Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
Przepływy danych są dostępne zarówno w potokach Azure Data Factory, jak i w potokach Azure Synapse Analytics. Ten artykuł dotyczy przepływów danych mapowania. Jeśli dopiero zaczynasz przekształcanie danych, zapoznaj się z artykułem wprowadzającym Przekształcanie danych przy użyciu przepływów danych mapowania.
Napiwek
Aby uzyskać równoważną transformację (Wybierz kolumny) w przepływie danych Gen2, zobacz Przewodnik dla użytkowników przepływu danych mapowania w Dataflow Gen2.
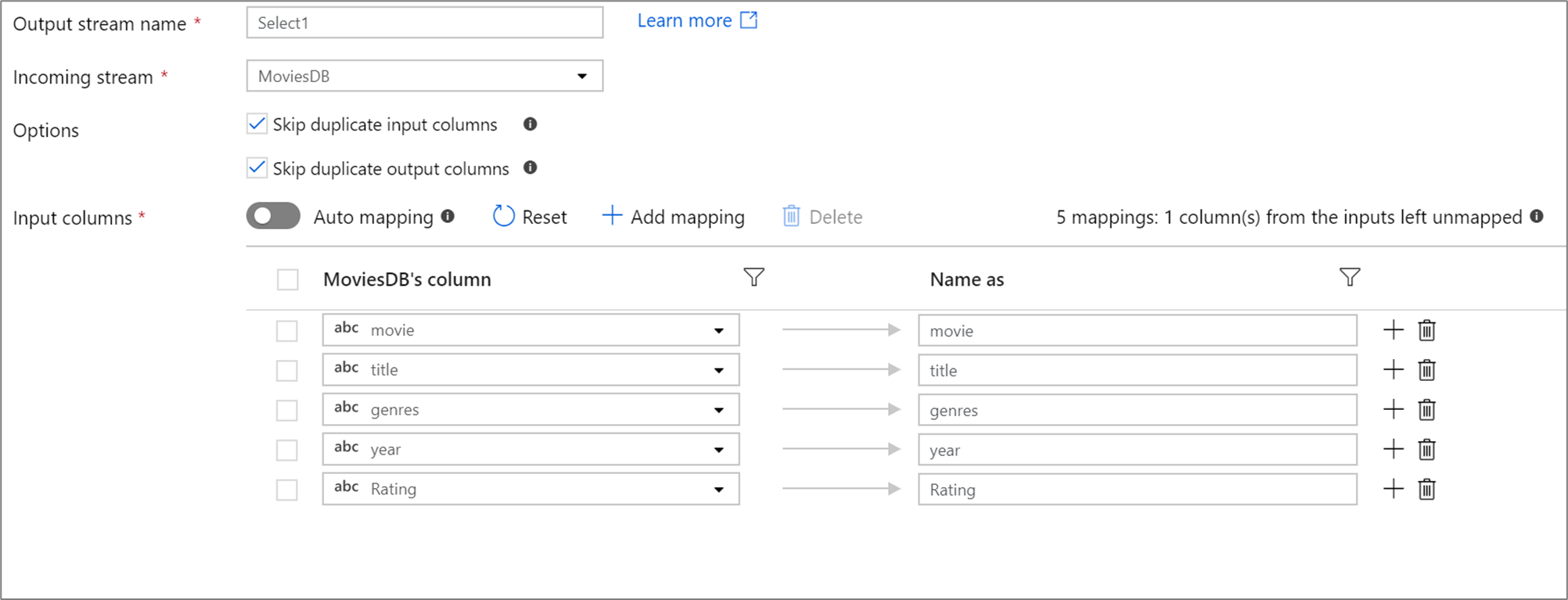
Użyj przekształcenia select, aby zmienić nazwę, upuść lub zmienić kolejność kolumn. Ta transformacja nie zmienia danych wierszy, ale wybiera kolumny, które są propagowane podrzędnie.
W wybranej transformacji użytkownicy mogą określać stałe mapowania, używać wzorców do mapowania opartego na regułach lub włączać automatyczne mapowanie. Mapowania stałe i oparte na regułach mogą być używane w ramach tego samego przekształcenia wyboru. Jeśli kolumna nie pasuje do jednego ze zdefiniowanych mapowań, zostanie porzucona.
Naprawiono mapowanie
Jeśli w projekcji zdefiniowano mniej niż 50 kolumn, wszystkie zdefiniowane kolumny będą domyślnie miały stałe mapowanie. Stałe mapowanie przyjmuje zdefiniowaną, przychodzącą kolumnę i mapuje ją na dokładną nazwę.
Uwaga
Nie można mapować ani zmieniać nazwy dryfowanej kolumny przy użyciu stałego mapowania
Mapowanie kolumn hierarchicznych
Ustalone mapowania mogą służyć do odwzorowywania podkolumny kolumny hierarchicznej na kolumnę najwyższego poziomu. Jeśli masz zdefiniowaną hierarchię, użyj listy rozwijanej kolumny, aby wybrać podkolumnę. Przekształcenie wyboru utworzy nową kolumnę, której wartość i typ danych będą odpowiadały podkolumnie.
Mapowanie oparte na regułach
Jeśli chcesz mapować wiele kolumn jednocześnie lub przekazywać przemieszczone kolumny, użyj mapowań opartych na regułach do definiowania mapowań za pomocą wzorców kolumn. Dopasuj na podstawie name, type, stream, i position kolumn. Można mieć dowolną kombinację mapowań stałych i opartych na regułach. Domyślnie wszystkie projekcje z więcej niż 50 kolumnami będą mapowane w oparciu o reguły, które są zgodne z każdą kolumną i zwracają nazwę wprowadzaną.
Aby dodać mapowanie oparte na regułach, kliknij pozycję Dodaj mapowanie i wybierz pozycję Mapowanie oparte na regułach.

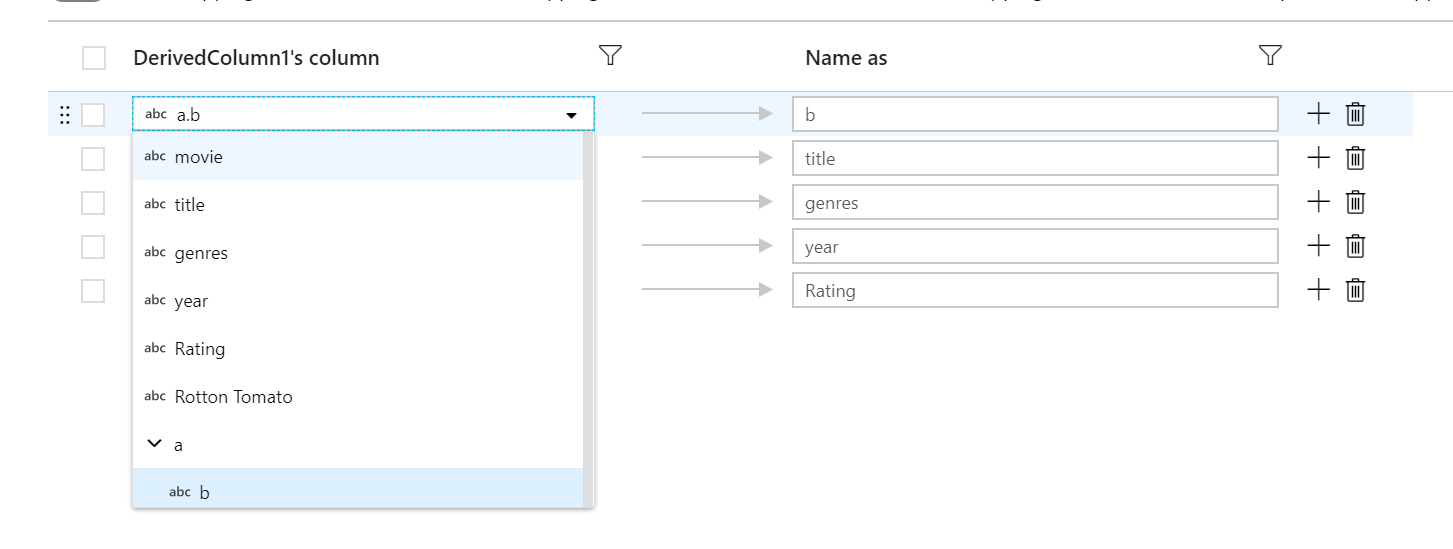
Każde mapowanie oparte na regułach wymaga dwóch danych wejściowych: warunku, według którego ma być dopasowane, oraz nazwy dla każdej z mapowanych kolumn. Obie wartości są wprowadzane za pośrednictwem konstruktora wyrażeń. W polu do wyrażenia po lewej stronie wprowadź warunek dopasowania logicznego. W polu wyrażenia po prawej stronie określ, na co zostanie zamapowana dopasowana kolumna.

Użyj $$ składni, aby odwołać się do nazwy wejściowej dopasowanej kolumny. Korzystając z powyższego obrazu jako przykładu, załóżmy, że użytkownik chce dopasować wszystkie kolumny tekstowe, których nazwy są krótsze niż sześć znaków. Jeśli jedna kolumna przychodząca nosi nazwę test, wyrażenie $$ + '_short' zmieni nazwę kolumny test_short. Jeśli jest to jedyne mapowanie, które istnieje, wszystkie kolumny, które nie spełniają warunku, zostaną usunięte z danych wyjściowych.
Wzorce pasują zarówno do przesuniętych, jak i zdefiniowanych kolumn. Aby zobaczyć, które zdefiniowane kolumny są mapowane przez regułę, kliknij ikonę okularów obok reguły. Sprawdź dane wyjściowe przy użyciu podglądu danych.
Mapowanie wyrażeń regularnych
Jeśli klikniesz ikonę strzałki w dół, możesz określić warunek mapowania regexu. Warunek mapowania wyrażenia regularnego jest zgodny ze wszystkimi nazwami kolumn, które pasują do określonego warunku wyrażenia regularnego. Może to być używane w połączeniu ze standardowymi mapowaniami opartymi na regułach.

Powyższy przykład jest zgodny ze wzorcem wyrażenia regularnego (r) lub dowolną nazwą kolumny zawierającą małą literę r. Podobnie jak w przypadku standardowego mapowania opartego na regułach, wszystkie dopasowane kolumny są zmieniane za pomocą warunku po prawej stronie używając składni $$.
Jeśli w nazwie kolumny znajduje się wiele dopasowań wyrażeń regularnych, możesz odwoływać się do określonych dopasowań, używając $n, gdzie "n" odnosi się do konkretnego dopasowania. Na przykład "$2" odnosi się do drugiego dopasowania w nazwie kolumny.
Hierarchie oparte na regułach
Jeśli zdefiniowana projekcja ma hierarchię, możesz użyć mapowania na podstawie reguł, aby mapować podkolumny hierarchii. Określ zgodny warunek i kolumnę złożoną, której kolumny podrzędne chcesz mapować. Każda dopasowana podkolumna zostanie wyświetlona zgodnie z regułą "Name as" określoną po prawej stronie.
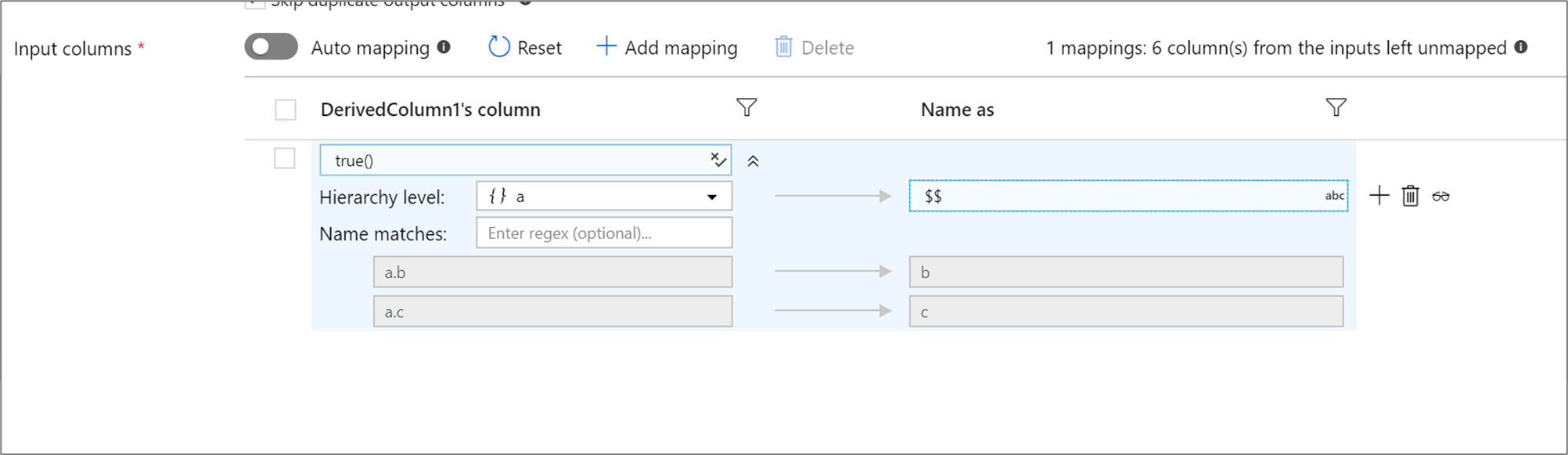
Powyższy przykład pasuje do wszystkich podkolumn kolumny złożonej a.
a zawiera dwa podkolumny b i c. Schemat danych wyjściowych będzie zawierał dwie kolumny b i c, zgodnie z warunkiem „'Nazwa jako' to $$”.
Parametryzacja
Nazwy kolumn można sparametryzować przy użyciu mapowania opartego na regułach. Użyj słowa kluczowego name , aby dopasować nazwy kolumn przychodzących do parametru. Jeśli na przykład masz parametr mycolumnprzepływu danych, możesz utworzyć regułę zgodną z dowolną nazwą kolumny, która jest równa mycolumn. Możesz zmienić nazwę dopasowanej kolumny na zakodowany ciąg, taki jak "klucz biznesowy" i odwoływać się do niej jawnie. W tym przykładzie warunek dopasowania to name == $mycolumn , a warunek nazwy to "klucz biznesowy".
Automatyczne mapowanie
Podczas dodawania przekształcenia można włączyć automatyczne mapowanie, przełączając suwak Automatyczne Mapowanie. Po automatycznym mapowaniu, transformacja wyboru mapuje wszystkie kolumny przychodzące, z wyjątkiem duplikatów, które mają taką samą nazwę jak ich dane wejściowe. Będzie to obejmować dryfowane kolumny, co oznacza, że dane wyjściowe mogą zawierać kolumny, które nie są zdefiniowane w schemacie. Aby uzyskać więcej informacji na temat kolumn podlegających dryfowi, zobacz schema drift.
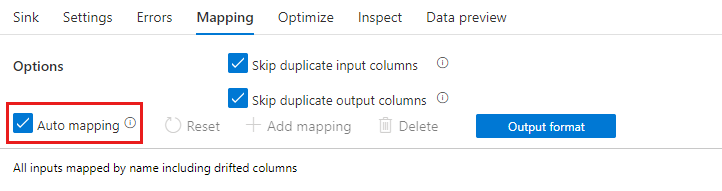
Po włączeniu automatycznego mapowania transformacja zaznaczenia będzie respektować ustawienia pomijania duplikatów i przypisywać nowy alias do istniejących kolumn. Aliasowanie jest przydatne podczas wykonywania wielu sprzężeń lub wyszukiwań w tym samym strumieniu danych i w scenariuszach samosprzężenia.
Zduplikowane kolumny
Domyślnie funkcja select transformation odrzuca zduplikowane kolumny zarówno w projekcji wejściowej, jak i wyjściowej. Zduplikowane kolumny wejściowe często pochodzą z transformacji sprzężenia i wyszukiwania, w których nazwy kolumn są duplikowane po obu stronach sprzężenia. W przypadku mapowania dwóch różnych kolumn wejściowych na tę samą nazwę, mogą wystąpić zduplikowane kolumny wyjściowe. Wybierz, czy chcesz usunąć czy zachować zduplikowane kolumny, używając pola wyboru.
Kolejność kolumn
Kolejność mapowań określa kolejność kolumn wyjściowych. Jeśli kolumna wejściowa jest mapowana wiele razy, zostanie uznane tylko pierwsze mapowanie. W przypadku usuwania zduplikowanych kolumn, pierwsze dopasowanie zostanie zachowane.
Skrypt przepływu danych
Składnia
<incomingStream>
select(mapColumn(
each(<hierarchicalColumn>, match(<matchCondition>), <nameCondition> = $$), ## hierarchical rule-based matching
<fixedColumn>, ## fixed mapping, no rename
<renamedFixedColumn> = <fixedColumn>, ## fixed mapping, rename
each(match(<matchCondition>), <nameCondition> = $$), ## rule-based mapping
each(patternMatch(<regexMatching>), <nameCondition> = $$) ## regex mapping
),
skipDuplicateMapInputs: { true | false },
skipDuplicateMapOutputs: { true | false }) ~> <selectTransformationName>
Przykład
Poniżej przedstawiono przykład przykładowego mapowania wyboru i skryptu przepływu danych.
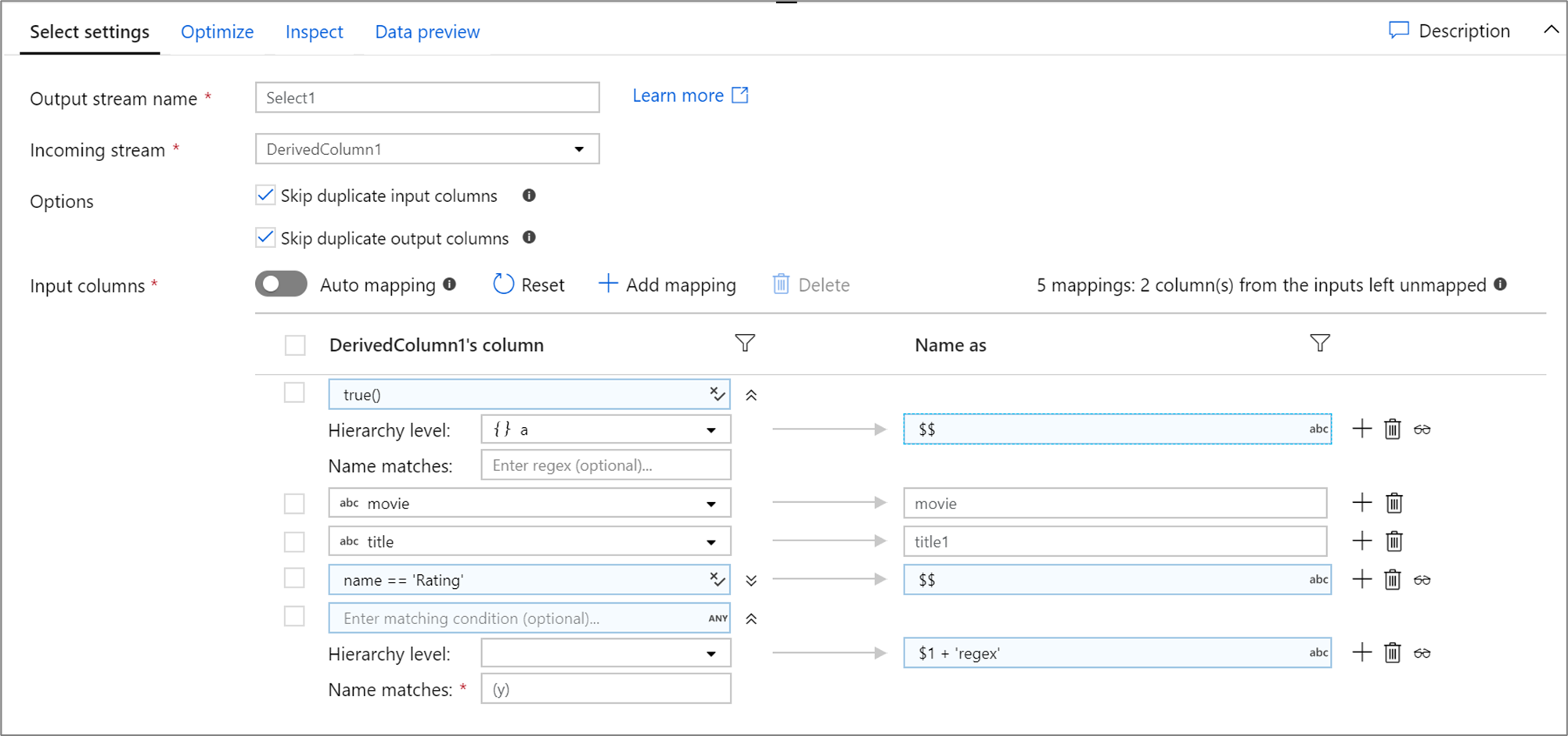
DerivedColumn1 select(mapColumn(
each(a, match(true())),
movie,
title1 = title,
each(match(name == 'Rating')),
each(patternMatch(`(y)`),
$1 + 'regex' = $$)
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> Select1
Powiązana zawartość
- Po użyciu polecenia Wybierz, aby zmienić nazwę, zmienić kolejność i nadać aliasy kolumnom, użyj transformacji ujścia, aby umieścić swoje dane w magazynie danych.