Używanie wzorców kolumn w przepływach danych mapowania
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Kilka przekształceń przepływów mapowania danych umożliwia odwoływania się do kolumn szablonów na podstawie wzorców zamiast zakodowanych na podstawie nazw kolumn. To dopasowanie jest nazywane wzorcami kolumn. Można zdefiniować wzorce, aby dopasować kolumny na podstawie nazwy, typu danych, strumienia, źródła lub pozycji, zamiast wymagać dokładnych nazw pól. Istnieją dwa scenariusze, w których przydatne są wzorce kolumn:
- Jeśli przychodzące pola źródłowe zmieniają się często, na przykład w przypadku zmiany kolumn w plikach tekstowych lub bazach danych NoSQL. Ten scenariusz jest znany jako dryf schematu.
- Jeśli chcesz wykonać wspólną operację w dużej grupie kolumn. Na przykład chcesz rzutować każdą kolumnę, która ma wartość "total" w nazwie kolumny w podwójne.
Wzorce kolumn w kolumnie pochodnej i agregacji
Aby dodać wzorzec kolumny w kolumnie pochodnej, agregacji lub transformacji okna, kliknij przycisk Dodaj nad listą kolumn lub ikoną znaku plus obok istniejącej kolumny pochodnej. Wybierz pozycję Dodaj wzorzec kolumny.
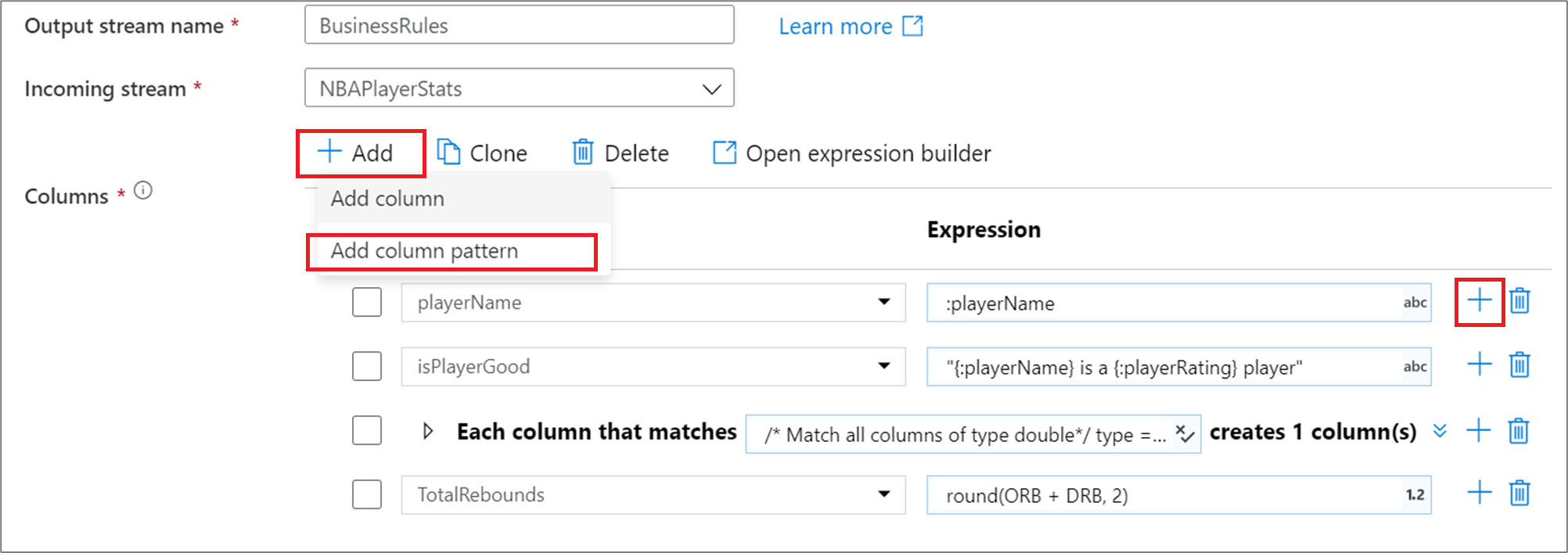
Użyj konstruktora wyrażeń, aby wprowadzić warunek dopasowania. Utwórz wyrażenie logiczne, które pasuje do kolumn na namepodstawie kolumn , , typestream, origini position kolumny. Wzorzec będzie mieć wpływ na dowolną kolumnę, dryf lub zdefiniowaną, gdzie warunek zwraca wartość true.
