Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
Przepływy danych są dostępne zarówno w potokach Azure Data Factory, jak i w potokach Azure Synapse Analytics. Ten artykuł dotyczy przepływów danych mapowania. Jeśli dopiero zaczynasz z przekształceń danych, zapoznaj się z artykułem wprowadzającym Przekształcanie danych przy użyciu przepływów mapowania danych.
Wskazówka
Aby uzyskać równoważną transformację (Kolumna niestandardowa) w Dataflow Gen2, proszę zobaczyć Przewodnik po Dataflow Gen2 dla użytkowników przepływu danych mapowania.
Użyj przekształcenia kolumny pochodnej, aby wygenerować nowe kolumny w przepływie danych lub zmodyfikować istniejące pola.
Tworzenie i aktualizowanie kolumn
Podczas tworzenia kolumny pochodnej można wygenerować nową kolumnę lub zaktualizować istniejącą kolumnę. W polu tekstowym Kolumna wprowadź nazwę tworzonej kolumny. Aby zastąpić istniejącą kolumnę w schemacie, możesz użyć listy rozwijanej kolumny. Aby skompilować wyrażenie kolumny pochodnej, wybierz pole tekstowe Enter expression (Wprowadź wyrażenie ). Możesz rozpocząć wpisywanie wyrażenia lub otworzyć konstruktora wyrażeń, aby utworzyć logikę.
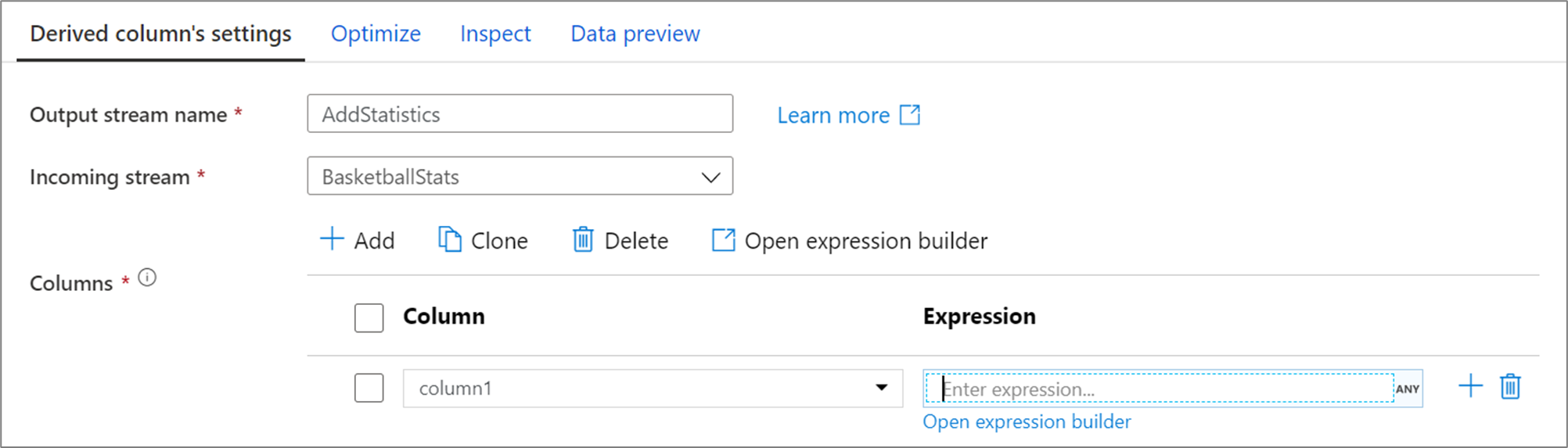
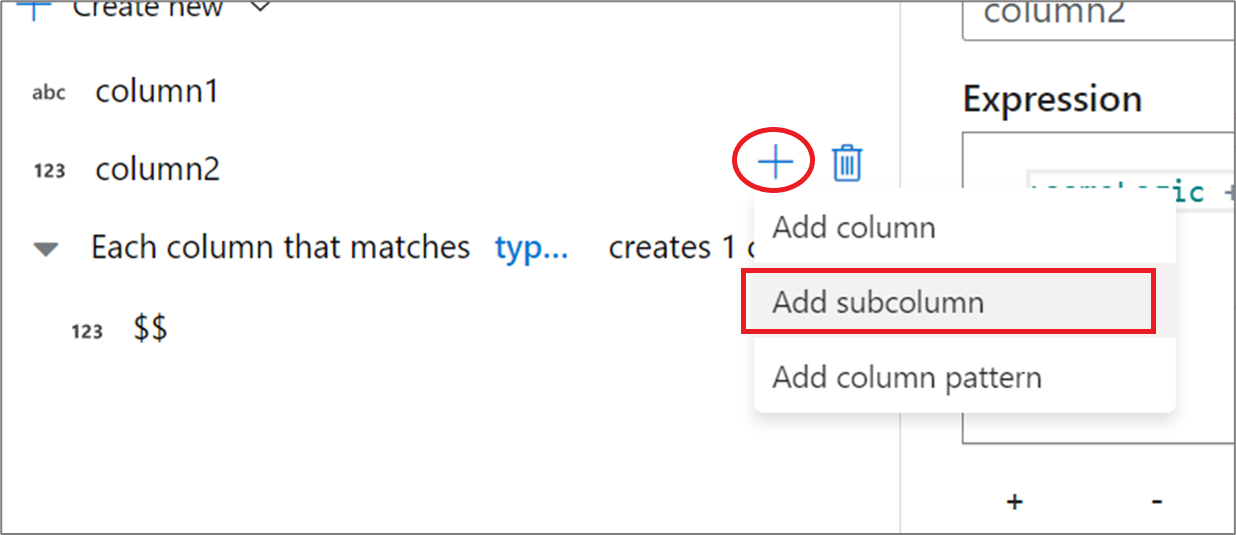
Aby dodać więcej kolumn pochodnych, wybierz pozycję Dodaj powyżej listy kolumn lub ikonę znaku plus obok istniejącej kolumny pochodnej. Wybierz pozycję Dodaj kolumnę lub Dodaj wzorzec kolumny.
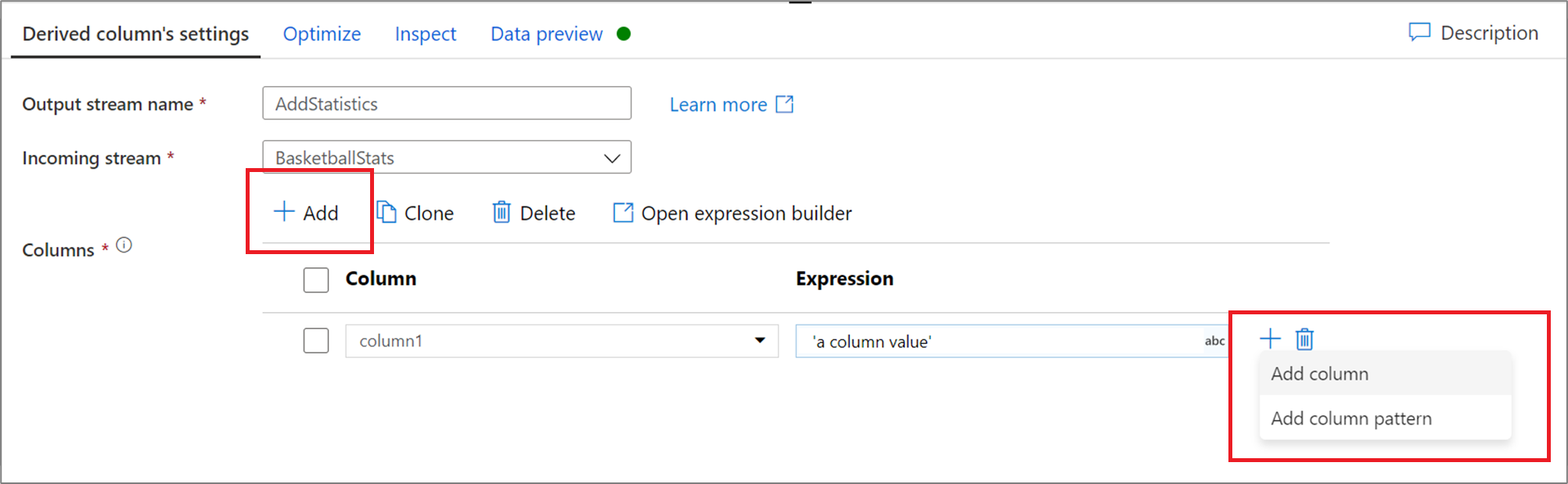
Wzorce kolumn
W przypadkach, gdy schemat nie jest jawnie zdefiniowany lub jeśli chcesz zbiorczo zaktualizować zestaw kolumn, należy utworzyć wzorce kolumn. Wzorce kolumn umożliwiają dopasowywanie kolumn przy użyciu reguł opartych na metadanych kolumn i tworzenie kolumn pochodnych dla każdej dopasowanej kolumny. Aby uzyskać więcej informacji, dowiedz się , jak tworzyć wzorce kolumn w transformacji kolumn pochodnych.
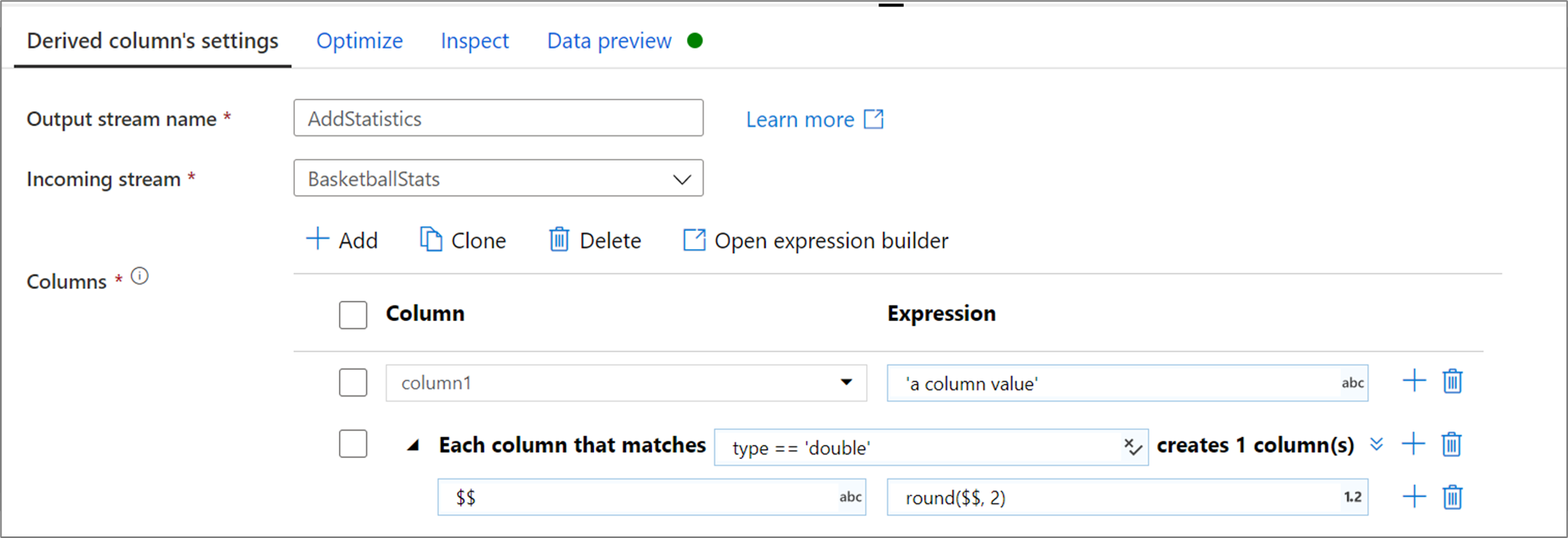
Kompilowanie schematów przy użyciu konstruktora wyrażeń
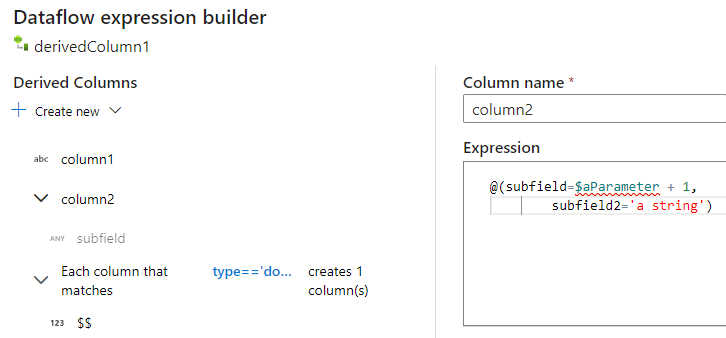
Korzystając z konstruktora wyrażeń przepływu mapowania danych, możesz tworzyć, edytować i zarządzać kolumnami pochodnymi w sekcji Kolumny pochodne. Zostaną wyświetlone wszystkie kolumny utworzone lub zmienione w transformacji. Interaktywnie wybierz edytowaną kolumnę lub wzorzec, wybierając nazwę kolumny. Aby dodać kolejną kolumnę, wybierz pozycję Utwórz nową i wybierz, czy chcesz dodać pojedynczą kolumnę, czy wzorzec.
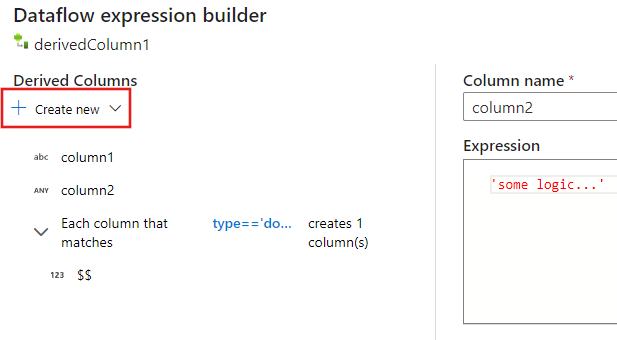
Podczas pracy z kolumnami złożonymi można tworzyć podkolumny. W tym celu wybierz ikonę znaku plus obok dowolnej kolumny i wybierz pozycję Dodaj podkolumnę. Aby uzyskać więcej informacji na temat obsługi złożonych typów w przepływie danych, zobacz Obsługa JSON w przepływie mapowania danych.
Aby uzyskać więcej informacji na temat obsługi złożonych typów w przepływie danych, zobacz Obsługa JSON w przepływie mapowania danych.
Skrypt przepływu danych
Składnia
<incomingStream>
derive(
<columnName1> = <expression1>,
<columnName2> = <expression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <deriveTransformationName>
Przykład
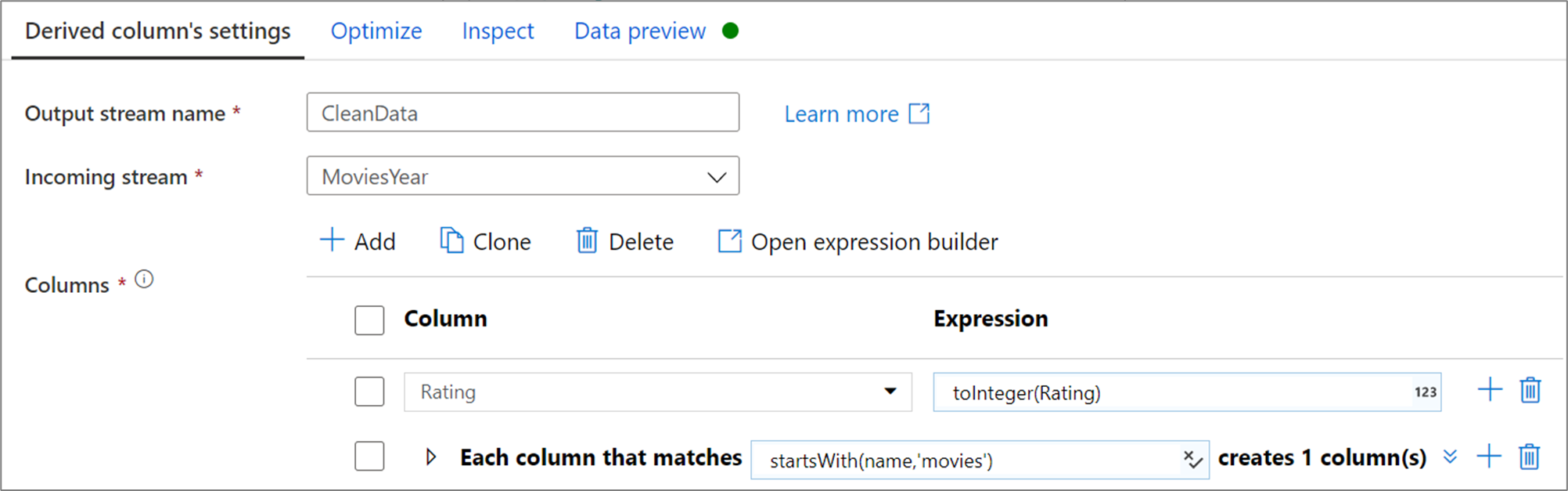
Poniższy przykład to kolumna pochodna o nazwie CleanData , która pobiera strumień MoviesYear przychodzący i tworzy dwie kolumny pochodne. Pierwsza kolumna pochodna zastępuje kolumnę Rating wartością oceny jako typem całkowitym. Druga kolumna pochodna jest wzorcem zgodnym z każdą kolumną, której nazwa zaczyna się od "filmów". Dla każdej dopasowanej kolumny tworzy kolumnę movie równą wartości dopasowanej kolumny poprzedzonej prefiksem "movie_".
W interfejsie użytkownika ta transformacja wygląda jak na poniższej ilustracji:
Skrypt przepływu danych dla tej transformacji znajduje się w poniższym fragmencie kodu:
MoviesYear derive(
Rating = toInteger(Rating),
each(
match(startsWith(name,'movies')),
'movie' = 'movie_' + toString($$)
)
) ~> CleanData
Powiązana zawartość
- Dowiedz się więcej o języku wyrażeń Mapping Przepływ danych.