Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
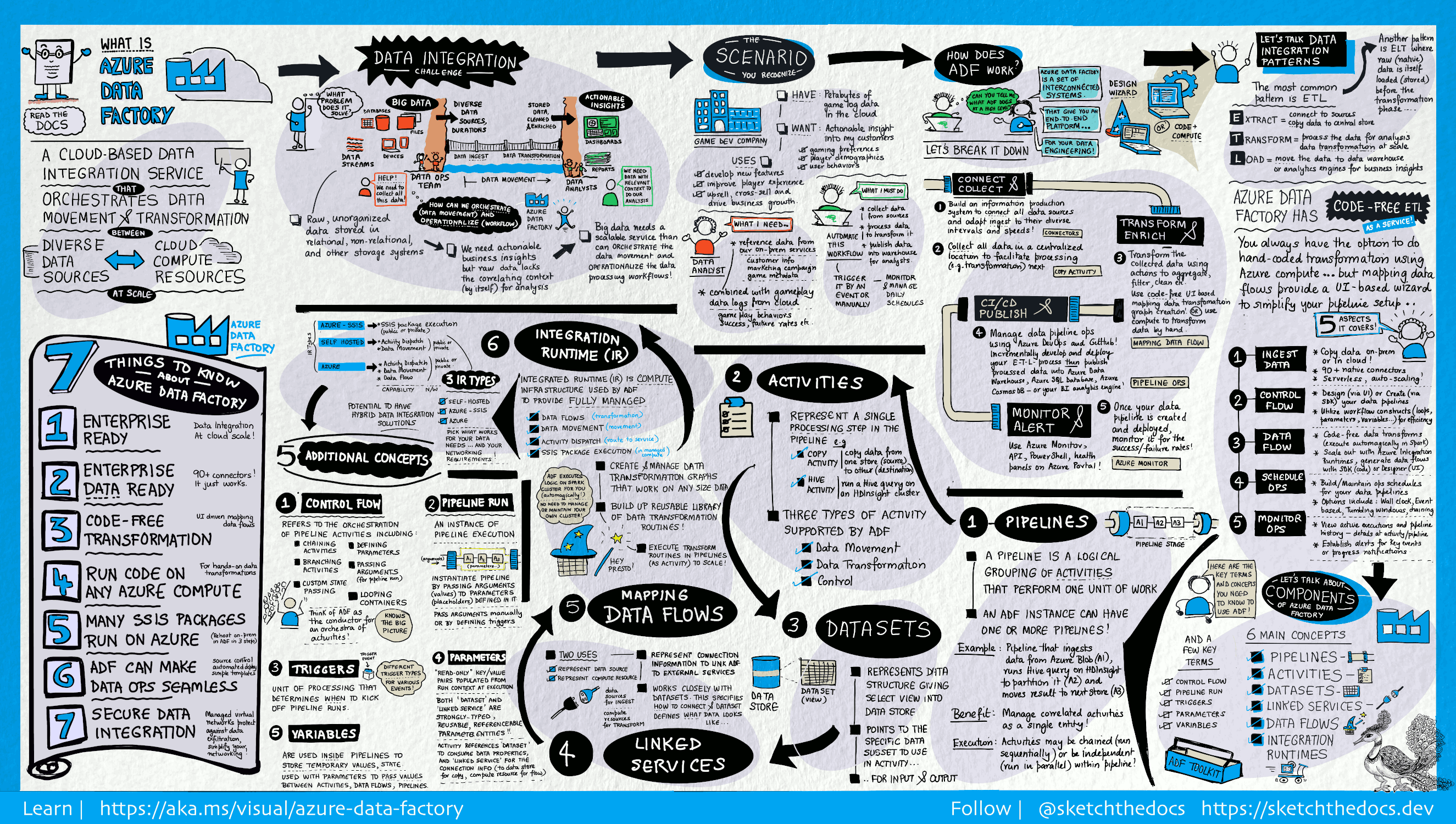
W świecie danych big data dane nieprzetworzone i niezorganizowane często są przechowywane w relacyjnych, nierelacyjnych i innych systemach magazynowania. Jednak same nieprzetworzone dane nie mają prawidłowego kontekstu ani znaczenia umożliwiającego zapewnienie istotnych informacji analitykom, specjalistom z zakresu danych i osobom podejmującym decyzje biznesowe.
Big data wymaga usługi, która umożliwia organizowanie i operacjonalizację procesów, aby przetworzyć te ogromne magazyny nieprzetworzonych danych na praktyczne wnioski biznesowe. Azure Data Factory to zarządzana usługa w chmurze, stworzona do realizacji złożonych, hybrydowych projektów ETL (extract-transform-load), ELT (extract-load-transform) oraz integracji danych.
Funkcje Azure Data Factory
Kompresja danych: podczas aktywności kopiowania można dane skompresować i zapisać skompresowane dane do docelowego źródła danych. Ta funkcja ułatwia optymalizowanie użycia przepustowości podczas kopiowania danych.
Rozbudowana obsługa łączności dla różnych źródeł danych: Azure Data Factory zapewnia szeroką obsługę łączności na potrzeby łączenia się z różnymi źródłami danych. Jest to przydatne, gdy chcesz ściągać lub zapisywać dane z różnych źródeł danych.
Niestandardowe wyzwalacze zdarzeń: Azure Data Factory umożliwia automatyzowanie przetwarzania danych przy użyciu niestandardowych wyzwalaczy zdarzeń. Ta funkcja umożliwia automatyczne wykonywanie określonej akcji w przypadku wystąpienia określonego zdarzenia.
Podgląd danych i walidacja: podczas operacji kopiowania danych dostępne są narzędzia do podglądu i walidacji danych. Ta funkcja pomaga upewnić się, że dane są poprawnie kopiowane i zapisywane w docelowym źródle danych.
Dostosowywalne przepływy danych: Azure Data Factory umożliwia tworzenie dostosowywalnych przepływów danych. Ta funkcja umożliwia dodawanie niestandardowych akcji lub kroków przetwarzania danych.
Zintegrowane zabezpieczenia: Azure Data Factory oferuje zintegrowane funkcje zabezpieczeń, takie jak integracja Entra ID i kontrola dostępu oparta na rolach w celu kontrolowania dostępu do przepływów danych. Ta funkcja zwiększa bezpieczeństwo przetwarzania danych i chroni dane.
Scenariusze użycia
Przykładowo wyobraź sobie, że firma zajmująca się grami gromadzi petabajty dzienników gier, które są tworzone przez gry w chmurze. Firma chce analizować te dzienniki w celu uzyskania wglądu w preferencje klientów, dane demograficzne i zachowania związane z użyciem. Dzięki temu firma będzie mogła identyfikować możliwości rozszerzania oferty i sprzedaży wiązanej, opracowywać nowe atrakcyjne funkcje, stymulować rozwój biznesu i oferować klientom lepsze doświadczenia.
Do analizy tych dzienników firma musi użyć danych referencyjnych, np. informacji o kliencie, grze i kampanii marketingowej, które znajdują się w lokalnym magazynie danych. Firma chce korzystać z tych danych z lokalnego magazynu danych, łącząc je z dodatkowymi danymi dzienników znajdującymi się w magazynie danych w chmurze.
Aby wyodrębnić szczegółowe informacje, ma nadzieję przetworzyć połączone dane przy użyciu klastra Spark w chmurze (Azure HDInsight) i opublikować przekształcone dane w magazynie danych w chmurze, takim jak Azure Synapse Analytics, aby łatwo utworzyć raport na jego podstawie. Firma chce zautomatyzować ten przepływ pracy oraz monitorować go i zarządzać nim zgodnie z codziennym harmonogramem. Chcą również wykonać go, gdy pliki pojawią się w kontenerze magazynu blobów.
Azure Data Factory to platforma, która rozwiązuje takie scenariusze danych. Jest to oparta na chmurze usługa ETL i integracji danych, która umożliwia tworzenie opartych na danych przepływów pracy do organizowania przenoszenia danych i przekształcania danych na dużą skalę. Za pomocą Azure Data Factory można tworzyć i planować oparte na danych przepływy pracy (nazywane potokami), które mogą pozyskiwać dane z różnych magazynów danych. Możesz tworzyć złożone procesy ETL, które przekształcają dane wizualnie za pomocą przepływów danych lub przy użyciu usług obliczeniowych, takich jak Azure HDInsight Hadoop, Azure Databricks i Azure SQL Database.
Ponadto możesz opublikować przekształcone dane w magazynach danych, takich jak Azure Synapse Analytics, aby użyć w aplikacjach analizy biznesowej (BI). Ostatecznie, przy użyciu Azure Data Factory, nieprzetworzone dane mogą być zorganizowane w znaczące magazyny danych i jeziora danych, aby podejmować lepsze decyzje biznesowe.
Jak to działa?
Usługa Data Factory zawiera szereg połączonych systemów, które tworzą kompleksową platformę dla inżynierów danych.

Ten przewodnik wizualny zawiera szczegółowe omówienie pełnej architektury usługi Data Factory:
Szczegółowy przewodnik wizualny po kompletnej architekturze systemu Azure Data Factory, zaprezentowany na jednym zdjęciu o wysokiej rozdzielczości.
Aby wyświetlić więcej szczegółów, wybierz powyższy obraz, aby powiększyć, lub przejdź do obrazu o wysokiej rozdzielczości. Dowiedz się więcej na temat opracowywania tego przewodnika wizualnego i szkicu projektu dokumentacji tutaj.
{kind=link}
Łączenie i zbieranie
Przedsiębiorstwa dysponują danymi różnych typów, znajdującymi się w różnych magazynach lokalnych i w chmurze, ze strukturą pełną i częściową, przychodzącymi w różnych interwałach i w różnym tempie.
Pierwszy krok tworzenia systemu uzyskiwania informacji polega na połączeniu wszystkich wymaganych źródeł danych i systemów przetwarzania, takich jak usługi SaaS, bazy danych, udziały plików oraz internetowe usługi FTP. Następnym krokiem jest przeniesienie danych w miarę potrzeb do centralnej lokalizacji w celu ich dalszego przetwarzania.
Firmy, które nie korzystają z usługi Data Factory, muszą tworzyć niestandardowe składniki umożliwiające przepływ danych lub projektować własne usługi, aby zintegrować źródła danych i systemy przetwarzania. Takie podejście jest kosztowne, a integracja i utrzymanie systemów stwarza trudności. Ponadto rozwiązanie to rzadko zapewnia mechanizmy kontrolne oraz funkcje monitorowania i wysyłania alertów na poziomie korporacyjnym. Możliwości te są natomiast dostępne w przypadku w pełni zarządzanej usługi.
Usługa Data Factory udostępnia działanie kopiowania w potoku danych, które pozwala przenosić dane z lokalnych magazynów danych i źródeł danych w chmurze do centralnego magazynu danych w chmurze w celu przeprowadzenia kolejnych etapów analizy. Można na przykład zbierać dane w Azure Data Lake Storage i przekształcać je później przy użyciu usługi obliczeniowej Azure Data Lake Analytics. Możesz również zbierać dane w usłudze Azure Blob Storage i przekształcać je później przy użyciu klastra Azure HDInsight Hadoop.
Przekształcanie i wzbogacanie
Po umieszczeniu danych w scentralizowanym magazynie danych w chmurze, przetwarzaj lub przekształcaj zebrane dane za pomocą przepływów danych ADF. Przepływy danych umożliwiają inżynierom danych tworzenie i konserwowanie wykresów przekształcania danych wykonywanych na platformie Spark bez konieczności zrozumienia klastrów Spark lub programowania platformy Spark.
Jeśli wolisz ręcznie przekształcać kod, usługa ADF obsługuje działania zewnętrzne do wykonywania przekształceń w usługach obliczeniowych, takich jak HDInsight Hadoop, Spark, Data Lake Analytics i Machine Learning.
CI/CD i publikowanie
Data Factory oferuje kompleksową obsługę CI/CD potoków danych przy użyciu Azure DevOps i GitHub. Dzięki temu można stopniowo opracowywać i dostarczać procesy ETL przed opublikowaniem gotowego produktu. Po przekształceniu danych pierwotnych w formę gotową do użytku biznesowego, załaduj dane do Azure Data Warehouse, Azure SQL Database, Azure Cosmos DB lub dowolnego aparatu analitycznego, do którego użytkownicy biznesowi mogą się odwołać za pomocą swoich narzędzi business intelligence.
Monitor
Po pomyślnym zbudowaniu i wdrożeniu potoku integracji danych, dostarczając wartość biznesową z przetworzonych danych, monitoruj zaplanowane działania i potoki pod kątem współczynników sukcesu i porażki. Azure Data Factory ma wbudowaną obsługę monitorowania potoków za pośrednictwem Azure Monitor, interfejsu API, programu PowerShell, dzienników Azure Monitor i paneli kondycji w portalu Azure.
Koncepcje najwyższego poziomu
Jedna subskrypcja Azure może mieć jedno lub więcej wystąpień Azure Data Factory (lub fabryk danych). Azure Data Factory składa się z następujących kluczowych składników:
- Pipelines
- Działania
- Zestawy danych
- Połączone usługi
- Przepływy danych
- Środowiska uruchomieniowe integracji
Ich współdziałanie pozwala udostępnić platformę umożliwiającą tworzenie opartych na danych przepływów pracy wraz z etapami służącymi do przenoszenia i przekształcania danych.
rurociąg
Fabryka danych może mieć jeden lub więcej potoków. Potok przetwarzania danych to logiczne grupowanie działań, które wykonują jednostkowe zadanie. Działania w rurociągu razem wykonują zadanie. Na przykład pipeline może zawierać grupę działań, które wczytują dane z obiektu blob w Azure, a następnie uruchamiają zapytanie Hive w klastrze HDInsight w celu partycjonowania danych.
Zaletą zastosowania pipeline'a jest możliwość zarządzania działaniami jako zestawem, zamiast zarządzać każdą czynnością osobno. Działania w potoku można połączyć w łańcuch, aby działały sekwencyjnie lub działać niezależnie.
Mapowanie przepływu danych
Tworzenie grafów logiki przekształcania danych i zarządzanie nimi, których można użyć do przekształcania danych o dowolnym rozmiarze. Możesz zbudować bibliotekę procedur przekształcania danych, która będzie wielokrotnego użytku, i uruchamiać te procesy w rozproszony sposób z poziomu potoków ADF. Usługa Data Factory wykona logikę w klastrze Spark, który uruchamia się i zatrzymuje, kiedy jest potrzebny. Nigdy nie trzeba zarządzać ani obsługiwać klastrów.
Działanie
Działania reprezentują krok przetwarzania w przepływie pracy. Można na przykład użyć działania kopiowania w celu skopiowania danych z jednego magazynu danych do drugiego. Podobnie możesz użyć działania programu Hive, które uruchamia zapytanie Hive w klastrze Azure HDInsight, aby przekształcać lub analizować dane. Usługa Data Factory obsługuje trzy typy działań: działania przenoszenia danych, działania przekształcania danych i działania sterowania.
Zestawy danych
Zestawy danych reprezentują struktury w magazynach danych. Struktury te po prostu wskazują na dane, które mają być używane w działaniach jako dane wejściowe lub wyjściowe.
Połączone usługi
Połączone usługi działają podobnie do parametrów połączenia, umożliwiając definiowanie informacji wymaganych przez usługę Data Factory do nawiązywania połączeń z zasobami zewnętrznymi. Mechanizm ten działa następująco: połączona usługa zawiera definicję połączenia ze źródłem danych, a zestaw danych reprezentuje strukturę danych. Na przykład usługa połączona z Azure Storage określa ciąg połączenia, aby nawiązać połączenie z kontem Azure Storage. Ponadto zestaw danych obiektów blob Azure określa kontener obiektów blob i folder zawierający dane.
Połączone usługi w usłudze Fabryka danych służą do dwóch celów:
Aby reprezentować magazyn danych, który obejmuje, ale nie jest ograniczony do bazy danych SQL Server, bazy danych Oracle, udziału plików lub konta magazynu obiektów blob Azure. Listę obsługiwanych magazynów danych zamieszczono w artykule na temat działania kopiowania.
Reprezentowanie zasobu obliczeniowego, który może hostować wykonywanie działania. Na przykład działanie HDInsightHive jest wykonywane w klastrze HDInsight na platformie Hadoop. Listę działań przekształcania i obsługiwanych środowisk obliczeniowych zamieszczono w artykule dotyczącym przekształcania danych.
Integration Runtime
W usłudze Data Factory działanie definiuje akcję do wykonania. Połączona usługa definiuje docelowy magazyn danych lub usługę obliczeniową. Środowisko Integration Runtime zapewnia most między działaniem a połączonymi usługami. Odwołuje się do niej połączona usługa lub działanie i udostępnia środowisko obliczeniowe, w którym działanie jest uruchamiane lub wysyłane. Dzięki temu działanie można wykonać w regionie najbliższym docelowemu magazynowi danych lub usłudze obliczeniowej, w sposób najbardziej wydajny, jednocześnie spełniając wymagania dotyczące zabezpieczeń i zgodności.
Wyzwalacze
Wyzwalacze reprezentują jednostkę przetwarzania, która określa, kiedy należy uruchomić wykonanie potoku. Istnieją różne typy wyzwalaczy dla różnych typów zdarzeń.
Uruchomienia potoków
Uruchomienie potoku jest wystąpieniem wykonywania potoku. Inicjacje potoków są zwykle realizowane przez przekazanie argumentów do parametrów zdefiniowanych w potokach. Argumenty można przekazać ręcznie lub w ramach definicji wyzwalacza.
Parametry
Parametry to pary klucz-wartość w konfiguracji przeznaczonej tylko do odczytu. Parametry są definiowane w rurociągu. Argumenty dla zdefiniowanych parametrów są przekazywane podczas wykonania z kontekstu uruchomienia, który został stworzony przez wyzwalacz lub potok wykonany ręcznie. Działania w rurze używają wartości parametrów.
Zestaw danych to silnie typizowany parametr oraz obiekt wielokrotnego użytku, do którego można się odwoływać. Działanie może odwoływać się do zestawów danych oraz wykorzystywać właściwości określone w definicji zestawu danych.
Połączona usługa to również silnie typizowany parametr zawierający informacje o połączeniu z magazynem danych lub środowiskiem obliczeniowym. Również jest to obiekt wielokrotnego użytku, do którego można się odwoływać.
Sterowanie przebiegiem
Koordynacja przepływu sterowania to zestawienie działań potoku, które obejmuje łączenie działań w sekwencji, rozgałęzianie, definiowanie parametrów na poziomie potoku oraz przekazywanie argumentów podczas wywoływania potoku według potrzeby lub z wyzwalacza. Obejmuje również kontenery przekazujące stan niestandardowy i kontenery do iteracji, czyli iteratory typu For-each.
Variables
Zmienne mogą być używane wewnątrz potoków do przechowywania wartości tymczasowych i mogą być również używane w połączeniu z parametrami, aby umożliwić przekazywanie wartości między potokami, przepływami danych i innymi działaniami.
Powiązana zawartość
Oto ważne dokumenty dotyczące następnego kroku do zbadania:
- Dataset and linked services (Zestaw danych i połączone usługi)
- Linie i działania
- Integration Runtime
- Mapowanie przepływów danych
- interfejs użytkownika usługi Data Factory w portalu Azure
- Narzędzie do kopiowania danych w portalu Azure
- PowerShell
- .NET
- Python
- REST
- Szablon menedżera zasobów Azure