Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
Ciągła integracja to praktyka testowania każdej zmiany wprowadzonej w bazie kodu automatycznie i jak najszybciej. Ciągłe dostarczanie następuje po testach realizowanych w ramach ciągłej integracji i wdraża zmiany do systemu przejściowego lub produkcyjnego.
W Azure Data Factory ciągła integracja i ciągłe dostarczanie (CI/CD) oznacza przenoszenie potoków usługi Data Factory z jednego środowiska (programowanie, testowanie, produkcja) do innego. Azure Data Factory używa szablonów Azure Resource Manager do przechowywania konfiguracji różnych jednostek usługi ADF (potoków, zestawów danych, przepływów danych itd.). Istnieją dwie sugerowane metody przenoszenia fabryki danych do innego środowiska:
- Automatyczne wdrażanie przy użyciu integracji usługi Data Factory z Azure Pipelines
- Ręcznie przekaż szablon Resource Manager za pomocą integracji interfejsu użytkownika usługi Data Factory z Azure Resource Manager.
Uwaga
Zalecamy użycie modułu Azure Az programu PowerShell do interakcji z Azure. Aby rozpocząć, zobacz Install Azure PowerShell. Aby dowiedzieć się, jak przeprowadzić migrację do modułu Az programu PowerShell, zobacz Migrate Azure PowerShell z modułu AzureRM do modułu Az.
Proces ciągłej integracji i dostarczania/deploymentu
Uwaga
Aby uzyskać więcej informacji, zobacz Ulepszenia ciągłego wdrażania.
Poniżej przedstawiono przykładowy przegląd cyklu życia CI/CD w fabryce danych Azure skonfigurowanej z użyciem Azure Repos Git. Aby uzyskać więcej informacji na temat konfigurowania repozytorium Git, zobacz Kontrola źródła w Azure Data Factory.
Utworzono i skonfigurowano fabrykę danych deweloperskich przy użyciu usługi Azure Repos Git. Wszyscy deweloperzy powinni mieć uprawnienia do tworzenia zasobów usługi Data Factory, takich jak potoki i zestawy danych.
Deweloper tworzy gałąź funkcji, aby wprowadzić zmianę. Podpisane zatwierdzenia nie są obsługiwane w usłudze Data Factory. Debugują przebiegi potoku przy użyciu najnowszych zmian. Aby uzyskać więcej informacji na temat debugowania uruchomienia potoku, zobacz Iteracyjne programowanie i debugowanie przy użyciu Azure Data Factory.
Gdy deweloper jest zadowolony ze swoich zmian, tworzy żądanie połączenia z gałęzi funkcji do gałęzi głównej lub współpracy, aby uzyskać zmiany przeglądane przez rówieśników.
Po zatwierdzeniu żądania ściągnięcia i scaleniu zmian w gałęzi głównej zmiany zostaną opublikowane w fabryce programowania.
Gdy zespół jest gotowy do wdrożenia zmian w fabryce testowej lub UAT (testowania akceptacyjnego przez użytkowników), zespół przechodzi do wersji udostępnienia w Azure Pipelines i wdraża żądaną wersję fabryki deweloperskiej do UAT. To wdrożenie ma miejsce w ramach zadania Azure Pipelines i używa parametrów szablonu Resource Manager do zastosowania odpowiedniej konfiguracji.
Po zweryfikowaniu zmian w fabryce testowej, wdróż je w fabryce produkcyjnej, korzystając z kolejnego zadania w ramach wydania potoków.
Uwaga
Tylko fabryka rozwoju jest skojarzona z repozytorium git. Fabryki testowe i produkcyjne nie powinny mieć skojarzonego z nimi repozytorium Git i powinny być aktualizowane tylko za pośrednictwem pipeline Azure DevOps lub szablonu zarządzania zasobami Azure.
Na poniższej ilustracji przedstawiono różne kroki tego cyklu życia.
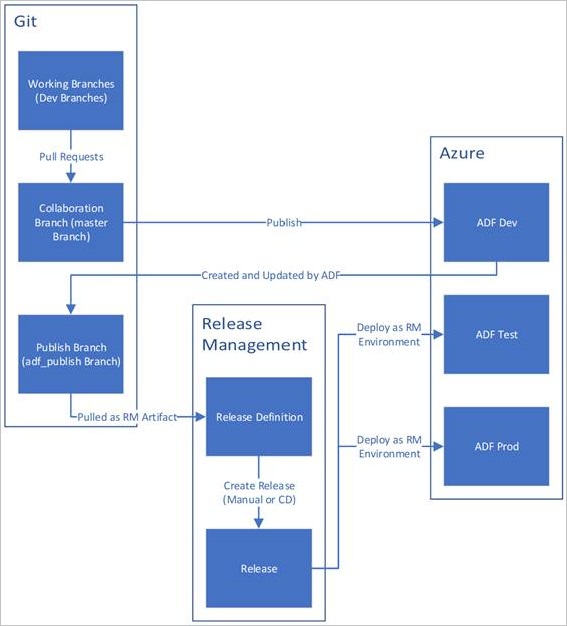
Najlepsze rozwiązania dotyczące ciągłej integracji/ciągłego wdrażania
Jeśli korzystasz z integracji z Git w fabryce danych (Data Factory) i masz potok CI/CD, który przenosi zmiany ze środowiska deweloperskiego do testowego, a następnie do produkcyjnego, zalecamy następujące najlepsze praktyki:
Integracja z usługą Git. Skonfiguruj tylko swoją deweloperską fabrykę danych z integracją Git. Zmiany wdrażane do środowiska testowego i produkcyjnego są realizowane za pośrednictwem CI/CD (ciągła integracja/ciągłe wdrażanie) i nie wymagają integracji z Git.
Skrypt przed wdrożeniem i po wdrożeniu. Przed wykonaniem kroku wdrażania Resource Manager w ramach CI/CD, należy wykonać pewne zadania, takie jak zatrzymanie i restart wyzwalaczy oraz wyczyszczenie. Zalecamy używanie skryptów programu PowerShell przed i po zadaniu wdrożenia. Aby uzyskać więcej informacji, zobacz Aktualizowanie aktywnych wyzwalaczy. Zespół fabryki danych udostępnił skrypt do użycia w dolnej części tej strony.
Uwaga
Użyj PrePostDeploymentScript.Ver2.ps1 jeśli chcesz wyłączyć lub włączyć tylko te wyzwalacze, które zostały zmodyfikowane, zamiast wyłączać lub włączać wszystkie wyzwalacze podczas procesów CI/CD (ciągłej integracji i ciągłego wdrażania).
Ostrzeżenie
Pamiętaj, aby uruchomić skrypt za pomocą programu PowerShell Core w zadaniu ADO.
Ostrzeżenie
Jeśli nie używasz najnowszych wersji modułu Programu PowerShell i usługi Data Factory, podczas uruchamiania poleceń mogą wystąpić błędy deserializacji.
Środowiska uruchomieniowe integracji i ich udostępnianie. Środowiska czasu wykonywania integracji nie zmieniają się często i są podobne na wszystkich etapach CI/CD. Dlatego Data Factory oczekuje, że w każdym etapie CI/CD będziesz mieć tę samą nazwę, typ i podtyp środowiska uruchomieniowego integracji. Jeśli chcesz udostępnić środowiska Integration Runtime na wszystkich etapach, rozważ użycie specjalnej fabryki tylko do przechowywania wspólnych środowisk Integration Runtime. Możesz użyć tej udostępnionej fabryki we wszystkich środowiskach jako połączonego typu środowiska Integration Runtime.
Uwaga
Udostępnianie środowiska Integration Runtime jest dostępne tylko dla samodzielnie hostowanego środowiska Integration Runtime. Azure SSIS Integration Runtime nie obsługują udostępniania.
Zarządzane wdrożenie prywatnego punktu końcowego. Jeśli prywatny punkt końcowy już istnieje w fabryce i próbujesz wdrożyć szablon usługi ARM zawierający prywatny punkt końcowy o tej samej nazwie, ale z zmodyfikowanymi właściwościami, wdrożenie zakończy się niepowodzeniem. Innymi słowy, można pomyślnie wdrożyć prywatny punkt końcowy, o ile ma on te same właściwości co ten, który już istnieje w fabryce. Jeśli jakakolwiek właściwość różni się między środowiskami, można ją zastąpić, parametryzując daną właściwość i podając odpowiednią wartość podczas wdrażania.
Key Vault. W przypadku korzystania z połączonych usług, których informacje o połączeniu są przechowywane w Azure Key Vault, zaleca się przechowywanie oddzielnych magazynów kluczy w różnych środowiskach. Można również skonfigurować oddzielne poziomy uprawnień dla każdego magazynu kluczy. Na przykład, możesz nie chcieć, aby członkowie zespołu mieli uprawnienia do tajemnic produkcyjnych. Jeśli zastosujesz tę metodę, zalecamy zachowanie tych samych tajnych nazw we wszystkich etapach. Jeśli zachowasz te same nazwy wpisów tajnych, nie musisz parametryzować każdego łańcucha połączenia w środowiskach ciągłej integracji/ciągłego wdrażania, ponieważ jedyną rzeczą, która się zmienia, jest nazwa magazynu kluczy, co stanowi osobny parametr.
Nazewnictwo zasobów. Ze względu na ograniczenia szablonu usługi ARM problemy z wdrażaniem mogą wystąpić, jeśli zasoby zawierają spacje w nazwie. Zespół Azure Data Factory zaleca używanie znaków "_" lub "-" zamiast spacji dla zasobów. Na przykład "Pipeline_1" byłby preferowaną wersją w porównaniu do "Pipeline 1".
Zmienianie repozytorium. Usługa ADF automatycznie zarządza zawartością repozytorium GIT. Zmiana lub dodanie ręcznie niepowiązanych plików lub folderu w dowolnym miejscu w folderze danych repozytorium Git usługi ADF może spowodować błędy ładowania zasobów. Na przykład obecność plików .bak może spowodować błąd w procesie ciągłej integracji i wdrażania (CI/CD) w Azure Data Factory, dlatego należy je usunąć, aby można było załadować ADF.
Kontrola ekspozycji i flagi funkcjonalności. Podczas pracy zespołowej zdarzają się sytuacje, gdzie można scalić zmiany, ale nie chcesz, aby były wdrażane w środowiskach z wyższymi poziomami uprawnień, takich jak PROD i QA. Aby obsłużyć ten scenariusz, zespół usługi ADF zaleca koncepcję DevOps polegającą na używaniu flag funkcji. W usłudze ADF można połączyć globalne parametry i aktywność warunku if, aby ukryć zestawy logiki na podstawie tych flag środowiska.
Aby dowiedzieć się, jak skonfigurować flagę funkcji, zobacz poniższy samouczek wideo:
Nieobsługiwane funkcje
Zgodnie z projektem usługa Data Factory nie zezwala na wybieranie zatwierdzeń ani selektywnego publikowania zasobów. Publikowanie będzie obejmować wszystkie zmiany wprowadzone w fabryce danych.
- Jednostki fabryki danych zależą od siebie. Na przykład wyzwalacze zależą od rurociągów danych, a rurociągi danych zależą od zestawów danych i innych rurociągów danych. Selektywne publikowanie podzestawu zasobów może prowadzić do nieoczekiwanych zachowań i błędów.
- W rzadkich przypadkach, gdy potrzebujesz selektywnego publikowania, rozważ użycie hotfixa. Aby uzyskać więcej informacji, zobacz temat Środowisko produkcyjne Hotfix.
Zespół Azure Data Factory nie zaleca przypisywania kontrolek RBAC Azure do poszczególnych jednostek (potoków, zestawów danych itp.) w fabryce danych. Jeśli na przykład deweloper ma dostęp do potoku lub zestawu danych, powinien mieć dostęp do wszystkich potoków lub zestawów danych w fabryce danych. Jeśli uważasz, że musisz zaimplementować wiele ról Azure w fabryce danych, zapoznaj się z wdrażaniem drugiej fabryki danych.
Nie można publikować z gałęzi prywatnych.
Obecnie nie można hostować projektów w usłudze Bitbucket.
Obecnie nie można eksportować i importować alertów i macierzy jako parametrów.
Częściowe szablony usługi Azure Resource Manager w gałęzi przeznaczonej do publikowania nie będą już obsługiwane od 1 listopada 2021 r. Jeśli projekt korzystał z tej funkcji, zmień na obsługiwany mechanizm wdrożeń, używając:
ARMTemplateForFactory.jsonlublinkedTemplatesplików.
Powiązana zawartość
- Ulepszenia ciągłego wdrażania
- Automatyzuj ciągłą integrację za pomocą wydań Azure Pipelines
- Ręcznie promuj szablon Menedżera zasobów do każdego środowiska
- Użyj parametry niestandardowe przy użyciu szablonu Resource Manager
- szablony Linked Resource Manager
- Używanie środowiska produkcyjnego z poprawkami doraźnymi
- Przykładowy skrypt wstępny i po wdrożeniu