Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY:
![]() Usługa Azure Cosmos DB for PostgreSQL (obsługiwana przez rozszerzenie bazy danych Citus do bazy danych PostgreSQL)
Usługa Azure Cosmos DB for PostgreSQL (obsługiwana przez rozszerzenie bazy danych Citus do bazy danych PostgreSQL)
W tym samouczku używasz Azure Cosmos DB for PostgreSQL, aby nauczyć się:
- Tworzenie fragmentów rozproszonych przy użyciu skrótów
- Zobacz, gdzie znajdują się fragmenty tabeli
- Identyfikowanie niesymetrycznego rozkładu
- Tworzenie ograniczeń dotyczących tabel rozproszonych
- Uruchamianie zapytań dotyczących danych rozproszonych
Wymagania wstępne
Ten samouczek wymaga działającego klastra z dwoma węzłami roboczymi. Jeśli nie masz uruchomionego klastra, postępuj zgodnie z samouczkiem dotyczącym tworzenia klastra, a następnie wróć do tego klastra .
Dane rozproszone hashowo
Dystrybucja wierszy tabeli na wielu serwerach PostgreSQL jest kluczową techniką skalowalnych zapytań w usłudze Azure Cosmos DB for PostgreSQL. Jednocześnie wiele węzłów może przechowywać więcej danych niż tradycyjna baza danych, a w wielu przypadkach może używać procesorów roboczych równolegle do wykonywania zapytań. Koncepcja tabel rozproszonych skrótami jest również nazywana fragmentowaniem opartym na wierszach.
W sekcji wymagań wstępnych utworzyliśmy klaster z dwoma węzłami roboczymi.
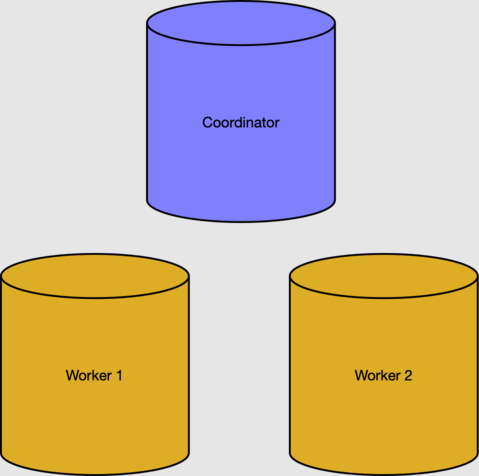
Tabele metadanych węzła koordynującego śledzą pracowników i rozproszone dane. Możemy sprawdzić aktywnych pracowników w tabeli pg_dist_node .
select nodeid, nodename from pg_dist_node where isactive;
nodeid | nodename
--------+-----------
1 | 10.0.0.21
2 | 10.0.0.23
Uwaga
Nazwy węzłów w usłudze Azure Cosmos DB for PostgreSQL to wewnętrzne adresy IP w sieci wirtualnej, a rzeczywiste widoczne adresy mogą się różnić.
Wiersze, fragmenty i umieszczanie
Aby korzystać z zasobów CPU i magazynu węzłów roboczych, musimy rozmieszczać dane tabeli w całym klastrze. Dystrybucja tabeli przypisuje każdy wiersz do grupy logicznej nazywanej shardem. Utwórzmy tabelę i rozdystrybuujmy ją:
-- create a table on the coordinator
create table users ( email text primary key, bday date not null );
-- distribute it into shards on workers
select create_distributed_table('users', 'email');
Usługa Azure Cosmos DB for PostgreSQL przypisuje każdy wiersz do fragmentu na podstawie wartości kolumny dystrybucji, którą w naszym przypadku określiliśmy jako email. Każdy wiersz będzie zawierać dokładnie jeden fragment, a każdy fragment może zawierać wiele wierszy.
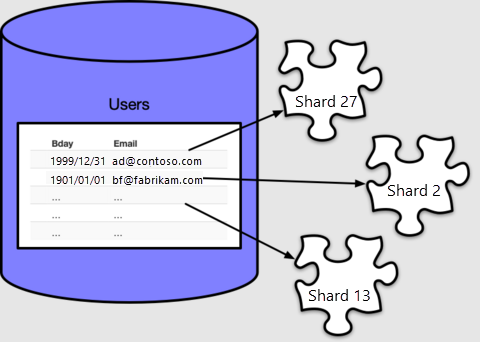
Domyślnie create_distributed_table() tworzy 32 fragmenty, co możemy zobaczyć, zliczając w tabeli metadanych pg_dist_shard:
select logicalrelid, count(shardid)
from pg_dist_shard
group by logicalrelid;
logicalrelid | count
--------------+-------
users | 32
Usługa Azure Cosmos DB for PostgreSQL używa pg_dist_shard tabeli do przypisywania wierszy do fragmentów na podstawie skrótu wartości w kolumnie dystrybucji. Szczegóły haszowania są nieistotne w tym samouczku. Ważne jest, aby móc sprawdzić, które wartości przypisane są do jakich identyfikatorów fragmentów.
-- Where would a row containing hi@test.com be stored?
-- (The value doesn't have to actually be present in users, the mapping
-- is a mathematical operation consulting pg_dist_shard.)
select get_shard_id_for_distribution_column('users', 'hi@test.com');
get_shard_id_for_distribution_column
--------------------------------------
102008
Mapowanie wierszy na fragmenty jest czysto logiczne. Fragmenty muszą być przypisane do określonych węzłów roboczych dla magazynu, w tym, co usługa Azure Cosmos DB for PostgreSQL wywołuje umieszczanie fragmentów.
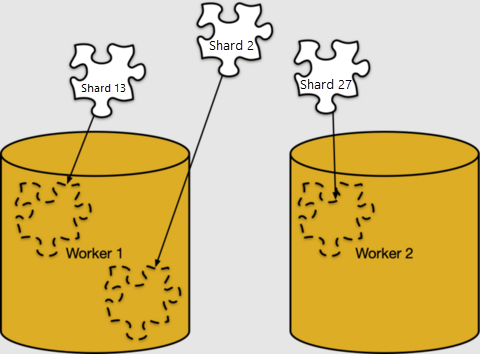
Możemy przyjrzeć się lokalizacjom fragmentów w pg_dist_placement. Połączenie ich z innymi tabelami metadanych, które widzieliśmy, pokazuje, gdzie znajduje się każdy fragment.
-- limit the output to the first five placements
select
shard.logicalrelid as table,
placement.shardid as shard,
node.nodename as host
from
pg_dist_placement placement,
pg_dist_node node,
pg_dist_shard shard
where placement.groupid = node.groupid
and shard.shardid = placement.shardid
order by shard
limit 5;
table | shard | host
-------+--------+------------
users | 102008 | 10.0.0.21
users | 102009 | 10.0.0.23
users | 102010 | 10.0.0.21
users | 102011 | 10.0.0.23
users | 102012 | 10.0.0.21
Niesymetryczność danych
Klaster działa najwydajniej, gdy dane są równomiernie rozmieszczone na węzłach roboczych i gdy powiązane dane są umieszczane razem na tych samych węzłach. W tej sekcji skupimy się na pierwszej części, jednolitości rozmieszczenia.
Aby zademonstrować, utwórzmy przykładowe dane dla naszej users tabeli:
-- load sample data
insert into users
select
md5(random()::text) || '@test.com',
date_trunc('day', now() - random()*'100 years'::interval)
from generate_series(1, 1000);
Aby wyświetlić rozmiary fragmentów, możemy uruchomić funkcje rozmiarów tabel na fragmentach.
-- sizes of the first five shards
select *
from
run_command_on_shards('users', $cmd$
select pg_size_pretty(pg_table_size('%1$s'));
$cmd$)
order by shardid
limit 5;
shardid | success | result
---------+---------+--------
102008 | t | 16 kB
102009 | t | 16 kB
102010 | t | 16 kB
102011 | t | 16 kB
102012 | t | 16 kB
Widzimy, że fragmenty mają równy rozmiar. Widzieliśmy już, że przydziały są równomiernie rozłożone między węzły robocze, więc możemy wywnioskować, że węzły robocze przechowują mniej więcej taką samą liczbę wierszy.
Wiersze w naszym users przykładzie są równomiernie rozmieszczone ze względu na właściwości kolumny rozdzielczej email.
- Liczba adresów e-mail była większa lub równa liczbie fragmentów.
- Liczba wierszy na adres e-mail była podobna (w naszym przypadku dokładnie jeden wiersz na adres, ponieważ zadeklarowaliśmy klucz e-mail).
Każdy wybór tabeli i kolumn dystrybucji, dla którego którakolwiek właściwość zawodzi, spowoduje nierównomierny rozkład rozmiaru danych dla procesów roboczych, czyli przesunięcie danych.
Dodawanie ograniczeń do danych rozproszonych
Korzystanie z usługi Azure Cosmos DB for PostgreSQL umożliwia kontynuowanie korzystania z bezpieczeństwa relacyjnej bazy danych, w tym ograniczeń bazy danych. Istnieje jednak ograniczenie. Ze względu na charakter systemów rozproszonych usługa Azure Cosmos DB for PostgreSQL nie będzie zawierać ograniczeń unikatowości między odwołaniami ani integralności referencyjnej między węzłami procesu roboczego.
Rozważmy nasz przykład tabeli users z powiązaną tabelą.
-- books that users own
create table books (
owner_email text references users (email),
isbn text not null,
title text not null
);
-- distribute it
select create_distributed_table('books', 'owner_email');
Dla wydajności, dystrybuujemy books w taki sam sposób jak users: przez adres e-mail właściciela. Dystrybucja według podobnych wartości kolumn jest nazywana kolokacją.
Nie mieliśmy problemu z dystrybucją książek z kluczem obcym dla użytkowników, ponieważ klucz znajdował się w kolumnie dystrybucji. Jednak mielibyśmy problemy z tworzeniem isbn klucza:
-- will not work
alter table books add constraint books_isbn unique (isbn);
ERROR: cannot create constraint on "books"
DETAIL: Distributed relations cannot have UNIQUE, EXCLUDE, or
PRIMARY KEY constraints that do not include the partition column
(with an equality operator if EXCLUDE).
W tabeli rozproszonej najlepszym, co możemy zrobić, jest zapewnienie unikalności kolumn w odniesieniu do kolumny rozkładu.
-- a weaker constraint is allowed
alter table books add constraint books_isbn unique (owner_email, isbn);
Powyższe ograniczenie powoduje jedynie, że wartość isbn unikatowa na użytkownika. Inną opcją jest ustawienie książek jako tabeli referencyjnej zamiast tabeli rozproszonej i utworzenie oddzielnej tabeli rozproszonej kojarzącej książki z użytkownikami.
Wykonywanie zapytań względem tabel rozproszonych
W poprzednich sekcjach pokazano, jak rozproszone wiersze tabeli są rozmieszczane w segmentach na węzłach roboczych. Przez większość czasu nie musisz wiedzieć, jak lub gdzie dane są przechowywane w klastrze. Usługa Azure Cosmos DB for PostgreSQL ma rozproszonego wykonawcę zapytań, który automatycznie dzieli regularne zapytania SQL. Uruchamia je równolegle w węzłach roboczych w pobliżu danych.
Na przykład możemy uruchomić zapytanie w celu znalezienia średniego wieku użytkowników, traktując tabelę rozproszoną users , tak jak jest to normalna tabela koordynatora.
select avg(current_date - bday) as avg_days_old from users;
avg_days_old
--------------------
17926.348000000000
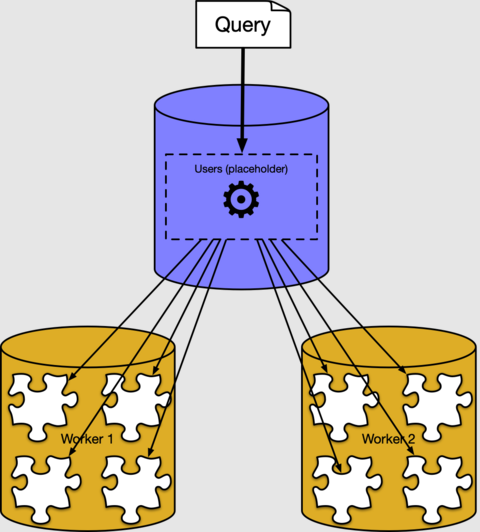
W tle funkcja wykonawcza usługi Azure Cosmos DB for PostgreSQL tworzy oddzielne zapytanie dla każdego fragmentu, uruchamia je w ramach procesów roboczych i łączy wynik. Możesz go zobaczyć, jeśli używasz polecenia EXPLAIN bazy danych PostgreSQL:
explain select avg(current_date - bday) from users;
QUERY PLAN
----------------------------------------------------------------------------------
Aggregate (cost=500.00..500.02 rows=1 width=32)
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=100000 width=16)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=10.0.0.21 port=5432 dbname=citus
-> Aggregate (cost=41.75..41.76 rows=1 width=16)
-> Seq Scan on users_102040 users (cost=0.00..22.70 rows=1270 width=4)
Dane wyjściowe przedstawiają przykład planu wykonywania dla fragmentuusers_10204010.0.0.21). Inne fragmenty nie są wyświetlane, ponieważ są podobne. Widzimy, że węzeł roboczy skanuje tabele fragmentów i stosuje agregację. Węzeł koordynacji łączy agregacje dla wyniku końcowego.
Następne kroki
W tym samouczku utworzyliśmy tabelę rozproszoną i poznaliśmy jej fragmenty i umieszczanie. Widzieliśmy wyzwanie związane z używaniem unikatowych i obcych ograniczeń kluczy, a na koniec zobaczyliśmy, jak zapytania rozproszone działają na wysokim poziomie.
- Przeczytaj więcej na temat typów tabel usługi Azure Cosmos DB for PostgreSQL
- Uzyskaj więcej wskazówek dotyczących wybierania kolumny dystrybucji
- Poznaj zalety kolokacji tabeli