Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Dryf schematu to sytuacja, w której źródła często zmieniają metadane. Pola, kolumny i typy można dodawać, usuwać lub zmieniać na bieżąco. Bez obsługi dryfu schematów przepływ danych staje się podatny na zmiany nadrzędnego źródła danych. Typowe wzorce ETL kończą się niepowodzeniem w przypadku zmiany przychodzących kolumn i pól, ponieważ są one zwykle powiązane z tymi nazwami źródłowymi.
Aby chronić przed dryfem schematu, ważne jest, aby w narzędziu przepływu danych umożliwić, jako inżynierowie danych, następujące elementy:
- Definiowanie źródeł, które mają modyfikowalne nazwy pól, typy danych, wartości i rozmiary
- Definiowanie parametrów przekształcania, które mogą współdziałać ze wzorcami danych zamiast zakodowanych na twardo pól i wartości
- Definiowanie wyrażeń, które rozumieją wzorce zgodne z polami przychodzącymi, zamiast używać nazwanych pól
Usługa Azure Data Factory natywnie obsługuje elastyczne schematy, które zmieniają się z wykonywania na wykonywanie, dzięki czemu można tworzyć ogólną logikę przekształcania danych bez konieczności ponownego kompilowania przepływów danych.
Musisz podjąć decyzję o architekturze w przepływie danych, aby zaakceptować dryf schematu w całym przepływie. W takim przypadku można chronić przed zmianami schematu ze źródeł. Utracisz jednak wczesne powiązanie kolumn i typów w całym przepływie danych. Usługa Azure Data Factory traktuje przepływy dryfu schematu jako przepływy opóźnione, więc podczas tworzenia przekształceń nazwy dryfowanych kolumn nie będą dostępne w widokach schematu w całym przepływie.
Ten film wideo zawiera wprowadzenie do niektórych złożonych rozwiązań, które można łatwo tworzyć w potokach usługi Azure Data Factory lub Synapse Analytics za pomocą funkcji dryfu schematu przepływu danych. W tym przykładzie tworzymy wzorce wielokrotnego użytku na podstawie elastycznych schematów bazy danych:
Dryf schematu w źródle
Kolumny przychodzące do przepływu danych z definicji źródłowej są definiowane jako "dryfowane", gdy nie są obecne w projekcji źródłowej. Projekcję źródłową można wyświetlić na karcie projekcji w transformacji źródłowej. Po wybraniu zestawu danych dla źródła usługa automatycznie przejmie schemat z zestawu danych i utworzy projekcję na podstawie tej definicji schematu zestawu danych.
W transformacji źródłowej dryf schematu jest definiowany jako odczytywanie kolumn, które nie są zdefiniowane w schemacie zestawu danych. Aby włączyć dryf schematu, zaznacz pole Zezwalaj na dryf schematu w transformacji źródłowej.
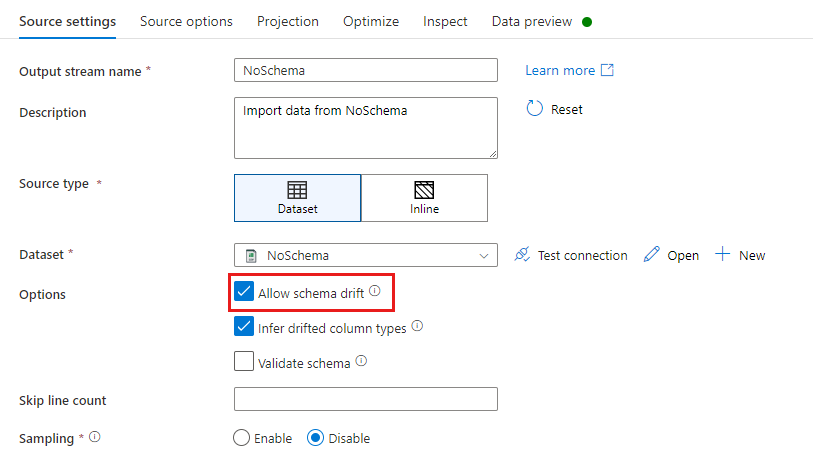
Po włączeniu dryfu schematu wszystkie pola przychodzące są odczytywane ze źródła podczas wykonywania i przekazywane przez cały przepływ do ujścia. Domyślnie wszystkie nowo wykryte kolumny znane jako kolumny dryfujące są dostarczane jako typ danych ciągu. Jeśli chcesz, aby przepływ danych automatycznie wnioskował typy danych dryfowanych kolumn, sprawdź w ustawieniach źródła dryfowane typy kolumn wnioskowania.
Dryf schematu w ujściu
W transformacji ujścia dryf schematu jest podczas pisania dodatkowych kolumn na podstawie tego, co jest zdefiniowane w schemacie danych ujścia. Aby włączyć dryf schematu, zaznacz pole Zezwalaj na dryf schematu w transformacji ujścia.
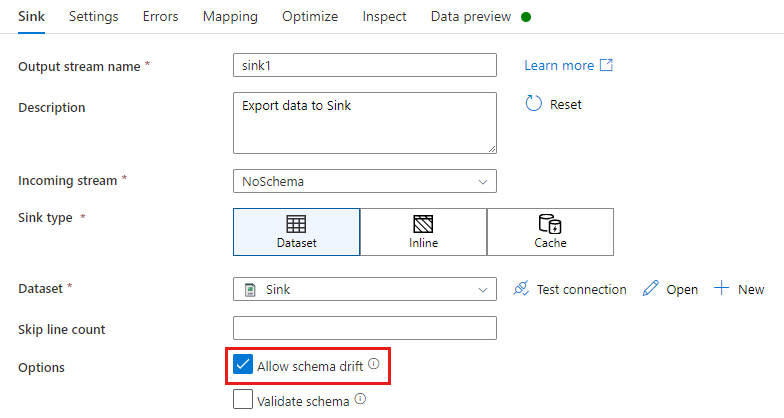
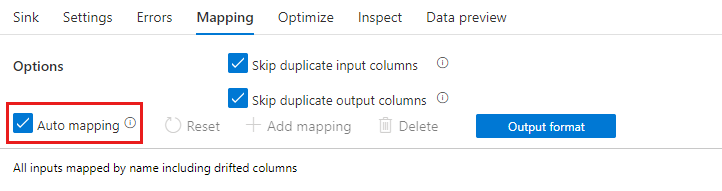
Jeśli dryf schematu jest włączony, upewnij się, że suwak Automatycznego mapowania na karcie Mapowanie jest włączony. Za pomocą tego suwaka wszystkie kolumny przychodzące są zapisywane w miejscu docelowym. W przeciwnym razie należy użyć mapowania opartego na regułach, aby zapisywać dryfowane kolumny.
Przekształcanie dryfowanych kolumn
Gdy przepływ danych dryfuje kolumny, możesz uzyskać do nich dostęp w przekształceniach przy użyciu następujących metod:
- Użyj wyrażeń
byPositionibyName, aby jawnie odwoływać się do kolumny według nazwy lub numeru położenia. - Dodawanie wzorca kolumny w transformacji Kolumna pochodna lub Agregacja w celu dopasowania do dowolnej kombinacji nazwy, strumienia, pozycji, źródła lub typu
- Dodawanie mapowania opartego na regułach w transformacji Wybierz lub Ujście, aby dopasować dryfowane kolumny do aliasów kolumn za pomocą wzorca
Aby uzyskać więcej informacji na temat implementowania wzorców kolumn, zobacz Wzorce kolumn w przepływie mapowania danych.
Szybkie działanie mapowania dryfowanych kolumn
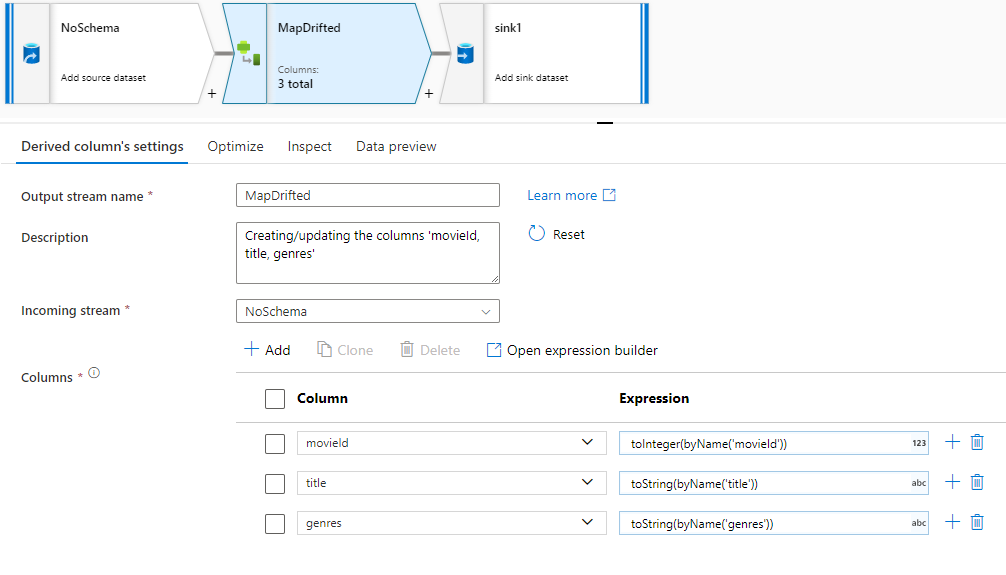
Aby jawnie odwoływać się do dryfowanych kolumn, możesz szybko wygenerować mapowania dla tych kolumn za pośrednictwem szybkiej akcji podglądu danych. Gdy tryb debugowania jest włączony, przejdź do karty Podgląd danych i kliknij przycisk Odśwież , aby pobrać podgląd danych. Jeśli fabryka danych wykryje, że dryfowane kolumny istnieją, możesz kliknąć pozycję Mapowanie dryfowane i wygenerować kolumnę pochodną, która umożliwia odwołowanie się do wszystkich dryfowanych kolumn w widokach schematu podrzędnych.
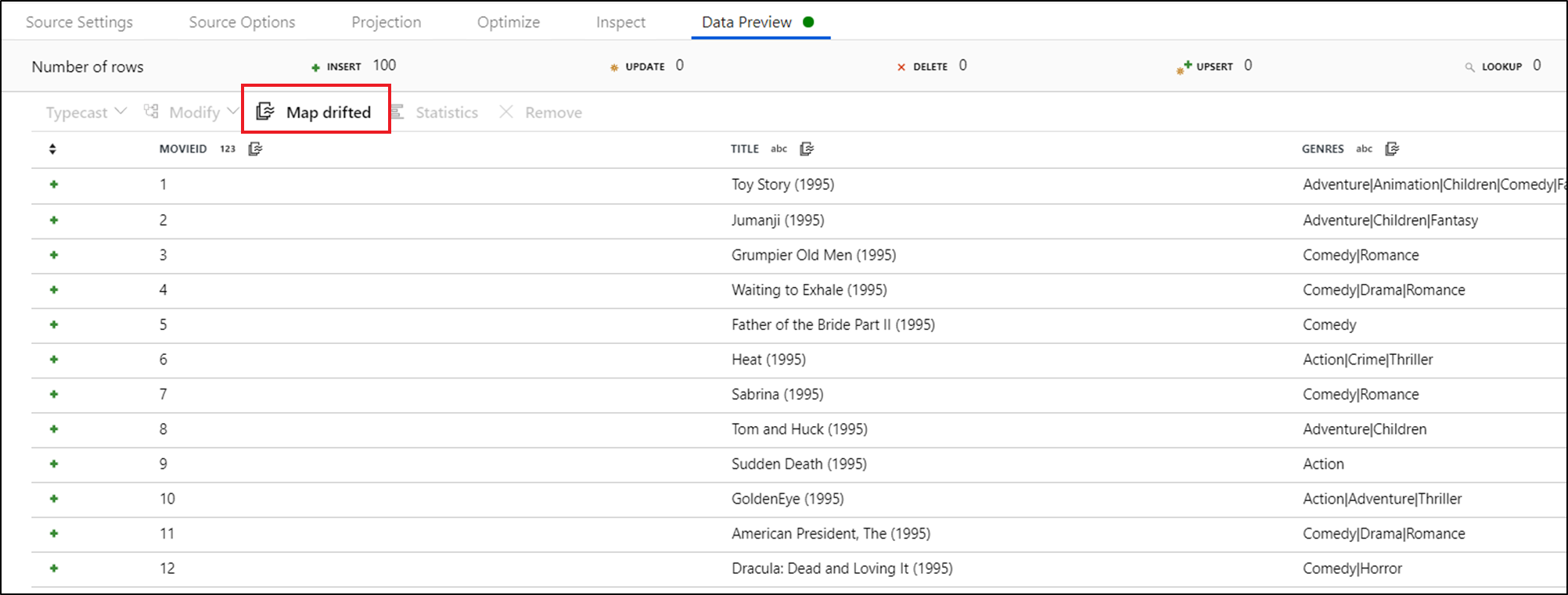
W wygenerowanej transformacji kolumny pochodnej każda dryfowana kolumna jest mapowana na wykrytą nazwę i typ danych. W powyższym podglądzie danych kolumna "movieId" jest wykrywana jako liczba całkowita. Po kliknięciu pozycji Map Drifted identyfikator movieId jest zdefiniowany w kolumnie pochodnej jako toInteger(byName('movieId')) i uwzględniony w widokach schematu w przekształceniach podrzędnych.
Powiązana zawartość
W języku Przepływ danych Expression Language znajdziesz dodatkowe funkcje wzorców kolumn i dryfu schematu, w tym "byName" i "byPosition".