Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Azure Data Lake Storage to wysoce skalowalne i ekonomiczne rozwiązanie typu data lake do analizy danych big data. Łączy ona możliwości systemu plików o wysokiej wydajności z ogromną skalą i oszczędnościami, aby pomóc w skróceniu czasu uzyskania wglądu. Data Lake Storage Gen2 rozszerza możliwości Azure Blob Storage i jest zoptymalizowany pod kątem obciążeń analitycznych.
Azure Data Explorer integruje się z Azure Blob Storage i Azure Data Lake Storage (Gen1 i Gen2), zapewniając szybki, buforowany i indeksowany dostęp do danych przechowywanych w magazynie zewnętrznym. Możesz analizować i wykonywać zapytania dotyczące danych bez wcześniejszego ładowania do Azure Data Explorer. Możesz również jednocześnie wykonywać zapytania dotyczące pozyskanych i nieopracowanych danych zewnętrznych. Aby uzyskać więcej informacji, zapoznaj się z tym, jak tworzyć tabelę zewnętrzną za pomocą kreatora w interfejsie użytkownika sieci Azure Data Explorer. Aby zapoznać się z krótkim omówieniem, zobacz zewnętrzne tabele.
Wskazówka
Najlepsza wydajność zapytań wymaga pozyskiwania danych do Azure Data Explorer. Możliwość wykonywania zapytań dotyczących danych zewnętrznych bez wcześniejszego pozyskiwania powinna być używana tylko w przypadku danych historycznych lub danych, które rzadko są odpytywane. Zoptymalizuj wydajność zapytań dotyczących danych zewnętrznych, aby uzyskać najlepsze wyniki.
Tworzenie tabeli zewnętrznej
Załóżmy, że masz wiele plików CSV zawierających informacje historyczne dotyczące produktów przechowywanych w magazynie i chcesz przeprowadzić szybką analizę, aby znaleźć pięć najpopularniejszych produktów z ubiegłego roku. W tym przykładzie pliki CSV wyglądają następująco:
| Sygnatura czasowa | Identyfikator produktu | Opis produktu |
|---|---|---|
| 2019-01-01 11:21:00 | TO6050 | 3.5in DS/HD Floppy Disk |
| 2019-01-01 11:30:55 | YDX1 | Syntezator Yamaha DX1 |
| ...\ | ...\ | ...\ |
Pliki są przechowywane w usłudze Azure Blob Storage mycompanystorage w kontenerze o nazwie archivedproducts partycjonowane według daty:
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00000-7e967c99-cf2b-4dbb-8c53-ce388389470d.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00001-ba356fa4-f85f-430a-8b5a-afd64f128ca4.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00002-acb644dc-2fc6-467c-ab80-d1590b23fc31.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00003-cd5fad16-a45e-4f8c-a2d0-5ea5de2f4e02.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/02/part-00000-ffc72d50-ff98-423c-913b-75482ba9ec86.csv.gz
...
Aby bezpośrednio uruchomić zapytanie KQL na tych plikach CSV, użyj polecenia .create external table, aby zdefiniować tabelę zewnętrzną w Azure Data Explorer. Aby uzyskać więcej informacji na temat opcji poleceń tworzenia tabeli zewnętrznej, zobacz polecenia tabeli zewnętrznej.
.create external table ArchivedProducts(Timestamp:datetime, ProductId:string, ProductDescription:string)
kind=blob
partition by (Date:datetime = bin(Timestamp, 1d))
dataformat=csv
(
h@'https://mycompanystorage.blob.core.windows.net/archivedproducts;StorageSecretKey'
)
Tabela zewnętrzna jest teraz widoczna w lewym okienku internetowego interfejsu użytkownika Azure Data Explorer:
Uprawnienia dla tabeli zewnętrznej
Przejrzyj następujące uprawnienia tabeli:
- Użytkownik bazy danych może utworzyć tabelę zewnętrzną. Twórca tabeli automatycznie staje się administratorem tabeli.
- Administrator klastra, bazy danych lub tabeli może edytować istniejącą tabelę.
- Każdy użytkownik bazy danych lub czytelnik może wykonywać zapytania dotyczące tabeli zewnętrznej.
Wykonywanie zapytań względem tabeli zewnętrznej
Po zdefiniowaniu tabeli zewnętrznej external_table() funkcja może służyć do odwoływania się do niej. Pozostała część zapytania jest standardowym językiem zapytań Kusto.
external_table("ArchivedProducts")
| where Timestamp > ago(365d)
| summarize Count=count() by ProductId,
| top 5 by Count
Zapytania do danych zewnętrznych i zaimportowanych jednocześnie
W ramach tego samego zapytania można wykonywać zapytania zarówno względem tabel zewnętrznych, jak i pozyskanych tabel danych. Możesz join lub union tabelę zewnętrzną z innymi danymi z Azure Data Explorer, serwerów SQL lub innych źródeł. Użyj let( ) statement, aby przypisać skróconą nazwę do zewnętrznego odwołania do tabeli.
