Samouczek: korzystanie z funkcji agregacji
Funkcje agregacji umożliwiają grupowanie i łączenie danych z wielu wierszy w wartość podsumowania. Wartość podsumowania zależy od wybranej funkcji, na przykład od liczby, wartości maksymalnej lub średniej.
Z tego samouczka dowiesz się, jak wykonywać następujące czynności:
- Używanie operatora podsumowania
- Wizualizowanie wyników zapytania
- Warunkowo zliczaj wiersze
- Grupowanie danych w pojemniki
- Obliczanie wartości min, maksimum, średniej i sumy
- Obliczanie wartości procentowych
- Wyodrębnianie unikatowych wartości
- Dane zasobnika według warunku
- Wykonywanie agregacji w oknie przewijania
W przykładach w tym samouczku użyto StormEvents tabeli, która jest publicznie dostępna w klastrze pomocy. Aby eksplorować własne dane, utwórz własny bezpłatny klaster.
Ten samouczek opiera się na podstawach z pierwszego samouczka — Poznaj typowe operatory.
Wymagania wstępne
- Konto Microsoft lub Microsoft Entra tożsamość użytkownika, aby zalogować się do klastra pomocy
Używanie operatora podsumowania
Operator podsumowania jest niezbędny do przeprowadzania agregacji danych. Operator summarize grupuje wiersze na by podstawie klauzuli , a następnie używa udostępnionej funkcji agregacji, aby połączyć każdą grupę w jednym wierszu.
Znajdź liczbę zdarzeń według stanu przy użyciu summarize funkcji agregacji count .
StormEvents
| summarize TotalStorms = count() by State
Dane wyjściowe
| Stan | TotalStorms |
|---|---|
| TEXAS | 4701 |
| KANSAS | 3166 |
| IOWA | 2337 |
| ILLINOIS | 2022 |
| MISSOURI | 2016 |
| ... | ... |
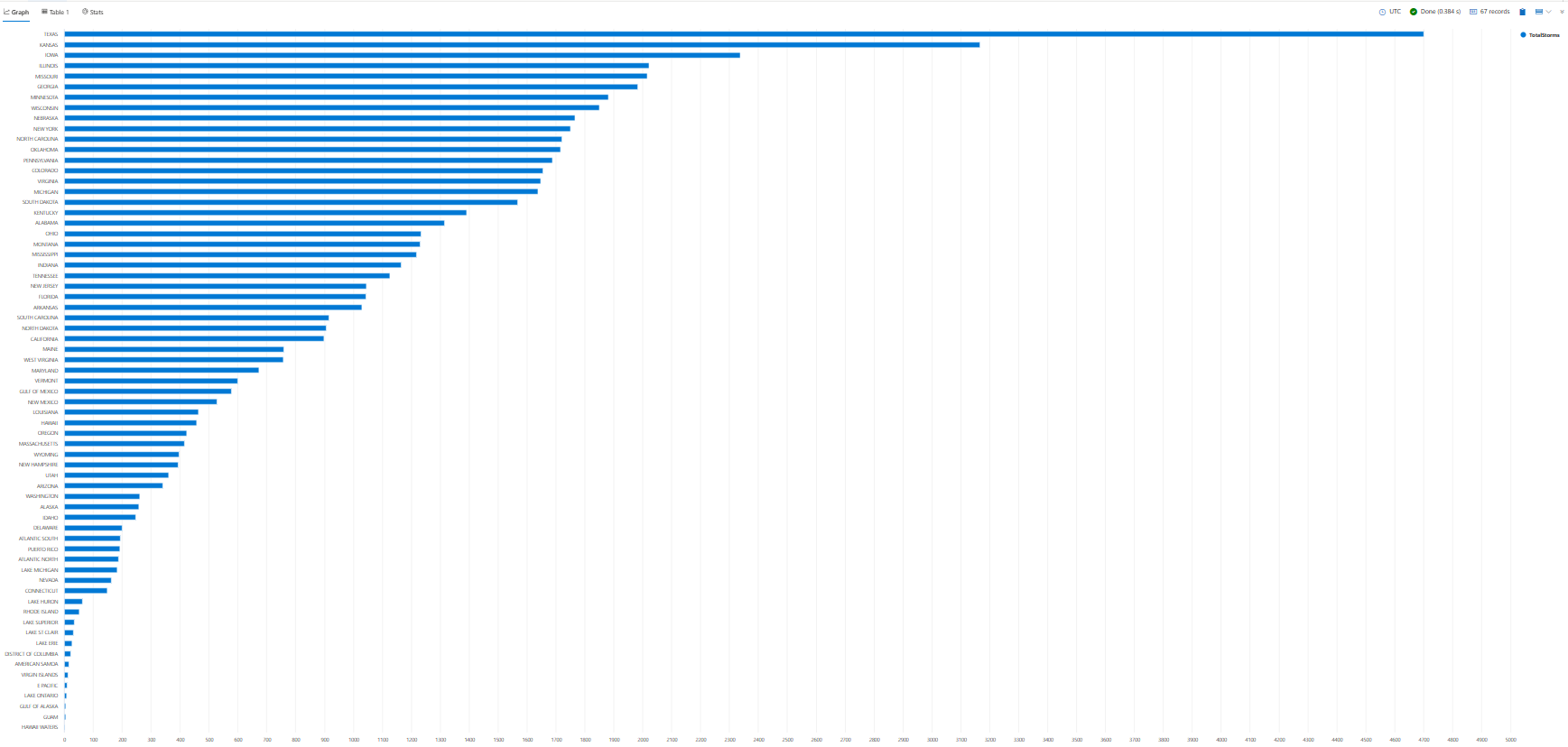
Wizualizowanie wyników zapytania
Wizualizowanie wyników zapytań na wykresie lub grafie może pomóc w identyfikowaniu wzorców, trendów i wartości odstających w danych. Można to zrobić za pomocą operatora renderowania .
W ramach tego samouczka zobaczysz przykłady użycia render do wyświetlania wyników. Na razie użyjemy render polecenia , aby wyświetlić wyniki z poprzedniego zapytania na wykresie słupkowym.
StormEvents
| summarize TotalStorms = count() by State
| render barchart
Warunkowo zliczaj wiersze
Podczas analizowania danych użyj funkcji countif(), aby zliczyć wiersze na podstawie określonego warunku, aby zrozumieć, ile wierszy spełnia podane kryteria.
Poniższe zapytanie używa countif() metody do zliczenia burz, które spowodowały szkody. Następnie zapytanie używa top operatora do filtrowania wyników i wyświetlania stanów z największą ilością uszkodzeń upraw spowodowanych przez burze.
StormEvents
| summarize StormsWithCropDamage = countif(DamageCrops > 0) by State
| top 5 by StormsWithCropDamage
Dane wyjściowe
| Stan | StormsWithCropDamage |
|---|---|
| IOWA | 359 |
| NEBRASKA | 201 |
| MISSISSIPPI | 105 |
| KAROLINA PÓŁNOCNA | 82 |
| MISSOURI | 78 |
Grupowanie danych w pojemniki
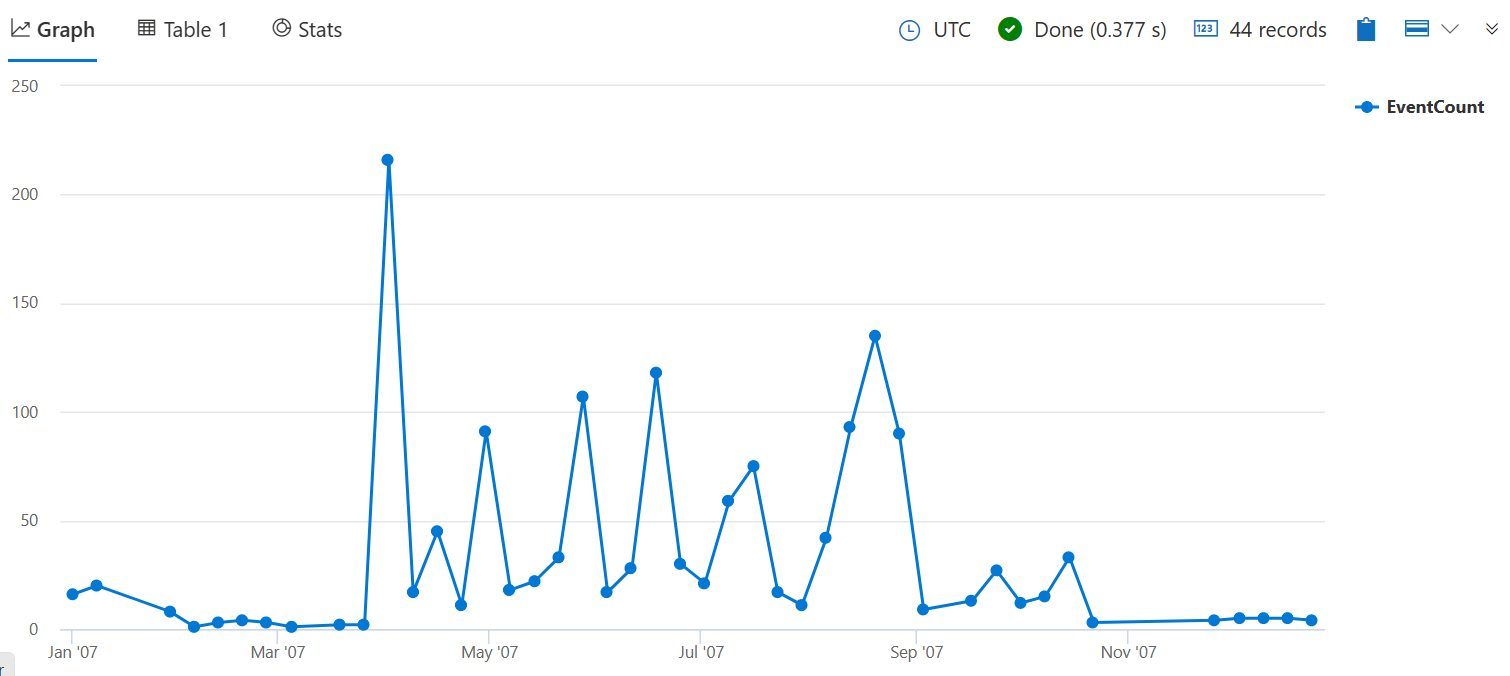
Aby agregować według wartości liczbowych lub czasowych, najpierw należy zgrupować dane w pojemniki przy użyciu funkcji bin(). Użycie bin() może pomóc zrozumieć, w jaki sposób wartości są dystrybuowane w określonym zakresie i dokonać porównań między różnymi okresami.
Poniższe zapytanie zlicza liczbę burz, które spowodowały szkody w uprawach w każdym tygodniu w 2007 roku. Argument 7d reprezentuje tydzień, ponieważ funkcja wymaga prawidłowej wartości przedziału czasu .
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize EventCount = count() by bin(StartTime, 7d)
Dane wyjściowe
| StartTime | EventCount |
|---|---|
| 2007-01-01T00:00:00Z | 16 |
| 2007-01-08T00:00:00Z | 20 |
| 2007-01-29T00:00:00Z | 8 |
| 2007-02-05T00:00:00Z | 1 |
| 2007-02-12T00:00:00Z | 3 |
| ... | ... |
Dodaj | render timechart element na końcu zapytania, aby zwizualizować wyniki.
Uwaga
bin() funkcja jest podobna floor() do funkcji w innych językach programowania. Zmniejsza każdą wartość do najbliższej wielokrotności modułu, który podajesz i umożliwia summarize przypisanie wierszy do grup.
Obliczanie wartości min, maksimum, średniej i sumy
Aby dowiedzieć się więcej o typach burz, które powodują szkody w uprawach, oblicz wartości min(), max()i avg() szkód w uprawach dla każdego typu zdarzenia, a następnie posortuj wynik według średniego uszkodzenia.
Należy pamiętać, że w jednym summarize operatorze można użyć wielu funkcji agregacji, aby utworzyć kilka kolumn obliczeniowych.
StormEvents
| where DamageCrops > 0
| summarize
MaxCropDamage=max(DamageCrops),
MinCropDamage=min(DamageCrops),
AvgCropDamage=avg(DamageCrops)
by EventType
| sort by AvgCropDamage
Dane wyjściowe
| Typ zdarzenia | MaxCropDamage | MinCropDamage | AvgCropDamage |
|---|---|---|---|
| Mróz/zamrożenie | 568600000 | 3000 | 9106087.5954198465 |
| Pożary lasów | 21000000 | 10 000 | 7268333.333333333 |
| Susza | 700000000 | 2000 | 6763977.8761061952 |
| Powódź | 500000000 | 1000 | 4844925.23364486 |
| Burza z piorunami | 22000000 | 100 | 920328.36538461538 |
| ... | ... | ... | ... |
Wyniki poprzedniego zapytania wskazują, że zdarzenia Frost/Freeze spowodowały średnio największe szkody w uprawach. Jednak zapytanie bin() wykazało, że zdarzenia z uszkodzeniem upraw miały miejsce głównie w miesiącach letnich.
Użyj funkcji sum(), aby sprawdzić łączną liczbę uszkodzonych upraw zamiast ilości zdarzeń, które spowodowały pewne szkody, zgodnie z count() poprzednim zapytaniem bin().
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize CropDamage = sum(DamageCrops) by bin(StartTime, 7d)
| render timechart
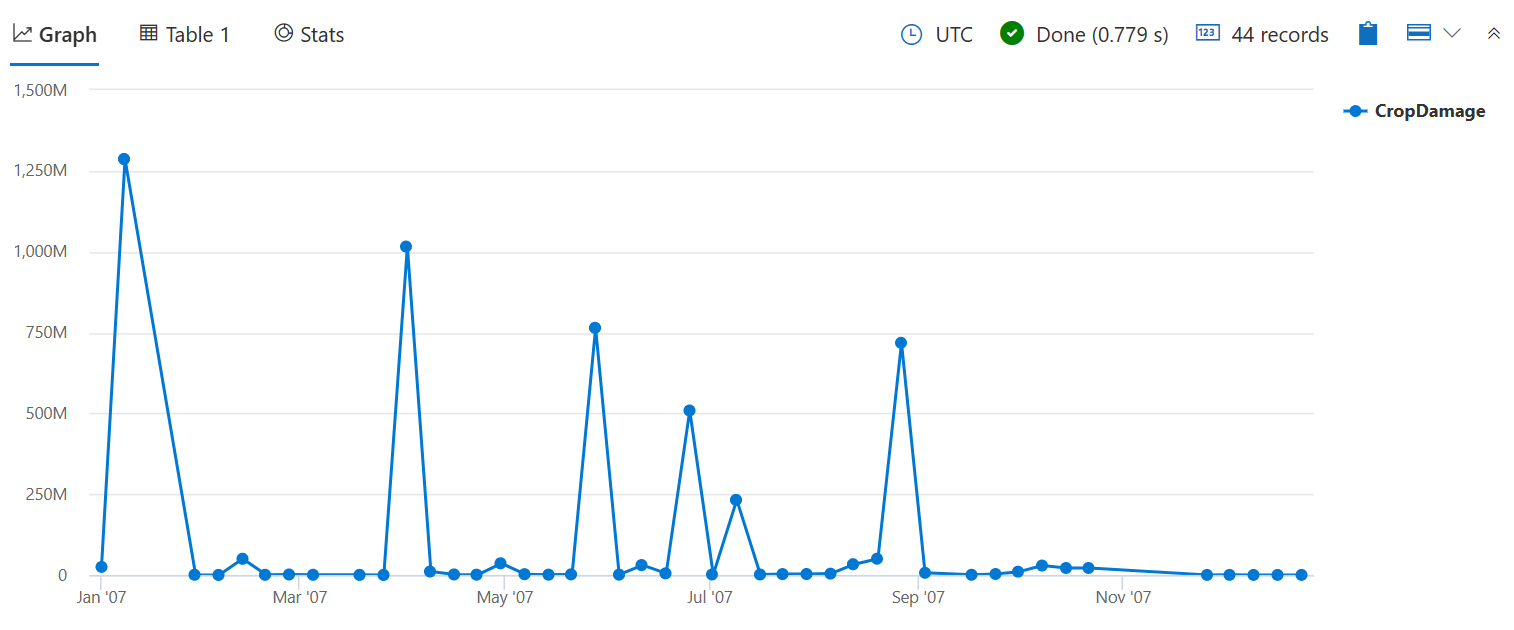
Teraz można zobaczyć szczyt szkód upraw w styczniu, który prawdopodobnie był spowodowany Frost / Freeze.
Porada
Użyj minif(), maxif(), avgif()i sumif(), aby wykonać agregacje warunkowe, tak jak w sekcji warunkowej liczby wierszy .
Obliczanie wartości procentowych
Obliczanie wartości procentowych może pomóc w zrozumieniu rozkładu i proporcji różnych wartości w danych. W tej sekcji opisano dwie typowe metody obliczania wartości procentowych przy użyciu język zapytań Kusto (KQL).
Obliczanie wartości procentowej na podstawie dwóch kolumn
Użyj funkcji count() i countif , aby znaleźć procent zdarzeń burzy, które spowodowały szkody w uprawach w każdym stanie. Najpierw zlicz łączną liczbę burz w każdym stanie. Następnie zlicz liczbę burz, które spowodowały szkody w uprawach w każdym stanie.
Następnie użyj rozszerzenia , aby obliczyć wartość procentową między dwie kolumny, dzieląc liczbę burz z uszkodzeniami upraw przez łączną liczbę burz i mnożąc przez 100.
Aby upewnić się, że uzyskasz wynik dziesiętny, przed wykonaniem dzielenia użyj funkcji todouble(), aby przekonwertować co najmniej jedną z wartości liczb całkowitych na wartość podwójną.
StormEvents
| summarize
TotalStormsInState = count(),
StormsWithCropDamage = countif(DamageCrops > 0)
by State
| extend PercentWithCropDamage =
round((todouble(StormsWithCropDamage) / TotalStormsInState * 100), 2)
| sort by StormsWithCropDamage
Dane wyjściowe
| Stan | TotalStormsInState | StormsWithCropDamage | PercentWithCropDamage |
|---|---|---|---|
| IOWA | 2337 | 359 | 15.36 |
| NEBRASKA | 1766 | 201 | 11.38 |
| MISSISSIPPI | 1218 | 105 | 8.62 |
| KAROLINA PÓŁNOCNA | 1721 | 82 | 4.76 |
| MISSOURI | 2016 | 78 | 3.87 |
| ... | ... | ... | ... |
Uwaga
Podczas obliczania wartości procentowych przekonwertuj co najmniej jedną z wartości całkowitych w dzieleniu na wartość todouble() lub toreal(). Zapewni to, że nie otrzymasz obcięć wyników z powodu dzielenia liczb całkowitych. Aby uzyskać więcej informacji, zobacz Reguły typów dla operacji arytmetycznych.
Obliczanie wartości procentowej na podstawie rozmiaru tabeli
Aby porównać liczbę burz według typu zdarzenia do całkowitej liczby burz w bazie danych, najpierw zapisz łączną liczbę burz w bazie danych jako zmienną. Instrukcje Let służą do definiowania zmiennych w zapytaniu.
Ponieważ instrukcje wyrażenia tabelarycznego zwracają wyniki tabelaryczne, użyj funkcji toscalar(), aby przekonwertować wynik count() tabelaryczny funkcji na wartość skalarną. Następnie wartość liczbowa może być używana w obliczeniu procentowym.
let TotalStorms = toscalar(StormEvents | summarize count());
StormEvents
| summarize EventCount = count() by EventType
| project EventType, EventCount, Percentage = todouble(EventCount) / TotalStorms * 100.0
Dane wyjściowe
| Typ zdarzenia | EventCount | Procent |
|---|---|---|
| Burza z piorunami | 13015 | 22.034673077574237 |
| Grad | 12711 | 21.519994582331627 |
| Powodzia błyskawiczna | 3688 | 6.2438627975485055 |
| Susza | 3616 | 6.1219652592015716 |
| Pogoda zimowa | 3349 | 5.669928554498358 |
| ... | ... | ... |
Wyodrębnianie unikatowych wartości
Użyj make_set(), aby przekształcić wybór wierszy w tabeli w tablicę unikatowych wartości.
Poniższe zapytanie używa make_set() metody do utworzenia tablicy typów zdarzeń, które powodują śmierć w każdym stanie. Tabela wynikowa jest następnie sortowana według liczby typów burzy w każdej tablicy.
StormEvents
| where DeathsDirect > 0 or DeathsIndirect > 0
| summarize StormTypesWithDeaths = make_set(EventType) by State
| project State, StormTypesWithDeaths
| sort by array_length(StormTypesWithDeaths)
Dane wyjściowe
| Stan | StormTypesWithDeaths |
|---|---|
| KALIFORNII | ["Thunderstorm Wind","High Surf","Cold/Wind Chill","Strong Wind","Rip Current","Heat","Excessive Heat","Wildfire","Dust Storm","Astronomiczna przypływ","Gęsta mgła","Winter Weather"] |
| TEXAS | ["Flash Flood","Thunderstorm Wind","Tornado","Lightning","Flood","Ice Storm","Winter Weather","Rip Current","Excessive Heat","Dense Fog","Hurricane (Typhoon)","Cold/Wind Chill"] |
| OKLAHOMA | ["Flash Flood","Tornado","Cold/Wind Chill","Winter Storm","Heavy Snow","Excessive Heat","Heat","Ice Storm","Winter Weather","Dense Fog"] |
| NEW YORK | ["Flood","Lightning","Thunderstorm Wind","Flash Flood","Winter Weather","Ice Storm","Extreme Cold/Wind Chill","Winter Storm","Heavy Snow"] |
| KANSAS | ["Burza Wiatr","Heavy Rain","Tornado","Flood","Flash Flood","Lightning","Heavy Snow","Winter Weather","Blizzard"] |
| ... | ... |
Dane zasobnika według warunku
Funkcja case() grupuje dane w zasobnikach na podstawie określonych warunków. Funkcja zwraca odpowiednie wyrażenie wyniku dla pierwszego spełnionego predykatu lub ostatniego wyrażenia innego, jeśli żaden z predykatów nie jest spełniony.
W tym przykładzie grupy są określane na podstawie liczby obrażeń związanych z burzą, które ich obywatele ponieśli.
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| sort by State asc
Dane wyjściowe
| Stan | InjuriesCount | UrazyBucket |
|---|---|---|
| ALABAMA | 494 | Duży |
| ALASKA | 0 | Brak obrażeń |
| AMERYKAŃSKIE SAMOA | 0 | Brak obrażeń |
| ARIZONA | 6 | Mały |
| ARKANSAS | 54 | Duży |
| PÓŁNOC ATLANTYCKIA | 15 | Śred. |
| ... | ... | ... |
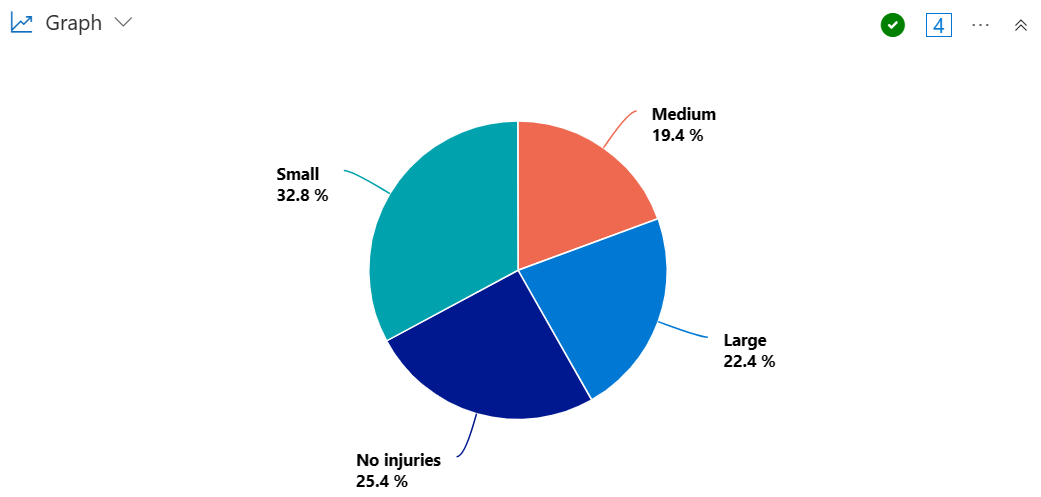
Utwórz wykres kołowy, aby zwizualizować proporcje stanów, w których wystąpiły burze, co spowodowało duże, średnie lub małe obrażenia.
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| summarize InjuryBucketByState=count() by InjuriesBucket
| render piechart
Wykonywanie agregacji w oknie przesuwanym
W poniższym przykładzie pokazano, jak podsumować kolumny przy użyciu okna przesuwanego.
Zapytanie oblicza minimalną, maksymalną i średnią szkodę właściwości tornada, powodzi i pożarów przy użyciu okna przesuwanego w ciągu siedmiu dni. Każdy rekord w zestawie wyników agreguje poprzednie siedem dni, a wyniki zawierają rekord dziennie w okresie analizy.
Oto szczegółowe wyjaśnienie zapytania:
- Należy zapisać każdy rekord do jednego dnia względem
windowStartelementu . - Dodaj siedem dni do wartości pojemnika, aby ustawić koniec zakresu dla każdego rekordu. Jeśli wartość jest poza zakresem
windowStartiwindowEnd, dostosuj odpowiednio wartość. - Utwórz tablicę z siedmiu dni dla każdego rekordu, począwszy od bieżącego dnia rekordu.
- Rozwiń tablicę z kroku 3 z rozszerzeniem mv, aby zduplikować każdy rekord do siedmiu rekordów z interwałami jednego dnia między nimi.
- Wykonaj agregacje dla każdego dnia. Ze względu na krok 4 ten krok faktycznie podsumowuje poprzednie siedem dni.
- Wyklucz pierwsze siedem dni z końcowego wyniku, ponieważ nie ma dla nich siedmiodniowego okresu wyszukiwania.
let windowStart = datetime(2007-07-01);
let windowEnd = windowStart + 13d;
StormEvents
| where EventType in ("Tornado", "Flood", "Wildfire")
| extend bin = bin_at(startofday(StartTime), 1d, windowStart) // 1
| extend endRange = iff(bin + 7d > windowEnd, windowEnd,
iff(bin + 7d - 1d < windowStart, windowStart,
iff(bin + 7d - 1d < bin, bin, bin + 7d - 1d))) // 2
| extend range = range(bin, endRange, 1d) // 3
| mv-expand range to typeof(datetime) // 4
| summarize min(DamageProperty), max(DamageProperty), round(avg(DamageProperty)) by Timestamp=bin_at(range, 1d, windowStart), EventType // 5
| where Timestamp >= windowStart + 7d; // 6
Dane wyjściowe
Poniższa tabela wyników jest obcięta. Aby wyświetlić pełne dane wyjściowe, uruchom zapytanie.
| Znacznik czasu | Typ zdarzenia | min_DamageProperty | max_DamageProperty | avg_DamageProperty |
|---|---|---|---|---|
| 2007-07-08T00:00:00Z | Tornado | 0 | 30000 | 6905 |
| 2007-07-08T00:00:00Z | Powódź | 0 | 200000 | 9261 |
| 2007-07-08T00:00:00Z | Pożary lasów | 0 | 200000 | 14033 |
| 2007-07-09T00:00:00Z | Tornado | 0 | 100000 | 14783 |
| 2007-07-09T00:00:00Z | Powódź | 0 | 200000 | 12529 |
| 2007-07-09T00:00:00Z | Pożary lasów | 0 | 200000 | 14033 |
| 2007-07-10T00:00:00Z | Tornado | 0 | 100000 | 31400 |
| 2007-07-10T00:00:00Z | Powódź | 0 | 200000 | 12263 |
| 2007-07-10T00:00:00Z | Pożary lasów | 0 | 200000 | 11694 |
| ... | ... | ... |
Następny krok
Teraz, gdy znasz już typowe operatory zapytań i funkcje agregacji, przejdź do następnego samouczka, aby dowiedzieć się, jak łączyć dane z wielu tabel.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla