Używanie parametrów niestandardowych w szablonach usługi Resource Manager
DOTYCZY: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Jeśli wystąpienie programistyczne ma skojarzone repozytorium Git, możesz zastąpić domyślne parametry szablonu usługi Resource Manager wygenerowanego przez opublikowanie lub wyeksportowanie szablonu. W następujących scenariuszach warto zastąpić domyślną konfigurację parametrów usługi Resource Manager:
Używasz automatycznej ciągłej integracji/ciągłego wdrażania i chcesz zmienić niektóre właściwości podczas wdrażania usługi Resource Manager, ale właściwości nie są domyślnie sparametryzowane.
Fabryka jest tak duża, że domyślny szablon usługi Resource Manager jest nieprawidłowy, ponieważ ma więcej niż maksymalne dozwolone parametry (256).
Aby obsłużyć limit parametru niestandardowego 256, dostępne są trzy opcje:
- Użyj pliku parametrów niestandardowych i usuń właściwości, które nie wymagają parametryzacji, czyli właściwości, które mogą zachować wartość domyślną, a tym samym zmniejszyć liczbę parametrów.
- Logika refaktoryzacji w przepływie danych w celu zmniejszenia parametrów, na przykład parametry potoku mają tę samą wartość. Zamiast tego można po prostu użyć parametrów globalnych.
- Podziel jedną fabrykę danych na wiele fabryk danych.
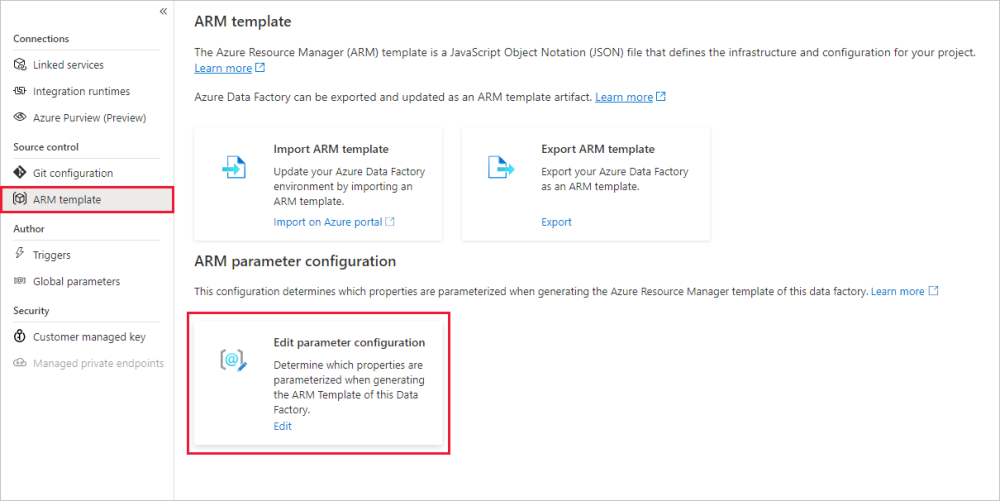
Aby zastąpić domyślną konfigurację parametrów usługi Resource Manager, przejdź do sekcji Zarządzanie centrum i wybierz szablon usługi ARM w sekcji "Kontrola źródła". W sekcji Konfiguracja parametrów usługi ARM wybierz pozycję Edytuj ikonę w obszarze "Edytuj konfigurację parametru", aby otworzyć edytor kodu konfiguracji parametru usługi Resource Manager.
Uwaga
Konfiguracja parametrów usługi ARM jest włączona tylko w trybie GIT. Obecnie jest on wyłączony w trybie "tryb na żywo" lub "Fabryka danych".
Utworzenie niestandardowej konfiguracji parametrów usługi Resource Manager powoduje utworzenie pliku o nazwie arm-template-parameters-definition.json w folderze głównym gałęzi git. Musisz użyć tej dokładnej nazwy pliku.
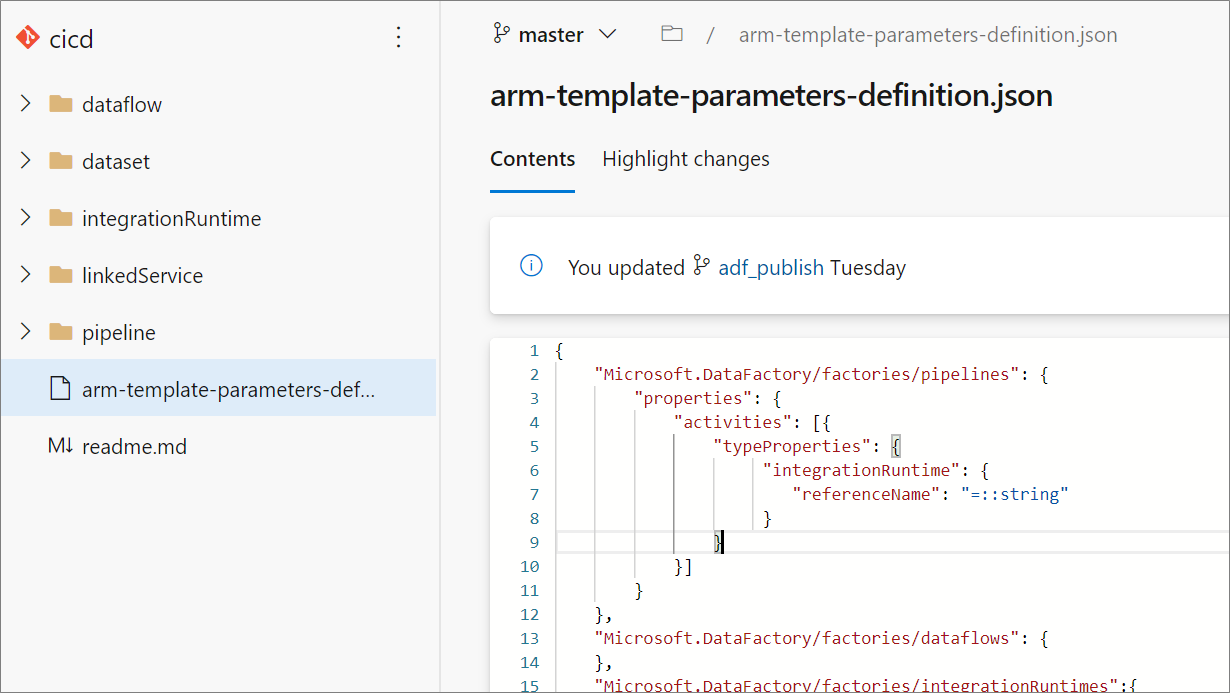
Podczas publikowania z gałęzi współpracy usługa Data Factory odczytuje ten plik i użyje jego konfiguracji, aby wygenerować właściwości, które są sparametryzowane. Jeśli nie znaleziono pliku, zostanie użyty domyślny szablon.
Podczas eksportowania szablonu usługi Resource Manager usługa Data Factory odczytuje ten plik z niezależnie od gałęzi, nad którą aktualnie pracujesz, a nie z gałęzi współpracy. Możesz utworzyć lub edytować plik z gałęzi prywatnej, w której można przetestować zmiany, wybierając pozycję Eksportuj szablon usługi ARM w interfejsie użytkownika. Następnie możesz scalić plik z gałęzią współpracy.
Uwaga
Niestandardowa konfiguracja parametru usługi Resource Manager nie zmienia limitu parametrów szablonu usługi ARM 256. Umożliwia wybranie i zmniejszenie liczby sparametryzowanych właściwości.
Składnia parametrów niestandardowych
Poniżej przedstawiono kilka wskazówek, które należy wykonać podczas tworzenia pliku parametrów niestandardowych, arm-template-parameters-definition.json. Plik składa się z sekcji dla każdego typu jednostki: wyzwalacza, potoku, połączonej usługi, zestawu danych, środowiska Integration Runtime i przepływu danych.
- Wprowadź ścieżkę właściwości pod odpowiednim typem jednostki.
- Ustawienie nazwy właściwości w celu
*wskazania, że chcesz sparametryzować wszystkie właściwości pod nim (tylko w dół do pierwszego poziomu, a nie rekursywnie). Można również podać wyjątki dla tej konfiguracji. - Ustawienie wartości właściwości jako ciągu wskazuje, że chcesz sparametryzować właściwość. Użyj formatu
<action>:<name>:<stype>.-
<action>może być jednym z następujących znaków:-
=oznacza zachowanie bieżącej wartości jako wartości domyślnej parametru. -
-oznacza, że wartość domyślna parametru nie jest zachowywana. -
|jest specjalnym przypadkiem dla wpisów tajnych z usługi Azure Key Vault dla parametry połączenia lub kluczy.
-
-
<name>to nazwa parametru. Jeśli jest ona pusta, przyjmuje nazwę właściwości. Jeśli wartość zaczyna się od-znaku, nazwa zostanie skrócona. Na przykładAzureStorage1_properties_typeProperties_connectionStringzostanie skrócony doAzureStorage1_connectionString. -
<stype>jest typem parametru. Jeśli<stype>wartość jest pusta, domyślnym typem jeststring. Obsługiwane wartości:string, ,securestring,boolint,objectsecureobject, iarray.
-
- Określenie tablicy w pliku definicji wskazuje, że zgodna właściwość w szablonie jest tablicą. Usługa Data Factory iteruje wszystkie obiekty w tablicy przy użyciu definicji określonej w obiekcie integration runtime tablicy. Drugi obiekt, ciąg, staje się nazwą właściwości, która jest używana jako nazwa parametru dla każdej iteracji.
- Definicja nie może być specyficzna dla wystąpienia zasobu. Każda definicja ma zastosowanie do wszystkich zasobów tego typu.
- Domyślnie wszystkie bezpieczne ciągi, takie jak wpisy tajne usługi Key Vault, i bezpieczne ciągi, takie jak parametry połączenia, klucze i tokeny, są sparametryzowane.
Przykładowy szablon parametryzacji
Oto przykład konfiguracji parametrów usługi Resource Manager. Zawiera przykłady wielu możliwych użycia, w tym parametryzacja zagnieżdżonych działań w potoku i zmiana wartości domyślnej połączonej parametru usługi.
{
"Microsoft.DataFactory/factories/pipelines": {
"properties": {
"activities": [{
"typeProperties": {
"waitTimeInSeconds": "-::int",
"headers": "=::object",
"activities": [
{
"typeProperties": {
"url": "-:-webUrl:string"
}
}
]
}
}]
}
},
"Microsoft.DataFactory/factories/integrationRuntimes": {
"properties": {
"typeProperties": {
"*": "="
}
}
},
"Microsoft.DataFactory/factories/triggers": {
"properties": {
"typeProperties": {
"recurrence": {
"*": "=",
"interval": "=:triggerSuffix:int",
"frequency": "=:-freq"
},
"maxConcurrency": "="
}
}
},
"Microsoft.DataFactory/factories/linkedServices": {
"*": {
"properties": {
"typeProperties": {
"accountName": "=",
"username": "=",
"connectionString": "|:-connectionString:secureString",
"secretAccessKey": "|"
}
}
},
"AzureDataLakeStore": {
"properties": {
"typeProperties": {
"dataLakeStoreUri": "="
}
}
},
"AzureKeyVault": {
"properties": {
"typeProperties": {
"baseUrl": "|:baseUrl:secureString"
},
"parameters": {
"KeyVaultURL": {
"type": "=",
"defaultValue": "|:defaultValue:secureString"
}
}
}
}
},
"Microsoft.DataFactory/factories/datasets": {
"*": {
"properties": {
"typeProperties": {
"folderPath": "=",
"fileName": "="
}
}
}
},
"Microsoft.DataFactory/factories/credentials" : {
"properties": {
"typeProperties": {
"resourceId": "="
}
}
}
}
Poniżej przedstawiono wyjaśnienie sposobu konstruowania poprzedniego szablonu podzielonego według typu zasobu.
Pipelines
- Każda właściwość w ścieżce
activities/typeProperties/waitTimeInSecondsjest sparametryzowana. Każde działanie w potoku, które ma właściwość na poziomie kodu o nazwiewaitTimeInSeconds(na przykładWaitdziałanie) jest sparametryzowane jako liczba, z nazwą domyślną. Nie będzie jednak mieć wartości domyślnej w szablonie usługi Resource Manager. Jest to obowiązkowe dane wejściowe podczas wdrażania usługi Resource Manager. - Podobnie właściwość o nazwie
headers(na przykład w działaniu) jest sparametryzowana z typemobjectWeb(JObject). Ma wartość domyślną, która jest taka sama jak wartość fabryki źródłowej.
IntegrationRuntimes
- Wszystkie właściwości w ścieżce
typePropertiessą sparametryzowane przy użyciu odpowiednich wartości domyślnych. Na przykład istnieją dwie właściwości w obszarzeIntegrationRuntimeswłaściwości typu:computePropertiesissisProperties. Oba typy właściwości są tworzone z odpowiednimi wartościami domyślnymi i typami (Object).
Wyzwalacze
- W obszarze
typePropertiesparametrów są sparametryzowane dwie właściwości. Pierwszy z nich tomaxConcurrency, który jest określony, aby mieć wartość domyślną i jest typustring. Ma domyślną nazwę<entityName>_properties_typeProperties_maxConcurrencyparametru . - Właściwość
recurrencejest również sparametryzowana. W nim wszystkie właściwości na tym poziomie są określane jako parametryzowane jako ciągi z wartościami domyślnymi i nazwami parametrów. Wyjątkiem jestintervalwłaściwość, która jest sparametryzowana jako typint. Nazwa parametru ma sufiks .<entityName>_properties_typeProperties_recurrence_triggerSuffixfreqPodobnie właściwość jest ciągiem i jest sparametryzowana jako ciąg.freqJednak właściwość jest sparametryzowana bez wartości domyślnej. Nazwa jest skrócona i sufiksowana. Na przykład<entityName>_freq.
Połączoneusługi
- Połączone usługi są unikatowe. Ponieważ połączone usługi i zestawy danych mają szeroką gamę typów, można zapewnić dostosowanie specyficzne dla typu. W tym przykładzie dla wszystkich połączonych usług typu
AzureDataLakeStorejest stosowany określony szablon. W przypadku wszystkich innych (za pośrednictwem*metody ) jest stosowany inny szablon. - Właściwość
connectionStringjest sparametryzowana jakosecurestringwartość. Nie będzie mieć wartości domyślnej. Ma skróconą nazwę parametru z sufiksemconnectionString. - Właściwość
secretAccessKeyma być właściwościąAzureKeyVaultSecret(na przykład w połączonej usłudze Amazon S3). Jest ona automatycznie sparametryzowana jako wpis tajny usługi Azure Key Vault i pobierana ze skonfigurowanego magazynu kluczy. Można również sparametryzować sam magazyn kluczy.
Zestawy danych
- Mimo że dostosowywanie specyficzne dla typu jest dostępne dla zestawów danych, można podać konfigurację bez jawnej konfiguracji *-level. W poprzednim przykładzie wszystkie właściwości zestawu danych w obszarze
typePropertiessą sparametryzowane.
Uwaga
Jeśli alerty i macierze platformy Azure są skonfigurowane dla potoku, nie są one obecnie obsługiwane jako parametry wdrożeń szablonów usługi ARM. Aby ponownie zastosować alerty i macierze w nowym środowisku, postępuj zgodnie z instrukcjami Monitorowanie, Alerty i Macierze usługi Data Factory.
Domyślny szablon parametryzacji
Poniżej znajduje się bieżący domyślny szablon parametryzacji. Jeśli musisz dodać tylko kilka parametrów, edytowanie tego szablonu bezpośrednio może być dobrym pomysłem, ponieważ nie utracisz istniejącej struktury parametryzacji.
{
"Microsoft.DataFactory/factories": {
"properties": {
"globalParameters": {
"*": {
"value": "="
}
}
},
"location": "="
},
"Microsoft.DataFactory/factories/globalparameters": {
"properties": {
"*": {
"value": "="
}
}
},
"Microsoft.DataFactory/factories/pipelines": {
},
"Microsoft.DataFactory/factories/dataflows": {
},
"Microsoft.DataFactory/factories/integrationRuntimes":{
"properties": {
"typeProperties": {
"ssisProperties": {
"catalogInfo": {
"catalogServerEndpoint": "=",
"catalogAdminUserName": "=",
"catalogAdminPassword": {
"value": "-::secureString"
}
},
"customSetupScriptProperties": {
"sasToken": {
"value": "-::secureString"
}
}
},
"linkedInfo": {
"key": {
"value": "-::secureString"
},
"resourceId": "="
},
"computeProperties": {
"dataFlowProperties": {
"externalComputeInfo": [{
"accessToken": "-::secureString"
}
]
}
}
}
}
},
"Microsoft.DataFactory/factories/triggers": {
"properties": {
"pipelines": [{
"parameters": {
"*": "="
}
}
],
"pipeline": {
"parameters": {
"*": "="
}
},
"typeProperties": {
"scope": "="
}
}
},
"Microsoft.DataFactory/factories/linkedServices": {
"*": {
"properties": {
"typeProperties": {
"accountName": "=",
"username": "=",
"userName": "=",
"accessKeyId": "=",
"servicePrincipalId": "=",
"userId": "=",
"host": "=",
"clientId": "=",
"clusterUserName": "=",
"clusterSshUserName": "=",
"hostSubscriptionId": "=",
"clusterResourceGroup": "=",
"subscriptionId": "=",
"resourceGroupName": "=",
"tenant": "=",
"dataLakeStoreUri": "=",
"baseUrl": "=",
"database": "=",
"serviceEndpoint": "=",
"batchUri": "=",
"poolName": "=",
"databaseName": "=",
"systemNumber": "=",
"server": "=",
"url":"=",
"functionAppUrl":"=",
"environmentUrl": "=",
"aadResourceId": "=",
"sasUri": "|:-sasUri:secureString",
"sasToken": "|",
"connectionString": "|:-connectionString:secureString",
"hostKeyFingerprint": "="
}
}
},
"Odbc": {
"properties": {
"typeProperties": {
"userName": "=",
"connectionString": {
"secretName": "="
}
}
}
}
},
"Microsoft.DataFactory/factories/datasets": {
"*": {
"properties": {
"typeProperties": {
"folderPath": "=",
"fileName": "="
}
}
}
},
"Microsoft.DataFactory/factories/managedVirtualNetworks/managedPrivateEndpoints": {
"properties": {
"*": "="
}
}
}
Przykład: parametryzacja istniejącego identyfikatora interaktywnego klastra usługi Azure Databricks
W poniższym przykładzie pokazano, jak dodać pojedynczą wartość do domyślnego szablonu parametryzacji. Chcemy tylko dodać istniejący identyfikator interaktywnego klastra usługi Azure Databricks dla połączonej usługi Databricks z plikiem parametrów. Ten plik jest taki sam jak poprzedni plik, z wyjątkiem dodawania existingClusterId elementu w polu właściwości .Microsoft.DataFactory/factories/linkedServices
{
"Microsoft.DataFactory/factories": {
"properties": {
"globalParameters": {
"*": {
"value": "="
}
}
},
"location": "="
},
"Microsoft.DataFactory/factories/pipelines": {
},
"Microsoft.DataFactory/factories/dataflows": {
},
"Microsoft.DataFactory/factories/integrationRuntimes":{
"properties": {
"typeProperties": {
"ssisProperties": {
"catalogInfo": {
"catalogServerEndpoint": "=",
"catalogAdminUserName": "=",
"catalogAdminPassword": {
"value": "-::secureString"
}
},
"customSetupScriptProperties": {
"sasToken": {
"value": "-::secureString"
}
}
},
"linkedInfo": {
"key": {
"value": "-::secureString"
},
"resourceId": "="
}
}
}
},
"Microsoft.DataFactory/factories/triggers": {
"properties": {
"pipelines": [{
"parameters": {
"*": "="
}
}
],
"pipeline": {
"parameters": {
"*": "="
}
},
"typeProperties": {
"scope": "="
}
}
},
"Microsoft.DataFactory/factories/linkedServices": {
"*": {
"properties": {
"typeProperties": {
"accountName": "=",
"username": "=",
"userName": "=",
"accessKeyId": "=",
"servicePrincipalId": "=",
"userId": "=",
"clientId": "=",
"clusterUserName": "=",
"clusterSshUserName": "=",
"hostSubscriptionId": "=",
"clusterResourceGroup": "=",
"subscriptionId": "=",
"resourceGroupName": "=",
"tenant": "=",
"dataLakeStoreUri": "=",
"baseUrl": "=",
"database": "=",
"serviceEndpoint": "=",
"batchUri": "=",
"poolName": "=",
"databaseName": "=",
"systemNumber": "=",
"server": "=",
"url":"=",
"aadResourceId": "=",
"connectionString": "|:-connectionString:secureString",
"existingClusterId": "-"
}
}
},
"Odbc": {
"properties": {
"typeProperties": {
"userName": "=",
"connectionString": {
"secretName": "="
}
}
}
}
},
"Microsoft.DataFactory/factories/datasets": {
"*": {
"properties": {
"typeProperties": {
"folderPath": "=",
"fileName": "="
}
}
}}
}
Powiązana zawartość
- Omówienie ciągłej integracji i dostarczania
- Automatyzowanie ciągłej integracji przy użyciu wydań Azure Pipelines
- Ręczne podwyższenie poziomu szablonu usługi Resource Manager do każdego środowiska
- Połączone szablony usługi Resource Manager
- Używanie środowiska produkcyjnego poprawek
- Przykładowy skrypt wstępny i po wdrożeniu