W poniższym przykładzie produkty to pozyskana tabela danych, a ArchivedProducts to tabela zewnętrzna, którą zdefiniowaliśmy:
let T1 = external_table("ArchivedProducts") | where TimeStamp > ago(100d);
let T = Products; //T is an internal table
T1 | join T on ProductId | take 10
Wykonywanie zapytań względem formatów danych hierarchicznych
Azure Data Explorer umożliwia wykonywanie zapytań w formatach hierarchicznych, takich jak JSON, Parquet, Avro i ORC. Aby zamapować schemat danych hierarchicznych na schemat tabeli zewnętrznej (jeśli jest inny), użyj poleceń mapowania tabel zewnętrznych. Jeśli na przykład chcesz wykonywać zapytania dotyczące plików dziennika JSON w następującym formacie:
{
"timestamp": "2019-01-01 10:00:00.238521",
"data": {
"tenant": "aaaabbbb-0000-cccc-1111-dddd2222eeee",
"method": "RefreshTableMetadata"
}
}
{
"timestamp": "2019-01-01 10:00:01.845423",
"data": {
"tenant": "bbbbcccc-1111-dddd-2222-eeee3333ffff",
"method": "GetFileList"
}
}
...
Definicja tabeli zewnętrznej wygląda następująco:
.create external table ApiCalls(Timestamp: datetime, TenantId: guid, MethodName: string)
kind=blob
dataformat=multijson
(
h@'https://storageaccount.blob.core.windows.net/container1;StorageSecretKey'
)
Zdefiniuj mapowanie JSON mapujące pola danych na pola definicji tabeli zewnętrznej:
.create external table ApiCalls json mapping 'MyMapping' '[{"Column":"Timestamp","Properties":{"Path":"$.timestamp"}},{"Column":"TenantId","Properties":{"Path":"$.data.tenant"}},{"Column":"MethodName","Properties":{"Path":"$.data.method"}}]'
Podczas wykonywania zapytań względem tabeli zewnętrznej mapowanie jest wywoływane i odpowiednie dane mapowane na zewnętrzne kolumny tabeli:
external_table('ApiCalls') | take 10
Aby uzyskać więcej informacji na temat składni mapowania, zobacz mapowania danych.
Zapytanie zewnętrznej tabeli TaxiRides w klastrze pomocy
Użyj klastra testowego o nazwie help aby wypróbować różne możliwości Azure Data Explorer. Klaster pomocy zawiera zewnętrzną definicję tabeli dla zestawu danych taksówek w Nowym Jorku zawierającego miliardy przejazdów taksówkami.
Utwórz tabelę zewnętrzną TaxiRides
W tej sekcji przedstawiono zapytanie użyte do utworzenia tabeli zewnętrznej TaxiRides w klastrze pomocy . Ponieważ ta tabela została już utworzona, możesz pominąć tę sekcję i przejść bezpośrednio do zapytania o dane tabeli zewnętrznej TaxiRides.
.create external table TaxiRides
(
trip_id: long,
vendor_id: string,
pickup_datetime: datetime,
dropoff_datetime: datetime,
store_and_fwd_flag: string,
rate_code_id: int,
pickup_longitude: real,
pickup_latitude: real,
dropoff_longitude: real,
dropoff_latitude: real,
passenger_count: int,
trip_distance: real,
fare_amount: real,
extra: real,
mta_tax: real,
tip_amount: real,
tolls_amount: real,
ehail_fee: real,
improvement_surcharge: real,
total_amount: real,
payment_type: string,
trip_type: int,
pickup: string,
dropoff: string,
cab_type: string,
precipitation: int,
snow_depth: int,
snowfall: int,
max_temperature: int,
min_temperature: int,
average_wind_speed: int,
pickup_nyct2010_gid: int,
pickup_ctlabel: string,
pickup_borocode: int,
pickup_boroname: string,
pickup_ct2010: string,
pickup_boroct2010: string,
pickup_cdeligibil: string,
pickup_ntacode: string,
pickup_ntaname: string,
pickup_puma: string,
dropoff_nyct2010_gid: int,
dropoff_ctlabel: string,
dropoff_borocode: int,
dropoff_boroname: string,
dropoff_ct2010: string,
dropoff_boroct2010: string,
dropoff_cdeligibil: string,
dropoff_ntacode: string,
dropoff_ntaname: string,
dropoff_puma: string
)
kind=blob
partition by (Date:datetime = bin(pickup_datetime, 1d))
dataformat=csv
(
h@'https://storageaccount.blob.core.windows.net/container1;secretKey'
)
Utworzoną tabelę
Wykonywanie zapytań o dane tabeli zewnętrznej TaxiRides
Zaloguj się do https://dataexplorer.azure.com/clusters/help/databases/Samples.
Zapytanie dotyczące zewnętrznej tabeli TaxiRides bez partycjonowania
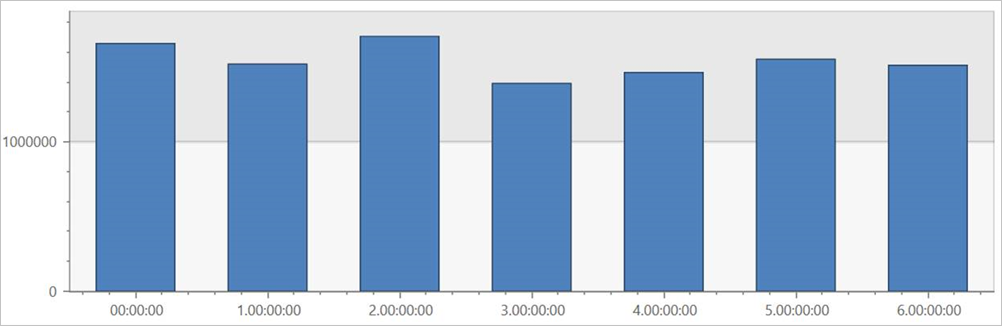
Uruchom to zapytanie w tabeli zewnętrznej TaxiRides , aby wyświetlić przejazdy dla każdego dnia tygodnia w całym zestawie danych.
external_table("TaxiRides")
| summarize count() by dayofweek(pickup_datetime)
| render columnchart
To zapytanie pokazuje najbardziej ruchliwy dzień tygodnia. Ponieważ dane nie są partycjonowane, zwrócenie wyników zapytania może potrwać do kilku minut.
Zapytanie tabeli zewnętrznej TaxiRides z partycjonowaniem
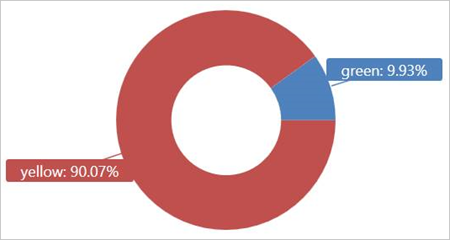
Uruchom to zapytanie w tabeli zewnętrznej TaxiRides , aby wyświetlić typy taksówki (żółty lub zielony) używane w styczniu 2017 roku.
external_table("TaxiRides")
| where pickup_datetime between (datetime(2017-01-01) .. datetime(2017-02-01))
| summarize count() by cab_type
| render piechart
To zapytanie używa partycjonowania, które optymalizuje czas i wydajność zapytań. Zapytanie filtruje kolumnę partycjonowaną (pickup_datetime) i zwraca wyniki w ciągu kilku sekund.
Możesz napisać inne zapytania do uruchomienia w tabeli zewnętrznej TaxiRides i dowiedzieć się więcej o danych.
Optymalizowanie wydajności zapytań
Zoptymalizuj wydajność zapytań w usłudze Lake, korzystając z poniższych najlepszych rozwiązań dotyczących wykonywania zapytań dotyczących danych zewnętrznych.
Format danych
- Użyj formatu kolumnowego dla zapytań analitycznych z następujących powodów:
- Można odczytać tylko kolumny istotne dla zapytania.
- Techniki kodowania kolumn mogą znacznie zmniejszyć rozmiar danych.
- Azure Data Explorer obsługuje formaty kolumnowe Parquet i ORC. Sugeruje się format Parquet ze względu na zoptymalizowaną implementację.
region Azure
Sprawdź, czy dane zewnętrzne są w tym samym regionie Azure co klaster Azure Data Explorer. Ta konfiguracja zmniejsza koszt i czas pobierania danych.
Rozmiar pliku
Optymalny rozmiar pliku to setki Mb (do 1 GB) na plik. Unikaj wielu małych plików, które wymagają niepotrzebnego obciążenia, takich jak wolniejszy proces wyliczania plików i ograniczone użycie formatu kolumnowego. Liczba plików powinna być większa niż liczba rdzeni procesora CPU w klastrze Azure Data Explorer.
Kompresja
Użyj kompresji, aby zmniejszyć ilość danych pobieranych z magazynu zdalnego. W przypadku formatu Parquet należy użyć wewnętrznego mechanizmu kompresji Parquet, który kompresuje grupy kolumn oddzielnie, umożliwiając ich oddzielne odczytywanie. Aby zweryfikować użycie mechanizmu kompresji, sprawdź, czy pliki są nazwane w następujący sposób: <filename>.gz.parquet lub <filename>.snappy.parquet, a nie <filename>.parquet.gz.
Partycjonowanie
Organizuj dane przy użyciu partycji "folder", które umożliwiają zapytaniom pomijanie nieistotnych ścieżek. Podczas planowania partycjonowania rozważ użycie rozmiaru pliku i typowych filtrów w zapytaniach, takich jak sygnatura czasowa lub identyfikator dzierżawy.
Rozmiar maszyny wirtualnej
Wybierz jednostki SKU maszyn wirtualnych z większą przepływnością rdzeni i wyższą przepływnością sieci (pamięć jest mniej ważna). Aby uzyskać więcej informacji, zobacz Wybierz poprawną jednostkę SKU maszyny wirtualnej dla klastra Azure Data Explorer.