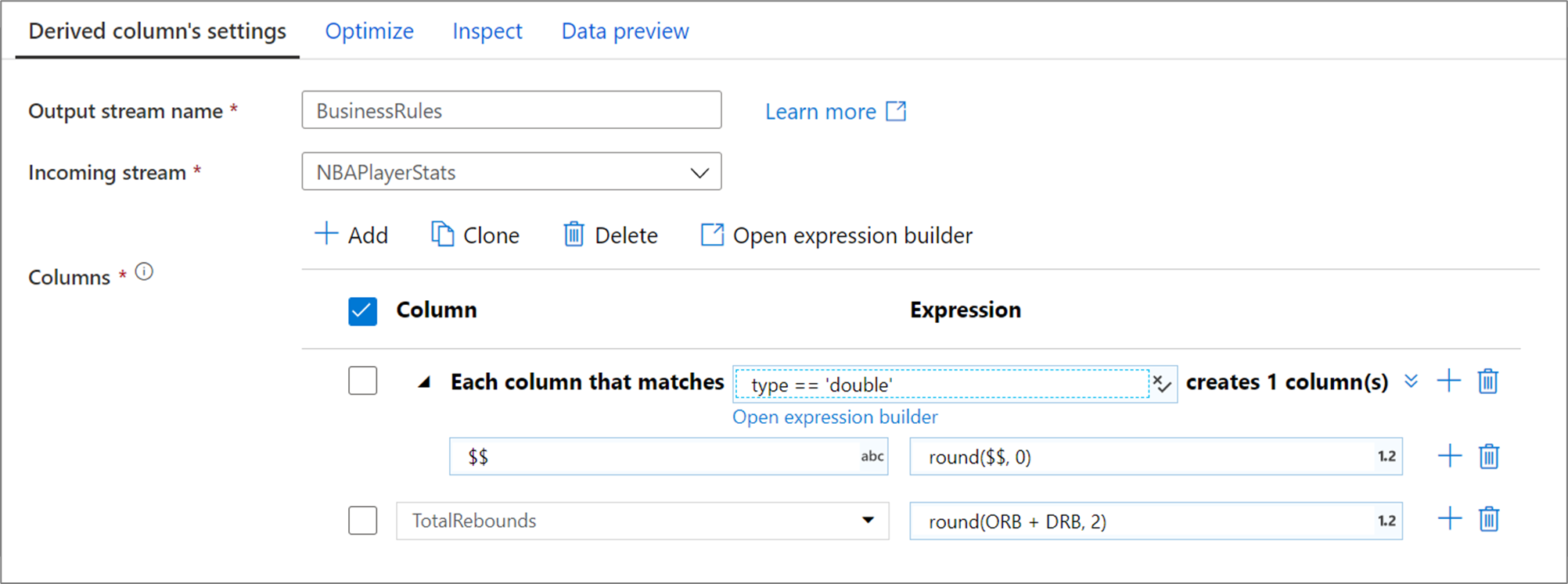
Powyższy wzorzec kolumny odpowiada każdej kolumnie typu podwójnej i tworzy jedną pochodną kolumnę na dopasowanie. $$ Określając jako pole nazwy kolumny, każda dopasowana kolumna jest aktualizowana o taką samą nazwę. Wartość każdej kolumny jest istniejącą wartością zaokrąglaną do dwóch punktów dziesiętnych.
Aby sprawdzić, czy zgodny warunek jest poprawny, możesz zweryfikować schemat wyjściowy zdefiniowanych kolumn na karcie Inspekcja lub uzyskać migawkę danych na karcie Podgląd danych.
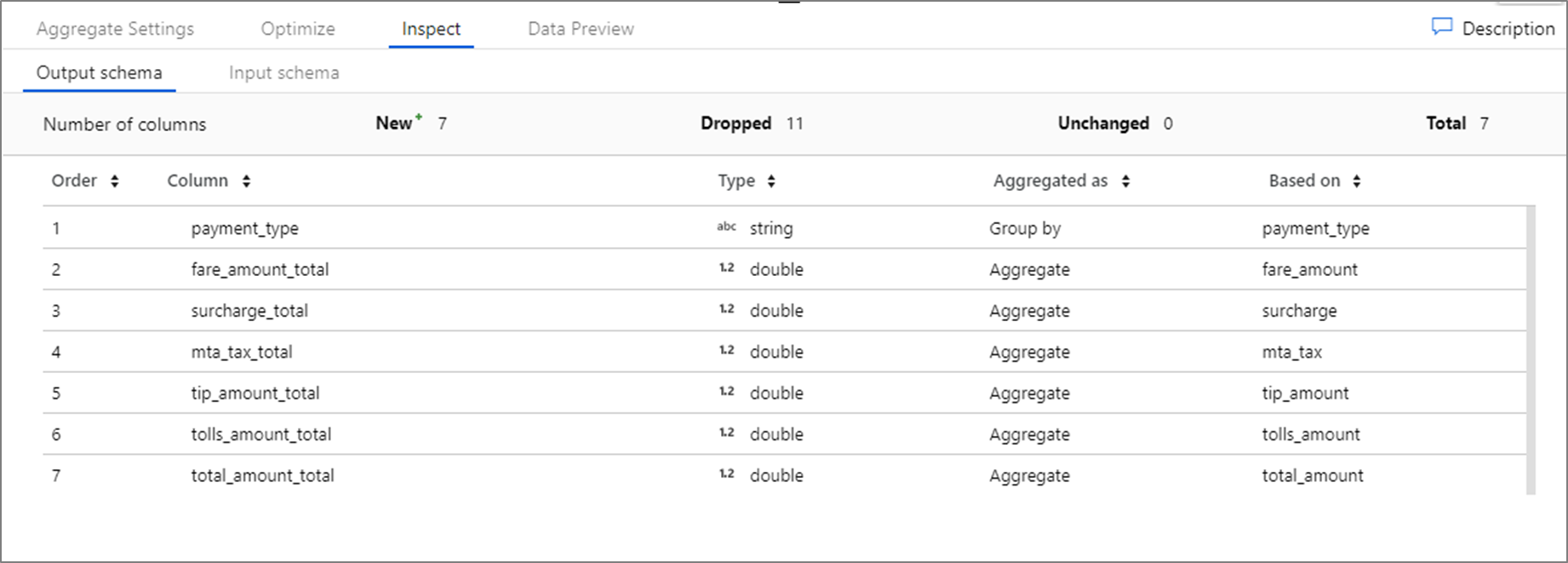
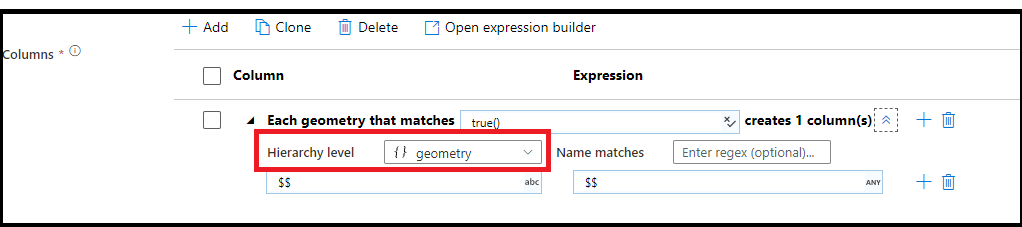
Dopasowywanie wzorca hierarchicznego
Można również tworzyć dopasowywanie wzorców wewnątrz złożonych struktur hierarchicznych. Rozwiń sekcję Each MoviesStruct that matches , w której zostanie wyświetlony monit o każdą hierarchię w strumieniu danych. Następnie można tworzyć pasujące wzorce dla właściwości w ramach wybranej hierarchii.
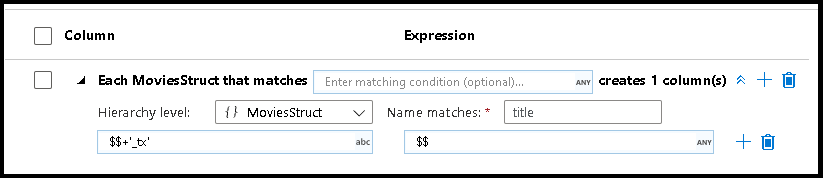
Spłaszczanie struktur
Gdy dane mają złożone struktury, takie jak tablice, struktury hierarchiczne i mapy, można użyć przekształcenia Spłaszczanie, aby wyrejestrować tablice i zdenormalizować dane. W przypadku struktur i map użyj przekształcenia kolumny pochodnej z wzorcami kolumn, aby utworzyć spłaszczonej tabeli relacyjnej z hierarchii. Możesz użyć wzorców kolumn, które będą wyglądać podobnie do tego przykładu, co spłaszcza hierarchię geografii w formularzu tabeli relacyjnej:
Mapowanie oparte na regułach w selektorze i ujściu
Podczas mapowania kolumn w źródle i wybierania przekształceń można dodać stałe mapowanie lub mapowania oparte na regułach. Dopasuj namena podstawie kolumn , type, stream, origini position . Można mieć dowolną kombinację mapowań stałych i opartych na regułach. Domyślnie wszystkie projekcje z większą niż 50 kolumnami domyślnie będą domyślnie mapowane na podstawie reguł, które są zgodne z każdą kolumną i wyprowadza nazwę wejściową.
Aby dodać mapowanie oparte na regułach, kliknij pozycję Dodaj mapowanie i wybierz pozycję Mapowanie oparte na regułach.

Każde mapowanie oparte na regułach wymaga dwóch danych wejściowych: warunku, według którego ma być dopasowana wartość i co nazwać każdą zmapowanych kolumn. Obie wartości są wprowadzane za pośrednictwem konstruktora wyrażeń. W polu wyrażenia po lewej stronie wprowadź warunek dopasowania warunkowego. W polu wyrażenia po prawej stronie określ, na co zostanie zamapowana dopasowana kolumna.

Użyj $$ składni, aby odwołać się do nazwy wejściowej dopasowanej kolumny. Korzystając z powyższego obrazu jako przykładu, załóżmy, że użytkownik chce dopasować się do wszystkich kolumn ciągów, których nazwy są krótsze niż sześć znaków. Jeśli jedna kolumna przychodząca nosi nazwę test, wyrażenie $$ + '_short' zmieni nazwę kolumny test_short. Jeśli jest to jedyne mapowanie, które istnieje, wszystkie kolumny, które nie spełniają warunku, zostaną usunięte z danych wyjściowych.
Wzorce są zgodne zarówno z dryfowaniem, jak i zdefiniowanymi kolumnami. Aby zobaczyć, które zdefiniowane kolumny są mapowane przez regułę, kliknij ikonę okularów obok reguły. Sprawdź dane wyjściowe przy użyciu podglądu danych.
Mapowanie wyrażeń regularnych
Jeśli klikniesz ikonę strzałki w dół, możesz określić warunek mapowania wyrażeń regularnych. Warunek mapowania wyrażenia regularnego jest zgodny ze wszystkimi nazwami kolumn, które pasują do określonego warunku wyrażenia regularnego. Może to być używane w połączeniu ze standardowymi mapowaniami opartymi na regułach.

Powyższy przykład jest zgodny ze wzorcem (r) wyrażeń regularnych lub dowolną nazwą kolumny zawierającą małe litery r. Podobnie jak w przypadku standardowego mapowania opartego na regułach, wszystkie dopasowane kolumny są zmieniane przez warunek po prawej stronie przy użyciu $$ składni.
Hierarchie oparte na regułach
Jeśli zdefiniowana projekcja ma hierarchię, możesz użyć mapowania na podstawie reguł, aby mapować podkolumny hierarchii. Określ zgodny warunek i kolumnę złożoną, której kolumny podrzędne chcesz mapować. Każdy dopasowany podkolumn zostanie wyświetlony przy użyciu reguły "Nazwa jako" określonej po prawej stronie.
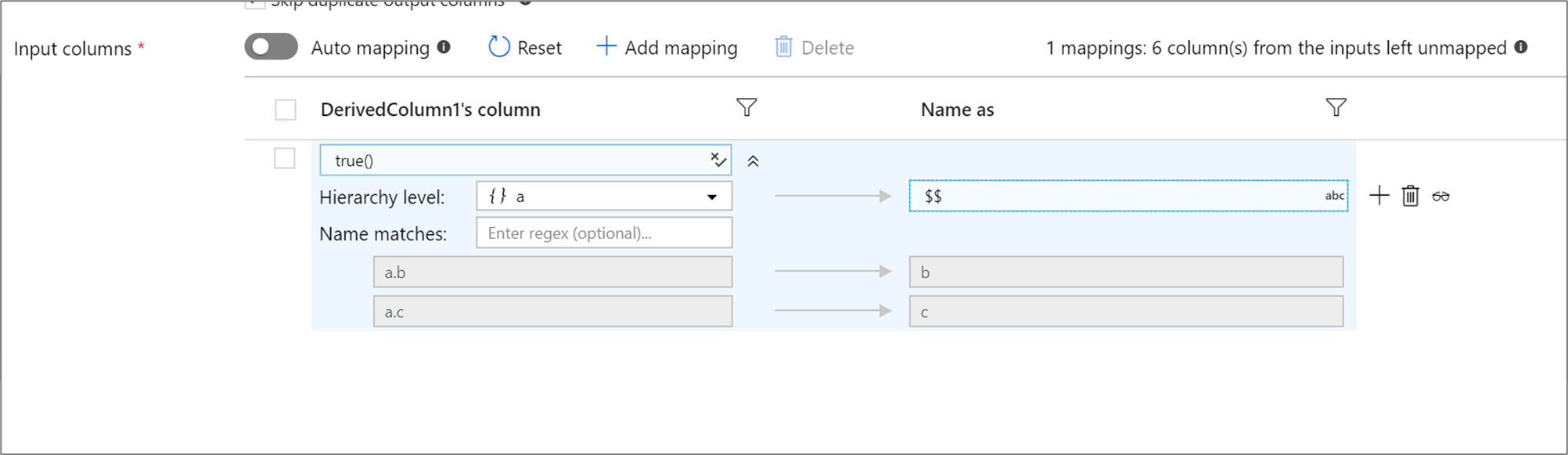
Powyższy przykład pasuje do wszystkich podkolumn kolumn zespolonej a. a zawiera dwa podkolumny b i c. Schemat danych wyjściowych będzie zawierać dwie kolumny b i c jako warunek "Nazwa jako" to $$.
Dopasowywanie wzorców wartości wyrażeń
$$Przekłada się na nazwę lub wartość każdego dopasowania w czasie wykonywania.$$Pomyśl o tym, jak równoważnethis$0Przekłada się na bieżące dopasowanie nazwy kolumny w czasie wykonywania dla typów skalarnych. W przypadku typów$0hierarchicznych reprezentuje bieżącą zgodną ścieżkę hierarchii kolumn.namereprezentuje nazwę każdej kolumny przychodzącejtypereprezentuje typ danych każdej kolumny przychodzącej. Listę typów danych w systemie typów przepływów danych można znaleźć tutaj.streamreprezentuje nazwę skojarzona z każdym strumieniem lub przekształcenie w przepływiepositionto pozycja porządkowa kolumn w przepływie danychoriginto przekształcenie, w którym pochodzi kolumna lub została ostatnio zaktualizowana
Powiązana zawartość
- Dowiedz się więcej o języku wyrażeń przepływów mapowania danych na potrzeby przekształceń danych
- Używanie wzorców kolumn w transformacji ujścia i wybieranie przekształcenia za pomocą mapowania opartego na regułach
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla