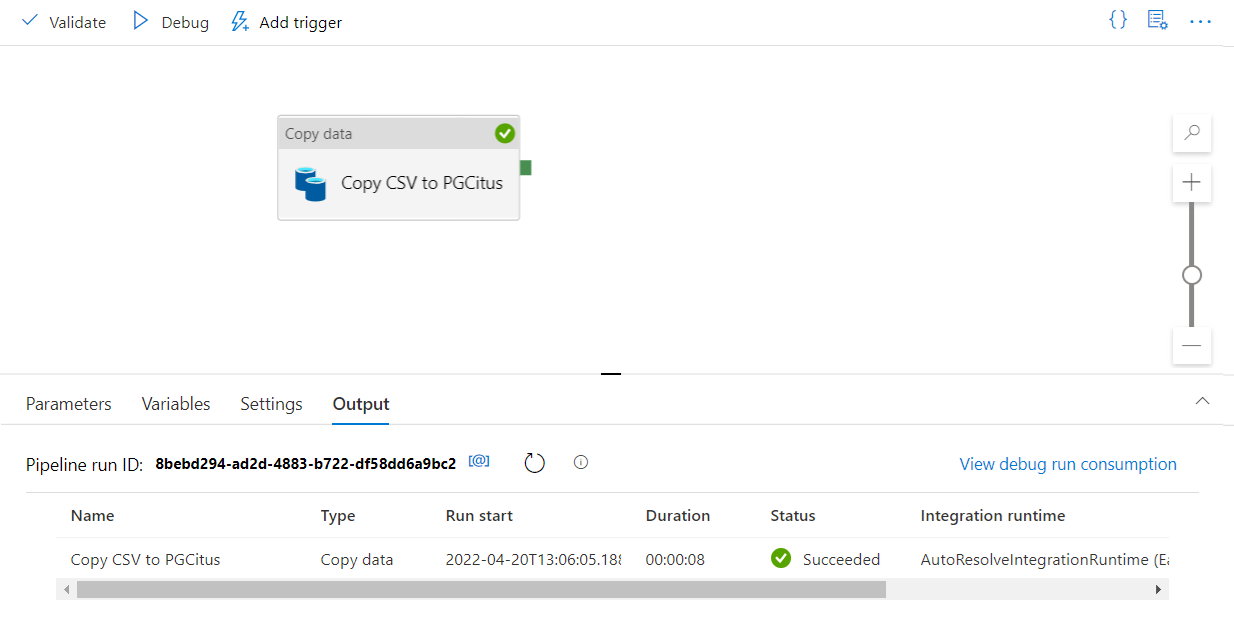
Gdy potok zostanie pomyślnie uruchomiony, na górnym pasku narzędzi wybierz pozycję Opublikuj wszystko. Ta akcja publikuje jednostki (zestawy danych i potoki) utworzone w usłudze Data Factory.
Wywoływanie procedury składowanej w usłudze Data Factory
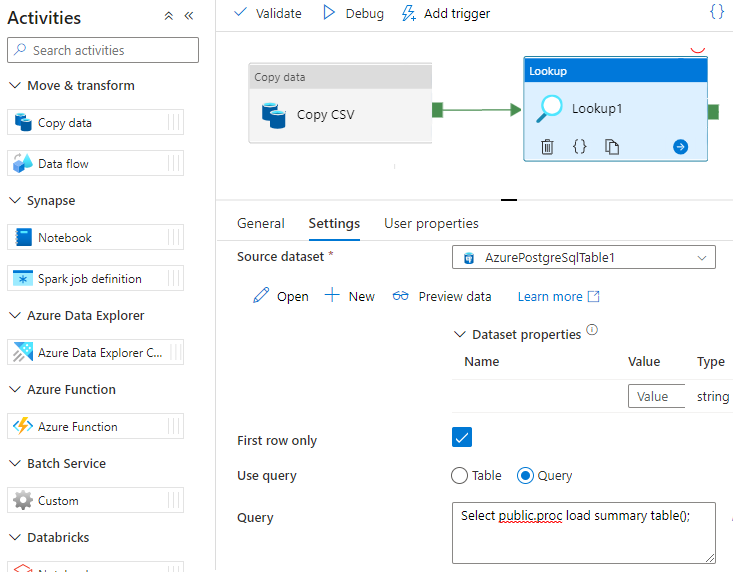
W niektórych konkretnych scenariuszach możesz wywołać procedurę składowaną/funkcję, aby przenieść zagregowane dane z tabeli przejściowej do tabeli podsumowującej. Usługa Data Factory nie oferuje działania procedury składowanej dla usługi Azure Cosmos DB for PostgreSQL, ale jako obejście można użyć działania Lookup z zapytaniem w celu wywołania procedury składowanej, jak pokazano poniżej:
Następne kroki
- Dowiedz się, jak utworzyć pulpit nawigacyjny w czasie rzeczywistym za pomocą usługi Azure Cosmos DB for PostgreSQL.
- Dowiedz się, jak przenieść obciążenie do usługi Azure Cosmos DB for PostgreSQL