operator sprzężenia
Scal wiersze dwóch tabel, aby utworzyć nową tabelę, pasując do wartości określonych kolumn z każdej tabeli.
język zapytań Kusto (KQL) oferuje wiele rodzajów sprzężeń, które wpływają na schemat i wiersze w wynikowej tabeli na różne sposoby. Jeśli na przykład używasz sprzężenia inner , tabela zawiera te same kolumny co lewa tabela oraz kolumny z prawej tabeli. Aby uzyskać najlepszą wydajność, jeśli jedna tabela jest zawsze mniejsza niż druga, użyj jej jako lewej join strony operatora.
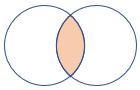
Na poniższej ilustracji przedstawiono wizualną reprezentację operacji wykonywanej przez każde sprzężenia. Kolor cieniowania reprezentuje zwrócone kolumny, a zacienione obszary reprezentują zwrócone wiersze.
Składnia
LeftTable | join [ kind = JoinFlavor ] [ Wskazówki ]( Warunki z prawej tabeli) on
Dowiedz się więcej na temat konwencji składni.
Parametry
| Nazwisko | Type | Wymagania | opis |
|---|---|---|---|
| LeftTable | string |
✔️ | Lewa tabela lub wyrażenie tabelaryczne, czasami nazywane tabelą zewnętrzną, której wiersze mają zostać scalone. Oznaczono jako $left. |
| JoinFlavor | string |
Typ sprzężenia do wykonania: innerunique, , inner, rightouterleftsemileftouterfullouterleftantirightanti. rightsemi Wartość domyślna to innerunique. Aby uzyskać więcej informacji na temat smaków sprzężenia, zobacz Zwracane. |
|
| Wskazówki | string |
Zero lub więcej wskazówek sprzężenia rozdzielanych spacjami w postaci wartości nazwy = , które kontrolują zachowanie operacji dopasowania wiersza i planu wykonania. Aby uzyskać więcej informacji, zobacz Wskazówki. |
|
| RightTable | string |
✔️ | Prawa tabelaryczna lub tabelaryczna wyrażenie, czasami nazywane tabelą wewnętrzną, której wiersze mają zostać scalone. Oznaczono jako $right. |
| Warunki | string |
✔️ | Określa, jak wiersze z tabeli LeftTable są dopasowywane do wierszy z tabeli RightTable. Jeśli kolumny, które chcesz dopasować, mają taką samą nazwę w obu tabelach, użyj składni ON ColumnName. W przeciwnym razie użyj składni ON $left.LeftColumn RightColumn==$right.. Aby określić wiele warunków, możesz użyć słowa kluczowego "and" lub oddzielić je przecinkami. Jeśli używasz przecinków, warunki są oceniane przy użyciu operatora logicznego "i". |
Napiwek
Aby uzyskać najlepszą wydajność, jeśli jedna tabela jest zawsze mniejsza niż druga, użyj jej jako lewej strony sprzężenia.
Wskazówki
| Klucz wskazówki | Wartości | opis |
|---|---|---|
hint.remote |
auto, , left, , localright |
Zobacz Łączenie między klastrami |
hint.strategy=broadcast |
Określa sposób udostępniania obciążenia zapytania w węzłach klastra. | Zobacz sprzężenia emisji |
hint.shufflekey=<key> |
Zapytanie shufflekey współudzieli obciążenie zapytania w węzłach klastra przy użyciu klucza do partycjonowania danych. |
Zobacz zapytanie mieszania |
hint.strategy=shuffle |
shuffle Zapytanie strategii współudzieli obciążenie zapytania w węzłach klastra, gdzie każdy węzeł przetwarza jedną partycję danych. |
Zobacz zapytanie mieszania |
| Nazwisko | Wartości | opis |
|---|---|---|
hint.remote |
auto, , left, , localright |
|
hint.strategy=broadcast |
Określa sposób udostępniania obciążenia zapytania w węzłach klastra. | Zobacz sprzężenia emisji |
hint.shufflekey=<key> |
Zapytanie shufflekey współudzieli obciążenie zapytania w węzłach klastra przy użyciu klucza do partycjonowania danych. |
Zobacz zapytanie mieszania |
hint.strategy=shuffle |
shuffle Zapytanie strategii współudzieli obciążenie zapytania w węzłach klastra, gdzie każdy węzeł przetwarza jedną partycję danych. |
Zobacz zapytanie mieszania |
Uwaga
Wskazówki dotyczące sprzężenia nie zmieniają semantyki, join ale mogą mieć wpływ na wydajność.
Zwraca
Schemat zwracany i wiersze zależą od smaku sprzężenia. Sprzężenia jest określony za pomocą słowa kluczowego kind . W poniższej tabeli przedstawiono obsługiwane smaki sprzężenia. Aby wyświetlić przykłady dla konkretnego smaku sprzężenia, wybierz link w kolumnie Sprzężenie smakowe .
| Sprzężenia smak | Zwraca | Ilustracja |
|---|---|---|
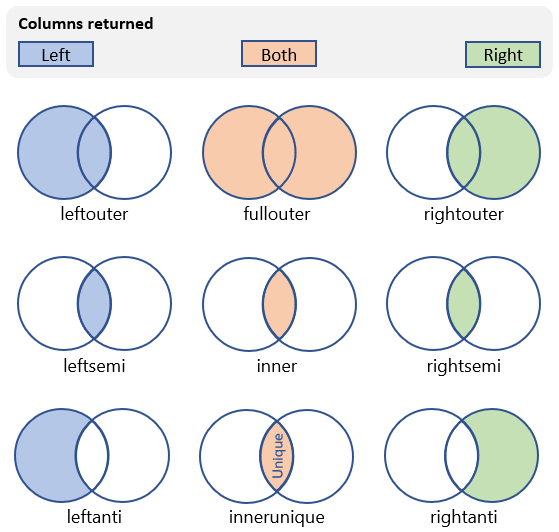
| innerunique (ustawienie domyślne) | Sprzężenie wewnętrzne z deduplikacją po lewej stronie Schemat: wszystkie kolumny z obu tabel, w tym pasujące klucze Wiersze: wszystkie deduplikowane wiersze z lewej tabeli pasujące do wierszy z prawej tabeli |
|
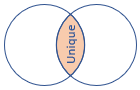
| wewnętrzny | Standardowe sprzężenie wewnętrzne Schemat: wszystkie kolumny z obu tabel, w tym pasujące klucze Wiersze: tylko pasujące wiersze z obu tabel |
|
| leftouter | Lewe sprzężenia zewnętrzne Schemat: wszystkie kolumny z obu tabel, w tym pasujące klucze Wiersze: wszystkie rekordy z lewej tabeli i tylko pasujące wiersze z prawej tabeli |
|
| rightouter | Prawe sprzężenia zewnętrzne Schemat: wszystkie kolumny z obu tabel, w tym pasujące klucze Wiersze: wszystkie rekordy z prawej tabeli i tylko pasujące wiersze z lewej tabeli |
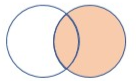
|
| fullouter | Pełne sprzężenia zewnętrzne Schemat: wszystkie kolumny z obu tabel, w tym pasujące klucze Wiersze: wszystkie rekordy z obu tabel z niezgodnymi komórkami wypełnionymi wartością null |
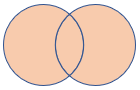
|
| leftsemi | Lewe sprzężenia półsprzężenia Schemat: wszystkie kolumny z lewej tabeli Wiersze: wszystkie rekordy z tabeli po lewej stronie pasujące do rekordów z prawej tabeli |
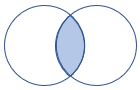
|
leftanti, , antileftantisemi |
Lewy antysprzężenia i częściowo wariant Schemat: wszystkie kolumny z lewej tabeli Wiersze: wszystkie rekordy z lewej tabeli, które nie pasują do rekordów z prawej tabeli |
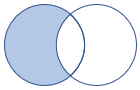
|
| rightsemi | Prawe sprzężenia półsprzężenia Schemat: wszystkie kolumny z prawej tabeli Wiersze: wszystkie rekordy z prawej tabeli pasujące do rekordów z lewej tabeli |
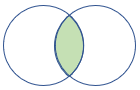
|
rightanti, rightantisemi |
Prawy antysprzężenia i pół-wariant Schemat: wszystkie kolumny z prawej tabeli Wiersze: wszystkie rekordy z prawej tabeli, które nie pasują do rekordów z lewej tabeli |
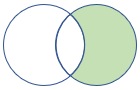
|
Sprzężenia krzyżowe
Język KQL nie zapewnia smaku sprzężenia krzyżowego. Można jednak osiągnąć efekt sprzężenia krzyżowego przy użyciu podejścia opartego na kluczu zastępczym.
W poniższym przykładzie klucz zastępczy jest dodawany do obu tabel, a następnie używany do operacji sprzężenia wewnętrznego, skutecznie osiągając zachowanie podobne do sprzężenia krzyżowego:
X | extend placeholder=1 | join kind=inner (Y | extend placeholder=1) on placeholder
Powiązana zawartość
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla